
Abstract
BACKGROUND:
Autistic Spectrum Disorder (ASD) is a neurodevelopment condition that is normally linked with substantial healthcare costs. Typical ASD screening techniques are time consuming, so the early detection of ASD could reduce such costs and help limit the development of the condition.
OBJECTIVE:
We propose an automated approach to detect autistic traits that replaces the scoring function used in current ASD screening with a more intelligent and less subjective approach.
METHODS:
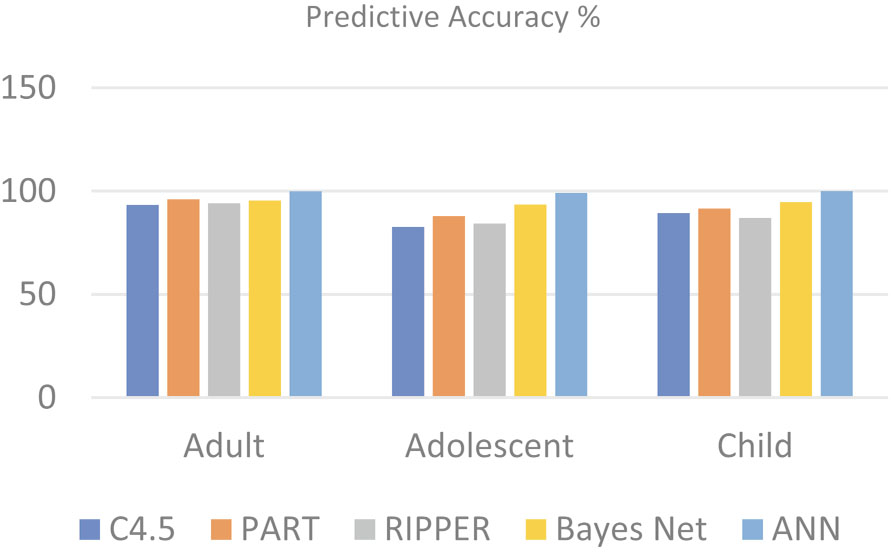
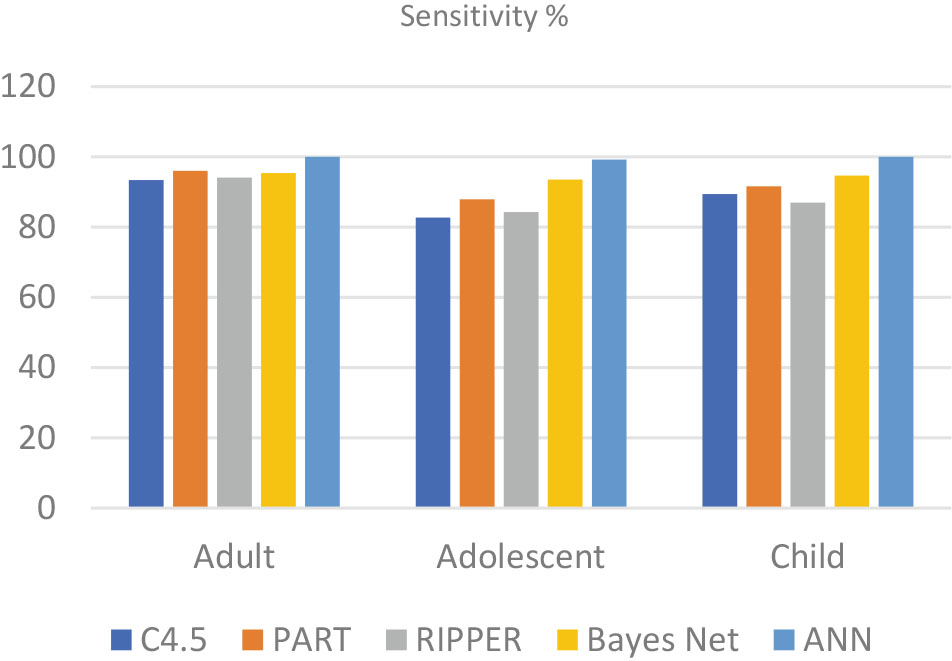
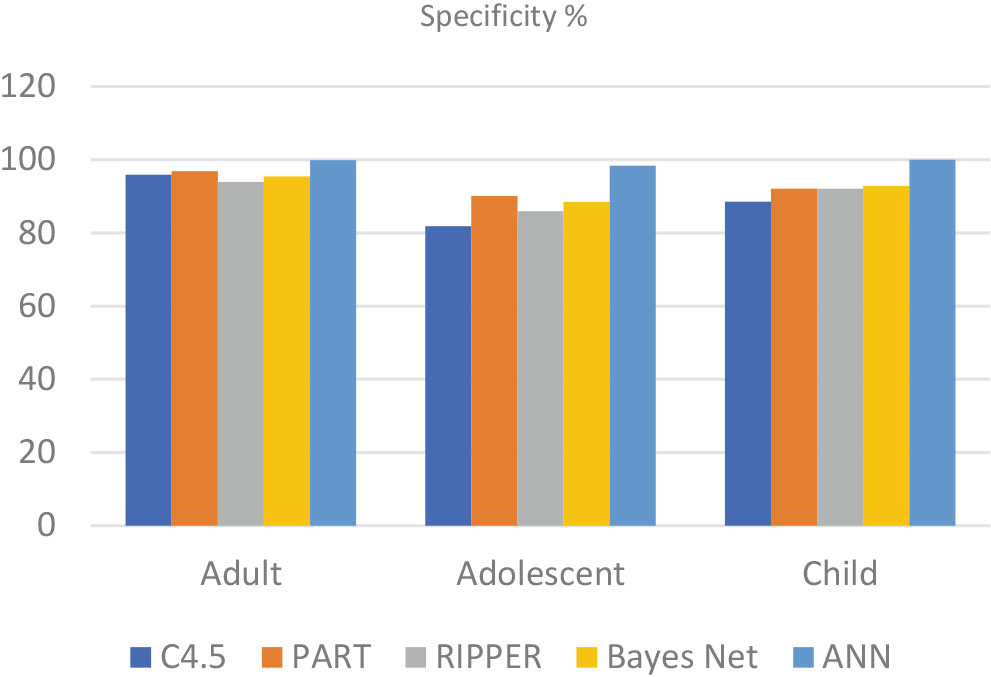
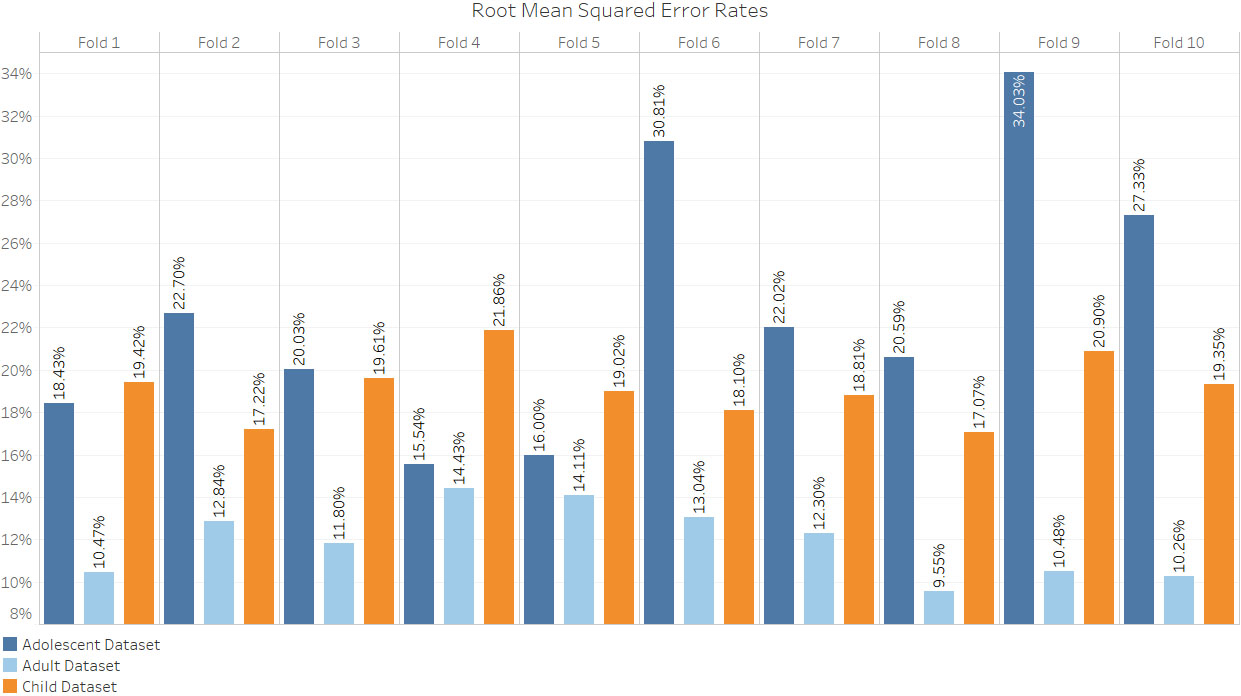
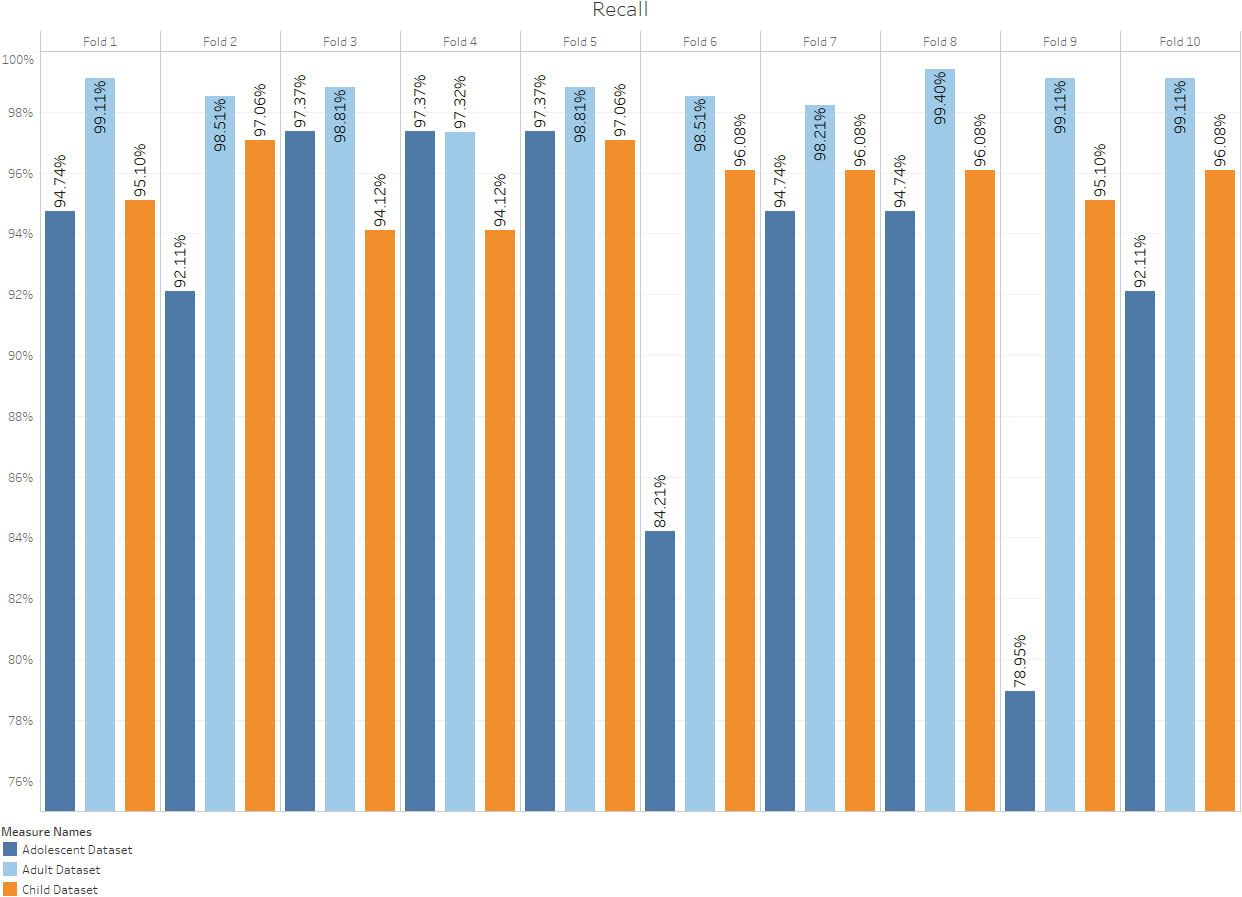
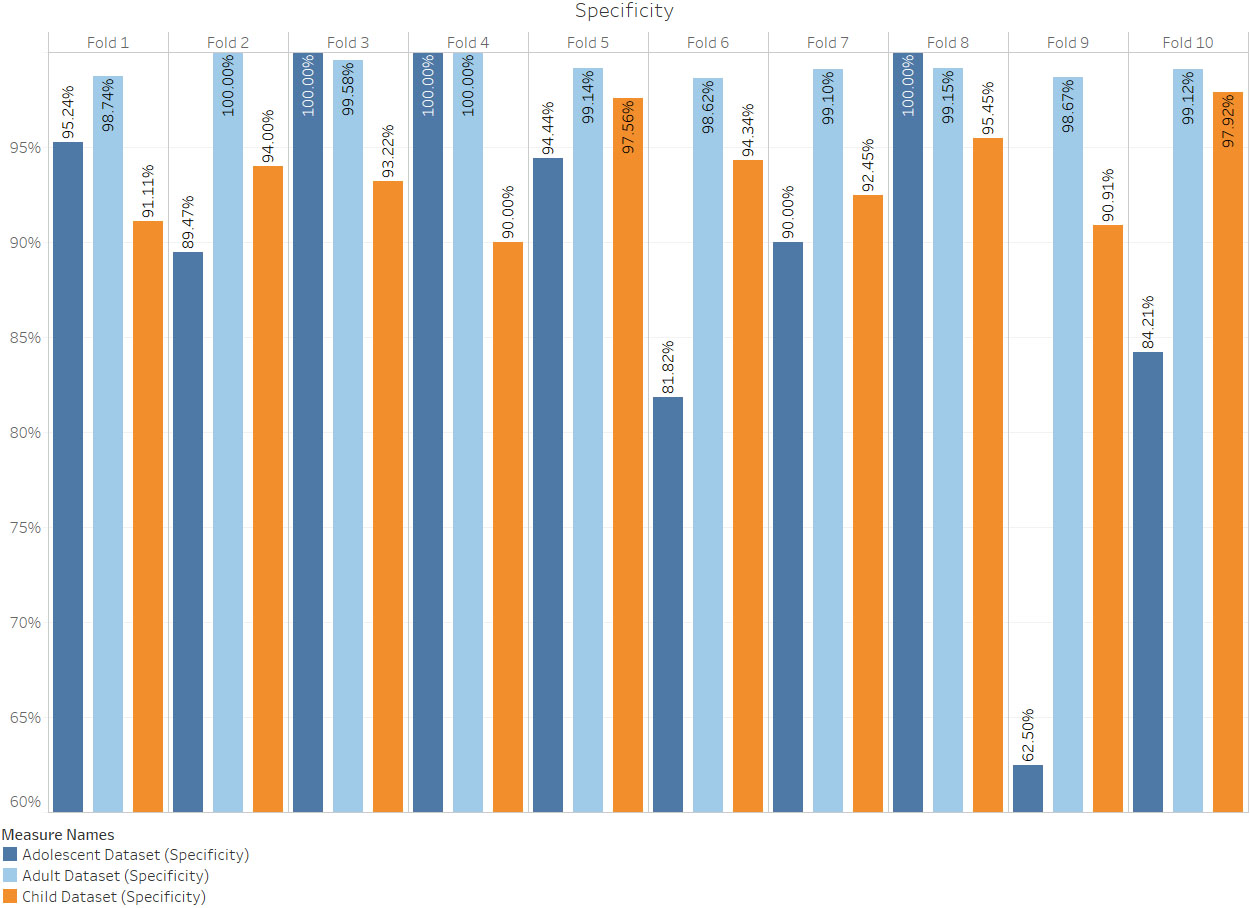
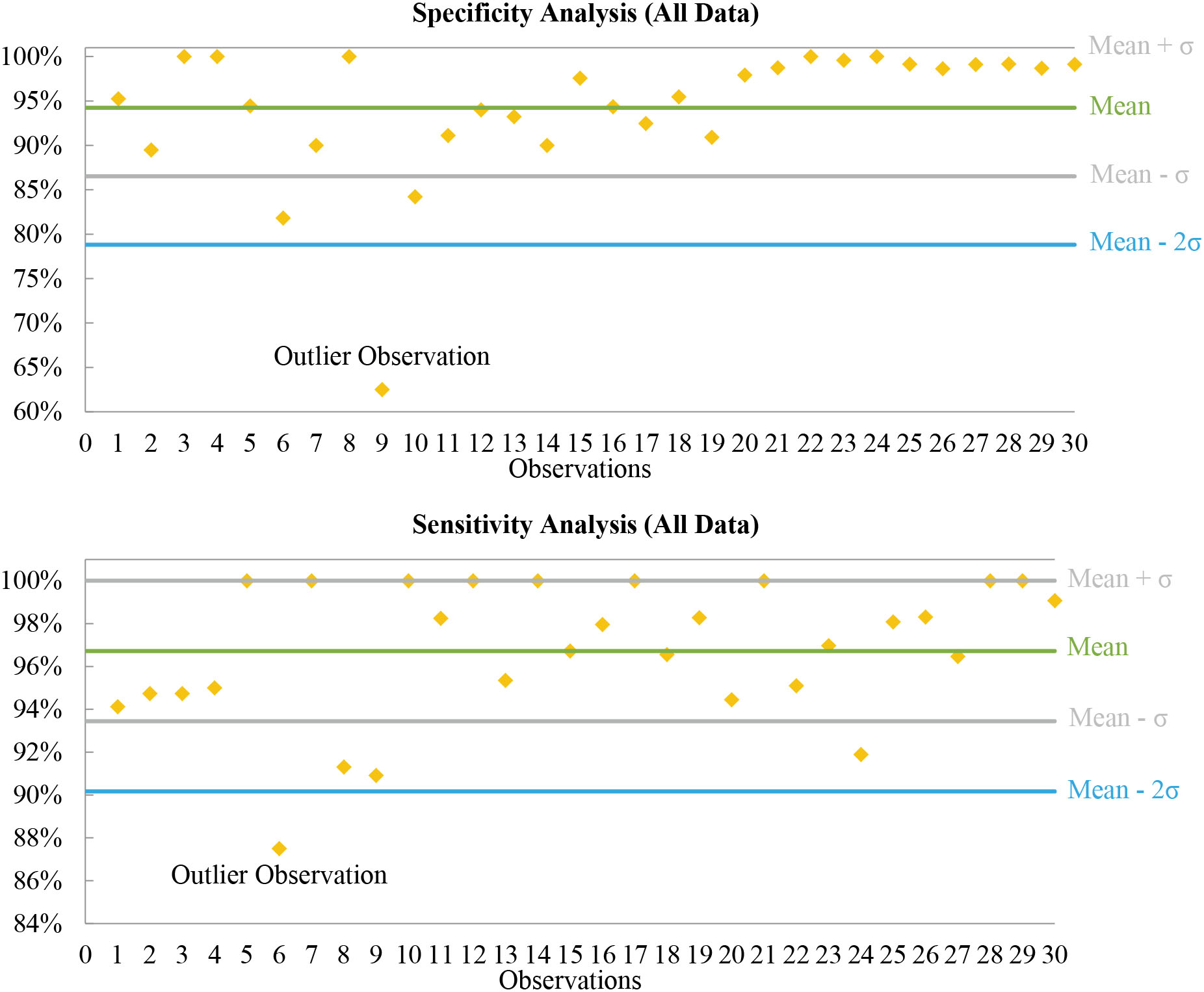
The proposed approach employs deep neural networks (DNNs) to detect hidden patterns from previously labelled cases and controls, then applies the knowledge derived to classify the individual being screened. Specificity, sensitivity, and accuracy of the proposed approach are evaluated using ten-fold cross-validation. A comparative analysis has also been conducted to compare the DNNs’ performance with other prominent machine learning algorithms.
RESULTS:
Results indicate that deep learning technologies can be embedded within existing ASD screening to assist the stakeholders in the early identification of ASD traits.
CONCLUSION:
The proposed system will facilitate access to needed support for the social, physical, and educational well-being of the patient and family by making ASD screening more intelligent and accurate.
Background
Autistic Spectrum Disorder (ASD) is a neurodevelopmental condition typically described as impairments in the development of social, cognitive, and communication skills that are exhibited by social, repetitive, or restricted behaviours and interests. ASD is one of the fastest growing development conditions with rates showing that 1.5% of the world’s population are on the autism spectrum and many remain undetected [1]. Usually, ASD is coupled with substantial healthcare costs that may hinder speedy detection [2]. On average, waiting time for a formal ASD diagnosis in the United Kingdom is over three years [3]. Despite receiving a diagnosis, some individuals exhibit above average scholastic or non-academic (e.g., artistic) capabilities, posing a challenge for professionals to rationalise a diagnosis [4].
The diagnosis of ASD is clinically based on observable and measurable behavioural indicators (e.g., social skills, engagement in age-appropriate play and leisure, behaviour excesses, communication skills) using diagnostic methods. Existing methods seem to subscribe to the idea that more questions translate to a more accurate classification of cases and controls – this is time consuming due to the large number of items the specialist must check. These have necessitated a change in the way diagnostics are coded and behave within ASD clinical tools for the classifying process.
Early detection of autistic traits can be accomplished by using screening methods such as the Autism Quotient (AQ) [5]. However, the number of items required to be checked by the user is still large, i.e. 50 items in the case of AQ. Attempts to reduce the number of items and improve the efficiency of screening and diagnostic tools have been observed over the last few years, for example by [6], and [11]. Nevertheless, all of the existing methods in ASD screening research are based on domain expert rules and simple scoring functions used to classify cases and controls [12]. Often, when the scores obtained exceed a certain threshold, the individuals are classified on the spectrum, or at least classified with having autistic traits. For instance, when the score obtained by an individual using AQ is larger than or equal to 32, the presence of autistic symptoms is indicated. In addition, the experience and knowledge of the clinician or the user undergoing the test (in case of self-administered) plays a part in the performance of the outcome [13].
One promising direction to enhance ASD screening performance (accuracy, sensitivity, and specificity) is to replace the scoring function with an objective and intelligent mechanism such as machine learning. Using this approach, individuals undergoing the screening will be classified using predictive models derived by studying valuable hidden patterns from previously labelled cases and controls. Therefore, the sole decision of classification will be by the domain expert exploiting the predictive models. This process will minimise the subjectivity while assisting clinicians and other stakeholders (such as parents, patients, caregivers, etc.) by offering objectivity for the classification decisions. Physicians and other medical experts will be able to utilise these intelligent models to quickly refer cases for further in-depth clinical evaluation and provide a more accurate rationale for diagnoses of individuals exhibiting above average skills within a particular domain.
Autism screening can be considered as a binary classification since the goal is to forecast whether individuals exhibit autistic traits based on predefined behaviour features (questions/items in the screening method) as shown in Fig. 1. This research investigates the applicability of a machine learning mechanism for ASD traits detection, primarily DNNs. These are advanced and powerful machine learning techniques that have the ability to learn complex non-linear relationships between many dependent and independent variables [14]. Since DNNs have not been widely studied in ASD behavioural research (i.e. [6, 15]), the proposed methodology of utilising DNNs will not only make screening tools more accurate but will also dramatically change the design of future clinical tools. When the neural network is embedded in the self-assessment tool, valuable knowledge is derived for the users while guiding the process of correct classification selection decisions in a more efficient manner.
Detecting autistic traits as a classification problem in machine learning.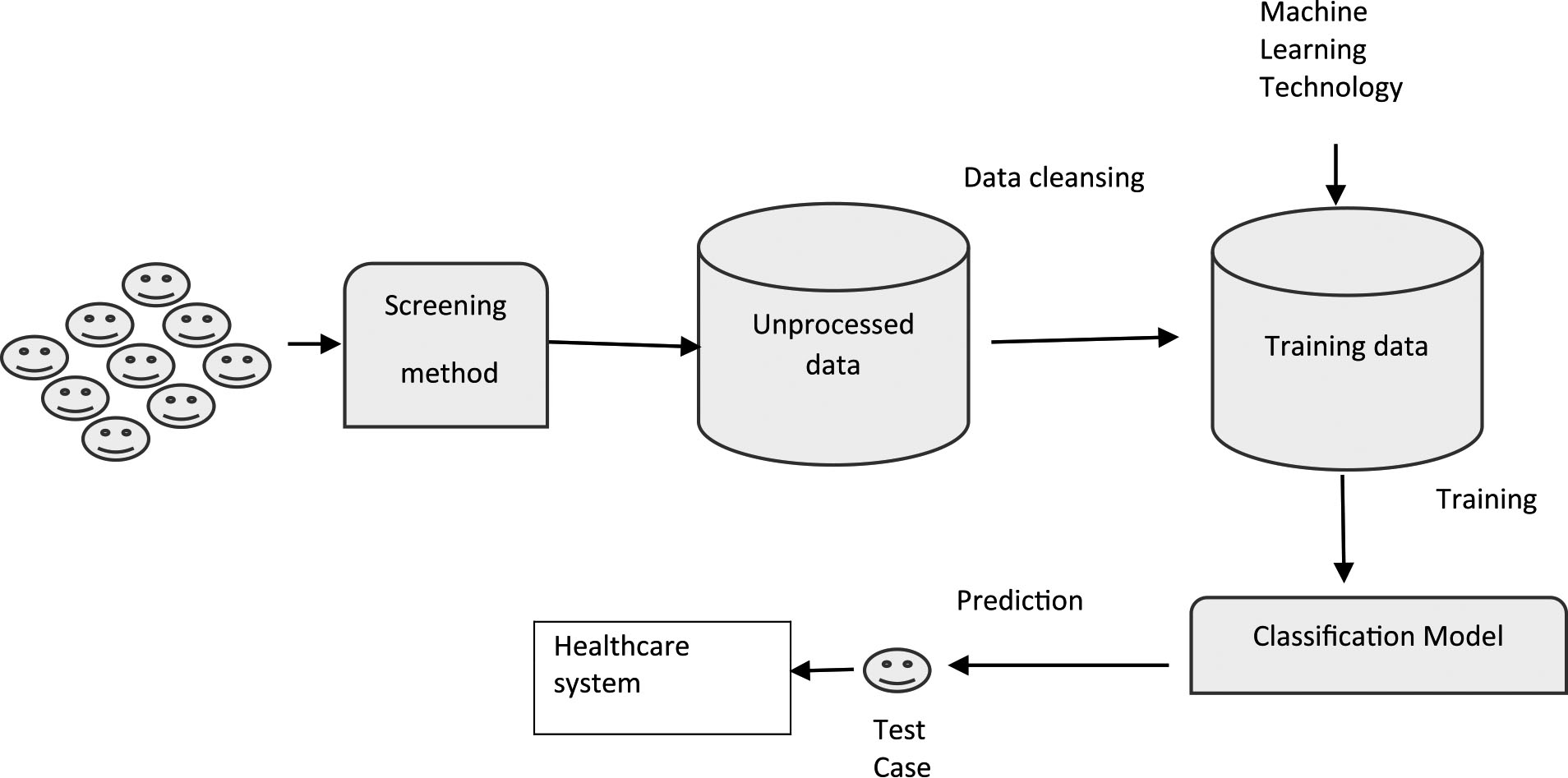
sAnother contribution of the study is to better understand what components contribute to an efficient data-based ASD screening tool that may be used by health professionals. More specifically, to establish a self-administered ASD screening method that reliably and accurately provides relevant feedback to patients, caregivers, and medical professionals for professional diagnostic services. The main research question that this paper investigates is:
Can DNNs improve ASD screening in terms of accuracy, sensitivity, and specificity when compared to other intelligent machine learning methods?
This paper is structured as follows: Section 2 critically reviews research works in the literature that adopt machine learning technology in autism research. Section 3 explains data and behavioural features and describes the experimental setup, while results are provided in Section 4. Lastly the conclusions are provided in Section 5.
Kosmicki et al. [11] investigated the impact of different machine learning techniques to improve the efficiency of conventional autism screening and diagnosis methods. They used data from the Simplex Simon Collection (SSC) version 15 [17] to differentiate between ADHD and autism cases. After processing the dataset, classifiers that were derived from the various machine learning techniques showed a reduction in the number of features – especially by Logistic Regression classifiers when compared to those of Random Forest. Despite the reduction of the features, there was no clear mechanism for distinguishing cases of ADHD from those of ASD. Likewise, Wall et al. [18] applied a number of machine learning algorithms to reduce the number of items in ADOS-R modules. After investigating the results of a decision tree algorithm, the authors claimed that out of the 29 items of ADOS-Revised (module 1), only eight features appeared in the classification system and therefore concluded that the 29 items could thus be replaced with just eight items. However, a later study by Bone and his colleagues [10] showed serious conceptual and implementation pitfalls with this study.
Kosmicki et al. [11] also presented an intelligent system to differentiate autism cases using a subset of autistic behaviours under the DSM-V. The study evaluated items within the ADOS diagnosis method to achieve its objectives. The intelligent system in this study consisted of four modules based on the language and developmental levels of the subjects. The initial assessment of the first module of ADOS, conducted by a certificated clinician in a clinical setting, suggested that approximately 27% of the subjects were left undiagnosed until the age of eight years old. Therefore, the researchers incorporated Support Vector Machines (SVM) on the second and the third modules of the ADOS with the use of stepwise backward feature selection. Data obtained from 4,240 individuals from several datasets were employed to evaluate the stepwise backward feature selection and the SVM algorithm. The results of the experiments demonstrated that 9 out of 28 behavioral dimensions can be captured through the ADOS module 2 incorporated with the SVM results, whereas module 3 can capture 12 out of 28 behaviours. Likewise, module 3 exhibited 96–97% accuracy in determining the risk of ASD in the considered sample population and reduced the number of individuals left undiagnosed by offering 97% sensitivity. Module 2 was also reported to have a sensitivity of 96.81% and specificity of 89.39%, after the SVM adaptation.
ASD can be characterised by neuroanatomical variations in different regions of the brain, but there have been few studies focused on individual subject features of neuropsychiatric disorders. Addressing this issue [19], investigated machine learning usability to understand the relationship between structural covariance features and autism symptomology using the inter-regional thickness correlation of the individuals. Through advertising, they recruited 82 cases and 84 controls of autism who were examined at the Institute of Psychiatry, Kings College London, the Autism Research Centre, University of Cambridge, and the Autism Research Group, University of Oxford using the ADOS and Autism Diagnostic Interview-Revised (ADI-R ASD) diagnostic tools [20]. Magnetic Resonance Imaging (MRI) data required to identify the relevant regions of the brain were obtained from the 3T systems at the three designated centres. The FreeSurfer analysis suite [21] was used to obtain average inter-regional thickness values related to each weighted MRI. The results of the study demonstrated a clear relationship between structural covariance of different brain regions and the presence of autism symptomology. The relationship between structural covariance of the left hemisphere regions of the brain was revealed to have a stronger impact than the left hemisphere regions on autistic behaviours. Even though the study did not address the clinical suitability of the machine learning classifiers based on different functional regions of the brain, it provided some evidence on machine learning applicability in discriminating the symptoms of various neuroanatomical impairments.
ASD is heterogeneous in nature and the treatment requirements vary significantly with individuals. In this respect, Vellanki et al. [22] studied how to identify learning patterns of different autism cases to personalise the educational curriculum. This study presented a method of learning patterns through data collected using a TOBY play pad. Since there was a large number of variables covering different types of skills, simulation, and languages, understanding the number of patterns accurately was challenging. To overcome this issue, the study adopted the Linear Position Gamma model (LPGM) [23], a Bayesian non-parametric factor analysis, and Indian Buffet Process (IBP) [24] to create intervention skill for subgroups of children. The authors evaluated the methodology on a dataset of 542 cases and derived 26 latent factors by repeating the same process 2,000 times. These latent factors established the relationship between individual children and their designated learning patterns. The investigation revealed similarities in the children based on their respective learning patterns that remained relatively stable over time. The findings of the study can help to personalise the computer-assisted learning syllabus with enhanced learning opportunities in children’s development areas, identifying the causes by grouping children with similar learning patterns.
Abbas et al. [6] developed an ASD screening instrument for young (
Liu et al. [9] proposed a machine learning system to predict ASD symptomology through the eye movement patterns of individuals. Initial experiments were carried out on two target groups of Chinese children. The first group consisted of three subgroups: 20 ASD children, 21 age-matched typically developing (TD) children, and 20 IQ matched TD children. Similarly, the second target group consisted of 19 ASD, 22 IQ-matched Intellectually Disabled (ID), and 28 age-matched TD young adults and adolescents. The eye movements and gazing patterns of each assessed subject was captured through a Tobii T60 Eye Tracker [27]. The images captured were analysed using k-means clustering to identify the eye gaze coordinates on the spatial domains and to divide the face into different regions. ASD cases are expected to be differentiated based on the magnitude and directions of both the eye gaze coordinates and eye motion.
George and Joseph [28] employed a model similar to ‘Bag of Words’ to document the sequence of coordinates per image per person. To divide the face into regions based on clusters of gazes, two types of histogram presentations were used. The first one was a hard histogram to capture the frequencies of the gazes, and the other was a soft histogram to capture the gazes falling on the border of two identified regions. Then the prediction models were developed using SVMs to avoid negative data and to identify linear decision boundaries. Finally, subject level predictions with a global threshold were enabled as a scoring framework to interpret functional margins and decision boundaries. However, findings of the experiments showed a greater potential and effectiveness in the proposed system for identifying symptoms of ASD.
Alwakeel et al. [8] introduced a machine learning-based electronic security alert system with wireless sensory devices that could recognise the child’s gestures and motions. This was to help parents protect their child from potential hazards since children diagnosed with autism often get injured or exposed to danger due to communication difficulties and/or neglect. The authors discussed the concepts, elements, functions, architecture, and operations of the proposed hazard control system. The system was named Autistic Child Sensor Network (ACSN) and comprised a wearable sensor, a mobile parental application, and also home automation system with an intelligent algorithm. Both wearable sensory device and parental app were connected with the home automation system, fixed at home and had the ability to facilitate communication between the devices. The home automation system can detect a hazardous situation and turn on any designated electronic device to distract the child away from his present position. To perform this task, ACSN’s three components were equipped with a GSM/SMS modem, GPS sensor, temperature sensor, heartbeat sensor, repetitive and undesired movement sensor, sound sensor, real time operating system, ambient controls, and an intelligent battery control with inductive charging and low battery special handling facilities. All these devices gather data to measure and define possible abnormal autistic events and process them through a machine learning algorithm to set threshold values. When an event violates the threshold and the values set by a machine learning algorithm is experienced, sensors are stimulated and warn the other devices through the operating system.
The autism and developmental disabilities network (ADDMN) [7] conducted an annual survey on 8-year-old children diagnosed with autism in the USA to determine whether they met the ASD surveillance criteria through the careful evaluation of obtained data by the clinicians. Since the sample population size kept increasing rapidly, it became more challenging for ADDMN to carry out this task manually. Therefore, [29] presented an intelligent-based automated system that embedded a modified Random Forest classifier for ADDMN to determine the surveillance criteria of the observed population. Data provided by [30] obtained from 1,162 children was used to train the Random Forest classifier. Autism criteria based on DSM-IV-TR [31] and its protocols were fed into the classifier. To maintain the reliability of the classifier’s output, a clinician was also employed for additional review. The classifier used words and phrases to identify the autism case status, and the Bag of Words approach was adopted to capture the words, phrases, and their frequencies. The Random Forest algorithm was then used to subgroup the identified words/phrases and to perform the actual classification. Finally, the developed system was tested on the dataset to determine the validity of the system in discriminating children who did not meet ASD surveillance criteria with children who met the criteria. The results indicated the validity and acceptability of the proposed system offering 84% sensitivity and an 89.4% predictive rate.
Guillen et al. [32] applied a number of machine learning algorithms fed by survey questionnaire-based databases of the medical records of autistic individuals to provide a better insight on autistic traits to discover the subtypes of autism. The Autism Research institute’s (ARI) E2 survey database was comprised of the medical data of children born after 1960. The data were processed through a four-step procedure to find sub-categories of autism. The first step was modelling the data by adapting the text format such as Attribute Relation File Format (ARFF). The second step involved identifying the appropriate clustering machine learning techniques to simplify the database characteristics. Through a careful analysis of data and available machine learning techniques, Expectation Maximisation (EM), and Minimum Message Length (MML) algorithms were chosen to optimise the data clustering process. The EM algorithm was used for probabilistic clustering, maximising the marginal likelihood and MML was integrated with the WEKA data mining tool to reveal the clustering performance. After obtaining the EM and MML algorithms’ results, the clusters were processed by applying the RIPPER classification algorithm [33] to extract simple rules that might explain the subtypes of autism. The results of the study identified nine different subtypes of autism through the RIPPER classification systems and the clusters obtained by the EM and MML methods.
Thabtah and Peebles [34] developed a classification algorithm based on the rule induction approach to detect autistic traits at preliminary stages. The authors implemented a classification algorithm that generates simple yet influential knowledge that can be used to reveal correlations among autistic symptoms and response variable (having potential autistic traits). The reported results showed that the classification algorithm was able to predict autistic symptoms with high accuracy when contrasted with classification models derived by decision trees and other rule induction approaches, at least on the datasets considered.
Methods
Datasets
ASD data related to children, adolescents, and adults was collected using a recently developed mobile application for autism screening called ASD Tests [35]. The data is publicly available from the University of Irvine repository and was collected after obtaining an ethical approval from the University of Huddersfield in the United Kingdom. The screening app used for collecting the dataset consists of four modules based on autism screening methods (Q-CHAT-10, AQ-10-Child, AQ-10-Adolescent, AQ-10-Adult) [36]. The app was developed to expedite the screening process and to cover a larger target audience. Here, individual experiments were conducted on adult, adolescent, and child datasets, excluding the toddler dataset since it has less than 2% of instances on the spectrum and was imbalanced with respect to the target variables (i.e. ASD traits).
The data were originally obtained after ethical approval from the University of Huddersfield by its prospective authors. According to Thabtah [35], and prior to completing the assessment in the ASD Tests app, it was ensured that participants consented to a disclaimer regarding privacy policy, anonymity, research background, and the use of the data. All data collected are anonymous and there was no direct contact with participants. More importantly, the app clearly stated the terms of use of the data and all participants had to agree before submitting any answer to the behavioural questions.
Table 1 shows the main features for each dataset. In particular, features A1-A10 correspond to the actual questions in the AQ-10-Child, AQ-10-Adolescent, and AQ-10-Adult autism screening methods, respectively. Differences were found in A1-A10 features in each dataset since they belong to different screening methods and target a different audience.
Features in the child, adolescent, and adult datasets
Features in the child, adolescent, and adult datasets
Details of variables mapping to the screening methods

Footnotes
Conflict of interest
The authors declare that they have no conflict of interest.