
Abstract
The uncertainty of developers’ activity can lead to engineering problems such as increased software defects during software development. Therefore, advanced approaches to discovering software defects are needed to improve software systems by software practitioners. This paper describes a novel framework named Weighted Supervised-And-Unsupervised Extreme Learning Machine (WSAU-ELM) including the construction of supervised weighted extreme learning machine for software defect prediction (WELM-SDP) and unsupervised weighted extreme learning machine with spectral clustering for software defect prediction (WELMSC-SDP) that can perform significantly better than the previous software prediction methods. The key advantages of this proposed work are: (i) both the two algorithms can reveal the better learning capability and computational efficiency; (ii) the supervised prediction algorithm is more precisely and faster to handle data sets than the common models, and save more time and resources for software companies; (iii) the unsupervised prediction algorithm can increase accuracy compared to the current method; (iv) the paper also discusses the software defect priority for the defective data, and provides the detailed priority levels that is not discussed before. Experimental results on the benchmark data sets show that the proposed framework is not only more effectively than the existing works, but also can extend the study by the priority analysis of software defects.
Keywords
Introduction
Software maintenance has been regarded as the most difficult and costly activity in software development life cycle [5]. During software maintenance period, it is difficult to maintain and evolve a software system with minimised environmental impact, a sufficient economic balance, and well-managed knowledge. Moreover, more bugs or defects cause software systems become complex and time-consuming to maintain. Hence, it is necessary to develop the effective solutions, which could discover the software bugs fast and reduce software development cost.
Yang and Qian [16] proposed approaches to software defect prediction based on supervised learning algorithms. Some popular classifier, including Naive Bayes [6], decision tree [24], logistic regression [1], support vector machine (SVM) [25], k-nearest neighbours (KNN) [18] and ensemble methods [3], have been all utilised to satisfy the requirements of classification. Although the supervised works have implemented the intelligent prediction, the time consuming of these algorithms cannot satisfy developers if the software data keeps increasing continuously, and the model performance were affected by the imbalanced data distribution in software defect data sets. Besides applying the supervised learning to software defect prediction, the unsupervised learning can be also used to predict defect proneness. The typical steps are: 1) clustering software data into k clusters; and 2) labelling each cluster as defective or clean. However, the data dimension usually affects the prediction performance.
To summarise the existing learning models applied in software defect prediction, this paper found that they suffer from either low classification performance or high time-consumption problems. Therefore, this paper wishes to propose more effective and efficient models. The proposed models are named WSAU-ELM. This paper selected extreme learning machine (ELM) as the baseline classifier in software defect prediction based on three observations: 1) it always has better than or at least comparable generality ability and classification performance as SVM and multiple-level perceptron (MLP) [10]; 2) it can tremendously save training time compared to other classifiers [12]; and 3) weighted ELM has an efficient strategy for imbalanced data distribution. In WSAU-ELM, it first took advantage of the idea of cost-sensitive learning to select the weighted extreme learning machine (WELM) [32] as the base learner to address the class imbalance problem existing in the procedure of software defect prediction. Then, it adopted the ELM algorithm to construct a supervised learning framework. Next, this paper drew the advantages from spectral clustering and ELM to descend the data dimension and design an effective weight unsupervised learning framework. Finally, this paper discussed the defect priority for the defective data by Euclidian distance computation, which can support software maintenance further. Experiments are conducted on NASA imbalanced data sets, and the results demonstrate that the proposed algorithmic framework is generally more effective and efficient than several state-of-the-art learning algorithms that were specifically designed for software defect prediction.
In order to solve the above problem, this paper introduced a software prediction framework named WSAU-ELM including the supervised prediction and unsupervised process. For the supervised process, WELM-SDP was proposed and proved that it is not only faster than other methods on running time, but also is competitive with state-of-the-art algorithms in the term of accuracy. For the unsupervised process, WELMSC-SDP can not only reduce the data dimension, but also advance the ACC with the current unsupervised method. Moreover, this paper has discussed the defect priority for the defective data by Euclidian distance computation, which will be able to support software maintenance further.
The contributions of this study are as follows:
Proposing novel methods, WELM-SDP and WELMSC-SDP, for software defect prediction on benchmark datasets in a unified framework. Presenting an empirical study to evaluate the WELM-SDP and WELMSC-SDP approaches against existing software defect prediction approaches.
The rest of this paper is organised as follows. Section 3 describes some priori knowledge and the proposed approach. Section 4 provides experimental results and analysis. Section 2 introduces the related work of software defect prediction. Finally, Section 5 concludes the contributions of this paper and indicates future work.
In this section, some preliminaries are presented first, including extreme learning machine, weighted extreme learning machine, and spectral clustering. Then the proposed core algorithmic models of this article are presented later.
Extreme learning machine
Extreme learning machine proposed by Huang et al. [10] is a specific learning algorithm for single-hidden layer feedforward neural networks (SLFN). The main characteristics of ELM that distinguish it from those conventional learning algorithms of SLFN is the random generation of hidden nodes. Therefore, ELM does not need to iteratively adjust parameters to make them approach the optimal values, thus it has faster learning speed and better generalisation ability. Previous research has indicated that ELM can produce better than or at least comparable generality ability and classification performance to SVM and multiple-level perceptron (MLP) but only consumes tenths or hundredths of training time compared to SVM and MLP.
Let us consider a classification problem with
where
where
According to previous work, ELM can be trained in the viewpoint of optimisation. In the optimisation version of ELM, we wish to synchronously minimise
where
Weighted Extreme Learning Machine that can be regarded as a cost-sensitive learning version of ELM is an effective way to handle imbalanced data. Similar to CS-SVM, the main idea of WELM is to assign different penalties for different categories, where the minority class has a larger penalty factor
where
and
where #(
Unsupervised models make use of clustering methods. Clustering is a common way to discover similar entities. Frequently applied clustering algorithms include k-means and hierarchical clustering. K-means clustering is often to handle high-dimensional data that are linearly separable [13] Hierarchical clustering generates clusters based on the structure of a similarity matrix [9]. Recently, spectral clustering has become more effective to implement clustering process [4] because it can handle different data distribution compared to the traditional clustering methods.
Unlike the k-means clustering based on Euclidean distance, spectral clustering divides dataset based on connectivity among its entities. The similarity [22] in the spectral clustering can be denoted as shown in
where
In the work of [15], a popular solution for spectral clustering is to minimise the normalised cut, which is a disassociation measure the cost of cutting a graph. The three major steps of the algorithm are described as follows:
The Laplacian matrix from weighted adjacency matrix is computed, where the Laplacian matrix is the representation of graph; The eigenvalues are conducted based on Laplacian matrix; and A threshold is chosen on the second smallest eigenvector to gain the bipartitions of the graph, and deciding the threshold through adjusting in the experiment.
In this section, a WSAU-ELM framework including supervised prediction and unsupervised prediction based on extreme learning machine (ELM) is described.
As seen in Fig. 1, the data sets are processed firstly. For the supervised WELM-SDP, the weighted ELM algorithm is applied to build learning model. Firstly, the feature and label of data can be found in the existing data sets. Secondly, the relationship between feature and label can be decided after the training data, and then a learning model will be obtained. Thirdly, applying to the obtained model implement the software defect classification, and evaluation is completed based on the testing data.
WSAU-ELM framework.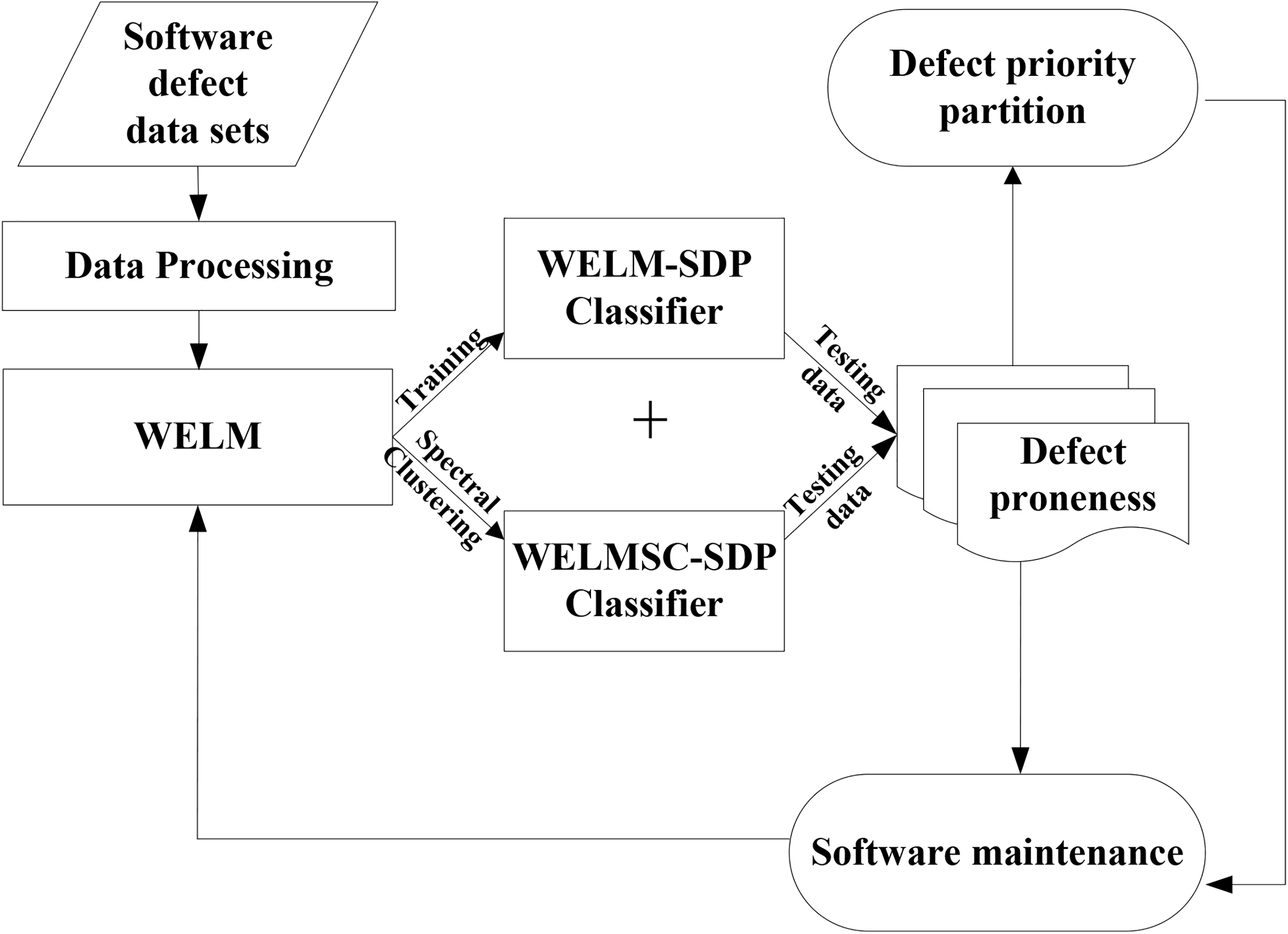
Beside the supervised process, the proposed method is also feasible to unsupervised process. In unsupervised WELMSC-SDP process, since the data label should be not known in unsupervised process, this paper first cleans the label in the existing data sets. Then, the weighted ELM is utilised to reduce data dimension in order to improve the prediction accuracy. Next, the unsupervised learning-spectral clustering is used to build the model based on the cleaned data, and the testing data is applied to evaluate the model.
Meanwhile, the defects are also divided into different priorities to support software maintenance. The following subsections will illustrate the models in detail.
In this section, the detailed procedure of the supervised algorithm is described. Specifically, the algorithm based on weighted extreme learning machine is called as WELM-SDP. Its flow path is briefly described as follows.
During the above process, it needs to carry out normalisation processing in order to eliminate classification error between the amounts of data samples, and the method is given as follow in Eq. (10).
where
The existing unsupervised defect prediction methods almost use the clustering algorithms to build the classification model. However, the high data dimension is still a problem in the clustering process. Hence, this section draws the advantages from spectral clustering and ELM, and proposes an improved unsupervised model. This model considers utilising WELM to discover the underlying structure of original data, and descend data dimension. Then, spectral clustering is applied to implement the software defect identification. The algorithm based on weighted extreme learning machine and spectral clustering is called as WELMSC-SDP. Its flow path is briefly described as follows.
It is important to point out in Step 4, this paper considers two situations for
If the number of hidden neurons ( If
Then the embedding matrix is calculated in Step 5, which makes preparation for the eigenvalues dimension descending. Finally, the spectral clustering performs the unsupervised task in the embedded space as seen in Step 6. The numbers of
The software developers can fix software defects better if they can know the software detailed defect priority. Thus, this subsection proposes a distance calculation method to divide the priority level. The IEEE has proposed software defect priority No. 1 through No. 5 as a standard [28]. Hence, it will be helpful if the defective data can be labelled by five levels of priority.
In order to achieve the target, the Euclidean distance is applied between each sample in defective data and each sample in non-defect cluster firstly. The “distance_every_ave” value is obtained to denote as the average of distance sum of any defective sample with all the non-defective samples, and all the “distance_every_ave” values in a cluster are calculated. Secondly, the calculated results are needed to sort and decide the defect level by the distance comparison. According to the Euclidean distance, it can be found that the distance between defective and non-defective data is closer, which proves that the similarity is higher and the fixing priority should be not urgent. Then the defective data is able to label from Priority 1 to Priority 5, which represents the highest priority and the lowest priority respectively.
Experiments and analysis
Data sets
The study collected the benchmark data sets NASA [2] to validate the effectiveness of the proposed algorithms. As shown in Table 1, the collection includes 10 data sets, number of instances, number of defects and defective ratio.
NASA data sets
NASA data sets
All algorithms are implemented in Matlab 2015a environment, and experiments are conducted on Intel(R) Core(TM) i7 6700HQ 8 cores CPU (main frequency: 2.60 GHZ for each core) and 32 GB RAM.
To validate the effectiveness and superiority of two proposed algorithms, this paper compared them with many representative and state-of-the-art class imbalance learning algorithms which are presented as follows.
Ensemble learning [27]: it is the standard ensemble process without any operations to addressing supervised software defect prediction based Bayes. KNN [26]: it is the standard KNN algorithm without any operations to train supervised prediction model on the training set. Logical regression (LR) [21]: It is the standard LR algorithm without any operations to train supervised prediction model on the training set. Decision tree (DT) [20]: It is the standard DT algorithm without any operations to train supervised prediction model on the training set. Spectral clustering [13]: It is the standard spectral clustering algorithm without any operations to train unsupervised prediction model on the training set.
Before training any classifier, each data set was scaled into [0, 1] interval. Also, considering for evaluation about supervised and unsupervised learning, the study adopted Accuracy and ACC (clustering accuracy) respectively, which is listed below, as the performance evaluation metrics.
where TP (true positive) indicates the defective data is classified as defect-prone; FP (false positive) indicates the non-defective data is classified as defect-prone; TN (true negative) describes the non-defective samples correctly classified as non-defect-prone and FN (false negative) indicates the defective samples incorrectly classified as non-defect-prone.
where
At last, to impartially compare the performance of various algorithms for supervised process, 100 times’ randomly external 10-fold cross validation is applied to calculate the final results that are provided in the form of mean
Tables 2 and 3 present the performance comparisons among the two algorithms on NASA data sets. Table 4 shows the defect priority analysis result. By observing the results, it is not difficult to draw some conclusions as follows.
Accuracy of comparisons between WELM-SDP and other algorithms
Accuracy of comparisons between WELM-SDP and other algorithms
ACC of WELMSC-SDP and spectral clustering
Priority of defective data
In Table 2, the five techniques are useful for promoting the classification performance of software defect prediction on NASA data sets. They have acquired higher Accuracy metric values. Meanwhile, the proposed WELM-SDP algorithm show obviously better performance than the other four algorithms on most data sets (1 to 8). Specifically, it is noted that the data sets (1 to 8) in Table 1 have a relatively high class imbalance ratio, the proposed WELM-SDP algorithm has produced significantly higher performance than other algorithms. The other two data sets have less class imbalance ratio, and the ensemble learning obtains the better results than other algorithms, but WELM-SDP also has the good performance. It proves that the proposed algorithm cannot achieve the good prediction performance, but also handle the imbalanced data problem in software defect data sets. In comparison with the other traditional or state-of-the-art supervised algorithms, WELM-SDP has acquired the best results on 8 data sets, respectively. In addition, it both perform stable on the other 2 data sets, indicating that it is robust enough.
In Table 3, it reports the clustering accuracy (average
As seen in Table 4, it obtains the numbers of different defective priority samples in all the datasets. It can be found: kc1 and pc2 have the same numbers of each priority for defective data; kc2 is different from other datasets on the numbers; kc3 is the same with mc1 and pc4; mc2 is the same with pc1 and pc5; mw1 is the same with pc3. According to the results, software developers can easily choose some datasets together based on the priority level and its numbers together. Meanwhile, the software developers are able to fix the defects more reasonably combining to the developing experience. It indicates that Euclidian distance can be used to calculate the similarity for the priority of software defective data after obtaining prediction results.
Next, this paper detected the clustering numbers of the parameter
Analysis of 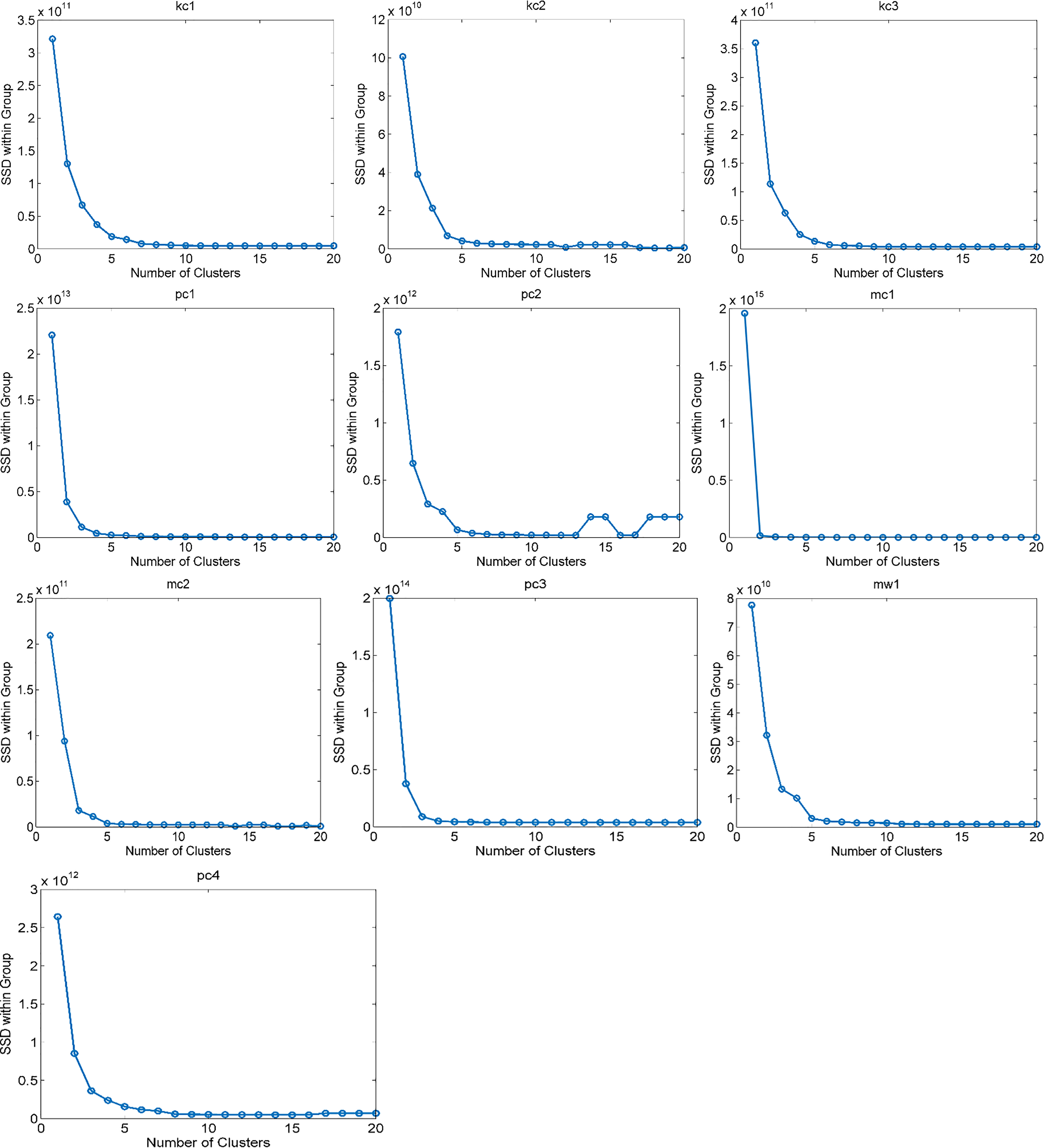
For comparison, this paper computed 100 times’ training time for WELM-SDP Ensemble, KNN, LR, and Decision Tree. According to Table 5, WELM-SDP is the most rapid classifier on the data training in all the compared classifiers. Take the dataset of mw1 as example which is marked by ID-1, it can be seen that Ensemble is over six times than WELM-SDP on running time, KNN is more than seven times than WELM-SDP, LR achieves to over 170 times than WELM-SDP, and LR uses more than eight times than WELM-SDP. The other datasets also show WELM-SDP can save more training time to complete software defect prediction, which can support software developers conduct software maintenance fast and effectively.
As same with Table 5, Table 6 also presents training time spent on unsupervised learning. Since WELMSC-SDP handles the software eigenvectors and conducts the dimension descending, the training time is higher than spectral clustering. Although it is not as fast as spectral clustering, time cost is still acceptable in practice.
Comparison of WELM-SDP and other learning algorithms on training time (s)
Comparison of WELM-SDP and other learning algorithms on training time (s)
Comparison of WELMSC-SDP and spectral clustering on training time (s)
Since the PROMISE repository [33] was created in 2005, the researchers utilised the defect prediction data sets to build comparable models for studies. So far, great numbers of researches have been devoted to metrics describing code modules and learning algorithms to create SDP models.
Software defect prediction can be seen as a binary problem in machine learning. For each sample, there are two types of labels: defective data and non-defective data. Based on the learning model, the input new samples are predicted to determine whether they contain defects. Hence, varieties of machine learning methods have been proposed and compare for SDP problems, supervised learning and unsupervised learning are two main techniques in machine learning, which have been used to build learning models for software defects [4, 5, 6, 7]. The main difference between supervised learning and unsupervised learning is whether the data sets have labels. According to the built SDP models, the time and accuracy of defect prediction can be improved compared to traditional manual work. However, no single method is found to be the best, due to different types of software, different algorithms settings and different performance evaluation criteria of assessing the models. Among all, Random Forest appears to be a good choice for large data sets and Naïve Bayes performs well for small data sets. Yan et al. proposed automated change-prone class prediction using unsupervised method that is more suitable to cross-project prediction [19]. Gray et al. [7] discussed just-in-time software defect prediction on practical code changes. Although all the above approaches can achieve to implement SDP, they ignored the effect of class imbalance.
In additions, Ensemble algorithms and their cost-sensitive variants were studied and shown to be effective if a proper cost ratio can be set [29]. Lu et al. [31] changed the data distribution to handle with the class imbalance based on ensemble undersampling-boost. Issam et al. [17] implemented software defect prediction using ensemble learning on selected features-greedy forward selection.
In summary, current SDP studies include the feature selection of SDP data sets, the data sampling techniques for class imbalance of SDP and ensemble algorithsm design for SDP prediction. This study mainly focuses on the imbalanced SDP problem to introduce an improved training classifier WELM with relative density measurement and fuzzy set, which shows more robust as it is irrelevant with the scale of data distribution in feature space in contrast with Euclidean distance-based measure. Comparing with top-used SDP classifiers like Random Forest and Naïve Bayes, WELM also has better generalisation ability than them. Moreover, the single classifier is also compared with some representative ensemble learning algorithms on SDP like DNC for SDP imbalance.
Conclusion and future work
This paper described WELM technique in the context of software defect prediction, and presented a framework of SDP named WSAU-ELM algorithms. First, comparing to the four existing learning techniques, the introduced WELM-SDP does not have the remarkable training efficiency that can save time and resources, but also shows the best classification accuracy on eight of ten data sets, and then the second better method is ensemble learning. Although ensemble technique is constructed by many single classifiers and recognised to be better choice in the classification, the proposed single WELM-SDP classifier still has the competitive performance on the benchmark data sets.
Then, with respect to the existing software defect unsupervised prediction, experimental results also show that the WELMSC-SDP model gives better accuracy compared to the current popular spectral clustering, which can evaluate the data dimension will affect the clustering result and WELM can be incorporated in the unsupervised process. For both prediction models, it proves that WELM cannot only satisfy the requirements of supervised and unsupervised software defect prediction, but also show better model performance than the common learning algorithms. Specially, the priority has been discussed for defective data to assist with software developers during software maintenance.
However, this paper only chose sample open source project data to evaluate the proposed approach and discussed the within project prediction. The practical software system is more complex. Therefore, it will be a challenging to present more intelligent methods or learning algorithms to solve complex prediction for practical software defects in the future.
Footnotes
Acknowledgments
This work was supported in part by the Scientific Research Foundation for the introduction of talent of Jiangsu University of Science and Technology, China; Natural Science Foundation of the Higher Education Institutions of Jiangsu Province, China (Grant No. 18JKB520011); Primary Research & Development Plan (Social Development) of Zhenjiang City, China (Grant No. SH2019021); Natural Science Foundation of Jiangsu Province, China (Grant No. BK20191457).
Authors’ Bios