
Abstract
BACKGROUND:
Non-invasive Brain-Computer Interface (BCI) uses an electroencephalogram (EEG) to obtain information on brain neural activity. Because EEG can be contaminated by various artifacts during the collection process, it has primarily evolved into motor imagery (MI) with a low risk of contamination. However, MI has a disadvantage in that accurate data is difficult to obtain.
OBJECTIVE:
The goal of this study was to determine which motor imagery and movement execution (ME) of the knee has the best classification performance.
METHODS:
Ten subjects were selected to provide MI and ME data for four different types of knee exercise. The experiment was conducted to keep the left, right, and both knees extend or bend for five seconds, and there was a five seconds break between each movement. Each motion was performed 20 times and the MI was carried out in the same protocol. Motions were classified through a modified model of the Lenet-5 of CNN (Convolution Neural Network).
RESULTS:
The deep learning data was classified, and a study discovered that ME (98.91%) could be classified significantly more accurately than MI (98.37%) (
CONCLUSION:
If future studies on other body movements are conducted, we anticipate that BCI can be further developed to be more accurate. And such advancements in BCI can be used to facilitate the patient’s communication by analyzing the user’s movement intention. These results can also be used for various controls such as robots using a combination of MI and ME.
Keywords
Introduction
Brain-Computer Interface (BCI) is a technology that allows users to interact with a computer or other external device directly through brain activity. In general, non-invasive BCIs use neural activity information recorded using an electroencephalogram (EEG) because of its portability, low cost, and high temporal resolution [1]. EEGs monitor brain activities, so it is possible to infer the mental states, emotional states, and intention of motions by using an EEG [2].
In particular, BCI studies have been conducted to facilitate communication for patients with severe movement disorders, increase their independence, and improve the quality of their lives [3]. In addition, EEG-BCI technology has recently advanced such that it can be used in everyday life environments as well. As a result, more BCI research is being conducted in ways that benefit ordinary people, including people with disabilities [4].
Several studies have been conducted to demonstrate that motor imagery (MI) can replace movement execution (ME) based on the fact that activated cerebral cortex regions partially overlap. A study by Neuper et al. [5] reported that subjects found similar activations in brain with ME of the same motion with hand movements by MI. Based on the results of the above study, Robert et al. [6] showed that the combination of BCI and virtual reality (VR) by using MI because MI and the same ME affect similar neural networks in the brain. Furthermore, MI has been preferred over ME in BCI studies because MI experiments can be performed with subjects in a fixed posture with their eyes closed, whereas ME measurements require the subjects to make a large movement due to hardware limitations, and the measurements may be contaminated with artifact in the process.
Whether MI and ME shared brain networks has been of interest to the scientific community for several decades. In the past, this has been examined by small-scale studies that simply identify common activation areas with limited sample sizes [7]. However, according to a comparative meta-analysis study of MI, ME, and action observation (AO) by Robert et al. [7], the activation of the same regions of the same part of the cerebral cortex on MI and ME cannot be regarded as performing the same function. And, in a study by Hanakawa et al. [8], MI and ME of right-hand finger tapping were analyzed with statistical parameter mapping (SPM), and it was reported MI and ME share many activations, but other activations had a greater impact. This means that the sharing of brain activation areas and the sharing of brain networks are different, and that it is difficult to grasp the user’s intentions simply through the activation areas. In addition, it is difficult to control MI accurately in the experimental process. As a result, MI has a disadvantage in that accurate data is difficult to obtain [8]. Furthermore, with recent advances in hardware technology, the amount of noise induced in the ME data collection process has been reduced, and various artifact removal methods can be used to remove the noise [9]. Therefore, studies on ME have been conducted actively in recent years. In particular, various studies on ME have been conducted focusing on the upper limb, especially the hand, for which a large area of the cerebral cortex is responsible. Cho et al. [10] proved that it is possible to classify five hand movements with ME as well as with MI. Furthermore, Chen et al. [11] investigated the possibility of classifying finger movements.
According to the cortical homunculus, the movement of the lower limb is responsible for a small region of the primary motor cortex (M1) compared to the movement of the upper limb. Moreover, the regions corresponding to the hand in the upper limb and the foot in the lower limb take up the largest area [12]. In the case of the lower limb, the regions in the M1 responsible for the lower limb are very closely arranged. Hence, it is difficult to obtain meaningful results. Therefore, the classification of the movement of the lower limb has not been actively researched in previous studies [13, 14, 15, 16]. Tariq et al. [17] conducted a study on the classification of lower limb movements in individuals with MI. Hooda et al. [16] collected data as the subjects performed exercise while part of their body was fixed or their foot was tied to the exercise equipment.
In this study, the MI and ME data of knee motion in the lower limb were collected and classified according to an artificial intelligence model, and the accuracy of the two experiments was compared to verify their applicability in BCI.
Method
This study was conducted with ten healthy males and females in their 20s (4 males and 6 females between the ages of 22 and 25) whose main foot is the right foot. The data was collected after receiving their written consent. The experiment was conducted in a quiet environment using an anomalous visual stimulus, and the subjects were instructed to look at the monitor during the experiment (Fig. 1). The experimental protocol was configured as shown in Fig. 2. Before the experiment, the subjects were given ten minutes to practice extending their right knee, left knee, and both their knees or bending both their knees and holding these postures for five seconds through visual stimulation. The subjects also practiced imagining performing these movements through visual stimulation during this practice time. There was a five-second gap between each motion. While the ME experiment was conducted, the subjects performed the instructed movements. After five minutes of rest, the MI experiment was conducted in the same manner. During this experiment, the subjects were instructed to imagine performing the instructed movements. For the ME and MI experiments, the subjects were instructed to repeat each movement 20 times.
Experimental environment. The subject performed a movement according to the visual signal shown on the screen.
Data collection protocol timeline.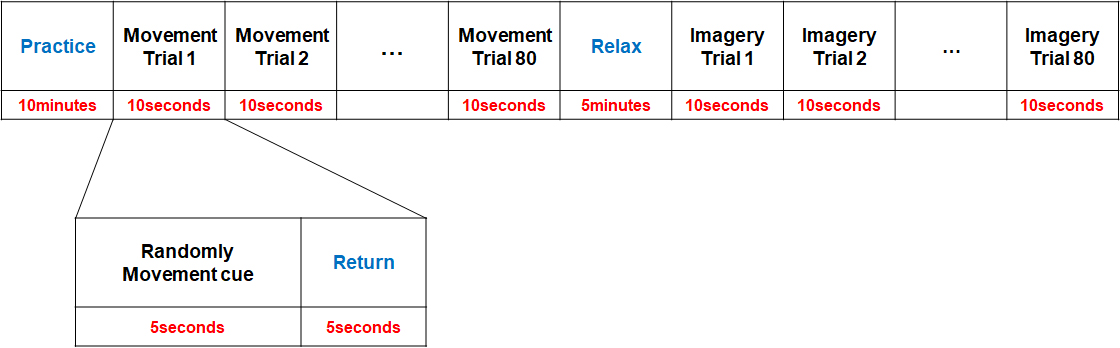
Q20r by CGX was used as the EEG, and the EEG data was recorded in 19 channels (F
There is a 5-second gap between each movement in the data collected through the experiment. To remove this gap, the collected data was transformed into the form of a three-dimensional array by cutting out five seconds of data for each movement. To transform the data to make it suitable for human activity recognition (HAR), the 3-dimensional array data was transformed into two dimensions. The transformed data was then collected again and used as a 3-dimensional array using the sliding window algorithm [18]. The input data used in the above process is in the form of a 19
Data scaling
When training a neural network, a data scaling process is performed to adjust the data to a suitable range and format. A model trained with scaled data generally performs much better than a model trained with unscaled data [19, 20].
If the data is scaled using the standard scaler, the scale of the data is adjusted as shown in the following Eq. (1). The data is transformed to have a mean value of 0 and a variance value of 1 through this process.
Since the values of the data collected in this study range from
To obtain high classification results, it is necessary to extract appropriate features from the EEG signals. Feature extraction based on the fast Fourier transform does not utilize the time domain information. However, time-domain information is required for EEG classification because EEG data is time-series data. Feature extraction based on wavelet transform is effective for EEG classification because it can decompose data into frequency components while maintaining time-domain information [21, 22]. The wavelet transform has a high-frequency resolution in the low-frequency domain and a high temporal resolution in the high-frequency domain. In addition, the discrete wavelet transform (DWT) can remove EEG noise during data preprocessing [23]. Because EEG data contains ocular artifacts such as eye blinks, classification performance can be improved by removing them using DWT.
In order to increase the data classification accuracy, DWT was used in this study to remove noise in the signal and extract features. And db2 was selected as the DWT coefficient.
A convolution neural network (CNN) is a neural network optimized for image recognition and classification. CNN learns by automatically extracting features from data and has a high image classification accuracy [24]. Since we train the neural networks using EEG data as images, we made some modifications to the Lenet-5 model of the CNN algorithm and used it for our training.
In this study, a convolution operation was performed using a 3x3 filter as a learning parameter, with a total of three convolution layers. We used batch normalization to speed up the learning rate and improve performance [25]. The CNN model has two fully-connected layers and uses the Softmax function for classification in the output layer. Moreover, the dropout layer was used to prevent overfitting. Table 1 shows detailed conditions for layers and parameters.
The details of layers and parameters
The details of layers and parameters
A support vector machine (SVM) is a technique for finding classification rules for data sets. An optimal hyperplane is found, which maximizes the margin between classes in the feature space. If there are two labels to classify, the hyperplane corresponds to a simple line. If there are three labels to classify, the hyperplane corresponds to a two-dimensional plane. SVM is a classification algorithm that draws a line optimized to classify labels [26].
To improve classification accuracy, we combined the SVM with the neural network training result of the CNN model’s output layer in this study.
Training method
The deep learning model was trained in an environment consisting of RTX 2060, TensorFlow 2.7.0, and Keras 2.7.0. EEG was sampled at 500 Hz, and the accuracy was derived from the results of training the model for 3000 epochs.
Statistical significance analysis
In this study, we performed the statistical analysis of the experimental results with the two-tailed distribution through the Paired-Samples T-Test for the comparison of the CNN model and the CNN-SVM model. For the comparison of the MI and ME, the statistical analysis was performed with the one-tailed distribution through the Independent-Samples T-Test. The statistical significance was defined as
Results
The average value was derived by training the deep learning model ten times using the MI and ME data, and the classification accuracy of each result is shown in Table 2.
When the MI data was used, the CNN model showed an average classification accuracy of 98.37%, and the CNN-SVM model showed an average classification accuracy of 98.46%. Although the CNN-SVM model showed a slightly higher classification accuracy on average, it did not show a statistically significant difference from the CNN model (
Training result of MI and ME
Training result of MI and ME
When the training results of the deep learning models for the MI and ME data were compared by model, the knee movement was classified more accurately in ME than in MI for both models. Hence, the difference between MI and ME was statistically significant (
Comparison of MI and ME
The classification accuracy of the training results of the CNN and CNN-SVM models. The vertical axis represents the accuracy.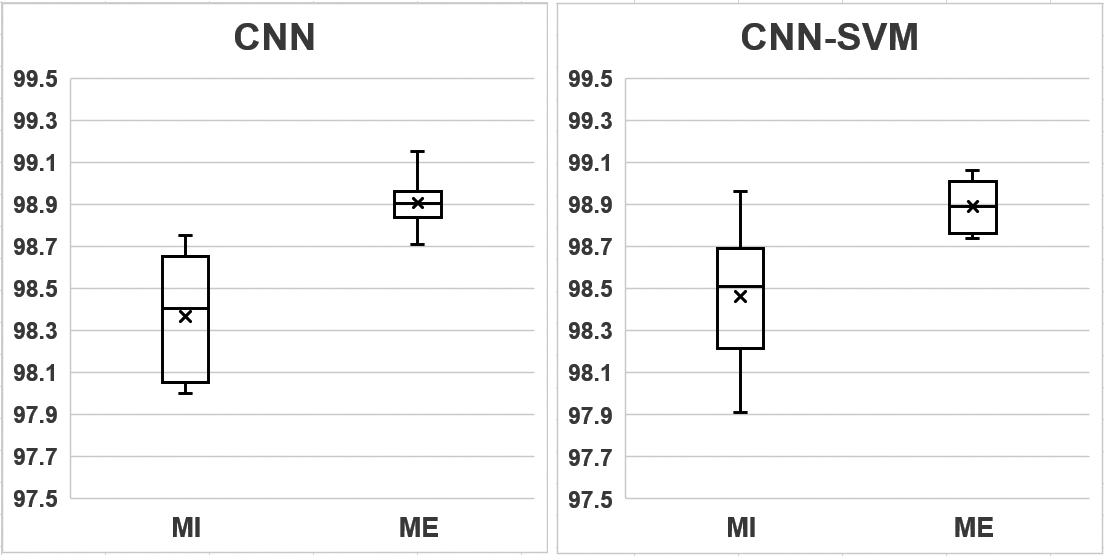
The aim of this study was to classify deep learning performed with MI and ME in the knee, and to compare the classification accuracy of the two experiments. This study differs from previous BCI studies in that it classified movements using a deep learning model with EEG data collected by knee movements rather than hand, arm, foot, and ankle movements, which have been actively researched in previous BCI studies [7]. The two-dimensional data recorded with a 19-channel EEG device was transformed into a three-dimensional array. The form of the data was modified through a sliding window algorithm suitable for HAR. The modified data was then used as the input data.
Using data obtained from 10 subjects, Jeong et al. [27] obtained an average classification accuracy of 73% in ME and 65% in MI by classifying the forearm movement according to the sophisticated rotation angle through the CNN transformation model. Also, the possibility of complex motion classification using EEG has been reported. In the study by Gwin et al. [14], knee and ankle movements of 5 subjects were classified through ICA (Independent Component Analysis) algorithm and an average classification accuracy of 90% was obtained. In the study of Tariq et al. [17], it was reported that the left and right dorsiflexion performed with MI of 9 subjects were classified with accuracy of 83.4%, 82.0%, and 81.3%, respectively, using LDA (Latent Dirichlet Allocation), SVM, and KNN (K-Nearest Neighbor) algorithms. A study by Hooda et al. [16] performed that the number of channels was adjusted by combining EMG (electromyography) and EEG, and left and right dorsiflexion and plantarflexion of 12 subjects were classified by SVM with up to 96.3%. Antelis et al. [28] proposed the use of Dendrite Morphological Neural Networks (DMNN) to recognize spontaneous movements in EEG signals. The DMNN recognition performance of ME and MI was evaluated through hand movement. Performance improvement was expected compared to SVM and LDA, and decoding accuracy was 80% ME and 77% MI.
Accordingly, in this study, MI and ME data obtained from 10 subjects were classified through artificial intelligence. To increase the size of the data, we adopt a sliding window algorithm that divides signals into fixed-length windows and generates labels for all sample in one window that are mainly adopted by HAR [29]. Also, we created an artificial intelligence model for EEG movement classification using CNN, the most widely used deep learning architecture, and SVM, the most widely used algorithm [30, 31].
Compared to the training results of the CNN model, the CNN-SVM model achieved a higher average classification accuracy in MI and a lower average classification accuracy in ME. However, the learning result of the CNN-SVM model is not significant because it did not show a significant difference in both MI and ME. When the results of the two experiments were compared for the CNN model, the average classification accuracy was 0.54% higher in ME than in MI. According to the findings of this study, EEG data collected while imagining and performing knee movements in the same environment can be classified more accurately in ME than in MI. It was consistent with the results of past study classifying MI and ME through experiments in opening and closing fists or moving feet [2].
According to the cortical homunculus, the knee is responsible for a very narrow region of the M1. Schellekens et al. [32] reported that the regions of the M1 corresponding to the ankles, toes, and knees were greatly activated during ankle movements, and the regions of the M1 corresponding to the knees and ankles were greatly activated during knee movements. Compared to other body parts, the knee showed a low degree of connection between body parts during its movements. This result indicates that knee movements induce a relatively unique activation in the M1 region. The findings of this study, combined with improvements in EEG hardware and the application of an artificial intelligence model, confirmed that knee movements in EEG data, which correspond to a small and deep movement region in the M1 and show a unique activation, could be classified. However, since the concentration level of each subject is different, outliers that deviate significantly from the average data should be identified and removed in advance.
In a study by Mattia et al. [33], it was reported that the ME of a quadriplegic patient exhibited the activation of M1 similar to the ME of healthy people. Therefore, if the intention of a quadriplegic patient to move his or her knee can be recognized based on the results of this study and applied to a functional electronic stimulator (FES), and this technique is utilized in various control technologies, it is expected that this technique will be helpful in restoring the knee movement function of quadriplegic patients. Furthermore, by using the EEG that is naturally generated by a ME, BCI can be applied and used in training to restore the knee movement function of patients with muscle paralysis caused by motor neuron diseases such as amyotrophic lateral sclerosis (ALS) [34]. Prior EEG studies through artificial intelligence have been used to measure the sleep staging or diagnose and classify epilepsy in the clinical field [35, 36, 37]. However, this study is conducted for BCI, not clinical. The result can be utilized as basic BCI data using motion prediction and classification accuracy through lower limb movements. A study by Gao et al. [38] attempted to attempted to develop the BCIBSHS environment, a type of BCI system based on a smart home system, to improve the lives of the disabled and the elderly. Based on the work results, it can be developed as a BCI environment using the MI and ME of lower extremity exercise.
Furthermore, it will be possible to apply the results of this study to not only simple bending of the knees but also to performing movements that require bending of the knee, such as sitting, standing, and walking. However, since this study was conducted only for the knee movements, studies on the movements of other body parts such as legs, ankles, and toes need to be conducted as well in order to apply the results of this study to high-level movements like walking.
Conclusion
This study confirmed that movements can be classified more accurately when using ME data than MI data, which was used in a majority of the previous BCI studies. If research on the movements of other body parts is conducted as well, based on the results of this study, we anticipate that BCI can be further developed to be more accurate. And such advancements in BCI can be used to facilitate the patient’s communication by analyzing the user’s movement intention. It can also be used in various control fields, such as assistant robots for patients with knee diseases and controlling training robots, and in the field of the rehabilitation of paralyzed patients.
Footnotes
Conflict of interest
None to report.