
Abstract
Due to the proliferation of the IoT devices, indoor location-based service is bringing huge business values and potentials. The positioning accuracy is restricted by the variability and complexity of the indoor environment. Radio Frequency Identification (RFID), as a key technology of the Internet of Things, has became the main research direction in the field of indoor positioning because of its non-contact, non-line-of-sight and strong anti-interference abilities. This paper proposes the deep leaning approach for RFID based indoor localization. Since the measured Received Signal Strength Indicator (RSSI) can be influenced by many indoor environment factors, Kalman filter is applied to erase the fluctuation. Furthermore, linear interpolation is adopted to increase the density of the reference tags. In order to improve the processing ability of the fingerprint database, deep neural network is adopted together with the fingerprinting method to optimize the non-linear mapping between fingerprints and indoor coordinates. The experimental results show that the proposed method achieves high accuracy with a mean estimation error of 0.347 m.
Introduction
With the updates of new smartphones, tablets, and wearables, etc., the performance of internet of thing (IoT) devices is growing rapidly. As an important part of the IoT’s application, location awareness is playing an increasingly important role, providing individuals with better user experience through delivering location information continuously and reliably in both indoor and outdoor environments (Hui & Kan, 2019). In recent years, indoor positioning has demonstrated great potentials in intelligent warehousing, asset tracking, rescue operation and navigation for industrial robots (Kuo, Shieh, Zhang, & Chen, 2013; Ma & Wang, 2017), etc. Because of the complex indoor environment, signals suffer from reflection, degradation, multipath, and obstruction which seriously undermine the accuracy of positioning technology (Miesen, Kirsch, & Vossiek, 2013). Multipath is the phenomenon whereby a RF signal arrives at a receiver’s antenna via more than one different paths (Wang & Katabi, 2013). Therefore, the indoor localization methods robust to multipath and non-line-of-sight scenarios are badly needed.
RFID as the key element of IoT is a promising technology for indoor location sensing which utilizes the backscatter signal for object tracking. Due to its non-contact, non-line-of-sight and strong anti-interference abilities, RFID has gained considerable attention in the field of indoor positioning (Chen et al., 2015b; Ma, Wang, Wang, & Ma, 2017). RFID based positioning methods mainly rely on measuring the Time-of-Arrival (TOA), Angle-of-Arrival (AOA), Received Signal Strength Indicator (RSSI) and phase to pinpoint the location of the objects (Wang, Adib, Knepper, Katabi, & Rus, 2013; He Xu, Wu, Li, Zhu, & Wang, 2018). Compared to AOA and TOA, RSSI based localization systems have a low deployment cost without compromising the positioning accuracy. The most well-known RSSI based system is LANDMARC (Ni, Liu, Lau, & Patil, 2003), which calculates the coordinates of tracking tags at different locations by comparing their RSSI values with those of reference tags at known locations. But it has two drawbacks (Liu, Wen, Qin, & Liu, 2016). First, it is severely affected by multi-path effects. Second, more reference tags are needed to increase the localization accuracy, which may cause RF interference phenomenon.
Many approaches have been proposed to improve the accuracy of the LANDMARC system. One of the most effective methods is called VIRE (Zhao, Liu, & Ni, 2007) which introduces the concept of virtual reference tags to increase the density of the tag. Accordingly, the RF interference phenomenon can be avoided. Experimental results show that the tracking accuracy of VIRE is 17% higher than LANDMARC. Proximity map is leveraged in VIRE to eliminate the unlikely positions of the target, which is not efficient and accurate to estimate the coordinates of tracking tags.
In recent years, deep learning, an algorithm that attempts to find the correct mathematical mapping from the input to the output with multiple processing layers, whether it be a linear relationship or a non-linear relationship, has been successfully applied in the fields of speech recognition, natural language processing and computer vision (LeCun, Bengio, & Hinton, 2015). (Shen, Zhang, Pang, Xu, & Li, 2019) introduced the relative localization method of RFID Tags Based on Deep Learning, which predict the sequence of the RFID tags not their absolute locations. (Huatao Xu, Wang, Zhao, & Zhang, 2019) leverages the neural network to create an effective hologram-based position estimation method, which is computationally expensive. The weighted path length and support vector regression algorithm are used to improve the positioning precision of LANDMARC (He Xu et al., 2018). Compared to the traditional machine learning method, in this paper, we propose the deep learning approach for positioning of RFID tags, in which the deep learning algorithm is combined with VIRE to improve the efficiency and accuracy.
Data preprocessing
The RFID reader can query multiple tags simultaneously, but the measured RSSI values can be influenced by many factors such as movement of people, multipath effect, reflection of floor, etc. Therefore, the data preprocessing is indispensable. The RSSI value and the distance between a reader and a tag follow the log-distance path model (Chen et al., 2015a), which can be expressed as:
Where PL(d) is the path loss when the distance between the reader and the tag is d. The term d0 indicates the reference distance which is set as one meter. n denotes the path loss exponent. X σ is a random variable which is used to model the fluctuation of RSSI. In order to smooth the output of the RSSI value and eliminate the fluctuation, the Kalman filter is used. The Kalman filter produces an estimate of the state of the system as an average of the system’s predicted state and of the new measurement using a weighted average. This process repeats at every time step.
Suppose the RSSI state is x
k
at timestamp k. The observation of RSSI is z
k
. The state transition equation and observation function can be expressed respectively as:
Where ωk-1 ∼ N (0, Q) denotes Gaussian noise of the system. Q is the process error covariance. v denotes the Gaussian noise during measurement. R is the measurement error covariance. The Kalman filter works in a two-step process. In the prediction step, the Kalman filter estimates the current RSSI variable and the uncertainty. In the update step, the filter updates the current state using the present observed RSSI and the previously estimated variable.
The prediction step:
The update step:
Where p is the prediction error covariance, and k denotes the Kalman gain. x predicted represents the state estimation of RSSI at timestamp k.
Figure 1 shows the result after applying the Kalman filter. In the experiment, there are 60 RSSI measurements of the same reference tag. After data preprocessing, and the data fluctuation is weakened effectively and smooth output is obtained.
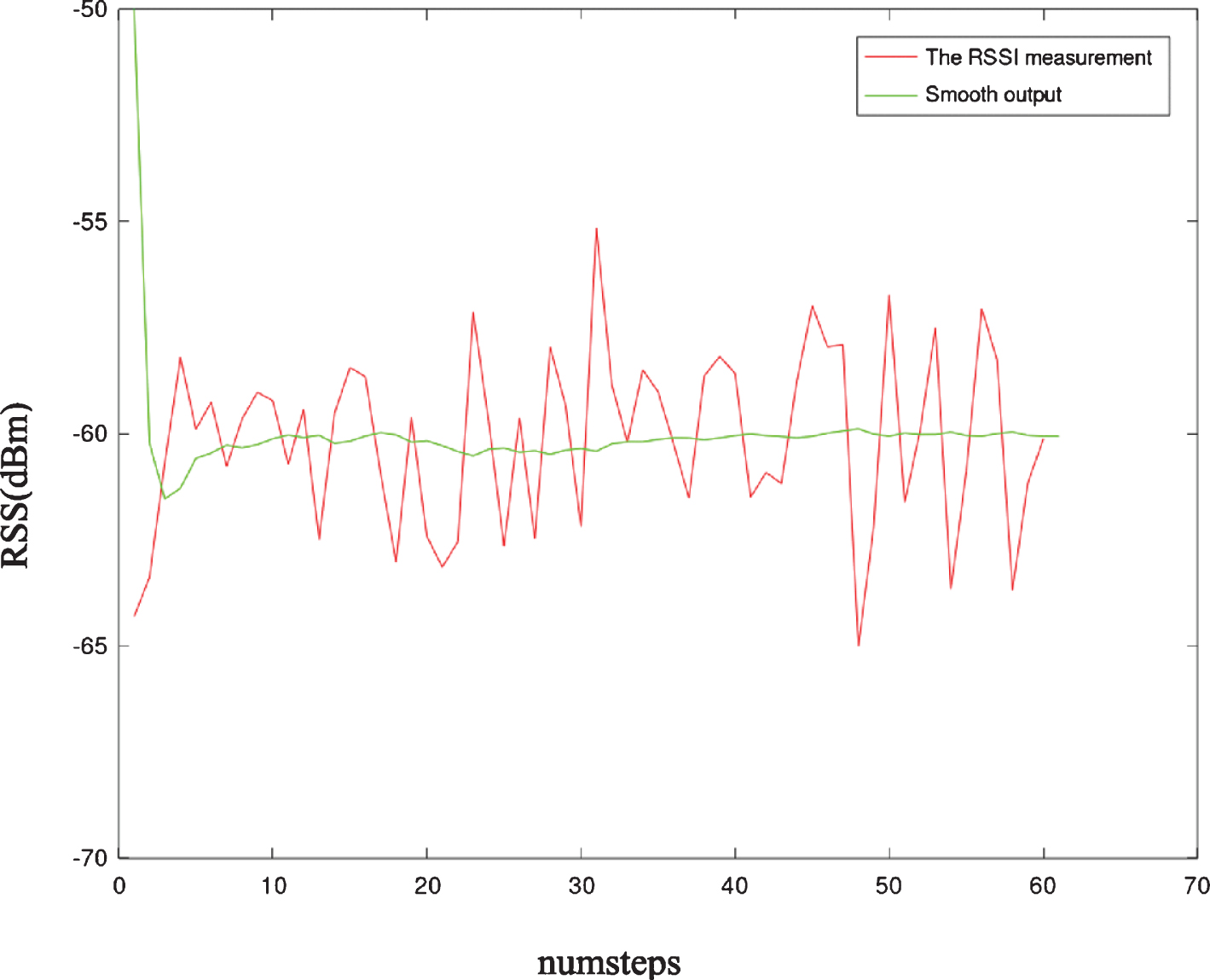
Data processing using Kalman filter.
Figure 2 illustrates the system architecture. The communication of Passive UHF RFID system relies on backscatter radio link. The RFID reader transmits electromagnetic waves to interrogate the tag. The RF signal is reflected off the tag and processed in the reader to decode the data, which contains the information of EPC code, RSSI, Phase, Timestamp, etc. After data collection and preparation, the preprocessed data is used to interpolate the RSSI values of the virtual reference tags. When the fingerprint database is established, the data is fed into the deep neural network for training the model. Finally, the test data is input to the deep learning model for indoor positioning.
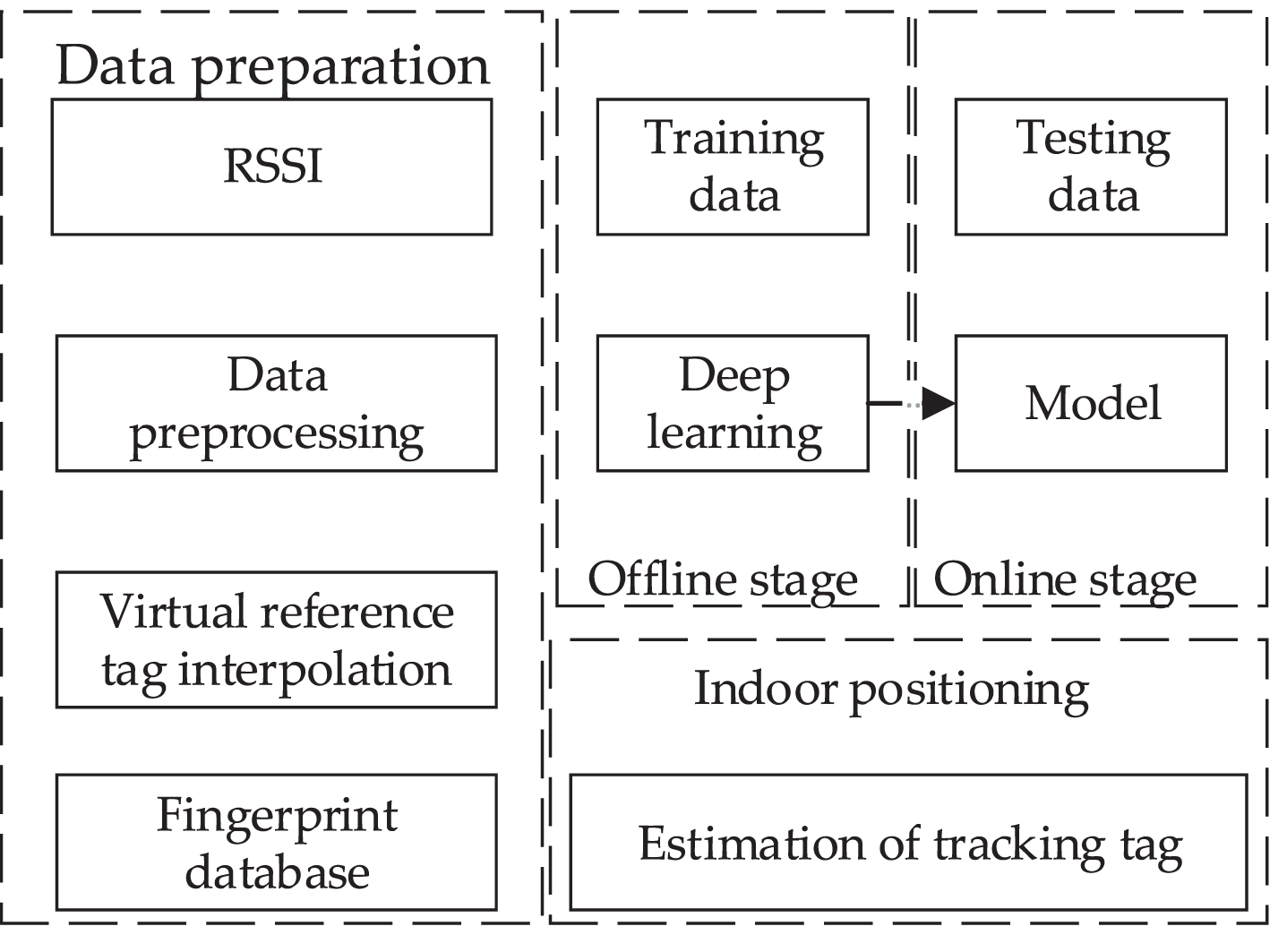
System architecture of the deep learning approach.
For the fingerprinting method, theoretically, more reference tags will improve the precision. Whereas, as mentioned before, increasing the density of the reference tags does not necessarily increase the accuracy. Instead, that will cause radio signal interference and result in worse performance. Moreover, deploying more reference tags is also costly. So we adopt the concept of virtual reference tag to improve the accuracy of the fingerprint algorithm.
The sensing area can be partitioned many grids, each of which is covered by four real reference tags. By dividing the grid equally into finer grid cells, the virtual reference tag is inserted. Because the positions of the real reference tags are already known, it is not difficult to calculate the coordinates of the virtual reference tags.
Next, the RSSI of the reference tag to the RFID reader should be determined. The linear interpolation algorithm is adopted to calculate the RSSI value of the virtual reference tag, which is fast and easy (Zhao et al., 2007). Suppose the physical grid is partitioned into n × n finer grid cells. There are n – 1 virtual reference tags are inserted between the two real tags. Totally, (n + 1) 2 - 4 reference tags will be added to each grid, as shown in Fig. 3. The RSSI values of the virtual reference tags can be calculated by the following equations.
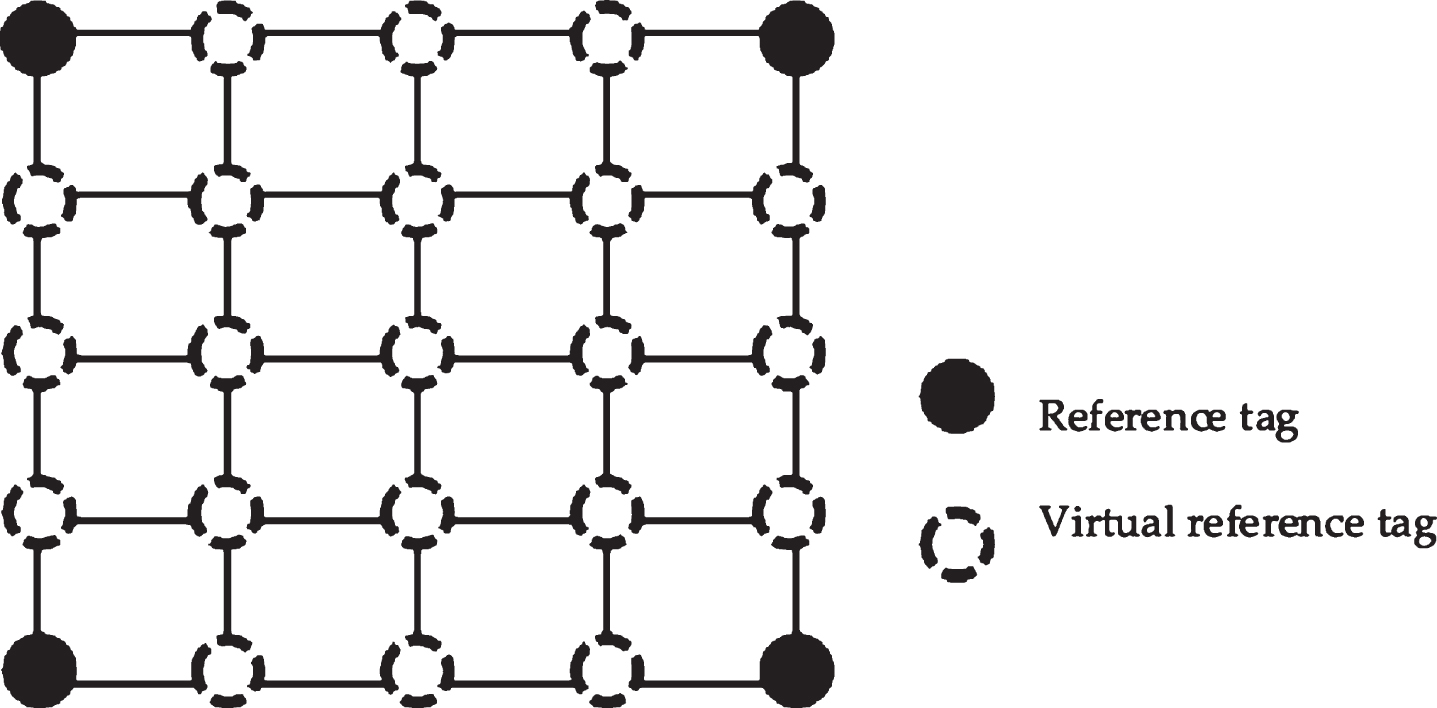
Deployment of virtual reference tags.
The RSSI values of virtual reference tags in the horizontal lines are obtained by:
The RSSI values of virtual reference tags in the vertical lines are obtained by:
Where 1 ≤ p ≤ n - 1, 1 ≤ q ≤ n - 1,
A deep-learning architecture is a stacked multiple processing layers, which compute non-linear input–output mappings. For a deep neural network with depth of 5 to 20, the deep learning algorithm can apply extremely complex functions of its inputs that are sensitive to minute details and insensitive to irrelevant noises such as the signal fluctuation and multipath effect.
The basic element of the deep neural network is called neuron (Fig. 4). The number of neurons in the input layer is determined by the dimension of the input data, while the dimension of the targets defined the number of neurons in the output layer (Han, Pei, & Kamber, 2011). Accordingly, the input dimension of the deep neural network equals to the number of RFID readers. The output dimension equals two since the x and y coordinates of the tracking tag are of interest to us.
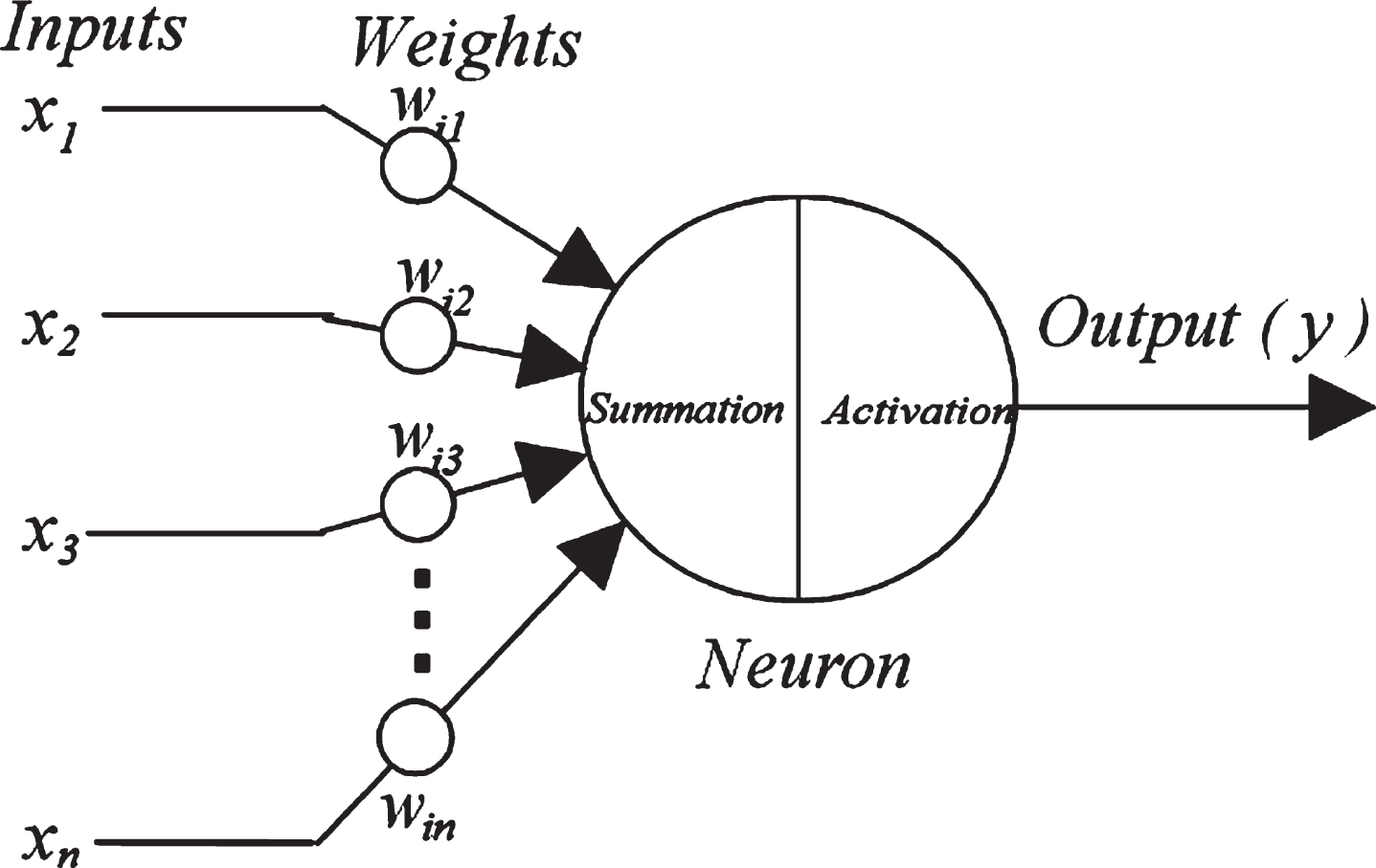
A single neuron.
The training of the multilayer neural networks consists of two passes, namely forward pass and backward pass as shown in Fig. 5. In order to monitor the progress of the deep neural network and ensure the training process is moving in correct direction, the value of the loss function should be calculated regularly. In general, the loss function is used to supervise how far away the training is from the optimal result. The selection of the loss function depends on the specific problem that needs to be solved. For indoor positioning, it is actually a regression problem. Mean Square Error (MSE) is the most commonly used regression loss function, which is defined as:

Deep neural network and backpropagation.
Where m is the number of training samples. The term t i indicates the target value. The equations used in the forward pass are described as follows:
For brevity, the bias terms have been omitted. The total input z to each neuron at each layer is computed firstly, which is calculated as the weighted sum of the outputs of the neurons in the layer below.
Where w
ij
is the weight between the neurons i and j. Then the output of the neuron is obtained by applying the activation function f (.) to z, which is a non-linear function. The activation functions commonly used in deep neural networks encompass the rectified linear unit (ReLU) f (x) = max(0, x), the most popular function in recent years, as well as the traditional functions such as Sigmoid, f (x) = 1/(1 + e-x) and TanH, f (x) = 2/(1 + e-2x) - 1.
The formulas used for calculating the backward pass are described as follows:
At the output layer, the partial derivative of the loss function with respect to the output of a neuron is calculated by subtracting the target value from the calculated output y.
At each hidden layer, the partial derivative of loss function with respect to the output of each neuron is calculated as the weighted sum of the error derivatives with respect to the total inputs to the neurons in the layer above.
Then the partial derivative of the loss function with respect to the input to the neuron at each hidden layer is computed by the error derivative with respect to the output times the gradient of f(z).
When the partial derivative of the loss function with respect to the input to the neuron ∂E/∂z is obtained, the partial derivative for the weight w connecting the neuron in the layer below and the neuron in the layer above can be calculated as:
After the gradient of the weight is calculated, gradient descent method is applied to adjust the deep neural network to minimize the loss function. The weights are updated as follows:
Where the term α denotes the learning rate. The learning rate is a hyperparameter in the deep neural network that controls how much the model should change corresponding to the calculated loss error when the model weights are updated.
The performance of the proposed deep learning approach is evaluated in this section. Experiments are carried out in two different indoor environments. Additionally, the deep learning approach is compared with two baseline methods, including LANDMARC and VIRE.
Experimental setup
The Impinj R420 RFID with four antennas is adopted in our experiments. The RFID reader operates in the 920.5Mhz –924.5MHz UHF band. The Alien Technology 2x2 RFDI tag is employed as reference tag, which is compatible with EPC Gen2 protocol. The RSSI values received by the RFID reader may differ at different environments. In order to evaluate the robustness of the proposed method, the experiments are conducted in a research lab and a typical office area in our university, as shown in Fig. 6. The antenna’s output power is set to be 30 dBm. There are 16 reference tags evenly distributed in a sensing area. The space between any two reference tags is one meter. Four reader antennas are deployed in the four corners of the sensing area.
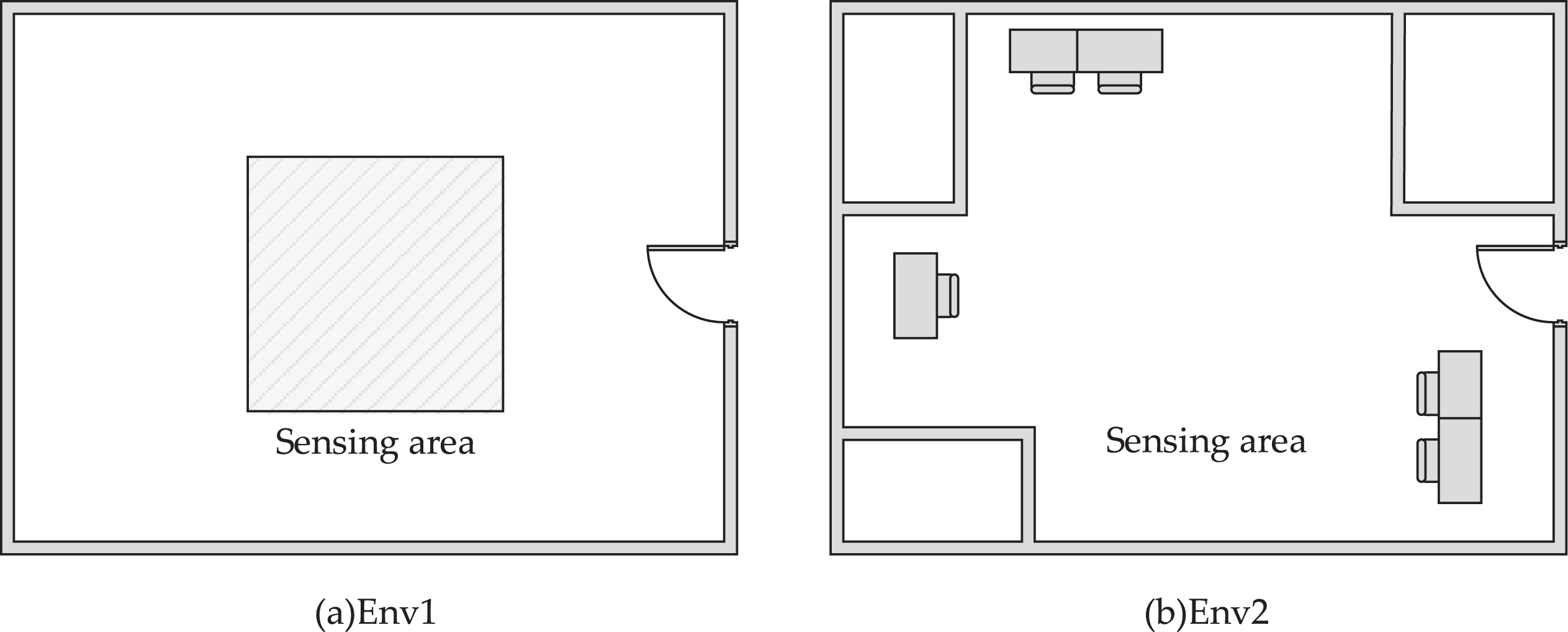
Layout of indoor environment. (a) research lab (b) office room.
The Tensorflow framework is used to build the deep neural network, which consists of four hidden layers with 25 nodes at each layer. ReLU is utilized as the activation function in the hidden layer and the activation function for the output layer is linear. Mean_absolute_error is selected as the loss function. Given the coordinate of the target tag (x
t
, y
t
), the estimation error is evaluated by the following formula:
The deep learning approach is first evaluated in the research lab which is spacious. The sensing area is not surrounded by walls. Figure 7(a) plots the estimated positions of the tracking tags, which are closely around the ground truth of the target. The mean estimation error of the proposed method is 0.347 m. Compared to the Env1, the calculated positions of the tracking tags in Env2 spread over a wider area as shown in Fig. 7(b). The average estimation error increases to 0.549m. Since the sensing area in Envionment2 is surrounded by desks and walls, the severe multipath effect will exert unexpected influence to the measured RSSI value, which can cause estimation error. Even though, the proposed method could achieve a reasonable accuracy.
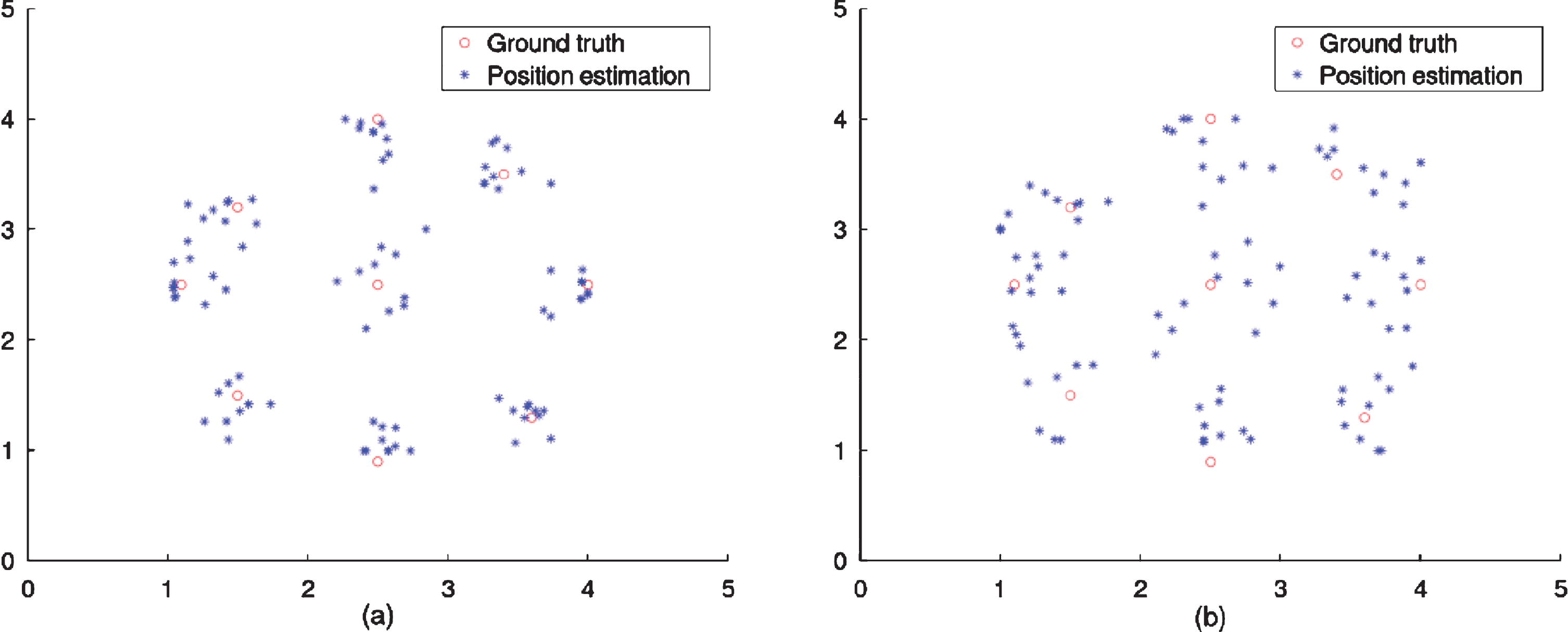
Position estimation of the deep learning approach (a) research lab (b) office room.
The deep learning approach is compared to the baseline methods in the two environments. Figure 8(a) shows the comparison of the three methods in Env1. Due to the introduction of the virtual reference tags, VIRE performs better than LANDMARC. The estimation error for VIRE reduces from 6% to 59% over LANDMARC for the tracking tags in Env1. The deep learning approach surpasses VIRE from 3% to 54% for all tracking tags. The worst estimation error for the deep leaning approach is 0.443 m and the mean estimation error is 0.347 m. Figure 8(b) illustrates the comparison of the three methods in Env2. The worst estimation error for LANDMARC is 1.27 m and the average error is 0.89 m. VIRE reduces the mean positioning error to 0.74 m and the least estimation error is 0.588 m. The localization error for the deep learning approach reduces from 6% to 46% over VIRE for the tracking tags in Env2. It is clear that the proposed method outperforms VIRE and LANDMARC over all locations.
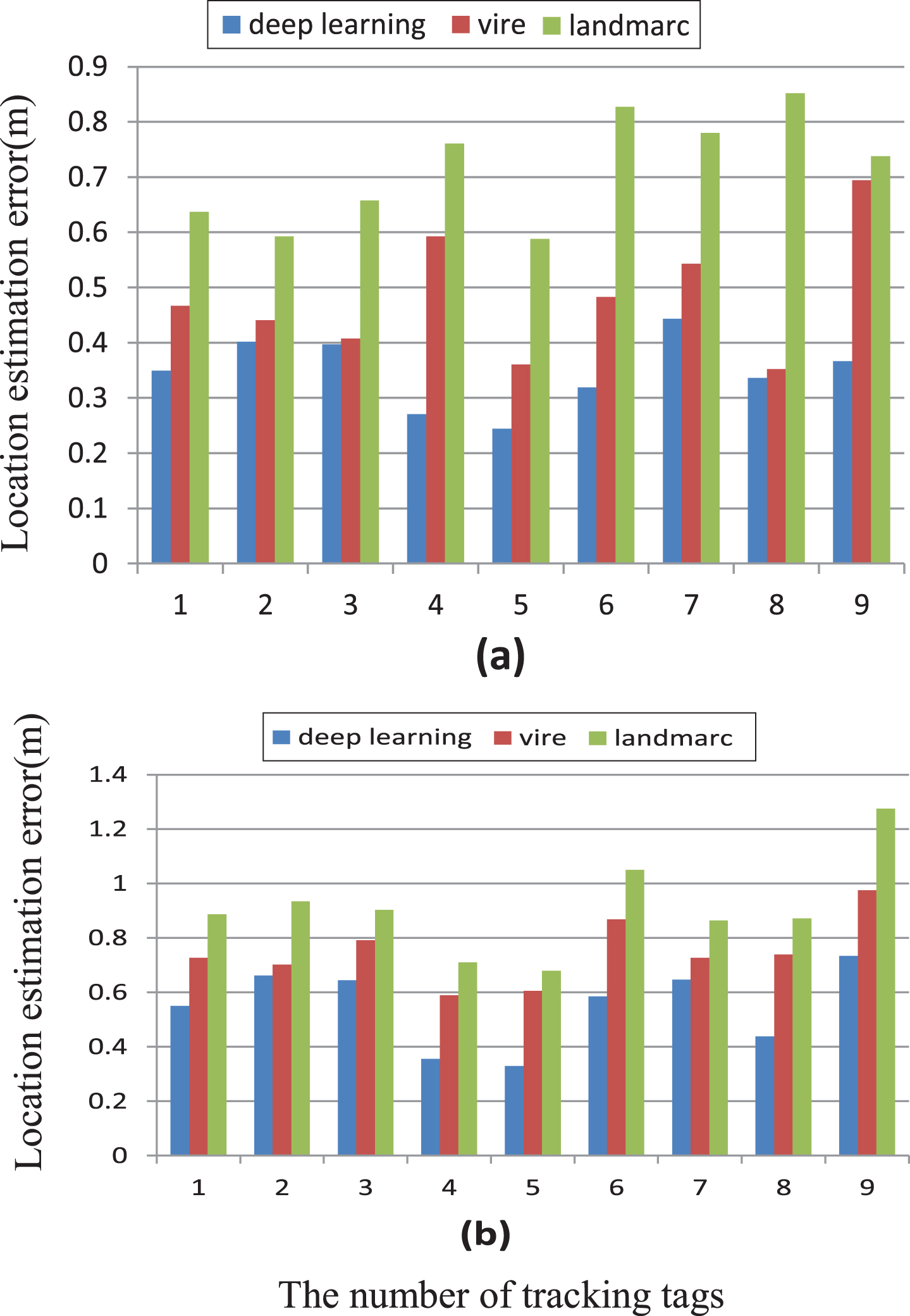
Comparison of estimation error between the deep learning approach and the baseline schemes (a) research lab (b) office room.
Virtual reference tag has the advantage of increasing the density of the reference tags. Moreover, the signal interference can be eliminated in this way. Theoretically, the accuracy of the deep learning approach grows with density of the virtual reference tag. Figure 9 illustrates the relationship between the position estimation error and the number of virtual reference tags in Environment 2 (office room). It is obvious that with the increase of the number of virtual reference tags, the estimation error decreases sharply. However, when the number exceeds 200, the accuracy increases slowly. Especially, there is no further improvement of accuracy when the number of the virtual reference tags is beyond 400.
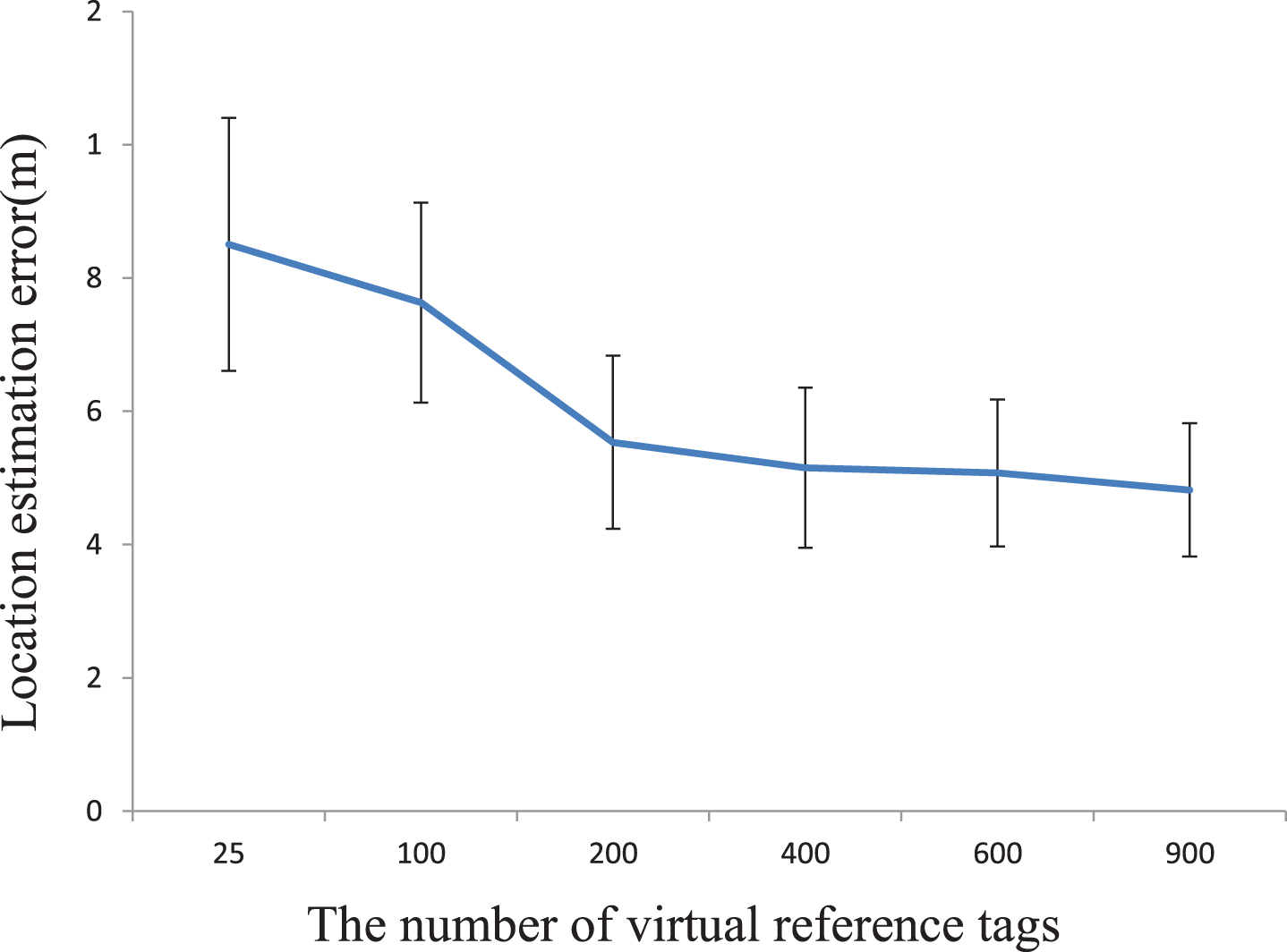
Relationship between the density of virtual reference tags and accuracy.
This paper presents a new RFID based indoor positioning approach, which is cost effective and provides reasonable accuracy. In order to improve the accuracy of fingerprint method, the concept of virtual reference tag is adopted, which is able to increase the number of reference tags without introducing the effect of signal interference. The key innovation of this research is that deep learning is leveraged to boost the computational efficiency and enhance the positioning estimation. The proposed approach is evaluated in our research lab and the office room. The results show that the deep learning method achieved high accuracy. Linear interpolation is used to estimate the RSSI value of the virtual reference tag, which is computationally inexpensive and easy to implement. Compared to the previous researches, this method improves the positioning accuracy and efficiency due to the combination of VIRE and deep learning. However, the RSSI value is not linearly correlated with the distance from the reader to tag. Further research will focus on the calculation of RSSI value using nonlinear algorithm. The proposed method can be applied to real-life scenarios. The development prospect of the system can be widely used in many indoor positioning environments such as warehouse goods inventory and indoor navigation.
Footnotes
Acknowledgments
This work is supported by the Education Department of Henan Province under Grant No.19B520004 and Henan University of Engineering under Grant No. DKJ2018025.