
Abstract
Due to the massive memory and computational resources required to build complex machine learning models on large datasets, many researchers are employing distributed environments for training the models on large datasets. The parallel implementations of Extreme Learning Machine (ELM) with many variants have been developed using MapReduce and Spark frameworks in the recent years. However, these approaches have severe limitations in terms of Input-Output (I/O) cost, memory, etc. From the literature, it is known that the complexity of ELM is directly propositional to the computation of Moore-Penrose pseudo inverse of hidden layer matrix in ELM. Most of the ELM variants developed on Spark framework have employed Singular Value Decomposition (SVD) to compute the Moore-Penrose pseudo inverse. But, SVD has severe memory limitations when experimenting with large datasets. In this paper, a method that uses Recursive Block LU Decomposition to compute the Moore-Penrose generalized inverse over the Spark cluster has been proposed to reduce the computational complexity. This method enhances the ELM algorithm to be efficient in handling the scalability and also having faster execution of the model. The experimental results have shown that the proposed method is efficient than the existing algorithms available in the literature.
Keywords
Introduction
Nowadays, humongous data is being generated through diversified data generating sources at an ever-increasing rate [2]. The size and dimensionality of these datasets are increasing day by day. So, it is a challenging task to develop efficient and effective machine learning algorithms that are useful in analyzing and extracting valuable knowledge from the massive amount of data. Over the past few decades, many machine learning algorithms have been developed for processing complex and massive datasets to provide valuable insights [6]. In addition to that, recent big data frameworks provided efficient mechanisms to process and model a massive amount of data to get actionable insights. At this juncture, it is indispensable to exploit distributed computing environment efficiently and effectively to model such humongous data [23]. Distributed learning based on the divide-and-conquer approach is used significantly in many frameworks for processing the humongous data, which includes three primary steps [23] Partitioning the original dataset into sub-datasets. distribute the sub-datasets to local machines in a network and learn a predictor from each sub-dataset. Synthesize the global predictor from these local predictors
Developing a classification problem in distributed computing environment is one of the most challenging problems in this big data era. Over the past few decades, machine learning algorithms have been developed for processing complex and massive datasets to get valuable insights. However, the primary requirement is that they should model the complex decision boundaries with less computational resources and time. One of the most popular machine learning algorithms is an Artificial Neural Network (ANN), which has been widely used in various fields. Neural network architectures have gone through many generations from the perceptron to the most recent deep network architectures. In recent years, Extreme Learning Machine (ELM) became most popular since it provides fast training time and having a lesser number of hyper-parameters to be tuned when compared to other neural networks [4]. However, there are many shortcomings of ELM that have been addressed in the literature to improve the performance of ELM. Nevertheless, a major problem i.e. memory consumption while dealing with large datasets has not been addressed extensively in the literature. This problem arises because ELM is a batch processing algorithm that expects all the data in memory to compute the pseudo inverse. So, memory limitation problem became a major bottleneck to use ELM for large datasets.
Heeswijk et al. [14] proposed GPU based parallel ELM ensemble method for large scale regression problems. The author focused on the training phase of ELM only. Sun et al. [26] proposed a parallel ensemble ELM classifier based on OS-ELM. These approaches are developed to process large data by selecting proper ELM model network architecture. Qing He et al. [16] proposed the first parallel ELM (PELM) for regression on MapReduce to process large datasets. In this approach, the author proposes a method that uses a chain of mapper and reducer jobs. So, this approach consumes more time, because it stores data in the disk for every phase. Xin et al. [8, 9] proposed an enhanced approach to PELM that uses single MapReduce job and reduces transfer time. Another variant of PELM is DELM [3], which uses blocks instead of specifying the rows and columns of a hidden layer output matrix. Due to this, the intermediate transmission of data during the shuffling phase has reduced. Some more variants of MapReduce based ELM are PEOS-ELM [22], BPOS-ELM [21], where all of them require many copies of each task and have more disk I/O overhead. To avoid the overhead of disk I/O, ELM based on Apache Spark distributed framework has been proposed by a few researchers. Duan et al. [11] proposed an ELM model on Apache Spark distribution without using the SVD method. The author used the standard matrix multiplication procedure to compute the Moore-Penrose pseudoinverse, whereas matrix multiplication is one of the heavy computational tasks in Apache Spark. Kozik, Rafal [17] developed ELM on Apache Spark using SVD decomposition. In this approach, the author computed the Gramian matrix for hidden layer output matrix and right singular values and then multiplied these right singular vectors with the target vector. The author used the Gramian matrix to avoid the computational cost of SVD for the tall and skinny behaviour of the hidden layer output matrix.
SVD based ELM on Apache Spark has memory limitations [1, 17]. In this paper, an efficient Moore-Penrose pseudo inverse computation using Block Recursive LU Decomposition [7] method is discussed to provide scalable ELM and solve the memory limitation. To avoid the numerical instability problem in LU factorization, a partial pivoting approach is used, and the discussion of this method is available in the methodology section.
This paper is organized as follows: Section 2 outlines the basic details of ELM and Apache Spark; Section 3 provides the methodology employed in this work; Section 4 describes the experimental results; finally, Section 5 provides the result analysis and conclusion.
Preview of ELM and Apache Spark
This section presents the ELM procedure along with mathematical representations and Distributed matrix representation with its computational challenges in Apache Spark Framework.
Mathematical Description of ELM
ELM is a variant of Single-hidden Layer Feedforward Neural networks (SLFNs) based on the notion that the classifier can achieve excellent generalization performance at extremely faster learning speed even if the input-to-hidden layer weights and biases are randomly chosen and not updated during the training process [5]. In addition to this, the hidden-to-output layer weights are determined analytically. G.B. Huang et al. [5] have shown the theoretical results in such a way that ELM can be a universal approximator with a wide variety of activation functions. The main concern of ELM is to avoid gradient-based iterative learning and laborious hyper-parameter tuning, which is a major bottleneck for general SLFN. Fig. 1 shows the architecture of ELM with one input layer, one hidden layer, and output layer.
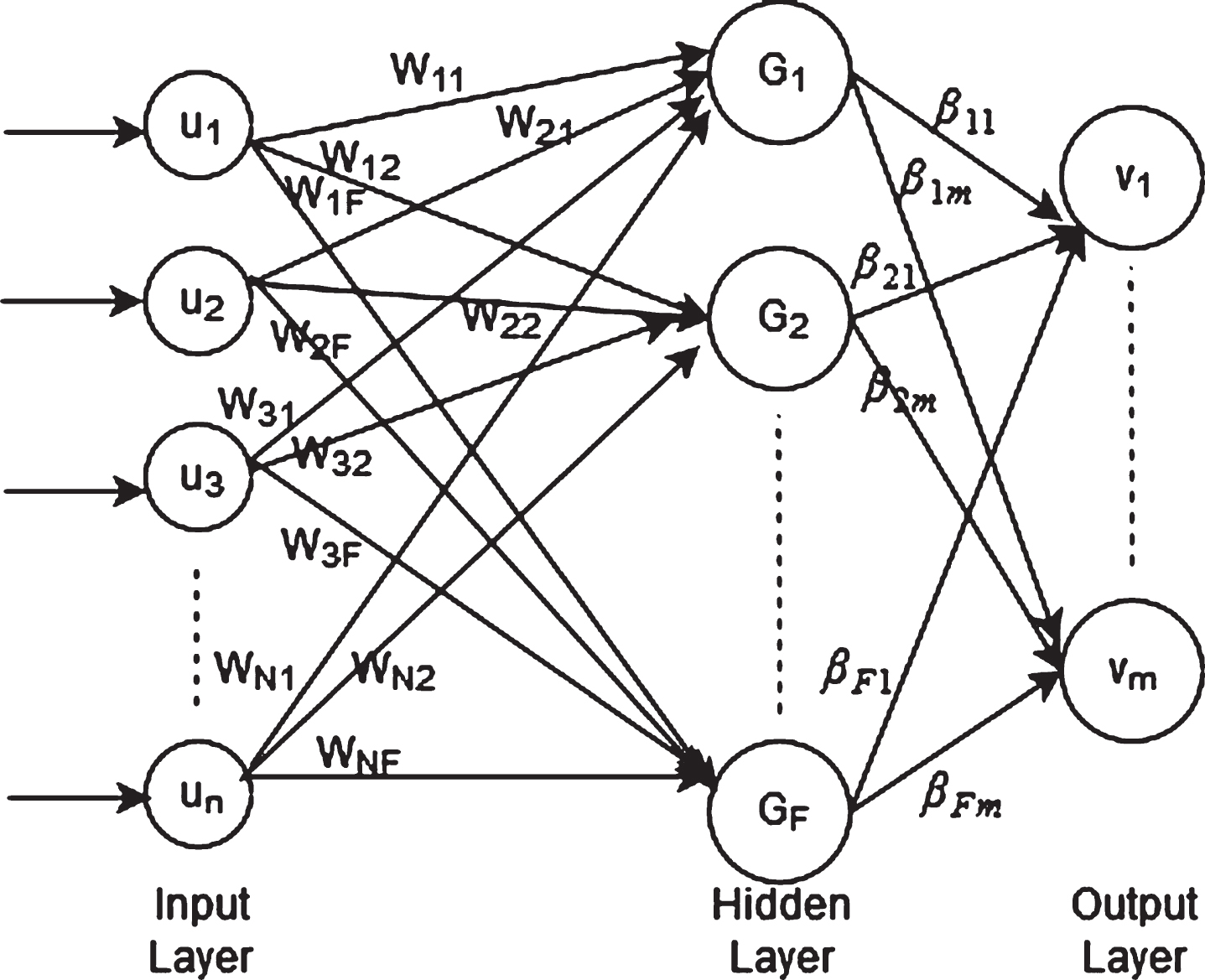
Basic architecture of ELM.
The training procedure of the ELM algorithm is described with the help of the flowchart in Fig. 2. The Moore-Penrose generalized inverse can be calculated using the following equations.

The Flowchart of the ELM.
MapReduce framework offers scalability, fault tolerance, load-balancing using distributed computing in both homogeneous and heterogeneous environments to handle large datasets. Even though it is one of the popular frameworks that use data parallelism to handle large datasets, the problems such as data replication, disk I/O communication cost, serialization, etc., have not been dealt in an efficient way. The MapReduce framework does not have elegant ways to control the iterations in iterative algorithm implementation. During the process of iteration-to-iteration, unnecessary scheduling overhead, data reloading, and reprocessing for every iteration cause wastage of resources. It uses a coarse-grained procedure to tackle such tasks, which are too heavy-weight for many of the machine learning tasks. Also, the MapReduce framework does not have control over the total pipeline of the map and reduce steps, so it cannot cache the intermediate results for faster performance. For example, the training of the neural network is an iterative procedure that involves matrix multiplications. Yang Liu et al. [25] studied the MapReduce implementation of Neural Network and concluded that it incurs a high overhead of computation due to the continuous starting and stopping of mappers and reducers in Hadoop environment. Hence, Apache Spark distributed framework for the implementation of ELM is used in this proposed methodology. The Apache spark has the following potential features to support matrix operations and iterative algorithms: The Apache spark operates on storage abstraction called Resilient Distributed Dataset (RDD) [13]. It consists of the number of deterministic coarse-grained operations and also provides an easy-to-use interface to users. RDDs permit user-defined data partitioning and hence, the execution engine can exploit this to co-partition RDDs and co-schedule tasks to avoid data movement [13]. To achieve fault tolerance efficiently, RDDs provide a restricted form of shared memory based on coarse-grained transformations rather than fine-grained updates to a shared state [13]. Spark has robust high-level operators in the form of actions and transformations for processing of the data in an easy and simple way, unlike MapReduce, which has very few operators and required low-level API to process.
Distributed matrix representation and computational challenges
Since ELM involves matrix operations to compute pseudo-inverse, it requires effective approaches to operate on distributed matrix representation to deploy in the cluster environment. The distributed matrix data representation, hardware-specific acceleration for matrix computation, and interaction of local matrix with distributed matrix in matrix computation are the typical challenges in a distributed computing environment [19]. In Apache Spark, the distributed matrix is partitioned into fixed-size blocks, which are represented by RDD. Usually, the fixed-size blocks are small and square. Fixed-size square blocks are useful to simplify many operations like transpose, etc.
Fig. 3(A), and Fig. 3(B) shows an example of the logical representation of a distributed matrix and physical RDD partitions with hash partitioning [12]. RowMatrix, IndexedRowMatrix CoordinateMatrix and BlockMatrix are matrix layouts used in Apache spark to represent the data of the distributed matrix. The total time required for basic computational operations on these layouts and I/O cost on distributed data-parallel jobs are the key factors to specify the large-scale matrix multiplication execution [18]. For example, computational operations such as small matrix multiplying with large matrix and multiplying two large matrices are two cases in the distributed matrix. In general, the BroadcastMM approach along with the RowMatrix layout is used to perform the large matrix multiplications in an efficient way. The RowMatrix is used to store row elements of Matrix in RDD form. The rows are represented by local vectors [27]. Hence, there is a limitation in the number of columns and also, it is not supported for large matrices. Due to this reason, BlockMatrix representation in Apache Spark is useful to represent the large matrices, whereas it stores the sub-matrix blocks in RDD form [27]. In addition to this, the execution strategy for large-scale matrix multiplication depends upon the scheduled execution workflow of the blocked sub-matrices on Apache Spark Environment [18]. In these execution strategies, the Replication-based Matrix Multiplication (RMM) and Cross-Product Matrix Multiplication (CPMM) are the most important on parallel computing platforms. The RMM execution strategy for matrix multiplication has been used in Apache Spark MLlib. So, R. Gu et al. [18] have adapted the RMM based execution strategy already available in Spark MLlib. Fig. 4 describes the RMM based execution strategy of matrix multiplication on Spark [18].
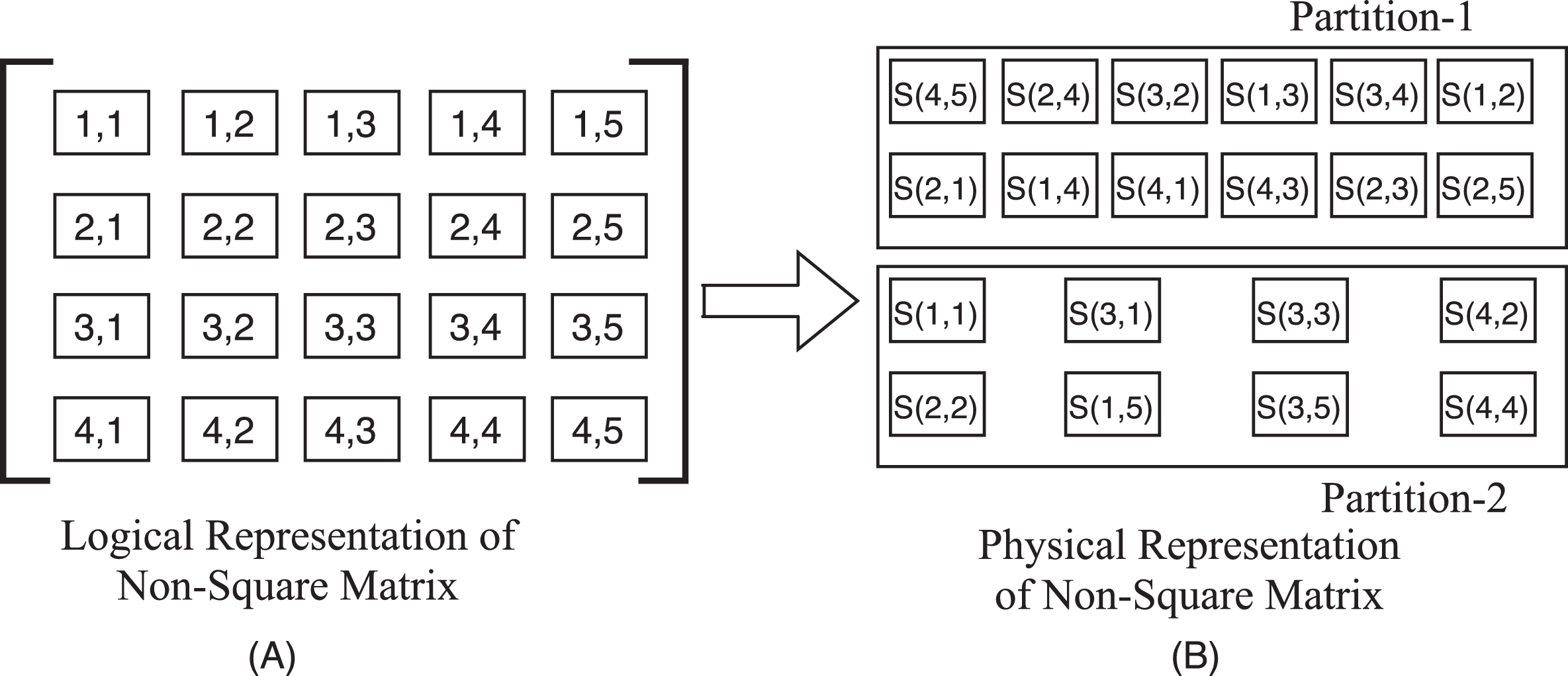
Distributed Matrix Representation: (A) Logical Representation (B) Physical Representation.
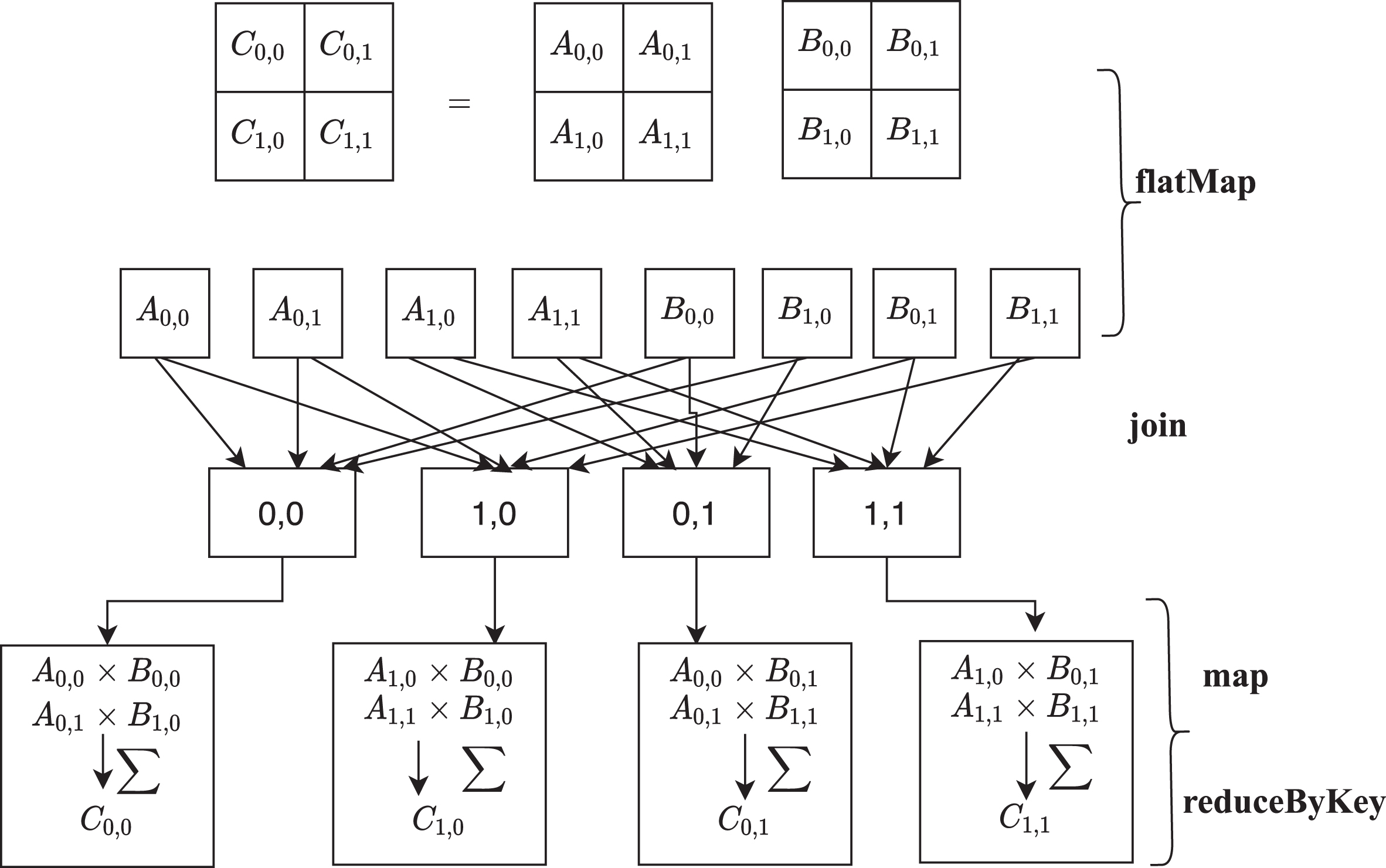
RMM based execution strategy of Matrix Multiplication on distributed environment.
In this work, Block Recursive LU Decomposition technique has been proposed to compute the Moore-Penrose pseudo-inverse of the large matrix in Apache spark distributed environment. Y. Kutlu et al. [24] proposed LU decomposition-based ELM on conventional environment and produced efficient results compared with basic ELM. The author experimented with Gaussian elimination with standard backward substitution to compute L (Lower triangular matrix) and U (Upper triangular matrix) in ELM. But this methodology is prone to numerical instability [10, 29] because this method breaks down if the elements in the principle diagonal matrix is zero. So it needs a systematic method to select the proper non-zero pivots during each iteration of the Gauss elimination process. The elements which are at the super-diagonal of a Lower triangular matrix are called pivots. LU Decomposition with partial pivoting method ensures that non-zero pivots in gauss elimination procedure and produce the results with less complexity compared to other methods such as small pivoting based LU Decomposition, complete pivoting based LU, etc [28]. By taking this into account, Recursive Block LU Decomposition with partial pivoting is employed in the present work.
The Moore-Penrose pseudo-inverse of the hidden layer activation matrix (G) is specified as G† = (G T G) -1G T . Here, G T G is a symmetric and square matrix. In the previous works, SVD is performed using eigenvalue decomposition-based approach to find the inverse, which takes more computational time and resources. In addition to this limitation, SVD has memory limitation if the dimensionality of the matrix is crossing 104 [20]. In this regard, block-recursive LU decomposition is an efficient strategy to compute (G T G) -1 than the SVD based decomposition used in the literature. The inverse found using block-recursive LU decomposition is then multiplied with G T to get the Moore-Penrose pseudo-inverse of the hidden layer activation matrix. Here, the G matrix is distributed over the cluster using the BlockMatrix method.
Every node in the cluster is used to compute the basic LU Decomposition of the distributed matrix. The implementation of Recursive Block LU Decomposition depends on two major tasks. The first task is to divide the matrix into sub-matrices, which are suitable for the distributed matrix. The second task is to collect the results of the small distributed matrix from all nodes in the cluster. However, the communication overhead is small in the present approach because Spark uses in-memory computation. The space complexity of recursive block LU decomposition takes
In the present work, BlockMatrix is used to store a large matrix in terms of sub-matrices (block) in a distributed fashion which is known to be efficient for large datasets [27]. In order to show the superiority of BlockMatrix in comparison with RowMatrix representation a detailed experiment analysis has been conducted. In the experimental study, the computational time required to perform the matrix multiplication is considered as the key metric. The time required to compute a matrix multiplication of large dimensional square matrices on pseudo-mode and multi-node cluster mode has been observed experimentally. The large matrices used in these experiments have been generated randomly for the comparison purpose. The data elements of each matrix are generated randomly in a range [1,100].
Fig. 5 shows the comparative results of RowMatrix, IndexedRowMatrix, CoordinateMatrix, and BlockMatrix data structure based matrix multiplication in pseudo-mode Apache spark. The pseudo-mode was setup on Lenovo ThinkPad with I5 processor and 8GB RAM. In the Fig. 5, the dot product of the matrix is also considered. There was a fatal memory error when performing the standard dot product method for the matrix multiplication when the matrix dimension crosses 4000. But, the data structure provided by Apache Spark has been able to compute matrix product even the matrix dimension crosses 4000. The experimental results showed that the computational time required for matrix multiplication based on RowMatrix, IndexedRowMatrix, and CoordinateMatrix has been increasing, whereas the BlockMatrix based matrix multiplication is consuming less time when compared to them. Another important observation from these experiments is that the heap memory is playing a vital role because the intermediate results of matrix multiplication need a lot of memory space. In this experimental setup, the primary heap memory size 512M is considered. Few experiments have also been carried out by increasing heap memory. The observation from these experiments showed that the computational time of matrix multiplication decreases as the heap memory size increases.

Average computational time of matrix multiplication operation using distributed matrix representations in pseudo-mode cluster of Apache Spark.
Fig. 6 shows the average computational time needed to perform the RowMatrix, IndexedRowMatrix, CoordinateMatrix, and BlockMatrix based matrix multiplication in a cluster. The extensive experiments have conducted on a multinode cluster. The multinode cluster has three slaves and one master node. Each node in the multinode cluster has 32GB RAM, 1TB hard disk, and 6.5GB heap memory. In this experimental setup, the average time required to compute the matrix multiplication is considered after performing 15 trails on the corresponding dataset. The time required to perform the matrix multiplication is included the communication overhead of the cluster. Even in the multinode cluster, BlockMatrix based matrix multiplication performed well compared to other data structures. In accordance with the results, BlockMatrix representation is used to represent the large dimension matrices in the proposed work.
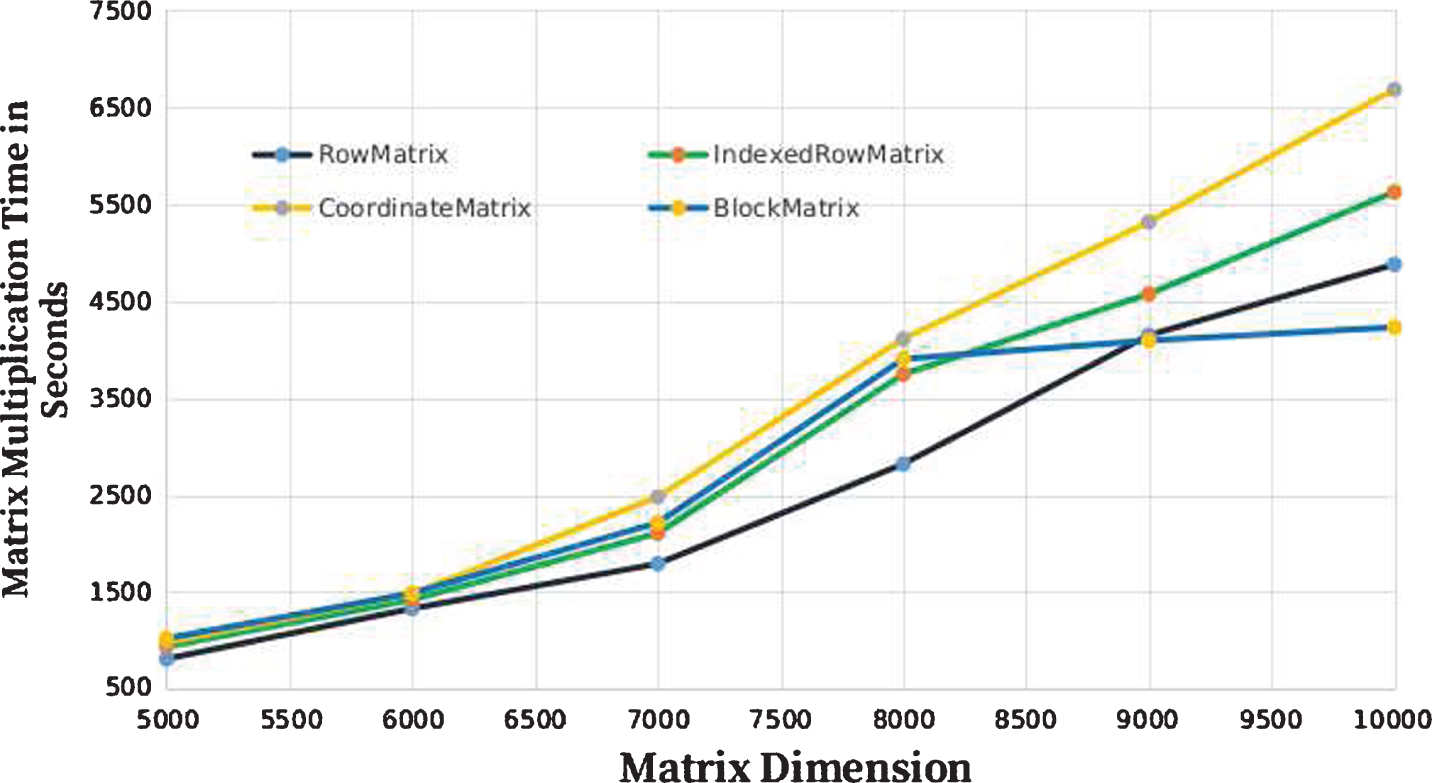
Average computational time of matrix multiplication operation using distributed matrix representations in multinode cluster of Apache Spark.
Let us assume the Gramian matrix (G
T
G) is B with dimension as n × n. The LU factorization of matrix B produces L and U, where L is [l
ij
] , 1≤i,j≤n and U is [u
ij
] , 1≤i,j≤n. Hence B = LU where L is Lower triangular matrix i.e l
ij
= 0 for 1 ≤ i < n and U is Upper triangular matrix i.e u
ij
= 0 for 1 ≤ j < i ≤ n. To provide numerical stability in LU decomposition, the pre-multiplication of pivot matrix P with B Matrix is used. Hence, the LU decomposition will be like PB = LU. Without loss of generality, we assume the order of the square matrix B is 2
k
b, where k an integer and b is the order of the block matrix that can be decomposed on a single server. The large matrices are decomposed the matrix into blocks that has been shown in the following equations.
Equation (9) is derived from Equation (6) which is as follows
Equation (10) is derived Equation (7) as follows
The workflow of the Recursive Block LU Decomposition Algorithm in Spark is described in Fig. 7. The algorithmic representation of this proposed approach is described with the help of three algorithms. Algorithm 1 is used to describe the computational procedure of partial pivoting LU decomposition, which will be executed on a single node. Algorithm 2 is used to describe the procedure of partition (blocks) and the recursive method of LU decomposition on a large matrix. Once the matrix size becomes small and able to get the LU decomposition directly, then Algorithm 2 will call the Algorithm 1 for getting actual Lower triangular (L), Upper triangular (U), and pivot matrix (P).
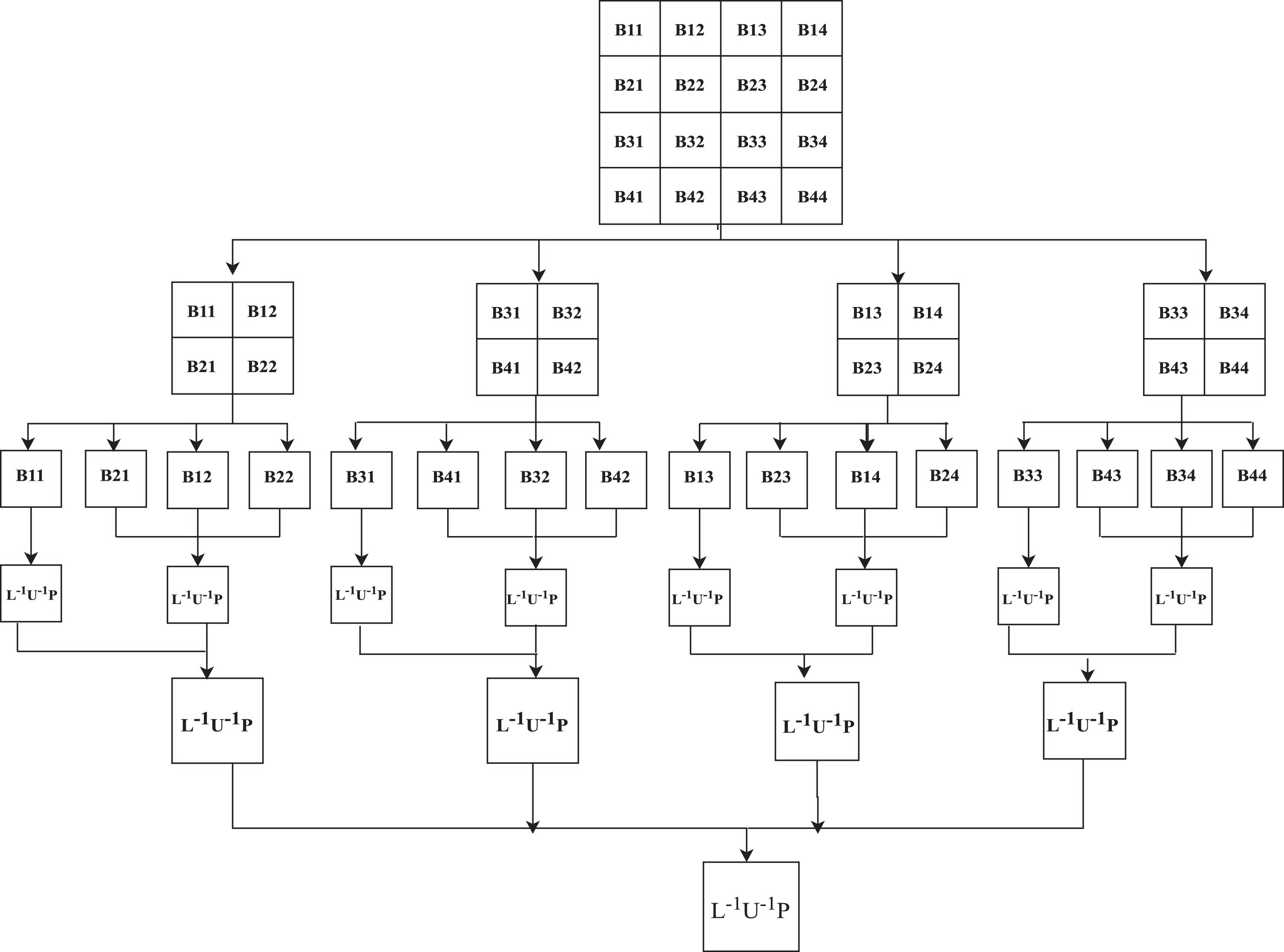
A workflow of Recursive Block LU Decomposition in Apache Spark.
The matrix-B is partitioned into four square sub-matrices. This partition process takes place recursively till the small sub-matrix, where the node can compute basic LU decomposition directly. After computation of LU decomposition on small sub-matrix, the inverse operation on L and U is performed. These results are merged to get the inverse of (G T G). The work flow of the Recursive block LU decomposition is described in Fig. 7. Finally, Algorithm 3 is used to take the original input and calls the Algorithm 2 for finding the results.
Procedure: BasicLUD(B)
Number of rows in B is stored in n
(j,i) ← argmax(∣Bk,k∣, ∣Bk+1,k∣,..., ∣Bn,k∣)
add j to P
swap i th row with j th row
Bi,k ← Bi,k / Bk,k
Bi,j ← Bi,j - Bi,k Bk,j
return(B,P) which is L, U and P
Procedure: BLUD(B)
(L, U, P) ← BasicLUD (B)
L-1 ← Inverse (L)
U-1 ← Inverse (U)
Partitioned B into four sub-blocks such as
Compute Equation (9)
Compute Equation (10)
Compute Equation (12)
Compute Equation (13)
Compute Equation (14)
return (L-1, U-1, P)
Procedure: BLU(B)
(L-1, U-1, P) ← BLUD(B)
B-1 ← U-1L-1P
return(B-1)
In this section, initially, the experimental results on a variant of the MNIST handwritten image dataset have been used to benchmark the proposed work performance with the existing work in the literature. The dataset consists of 5000 samples with 400 features of a handwritten digit image. Initially, the Recursive - Block LU based decomposition has been tested with a master and one single slave node on a standalone cluster. The standalone cluster node has 8GB RAM, 1TB hard disk and Intel i5 processor with four cores as a cluster configuration. The result analysis is shown in Table 1. The numbers of hidden nodes have chosen to support the block size of distributed BlockMatrix in Apache Spark. It is identified that the proposed approach with appropriate distributed block size along with the corresponding hidden layer neurons can produce high training accuracy for classification problems. Due to the limitation in memory for computational tasks, the SVD based ELM with 4095 hidden neurons got a memory exception error. With the help of partitions in RDD, the proposed approach can process the data with a 4095 number of hidden nodes in a cluster.
Comparison of SVD based ELM and Block Recursive LU Based ELM in Apache Spark with varying hidden nodes and different distributed block sizes (Block size in KBs)
Comparison of SVD based ELM and Block Recursive LU Based ELM in Apache Spark with varying hidden nodes and different distributed block sizes (Block size in KBs)
M.Duan et al. have implemented the parallel ELM in Spark that used direct matrix multiplication formulae to calculate Moore-Penrose pseudo-inverse. The author used RDD partitions to represent the data with RDD partitions. However, Apache Spark has a severe limitation on the number of partitions used in RDD. Hence, this approach not able to give an efficient performance if the number of partitions in the RDD is more than 5000 [15].
The same dataset is used for analysis over the multi-node cluster. The multi-node cluster has four nodes, out of which one node is a master node, and the remaining three nodes are slave nodes. The configuration of each node in a cluster has 32GB RAM, 1 TB hard disk with four cores. It is observed that there is a slight increase in the training time due to communication overhead. However, the added advantage here is that the present approach can be extended to large datasets. Fig. 8 shows the training time comparative study of Recursive Block LU decomposed based ELM and SVD based ELM in a multi-node spark cluster. The proposed approach empirically showed that it would take less training time for a large number of hidden nodes in a Spark cluster. Fig. 9 shows the training phase accuracy of Recursive Block LU decomposed based ELM and SVD based ELM in a multi-node Apache Spark cluster. From Fig. 9, it can concluded that the training accuracy of both approaches is almost the same.
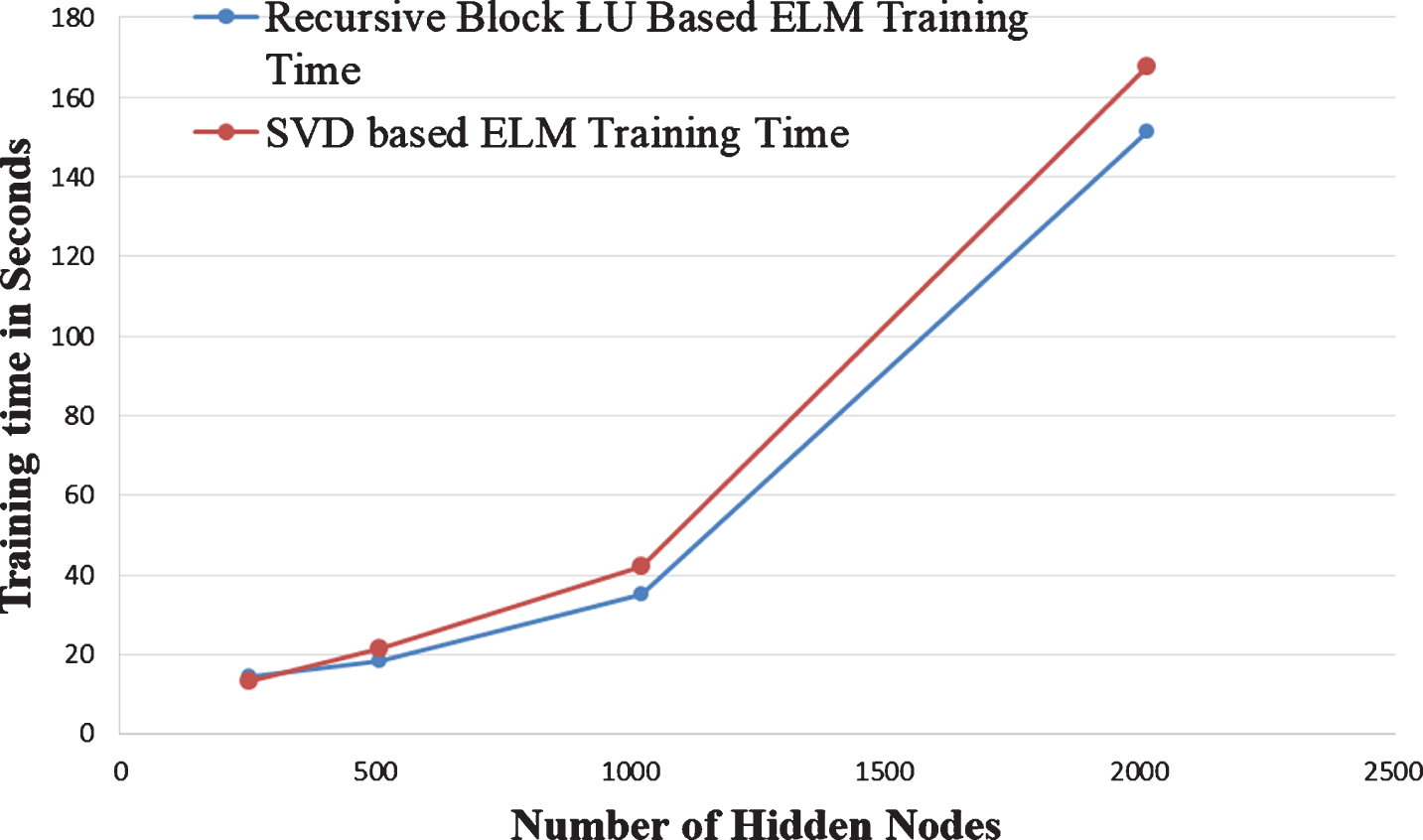
Training time comparison of Recursive Block LU Decomposition based ELM with SVD based ELM in Cluster.
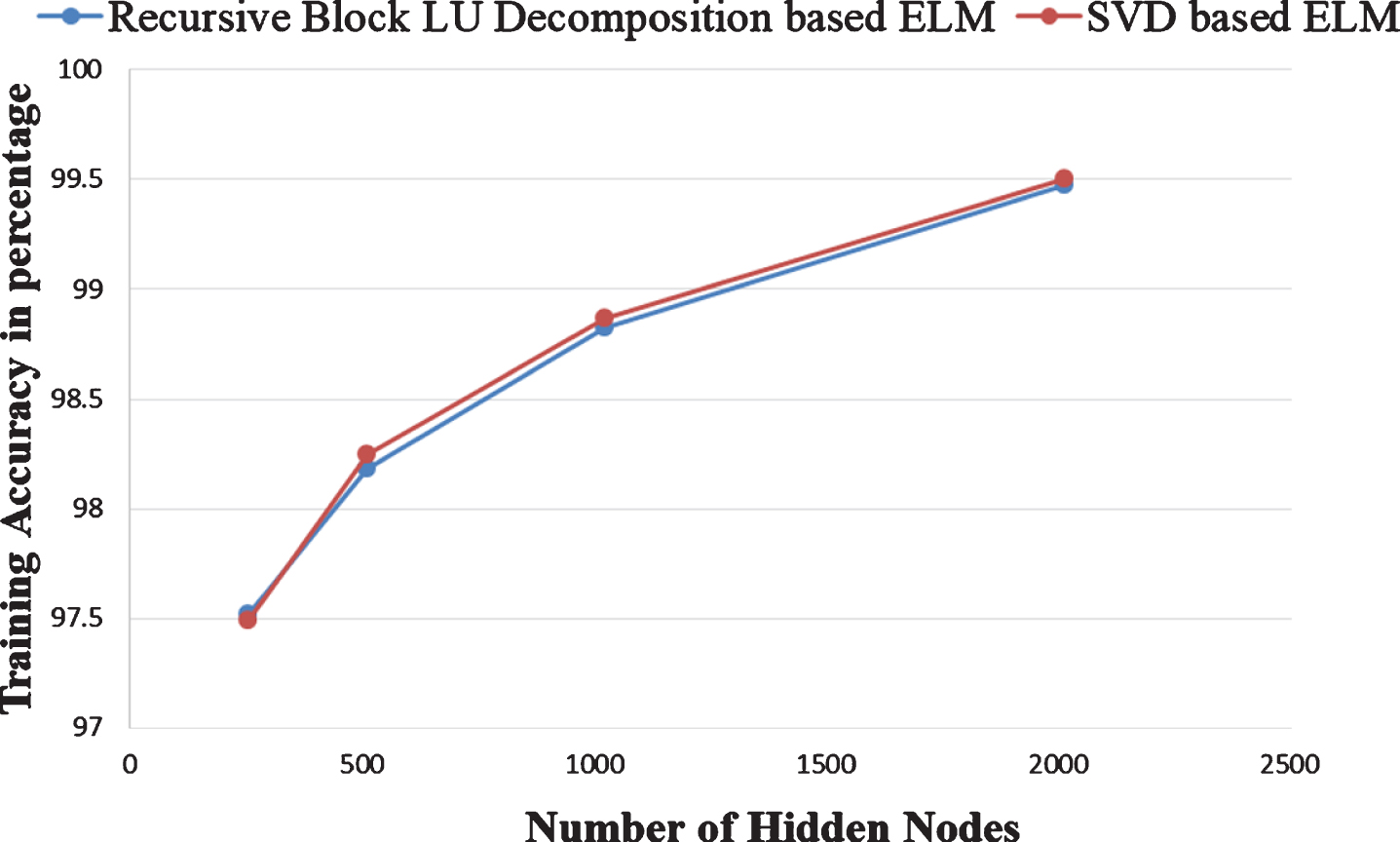
Training accuracy comparison of Recursive Block LU Decomposition based ELM with SVD based ELM in Cluster.
The proposed approach has also been tested on forest-cover dataset to give greater clarity regarding the performance of the proposed approach. Forest cover dataset contains 30 × 30m patches of forest in the US, collected for the task of predicting each patch’s cover type. The forest cover dataset consists of 581012 instances with 54 features. There are seven cover types (classes), which makes the task as a complex multiclass classification problem. Here, one can observe that the number of instances is vast, which is a challenging task for SVD based or standard ELM based implementations. It can be observed that the proposed algorithm can scale up for such a large dataset and produced the results. Table 2 shows the performance analysis of the proposed approach on the forest-cover dataset.
Performance Analysis of Recursive Block LU Decomposition on forest cover dataset with different Distributed Block Sizes
From the result analysis, it can be observed that SVD based ELM in Apache Spark requires large driver memory for computation of the Eigenvalues and Eigenvectors on large blocks of the matrix. But, the Recursive Block LU decomposition-based ELM method in Apache Spark cluster has attained the same training accuracy with less computational time when compared to SVD based ELM in a cluster on moderately large datasets. Also, Recursive Block LU Decomposition based ELM method is scalable when the block size of the matrix is large, which is necessary for training large datasets such as Forest cover dataset. Hence, the present work confidently concludes that the proposed approach is efficient for large datasets where the previous works in the literature have severe limitations that is evident from the experimental results.