
Abstract
There is a growing need to perform real-time analytics on dynamic graphs in order to deliver the values of big data to users. An important problem from such applications is continuously identifying and monitoring critical patterns when fine-grained updates at a high velocity occur on the graphs. A lot of efforts have been made to develop practical solutions for these problems. Despite the efforts, existing algorithms showed limited running time and scalability in dealing with large and/or many graphs. In this paper, we study the problem of continuous multi-query optimization for subgraph matching over dynamic graph data. (1) We propose annotated query graph, which is obtained by merging the multi-queries into one. (2) Based on the annotated query, we employ a concise auxiliary data structure to represent partial solutions in a compact form. (3) In addition, we propose an efficient maintenance strategy to detect the affected queries for each update and report corresponding matches in one pass. (4) Extensive experiments over real-life and synthetic datasets verify the effectiveness and efficiency of our approach and confirm a two orders of magnitude improvement of the proposed solution.
Introduction
Dynamic graphs emerge in different domains, such as financial transaction network, mobile communication network, data center network [20–22], uncertain network [2], etc. These graphs usually contain a very large number of vertices with different attributes, and have complex relationships among vertices. In addition, these graphs are highly dynamic with frequent updates of edge insertions and deletions.
Identifying and monitoring critical patterns in a dynamic graph is important in various application domains [8] such as fraud detection, cyber security, and emergency response, etc. For example, cyber security applications should detect cyber intrusions and attacks in computer network traffic as soon as they appear in the data graph [3]. In order to identify and monitor such patterns, existing work [3,13,15] studies the continuous subgraph matching problem that focuses on a-query-at-a-time. Given an initial graph G, a graph update stream
Figure 1 shows an example of continuous subgraph matching. Given a query pattern Q as show in Fig. 1(a), and an initial graph G with an edge insertion operation

An example of continuous subgraph matching.
However, these applications deal with dynamic graphs in such a setup that is often essential to be able to support hundreds or thousands of continuous queries simultaneously. Optimizing and answering each query separately over the dynamic graph is not always the most efficient. Zervakis et al. [30] first propose a continuous multi-query process engine, namely,
These problems of existing methods motivated us to develop a novel concept of annotated query graph (
In summary, our
We propose an efficient continuous multi-query matching system,
We define annotated query graph, in which corresponding matching results can be obtained in one pass instead of multiple.
We construct a newly data-centric auxiliary data structure based on the equivalent query tree of the annotated query graph to represent the partial solution in a compact form.
We propose an incremental maintenance strategy to efficiently maintain the intermediate results in
We experimentally evaluate the proposed solution using three different datasets, and compare the performance against the three baselines. The experiment results show that our solution can achieve up to two orders of magnitude improvement in query processing time against the sequential processing strategy.
In this section, we first introduce several essential notions and formalize the continuous multi-query processing over dynamic graphs problem. Then, we overview the proposed solution.
Preliminaries
We focus on a labeled undirected graph
(Graph Update Stream).
A graph update stream
A
(Subgraph homomorphism).
Given a query graph
Since subgraph isomorphism can be obtained by just checking the injective constraint [15], we use the subgraph homomorphism as our default matching semantics. Note that we omit edge labels for ease of explanation, while the actual implementation of our solution and our experiments support edge labels.
Based on the above definitions, let us now define the problem of multi-query processing over dynamic graphs.
Problem statement Given a set of query graphs
Overview of solution
In this subsection, we overview the proposed solution, which is referred to as Representation of intermediate results should be compact and can be used to calculate the corresponding matches of affected queries in one pass. Update operation needs to be efficient such that the intermediate results can be maintained incrementally to quickly detect the affected queries.
The former challenge corresponds to Continuous Multi-query Processing Model, while the latter corresponds to Continuous Multi-Query Evaluation Phase.
Algorithm 1 shows the outline of

When an edge update occurs, it is costly to conduct sequential query processing. The central idea of multi-query handling is to employ a delicate data structure, which can be used to compute matches of affected queries in one pass.
Annotated query graph
Different from the work proposed in [30] that decomposes queries into covering paths and handles updates by finding affected paths, we provide a novel concept of annotated query graph, namely,
The queries in Fig. 2(a) are overlaped and can be merged into an annotated
Note that, there exists a case that the queries in the

Annotated query graph.
Since continuous multi-query processing is triggered by each update operation on the data graph, it is more useful to maintain some intermediate results for each vertex in the data graph as
The
Note that since we will transform all edges of
For each vertex

Example of constructing
Let
Consider the edge
Based on
Note that we do not store
Figure 3(c) gives the
We rely on an incremental maintain strategy to efficiently maintain
Incremental maintenance of intermediate results
We propose an edge state transition model to efficiently identify which update operation can affect the current intermediate results and/or contribute to positive/negative matches for each affected query. The edge state transition model consists of three states and six transition rules, which demonstrates how one state is transited to another.

Maintenance strategy.
Handing edge insertion When an edge insertion
Figure 4(b)–(c) give the example of edge transition rule from
Figure 4(d)–(e) give the example of edge transition rule from
Handing edge deletion When an edge deletion
Figure 4(f) gives the example of edge transition rule from
Figure 4(g)–(h) give the example of edge transition rule from
If the state of an edge
In order to calculate the matching order,
Intuitively,
In the next stage,

As show in Fig. 3(d), the state of edge insertion
In this section, we present detailed algorithms for
MDCG construction
In this subsection, we explain
The time complexity of
In the worst case,

Note that not all the insertion edge

Here,
In this section, we perform extensive experiments on both real and synthetic datasets to show the performance of
Datasets and query generation
In order to construct the set of query graph patterns
Our method, denoted as
We measure and evaluate (1) the elapsed time and the size of intermediate results for
Evaluating the efficiency of IncMQO
In this subsection, we evaluated the performance of
Time efficiency comparison Fig. 5(1) shows the total processing time of
Space efficiency comparison Fig. 5(2) shows the size of intermediate results on each dataset. We only evaluate the
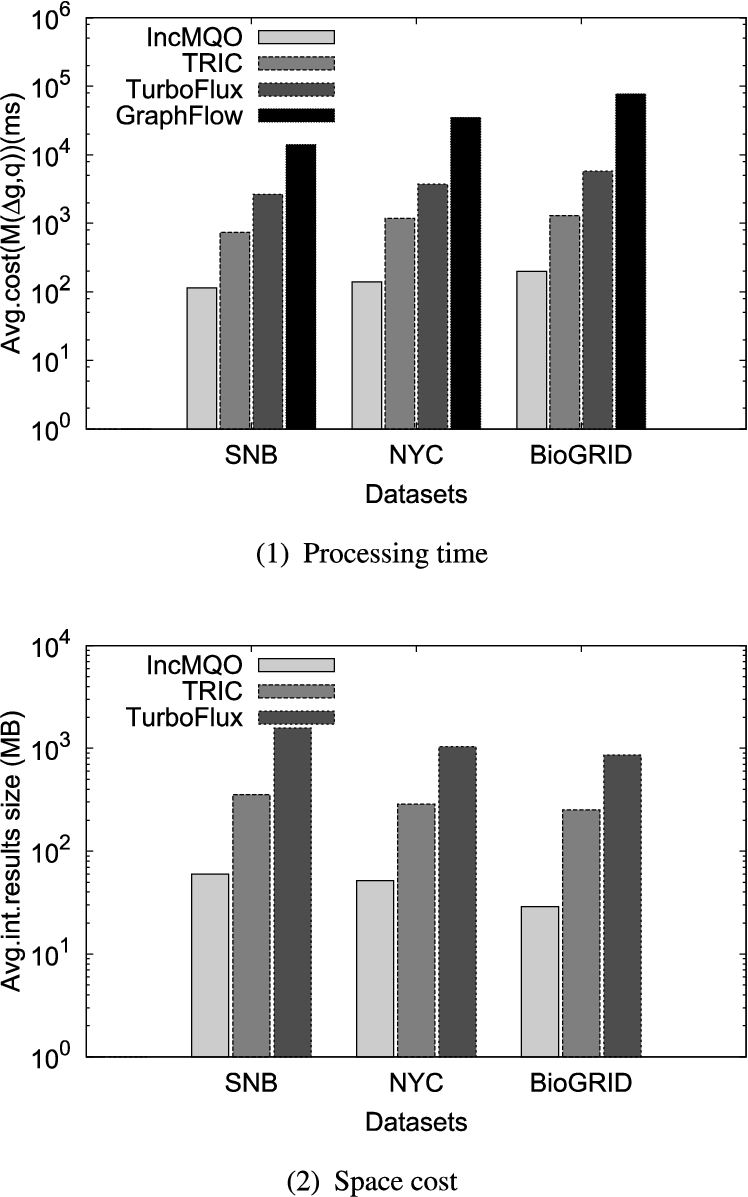
Performance on SNB1M, NYC and BioGRID.

Performance of varying the percentage of query overlap.
In Fig. 6(1) we give the results of the time efficiency evaluation when varying the parameter θ, for

Performance of varying the average query size.
In this subsection, we evaluate the impact of the average query size in

Performance of varying query database size.
In this subsection, we evaluate the impact of the size of query database on the performance of

Performance of varying the edge insertion size.
Figure 9(1)–(2) show the performance results using SNB1M for varying edge insertion size. Here, we vary the number of newly-inserted edges from

Performance of varying the edge deletion size.
Figure 10(1)–(2) show the performance results using SNB1M for varying edge deletion size. Here, we vary the number of expired edges from
Varying dataset size
Figure 11(1)–(2) show the performance results using SNB for varying dataset size. Here, we fixed

Performance of varying dataset size.
In this set of experiments, we evaluate the performance of different matching orderings on SNB1M dataset. We compare our proposed matching order with that proposed in

Comparison of different matching orders.
In this set of experiments, we evaluate the performance of single query to text the efficiency when there is no common components in the query set

Performance evaluation of single query.
In this subsection, we further compare the incremental algorithm (

Results of the comparison.
We categorize the related work as follows.
Subgraph isomorphism research Subgraph isomorphism research is a fundamental requirement for graph databases and has been widely used in many fields. While this problem is NP-hard, in recent years, many algorithm have been proposed to solve it in a reasonable time for real datasets, such as VF2 [4], GraphQL [11], TurBOiSO [10], QuickSI [26]. Most all these algorithms follow the framework of Ullmann [28], with some pruning strategies, heuristic matching order algorithm and auxiliary neighborhood information to improve the performance of subgraph matching search. Lee et al. [17] compared these subgraph isomorphism algorithms in a common code base and gave in-depth analysis. However, these techniques are designed for static graphs and are not suitable for processing continuous graph queries on evolving graphs.
Multiple query optimization for relational database Multiple query optimization (MQO) has been well studied in relational databases [24,25]. Most work on relational database extend existing cost model based on statistics, and search for a global optimal access plan among all possible access plan combinations for each single query. Meanwhile, some intermediate access plan can be shared to accelerate multi-query evaluation. However, these relational MQO methods cannot be directly used for subgraph homomorphism search of MQO, because we do not assume that statistics or indexes exist on the data graph, and some relational optimization strategies (such as push selection and projection) are not suitable for subgraph homomorphism search. In addition, the methods of identifying common relation subexpression [7] are also difficult or inefficient for graph-based multi-query evaluation since it is inefficient to evaluate graph pattern queries by converting them into relational queries [11].
One-time multiple query evaluation Le et al. [16] studied the problem of evaluating SPARQL one-time multiple queries (SPARQL-MQO) over RDF graphs. Given a batch of graph queries, it clustered the graph queries into disjoint finer groups and then rewrote the patterns into a single query common pattern graph for each group. However, its clustering technique (and selectivity information) becomes degenerate and the construction of query sets ignores the cyclic structures in queries. Subsequently, Ren et al. [23] extended one-time multiple queries for an undirected labeled graph. It organized the useful common subgraphs and the original queries in a data structure called pattern containment map (PCM), and then it further cached the intermediate results based on PCM to balance memory usage and the execution time. Note that, PCM was designed for static graph. When using it in dynamic graph, we need reconstruct PCM for each update operation, which is practically infeasible. In contrast, our proposed
Continuous query process Continuous query process has first been considered in [29] which means continuously monitoring a set of graph streams and reporting the appearances of a set of pattern graphs in a set of graph streams at each timestamp [3,14]. But it offered an approximate answer instead of using subgraph isomorphism verification to find the exact query answers. In the latter study, Fan et al. [6] proposed the concept of incremental subgraph matching to handle continuous query problem. It only executed subgraph matching over the updated part, avoiding recomputing from scratch. In addition, Gillani et al. [9] proposed continuous graph pattern matching over knowledge graph streams and used two different executional models with an automata-based model to guide the searching process. Kim et al. [15] proposed a novel data-centric presentation to process continuous subgraph matching. However, all of the above algorithms evaluate each query separately and cannot be directly used for multi-query problem.
Continuous multiple query evaluation In addition, there are some researches on the topic of continuous multiple queries evaluation. Pugliese et al. [19] studied maintaining multiple subgraph query views under single-edge insertion workloads. It took advantage of common substructures and used an optimal merge strategy. However, it only focused on insertion. But in the real world, deletions also occur. Kankanamge et al. [12] studied the problem of optimizing and evaluating multiple subgraph queries continuously in a changing graph. It decomposed all the queries into multiple delta queries, which were then evaluated one query vertex at a time, without requiring any auxiliary data structures. Mhedhbi et al. [18] optimized both one-time and continuous subgraph queries using worst-case optimal joins. Since the methods in literatures [12] and [18] did not store any intermediate results, they needed to evaluate subgraph matching for each update, even if the update did not generate any positive/negative match. In recently, Zervakis et al. [30] handled the continuous multi-query problem over graph streams via decomposing the query into covering paths, and then it constructed a tree-based data structure to indexing and clustering continuous graph queries. However, this data structure is not concise enough, leading to many expensive join operations. Compared to covering paths, our proposed
Conclusion and further work
In this paper, we proposed an efficient continuous multi-query processing engine, namely,
A couple of issues need further study. We only simply consider the scenario that all the queries have been given at the start. However, the queries set will actually be updated due to users’ demands. To this end, we are going to consider this scenario in the future work and design an efficient algorithm to deal with the updates of queries set in multiple queries processing over dynamic graph.
Footnotes
Acknowledgement
This work is partially supported by National key research and development program under Grant Nos. 2018YFB1800203, Tianjin Science and Technology Foundation under Grant No. 18ZXJMTG00290, National Natural Science Foundation of China under Grant No. 61872446, and National Natural Science Foundation of Hunan Province under grant No. 2019JJ20024.