
Abstract
BACKGROUND:
P300-spellers are brain-computer interface (BCI)-based character input systems. Support vector machine (SVM) ensembles are trained with large-scale training sets and used as classifiers in these systems. However, the required large-scale training data necessitate a prolonged collection time for each subject, which results in data collected toward the end of the period being contaminated by the subject’s fatigue.
OBJECTIVE:
This study aimed to develop a method for acquiring more training data based on a collected small training set.
METHODS:
A new method was developed in which two corresponding training datasets in two sequences are superposed and averaged to extend the training set. The proposed method was tested offline on a P300-speller with the familiar face paradigm.
RESULTS:
The SVM ensemble with extended training set achieved 85% classification accuracy for the averaged results of four sequences, and 100% for 11 sequences in the P300-speller. In contrast, the conventional SVM ensemble with non-extended training set achieved only 65% accuracy for four sequences, and 92% for 11 sequences.
CONCLUSION:
The SVM ensemble with extended training set achieves higher classification accuracies than the conventional SVM ensemble, which verifies that the proposed method effectively improves the classification performance of BCI P300-spellers, thus enhancing their practicality.
Keywords
Introduction
Brain-computer interfaces (BCIs) establish a new means of communication between the human brain and computers [1, 2, 3]. This communication method does not depend on the muscles, but uses the potential changes of the cerebral cortex to help patients with amyotrophic lateral sclerosis (ALS) or other severe motor disabilities to achieve real-time interaction with the outside world [4, 5].
The P300-speller is a widely used BCI system that allows users to communicate characters by focused attention. It is so named because it relies heavily on the P300 potential, which is a large positive potential, typically elicited at 300 ms to 500 ms after the subject is exposed to rare target stimulus in a series of conventional stimuli [6, 7, 8, 9]. A P300-speller with row-column paradigm (RCP) was first presented by Farwell and Donchin [10]. In the P300-speller, a 6
In addition to the stimulus paradigm, researchers also focused on optimization of signal processing and classification algorithms to improve the performance of the BCI P300-speller [14, 15, 16, 17]. A simple linear discriminant analysis (LDA) with regularization can detect P300 potentials based on a large number of training sets [18]. Further, researchers have also introduced the zero-training framework with transfer learning [19, 20]. However, the transfer learning method also requires a significant amount of training data, even if these do not come from the user. Support vector machine (SVM) has been successfully applied for classifying the P300 potential [21]. SVM ensemble is an improvement to SVM that combines several individual SVM sub-classifier results to produce a final result. These differences among the sub-classifiers of SVM ensemble reduce the interference of EEG noise and the impact of sub-classifier errors [22]. SVM ensemble achieves more satisfactory classification performance than SVM [23]. It is well-known that the larger the scale of the EEG training set is, the better the classification performance can achieve [24]. However, during EEG data collection, subjects would gradually become fatigued, resulting in an obvious difference and inconsistency in the EEG data from the beginning to the end of the period. Using EEG data from different periods, SVM sub-classifier results would have deviations and affect the classification performance.
In this study, based on a P300-speller with the familiar face paradigm, we shrank the collection time for training data and developed a training set extension method for SVM ensemble that extends the small-scale training set to a larger scale training set by superposition and averaging of two corresponding training datasets in two sequences. Figure 1 shows the flow diagram for a P300 speller system with the training set extension.
Flow diagram for the P300 speller system with training set extension and parameter 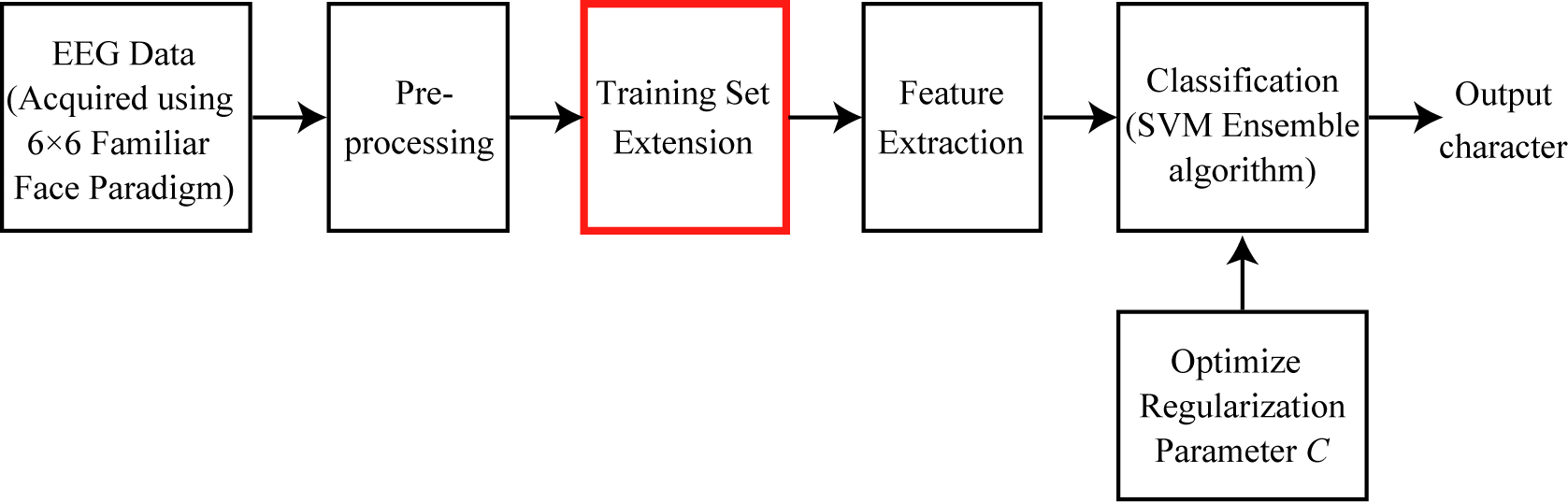
The familiar face paradigm (the characters were overlaid with translucent pictures of a famous face (David Beckham) when one row or column was flashed). (The photos of David Beckham are replaced here by that of one of the subjects owing to lack of a print license).
Familiar face paradigm
In this study, visual stimulation was achieved via the familiar face paradigm [11, 25]. Thirty-six spelling characters were presented in a 6
Participants
Seventeen right-handed university students (six females: 21–26 years old, mean: 24.6 years) participated in this experiment. All participants were native Chinese speakers who were very familiar with the English alphabet. No participant used drugs or alcohol or had any history of neurological disease. They had normal or corrected-to-normal vision and normal hearing. Before the experiment, the subjects were required to get adequate sleep and be in good mental condition. Upon receipt of a complete description of the purpose and risk of the experiment, the subjects signed a written informed consent form for participation and received 100 RMB as compensation. The study was approved by the ethics committee of Changchun University of Science and Technology (CUST).
Data acquisition
Each subject was seated in a comfortable chair at a distance of about 70 cm in front of the computer monitor in a laboratory room shielded from sound and electromagnetic interference. Stimuli were presented on a 19
Experimental procedure. There are six separate sessions, and a five-character word was required to communicate in each session. Between each session, a two- to five-minute break was arranged. There were five runs in each session, and a target character was communicated in one run. One row or column flash was one trial. Six rows and six columns flashing consecutively in pseudo-random order was defined as a sequence. The sequence was repeated 15 times in one run. The inter stimulus interval (ISI) was 250 ms, in which, each character changed to the famous face picture for 200 ms, and then returned to the gray character for 50 ms.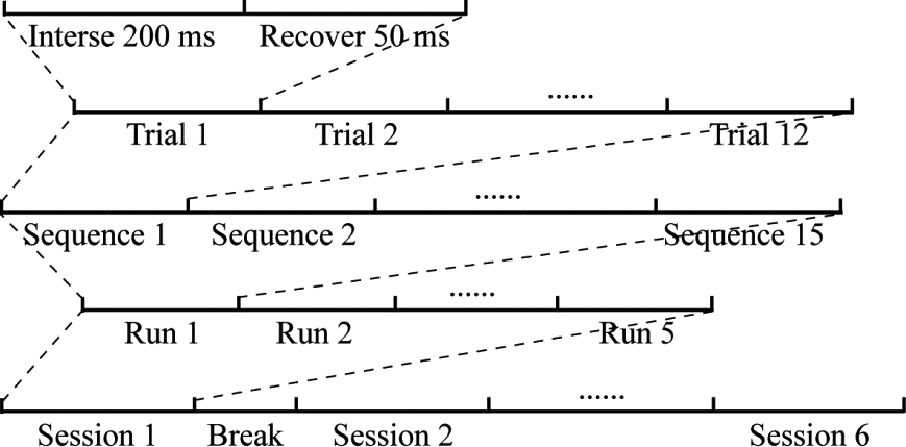
Placement of 14 electrodes on the scalp (Fz, F3, F4, FC1, FC2, Cz, C3, C4, Pz, P3, P4, Oz, O1, and O2).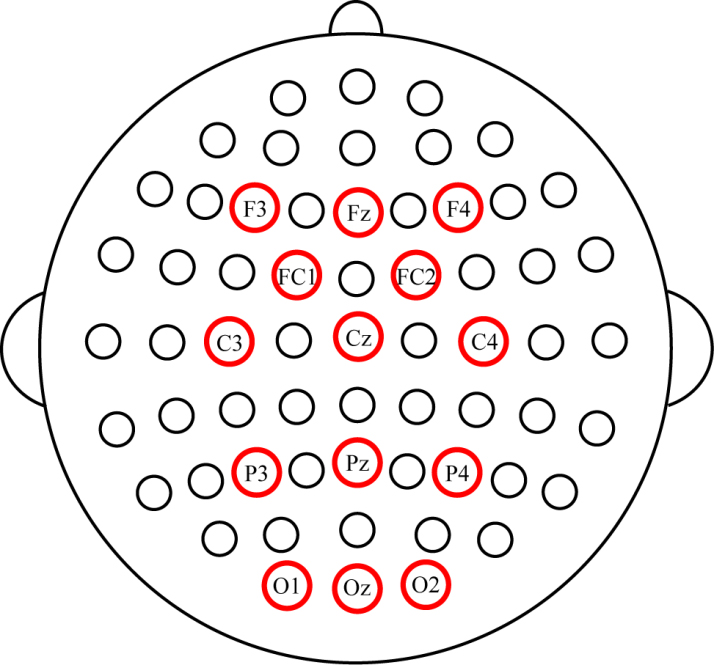
Before the formal experiment, subjects were assigned a 20-second practice run to familiarize themselves with the paradigm and the familiar face used as stimuli. Between each session, a two to five minutes break was arranged so that the subjects could maintain optimal focus.
EEG data were recorded via 14 electrodes (Fz, F3, F4, FC1, FC2, Cz, C3, C4, Pz, P3, P4, Oz, O1, and O2). Figure 4 depicts the placement of electrodes on the scalp [25]. The left mastoid was used as ground, and the right mastoid as the reference. A pair of horizontal electrooculogram (HEOG) electrodes was placed at the outer canthus of the left eye and the right eye to detect horizontal eye movements. Simultaneously, a pair of vertical electrooculogram (VEOG) electrodes was placed above and below the left eye to measure vertical eye movements. All impedances were kept below 5 k
EEG data were digitally filtered with 0.01 Hz high and 30 Hz low pass. The ocular artifacts were corrected with both HEOG electrodes and VEOG electrodes by a regression analysis algorithm [27]. The EEG data were then divided into epochs ranging from
Long feature vectors require longer processing time. To compress the EEG data, down-sampling was adopted for feature extraction. The sampling rate was reduced from 256 Hz to 64 Hz by taking one point for every four points. The original EEG trial consisted of 128 points for 500 ms. Following down-sampling, the number of points decreased to 32. As 14 channels were used for collection, the feature vectors of the EEG trials for the 14 channels were combined in the order F3, Fz, F4, FC1, FC2, C3, Cz, C4, P3, Pz, P4, O1, Oz, O2 as feature vector. Thus, the length of each feature vector was
Training set extension and classification
Training set extension
An extension strategy that extended the small-scale training set to a larger scale training set by superimposing and averaging the corresponding EEG trials of two different EEG sequences was adopted. We assumed that a matrix of
Similarly,
Thus, the training set was extended by applying the following steps:
Get two EEG sequences from In accordance with Eqs (1) and (2), average two corresponding column EEG trials (
Select another two EEG sequences, at least one of which differs from the selected EEG sequences. Repeat Steps 2) to 4) until a total of
In our case,
Flow diagram of training set extension process, in which the training set is used to communicate one target character with 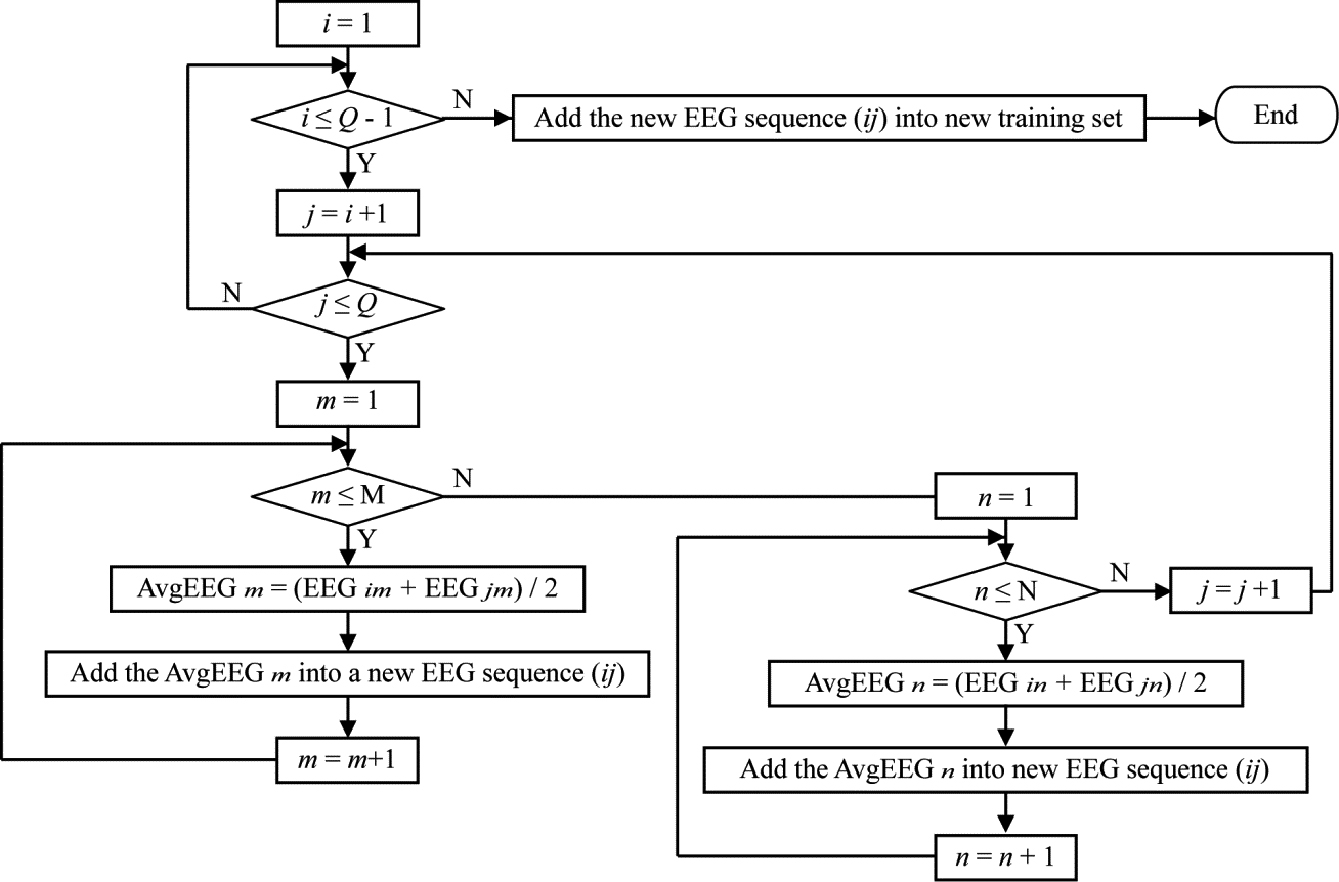
SVM is a binary classifier that constructs a hyperplane by dividing the data space into two subsets [21]. The hyperplane is always described by weight vector
Among several hyperplanes, only the one with the largest separation margin
To measure the deviation of training data outside the
In terms of positive Lagrangian multipliers
Integrating Eqs (3) and (6), and replacing
In this study, a Gaussian kernel was used for all SVM sub-classifiers:
The performance of the SVM classifiers depends on the setting of hyper-parameter
All EEG trials in each session were treated as one group. Thus,
where acc is the character’s average input accuracy.
The average accuracies for the different values of
In addition to the training session, the five remaining sessions were arranged as a testing set. Each sequence consists of
After SVM classification, weight voting was applied to integrate the results. The feature vectors of each sequence in the 12 trials were classified by seven sub-classifiers; thus, each trial had seven results matched with seven sub-classifier weights. Each EEG trial’s seven results were summed up by seven weights to obtain a final score.
Average classification accuracy for 17 subjects with different values of
The number of sub-classifiers used for SVM ensemble was
The score of
To derive only one decision from these seven SVM sub-classifiers, we considered that the row and column with the highest score should be the row and column that expected to contain the target character. To get the most probable column trial in
The most probable row trial in
According to
Average sequences when accuracy achieved 100% with different values of
Note: SD refers to standard deviation among the 17 subjects.
Average classification accuracy for the 17 subjects with the number of sequences
Note: The format of results is Average
Results for regularizing parameter C
To compare the effects of different values of parameter
Results for training set extension
To verify the effect of training set extension with small training set, one session was used to train the sub-classifiers, and the other five sessions were used to test. We calculated the individual and average accuracies of the 17 subjects, respectively using the non-extended training set and the extended training set. The average classification accuracies with the number of sequences are listed in Table 3. The individual and average classification accuracies for the 17 subjects are shown in Fig. 6.
Individual and average classification accuracy for the 17 subjects.
Optimization of regularizing parameter C
It is clear that when
Training set extension
The average accuracies of the 17 subjects increased with the number of sequences (Table 3). A repeated-measures ANOVA on accuracy of classification with the within-subjects factors of sequences (2–15 sequences, 14 levels) and training set (extended and non-extended) showed that the classification accuracy using the extended training set for training is significantly higher than that of the non-extended training set [F (1, 16)
In addition, the accuracy of each subject also improved with increasing number of sequences (Fig. 6). When trained by the extended training set, all subjects achieved 100% accuracy after 15 sequences, compared to only five subjects (subjects 4, 6, 7, 9, and 16) achieving 100% after 15 sequences with the non-extended training set. Among the 17 subjects, the results for 16 subjects show that being trained by the extended training set results in higher classification accuracy than being trained by the non-extended training set. Further, the fewer sequences used for classification, the greater the superiority that can be achieved. In addition, as the number of sequences increases, training using the extended training set results in greater increase in accuracy than training by the non-extended training set.
Therefore, our results prove that training using the extended training set produces higher performance than the non-extended training set. The training set extension has a large advantage in the case of a small training set.
Conclusion
This study proposed a small training set extension method that reduces the training set collection time for SVM ensemble based on a BCI P300-speller with the familiar face paradigm. The offline results verify that the extended training set indeed leads to better performance by the BCI P300-speller compared to the traditional non-extended training set, thereby enhancing its practicality. In future work, this training set extension method will be applied to an online P300-speller and to practical BCI applications.
Footnotes
Acknowledgments
The study was financially supported by the National Natural Science Foundation of China (61773076) and the Science and Technology Development Program of Jilin Provincial Science and Technology Department in China (20180519012JH). The authors would like to thank all the subjects who participated in the experiments and the anonymous reviewers for their valuable comments.
Conflict of interest
The authors declare that they have no conflict of interest.