
Abstract
BACKGROUND:
Lung cancer (LC) is a harmful malignant tumor and potentially lethal illness. Therefore, early detection of LC is an urgent need, and dependent on the type of histology and the type of disease. The use of deep learning algorithms (DL) is required to analyse the histopathology images of LC and make treatment decisions accordingly.
OBJECTIVE:
This study aimed to apply pretrained EfficientNetB7 model to facilitate the process of classifying LC histopathology images as primary malignancy categories (adenocarcinoma, squamous cell carcinoma and large cell carcinoma) for early treatment of LC patients. Also, aims to analyse the performance of the proposed model using the accuracy measure.
METHODS:
The dataset of 15000 histopathology images of lung cancer were examined. EfficientNetB7, a special type of convolution neural network (CNN), pretrained with ImageNet for transfer learning were trained on this dataset. Accuracy metric was used for the evaluation of the proposed model.
RESULTS:
The feature extraction was performed by applying transfer learning using EfficientNetB7 as pretrained model. The proposed model achieved 99.77% accuracy, while previous studies model achieved over 90 to 99% accuracy.
CONCLUSION:
The employment of CNN based EfficientNetB7 model for the classification of LC based on histopathology images can speed up the diagnosis of LC and reduce the burden on pathologists for the early treatment of patients.
Introduction
Lung cancer is the second most malignancy, the leading killer-cancer worldwide and accounting for the highest mortality rates among both men and women [1]. Microscopic investigation, such as biopsy, and electronic modalities, such as CT, Ultrasound, and others are used to examine cancer tissue. Histological classification is essential for pathological investigation of cancer and has recently become critical for the selection of treatment methods based on different sensitivities to chemotherapy and radiotherapy by subtype of lung cancer [2].
Lung cancer is classified histologically into two types: non-small cell lung cancer (NSCLC) and small cell lung cancer (SCLC). As shown in Fig. 1, small cell lung cancer (SCLC) is the most common cancer type; NSCLC is the second most common cancer type, accounting for 85% of the remaining 15% are SCLC. NSCLC subtypes include adenocarcinoma, squamous cell carcinoma, and giant cell carcinoma [3, 4].
Schematic diagram showing major histological classifications in lung cancer.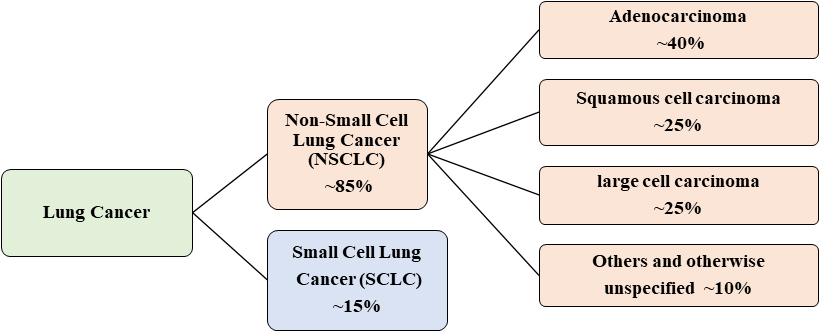
Identifying early LC remains challenging due to the difficulty in distinguishing patients with accurate classification of massive lung cancer data. Fortunately, the digitization of histopathological slides is shifting the way pathologists work and allowing artificial intelligence (AI) to integrate with traditional laboratory workflows. Machine learning technology combined with medical information technology has increased the accuracy of disease prediction using predictive models generated from disease-related learning data [5]. However, since complex data is analyzed, a deep learning technique is required [6, 7].
Most of the deep learning computations in cancer screening are performed by convolutional neural networks (CNNs). Deep learning algorithms use an image as input and assign learnable weights and biases to each object or element inside the image, allowing it to be identified. As a result, CNN processing is faster.
In practically all types of cancer diagnosis, researchers have utilized both DL and non-DL based learning methods. According to a survey conducted by Alboaneen et al. [8], the majority of histopathological image-based research yielded outcomes that were more than 90% correct. It implies that histopathological images carry significant information. This could considerably help image categorization. Because our work focuses on lung cancer diagnosis domain, we examine and describe in detail some of the most significant studies published in recent years based on histopathology lung image dataset.
In 2019, Mangal et al. proposed the CNN framework for classifying colon and lung Malignancies based on histological images using shallow neural network classifier [10]. The results showed that the proposed technique produced higher accuracy of 97% and 96%, respectively. Kumar et al. compared the DenseNet-121 image feature extraction for lung and colon cancer histopathology in 2022. When compared to previous CNN pre-trained networks, this empirical study discovered that using micro links improved the network’s accuracy and efficiency. Chehade [15] used medical imaging to study colon and lung cancer subgroups. The proposed method employed the XGBoost model, which achieved 99% accuracy and a 98.8% F1 score. In 2020, Sarwinda suggested a classifier for the analysis of deep feature extraction for colon cancer using a DenseNet-121 pretrained network [12]. It was determined that their model attained 98.53% accuracy and 98.63% recall for the result. Hatuwal et al. [11] suggested a CNN classifier for the lung tissues categorization model based on lung cancer dataset. The proposed model achieved the classifier with 97.20% accuracy, 97.33% recall, and 97.33% precision. In 2021, Wang et al. built a deep learning-based Python tool to detect cancer image types. In their proposed technique, they used the CNN model and the SVM algorithm. The SVM model’s total accuracy was 94% [14]. Masud et al. [9] presented a framework for employing DL techniques to classify colon and lung histology pictures. Using two types of domain modifications, this study obtained four picture categorization feature sets. After this, properties of the two features sets are merged to get final categorization result using DL with 96.33% accuracy. Kumar et al. [13] compared the DenseNet-121 utilized for lung and colon cancer histopathology image feature extraction in 2022. This empirical investigation found that using tiny links improved the network’s accuracy and efficiency when compared to other CNN pre-trained networks. Chehade [15] used medical imaging to study colon and lung cancer subgroups. The proposed method used the XGBoost model, which achieved 99% accuracy and an F1 score of 98.8%.
The study’s primary goal is developing a CNN model to classify lung cancer from the histopathology image dataset to achieve the high levels of accuracy. The goal of this work is to save time and help patients suffering from lung cancer by analyzing the categorization of lung cancer using CNNs deep learning methods and lung cancer histopathology images. To summarize, a CNN-based lung cancer prediction model for detecting lung cancer has been proposed.
The lung cancer histopathology image dataset 2020 [16, 17] was used to find lung-cancer related health data. First, feature extraction was performed by applying transfer learning using EfficientNetB7 as pretrained model. Second, EfficientNetB7 was used to test a CNN model of lung cancer classification using transfer learning. Finally, the performance of the model for the training and testing datasets has been analyzed and gives a very high classification accuracy of 99.77%.
The proposed model simulations were conducted on a computer with an Intel(R) Xeon(R) Platinum 8259CL CPU @ 2.50GHz processor and 32GB of RAM, running on the Windows 10 operating system. Python 3.9 compiler and Anaconda were utilized as the development environment for data pre-processing and analysis, along with TensorFlow 1.14 and Keras 2.3 as the necessary libraries. At the end of 2 hrs 45 mins and 24 s training and validation process was successfully completed. Additionally, to optimize the developed mechanism, a brief description of the datasets and implementation hyperparameter settings were provided in the following subsections.
Dataset collection
The suggested work aims at the classification of lung cancer using histopathology images. The proposed model trained and tested using the LC25000 dataset [16], which was developed by Borkowski et al. [17]. The dataset has been confirmed and is HIPAA (Health Insurance Portability and Accountability Act of 1996) compliant [17].
HIPAA is a federal law that mandated the development of national standards to safeguard sensitive patient health information from being revealed without the patient’s knowledge or consent. The providers of the Lung dataset [17] claim that every image is de-identified, HIPAA compliant, validated, and freely accessible for download by AI researchers.
Table 1 displays the elements of the LC25000 dataset as well as the corresponding class labels. The normal lung tissue image and the lung cancer tissue collected from the LC25000 dataset are shown in Fig. 2.
Contents of the LC25000 lung cancer dataset and the assigned class labels
Contents of the LC25000 lung cancer dataset and the assigned class labels
Sample images of (a) Normal lung tissue image (b) lung adenocarcinoma, (c) lung benign tissue, and (d) lung squamous cell carcinoma.
There are 25000 color images in the dataset of which 15000 images cover the three categories of lung cancer samples and 10000 images for colon cancer samples. Since the proposed work focuses on the lung cancer domain, the lung cancer images with three categories namely Lung Benign Tissue (normal cells), Lung Adenocarcinoma, and Lung Squamous Cell Carcinoma (both are cancerous cells) datasets are utilized for this work. The original images image obtained are only 15000 images in total and the size of the images are 768x768 pixel, where each category gets 5000 each.
This section explains the deep learning-based classification method for lung cancer diagnosis that has been proposed. The development of automatic lung cancer detection using histopathology lung cancer digital images is becoming increasingly important. To create this model, we used the CNN with pretrained EfficientnetB7 model. The preferred strategy is shown in Fig. 3.
Model framework.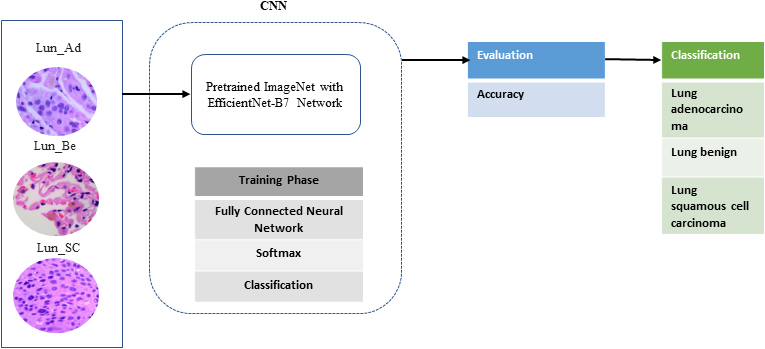
CNNs are one of the most commonly utilized models in medical imaging technologies, particularly for cancer image data screening. CNN analyzes a large number of similar-sized images of the research center [18, 19, 20, 21]. As a result, all images were shrunk to 224 by 224 pixels before being shared with CNN. The lung cancer image dataset [16] has been divided into 80% of the images for training and 20% of the images for testing.
Pretrained model
Generally, the CNN model takes an image as input and assign learnable weights and biases to the image feature set for the classification. CNN processing is, therefore, quicker than other categorized techniques. EfficientNet is one of the most powerful CNN architectures. ImageNet in Keras is a large collection of image data categories [22]. The pretrained models in Keras such as EfficientNetB7 which is trained on ImageNet.
EfficientNet-B7 model architecture [22].
Figure 4 depicts the architecture of the seven blocks. It employs a compound scaling strategy to boost network depth, width, and resolution, yielding good capacity over a wide range of benchmark datasets while using fewer computational resources than earlier models [23].
EfficientNet is capable of a wide range of image classification tasks and also good model for transfer learning. Training EfficientNet on ImageNet takes various resources and several techniques that are not a part of the model architecture itself. When the model is intended for transfer learning, Keras implementation provides an option to remove the top layers. This option excludes the final Dense layer and replacing the top layer with custom layers allows using EfficientNet as a feature extractor in a transfer learning workflow. Figure 5 depicts the architecture of the CNN model we used to solve our classification challenge.
Architecture of the CNN model with EfficientNet-B7 for the proposed research.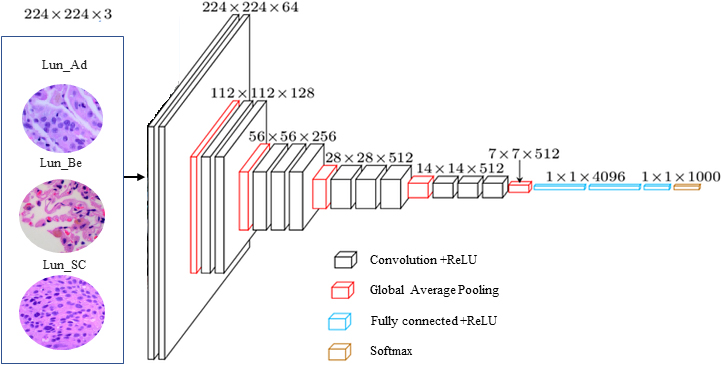
There are 15000 lung cancer histopathological images. It has been split into training and testing in the ratio of 80%, 20% respectively. The image size has width, height, and depth 224
The output of the pretrained model has a global average pooling layer and three dense layers with one flatten layer. Global average pooling (GAP) generates one feature map for each appropriate category of the dataset. The classification operation is performed in the last convolution layer. Figure 6 shows an example of GAP operation.
Global average pooling operation.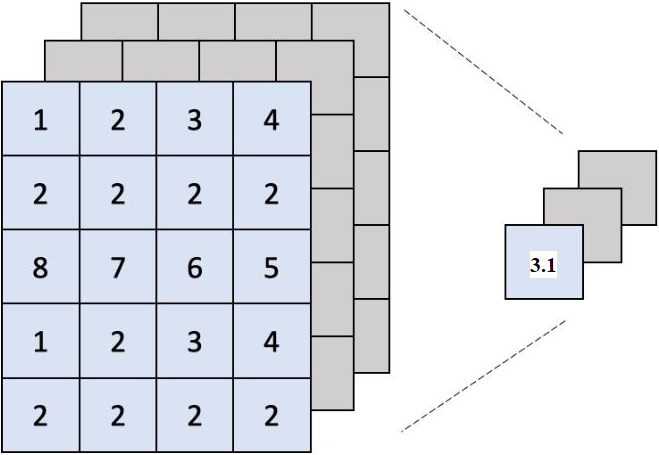
Because GAP sums up the spatial information, it is more resistant to spatial translations of the input. As we can see GAP is a structural regularize that expressly requires feature maps to be category confidence maps. By imposing correspondences, GAP over completely connected layers becomes more organic to the convolution structure. In the GAP between feature maps and categories, there is no parameter to tune. As a result, at this layer, overfitting is avoided. Feature maps are generated by pretrained model. As the proposed model does not involve any segmentation work on the input image, GAP has been used to do the averaging on the confidence map of each category. The confidence map is a probability density function on the new image, assigning each pixel of the new image a probability, which is the probability of the pixel color occurring in the object in the previous image.
The feature maps of the final convolutional layer are vectorized and fed into fully connected layers, which are subsequently followed by a SoftMax layer. The convolutional layers are treated as feature extractors, and the resulting feature is classified as usual. The SoftMax layer (output layer) of the suggested approach is modified with the number of our classes set to three.
We tested our model’s performance using accuracy. The proposed model was tested using the classification confusion matrix and accuracy (Table 2).
Description of metrics
Description of metrics
True positive (TP) means the patient has the condition and the test was positive. True negative (TN) indicates that the patient is healthy with a negative test result. A false negative (FN) indicates when negative samples are incorrectly expected to be positive. False positive (FP) refers to when positive patient samples are incorrectly anticipated to be negative.
In this study, we propose a classification method based on EfficientNetB7, a special type of convolutional neural network. The method focuses on the establishment of a classification model with transfer learning EfficientNetB7 to achieve automatic classification of lung images. The detail of the method is shown as a pseudo-code in Algorithm.
Results and discussion
The proposed model was built with TensorFlow environment. Table 3 shows that the system is trained on a scale of 768x768 pixels image to 224x224 pixels using a batch size of 128 and 50 epochs. The weights that EfficientNetB7 pre-trained on ImageNet are used to begin training and are fine-tuned later. Also, to optimize the developed mechanism, implementation hyperparameter settings are provided in Table 3. Table 3 offers further information on the CNN model used to classify histological cancer images. Because we are working with a balanced dataset (each class has the same number of samples), the model’s decision-making will be less prone to bias. For training, the ADAM optimizer with a learning rate of 0.001 and a categorical-cross-entropy loss function is utilized. The accuracy metric is used to assess the proposed model’s performance in a classification task.
Properties of the employed CNN model
Properties of the employed CNN model
Sample epochs data with training loss, test accuracy
To obtain the result displayed in Table 4, the proposed model is qualified and evaluated repeatedly (
Accuracy and loss results of the proposed model.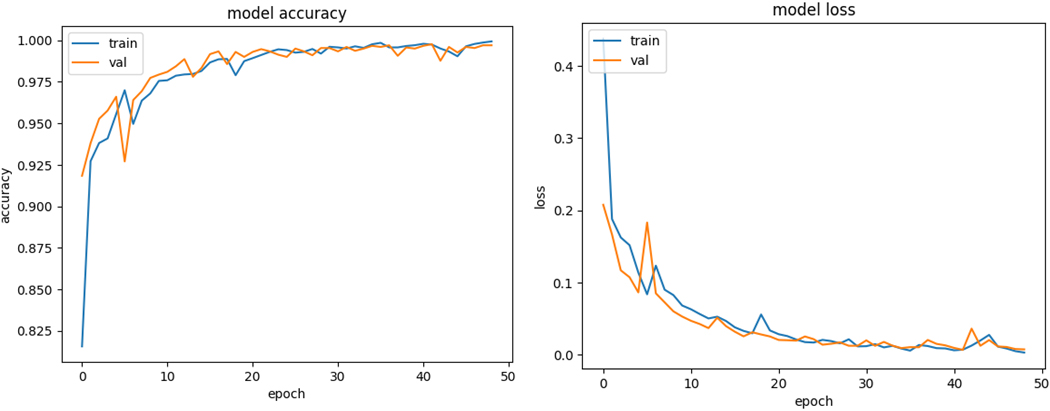
Confusion matrix.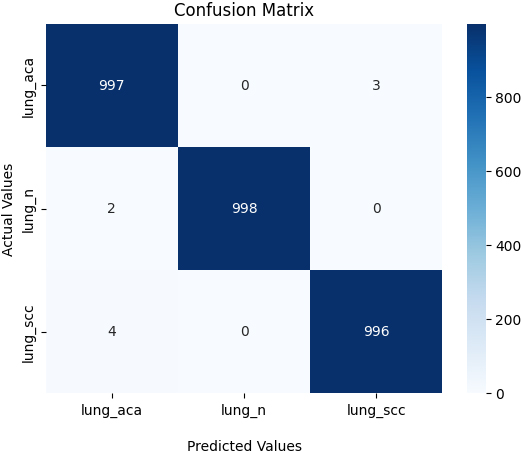
The best training accuracy during epoch 42 was 99.77%, which is comparable to the accuracy of the preceding epoch of 99.67%. The testing accuracy curve resembles the training accuracy curve in that the outcome improves as the training progresses. After 20 epochs, the curve drops to 98.77%, indicating that the model may offer a reasonable classification result even with fewer epochs.
The testing accuracy curve is similar to the training accuracy curve, with the outcome improving as the training proceeds. The curve reduces to 98.77% after 20 epochs, suggesting that the model may provide a reasonable classification result even with fewer epochs.
The training accuracy curve increased gradually and almost steadily towards the top, as shown in Fig. 7. At epoch number 43, the greatest training accuracy was 99.77%. In addition, the training and validation loss graph, which represents the percentage of data loss for each classification attempt (Fig. 7). Confusion matrix results (Fig. 8) is given to show the pre-trained models’ results in the classes’ training process.
When examining the confusion matrix, the numbers corresponding to the diagonals are expected to be the highest number in that row. High numbers on the diagonal mean that the result is good. The suggested model was tested against other approaches for lung cancer classification using the same dataset (Table 5). As shown in Table 5, our model outperforms existing lung cancer detection models in terms of maximal classification accuracy. Model accuracy is calculated based on confusion matrix values. The confusion matrix obtained for this study is given in Fig. 8. TP means the patient has the condition and the test was positive. TN indicates that the patient is healthy with a negative test result. FN indicates that negative samples are incorrectly expected to be positive. FP refers to when positive patient samples are incorrectly anticipated to be negative. TP and TN values are used for calculating the accuracy.
Comparison of the acquired results with other methods
This work explores the automatic detection and categorization of lung cancer in histopathology images using a deep learning system. For detecting lung cancer images and classifying them as normal or abnormal, the CNN algorithm and EfficientNETB7 were used. The dataset [17] used in this study were histopathological lung cancer images. The model has an accuracy of 99.77%, whereas earlier research’ models had an accuracy of 90 to 99%, demonstrating that the provided strategy is effective for tackling lung cancer classification difficulties. In the future, we intend to improve the classification model’s architecture by developing additional sets of features from more histopathological images.
Author contributions
Conceptualization, M.A.; Methodology, M.A.; Software, M.A., P.B.; Formal analysis, G.K.; Investigation, G.K.; Resources, S.A.S.A.; Data curation, M.A., S.M.B.; Writing – original draft, M.A.; Writing – review & editing, P.B., S.A.S.A. and S.A.M.; Supervision, M.A.; Project administration, M.A., S.A.S.A.; Funding acquisition, M.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research is financially supported by the Deanship of Scientific Research at King Khalid University (research grant number: RGP1/335/44).
Data availability statement
Online data sources from Kaggle are used throughout the study:
Footnotes
Acknowledgments
The authors extend their appreciation to the Deanship of Scientific Research at King Khalid University for funding this work through Small group Research Project under grant number RGP1/335/44.
Conflict of interest
The authors declare that there is no conflict of interest.