
Abstract
Statistical classifications are essential for collecting consistent data that can be compared over space and time. However, a publicly-documented body of practice concerning how to undertake the development and testing of a statistical classification is currently lacking. What aspects of the classification should be tested during the development process? How do we judge whether the classification is fit-for-purpose? How should problems and shortcomings be identified so that they can be remedied?
To fill this gap, we drew on existing, authoritative sources to develop an analytic structure for use in the development and testing of statistical classifications. It consists of two components: (1) a statistical classification development and testing framework reflecting the required features of a statistical classification; and (2) a 4-tier model representing the main elements that make up a statistical classification, to use as a heuristic structure within which to locate issues identified and consider how they can be addressed.
In this paper, we outline the development of the framework and model, and reflect on their application in testing a draft classification of health interventions. We propose this analytic structure as a new tool to support those engaged in the development of statistical classifications.
Keywords
Introduction
Standard statistical classifications exist across a wide range of fields of human endeavour, and collectively they play a crucial role in the functioning and administration of jurisdictions and economies [1, 2]. They are essential for collecting and analysing statistical data, and for comparing data over space and time [1, 3]. As stated in Principle 9 of the United Nations Fundamental Principles of Official Statistics, ‘The use by statistical agencies in each country of international concepts, classifications and methods promotes the consistency and efficiency of statistical systems at all official levels’ [4].
A statistical classification can be defined as ‘an exhaustive set of mutually exclusive categories to aggregate data at a pre-prescribed level of specialization for a specific purpose’ [5]. As well as providing a standard structure for the aggregation of data, classifications articulate a common understanding of the content and structure of an information domain, and so provide a basis for building knowledge and communicating information. By connecting concepts within a meaningful structure, classifications perform heuristic, descriptive, and explanatory functions central to knowledge creation [6, 7]. Examples of well-established and widely used statistical classifications include the World Health Organization’s International Classification of Diseases (ICD), used internationally for morbidity and mortality statistics [8], and the International Standard Industrial Classification of All Economic Activities (ISIC), used internationally for statistics on productive activities [9].
The development or revision of a statistical classification is a complex and resource-intensive undertaking that involves input from a wide spectrum of stakeholders [10]. Testing is a normal and essential part of the classification development process, and involves investigating the extent to which a classification is capable of performing its intended functions and identifying modifications needed. Principles concerning the desired attributes of statistical classifications have been articulated in a small number of key sources, notably two documents produced by the United Nations Statistics Division (UNSD) [3, 11]. Drawing on these sources, we have developed a clear and practical analytic structure for use in testing statistical classifications as part of the development process. This paper outlines the development of this analytic structure, describes its application in testing a new classification of health interventions, and discusses its potential value as a tool for future use in developing and testing statistical classifications.
Context: Public health uses for a new classification of health interventions
In its framework for action on strengthening health systems to improve health outcomes, the World Health Organization (WHO) identified ‘information’ as one of six building blocks that make up the health system, alongside health services, health workforce, medical products, vaccines and technologies, health financing, and leadership and governance [12]. The WHO plays an important role in promoting the production and use of health information globally, supporting countries to develop systems for data collection and management, and collating and reporting internationally comparable data. The provision of data standards, including statistical classifications, is a key aspect of this role [13].
In 2007, work began on developing a new WHO classification: the International Classification of Health Interventions (ICHI) (
ICHI is built around three axes:
Target: entity on which the Action is carried out; Action: deed done by an actor to the Target; Means: processes and methods by which the Action is carried out.
Each axis is a coded list of descriptive categories, and each intervention is represented by a title and a unique seven-character code denoting the Target, Action and Means for that intervention. For example, the code KBO.JK.AA is ‘Appendicectomy’, with Target KBO (Appendix), Action JK (Excision, total), and Means AA (Open approach). Thus, ICHI is a classification of pre-coordinated intervention codes underpinned by a tri-axial structure that can be utilised in the grouping and analysis of ICHI-coded data.
Today, in the field of public health, there is no established culture of systematic data collection and reporting on interventions. This is in contrast to the hospital sector in many countries, where data on interventions are routinely captured in administrative data systems and used for reimbursement and statistics. Without summary data on interventions for public health, it is not possible to examine the mix of interventions delivered, to make comparisons between jurisdictions or programs, to monitor trends over time, or to examine interventions delivered in relation to population demographic variables or policy priorities. Thus, the broad scope of ICHI potentially has great value for the field of public health.
A comprehensive developmental appraisal of the 2016 version of ICHI, focusing on public health applications, was undertaken to gain an understanding of its strengths and limitations, and to assist in further developing the classification and improving its utility. In preparing to test the draft classification, we searched the academic and grey literature for an appropriate framework or list of criteria to provide guidance concerning the aspects of the classification that should be tested. No single, authoritative source was found that could be used for this purpose. The following section describes the analytic structure developed to fill this gap.
Developing an analytic structure for use in classification development and testing
Published literature on the development and testing of classifications is sparse. While some form of testing is likely always to occur during the development process, it may often be less extensive and systematic than is ideal due to resource constraints, and publication of the process or results may not be a priority. Detailed information about the development and testing of the ICF, for example, has not been made publicly available by WHO, and only a small number of papers have been published describing what was done, e.g. [17, 18, 19]. Similarly, a program of testing was conducted during development of the ICD-11 [20], but there is no publicly-available documentation setting out the overall methodological framework, or detailing which aspects of the classification were tested or what criteria were used. Relevant published research is often focused on testing specific aspects or characteristics of a classification, such as clinical utility, inter-rater reliability, domain coverage, or cross-cultural applicability, e.g. [18, 21, 22, 23, 24, 25, 26].
The lack of a publicly-documented body of practice that can inform an overall approach to the development and testing of a statistical classification means that those involved in such endeavours cannot easily draw on prior experience.
We sought to identify relevant sources concerning the development and testing of statistical classifications in the academic and grey literature. Due to the nature of the topic, term-based searching of electronic databases was found to be of limited effectiveness. Therefore, starting with a small number of key works, we took an exploratory and iterative approach using reference lists and citation searches to find additional material. Using this method, we identified a number of sources that articulate desired attributes of statistical classifications and principles to guide classification development. Drawing on these, we developed an analytic structure made up of two components:
a statistical classification development and testing framework, listing required features against which a given classification may be appraised, and a 4-tier model representing the main elements that make up a statistical classification, to use as a heuristic structure within which to locate issues identified and consider how they can be addressed.
These two components are presented below, with a brief account of how each was developed, before turning to an application of the analytic structure in the case of ICHI to test its practical utility and robustness.
Statistical classification development and testing framework
Two important references addressing the design, testing, use, updating and revision of statistical classifications are the UNSD documents ‘Standard statistical classifications: basic principles’ [11] and ‘Best practice guidelines for developing international statistical classifications’ [3]. The former lists principles to be applied in the development or revision of statistical classifications and briefly discusses several methodological issues, including selecting the main variables of the classification, designing the structure, identifying the main statistical units, and gathering information required to describe and define categories. The latter is a succinct guide for developers on the range of matters to be addressed in the development process, and lists ‘essential components of a statistical classification’.
A third key document is ‘World Health Organization Family of International Classifications: definition, scope and purpose’ [27], which lists principles for including classifications in the WHO Family of International Classifications. A fourth source is a framework for evaluating health classifications used for statistical and reporting purposes [28], and a much earlier paper articulates four ‘attributes of an acceptable classification system’ [29]. Several principles concerning requirements of international classifications can also be found in the ICF [16]. These sources are consistent and complement each other.
Statements concerning the desired attributes of statistical classifications were extracted from these sources and initially roughly grouped according to the aspect of a classification to which they related. From this base, an iterative process of sorting and synthesis was used to generate a set of criteria comprehensively capturing the principles articulated in the source documents, grouped under twelve headings relating to distinct aspects of a statistical classification. The aim was to specify the criteria at a level of granularity that would facilitate their application in practice (Box 1). (See [30], Appendix 2.2, which shows how principles articulated in each of the source documents contributed to developing the framework).
These twelve headings are broad topics to which attention should be directed. The criteria are focused on those attributes of the classification that can be tested during the development phase (i.e., before the classification is in active use). Some principles articulated in the source documents relate to processes and infrastructure required to support the maintenance and consistent use of a classification, such as custodianship arrangements, version control mechanisms, updating and maintenance plans, and training materials. These are all important considerations that affect the quality and sustained utility of the classification, but they are not so relevant in the context of a developmental appraisal, and were therefore not included.
The criteria set out under the twelve headings of the framework provide a basis for examining the extent to which a draft classification possesses the desired features of a statistical classification. Problems or limitations identified against any of these criteria indicate issues that should be addressed to improve its utility.
4-tier model representing key elements of a statistical classification.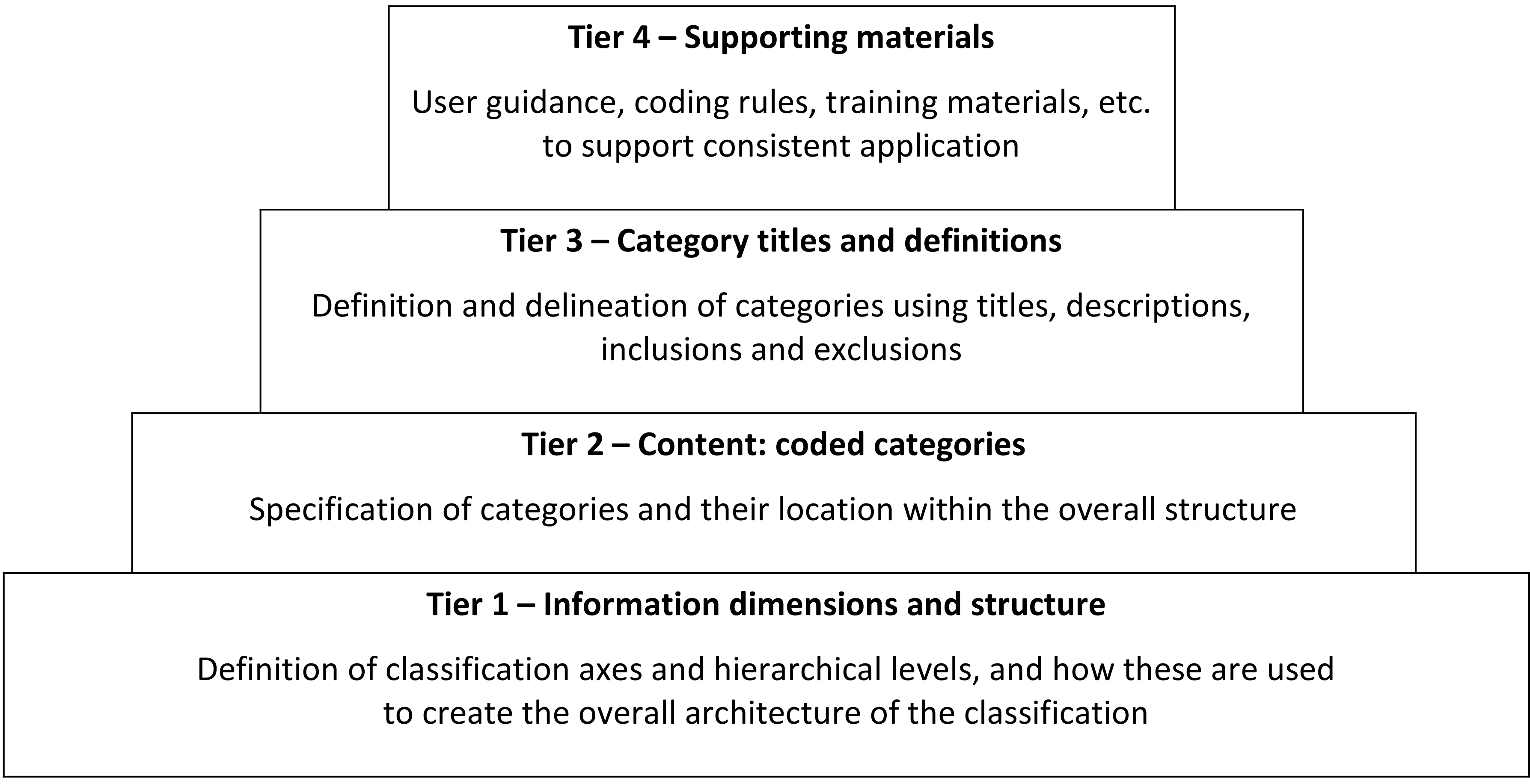
To complement the framework, we developed a simple model representing the main elements or layers that make up a statistical classification. The model was informed by a comparative analysis of the three WHO-FIC reference classifications (ICD, ICF and ICHI) [30], and also the essential components of a statistical classification as outlined in the ‘Best practice guidelines for developing international statistical classifications’ [3]. It has four ‘tiers’ (Fig. 1):
Tier 1 – Information dimensions and structure. This tier represents the conceptual structure that is the foundation for the classification. Tier 1 issues are concerned with the definition of classification axes and hierarchical levels, and how these elements are used to create the overall architecture of the classification. Tier 2 – Content: coded categories. This tier represents the population of the classification structure with coded categories. Tier 2 issues are concerned with the specification of categories and their location within the overall structure. Tier 3 – Category titles and definitions. This tier represents the way the content of and delineation between categories is communicated within the classification itself. Tier 3 issues are concerned with category titles, definitions, descriptions, inclusions and exclusions. Tier 4 – Supporting materials. This tier represents the infrastructure of materials developed to support consistent use of the classification, and thus to promote stability of the data produced through its application. Tier 4 issues are concerned with indexes, user guidance, coding rules, reporting standards and education/training materials.
The process of developing or revising a classification can be understood in terms of the 4-tier model, with development activities focusing on different tiers at different times.
Using ICHI as an example, initial developmental work focused on establishing the tri-axial structure and coding scheme, and populating the axes (Tiers 1 and 2). The next phase was concerted content development, with the generation of intervention codes by drawing on existing resources (particularly ICD-9-CM Volume 3 for medical and surgical interventions [31]) and by combining Target, Action and Means categories (Tier 2). Then followed several years of expanding, reviewing and refining both axis categories and intervention codes, with particular attention to the wording of titles, definitions, inclusions and exclusions to clearly delineate categories; a system of extension codes was developed to provide a way of capturing key additional information about an intervention (Tiers 2 and 3). Development of user guidance, coding rules and training materials (Tier 4) got underway once the bulk of the work on the structure and content of the classification had been completed. This is illustrated in Fig. 2.
Illustration of ICHI development in relation to the 4-tier model.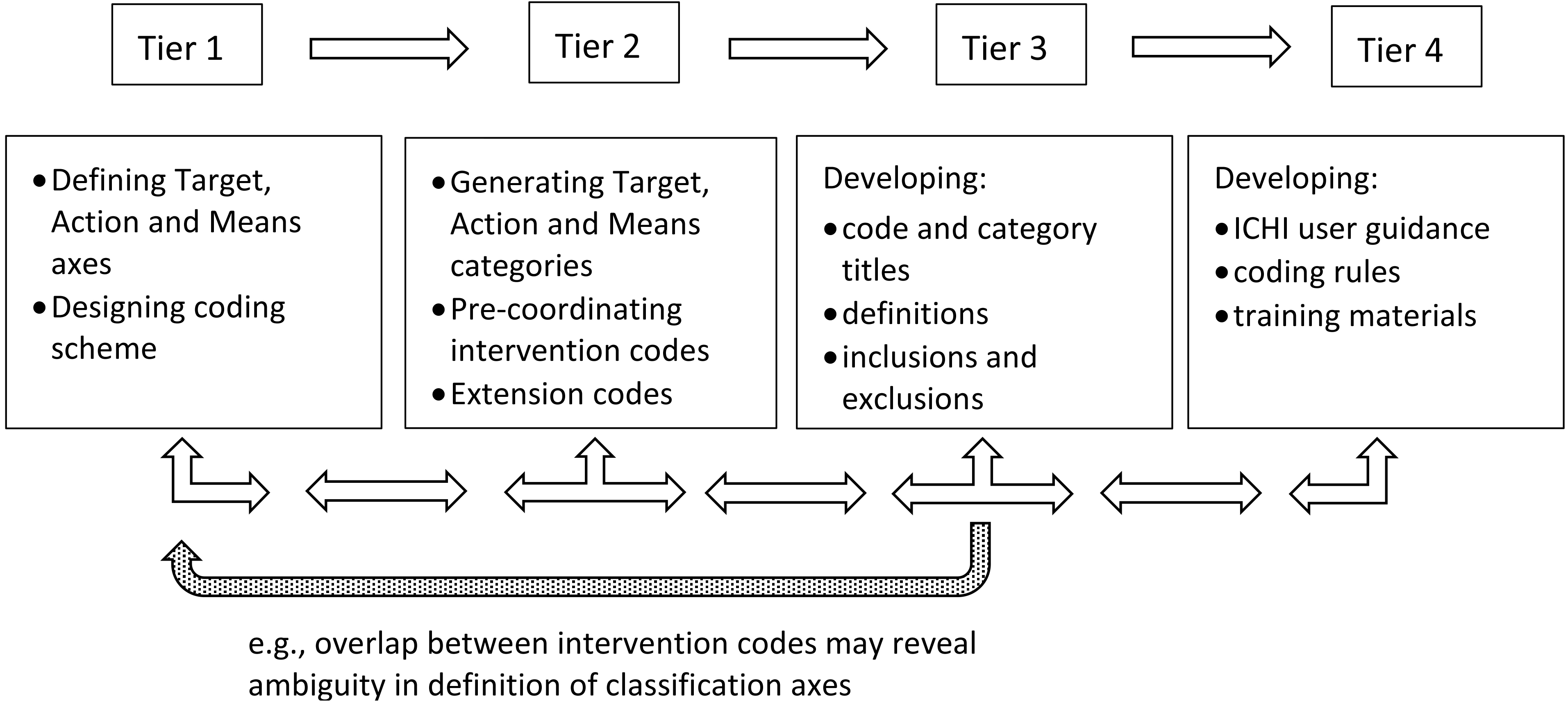
However, classification development is not a one-way, linear process. Although the lower tiers of the model can be seen as foundational to the tiers above, issues encountered during work focused at a higher tier may prompt review of decisions made at lower tiers. For example, use of the 4-tier model as a heuristic tool may assist in understanding that an apparent overlap between intervention codes (Tier 3) has its origins in ambiguity in the definition of the classification axes (Tier 1). Thus, the relationships and connections between the four tiers are important, and there will be flow up and down the model.
To appraise the draft ICHI classification for application in a public health context, three research components were undertaken:
ICHI public health data coding study: The draft classification was used to code interventions in three data sets that contained descriptions of public health interventions. Frequency distributions of the resulting ICHI-coded data were produced. Thematic analysis of detailed coding notes was conducted [32] to explore how well the classification was able to capture interventions, and distinctions between interventions, as they were described in the three data sets. Inter-coder comparison study: The draft classification was used independently by two coders to code a subset of records from each of the data sets. Rates of agreement between coders were calculated. Reasons for coding discrepancies were explored to understand differences in interpretation of classification categories and consider implications of coding discrepancies for the reliability of ICHI-coded data. In-depth key-informant interviews: Semi-struc-tured interviews were conducted to obtain feedback from key informants associated with each of the data sets (a total of 10 key informants), concerning the structure and content of the draft classification, and its utility for representing and analysing data on public health interventions.
The analytic structure described above was used to draw together the findings from these three research components. First, strengths and limitations of the classification were identified in relation to the criteria set out under the twelve headings of the framework (Box 1). The 4-tier model was then used as a heuristic tool to consider the origins and manifestations of, and the interactions among, the limitations identified, and how they might be addressed. This process facilitated clear articulation of the often complex and interrelated issues identified.
Summarising and documenting the research findings within the structure of the framework and the model provided a basis for an overall appraisal of the draft classification, a set of recommendations concerning specific changes needed, and a plan for further development of the classification in view of some more fundamental challenges identified [30]. Based on this application of the analytical structure, reflections on its practical utility in classification testing and development are provided below.
Utility of the statistical classification development and testing framework
In applying the framework to the research findings, it became clear that some issues could appropriately be discussed under more than one heading, and some issues were causally related to issues discussed elsewhere in the framework. For example, the finding that some axis categories were not sufficiently delineated was picked up under no. 5 ‘Mutual exclusivity’ and no. 6 ‘Clearly defined classification categories’. Issues concerning how the ICHI axes Target and Action are operationalised for public health interventions were discussed under no. 2 ‘Structure and organisational principles’, and identified as a cause of mutual exclusivity issues (no. 5); similarly, problems with identifying units of classification (no. 3) and coverage gaps (no. 4) were identified as contributing to poor reliability (no. 9).
These inter-relationships were not surprising. Rather than resulting in duplication or redundancy, the inter-relatedness of different components of the framework enables a given issue to be viewed from different perspectives, fostering a greater depth of understanding.
The appraisal highlighted the multi-faceted nature of some of the criteria. For example, exploration of research findings in relation to no. 2, ‘Structure and organisational principles’, revealed this to be a multi-faceted topic, concerning not only the identity and definition of classification axes but also how the axes are realised as lists of axis categories, what underlying concepts are present, and how axis categories are used in the construction of intervention codes. In relation to mutual exclusivity (no. 5), there were issues of two broad types: applicability of more than one axis category (and thus intervention code) to a single unit of classification, and unclear or overlapping axis categories.
We considered whether the framework should be further elaborated, to list the different types of issues that might arise under each heading. However, the nature of specific issues that arise might vary depending on the characteristics of a given classification. On balance, our view was that the current level of detail is adequate, and it should be left to users to discover and investigate the issues that arise for a particular classification in relation to each of the criteria.
Utility of the 4-tier model
The 4-tier model proved to be a useful tool that aided consideration of how the problems identified through applying the framework could be addressed in the next phases of developing ICHI. Ideally, development would address issues at tier 1 first, to strengthen the conceptual structure that is the foundation for the classification, then progress upwards to address issues at subsequent tiers. In some cases, a decision taken at a lower tier may obviate the need to address an issue identified at a higher tier. Conversely, development at a higher tier (e.g., work on category definitions) may suggest the need for changes at a lower tier (e.g., adding or removing categories).
In practice, it may not always be possible to resolve issues at lower tiers before tackling higher-tier issues, for instance because of time or resource constraints. In such situations a pragmatic decision may be to seek solutions at higher tiers to improve the practical utility of the classification. For example, tightening up definitions and adding exclusion terms may solve mutual exclusivity problems that have their roots in underlying conceptual issues with classification axes. Whichever pathway is taken, understanding the nature and source of problems is valuable for considering options during development.
Viewing issues as located at different levels of the 4-tier model is helpful for appreciating the relationships and dependencies that exist between issues. This provides a basis for making pragmatic decisions about how to move forward, while being aware of what issues remain so that these can be considered in future revisions of the classification, and can inform interpretation of data produced using the classification.
Conclusions and recommendations for future use of the analytic structure for statistical classification development and testing
In the context of conducting an appraisal of the draft ICHI classification for public health, the statistical classification development and testing framework and 4-tier model proved valuable for identifying and articulating specific strengths and limitations of the classification. Both elements of the analytic structure assisted with separating out the issues identified while also capturing inter-relationships among them, serving to provide a clear basis for identifying options for the further development of the classification.
The statistical classification development and testing framework is based on existing, authoritative sources, and adds value by extracting those requirements that are relevant to a classification in the developmental phase and formalising them as a concise and comprehensive list. It does not stipulate how to decide whether a particular criterion is satisfied, or whether the classification is ‘fit-for-purpose’ overall. Rather, it provides a checklist of issues to be considered or tested as part of a developmental appraisal.
In our case, we concluded that, while ICHI has potential utility, the 2016 draft version did not sufficiently meet the criteria to function as a robust statistical classification in the public health domain. However, applying the analytic structure to the research findings led to development of a set of proposals for improving the utility of the classification, and a path forward that would see ICHI used more broadly and flexibly as a common framework to provide a basis for connection and information exchange between diverse actors across various settings. This is something that has, to date, been absent in the field of public health.
The 4-tier model functioned well as a heuristic structure within which to locate the particular issues identified as needing to be addressed to improve the classification. It highlighted the importance of taking an integrated approach to the further development of ICHI, maintaining an awareness of how issues addressed at one tier affect or are affected by aspects of the classification at other tiers, rather than seeking to ‘fix’ specific issues in a piecemeal fashion. Although it is a simple model of the main elements or layers that make up a statistical classification, it can function as a powerful tool to support the process of identifying and comparing options for making changes to improve a classification’s utility, and thinking clearly about the implications of choices made. Continued use of this model is proposed as part of an integrated approach to the further development of ICHI.
As there is currently no established, publicly-documented body of practice concerning the development and testing of statistical classifications, we propose that the statistical classification development and testing framework and 4-tier model will be of value to future classification development and revision projects. Their use can support a comprehensive, rigorous and conceptually explicit approach to the appraisal of a classification during the development or review process, leading to clearer decisions about changes needed in order to optimise utility of the classification for its intended users. We welcome testing of the analytic structure in other fields of statistical endeavour, such as industrial classifications, to assess its global relevance.
The development of infrastructure and processes to support the production of high quality, reliable and comparable statistics is a central concern of national and international statistical agencies. The Fundamental Principles of Official Statistics were adopted by the UN General Assembly in 2014. More recently, the UN Conference on Trade and Development has developed the UN Statistics Quality Assurance Framework (SQAF), designed to support the production and dissemination of the best quality statistics possible [33]. The analytic structure for statistical classification development and testing we describe here has the potential to complement these instruments and contribute to improved statistics by supporting the development of quality statistical classifications.