
Abstract
In recent times, recommendation systems provide suggestions for users by means of songs, products, movies, books, etc. based on a database. Usually, the movie recommendation system predicts the movies liked by the user based on attributes present in the database. The movie recommendation system is one of the widespread, useful and efficient applications for individuals in watching movies with minimal decision time. Several attempts are made by the researchers in resolving these problems like purchasing books, watching movies, etc. through developing a recommendation system. The majority of recommendation systems fail in addressing data sparsity, cold start issues, and malicious attacks. To overcome the above-stated problems, a new movie recommendation system is developed in this manuscript. Initially, the input data is acquired from Movielens 1M, Movielens 100K, Yahoo Y-10-10, and Yahoo Y-20-20 databases. Next, the data are rescaled using a min-max normalization technique that helps in handling the outlier efficiently. At last, the denoised data are fed to the improved DenseNet model for a relevant movie recommendation, where the developed model includes a weighting factor and class-balanced loss function for better handling of overfitting risk. Then, the experimental result indicates that the improved DenseNet model almost reduced by 5 to 10% of error values, and improved by around 2% of f-measure, precision, and recall values related to the conventional models on the Movielens 1M, Movielens 100K, Yahoo Y-10-10, and Yahoo Y-20-20 databases.
Keywords
Introduction
Recently, the recommendation system has become one of the emerging research topics, which learns an individual’s preferences for developing effective recommendations [1]. The recommendation systems are implemented in several applications such as electronic-product recommendations, movie recommendations, song recommendations, book recommendations, etc. [2, 3, 4]. The purpose of the recommendation systems is to automatically recommend news, web pages, movies, e-commerce products, songs, etc. for individuals based on their historical preferences [5]. In recent times, the movie recommendation gained more attention among the researcher’s communities, due to the extensive growth of online multimedia platforms [6]. The movie recommendation system helps users to access their preferred movies from large movie libraries. In recent decades, recommendation systems are categorized into 4 types hybrid systems, knowledge-based systems, content-based systems, and collaborative filtering systems [7, 8]. Compared to other recommendation systems, collaborative filtering systems are effective in predicting the users’ ratings based on the same users’ preferences [9, 10]. Most of the prior collaborative filtering systems first find the same users, and further, predicts the movie ratings based on users’ preferences and their prior ratings [11, 12, 13].
The prior collaborating filtering systems are affected by cold-start, data sparsity, and scalability issues [14, 15]. The accuracy of recommendation is reduced, when the users-items interaction matrices become sparse and it creates sparsity and scalability concerns. To highlight the above-stated issues, a novel movie recommendation system is introduced in this manuscript. After acquiring the input data from the Movielens 1M, Movielens 100K, Yahoo Y-10-10, and Yahoo Y-20-20 databases, the Min-Max normalization technique is utilized for rescaling the collected data. The rescaled data have limited outliers and redundant data which helps in improving the accuracy of movie recommendations. Lastly, the rescaled data are fed to the improved DenseNet model for relevant movie recommendations. In the experimental segment, the proposed improved DenseNet models efficiency is analyzed in light of Root Mean Square Error (RMSE), Mean Absolute Error (MAE), f-measure, MSE, precision, and recall values on Movielens 1M, Movielens 100K, Yahoo Y-10-10 and Yahoo Y-20-20 databases. Simulation results confirmed that the improved DenseNet model has shown a 5% to 10% enhancement in error values, and a 2% improvement in the f-measure, precision, and recall values related to the existing models.
The organization of this manuscript is specified as follows: recent papers related to the movie recommendations are given in Section 2. In addition, Section 3 describes the improved DenseNet model with pseudocode, and its results are denoted in Section 4. The conclusion of the present study is represented in Section 5.
Literature review
In this section, a few articles related to movie recommendation are efficiently surveyed. Jain et al. [16] implemented an enhanced multi-stage user based Collaborative Filtering (CFs) technique for effective movie recommendation. In this literature study, the developed technique’s performance was validated on two online databases movielens 100K and movielens 1M. The developed technique attained superior recommendation results compared to the existing competing techniques. Generally, the CF technique has a cold start issue in the recommendation systems. In addition, Zou et al. [17] presented a two-stage recommendation system based on multi-objective teaching learning optimizer and improved CF technique. The experiments conducted on the movielens databases show the effectiveness of the developed system in the personalized recommendation system. The presented system obtains a set of recommendation lists for one target user where it spends more running time for all target users.
Singh et al. [18] utilized the Apriori algorithm for creating user profiles by utilizing the categorical attributes and item ratings, and the created user’s profiles comprise the details of categorical properties of the objects. The effectiveness of the developed recommendation system was evaluated on the movielens databases. The comparative results show that the developed system outperformed the traditional CF techniques on the movielens databases in terms of prediction accuracy. The low expandability and the data sparsity were the major problems faced in this literature study. On the other hand, Singh et al. [19] combined K-Nearest Neighbor (KNN) and cosine similarity functions for effective movie recommendation. However, traditional machine learning techniques such as KNN suffer from a cold start problem.
Li et al. [20] implemented a hybrid recommendation system by integrating both users’ interests and movie features for calculating the similarity between users. In this literature study, the user’s rating matrix and the movie’s feature were integrated for generating the user’s interest vectors. Next, the user’s rating matrix and interest vectors were integrated for generating the hybrid user’s interest vectors to calculate the similarity among users. The experimental result confirmed that the presented recommendation system attained higher recommendation results related to the existing systems, and it relieves the issues created due to data sparsity and by changing the user’s interest.
Vilakone et al. [21] used an improved k-clique algorithm for effective movie recommendation. The presented improved k-clique algorithm’s effectiveness was evaluated on the Movielens databases, where the developed algorithm attained maximum performance compared to the existing CF techniques, k-clique algorithm, KNN etc. Whereas, the improved k-clique algorithm suffered from scalability and sparsity issues. Further, Widiyaningtyas et al. [22] developed a similarity technique: user profile correlation-based similarity for relevant movie recommendations. The extensive experimental evaluations showed that the developed similarity technique outperformed the existing techniques in light of MAE, RMSE, and recommendation accuracy, but it has a system scalability issue that needs to be addressed as a future extension.
Kharita et al. [23] implemented a new item based CF for movie recommendation in real time. As denoted earlier, in the recommendation systems, the CF technique has a cold-start issue. On the other hand, Ali et al. [24] created a hybrid movie recommendation framework based on a content based filtering technique and genomic movie tags. In this literature study, the Pearson correlation method and principal component analysis were utilized for reducing the redundant tags which show low variance proportion. The removal of redundant movie tags helps in decreasing computational complexity. The experimental results prove that the hybrid movie recommendation system identifies similar types of movies compared to the existing systems but it suffers from inherent problems: data sparsity, poor scalability, and cold start.
Lin and Chi [25] combined the CF technique and neural network for developing an effective movie recommendation system. Zhang and Mao [26] introduced a model named Markovian factorization for relevant movie recommendations. The experiments conducted on the Movielens databases confirmed that the presented model achieved better recommendation performance than the standard factorization models. Hence, the textual information related to the rating leads to early-voter and cold-start problems. Vilakone et al. [27] implemented an effective personalized movie recommendation system based on k-clique algorithm, which attained better recommendation results on the movielens databases. As specified earlier, the k-clique algorithm suffered from scalability and sparsity concerns.
Kumar and Prabhu [28] integrated fuzzy C means clustering algorithm and fire-fly optimizer for relevant movie recommendations as per user’s request. In this study, the fire-fly optimizer selects and initializes the cluster’s position and then, the fuzzy C means classifies the similarity of the users’ rating. The evaluation measures such as recall, precision, and MAE confirmed the effectiveness of the developed model on the movielens databases. In addition, the presented model was more sensitive during the selection of the initial cluster center.
Vilakone et al. [29] integrated normalized discounted cumulative gain and k-clique to recommend relevant movies. This model works based on the movie rating and user’s personal information. The implemented model’s performance was compared with the prior successful models to assess its effectiveness but the implemented model was computationally expensive. Behera et al. [30] implemented a hybrid movie recommendation system based on restricted Boltzmann machine and KNN. The developed system’s effectiveness was validated on the movielens databases. As mentioned above, the machine learning techniques like KNN suffer from a cold start problem.
Zarzour et al. [31] integrated hypergraph partition technique and expectation maximization scheme with the CF technique for movie recommendation. The presented hybrid recommendation system was tested on the real-world movielens databases in terms of precision, RMSE, F1-score, accuracy, and recall. The presented model has a higher computational time and it was the main concern in this literature. Alhijawi and Kilani [32] implemented a genetic algorithm-based movie recommendation system, which works based on historical data rating and semantic information. In future work, the implemented system will be tested on larger sized imbalanced databases and more features are considered and tested apart from genre features.
Gupta and Kant [33] created a multi-criteria recommendation system based on genetic algorithms. The experiments conducted on the movielens and Yahoo databases demonstrated the effectiveness of the developed recommendation system. Whereas, the developed system’s performance was validated in light of precision, f-measure, coverage, and accuracy. The presented recommendation system does not deal with sparsity issues, and it was the main issue in this study.
In order to address the above-mentioned issues, a new deep learning based movie recommendation system is implemented in the present research manuscript.
Improved DenseNet model for movie recommendation
In recent decades, web expansion has brought huge user’s convenience, but it leads to an issue of information overload. A recommendation system is an effective tool that helps in solving the overload issue by suggesting relevant information to the users. In recent times, the recommendation system is deployed in a variety of online systems like hotels, news articles, online social networks, books, songs, movies, online videos, etc., due to the intense growth of the internet. Usually, the recommendation systems are implemented based on numerous filtering techniques like CF, Content based Filtering (CBF), Hybrid-Filtering, etc. [34, 35]. However, the filtering techniques create effective recommendations only for similar users. Therefore, a new deep learning (improved DenseNet model) based movie recommendation system is implemented in this manuscript, and the flow diagram of the proposed system is depicted in Fig. 1.
Flow diagram of the proposed system.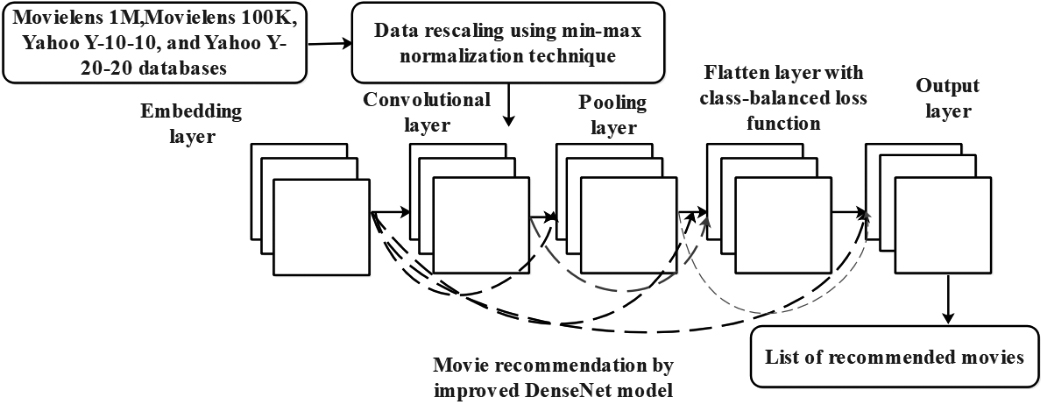
The proposed improved DenseNet model’s effectiveness is analysed on four benchmark databases as movielens 1M, movielens 100K, Yahoo Y-10-10, and Yahoo Y-20-20. The Yahoo! movies database comprises 976 movies and 6078 users, and every movie is classified based on five criteria like visuals, direction, acting, overall rating and story. The movie rating is varied from A
The movielens 1M database has 6040 users, 3900 movies and 1,000,209 ratings, and also it has demographic information such as user’s occupations (executive/managerial, craftsman, artist, customer service, 12
Data denoising
After the acquisition of Movielens 1M, Movielens 100K, Yahoo Y-10-10, and Yahoo Y-20-20 databases, the data normalization is accomplished by using Min-Max normalization technique. In this research, the Min-Max normalization technique performs an effective linear transformation on the acquired data and it rescales the data between the ranges of zero to one. This procedure helps in preserving the linear relationships among the collected data variables. The mathematical presentation of the Min-Max normalization technique is stated in Eq. (1) [36].
Where,
After rescaling the acquired data, the rating criteria (0 to 5) are calculated for every user and movie, and the overall rating criteria are computed for all users and movies. In this manuscript, the improved DenseNet is used to predict the rating of target users for a recommendation. The DenseNet is an effective deep-learning model, where every layer is directly-connected with each other for achieving better information flow. In the DenseNet model, each layer collects inputs from the previous layers, and then, transfers them as the feature maps to the subsequent layers. The feature map of the current layer is combined with prior layers by performing a concatenation process. In a network, each layer linked with all the prior layers is named as DenseNet, which needs lower parameters compared to the traditional models. Additionally, the DenseNet decreases the overfitting issue, which occurs in the training sets [37].
Initially, the denoised data are passed to the improved DenseNet model, which includes
Where,
In the DenseNet model, the convolution operation learns the data features with filtering techniques. After performing the convolution operation, a ReLU activation function is applied to the output feature maps, and it is mathematically depicted in Eq. (3). In addition to this, the pooling operation is accomplished for decreasing the output feature maps dimensionality, and it is performed either by utilizing average pooling or max-pooling operation. The average pooling operation partitions the input into different pooling areas and then estimates the mean value. Similarly, the max-pooling operation takes the largest elements from the feature maps. The global average pooling function calculates the mean of every feature map and further, the resultant feature vectors are fed to the softmax layer.
In the proposed model, the classification layer has a fully-connected softmax layer, and it sets neurons based on the attributes in the acquired databases like movielens 1M, movielens 100K, Yahoo Y-10-10 and Yahoo Y-20-20. The softmax function is used to categorize multi-class classification issues by computing the probability distributions of every class
Where,
Where, Bias
In the proposed model, an Adaptive Learning Rate Optimization Algorithm (ADAM) is utilized for updating weights based on acquired data. The ADAM optimizer identifies a learning rate for individual parameters. The ADAM optimizer utilizes first and second-order-gradient moments for adjusting the learning rate of individual weight in the DenseNet model, which is known as adaptive moment estimation. By utilizing increased moving averages, the ADAM optimizer evaluates the gradient moments, and the moving averages are computed using the present mini-batch, as mentioned in Eqs (8) and (9).
Where,
Where,
Architecture of the improved DenseNet model.
Where,
Pre-process the input data Read pre-processed data and set parameters for the neural network: improved DenseNet model Read user features and movie features from data frame Construct similarity calculation for users and construct a graph K fold split of data is done and the train Save the trained model and parameters Load the model and recommend for the cold start user according to timestamp Recommend list of the movies based on multi-criteria Return
In this research manuscript, the proposed improved DenseNet model is simulated using a python software environment on a computer with Intel core i5 processor, windows 10 (64-bit) operating system, 8 GB random access memory and NVIDIA GeForce GT 730 graphics card. The proposed improved DenseNet model’s efficacy is tested on the movielens 1M, movielens 100K, Yahoo Y-10-10, and Yahoo Y-20-20 databases in light of RMSE, MAE, f-measure, MSE, precision, and recall. The mathematical formula of the RMSE, MAE and MSE is stated in Eqs (13–(15). Where,
The mathematical formula of recall, precision, and f-measure is represented in Eqs (16)–(18). Where, TP, TN, FP and FN indicate true positives, true negatives, false positives and false negatives.
The experimental results of the improved DenseNet model on the movielens 1M and 100K databases in light of RMSE, MAE, and MSE are specified in Table 1. By investigating Table 1, the experimental outcomes are analyzed with two different cross fold validations (
Experimental results of the improved DenseNet model on the movielens 1M and 100K databases by using different evaluation metrics
Experimental results of the improved DenseNet model on the movielens 1M and 100K databases by using different evaluation metrics
Graphical comparison of the improved DenseNet model on movielens 1M database.
Similarly, the experimental results of the improved DenseNet model on the Yahoo Y-10-10 and Yahoo Y-20-20 databases in light of RMSE, MAE, and MSE are denoted in Table 2. By viewing Table 2, the improved DenseNet model achieved a minimum error rate in the
Experimental results of the improved DenseNet model on the Yahoo Y-10-10 and Yahoo Y-20-20 databases by using different evaluation metrics
Graphical comparison of the improved DenseNet model on movielens 100K database.
In this phase, the proposed improved DenseNet model’s effectiveness is compared with the existing works developed by Behera et al. [30] and Gupta and Kant [33]. Behera et al. [30] developed a hybrid movie recommendation system based on KNN and Boltzmann machine. The developed model’s performance is investigated on the movielens 1M and 100K databases by means of RMSE and MAE, and the comparative results are depicted in Table 3. In addition, Gupta and Kant [33] created a Multi-Criteria Recommendation System (MCRS) based on a genetic algorithm and its Credibility Score (CS). The developed MCRS-CS model has achieved higher recommendation results by using the evaluation metrics like f-measure, precision and recall on the Y20-20 and Y10-10 databases, and the results are depicted in Table 4. By investigating Tables 3 and 4, the improved DenseNet model achieved a minimum error rate and maximum recommendation results related to the existing models.
Comparative results by means of RMSE and MAE
Comparative results by means of RMSE and MAE
Comparative results by means of f-measure, recall, and precision
Graphical comparison of the improved DenseNet model on Yahoo Y-10-10 database.
Graphical comparison of the improved DenseNet model on Yahoo Y-20-20 database.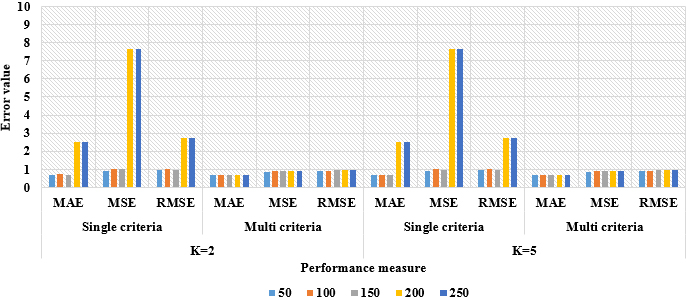
The primary aim of the movie recommendation system is to predict and filter the movies as per user request. In the present scenario, the machine learning and deep learning models are effective in the movie recommendation by handling an enormous amount of data. In this manuscript, an improved DenseNet model is proposed for movie recommendation. The improved DenseNet model has a class-balanced loss function and a weighting factor for effectively managing the overfitting risks. In addition, the improved DenseNet model superiorly understands the movie content and resolves the problems like sparsity, scalability, and cold start. These are the major benefits of employing an improved DenseNet model in movie recommendation. The performance of the improved DenseNet model is validated on the movielens 1M, movielens 100K, Yahoo Y-10-10, and Yahoo Y-20-20 databases in light of RMSE, MAE, f-measure, MSE, precision, and recall. Further, the improved DenseNet model’s effectiveness is shown in the Tables 1–4.
Conclusion and future work
In recent decades, the number of online movies is rapidly increasing, due to the growth of multimedia networks. The recommendation systems are effective in dealing with this issue and a movie recommendation system provides users with highly ranked lists of movies based on an individual’s constraint and preference. A user rating on every movie is impossible, and the same ratings on similar movies from different users become highly overlap, and it leads to data sparsity issues that limit the accuracy of the recommendation model. So, a new recommendation model is introduced in this article for relevant movie recommendations. In the initial phase, the input data is acquired from Movielens 1M, Movielens 100K, Yahoo Y-10-10, and Yahoo Y-20-20 databases. The collected high dimensional data are rescaled using Min-Max normalization technique, which decreases redundant data and provides better data representation with a limited outlier. The rescaled data are given to the improved DenseNet for a relevant movie recommendation, where it incorporates a weighting factor and class-balanced loss function for managing class imbalance issues and overfitting risk. The evaluation metrics: MAE, MSE, and RMSE demonstrated that the improved DenseNet model reduced by 5 to 10% of error values. Further, the evaluation metrics: f-measure, precision and recall showed that the proposed model improved 2% of recommendation results related to the traditional models on the Movielens 1M, Movielens 100K, Yahoo Y-10-10 and Yahoo Y-20-20 databases.
As a future extension, a novel hybrid clustering technique is developed to overcome scalability issues and computational time. Additionally, big data technology and parallel processing are considered in the large scaled databases.
Funding
This research received no external funding.
Data availability
The datasets generated during and/or analysed during the current study are available in the [Movielens 1M], [Movielens 100K] and [Yahoo Y-10-10 and Yahoo Y-20-20] repositories.
Footnotes
Conflict of interest
The authors declare that they have no conflict of interest.
Author’s Bios
Interested in the areas of Computer science & engineering particularly Cloud Computing and its applications. Has been author & coauthor for papers published in International Journals & conferences of IEEE, Springer, Elsevier.