
Abstract
This article introduces TableMiner+, a Semantic Table Interpretation method that annotates Web tables in a both effective and efficient way. Built on our previous work TableMiner, the extended version advances state-of-the-art in several ways. First, it improves annotation accuracy by making innovative use of various types of contextual information both inside and outside tables as features for inference. Second, it reduces computational overheads by adopting an incremental, bootstrapping approach that starts by creating preliminary and partial annotations of a table using ‘sample’ data in the table, then using the outcome as ‘seed’ to guide interpretation of remaining contents. This is then followed by a message passing process that iteratively refines results on the entire table to create the final optimal annotations. Third, it is able to handle all annotation tasks of Semantic Table Interpretation (e.g., annotating a column, or entity cells) while state-of-the-art methods are limited in different ways. We also compile the largest dataset known to date and extensively evaluate TableMiner+ against four baselines and two re-implemented (near-identical, as adaptations are needed due to the use of different knowledge bases) state-of-the-art methods. TableMiner+ consistently outperforms all models under all experimental settings. On the two most diverse datasets covering multiple domains and various table schemata, it achieves improvement in F1 by between 1 and 42 percentage points depending on specific annotation tasks. It also significantly reduces computational overheads in terms of wall-clock time when compared against classic methods that ‘exhaustively’ process the entire table content to build features for inference. As a concrete example, compared against a method based on joint inference implemented with parallel computation, the non-parallel implementation of TableMiner+ achieves significant improvement in learning accuracy and almost orders of magnitude of savings in wall-clock time.
Keywords
Introduction
Recovering semantics from tables is a crucial task in realizing the vision of the Semantic Web. On the one hand, the amount of high-quality tables containing useful relational data is growing rapidly to hundreds of millions [3,4]. On the other hand, search engines typically ignore underlying semantics of such structures at indexing, hence performing poorly on tabular data [21,24]. Research directed to this particular problem is An example Wikipedia webpage containing a relational table (Last retrieved on 9 April 2014).
Although classic Natural Language Processing (NLP) and Information Extraction (IE) techniques address similar research problems [5,10,28,45], they are tailored for well-formed sentences in unstructured texts, and are unlikely to succeed on tabular data [21,24]. Typical Semantic Table Interpretation methods make extensive use of structured knowledge bases, which contain candidate concepts and entities, each defined with rich lexical and semantic information and linked by relations. The general workflow involves: (1) retrieving candidates corresponding to table components (e.g., concepts given a column header, or entities given the text of a cell) from the knowledge base, (2) represent candidates using features extracted from both the knowledge base and tables to model semantic interdependence between table components and candidates (e.g., the header text of a column and the name of a candidate concept), and between various table components (e.g., a column should be annotated by a concept that is shared by all entities in the cells from the column), and (3) applying inference to choose the best candidates.
This work addresses several limitations of state-of-the-art on three dimensions: effectiveness, efficiency, and completeness.
Effectiveness – Semantic Table Interpretation methods so far have primarily exploited features derived from two sources: the knowledge bases, and table components such as header and row content (to be called
We show empirically that we can derive useful features from out-table context to improve annotation accuracy. Such out-table features are highly generic and generally available. While on the contrary, many existing methods use knowledge base specific features that are impossible to generalize, or suffer substantially in terms of accuracy when they can be adapted, which we shall show in experiments.
Efficiency – We argue that efficiency is also an important factor to consider in the task of Semantic Table Interpretation, even though it has never been explicitly addressed before. The major bottleneck is mainly due to three types of operations: querying the knowledge bases, building feature representations for candidates, and computing similarity between candidates. Both the number of queries and similarity computation can grow quadratically with respect to the size of a table as often such operations are required for each pair of candidates [21,24,27]. Empirically, Limaye et al. [21] show that the actual inference algorithm only consumes less than 1% of total running time. Using a local copy of the knowledge base only partially addresses the issue but introduces more problems. First, hosting a local knowledge base requires infrastructural support and involves set-up and maintenance. As we enter the ‘Big-Data’ era, knowledge bases are growing rapidly towards a colossal structure such as the Google Knowledge Graph [33], which constantly integrates increasing numbers of heterogeneous sources. Maintaining a local copy of such a knowledge base is likely to require an infrastructure that not every organization can afford [29]. Second, local data are not guaranteed to be up-to-date. Third, scaling up to very large amount of input data requires efficient algorithms in addition to parallelization [32], as the process could be bound by the large number of I/O operations. Therefore in our view, a more versatile solution is cutting down the number of queries and data items to be processed. This reduces I/O operations in both local and remote scenarios, also reducing costs associated with making remote calls to Web service providers.
In this direction, we identify an opportunity to improve state-of-the-art in terms of efficiency. To illustrate, consider the example table that in reality contains over 60 rows. To annotate each column, existing methods would use content from every row in the column. However, from a human reader’s point of view, this is unnecessary. Simply reading the eight rows one can confidently assign a concept to the column to best describe its content. Being able to make such inference with limited data would give substantial efficiency advantage to Semantic Table Interpretation algorithms, as it will significantly reduce the number of queries to the underlying knowledge bases and the number of candidates to be considered for inference.
Completeness – Many existing methods only deal with one or two types of annotation tasks in a table [35,36]. In those that deal with all tasks [7,21,23–25], only NE-columns are considered. As shown in Fig. 1, tables can contain both NE-columns containing entity mentions, and literal-columns containing data values of entities on the corresponding rows. Methods such as Limaye et al. [21] and Mulwad et al. [24] can recognize relations between the first and third columns, but are unable to identify the relation between the first and the second columns. We argue that a Semantic Table Interpretation method should be able to annotate both NE-columns and literal-columns.
To address these issues, we developed TableMiner previously [42] that uses features from both in- and out-table context and annotates NE-columns and cells in a relational table based on the principle of ‘start small, build complete’. That is, (1) create preliminary, likely erroneous annotations based on partial table content and a simple model assuming limited interdependence between table components; (2) and then iteratively optimize the preliminary annotations by enforcing interdependence between table components. In this work we extend it to build TableMiner+, by adding ‘subject column’ [35,36] detection, relation enumeration, and improving the iterative optimization process. Concretely, TableMiner+ firstly interprets NE-columns (to be called column interpretation), while coupling column classification and entity disambiguation in a mutually recursive process that consists of a LEARNING phase and an UPDATE phase. The LEARNING phase interprets each column independently by firstly learning to create preliminary column annotations using an automatically determined ‘sample’ from the column, followed by ‘constrained’ entity disambiguation of the cells in the column (limiting candidate entity space using preliminary column annotations). The UPDATE phase iteratively optimizes the classification and disambiguation results in each column based on a notion of ‘domain consensus’ that captures inter-column and inter-task dependence, creating a global optimum. For relation enumeration, TableMiner+ detects a subject column in a table and infers its relations with other columns (both NE- and literal-columns) in the table.
TableMiner+ is evaluated on four datasets containing over 15,000 tables, against four baselines and two re-implemented near-identical1
Despite our best effort, identical replication of existing systems and experiments has been not possible due to many reasons, see Appendix D.
The remainder of this paper is organized as follows. Section 2 defines terms and concepts used in the relevant domain. Section 3 discusses related work. Sections 4 to 9 introduce TableMiner+ in detail. Sections 10 and 11 describe experiment settings and discuss results, followed by conclusion in Section 12.
A
Relational tables may or may not contain a
A
The task of Semantic Table Interpretation addresses three annotation tasks. Named Entity Disambiguation associates each cell in NE-columns with one canonical entity; column classification annotates each NE-column with one concept, or in the case of literal-columns, associates the column to one property of the concept assigned to the subject column of the table; Relation Extraction (or enumeration) identifies binary relations between NE-columns, or in the case of one NE-column and a literal-column and given that the NE-column is annotated by a specific concept, identifies a property of that concept that could explain the data literals. The candidate entities, concepts and relations are drawn from the knowledge base.
Using the example table and Freebase as example, the first column can be considered a reasonable subject column and should be annotated by the Freebase type ‘Film’ (URI ‘fb:5
fb:
Legacy tabular data to linked data
Research on converting tabular data in legacy data sources to linked data format has made solid contribution toward the rapid growth of the LOD cloud in the past decade [6,12,19,30]. The key difference from the task of Semantic Table Interpretation is that the focus is on data generation rather than interpretation, since the goal is to pragmatically convert tabular data from databases, spreadsheets, and similar data structures into RDF. Typical methods require manually (or partially automated) mapping the two data structures (input and output RDF), and they do not link data to existing concepts, entities and relations from the LOD cloud. As a result, the implicit semantics of the data remain uncovered.
General NLP and IE
Some may argue to use the general purpose NLP/IE methods for Semantic Table Interpretation, due to their highly similar objectives. This is infeasible for a number of reasons. First, state-of-the-art methods [17,31] are typically tailored to unstructured text content that is different from tabular data. The interdependence among the table components cannot be easily modeled in such methods [22]. Second and particularly for the tasks of Named Entity Classification and Relation Extraction, classic methods require each target semantic label (i.e., concept or relation) to be pre-defined and learning requires training or seed data [28,40]. In Semantic Table Interpretation however, due to the large degree of variations in table schemata (e.g., Limaye et al. [21] use a dataset of over 6,000 randomly crawled Web tables of which no information about the table schemata is known a priori), defining a comprehensive set of semantic concepts and relations and subsequently creating necessary training or seed data are infeasible.
A related IE task tailored to structured data is wrapper induction [9,18], which automatically learns wrappers that can extract information from regular, recurrent structures (e.g., product attributes from Amazon webpages). In the context of relational tables, wrapper induction methods can be adapted to annotate table columns that describe entity attributes. However, they also require training data and the table schemata to be known a priori.
Table extension and augmentation
Table extension and augmentation aims at gathering relational tables that contain the same entities but cover complementary attributes of the entities, and integrate these tables by joining them on the same entities. For example, Yakout et al. [38] propose InfoGather for populating a table of entities with their attributes by harvesting related tables on the Web. The users need to either provide the desired attribute names of the entities, or example values of their attributes. The system can also discover the set of attributes for similar entities. Bhagavatula et al. [1] introduce WikiTables, which given a query table and a collection of other tables, identifies columns from other tables that would make relevant additions to the query table. They first identify a reference column (e.g., country names in a table of country population) in the query table to use for joining, then find a different table (e.g. a list of countries by GDP) with a column similar to the reference column, and perform a left outer join to augment the query table with an automatically selected column from the new table (e.g., the GDP amounts). Lehmberg et al. [20] create the Mannheim Search Joins Engine with the same goal as WikiTables but focus on handling tens of millions of tables from heterogeneous sources.
The key difference between these systems and the task of Semantic Table Interpretation is that they focus on integration rather than interpretation. The data collected are not linked to knowledge bases and ambiguity still remains.
Semantic Table Interpretation
Hignette et al. [14,15] and Buche et al. [2] propose methods to identify concepts represented by table columns and detect relations present in tables in a domain-specific context. An NE-column is annotated based on two factors: similarity between the header text of the column and the name of a candidate concept; plus the similarities calculated for each cell in the column and each term in the hierarchical paths containing the candidate concept. For relations, they only detect the presence of semantic relations in the table without specifying the columns that form binary relations.
Venetis et al. [35] annotate table columns and identify relations between the subject column and other columns using types and relations from a database constructed by mining the Web using lexico-syntactic patterns such as the Hearst patterns [13]. The database contains co-occurrence statistics about the subject and object of triples, such as the number of times the word ‘cat’ and ‘animal’ extracted by the pattern
Likewise, Wang et al. [36] argue that tables describe a single entity type (concept) and its attributes and therefore, consist of an entity column (subject column) and multiple attribute columns. The goal is to firstly identify the entity column in the table, then associate a concept from the Probase knowledge base [37] that best describes the table schema. Essentially this allows annotating the subject NE-column and literal-columns using properties of the concept, also identifying relations between the subject column and other columns. Probase is a probabilistic database built in the similar way as that in Venetis et al. [35] and contains an inverted index that supports searching and ranking candidate concepts given a list of terms describing possible concept properties, or names describing possible instances. The method heavily depends on these features and the probability statistics gathered in the database.
Muñoz et al. [26] extract RDF triples for relational tables from Wikipedia articles. The cells in the tables must have internal links to other Wikipedia articles. These are firstly mapped to DBpedia named entities based on the internal links, then to derive relations between two entities on the same row and from different columns, the authors query the DBpedia dataset for triples in the form of
Zwicklbauer et al. [46] use a simple majority vote model for column classification. Each candidate entity in the cells of the column casts a vote to the concept it belongs to, and the one that receives the most votes is the concept used to annotate the column. They show that for this very specific task, it is unnecessary to exhaustively disambiguate each cell in a column. Instead, comparable accuracy can be obtained by using a fraction of the cells from the column. However, the sample size is arbitrarily decided.
Syed et al. [7] deal with all three annotation tasks using DBpedia and Wikitology [34], the latter of which contains an index of Wikipedia articles describing entities and a classification system that integrates several vocabularies including the DBpedia ontology, YAGO, WordNet6
Limaye et al. [21] propose to model table components and their interdependence using a probabilistic graphical model. The model consists of two components: ‘variables’ that model different table components, and ‘factors’ that are further divided into node factors modeling the compatibility between the variable and each of its candidate, and edge factors modeling the compatibility between the variables believed to be correlated. For example, given an NE-column, the header of the column is a variable that takes values from a set of candidate concepts; and each cell in the column is a variable that takes values from a set of candidate entities. The node factor for the header could model the compatibility between the header text and the names of each candidate concept; while the edge factor could model the compatibility between any candidate concept for the header and any candidate entity from each cell. The strength of compatibility could be measured using methods such as string similarity metrics [11] and semantic similarity measures [43]. Then the task of inference amounts to searching for an assignment of values to the variables that maximizes the joint probability. A unique feature of this method is that it solves the three annotation tasks simultaneously, capturing interdependence between various table components at inference, while other methods either tackle individual annotation tasks or tackles each separately and sequentially.
Mulwad et al. [24] argue that computing the joint probability distribution in Limaye’s method is very expensive. Built on the earlier work by Syed et al. [7] and Mulwad et al. [23,25], they propose a light-weight semantic message passing algorithm that applies inference to the same kind of graphical model. This is similar to TableMiner+ in the way that the UPDATE phase of TableMiner+ can be considered as a similar semantic message passing process. However, TableMiner+ is fundamentally different since it (1) adds a subject column detection algorithm; (2) deals with both NE-columns and literal-columns, while Mulwad et al. only handle NE-columns; (3) uses an efficient approach bootstrapped by sampled data from the table while Mulwad et al. build a model that approaches the task in an exhaustive way; (4) defines and uses context around tables as features while Mulwad et al. has used knowledge base specific features; (5) uses different methods for scoring and ranking candidate entities, concepts and relations; and (6) models interdependence differently which, if transforms to an equivalent graphical model, would result in fewer factor nodes.
Existing Semantic Table Interpretation methods have several limitations. First, they have not considered using features from out-table context, which is highly generic and generally available. Instead, many have used knowledge base specific features that are difficult or impossible to generalize. For example, the co-occurrence statistics used by Venetis et al. [35] and Wang et al. [36] are unavailable in knowledge bases such as YAGO, DBpedia, and Freebase. Methods such as Limaye et al. [21] and Mulwad et al. [24] use the concept hierarchy in their knowledge bases. However, Freebase does not have a strict concept hierarchy. These methods can become less effective when adapted to different knowledge bases, as we shall show later.
Second, no existing methods explicitly address efficiency, which we argue as an important factor in Semantic Table Interpretation tasks. Current methods are non-efficient because they typically adopt an exhaustive strategy that examines the entire table content, e.g., column classification depends on every cell in the column. This results in quadratic growth of the number of computations and knowledge base queries with respect to the size of tables, as such operations are usually required for every pair of candidates, e.g., candidate relation lookup between every pair of entities on the same row [24,26,27], or similarity computation between every pair of candidate entity and concept in a column [21]. This can be redundant as Zwicklbauer et al. [46] have empirically shown that comparable accuracy can be obtained by using only a fraction of data (i.e., sample) from the column. However, there remains the challenge to automatically determine the optimal sample size and elements.
Further, existing methods are incomplete, since they either only tackle certain annotation tasks [35,36], or only deal with NE-columns [7,21,23–25].
In an attempt to address some of the above issues, we previously developed a prototype TableMiner [42] that is able to annotate NE-columns and disambiguate entity cells in an incremental, mutually recursive and bootstrapping approach seeded by automatically selected sample from a table. And in Zhang [41] we further explored different methods for selecting the sample and its effect on accuracy. This work joins the two and largely extends them in a number ways: (1) adding a new algorithm for subject column detection and for relation enumeration; (2) revising the column classification and entity disambiguation processes (primarily in the UPDATE process); (3) performing significantly more comprehensive experiments to thoroughly evaluate the new method; and (4) releasing both the dataset and software to encourage future research.
Overview
Figure 2 shows the data flow and processes of TableMiner+. Given a relational table it firstly detects a subject column (Section 6), which is used by later processes of column interpretation and relation enumeration. Then TableMiner+ performs NE-column interpretation, coupling column classification with entity disambiguation in an incremental, mutually recursive, bootstrapping approach. This starts with a LEARNING phase (Section 7) that interprets one NE-column at a time independently to create preliminary concept annotation for an NE-column and entity annotation for the cells, followed by an UPDATE phase (Section 8) that iteratively revises the annotations by enforcing interdependence between columns, and between the classification and disambiguation results.
The overview of TableMiner+. (a) a high-level architecture diagram; (b) detailed architecture with input/output. d – table data. Grey colour indicates annotated table elements. Angle brackets indicates annotations. Inside a table: H – header. E, a, b, x, z – content cells.
In the LEARNING phase, for preliminary column classification (Section 7.2), TableMiner+ works in an incremental, iterative manner to gather evidence from each cell in the column at a time until it reaches a stopping criteria (automatically determined), usually before covering all cells in the column. Therefore, TableMiner+ can use only partial content in the column to perform column classification. We say that it uses a ‘sample’ from the column for the task and each element in the sample is a cell which TableMiner+ has used as evidence for preliminary column classification until stop. In theory, the size and elements of the sample can affect the outcome and hence the accuracy of classification. For this reason, a sample ranking process (Section 7.1) precedes preliminary column classification to re-order table rows based on the cells in the target column with a goal to optimize the sample to obtain the highest accuracy of classification. Next, the preliminary concept annotation for the column is used to constrain entity candidate space in disambiguating cells in the column (preliminary cell disambiguation, Section 7.3). Using a sample for column classification and constraining entity candidate space allows TableMiner+ to be more efficient than state-of-the-art methods that exhaustively process all content from a column.
The UPDATE phase begins by taking the entity annotations in all NE-cells to create a ‘domain representation’ (Section 8.1), which is compared against candidate concepts for each NE-column to revise the preliminary column classification results (Section 8.2). If any NE-column’s annotation changes due to this process, the newly elected concept is then used to revise disambiguation results in that column (Section 8.3). This process repeats until no changes are required.
Finally relation enumeration (Section 9) discovers binary relations between the subject column and other NE-columns; or identifies a property of the concept used to annotate the subject column to best describe data in the literal-columns. In the latter case, the property is considered both the annotation for the literal-column, and the relation between the subject column and the literal-column.
The incremental, iterative process used by preliminary column classification is implemented as a generic incremental inference with stopping algorithm (I-Inf), which is also used for subject column detection and is described in Section 5.
Types of context from which features are created for Semantic Table Interpretation
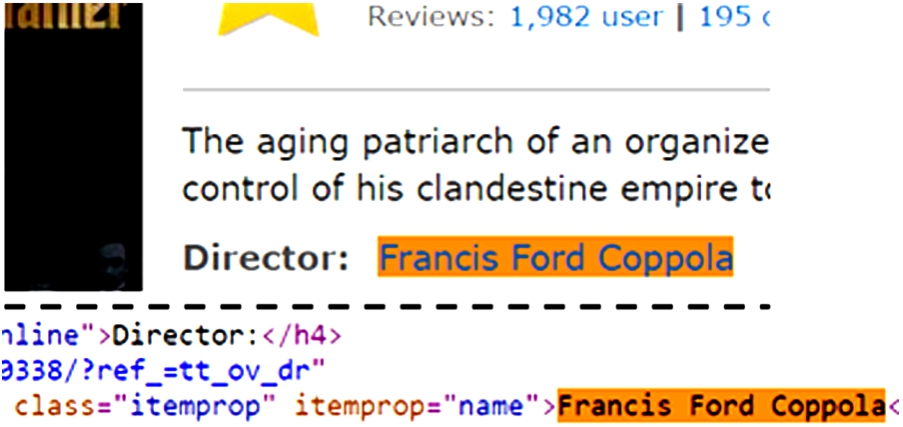
Example semantic markup in a webpage.
In the following sections we describe details of each component, and we will highlight the changes or additions to the previous TableMiner (if any) in each section. In Appendix F we list an index of mathematical notations and equations that are used throughout the remainder of this article. Readers may use this for quick access to their definitions.
We firstly describe the I-Inf algorithm that we have previously introduced in [42]. Here we generalize it so it can be used by both subject column detection and preliminary column classification. As shown in Algorithm 1, it starts by taking input a dataset D, an empty set of key-value pairs I-inf
Preprocessing
Subject column detection begins by classifying cells from each column (denoted by
Next, if a candidate NE-column has a column header that is a preposition word, it is discarded. An example like this is shown in Fig. 4, where the columns ‘For’ and ‘Against’ are clearly not subject columns but rather form relations with the subject column ‘Batsman’.
An example table containing columns with preposition words as headers.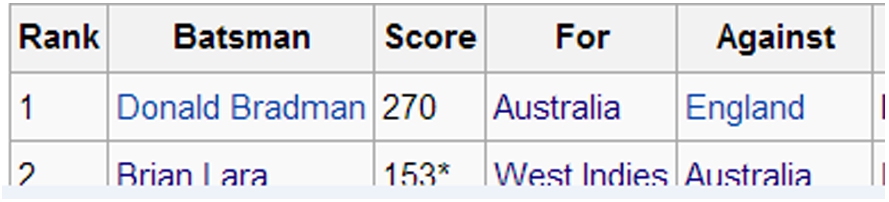
Features used for subject column detection. Examples are based on the visible content in the example table
Features used for subject column detection. Examples are based on the visible content in the example table
For each row, the cell that receives the highest score is considered to be containing the subject entity for the row. The intuition is that the query should contain the name of the subject entity plus contextual information of the entity’s attributes. When searched, it is likely to retrieve more documents regarding the subject entity than its attributes, and the subject entity is also expected to be repeated more frequently. For the first content row in the example table, we create a query by concatenating text from the 1st, 3rd and 4th cells on the row (only NE-columns are candidates of subject columns), i.e., ‘big deal on madonna street, mario monicelli, marcello mastroianni’. This is searched on the Web to return a list of documents. Then for each document, we count the frequency of each phrase in the title and snippet and compute countp for each corresponding cell. Next, take the 1st cell for example, ‘big deal on madonna street’ is transformed to a set of unique words {‘big’, ‘deal’, ‘madonna’, ‘street’}, and we count the frequency of each word in the titles and snippets of each document to compute countw. If any occurrence is part of an occurrence of the whole phrase that is already counted in countp, we ignore them. Likewise, we repeat this for the 3rd and 4th cells. Finally, we find that the 1st cell receives the highest Web search score, and we mark it as the subject entity for this row. In principle the Web search score of a column Following Example 1, we obtain three key-value pairs after processing the first content row:
Features (except
An alternative approach would be to train a machine learning model using these features to predict subject column. However, we did not explore this extensively as we want to keep TableMiner+ unsupervised. Also we want to focus on creating semantic annotations in tables in this work.
NE-column interpretation – The LEARNING phase
After subject column detection, TableMiner+ proceeds to the LEARNING phase where the goal is to perform preliminary column classification and cell disambiguation on each NE-column independently.
In preliminary column classification (Section 7.2), TableMiner+ generates candidate concepts for an NE-column and computes confidence scores for each candidate. Intuitively, if we already know the entity annotation for each cell, we can define candidate concepts as the set of concepts associated with the entity from each cell. However, cell annotations are not available at this stage. To cope with this ‘cold-start’ problem, preliminary column classification encapsulates a cold-start disambiguation process in the context of the I-Inf algorithm. Specifically, in each iteration, a cell taken from the column is disambiguated by comparing the feature representation of each candidate entity against the feature representation of that cell. Then the concepts associated with the highest scoring (i.e., the winning) entity7
Practically, our implementation also takes into account the fact that there can be multiple entities with the same highest score from a cell. For the sake of simplicity, throughout the discussion we assume there is only one. This also applies to the winning concept on a column and relation between two column.
Since I-Inf enables TableMiner+ to use only a sample of the column data to create preliminary column annotations, the sample ranking process (Section 7.1) is applied before preliminary column classification to ensure that the latter uses an optimal sample which potentially contributes to the highest accuracy.
In preliminary cell disambiguation (Section 7.3), the annotation of the column created in the previous stage is used to (1) revise cold-start disambiguation results in cells that have been processed; and (2) constrain candidate entity space in the disambiguation of the remaining cells.
For both preliminary column classification and cell disambiguation, we mostly8
Minor modifications will be pointed out.
Preliminary column annotations depend on cold-start disambiguation of the cells in the sample. For this reason, we hypothesize that a good sample should contain cells that are ‘easy’ to disambiguate, such that it is more likely to obtain high disambiguation accuracy, which then may contribute to high classification accuracy. We further hypothesize that a cell makes an easy disambiguation target if: (1) we can create rich feature representation of its candidate entities, or its context, or both; and (2) the text content is less ambiguous hence fewer candidates are retrieved (i.e., if a name is used by one or very few entities). Previously, we introduced four methods based on these hypothesis and have shown that they have comparable performance in terms of both accuracy and efficiency. Here we choose the method based on ‘feature representation size’, which is slightly more balanced.
Given an NE-column, each cell is firstly given a preference score. Then the rows containing these cells are re-ordered based on the descending order of the scores. Since preliminary column classification follows an incremental, iterative procedure using the I-Inf algorithm until convergence, effectively by changing the order of the cells (and rows), a different set of cells could have been processed by the time of convergence (thus a different sample is used). And this possibly results in different classification outcome.
To compute the preference score of each cell, we firstly introduce a ‘one-sense-per-discourse’ hypothesis in the context of a non-subject NE-column. One-sense-per-discourse is a common hypothesis in sense disambiguation. The idea is that a polysemous word appearing multiple times in a well-written discourse is very likely to share the same sense [8]. Though this is widely followed in sense disambiguation in free texts, we argue that it is also common in relational tables: given a non-subject column, cells with identical text are extremely likely to express the same meaning (e.g., same entity or concept). Note that one-sense-per-discourse is more likely to hold in non-subject columns than subject-columns, as the latter may contain cells with identical text content that expresses different meanings. A typical example is the Wikipedia article ‘List of peaks named Bear Mountain’,9

One-sense-per-discourse does not always hold in subject-columns.
The principle of one-sense-per-discourse allows us to treat cells with identical text content as singleton, to build a shared and combined in-table context by including the rows of each cell. As a result, we can create a larger and hence richer feature representation based on the enlarged context. Next, we count the number of features in the feature representation of a cell and use the number as the preference score.
Following Example 2 and assuming that we now need to interpret the non-subject column ‘Director’ (column 3), and the table is complete. By applying the rule of one-sense-per-discourse, we will put the content rows 3, 4 and 7 adjacent to each other, as the target cells (3,3), (4,3) and (7,3) contain identical text ‘Dino Risi’, which we assume to have the same meaning. Then suppose we use the row context of a cell to create a bag-of-words feature representation. The three cells will share the same feature representation, which takes the text content from rows 3, 4 and 7 (excluding the three target cells in question) and applies the bag-of-words transformation. This gives us a bag-of-words representation of 16 features and we use the number 16 as the preference score for the three target cells. We repeat this to other cells in the column, and eventually we re-rank the rows to obtain the table shown in Fig. 6. Another example is shown in Fig. 2 (from data d2 to d3).
Sample ranking result based on the example table. The three ‘Dino Risi’ cells will have the same feature representation based on the row context highlighted within dashed boxes.
Next, with the table rows re-arranged by sample ranking, TableMiner+ proceeds to classify the column using the I-Inf algorithm. Using Algorithm 1, D contains the ranked list of cells from the column where each element d is an individual cell; for a key-value pair the key (k) is a candidate concept for the column, and the value v is the confidence score. The process operation (line 6) performs cold-start disambiguation of a cell to generate candidate concepts and compute their scores (Section 7.2.1); the update operation (line 7) takes the output of cold-start disambiguation from a cell and updates the set of candidate concepts for the entire column (Section 7.2.2). This repeats until convergence.
Cold-start disambiguation
We first retrieve candidate entities for a cell and then disambiguate the cell based on the similarity between the feature representation of the cell and candidate entities.
Candidate entity generation Given a cell, we search its text content
Confidence score of entity Given a candidate entity
To compare
The context of the cell
The overlap between
The overlap between
Then let
The entity name score is measured based on the name of
Finally, an overall confidence score
Candidate concept generation Then the set of candidate concepts associated with the winning entity are collected and added to the set of candidate concepts for the column
Confidence score of concept For each candidate concept, we compute a confidence score based on two components: a
The concept instance score of a candidate concept is the sum of the confidence scores of the winning entities on each row where the winning entities elect the candidate concept:
Given a candidate concept, if the winning entity on every row
The concept context score is computed in the same principle as entity context score ec using Eq. (10), and the function used to calculate an overlap score between
The final confidence score of a candidate concept
Update candidate concepts for the column
Cold-start disambiguation derives a set of candidate concepts from each cell in a column. If a concept
Repetition and convergence
The above processes are repeated in the context of I-Inf until convergence is detected by comparing the set of candidate concepts from the current and previous iterations. The end output of this process is Following Example 3 we continue to classify the ‘Director’ column in the table shown in Fig. 6. Starting from the first cell ‘Dino Risi’, we retrieve candidate entities and compute a confidence score for each. Assuming the winning entity is the Freebase topic ‘fb:/m/0j_nhj’, we then extract its associated concepts and compute confidence score for each concept. Some of the concepts are ‘Film director (fb:/film/director)10 All examples are superficial and adapted based on real data.
Next,
Disambiguation of each new cell generates a set of concepts, of which some can be new while others may already exists in Following Example 4, we use ‘Film writer (fb:/film/writer)’ as constraint to disambiguate the cells in the column. For the four cells already processed in Example 4, we simply re-select from their candidate entities the highest scoring one that is also an instance of this concept. To disambiguate the new cell ‘Nanni Loy’, we only consider candidate entities that are instances of the concept for the column:‘Film writer’. Assuming that the winning entity is ‘fb:/m/02qmpfs’. Then its associated concepts ‘Film writer’, ‘Film director (fb:/film/director)’, ‘Film actor (fb:/film/actor)’ are used to further update the candidate concepts on the column. At the end of the process, it is likely that the highest scoring concept for the column has changed to ‘Film director (fb:/film/director)’.
Once the LEARNING phase is applied to all NE-columns in the table, the UPDATE phase begins to enforce interdependence between classification and disambiguation within each column as well as across different columns. This is done by an iterative optimization process shown in Algorithm 2. Note that our previous work [42] only captures interdependence between classification and disambiguation within each separate column. Here we improve it by also capturing cross-column interdependence with a notion of ‘domain consensus’.
UPDATE
In each iteration, the process starts with creating a bag-of-words representation of the domain using the winning entities from all cells (
The bag-of-words representation of the domain is then used to revise the concept annotations on all NE-columns (
Since the sizes of
Cell annotation revision
For any column, if the new winning concept is different from the that generated in the previous iteration, the disambiguation result on that column is revised (Line 10). This follows the procedure of preliminary cell disambiguation (Section 7.3).
These updating processes are repeated until all annotations are stabilized. Specifically, in each iteration function
Note that re-computing disambiguation and classification may require retrieving data of new entity candidates from the knowledge base and subsequently constructing their feature representation for disambiguation due to the possible change of Following Example 5, assuming we have annotated all NE-columns and their cells (also see d6 in Fig. 2). We begin the UPDATE process by taking the winning entity annotations from columns 1, 3, and 4 in the Table shown in Fig. 6 to create a bag-of-words representation of the domain. Again using the ‘Director’ column, we proceed to compute a domain consensus score for each candidate concept for this column (i.e., ‘Film director’, ‘Film writer’ etc.) and update their confidence scores. The winning concept is re-selected, which we assume is changed to ‘Film director’. This is different from that at the beginning (‘Film writer’). Therefore, we take the new concept and use it to revise cell annotations in the column. We do this for the other two columns and repeat this process until all annotations are no longer changed.
Relation enumeration
Relation enumeration firstly begins by interpreting relations between the subject column and any other columns on each row independently. Let
Then a confidence score is computed for each candidate relation
After the winning relation is computed for each row between
Then a confidence score is computed for each instance
The relation context score is computed in the same way as entity context score using Eq. (10), and the function used to calculate an overlap score between
The final confidence score of a candidate relation adds up its instance and context score with equal weights, and the final binary relation that associates subject column Assuming the entity annotation for cell
Literal-columns are expected to contain attribute data of entities in the subject column. They do not denote entities and therefore, cannot be interpreted using the column interpretation method described above. In previous work [7,21,23–25] they are simply ignored. This work also assigns a column annotation that best describes the attribute data in literal-columns.
Given a literal-column
Experiment settings
Semantic Table Interpretation can be evaluated by both in-vitro (assessing the annotations directly) and in-vivo (assessing the accuracy of applications built on top of the annotations) experiments. In this work, we use in-vitro experiments because (1) they are the most commonly used evaluation approach and (2) standard datasets are available.
Knowledge base and datasets
We use Freebase as the knowledge base for Semantic Table Interpretation, as it is currently the largest knowledge base and linked data set in the world. It contains over 3.1 billion facts about over 58 million topics (e.g., entities, concepts), significantly exceeding other popular knowledge bases such as DBpedia and YAGO. Further it has direct mappings to resources from other datasets, making them easier to be used as gold standard. For evaluation, we compiled and annotated four datasets using Freebase:
Please contact the author on how to obtain, as the dataset is very large. Although Freebase has been closed, this work was however, first submitted in May 2013, at which time the close-down of Freebase was not foreseeable. To enable comparative studies, we also release cached Freebase data for this work. Also the current API on GitHub implements an interface with DBpedia, and a plan is made to migrate relevant software to the Google Knowledge Graph once an appropriate API is available.
These datasets are the rebuilt versions of the original four datasets used by Limaye et al. [21]. The original datasets consist of over 6,000 tables, 94% collected from Wikipedia and the rest from the general Web. Entities in the tables were annotated with links to Wikipedia articles; columns and binary relations between columns were annotated by concepts and relations in the YAGO knowledge base (2008 version).
These datasets are re-created for a number of reasons. First, Wikipedia has undergone significant changes since the publication of the datasets such that a large proportion of the source webpages – as well as the contained tables – have been changed. Second, we notice that the original ground truth for named entity disambiguation were very sparse and possibly biased. As shown in Appendix C, it is less well-balanced than the re-created dataset and a simple exact name match baseline has achieved significantly higher accuracy than the original reported results in Limaye et al. [21]. Third, this work uses a different knowledge base from YAGO, such that the original ground truth cannot be directly used.
Entity ground truth – LimayeAll We run a process to automatically update the webpages in the original dataset and re-annotate entity cells by mapping the original Wikipedia ground truth to Freebase. Details of this process is described in Appendix B.
Column annotation and relation ground truth – Limaye200 To create the ground truth for evaluating column classification and relation enumeration, a random set of 200 tables are drawn from the LimayeAll dataset. These tables are firstly manually examined to identify subject columns, then annotated following a similar process as Venetis et al. [35]. Specifically, TableMiner+ and the baselines (Section 10.3) are run on these tables and the candidate concepts for all table columns and relations between the subject column and other columns in each table are collected and presented to annotators. The annotators mark each label as ‘best’, ‘okay’, or ‘incorrect’. The basic principle is to prefer the most specific concept/relation among all suitable candidates. For example, given a cell ‘Penrith Panthers’, the concept ‘Rugby Club’ is the ‘best’ candidate to label its parent column while ‘Sports Team’ and ‘Organization’ are ‘okay’. The annotators may also insert new labels if none of the candidates are suitable.
IMDB
The IMDB dataset contains over 7,000 tables extracted from a random set of IMDB movie webpages. Each IMDB movie webpage13
E.g.,
The MusicBrainz dataset contains some 1,400 tables extracted from a random set of MusicBrainz record label webpages. Each MusicBrainz record label webpage14
contains a table listing the music released by a production company. Each webpage uses pagination to separate very large tables, and only the first page is downloaded. The table typically has 8 columns, of which one lists music release titles (subject column) and one lists music artists. Each release title or artist has a MusicBrainz id, which can be mapped to a Freebase URI in the same way as for the IMDB dataset. Thus entities in these two columns are annotated in such a way. Then the table columns and binary relations between the subject column and others are also annotated manually following the same procedure as for IMDB and Limaye200.
Statistics of the datasets for evaluation. ‘All’ under ‘Labeled columns’ shows the number of both labeled NE- and literal-columns, while ‘NE’ refers to only NE-columns. Likewise ‘All’ under ‘Labeled relations’ shows the number of labeled relations between subject columns and either NE- or literal columns, while ‘NE’ refers to only relations with NE-columns
Statistics of the datasets for evaluation. ‘All’ under ‘Labeled columns’ shows the number of both labeled NE- and literal-columns, while ‘NE’ refers to only NE-columns. Likewise ‘All’ under ‘Labeled relations’ shows the number of labeled relations between subject columns and either NE- or literal columns, while ‘NE’ refers to only relations with NE-columns

Dataset statistics (min., max. avg. (black diamonds), kth quantile): #r – number of rows; #nec – number of columns containing annotated named entities in ground truth; cl – content cell text length in terms of number of tokens delimited by non-alphanumeric characters.
Comparison against datasets used by state-of-the-art. ‘–’ indicates unknown or not clear
For column classification and relation enumeration, evaluation reports results under both ‘strict’ and ‘tolerant’ mode. To evaluate column classification, the strict mode only considered ‘best’ annotations; while the tolerant mode considers both ‘best’ and ‘okay’ annotations. Evaluating relation enumeration under the strict mode only considers relations between subject column and other columns in a table, and only ‘best’ annotations are included. Under the tolerant mode, in addition to also including ‘okay’ annotations, if TableMiner+ predicts correct relations between non-subject columns or the reversed relation between the subject column and other columns, then each prediction is awarded a score of 0.5.
Moreover, since most state-of-the-art methods have focused on only NE-columns, we report results obtained on NE-columns as well as both NE- and literal-columns for column classification and relation enumeration.
The
Comparative models and configurations
TableMiner+ is evaluated against four baseline methods and two re-implemented state-of-the-art methods. The implementation of all these methods are released on GitHub.15
Each baseline starts with the same subject column detection component, but uses different methods for disambiguating entity cells, classifying columns, and annotating relations between subject column and other columns.
Baseline ‘name match’ B nm firstly disambiguates every cell in an NE-column by retrieving candidate entities from Freebase using the text content in the cell as query, then selecting a single entity: the highest ranked candidate whose name matches exactly the cell text. If no candidates are found to match, the top-ranked candidate is chosen. Freebase adopts a ranking algorithm that reflects both the relevance and popularity of a topic in the knowledge base.
Next, to classify the NE-column with a concept, entities from each cell cast a vote for the concepts they are associated to, and the one receiving the most votes is chosen as the annotation for the column.
Relation enumeration follows a similar procedure. Candidate relations on each row is derived and their scores computed in the same way as TableMiner+ (Section 9.1, Eq. (18)). Then each candidate with a score greater than 0 is selected from the row and considered as a candidate relation for the two columns and casts a vote toward the candidate. The best relations for the two columns are those receiving the most votes.
Literal-columns are annotated the same way as TableMiner+ (Section 9.2).
Baseline ‘similarity-based’ firstly disambiguates every cell in an NE-column, then derives column annotations based on the winning entity from every cell.
For cell disambiguation, we compute a score for each candidate entity as the sum of a simple context score and the string similarity between the name of the candidate and the cell text. The context score is computed using Eq. (9), where x is the row content only.
For column classification, candidate concepts for an NE-column are firstly gathered based on the winning entities from each cell. The final score of a candidate concept consists of two parts: (1) the number of winning entities associated with the concept normalized by the number of rows in the table, and (2) a string similarity score between the concept’s name and the header text (if exists).
For relation enumeration and the annotation of literal-columns, we use the same procedures from the name match baseline B nm .
To compute string similarity, we test three metrics and therefore create three similarity baselines:
The key differences between the four baselines and TableMiner+ are: (1) TableMiner+ uses out-table context while the baselines do not; (2) TableMiner+ adopts a bootstrapping, incremental approach with an iterative, recursive optimization process to enforce interdependence between different annotation tasks. The baselines however, use an exhaustive strategy and are based on very simple interdependence (i.e., both relation enumeration and column classification depend on cell disambiguation).
Re-implementation of state-of-the-art
We re-implemented two state-of-the-art methods and adapted them to Freebase as there are no existing software that can be directly used, and also different knowledge bases have been used in the original work. We choose to implement the methods by Limaye et al. [21] and Mulwad et al. [24], as they are able to address all three annotation tasks in Semantic Table Interpretation. Re-implementation of these methods is not a trivial task. First, the use of different knowledge bases implies that certain features used in the original work are unavailable, must be adapted or replaced. Second, each method has used in-house tools for pre-processing or training. Therefore, our re-implementation has focused on the core inference algorithm in the two methods. We advise readers that the re-implementation is not guaranteed to be an identical replication of the original systems. We describe details of re-implementation in Appendix D, and here we summarize key points. Note that both methods can only deal with NE-columns.
Limaye et al. (Limaye2010) model a table as a factor graph and apply joint inference to solve the three annotation tasks simultaneously. A factor encodes the compatibility between a variable (e.g., a cell) and its candidates (e.g., candidate entities), or between variables believed to be interdependent. In the original work, the compatibility is calculated based on a number of features, the weight of which is learned using a supervised model. Our implementation16
We used Mallet GRMM:
Mulwad et al. model a table using a similar factor graph, then apply a light-weight inference algorithm based on semantic message passing. Their method depends on a pre-process that disambiguates entity cells (i.e., the so-called ‘entity ranker’). This process uses a supervised model built on features that are specific to the knowledge bases used in the original work. We create two models each with a different substitute of the ‘entity ranker’.
The convergence threshold in the I-Inf algorithm is set to 0.0117
This is a rather arbitrary choice that was found to perform reasonably well during development. We did not experiment with different choices extensively.
Different context weight used in different components
Context is assigned a weight of 1.0 if it is considered ‘very important’ or 0.5 otherwise (subjectively decided). For example, in subject column detection, if header words are found in the webpage title or table captions, they are stronger indicators (hence ‘very important’) of subject column than if found in paragraphs that are distant from tables. For column classification and relation enumeration, different types of context are equally weighted because the bag-of-words representations for candidate concepts and relations are based on their names – semantically very important features but can be very sparse therefore any matches are considered a strong signal.
In the four datasets, semantic markups are only available in IMDB and MusicBrainz as the Microdata format. Any2319
All models except Limaye2010 do not require parallelization as they are reasonably fast. Each model is able to run on a server with 4 GB memory. Limaye2010 requires similarity computation between every pair of candidate entity and concept for each column, the amount of which grows quadratically with respect to the size of a table. Thus the running of Limaye2010 is parallelized on 50 threads, each allocated with 4 GB memory.
Results and discussion
Subject column detection
Table 6 shows the precision of predicting subject columns in the Limaye200 and MusicBrainz datasets. The unsupervised subject column detection method achieves a precision of near 96% and 93% on the Limaye200 and MusicBrainz datasets respectively, compared to the reportedly 94–96% precision by a supervised model in Venetis et al. [35], and therein 83% by a baseline that chooses the leftmost column that does not contain numeric data.
Subject column detection results in Precision
Subject column detection results in Precision
Figure 8 shows the convergence statistics in computing the Web search score (ws) in the I-Inf algorithm. The number of tables in which the ws score is calculated20
In cases that only one NE-column is available in a table, this column is simply selected as the subject column.

Convergence statistics (max, min, average (black diamond), kth quantiles) for I-Inf in the calculation of the Web search score for subject column detection. itr – number of iterations (rows processed) until convergence; % – fraction of table rows processed.
Statistics of the slowest convergence in the calculation of the Web search score for subject column detection
Using Limaye200 as an example, Fig. 8 suggests that to compute the ws score, on average, only 4 rows (or less than 35%) are processed, and in 75% of tables no more than 5 rows (or less than 55%) are processed. Table 7 suggests that among all 145 tables that need calculation of ws scores, only 10 tables have all of their rows processed. They have an average of 7.2 rows and none has greater than 20 rows. Then 26.2% of these 145 tables have at least 50% of their rows processed. However, on average they have only 6 rows and none of them have greater than 20 rows. These figures suggest potentially significant improvement in efficiency over an exhaustive approach that computes the ws score using all rows in tables. The figures on the LimayeAll and MusicBrainz datasets suggest even greater savings. Consider that typical Web search APIs are quota-limited and pay-per-use, and it is extremely expensive (if not impossible) to run a local search engine on a reasonable sample of the entire Web. We believe that the I-Inf algorithm delivers substantial benefits in the task of subject column detection.
Manual inspection shows that in most cases the errors fall under several categories. The first is due to duplicate values in subject columns. An extreme example is the disambiguation table discussed before (i.e., ‘List of peaks named Bear Mountain’), in which the subject column contains only a single unique value. The second is caused by long-named entities in subject columns. For example, the subject column in the MusicBrainz tables lists titles of music releases, some of which has a name consisting of more than 10 tokens. This severely penalizes their context match cm and ws scores as it is unlikely to find exact match of their names in table context and search result documents. The third category includes arguable (few) tables that in strict terms, do not necessarily have a subject column. This includes tables listing events, such as lap records of racing car drivers in a particular tournament. In these cases, annotators typically selected the leftmost NE-column.
Against baselines
Tables 8, 9 and 10 compare TableMiner+ against the four baselines in the cell disambiguation, column classification and relation enumeration tasks respectively. The highest figures are marked in
Disambiguation results (F1) on four datasets
Disambiguation results (F1) on four datasets
Classification results (F1) on three datasets
Relation enumeration results (F1) on two datasets
For
Macro-average over all datasets taking into account the size of each dataset.
Its highly competitive performance on the IMDB dataset could be explained by the domain and the method for ranking search results by Freebase. Movie is a highly popular domain representing a fair large proportion of Freebase. Since Freebase Search API promotes popular topics, when a person name is searched it is more likely to obtain movie-related topics as top results than any other domains. Hence by selecting the top result B nm is very likely to succeed.
While although music is also a highly popular domain, B nm could not replicate similar performance. Manual inspection shows that a fair proportion of music titles and artists uses very ambiguous names (e.g., ‘Trouble’, a musical release, ‘Pine’, an artist). In contrast, other baselines perform significantly better by considering row content in tables.
Compared to the baselines, TableMiner+ consistently obtains the best performance. On the most diverse dataset LimayeAll, it improves F1 by between 0.9 and 1.5 points. On the MusicBrainz dataset, it makes little difference from B lev , Bcos, and B dice . By examining the data it is found that the out-table context on MusicBrainz webpages are very sparse. In most cases, the webpage contains only the table. Microdata annotations are also predominantly found inside table structures, which are not used by TableMiner+. On the contrary, the IMDB dataset is completely the opposite: the webpages contain much richer out-table context (including pre-defined Microdata annotations), but little in-table context as the tables have only two columns and neither has column headers. TableMiner+ achieves significant improvement (between 3.9 and 4.6) over baselines on IMDB. This strongly suggests that out-table context serves as useful clues for disambiguating entities in table cells, particularly when in-table context is absent. Further, the Microdata-annotations extracted from these webpages could have been a strong contributor considering that the only difference in out-table context used on LimayeAll and IMDB is that the latter also uses them as features.
For
Also note that the performance by B nm is generally inferior on any dataset. This is due to its inability to promote a single top ranked candidate concept in most cases, or in other words, multiple winning candidates are penalized by the scoring method. Other baselines improve this by also considering the string similarity between candidate concept’s label and table column headers.
Comparison (F1) against the two re-implemented state-of-the-art (NE-columns only). Note that the re-implementation is not guaranteed to be identical to the original works due to reasons such as the use of specific tools, change of knowledge bases and datasets
For
Table 11 shows that TableMiner+ outperforms the re-implemented state-of-the-art models by a large margin in most cases. Surprisingly, models Limaye2010 and Mulwad2013 have underperformed many baselines in most occasions, particularly in the disambiguation task. This may be attributed to two reasons. First, as discussed before, the original work has used knowledge base specific features that are unavailable in Freebase, or supervised processes to optimize features. This has made the adaptation work difficult and although we have made careful attempt to implement alternatives, we cannot guarantee an identical replication of the original methods. Second, we observe that in the cell disambiguation task, both Limaye2010 and Mulwad2013 have only used features that are based on string similarity metrics. Our similarity baselines (B lev , Bcos, B dice ) also use string similarity features but add an important type of feature that proves to be very effective: a context score that compares the bag-of-words representation of candidate entities of a cell against the row context of the cell.
By using the disambiguation component of Table-Miner+, Mulwad2013tm+ made significant improvement over Mulwad2013 on the cell disambiguation and column classification tasks. It also outperforms baselines in several occasions, but still obtained lower accuracy than TableMiner+.
The poor performance of all three models on the column classification task under strict mode is mainly due to the fact that the algorithms empirically favored general concepts (‘Person’) over more specific ones (‘Movie Directors’). Again this could be caused by the lack of a clean, strict concept hierarchy that could be more reliable reference of concept specificity than the alternative features we have to use in Freebase. However, concept hierarchies are not necessarily available in all knowledge bases. Nevertheless, TableMiner+ is able to predict a single best concept candidate in most cases without such knowledge. Additionally, the extremely poor accuracy on the IMDB dataset under the strict mode is largely because all tables in the dataset share the same schema.
We must re-iterate that despite our best effort, the re-implementation is not identical to the original works due to many reasons stated above. Hence following the practice adopted by Mulwad et al. [24], we also compare against state-of-the-art using reported figures in Table 12. As it is shown, TableMiner+ has obtained very competitive results.
Overall, we believe these results are very positive. The rich context model adopted by TableMiner+ – especially the usage of out-table context – enables TableMiner+ to achieve the best performance in all tasks, and significantly outperform both baseline and state-of-the-art methods that ignore out-table contextual features in most cases. In particular, column classification appears to benefit most, suggesting that out-table context provides very useful clues for annotating table columns. The superior performance observed on the IMDB dataset further confirms this, and also shows that existing semantic markups within webpages can be very useful features in this task. Intuitively, when describing table content we tend to focus on the general information rather than specific data in individual table components, which possibly explains the particular contribution by out-table context to the column classification task. Moreover, results on the IMDB dataset also suggest that TableMiner+ can be easily adapted to solve tasks in list structures, which are essentially single column tables without headers.
Efficiency
Table 13 compares the wall-clock hours of Table-Miner+ against B lev on the four datasets, and shows the proportion of time spent by TableMiner+ on data retrieval – including searching for candidate entities and retrieving their data from Freebase or cache. TableMiner+ is shown to be faster than B lev , despite its complicated feature modeling and algorithmic computation.
Wall-clock hours observed for TableMiner+ as savings against the baseline
Wall-clock hours observed for TableMiner+ as savings against the baseline
Candidate entity reduction in disambiguation operations by TableMiner+ compared against exhaustive baseline
TableMiner+ achieves efficiency improvement by using sample-driven column classification and reducing the number of candidates for cell disambiguation, therefore cutting down both the number of data retrieval and feature construction operations. Specifically, it benefits from two design features. First, the one-sense-per-discourse hypothesis ensures that values repeating on multiple cells in non-NE columns are disambiguated collectively costing only one operation. This avoids both repeated data retrieval and feature construction operations for the same set of entity candidates. Whereas classic methods disambiguate these cells individually, costing extra computation. Second, the bootstrapping approach in TableMiner+ reduces the total number of candidate entities by firstly creating preliminary column annotations using a sample instead of the entire column content, then using this outcome to constrain candidate space in entity disambiguation. Table 14 compares the total number of candidate entities processed during disambiguation operations in TableMiner+ against (1) the exhaustive baseline B
lev
, and (2) a ‘would-be exhaustive TableMiner+’ (
Compared against the exhaustive baseline B lev , TableMiner+ reduces the total number of candidate entities to be disambiguated by 10–67%. Note that the smallest improvement on the IMDB dataset is due to (1) the dataset being dominated by very small tables (see Fig. 7 on average less than 15 rows), and as a result, I-Inf in the LEARNING phase does not converge or converges relatively slowly (to be discussed in Appendix E); and (2) one-sense-per-discourse being void since only one column (hence the subject column) is available. Empirically, this translates to the very small improvement in wall-clock time shown in Table 13.
The reduction narrows when compared against exh-TableMiner + , however it still represents a substantial improvement. If we only consider the new cells to be disambiguated after the preliminary column classification phase, in which case the disambiguation candidate space is constrained by the preliminary column annotations (i.e., ‘constrained disambiguation phase’ in Table 14), TableMiner+ improves over exh-TableMiner + by a significant 39–60%.
Number of entity candidates need to be retrieved from Freebase at the UPDATE phase
Furthermore, as mentioned before, one potential issue that may damage TableMiner+’s efficiency is that during the UPDATE phase, new entity candidates can be retrieved and processed, due to the change of winning concepts on a column in each update iteration. In the worst case, the total number of candidates to be retrieved from Freebase equals that in an exhaustive method. However, empirically it is found that this rarely happens. The number of entity candidates to be retrieved from Freebase in the UPDATE phase are shown in Table 15, compared to the total number of new entity candidates retrieved from Freebase by TableMiner+ in all phases. Further, Table 16 shows the number of iterations until stabilization is reached in the UPDATE phase. It suggests that the UPDATE phase stabilizes very fast. Compared to the semantic message passing algorithm in Mulwad et al. [24], at high-level, the iterative UPDATE phase is similar to running semantic message passing on a graph containing two types of variable nodes – column headers and content cells – and one type of factor nodes that model compatibility between the variable nodes. This is a much simpler graph than that used by Mulwad et al., which can fail to converge and empirically a threshold must be used to exit the loop.
Number of iterations until stabilization at the UPDATE phase. 1 itr – fraction of tables on which the UPDATE phase stabilizes after 1 iteration
Wall-clock hours observed for TableMiner+ (1 thread), Mulwad2013 (1 thread), and Limaye2010 (50 threads) when only local cache is used
TableMiner+ uses partial content from a table column to perform preliminary column classification, the outcome of which is used to guide preliminary cell disambiguation. The annotations are then revised by the UPDATE process, which allows evidence from the remaining content from the table to feed back into the annotation process. Hence one question that remains to be answered is whether a Semantic Table Interpretation system that is purely based on partial data can be as good as systems that use the entire table content.
To answer this question we carry out additional experiments that are detailed in Appendix E. First, we drop the UPDATE phase from TableMiner+ to create a model
Results have shown that
Conclusion
This work introduced TableMiner+, a Semantic Table Interpretation method that annotates tabular data for semantic indexing, search and knowledge base population. We have made several contributions to state-of-the-art. First, TableMiner+ uses various context both inside and outside tables as features in Semantic Table Interpretation. This is shown to be particularly useful for improving annotation accuracy. Second, TableMiner+ is able to make inference based on partial content sampled from a table. This is shown to deliver significant efficiency improvement against state-of-the-art methods that exhaustively process the entire table. Third, TableMiner+ offers a comprehensive solution, solving all annotation tasks of Semantic Table Interpretation and deals with both entity and literal columns. And finally, we release the largest collection of datasets as well as the first publicly available software for the task.
Extensive experiments show that TableMiner+ outperforms all baselines and re-implemented (near identical) state-of-the-art methods on any datasets under any settings. On the two most diverse datasets covering multiple domains and different table schemata, it significantly improves over all the other models by up to 42 percentage points. Compared against classic, exhaustive baselines, TableMiner+ reduces empirical wall-clock time by up to 29% and in the column classification task alone, but uses only 55% of table content (as opposed to 100% by exhaustive methods) to classify columns in the two most diverse datasets. It is also significantly faster than the re-implemented methods even when network latency is eliminated by using a local copy of the knowledge base.
TableMiner+ is however, still limited in a number of ways. First, relation enumeration is yet incomplete, as TableMiner+ only handles binary relations between the subject column and other columns. Second, several threshold setting (e.g., I-Inf convergence threshold) and weighting in formulas (e.g., subject column score formula) could be improved by using machine learning techniques to learn optimal configurations from data. Third, TableMiner+ is evaluated using Freebase, and in the general domain. Plans are made to evaluate it with other knowledge bases such as DBpedia and WikiData, as well as adapting to domain specific contexts. We will explore these directions in the future work.
Footnotes
Acknowledgement
Part of this research has been sponsored by the EPSRC funded project LODIE: Linked Open Data for Information Extraction, EP/J019488/1. I am particularly grateful to reviewers and editors for their invaluable time and effort devoted to this work to help improve this article substantially.
Name changes from Zhang [ 41 ]
In the following, we use italic to highlight names adopted in our previous work.
the LEARNING phase – the forward learning phase the UPDATE phase – the backward update phase preliminary annotations/interpretation – initial annotations/interpretation entity context score (ec) – context score ctxe entity name score (en) – name score nm entity confidence score (cf) – final confidence score fse concept instance score (ce) – base score bs concept context score (cc) – context score ctxc concept confidence score (cf) – final confidence score fsc
Recreation of the Limaye datasets
The original Limaye datasets are firstly divided into tables extracted from Wikipedia (wiki-table) and those from the general Web (Web-table). Each wiki-table is re-created based on the live version of Wikipedia. To do so, the corresponding Wikipedia article is downloaded, and tables containing links to other Wikipedia articles (internal links) are extracted. Each newly extracted table is then submitted to a content checking process against the original table. Let
Very large tables in the original datasets are split into smaller ones. The criteria of splitting is unknown. In this case, tables from the original dataset are used.
If no tables are extracted from the new source article or pass the content check, the original table
In some cases, no Wikipedia articles can be found to contain the original table, usually because the article has been deleted. In this case, the original table is kept as-is. Original Web-tables are also kept as-is, since no provenance has been recorded for them.
Thus after re-creating all tables in these datasets, they are re-annotated according to Freebase to create the entity annotation ground truth. Each internal link in a table is firstly searched using the MediaWiki API23
Testing with the original Limaye datasets
In addition to the re-created entity ground truth described above, another version has also been created by only re-annotating entity cells without re-downloading the most recent webpages. Each Wikipedia internal link in the original table ground truth is mapped to a Freebase URI using the MediaWiki API and Freebase using the MQL API, following the procedures discussed in the previous section. To contrast against the new Limaye dataset, this is to be called the original Limaye dataset,
TableMiner+ and the four baselines are tested on this dataset for entity disambiguation and results are shown in Table 18. Surprisingly, the most simplistic baseline B nm obtains the highest accuracy (F1) while TableMiner+ scores the second. Considering the intuition behind B nm this could suggest that LimayeAll-Original is biased toward popular entities. To obtain a better understanding, two types of analysis have been carried out.
First, the dataset statistics of LimayeAll-Original is gathered and compared against LimayeAll, as shown in Table 19. The statistics show that LimayeAll nearly doubled LimayeAll-Original in terms of the number of entity annotations in the ground truth. Further, LimayeAll also has a larger population of short entity names, as measured by the number of tokens in cells. Typically, short names are much more ambiguous than longer names, thus making disambiguation tasks more challenging. Together this could have made LimayeAll a more balanced dataset with much improved level of diversity, increasing the difficulty of the task and possibly offsetting the bias in LimayeAll-Original.
Second, to obtain a more balanced view of the performance of different systems on LimayeAll-Original, the results created by the baselines and TableMiner+ are manually inspected and re-annotated. To do so, a random set of 100 tables are selected from LimayeAll-Original and the output by B nm , B lev and TableMiner+ are collected. The output of Bcos and B dice are not examined since they only differ from B lev in terms of the string similarity metric and the performance of the three systems is not much different. Then for each method, the predicted entity annotations that are already covered by the ground truth in LimayeAll-Original are excluded. Then, in the remaining annotations, those that all three systems predict the same are removed. The remainder are the ones that the three systems ‘disagree’ on, and are manually validated. This resulted in a total of 903 entity annotations, of which 579 is predicted correctly by at least one system. Table 20 shows the precision by the three systems based on this part of data. TableMiner+ significantly outperforms the two baselines. Manual inspection of 20% of the wrong annotations by all three methods shows that it is largely because (over 80%) the knowledge base does not contain the correct candidate. When only annotations that are correct by any one method are considered (‘Precision either-or’), TableMiner+ achieves a precision of 75.1, 35.7 higher than B nm and 32.4 higher than B lev .
Implementation of state-of-the-art
The effect of using samples in TableMiner +
To specifically evaluate the accuracy of annotations using sample data as opposed to an entire table column, four ‘slim’ versions of TableMiner+ are created. Firstly, the UPDATE phase is dropped from the column interpretation component. This creates
Zwicklbauer et al. [46] have shown that a sample size between 10 and 20 rows lead to close-to-maximum performance in column classification.
Mathematical notation lookup table
See Table 25. Continue on the next page.
Mathematical notations in alphabetical order. § – Section, Eq. – Equation, Alg. – Algorithm
Notations
Definition
First defined in
a key-value pair in the I-Inf Algorithm
§5, near Alg. 1
candidate concepts for
§7.2.1, near Eq. (13)
a candidate concept for
§7.2.1, near Eq. (14)
the highest scoring concept for
§7.2.3 beginning
the set of
§5, near Alg. 2
D
a generic dataset used in the I-Inf algorithm
§5, near Alg. 1
a generic data item used in the I-Inf algorithm
§5, near Alg. 1
candidate entities from
§7.2.1 beginning
a candidate entity from
§7.2.1 beginning
the highest scoring entity for
§7.2.1, near Eq. (13)
the set of
§8.1, near Alg. 2
I is the set of row indexes in the sample used by preliminary column classification; i is the index of one row unless otherwise stated
§7.2.1, near Eq. (13)
a webpage, and a set of webpages
§6.2, near Eq. (4)
The title of a webpage in the results returned by a search engine
§6.2, near Eq. (5)
The snippet of a webpage in the results returned by a search engine
§6.2, near Eq. (5)
candidate relations between two columns
§9.1, near Eq. (19)
candidate relations between two columns collected from row i
§9.1 beginning
a candidate relation between two columns
§9.1, near Eq. (19)
a candidate relation between two columns collected from row i
§9.1, near Eq. (18)
the highest scoring candidate relation between two columns collected from row i
§9.1, near Eq. (19)
the set of
a table row
§6.2, near Eq. (4)
a table column
§6.1 beginning
a table cell
§6.2, near Eq. (4)
w
a single word
§6.2, near Eq. (3)
x denotes a particular type of context (e.g., header text, paragraphs). X denotes the set of all types of contexts
§6.2, near Eq. (3)
§9.1, near Eq. (18)
Functions
Definition
Used in equations
returns a bag-of-words (multiset) of an object, applying morphological normalization and stop words removal
Eqs (3), (6), (8), (9), (12), (16)
returns the set of unique tokens in
Eqs (6), (8), (9), (11)
concept context score of
Eq. (15)
concept instance score of
Eqs (14), (15)
overall confidence score of
Eq. (15)
overall confidence score of
Eqs (12), (13), (14)
overall confidence score of a relation (on a particular row or between two columns in general)
Eqs (18), (20)
returns the concepts associated with
Eqs (13), (14)
component function of the Web search score
Eqs (4), (5)
component function of the Web search score
Eqs (4), (6)
measures overlap between
Eq. (9)
domain consensus score of
Eq. (17)
a special bag-of-words representation of
Eq. (16)
frequency weighted dice function measuring overlap between two objects
Eqs (8), (17), (18)
entity context score of
Eqs (10), (12)
entity name score of
Eqs (11), (12)
entropy of iteration i computed in the I-Inf algorithm
Eq. (1)
returns the frequency of w in
Eqs (3), (5), (6), (8), (9)
returns the ‘name’ or ‘label’ of an object
Eqs (4), (5)
returns the object of triple
Eq. (18)
generalized function to denote either
Eq. (10)
returns the predicate of triple
Eq. (18)
relation instance score of
Eq. (20)
returns a score of the degree to which
Eq. (7)
weight assigned to a feature
Eqs (3), (10)