
Abstract
A wide variety of uses, such as video interpretation and surveillance, human-robot interaction, healthcare, and sport analysis, among others, make this technology extremely useful, human activity recognition has received a lot of attention in recent decades. human activity recognition from video frames or still images is a challenging procedure because of factors including viewpoint, partial occlusion, lighting, background clutter, scale differences, and look. Numerous applications, including human-computer interfaces, robotics for the analysis of human behavior, and video surveillance systems all require the activity recognition system. This work introduces the human activity recognition system, which includes 3 stages: preprocessing, feature extraction, and classification. The input video (image frames) are subjected for preprocessing stage which is processed with median filtering and background subtraction. Several features, including the Improved Bag of Visual Words, the local texton XOR pattern, and the Spider Local Picture Feature (SLIF) based features, are extracted from the pre-processed image. The next step involves classifying data using a hybrid classifier that blends Bidirectional Gated Recurrent (Bi-GRU) and Long Short Term Memory (LSTM). To boost the effectiveness of the suggested system, the weights of the Long Short Term Memory (LSTM) and Bidirectional Gated Recurrent (Bi-GRU) are both ideally determined using the Improved Aquila Optimization with City Block Distance Evaluation (IACBD) method. Finally, the effectiveness of the suggested approach is evaluated in comparison to other traditional models using various performance metrics.
Keywords
Introduction
Human activity recognition (HAR) [1, 2] is an area of research that focuses on the spontaneous recognition of people’s daily normal activities via time series recordings and sensors. Sensors, edge computing, IoT, and cloud computing has provide a significant developments in the previous decade. As the sensors are low-cost components that may be easily incorporated or implanted in both non-portable and portable devices, the majority of human activity recognition [3, 4] research has switched to sensor technology. Wearable sensors are the common IoT application that is utilized for the quick capturing of diverse physical movements or actions. In recent decades, the quick proliferation of reasonably priced smart phones as well as smart watches with wearable Inertial Measurement Units (IMU) sensors (gyroscopes andaccelerometers) can accurately detect and locate human motions in different fields like personal fitness trackers, healthcare, biometrics, elderly care, sports analytics, surveillance, and security. The significance of human activity recognition [5, 6] depending on wearable sensors is evident in the fact that it could be used to monitor and locate a wide range of everyday activities, including drinking, eating, detecting sleep irregularities, as well as brushing teeth, but not confined to exercise-related actions.
Human activity recognition [7, 8] distinguishes simple and complex actions. There are limited research on recognizing complicated human activities including brushing teeth, dribbling a ball, and so on. Complicated human actions encompass performing a simple human action along with a specific transition activity. Several applications are available for video action recognition [9, 10], including surveillance privacy and security systems, content-based video retrieval, human–computer interaction, and activity identification. Moreover, the activity recognition goal [11] is to identify and verify individuals, their behavior, or unusual behaviors in videos, as well as to offer relevant information to assist interactive programmers and IoT-based systems. Due to major advancements in occlusions, camera movements, action recognition variations, and complex backgrounds in illumination postures numerous challenges with regards to guaranteeing the safe and secure environment of residents, such as virtual reality, industrial monitoring, person identification, violence detection, and cloud environments. In videos, temporal and spatial information are critical for distinguishing various human behaviours [12].
Human activity recognition with labeled data is a multivariate time series categorization and supervised learning challenge in the machine learning [13] field. Numerous research have looked at the challenge of activity recognition utilizing both classic techniques like XGBoost, SVM, and Random Forest (RF), as well as non-traditional deep learning approaches like Convolutional Neural Network (CNN), Artificial Neural Network (ANN), Long Short Term Memory (LSTM), and Recurrent Neural Network (RNN). Conventional methods have the disadvantage of requiring a lot of feature engineering and human feature extraction, which would be time-consuming. deep learning approaches [14] could acquire features from necessary data, making them better suited to the challenge of identifying complicated human actions. In video-based action and behavior identification, deep learning is presently the most popular and commonly used approach for learning increased discriminative important aspects and building end-to-end systems. Conventional deep learning techniques for human activity recognition [15] use pre-trained models to learn features from video frames using simple CNNs algorithms in convolution operations. To train a classification algorithm [16], these convolutional layers collect and integrate spatial information. Conventional CNN models perform worse in sequential data than handmade features. For example, LSTM [17, 18] is used to recognize actions utilizing characteristics learnt from a CNN with spatiotemporal data. Direct image classification is done using CNN [56]. Deep learning algorithms are divided into four categories based on how they are used, including mapping-based deep learning, instance-based deep learning, network-based deep learning, and adversarial-based deep learning [57, 58, 59]. Furthermore, RNNs have been used to address spatiotemporal difficulties in surveillance technology, with the LSTM developed particularly for higher-term video sequences in human activity recognition for learning and interpreting temporal characteristics [19, 20]. When compared to single learner, ensemble classifier is used [51]. Ensemble classifier improves the accuracy and robustness of the system [52]. Successful generalizable machine learning models are mostly determined by the quantity of training data. The machine-running technology developed to deal with these problems is ensemble methods. An ensemble of classifiers combines the opinions of individual classifiers in some way in order to categorize fresh samples [53, 54, 55].
The following is the major contributing parts of this research work:
Improved Bag of Visual words, local texton XOR pattern, and Spider Local Image Feature (SLIF) based features are determined. Hybrid classifier with fined tuned weights via proposed Improved Aquila Optimization with City Block Distance Evaluation (IACBD) model. Offers an upgraded version of the Aquila Optimizer in the form of a new IACBD framework. The proposed overcomes the drawback of traditional Aquila Optimizer (AO), such as lack of exploration ability and enhances its performance.
The paper is structure in this format: The review of the human activity recognition model is given in Section 2 of this article. Section 3 depicts the human activity recognition model’s overall framework. In Section 4, the pre-processing and feature extraction stages of human activity recognition are described. Section 5 explains the classification using a hybrid classifier like optimised Bi-directional Gated Recurrent Unit (Bi-GRU) and LSTM. The weight optimization of Bi-GRU and LSTM using an improved aquila optimization with city block distance evaluation is depicted in Sectio 6. Then, Section 7 specifies the result and discussion. Section 8 at the end contains the research’s conclusion. Table 1 depicts the nomenclature.
Nomenclature
In 2021, Saurabh et al. [21] have suggested CNN-GRU, a unique hybrid deep learning approach to identify the complicated human behaviors by researchers. In this investigation, raw sensor data from the WISDM dataset was employed. From the original dataset, distinct datasets for smart phones and smart watches were separated out. The sliding window method was used to manipulate data during preprocessing. This research did not include any manual feature engineering. As a whole, the analysis indicate that hybrid deep learning models can proficiently and spontaneously extract spatial-temporal features from raw sensor data to categories complicated human actions, as well as they can offer higher accuracy than other deep learning techniques used in this research, that had a more complicated architectures.
In 2020, Jie et al. [22] has suggested a high-speed network for human activity recognition. The goal is to increase the performance of optical flow feature extraction and investigate the spatio-temporal feature fusion approach. This technique for spatio-temporal features fuses temporal and spatial data into fusion features. Rather than the VGG16 network, that is employed to analyze optical flow characteristics to acquire plentiful features, they suggest CNN with OFF. On the other hand, they employ CNN to compute optical flow, considerably increasing the model’s speed. Finally, the algorithm could operate at a frame rate of around 140 frames/second. The suggested approach might effectively increase the accuracy of human activity recognition when comparing to extant video action recognition techniques.
In 2021, Kumie et al. [23] has focused on two Branch Novel-View Action Generation technique, that creates a new action sample for arbitrary-view human activity recognition using auxiliary conditional Generative Adversarial Network (GAN). The created sample increases the number of action examples available for training. Additionally, they offer a view-domain generalization approach which enhances the arbitrary-view based on detection capability of human activity recognition by narrowing the description of actions in various views. This technique was validated using two forms of view-invariant assessments on 3 datasets. The suggested method succeeds admirably in the recognition of human actions.
In 2021, Jianjing et al. [24] have proposed a hybrid method to context-aware human activity recognition and predictions based on the merging of Virtual Measurement (VMM) and CNN. The goal was to use the temporal and spatial context encoded in visual information to identify and anticipate human actions. For collaborative context recognition and action detection, a bi-stream CNN framework object information and parses person is determined as the spatial context included in video pictures. In test bed, the effectiveness of the devised approach was experimentally assessed. Both prediction and action recognition have been shown to be extremely accurate.
In 2021, Jonghyun et al. [25] have proposed TA3DNet, a weakly-supervised 3D network with temporal attention in human activity recognition that speeds up 3D CNNs through allocating varying priority to each frame at various times. Then, they use a temporal attention module to give each frame varying weights. In a weakly-supervised method, they trained the temporal attention component in which weights were updated with no supplementary labels as well as class labels. As a consequence, TA3DNet minimizes the input frames amount and builds a network based on lightweight action recognition. Tests revealed that TA3DNet beats traditional algorithms for action recognition on 2 tough datasets.
In 2021, Khan et al. [26] has adopted a BiLSTM-based learning algorithm with a Deep Convolutional Neural Network (DCNN) which systematically concentrates on effective characteristics in the image input. Researchers employ the DCNN framework to identify the prominent features in this varied network, and the residual blocks used to enhance the features to maintain larger data. They also combine Softmax with the centre loss to increase the loss function in video-based action categorization resulting better outcomes. The suggested approach was tested against three datasets, and it obtained recognition rates of 98.3%, 99.1%, and 80.2%, correspondingly, indicating a 1%–3% increase over extant systems.
In 2021, Jansi et al. [27] has suggested hierarchical evolutionary scheme for human activity recognition based on sparse characterizations. The aim of this article was to build a methodology for human activity recognition that yields higher outcomes. Hierarchical Aggregation/disaggregation and Decomposition/composition (HAD) algorithm, a revolutionary approach for determining hierarchical structure from input data, was described. They also proposed a new Sparse Dictionary Optimization (SDO) approach for building dictionaries, which could also help with sparse representation-based categorization. For the USC–HAD and HAPT datasets, the selected classification system received F-score values of 98.01% and 93.51%, correspondingly.
Review on extant human activity recognition approaches: features and limitations
Review on extant human activity recognition approaches: features and limitations
In 2021, Suwannarat et al. [28] have worked to optimize DNN-depending on human activity recognition through lowering the acceleration data dimensionality, selecting the most appropriate sample size for DNN processing, as well as minimizing the parameters of the suggested architecture. To develop our potential designs, they used 2 reported DNN-based human activity recognition frameworks as starting points and baselines. Based on getting acceleration data in the CPU processing time and sensor, the suggested classifiers with optimized parameters were beneficial since they demand less processing time and power usage. They also lower the amount of memory required for parameter storage and ideal to be used in a wearable device.
The review on existing human activity recognition model was expressed in Table 2. First, the CNN-GRU method was used in [21] that has a higher accuracy, maximum F1-score, improved precision, and better recall; nevertheless, more complex DNN models were not considered in this work. CNN model was used in [22] has high speed, better efficiency, and improved accuracy, but the proposed work does not explored more efficient ways to generate optical flow. Moreover, the two-branch novel-view sample generation scheme was determined in [23] with larger recognition accuracy, and high-quality samples. Nevertheless, NTU RGB
The human activity recognition system presented in this research that involves 3 stages: preprocessing, feature extraction, and classification”. The input image frames (video)are initially processed to the preprocessing step. Initially, median filtering and background subtraction based preprocessing is performed. The preprocessed image is next exposed for the feature extraction, which extracts an improved Bag of Visual words, local texton XOR pattern, as well as SLIF. Furthermore, the extracted features are subjected for the classification. In this instance, a hybrid classifier such as LSTM and Bi-GRU is used to classify the actions. The hybrid model is as follows: The features are separately passed to both the classifiers, and obtains the classified outcome. The outcomes of LSTM and Bi-GRU are averaged to provide the final classified results. To improve performance of the system, the weight of both the LSTM and Bi-GRU will be optimally tuned by the proposed IACBD that ensures precise recognition. Then, the final outcome is extremely accurate. The adopted scheme’s layout is shown in Fig. 1.
Adopted scheme’s layout.
Preprocessing
To star with the model, preprocessing is the initial process, which will be handled under certain processes. In this work, two processes will be performed to enhance the input, and they are: Median Filtering, and Background subtraction.
Median filtering
During the pre-processing stage, the input image is improved using the median filtering method. Using the median filtering [29] approach, the input image is smoothed and denoised. The neighborhood mask of the median value is also used to recover the noise value or digital picture sequence. The aggregated median value, which replaces the noisy value, and the neighboring pixels are sorted, is recorded depending on the grey levels. Moreover,
where
Lowering the noise performance: A nonlinear filter called median filter evaluate an image with random noise is challenging. The median filtering method is used to calculate the noise variance of a picture underneath a normal distribution having zero mean noise, as stated in Eq. (1).
where
The noise variance is represented in Eq. (2) when using the average filter.
The impacts of median filtering depend on the noise distribution and mask size when comparing Eqs (1) and (2). Furthermore, compared to the average filtering efficiency, the median filtering results yield the least amount of random noise. Since the pulse width is smaller than
Background subtraction [30, 31] is a method that involves creating a foreground mask to separate foreground items from the background. Moreover, the foreground mask is calculated through the background subtraction via subtracting the recent frame from a background model that includes the static component of the picture. There are two basic phases in background modelling: Background Initialization, and Background Update.
The background’s initial model is calculated in the 1
Thereby the pre-processed image is denoted as
Feature extraction
Subsequent to the preprocessing, certain features are extracted from the preprocessed image that aids in recognition. Three sort of features are extracted including (i) Improved bag of visual words, (ii) Local Texton XOR pattern, and (iii) Spider Local Picture Feature (SLIF)
(i) Improved bag of visual words: the bag of visual words (BoW) is probably the most used feature representation approach for videos and still pictures in the field of human activity recognition. The BoW, also known as the bag of visual words is a typical feature symbolization approach used for document symbolization in information retrieval. In the domains of image/video retrieval, this approach was applied. Here the required collection of visual words can be computed in Eq. (3).
As per the improved bag of visual words, this required collection of visual words is evaluated by new formula calculation given in Eq. (4). Here, the shannon’s entropy
where
Texton shapes.
(ii) Local Texton XOR pattern [32, 33]: In this LTXOR pattern, Seven dissimilar Texton shapes are used for generating the texton image. Figure 2 illustrates the texton shapes where the image is splitted into overlapping
The centre of each pixel and surrounding neighbors are gathered on the texton picture, after computing the texton image, it performed the XOR operation between the centre texton and neighbor. Equation (7) also determines the local texton XOR patterns.
where
where
Further, the specified image of texton is transformed to maps of LTxXORP within 0 to
Figure 3 represents the LTxXORP for an image. The extracted LTxXORP features are specified as
Examination of LTxXORP image.
(ii) Spider Local Picture Feature (SLIF): In the SLIF [34] description model, the feature vectors are calculated by a unique orb web sampling pattern stimulated in the simplify orb web scheme. Moreover, SLIF is defined in Eq. (10).
where
Additionally, the total set of retrieved features is described as
The classification technique was carried out using an optimized hybrid classifier (HC) like LSTM as well as Bi-GRU once the overall feature
Optimized Long Short Term Memory (LSTM)
A gate control unit and linear association are both used by the LSTM network to effectively address gradient desertion issues. Then, the LSTM model in the time-series data detects the considerable reliance.
The development of LSTM [35] comprises the persisting LSTM cells sequences. Moreover, the forget gate, output gate, and input gate are symbolized in 3 units of LSTM cells. Further, these characteristic allows the memory cells of LSTM to suggest and accumulate data for an extended time. Assume
Long short term memory model (LSTM).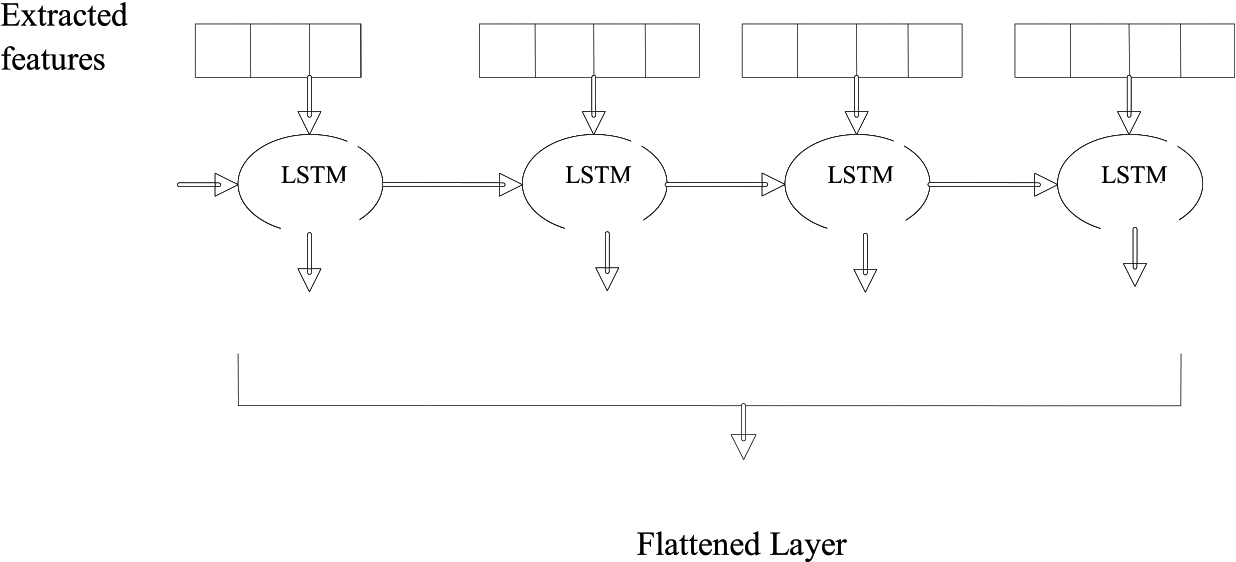
The LSTM cell used
where
Furthermore, in Eqs (12) and (13), the LSTM receives hidden layer (output) from output gate.
where the weight and bias variables for
During lengthy sequence training, LSTM eliminates gradient disappearance and gradient explosion. As a result, it performs better during training of lengthier sequences. The long-term memory of the LSTM model is preserved by Bi-GRU, a condensed form of LSTM. The update gate and reset are used in place of the LSTM cell’s input gate, forgetting gate, output gate, and reset in Bi-GRU. The update gate performs similar operations to the input and forgotten gates of the LSTM. It decides what data should be removed and what new data should be added. Another gate that makes the decision to forget knowledge from the past is the reset gate. Bi-GRU performs better when dealing with lengthy digital sequences than LSTM since it uses less tensor operations.
To organize the sequential information, constructing a system is most advantageous. RNNs specialize at encoding sequence information. It utilized a Bi-GRU to extract DDI and afterwards attached the results to the GCN [36]. Further, the Bi-GRU [37] is separated into 2 components of information transfers for computation: reverse sequence and forward sequence. In addition, the forward GRU for the given sentence is determined:
Bi-directional Gated Recurrent Unit (Bi-GRU) model.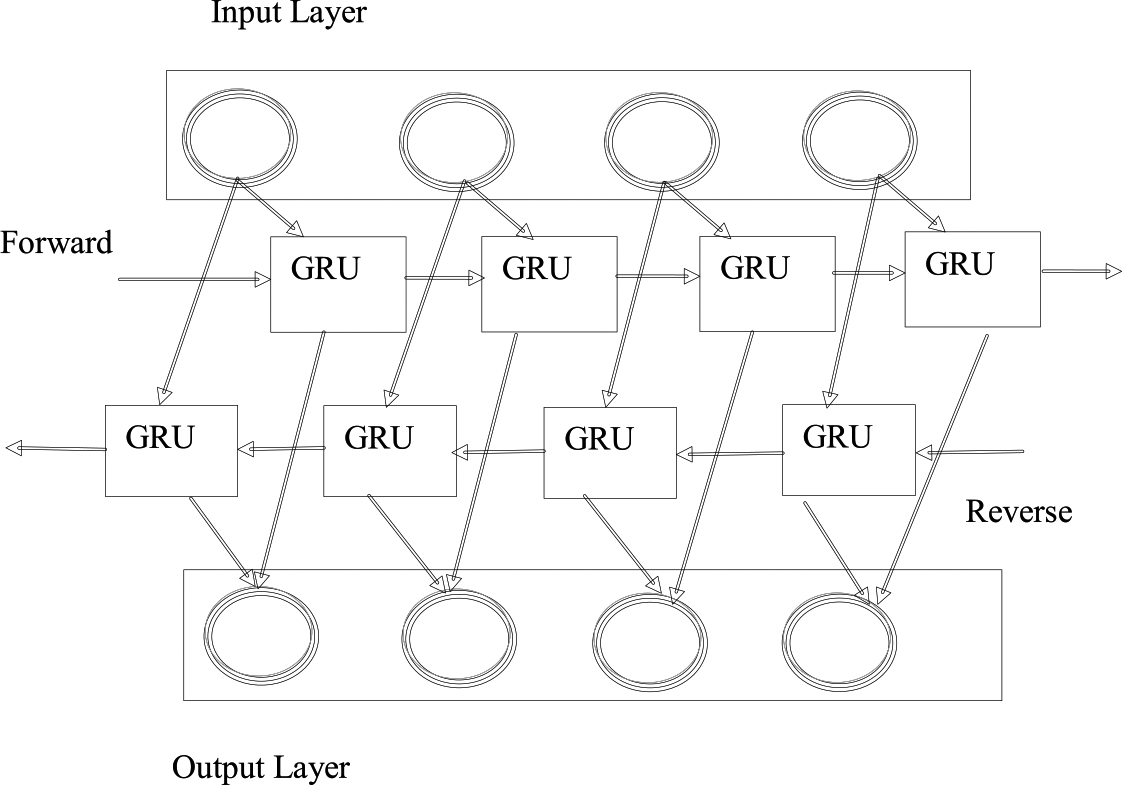
The forward GRU is determined:
The weight matrix and bias vector are determined as
The overall results of the classification examination are shown as OT as per Eq. (21).
Despite their effectiveness and resilience, CNN-based techniques are only suitable for fixed and short sequence classification problems; they does’nt advised for use with long-term challenges involving complex time series data. The ability to retain knowledge for a long time is called long short-term memory (LSTM). In addition to learning how to categorize sequences, an LSTM network also learns what information in a sequence would most effectively promote classification. We hypothesize that this is crucial for robust processing. While some (such as conditional random fields) can suffer from excessive computational cost, others (such as those that capture relationships between inputs that are not local in time) can struggle to do so. The ability of LSTM to tractably extract and correlate temporally scattered information makes it an increasingly potent alternative to such approaches. The Bi-GRU consists of both the forward and backward components. The Bi- GRU model beat some old deep learning models utilized for the human activity recognition task because it is both temporally and spatially deep. Multi-input architecture’s capacity to collect both deep and shallow characteristics aids in more accurate activity prediction.
Objective function and solution encodings
As previously mentioned, the IACBD technique is utilised to modify the weights of the LSTM and the Bi-GRU. Figure 6 contains the input solution for the IACBD model. In this case, the LSTM’s final weights are
Solution encoding.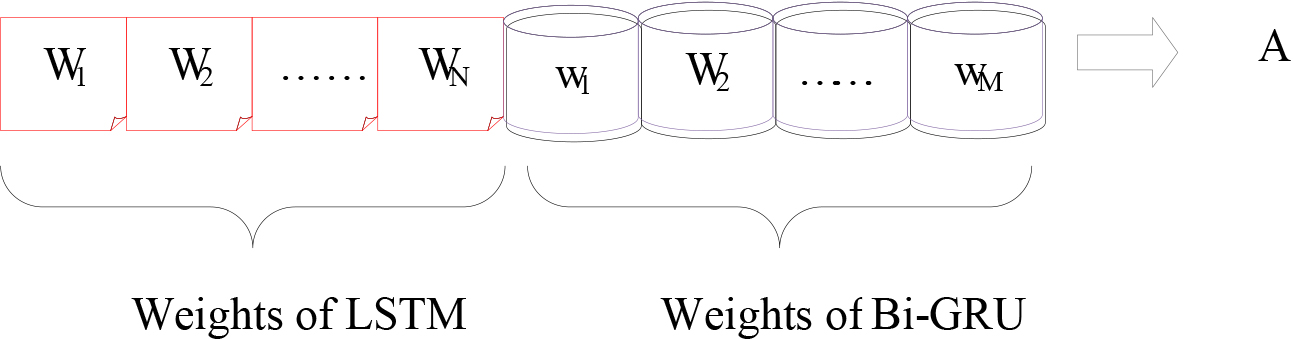
Aquila Optimizer (AO) [38] has strong global exploration capabilities, but its local exploitation phase lacks sufficient stability. The IACBD scheme is suggested for addressing these limitations. The quality and accuracy of the discovered optimal solution are then improved during the exploitation phase by doing additional local searches. The various algorithms suffer from slow convergence speed, the tendency to fall into the local optima, and premature convergence The ICABD model keeps exploration and exploitation in the right proportions and provides higher quality solution for proposed one. Normally, previous optimization approaches have provided that self-development is feasible [39, 40, 41, 32, 42]. The activities of Aquilas throughout the capture procedure of prey is the nature inspired Aquila Optimizer.
Solutions initialization
One of the population-based schemes is the Aquila optimization, and its rule started along the population
where
where
The developed Aquila Optimizer scheme displays the measures obtained during each hunt step and it simulated the behaviour of Aquila’s in hunt. If
The goal of modelling the behaviour of Aquilas as a numerical optimization approach is to find the optimal solution given a variety of constraints. The mathematical equation for this Aquila Optimizer is known.
Phase 1: Expanded exploration
During 1
where
where
where Dim represents the issue’s dimension size and
Phase 2: Narrowed exploration
The Aquila organises the land, circles in desired prey, and strikes in 2
The upcoming iteration of the
where
where
where
where
Phase 3: Extended exploitation
The 3
where
Phase 4: Narrowed exploitation
In 4
where QF represents a quality function approached by Eq. (38) for equalizing the search schemes and
where
The suggested IACBD model pseudo-code is illustrated in Algorithm 1.
Simulation procedure
The proposed human activity recognition with HC+ IACBD approach was implemented in Python and their outcomes was verified. Further, examination was performed using 2 datasets that were downloaded from UCF-ARG [43].
Dataset Description: “UCF-ARG (University of Central Florida-Aerial camera, Rooftop camera and Ground camera) Data set is a Multi view Human Action dataset. UCF-ARG includes 10 actions performed through 12 actors recorded from a ground camera, a rooftop camera at a height of 100 feet, and an aerial camera mounted onto the payload platform of a 13’ Kingfisher Aerostat helium balloon. Except for Open-Close Trunk, all the other actions are performed 4 times by each actor in different directions. Open-Close Trunk is performed only 3 times, i.e. on 3 cars parked in different directions. The actions are captured using a high-definition camcorder 1920 X 1080 at 60fps (frames per second)”.
The sample images are illustrated in Fig. 7. The developed HC+IACBD model over the existing approaches including HC+SOA [44], HC+AO [38], HC+CHIO [29], HC+PRO [45], and HC+BES [46], respectively based on certain measures for different learning percentages like 50, 60, 70, and 80, correspondingly.
Sample images.
continued.
Analysis of the developed method’s performance in comparison to extant schemes.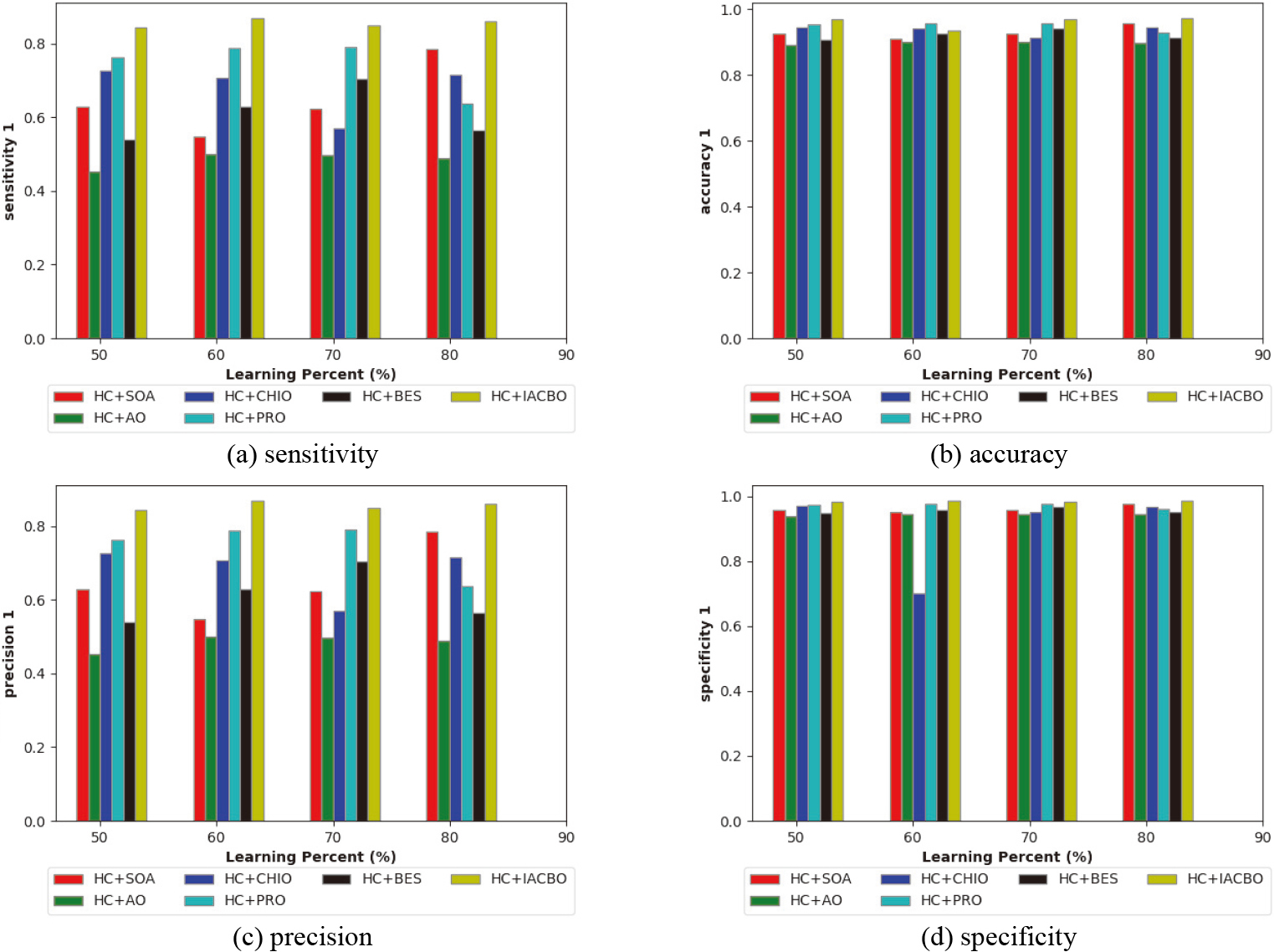
The given HC+IACBD scheme’s performance analysis is compared to conventional methods for particular metrics, as seen in Figs 8–10. Moreover, the presented HC+IACBD approach at learning percentage 50 is 5.20%, 8.33%, 3.12%, 1.04%, and 7.29% superior accuracy than the existing schemes like HC+SOA, HC+AO, HC+CHIO, HC+PRO, and HC+BES, correspondingly in Fig. 8(b). As a result, it demonstrates that accepted HC+IACBD work has more accuracy than existing techniques. Further, the developed HC+IACBD scheme attains higher sensitivity (
The given HC+IACBD model to various standard methods based on negative metrics like FPR and FNR is given in Fig. 9. The suggested HC+IACBD work’s minimum FNR (0.15) value shows it is less susceptible to errors, leading in exact prediction results for learning percentage 80 (Fig. 9(a)). While comparing to various standard methods like HC+SOA, HC+AO, HC+CHIO, HC+PRO, and HC+BES, the FPR of the given HC+IACBD system is 0.018 at learning percentage 50, which would be the lowest value. The difference in performance is shown by the variation in learning percentage. This has demonstrated that the implemented optimization method ensures that the model with optimal weights assures the least amount of inaccuracy.
Analysis of the developed method’s performance in comparison to extant schemes.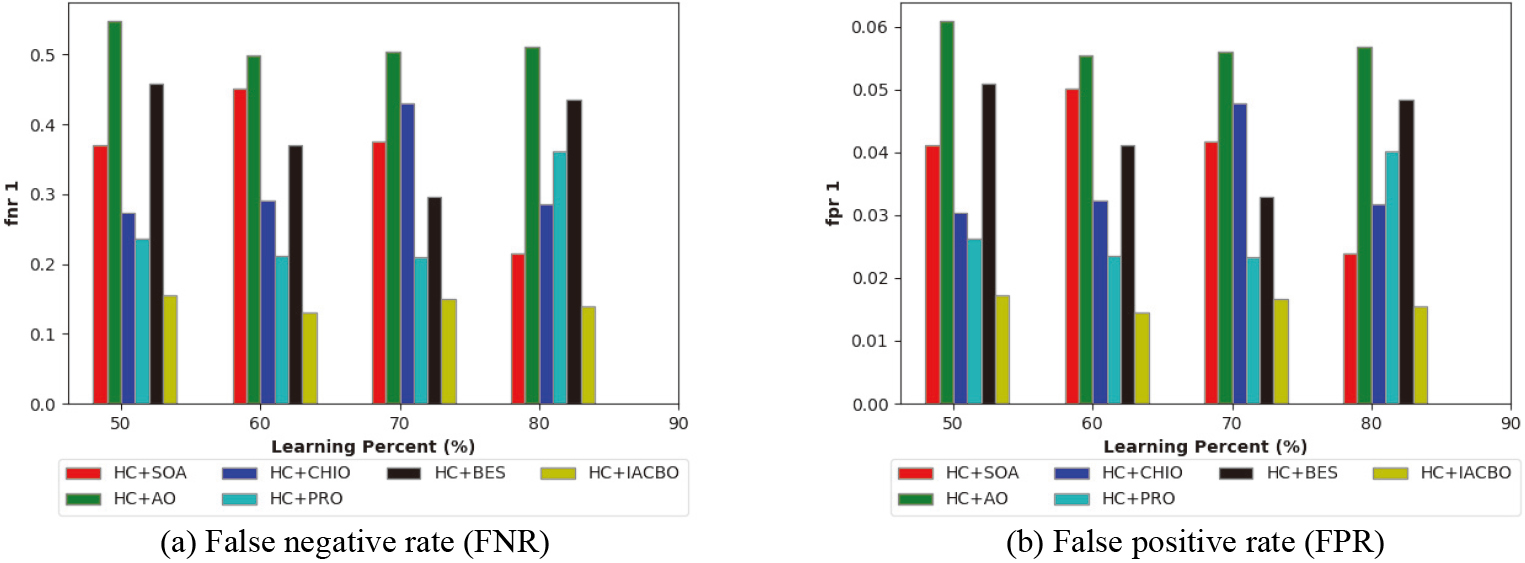
Analysis of the developed method’s performance in comparison to extant schemes.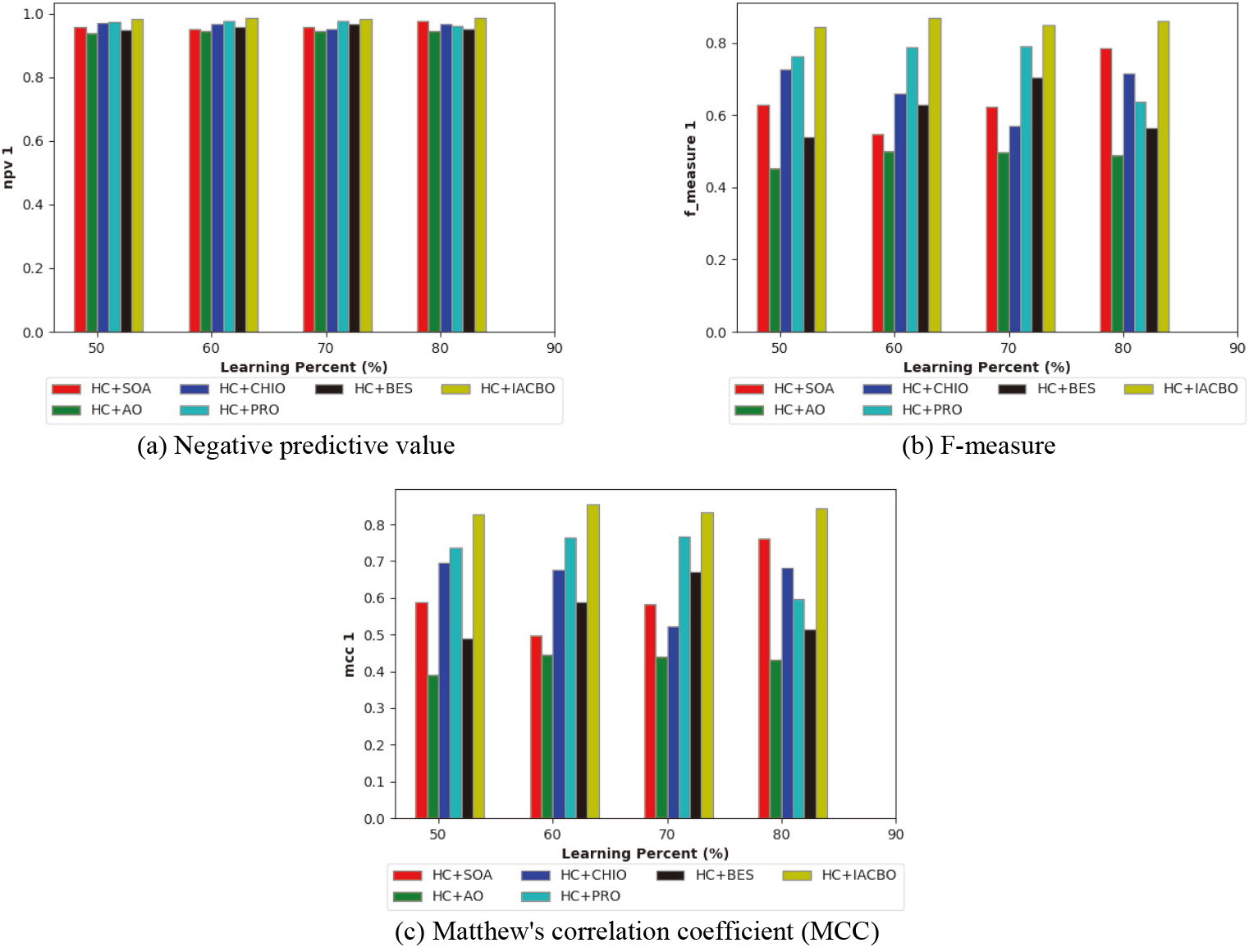
Figure 10 represents the accepted HC+IACBD approach to other traditional models in regards of extra values having NPV, Matthews correlation coefficient (MCC), and F-measure. The F-measure of the selected HC+IACBD scheme in Fig. 10(b) outperformed other conventional systems including HC+SOA, HC+AO, HC+CHIO, HC+PRO, and HC+BES for learning percentage 80. The accepted HC+IACBD system has a better NPV (0.98) at learning percentage 70, but the evaluated previous systems have lower values as shown in Fig. 10(a). The implemented HC+IACBD method obtains the maximum MCC with a learning percentage of 80 as opposed to the learning percentage 60 in Fig. 10(c). Therefore, the performance of the provided HC+IACBD model outperformed than other existing schemes.
Table 3 represents the overall performance assessment of recommended HC+IACBD system in terms of the different measures. The selected HC+IACBD method has demonstrated its recognition ability to extant models including LSTM, RNN, DBN, SVM, Linear SVM, Classic CNNs, Ensemble classifiers (paper 1) as seen in the table. Additionally, as compared to previous systems, the suggested HC+IACBD system achieves the highest accuracy values (0.933). Similarly, the suggested HC+IACBD system outperformed standard algorithms such as LSTM, RNN, DBN, SVM, Linear SVM, Classic CNNs, Ensemble classifiers (paper 1) in terms of MCC. Table 3 presents that the selected HC+IACBD system has a reduced FPR value with superior performance to conventional approaches such as LSTM, RNN, DBN, SVM, Linear SVM, Classic CNNs, Ensemble classifiers (paper 1). The outcomes show that the HC+IACBD scheme is higher than traditional schemes for human activity recognition model. This proves that the proposed method was less prone to misclassification of actions.
Overall performance analysis of recommended and previous techniques
Overall performance analysis of recommended and previous techniques
Table 4 shows the statistical analysis of the provided HC+IACBD system in comparison to the previous system on the basis of error measure. Naturally, meta-heuristic methods are stochastic; thereby to determine the exact results, the algorithms are allowed to run for numerous times to examine the achievement of defined objective. The selected HC+IACBD strategy has better mean outcomes to other previous models like HC+SOA, HC+AO, HC+CHIO, HC+PRO, and HC+BES. The best-case scenario demonstrates that suggested approach is better value (
Statistical analysis based on error measures: developed vs previous models
Statistical analysis based on error measures: developed vs previous models
The analysis of developed approach based on features and optimization is determined in Table 5. Furthermore, the adopted HC+IACBD model hold better MCC than the adopted model with no Optimization and adopted technique with extant BoW. Further, the accuracy of adopted HC+IACBD model has shown (
Analysis of proposed work based on features and optimization
Analysis of proposed work based on features and optimization
The convergence of the chosen IACBD framework and the conventional approaches is assessed by changing the iteration count from 0, 5, 10, 15, 20, and 25 Convergence analysis of the provided technique to standard approaches is shown in Fig. 11. Recommended IACBD approach holds the least cost function. The IACBD technique has reduced cost function since the iterations count maximizes. The cost function of the developed PRDO system fell between the 16
Convergence analysis of provided approach to previous methods.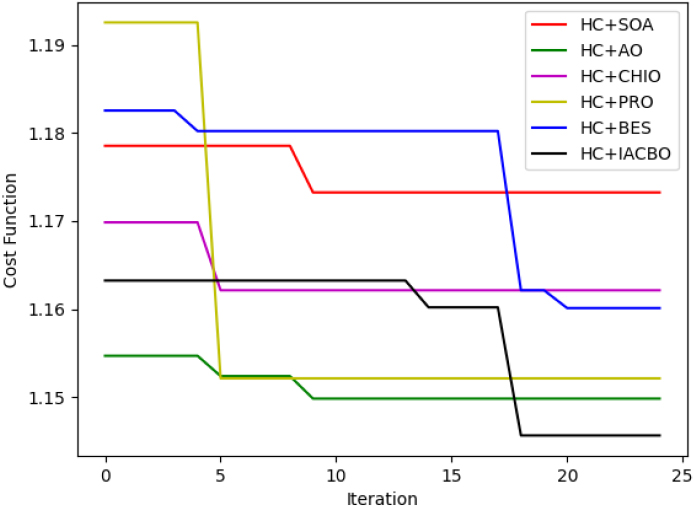
The ROC curve is shown in Fig. 12. The diagnostic capability of a binary classifier system is represented graphically by a receiver operating characteristic curve, or ROC curve, which changes as the discrimination threshold is altered. The proposed solution has a significant advantage over other traditional methods.
Analysis interms of Region of Curve.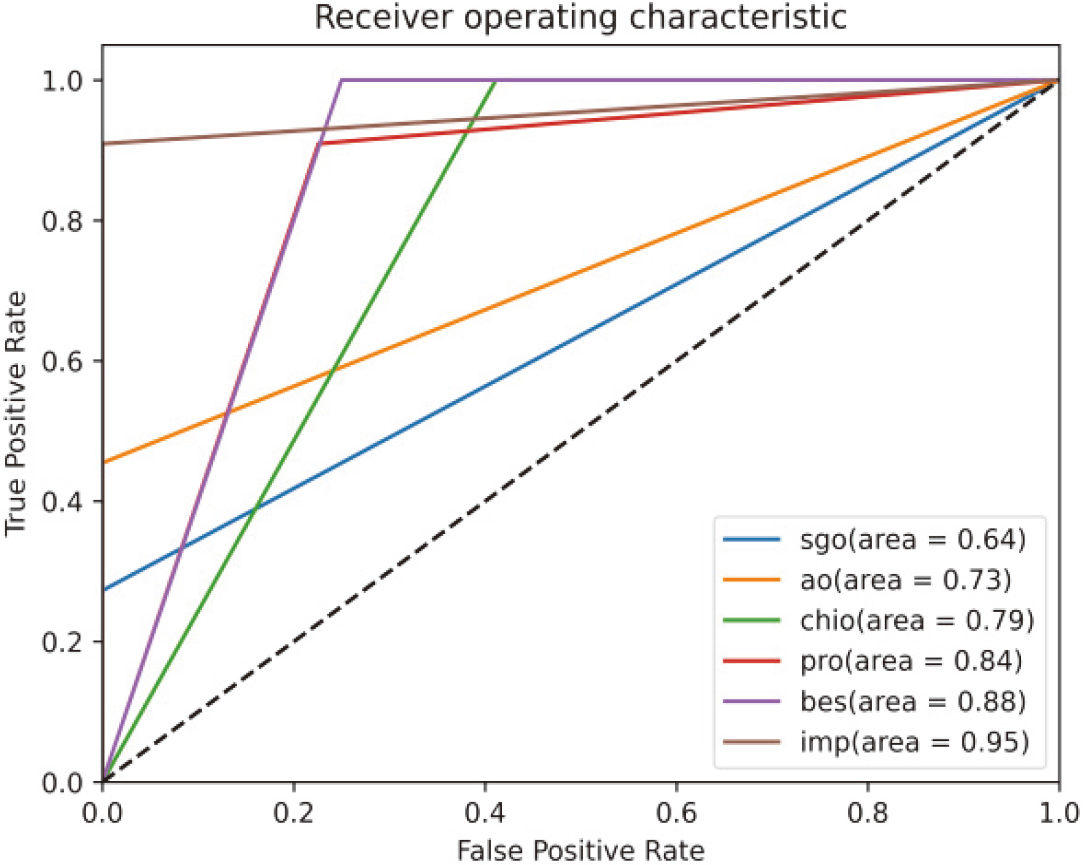
The term “Area under the ROC Curve” (AUC) refers to the level or assessment of separability. It demonstrates how well the model can distinguish between classes. The greater the AUC, the better the approach does in distinguishing between the positive and negative classifications. Analysis of the AUC are blinked in Table 6.
Area under curve analysis
Area under curve analysis
This article has described the human activity recognition system, which includes 3 stages: preprocessing, feature extraction, and classification. Moreover, the input human action images were provided to the preprocessing stage. Here, the median filtering and background subtraction was processed during pre-processing phase. From the preprocessed image, an Improved Bag of Visual Words, local texton XOR pattern, and SLIF were extracted during the feature extraction step. Further, the extracted features were provided to the classification stage. Here, the classification was done via hybrid classifier (HC) including Bi-GRU and LSTM. Next, the LSTM and Bi-GRU outputs were averaged to provide an effective output. The weight of both the LSTM and Bi-GRU was optimally tuned by IACBD approach to make the recognition more accurate and precise. Lastly, the actual outcome was highly exact. Subsequently, the results of developed method were compared to existing approach based on more metrics. Moreover, the presented HC+IACBD scheme for learning percentage 50 was 5.20%, 8.33%, 3.12%, 1.04%, and 7.29% superior accuracy than the existing schemes like HC+SOA, HC+AO, HC+CHIO, HC+PRO, and HC+BES. The accepted HC+IACBD system has a better NPV (0.98), but the evaluated prfevious systems have lower values at learning percentage 70. The best-case scenario demonstrates that suggested approach was better value (
Footnotes
Declaration of statement
To the best of the authors’ knowledge, the paper entitled “Hybrid Classifier Model with Tuned Weights for Human Activity Recognition” is not considered for publication elsewhere and has not been published anywhere.
Author’s Bios
Degree in 1995 from Lucknow University, India and Ph.D. degree in Computer Science in 2005 from Babasaheb Bhimrao Ambedkar University, Lucknow, India. He has 25 years of teaching experience and 18 years of research experience in the field of Computer Graphics, Cryptography, Software Engineering, and Data Mining. He has published more than 48 International and National publications. Seven students have been awarded a Ph.D. degree in Computer Science under his guidance. He is a member of the editorial board of a reputed Journal. He is a member of the Computer Society of India, the Indian Science Congress, and the International Association of Engineers (IAENG).