
Abstract
Remote sensing is an indispensable technical way for monitoring earth resources and environmental changes. However, optical remote sensing images often contain a large number of cloud, especially in tropical rain forest areas, make it difficult to obtain completely cloud-free remote sensing images. Therefore, accurate cloud detection is of great research value for optical remote sensing applications. In this paper, we propose a saliency model-oriented convolution neural network for cloud detection in remote sensing images. Firstly, we adopt Kernel Principal Component Analysis (KCPA) to unsupervised pre-training the network. Secondly, small labeled samples are used to fine-tune the network structure. And, remote sensing images are performed with super-pixel approach before cloud detection to eliminate the irrelevant backgrounds and non-clouds object. Thirdly, the image blocks are input into the trained convolutional neural network (CNN) for cloud detection. Meanwhile, the segmented image will be recovered. Fourth, we fuse the detected result with the saliency map of raw image to further improve the accuracy of detection result. Experiments show that the proposed method can accurately detect cloud. Compared to other state-of-the-art cloud detection method, the new method has better robustness.
Keywords
Introduction
With the rapid development of remote sensing technology, remote sensing image has been widely used in scientific research, social services and other fields [1, 2, 3]. In China, the indexes of domestic satellites represented by Gaofen-1, Gaofen-2 and Resource-3 are close to the international advanced level [4]. The quality and data volume of domestic satellite images are increasing rapidly, and the marketization degree is greatly improved compared with previous time, which plays an important role in various fields of society. However, not all remote sensing images can be directly used in engineering projects and research practices. One of the important limiting factors is that the images acquired by satellite-borne satellites generally contain clouds due to cloud cover, which accounts for a relatively large proportion, generally more than 50% [5]. The existence of clouds not only covers the surface information, but also affects image registration, fusion, image information extraction and other processing. Therefore, it is very necessary to detect and remove clouds from remote sensing image. However, there are still bottlenecks in the current image cloud detection and removal technology [6].
Cloud is ubiquitous in remote sensing images. By shielding ground objects, it weakens the recording of the real radiation characteristics of the surface by satellite sensors, thus changing the spectral information of ground objects [7, 8, 9]. Therefore, remote sensing image cloud identification is a very critical data preprocessing, and the accuracy of cloud identification has an important impact on land use classification, change detection and quantitative extraction of remote sensing parameters.
In this paper, we propose a saliency model-oriented convolution neural network for cloud detection in remote sensing images. This paper is organized as follows. First, the related works are shown in Section 2. The training process and super-pixel segmentation are introduced in Section 3. In Section 4, the super-pixel segmentation method is adopted for obtaining cloud saliency map. In Section 5, experiments on the remote sensing images from Google Earth are implemented. The proposed method and the state-of-the-art cloud detection methods are compared in both subjective and quantitative evaluations. Finally, a conclusion is conducted in Section 6.
Literature review
In recent years, many scholars have proposed a variety of cloud detection methods in remote sensing image, where spectral threshold method is one of the simplest and most effective algorithms in the current cloud detection field. The method mainly uses remote sensing image spectral feature, namely according to the cloud in the visible or infrared reflectivity or bright temperature value and other spectral characteristics, the cloud and non-cloud by brightness threshold feature will be segmented.
Cloud detection methods are mainly divided two aspects. One is the traditional method. For example, Wang [10] proposed an improved method for detecting cloud combining K-means clustering and the multi-spectral threshold approach. On the basis of landmark spectrum analysis, MODIS data was categorized into two major types initially by K-means method. The first class included clouds, smoke and snow, and the second class included vegetation, water and land. Then a multispectral threshold detection was applied to eliminate interference such as smoke and snow for the first class. Li [11] presented a new spectral-spatial classification strategy to enhance the performance of an orbiting cloud screen obtained on hyperspectral images by integrating a threshold exponential spectral angle map (TESAM), adaptive Markov random field (AMRF) and dynamic stochastic resonance (DSR). TESAM was applied to roughly classify cloud pixels based on spectral information. Then AMRF was used to do optimal process by using spatial information, which improved the classification performance significantly. Nevertheless, misclassifications occurred due to noisy data in the onboard environments, and DSR was employed to eliminate noise data produced by AMRF in binary labeled images. Another method is deep learning method. For example, Jedlovec [12] proposed a new cloud detection technique. The bispectral composite threshold (BCT) technique adopted only the 11th mum and mum 3.9 channels, and the composite imagery generated from these channels. In a four-step cloud detection procedure to produce a binary cloud mask at single pixel resolution. This kind of cloud detection method has the advantages of simple calculation and high monitoring efficiency. But it also has many defects, such as requiring images to have thermal infrared band information, slightly lower monitoring accuracy, misjudgment and so on.
Based on the difference of cloud and ground object texture features, cloud and ground object can be distinguished by extracting feature combination (such as gray level symbiosis matrix, Gabor texture features, etc.), which is another cloud detection method with better effect in remote sensing image. Başeski [13] proposed a new method making use of both color and texture characteristics of cloud regions. The image was divided into sub-images in order to perform initial color and edge analysis. Liu [14] designed a super-pixel level cloud detection method based on convolutional neural network (CNN) and deep forest. Firstly, remote sensing images were segmented into super-pixels through the combination of SLIC and SEEDS. Structured forests was carried out to compute edge probability of each pixel, based on which super-pixels were segmented more precisely. Segmented super-pixels composed a super-pixel level remote sensing database. However, due to the diversity of cloud features in optical remote sensing images, the distribution of different cloud features in feature combination is not typical, so it is still difficult to use texture difference for cloud detection. Some modified cloud detection algorithms based on texture feature, to a certain extent, improve the cloud detection accuracy. But there are some defects such as time-consuming, laborious training classifier and difficulty in automatic extraction of massive image data. Convolutional neural network (CNN) is a typical deep learning algorithm, and its model parameters can be obtained through network training by gradient descent method, avoiding the complex pre-processing process in the early stage of image. Moreover, the trained convolutional neural network can fully mine the features in the image and efficiently complete the cloud detection of remote sensing image.
To solve the above problems, we propose a saliency model-oriented convolution neural network for cloud detection in remote sensing images. We use KCPA to unsupervised pre-training the network. Then the network structure is fine-tuned. Remote sensing images are performed with super-pixel approach before cloud detection to eliminate the irrelevant backgrounds and non-clouds object. The image blocks are input into the trained CNN for cloud detection. Finally, we fuse the detected result with the saliency map of raw image to further improve the accuracy of detection result.
Proposed CNN and super-pixel segmentation
Convolution neural network (CNN)
Convolution neural network (CNN) is inspired by biology, neuroscience [15, 16, 17]. It refers to its structure principle combined with artificial neural network and produces one of the pioneering researches. CNN is a kind of feed forward artificial neural network system with deep learning ability. Typical convolution neural network model concludes the input layer, convolution, sample layer, fully connected layer. Compared with the traditional neural network, the convolutional neural network has strong applicability, feature extraction and classification at the same time, strong generalization ability, less global optimization training parameters, which gradually becomes the hot-spot research in the field of deep learning [18, 19]. Its principle structure is shown in Fig. 1.
CNN framework.
The working processes of the convolutional neural network are as follows.
First of all, the image executes convolution operation on convolution layer. And the convolution output feature graph is sampled by the sampling layer [20]. Then after a number of convolution operations and sampling processing, the extracted feature images are classified through the full connection layer. Output the target result.
In this paper,
where the symbol
The feature graph calculated by the CNN has the dimension of millions. If classifiers are trained directly, it is easy to lead to over-fitting [21, 22]. Therefore, it is necessary to carry out the image feature graph down-sampling after the convolution operation, namely pooling operation. At the same time, in order to avoid the loss of information in the pooling operation, the probability maximization is usually used for the pooling operation.
Assume that one neuron in the sampling block
Traditional full connection layer parameters are huge, which may lead to over-fitting problems. Therefore, when designing the network framework, this paper considers to replace the final full connection layer with a fully maximized pooling layer. The structure of deep convolutional neural network designed in this paper is shown in Fig. 2.
Proposed CNN network in this paper.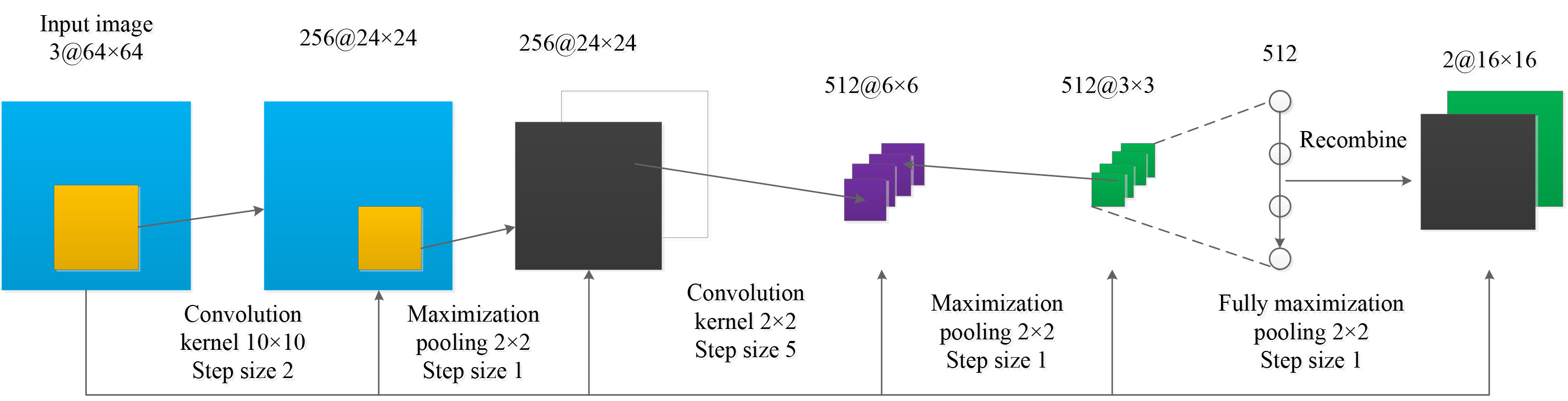
The training of CNN requires a large number of samples, while the actual sample base establishment requires a lot of time and manpower. To solve this problem, this paper adopts the semi-supervised classification method to train the CNN network, which can effectively improve the training efficiency while ensuring the training samples [23].
This paper adopts the unsupervised pre-training network based on kernel principal component analysis structure. It is assumed that the images input into the convolutional neural network have M scenes, the size is
Kernel principal component analysis method is adopted to minimize reconstruction errors and solve eigenvectors.
where
where
The network structure is supervised and pre-trained through kernel principal component analysis, and the initial weight parameters of the network are obtained. Then the whole network is fine-tuned through labeled data. The process of training convolutional neural network in this paper is shown in Fig. 3.
The new detection process in this paper. Abbreviations: CNN: Convolutional Neural Network. KPCA: Kernel Principal Component Analysis. SLIC: Simple Linear Iterative Clustering.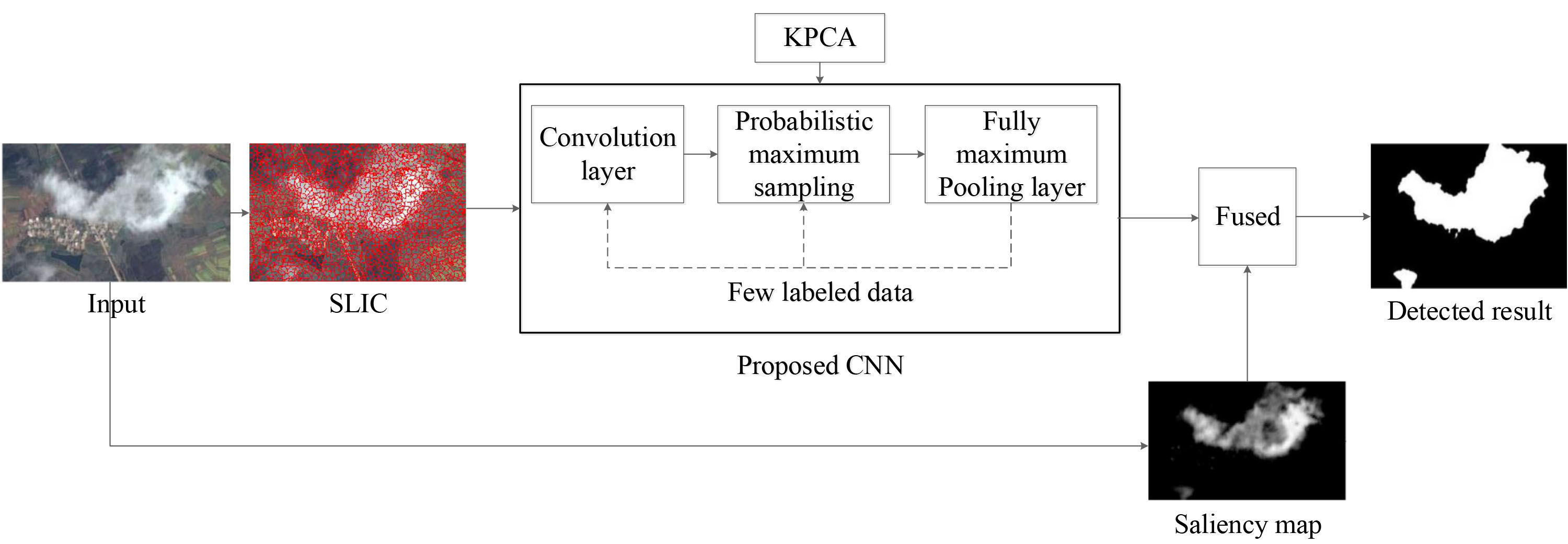
In order to avoid the low efficiency of cloud detection by inputting the whole image into the convolutional neural network, the remote sensing image needs to be pre-processed into blocks before cloud detection. On the basis of the spectral and spatial characteristics of remote sensing image, the simple linear iterative cluster (SLIC) is used to generate super-pixels [24] to improve the classification accuracy.
SLIC consists of similar pixels with similar spectra and adjacent spaces. Assuming remote sensing image
The spectral features are described as the sum of the Euclidean distances of the pixel spectra and all the generated super-pixels in the N bands, which can be expressed as:
where
The spatial feature is described by the distance between the pixel and the super-pixel in the coordinate system, and the expression is:
The final SLIC clustering function can be defined as:
where
The function of human visual attention mechanism is to locate the interesting object quickly from the complex visual scene. Current simulation calculation model of visual attention is mainly divided into two categories: a) Bottom-up visual calculation model based on low-level vision features, the typical model is Itti [25], when the background distribution is clutter, the processing result is not ideal. b) For a specific object, the top-down visual selective attention model based on its advanced visual feature. In remote sensing images, clouds have typical shape and significant texture features. Therefore, this paper uses visual model to calculate region saliency regarding the cloud area and shape, texture features as the visual search object and middle-bottom feature respectively. And it considers the above as the evaluation index to judge whether this region is a cloud region, finally determine the location of the cloud region by measuring this index.
In order to highlight the texture of cloud area and improve the distinction between cloud area texture and other disturbing textures, there are two processing means. 1) Combining with the features (such as multi-scale, multi-direction and translational invariance) of nonsubsampled contourlet transform (NSCT), local texture energy of each scale and direction sub-band after NSCT decomposition is taken as its texture feature. Combining with maximizing the information content of each feature, the saliency map is obtained. However, more global features are lost under more complex background. 2) On the basis of “global isolation and local compactness” in saliency region, the problem of saliency detection is transformed into markov random walk problem. So an algorithm for detecting saliency objects based on random walk on mixed graph is proposed. However, due to the fully connected mixed graph constructed by the algorithm, the time complexity of the algorithm is
In order to rapidly calculate the saliency features, the QDCT (quaternion discrete cosine transform) method [26] is adopted to extract the saliency map in this paper.
where
A single pixel is not enough to represent the feature information of the cloud, so the cloud needs to be segmented. In order to speed up the subsequent processing, this paper adopts the method of combining super-pixel block with visual saliency map. Based on SLIC algorithm, the image is biased into blocks combined with the obtained saliency image, and dense super-pixels are generated for saliency regions. A relatively sparse super-pixel is generated in the non-significant region. While reducing the number of global pixels, the edge details are retained, which is beneficial to the subsequent extraction and processing.
Saliency region
Grid initialization. The grid space
where
Clustering. Under the defined distance function
where
Edge refinement. According to SLIC algorithm, it finds the edge pixel
We define our proposed cloud detection method as SCNN (saliency model-oriented convolution neural network). The following is the procedure of SCNN cloud detection Algorithm 1.
Experiments and analysis
The experiments are conducted on Ubuntu16.04 with Python software. The deep learning framework is Caffe, whose hardware environment is Intel Core i7, 16G memory, GPU GeForce GTX 1080.
The convolutional neural network structure constructed in this paper consists of two convolutional layers, two pooling layers and a full connection layer. The first layer of convolution filters is set to 340. The second layer of convolution filters is set to 200. Filter sizes are set to 5
Visual comparisons of the cloud detection results with different methods.
As can be seen from Fig. 4, the proposed network can improve the performance of the training network, which verifies the rationality of the network constructed in this paper.
To verify the effectiveness of the proposed cloud detection method in this paper, we also conduct comparison with GAGC [27], SLCD [28] and COF [29]. GAGC treated clouds as a special kind of object and eliminate human labeling by two procedures. First, it adaptively computed the thresholds for each cloud image which automatically label some pixels as “cloud” or “clear sky” with high confidence. Then, those labeled pixels served as hard constraint seeds for the following graph cut algorithm. SLCD contained two modules: feature data simulating and cloud detector learning and applying. It first simulated a kind of cubic structural data by stacking different fundamental image features, including color, statistical information, texture, and structure. Such data synthesized different image features, and it was used for cloud detector training and applying. Cloud detector was designed based on minimizing the residual error between the feature data and its labels. COF extracted the color, texture, and statistical features of the remote sensing images with the color transform, dark channel estimation, Gabor filtering, and local statistical analysis methods. Then, an initial cloud detection map could be obtained by performing the support vector machines (SVM) on the stacked features, in which the SVM was trained with a set of samples automatically labeled by processing the dark channel of the original image with several thresholding and morphological operations. Finally, guided filtering was used to refine the boundaries in the initial detection map. The images are obtained from Google Earth. The ground truth of all images is manually marked. The cloud detection comparison results with different method are shown in Fig. 4.
In this paper, precision, recall (recall
where TP denotes the case where positive class is judged as positive, FP represents the case where negative class is judged as positive, and FN represents the case where negative class is judged as positive. The value of precision rate and recall rate is from 0 to 1. The value is closer to 1, the algorithm performance is better. However, there is a contradiction between them. By introducing the weighted average
Overall comparison.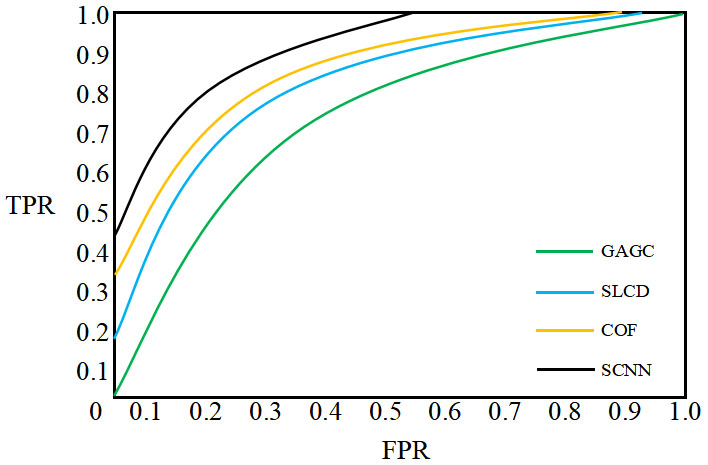
The original images contain thin cloud, thick cloud, broken cloud and the translucent thin cloud, which are difficult to distinguish. Some images include cloud and snow or ice, which can easily cause confusion. It can be seen from Fig. 5 that the GAGC method can effectively identify thick clouds, but it has a poor effect on thin clouds. It is easy to identify bright ground objects as clouds, such as underlying surface covered with snow or ice. The SLCD method uses the combination of feature data simulating and cloud detector learning, which can overcome the interference of some noises. However, it is easy to be affected by the super pixel segmentation and generate the initial error, so the detection accuracy at the pixel level cannot be obtained, and it is easy to miss the detection of broken clouds. COF is an unsupervised method for cloud detection. It extracts the color, texture, and statistical features of the remote sensing images with the color transform, dark channel estimation, Gabor filtering, and local statistical analysis methods. So, an initial cloud detection map can be obtained by performing the support vector machines (SVM). A guided filtering is used to refine the boundaries in the initial detection map to improve the cloud detection accuracy. But it loses some features in the sampling process, resulting in fuzzy and smooth cloud detection results.
Performance comparison
Abbreviations: COF: Coarse-to-Fine Method. GAGC: Ground-Based Cloud Detection Using Automatic Graph Cut. SCNN: Saliency Model-oriented Convolution Neural Network. SLCD: Scene Learning for Cloud Detection.
Average accuracy and error comparison
ROC comparison.
The cloud detection result of proposed method is better than that of other three methods. SCNN method adopts KCPA to unsupervised pre-training the network. Small labeled samples are used to fine-tune the network structure. The proud is that it fuses the saliency map to further improve the detection result. Even under complex conditions (underlaying surface, a large number of thin clouds, etc.), the cloud can still be more completely extracted.
As can be seen from Table 1, compared to other methods, the recall and precision rate of the proposed algorithm is the highest. The F-measure of proposed method is improved due to the introduction of super pixel and saliency-oriented. Meanwhile, the time cost is less. Table 2 is the comparison of average accuracy and error. It displays the better result with proposed cloud detection method. Figure 6 is the ROC comparison with different methods. As seen, for the clouds, the ROC value of SCNN is greater than those of GAGC, SLCD and COF. This can be easily explained because the super-pixel segmentation approach of SCNN are more suitable for remote sensing objects than those of other methods. Better cloud detection results are obtained using SCNN.
This paper proposes a new cloud detection method based on saliency model via convolution neural network. Through experimental analysis, this method can make up for the shortcomings of traditional cloud detection methods. The cloud detection method proposed in this paper has high detection accuracy, few misjudgments and low error detection rate. Cloud shadows can be detected effectively with good generalization compared to other state-of-the-art methods. However, if the overlapped clouds are very complex, the proposed method has a low detection rate. In the future, we will research more advanced deep learning methods to improved the complex cloud detection effect.
Footnotes
Author’s Bios