
Abstract
Ensemble learning plays an important role in big data analysis. A great limitation is that multiple parties cannot share their knowledge extracted from ensemble learning model with privacy guarantee, therefore it is a great demand to develop privacy-preserving collaborative ensemble learning. This paper proposes a privacy-preserving collaborative ensemble learning framework under differential privacy. In the framework, multiple parties can independently build their local ensemble models with personalized privacy budgets, and collaboratively share their knowledge to obtain a stronger classifier with the help of central agent in a privacy-preserving way. Under this framework, this paper presents the differentially private versions of two widely-used ensemble learning algorithms: collaborative random forests under differential privacy (CRFsDP) and collaborative adaptive boosting under differential privacy (CAdaBoostDP). Theoretical analysis and extensive experimental results show that our proposed framework achieves a good balance between privacy and utility in an efficient way.
Introduction
In the age of big data [36], it is valuable to investigate the methodologies of big data analysis, so that the custodians of such big data can make decision by estimating useful knowledge extracted from data. For example, facial images are captured in surveillance videos to trace the escaped criminals [23]. Amazon collects the text and images of clothing purchased by millions of customers to mine styles of fashionable dresses. Based on historical loan records, banks give credit scores to applicants and decide if loans should be issued [5].
Ensemble learning [26] is one of machine learning paradigms where multiple models jointly solve a particular problem. In contrast to ordinary approaches which try to learn one hypothesis from training data set, ensemble learning tries to construct a set of hypothesises and combine them. This strategy is primarily used to improve the performance of the model, or reduce the error of one hypothesis. Ensemble learning is very in line with classification. It has already applied to diverse applications, such as predicting potential side effects of drugs [38], detecting visual concept of web images [29], or exploring appropriate rules for stock trading decision [20].
However, ensemble learning may disclose individual privacy if data is shared among organizations or submitted to public commercial cloud [33]. For example, electronic health records [14] generally contain patients’ data such as demographics, diagnostics, medications and nursing problems. Most of them are extremely sensitive to patients. If those data had been exposed to adversary, it would have brought incalculable losses. Considering this risk, most of organizations have no choice but to build its decision support system with limited available data. Thus, there is a contradiction between preserving individual privacy and having sufficient data for modeling then making decision.
There are existing work on privacy-preserving ensemble learning [1,18], and they give specific solutions, but these proposals do not fully address the key problem of how to share knowledge securely and efficiently among multiple parties. The work in [1] discussed differentially-privacy random forests, and compared three variants of the algorithm: majority voting, threshold averaging and probabilistic averaging. Even when privacy guaranteed, majority voting rule is an excellent candidate because it is less sensitive to the choice of parameters. The recent work [18] of adaptive boosting developed a distributed protocol to mine healthcare data. But it would disclose the information of the model. Therefore, a practical privacy-preserving ensemble learning solution is still deficient.
In this paper, by introducing differential privacy, we propose a privacy-preserving collaborative ensemble learning framework. Under this framework, we present the differentially private version of two widely-used ensemble learning algorithms: collaborative random forests under differential privacy (CRFsDP) and collaborative adaptive boosting under differential privacy (CAdaBoostDP). The goal of our work is to build an effective collaborative decision support system that can share knowledge among multiple parties without revealing personal sensitive information. In our framework, each party trains its own classifier by ensemble learning with its local data, and the useful knowledge extracted from classifier is then transferred to a central agent without disclosing the sensitive data. Our approach integrates these classifiers at the honest-but-curious central agent under privacy constraints.
Compared with existing work, our solution has the following salient advantages. First, with a central agent, our solution reduces computation and communication cost dramatically for the overall system. Our framework avoids to transfer data directly among multiple parties. Each party uploads and receives integrated model from the central agent, and there is no interaction between parties. Second, we regard the threat model of central agent as honest-but-curious instead of trust. Therefore, our framework is practical in the sense of security assumption. Third, our approach provides flexible configuration of privacy budget for each party. When faced with sensitive data, different users have different levels of privacy expectations. But most of existing literatures set a universal standard without catering for users’ personalized needs. The consequence is that we may be offering insufficient protection to a subset of people, while applying excessive privacy control to another subset [34].
Our main contributions are summarized as follows.
We propose an ensemble learning framework under differential privacy, and it is applicable to any concrete algorithm that follows ensemble learning concept. The framework focuses on the scenario that multiple parties in ensemble learning have to share knowledge with each other, but do not want to disclose their own private sensitive data.
Our framework is efficient in terms of complexity and practicality in terms of security assumption. By utilizing a central agent, our framework only requires model exchange instead of data set. It not only significantly saves the cost of computation and communication, but also ensures minimized privacy breach and maximized utility. We also treat the central agent as honest-but-curious, and design a simple yet effective integrating approach to integrate local models.
We consider personalized differential privacy. Our proposed framework allows privacy budget to be specified at party level, so each party in our framework can control privacy budget by itself. It provides significantly better performance than the existing solutions.
We conduct theoretical analysis and extensive experiments on real credit card clients data set to evaluate the effectiveness of our proposed framework, and the results illustrate that a satisfactory tradeoff between privacy and utility can be achieved simultaneously.
The rest of this paper is organized as follows: In Section 2, we provide related work on privacy-preserving data mining, especially for ensemble learning. In Section 3, we give necessary preliminaries on ensemble learning and differential privacy. In Section 4, we formulate the problem and system, as well as the security model considered in this paper. In Section 5, we propose the ensemble learning framework under differential privacy in detail. Section 6 and Section 7 give theoretical analysis and experimental results, respectively. Section 8 concludes the paper.
Notations
Notations
In this section, we first give a very brief overview of privacy study in data mining, and then discuss related work on privacy-preserving ensemble learning.
Privacy-preserving data mining
The time has witnessed the development of privacy-preserving data mining, from K-anonymity [30], L-diversity [21] to T-closeness [17]. K-anonymity ensures that individuals cannot be uniquely re-identified in a data set and thus guards against linking attacks. However, the adversary with background knowledge can infer sensitive information about individuals even without re-identifying them. L-diversity requires that each equivalence class has at least l well-represented values for each sensitive attribute, but it does not consider semantic meaning of sensitive values. T-closeness [17] requires that the distribution of sensitive attribute in any equivalence class is close to the distribution of that in the overall table, but it fails to prevent identity disclosure. Differential privacy [6,7] guarantees that the distribution of noisy query result changes very little with the addition or deletion of any record. It has applied to support vector machine [28], location-based services [9], correlated data publication [4], high dimensional data publication [37], etc.
Privacy-preserving ensemble learning
Random forests with differential privacy was first observed in [15]. The authors presented a differentially private decision tree ensemble algorithm using the random decision tree, but they did not estimate the quality of differentially-privacy algorithm. In [32], encryption-based method was developed securely to construct random forests and distributed strategy was proposed for knowledge discovery. In [31], the random response idea was used to mix set of data instead of generalization, but it was only appropriate for binary attribute. In [27], the authors discussed the quality function of decision tree, and they stated that information gain, max operator and Gini index had almost same effect on accuracy regardless of sensitivity towards noise. The recent work [1] provided strong theoretical guarantees of both non-differentially private and differentially private random forests. The result was that majority voting and threshold averaging had better accuracy than probabilistic averaging.
Compared with random forests, adaptive boosting with privacy constraints has rarely been researched. Gambs et al. [12] first proposed privacy-preserving boosting data mining algorithms: BiBOOST and MultBOOST. The algorithms allowed two or more parties to construct a boosting classifier without sharing their own data sets. However, the main problem there was that each party’s optimal classifier had been exposed potentially at merging step through anonymous broadcast. In [8], the authors used boosting for arbitrary low sensitivity query. The latest work in [18] exhibited a distributed protocol based on the adaptive boosting strategy, but its integration process required plenty of communication cost and existed potential risk of leaking model information.
Preliminaries
This section gives preliminaries closely related to our work, including classification and regression trees, ensemble learning and differential privacy. We first introduce the notations in Table 1.
Classification and regression trees
Classification and regression trees [19] are methods for constructing predication model for data. The model is obtained by recursively partitioning the data and fitting a simple predication model within each partition. It can be visualized with a decision tree. CART [3] is one form of classification and regression trees, which splits node by exhaustively searching over inputs and finds best branch attribute variable based on Gini index [24] minimization principle. CART first grows a complete large tree and then prunes it to a smaller one to make an estimate of misclassification error minimized. CART employs cross-validation method to compute error rate. We formally define process of generation and pruning of CART as follows:
Ensemble learning
Ensemble Learning refers to learning a combination of base hypotheses. Its goal is to strength the capability of base model. Suppose we have gained T CARTs, each is denoted as (Ensemble learning [25]).
Random forests
Random forests [2] algorithm is an ensemble learning method. It consists of a collection of decision trees where these trees are independently constructed, and each tree gives the same weight vote for input to predict class variable. Random forests include training and predication phases. It first takes a bootstrap sample from training data set and builds decision tree using sample. After a number of trees are generated, they vote for the majorities.
Random forests algorithm outperforms many models in computational speed, due to the inherent property of random partition employed in tree generating process. Randomness is introduced so that random forests model is not easily overfitting. Random forests are able to support parallel operation easily.
Adaptive boosting
Adaptive boosting (AdaBoost) [11] is one of ensemble learning algorithms which iteratively generates a strong classifier from a pool of single weak classifiers. In each iteration, a classifier is learned, and based on the correctness of the prediction in previous round, the weight distribution of training data set is updated. Such that, in the subsequent iteration, the classifier will focus on the misclassified records in previous iteration. The final classifier is a weighted combination of those classifiers.
AdaBoost provides a way of combining multiple base classifiers whose combined performance is significantly better than that of any of the base classifiers, and does not require feature selection before training. It can also avoid overfitting, but the time complexity is a little higher than base classifier.
Differential privacy
Differential privacy is a novel technique providing privacy-preserving noisy query answers over statistical databases [16]. It guarantees that the distribution of noisy query answers changes little with the addition or deletion of any record. The goal of differential privacy is to answer queries over sensitive data sets without compromising the privacy of individuals, whether their records are in data sets or not.
(ϵ-Differential privacy [7]).
A randomized function
The probability is the risk of privacy disclosure and it is controlled by function
In order to achieve differential privacy, two standard techniques, Laplace mechanism [7] and exponential mechanism [22], have been proposed in the literatures. A fundamental concept of these two mechanisms is global sensitivity that maps a database to real values.
(Global sensitivity [7]).
For any function
Laplace mechanism is proposed in [7], which takes as inputs a data set, a function f, and a privacy budget ϵ and returns the true output of f plus some Laplace noise. The noise is drawn from a Laplace distribution. Formally, for a given function
Exponential mechanism [22] is useful for the analysis whose outputs are not real after adding noise. It selects an output r from the outputs
Problem statement and system model
In this section, we state the problem considered in this paper and its challenges, as well as the involved system model and security model.
Problem statement
We consider the problem of privacy-preserving collaborative ensemble learning in this paper. Specifically, multiple parties hold their own data sets respectively, or they get a part of data sets from a data set pool. They want to collaborate with others and use ensemble learning to obtain better predictive performance, but they do not want to publish their own data sets directly for their privacy concerns, so each party runs ensemble learning on their own data sets locally. The question is: how they can obtain better predictive performance through ensemble learning in collaborative and distributed way and protect the privacy of each party at the same time?
This problem is prevalent in practice because knowledge sharing between multiple parities is often an essential requirement due to limited amount of storage space or computing power. A case is that several hospitals have a patient’s electronic health records corresponding to diverse symptoms. Patient will be able to obtain better treatment through comprehensive consultation if these medical records should have been shared. Similar scenes also frequently occur in other industries. In age of big data, traditional single machine is far from enough to cope with trillion or even more data, so distributed architecture is necessary to mine data. Efficiently integrating data from local ones is a must in this case, but we have to concern the privacy.
Challenges
There are mainly two challenges of solving the problem of privacy-preserving ensemble learning. On one hand, the computation complexity or communication cost maybe unaffordable when privacy is considered in ensemble learning. For example, one solution is that each party can send the encrypted data or the model to others, but it will introduce large computation workloads at each party or heavy communication overheads between parties. On the other hand, it is hard to meet the personalized privacy requirements. Because different parties may have different privacy concerns, it is a challenge to provide flexible privacy budget for each party in ensemble learning while getting a satisfactory integrated model.
System model
The system model of our solution is demonstrated in Fig. 1. Each party is responsible for building local ensemble model and transferring it to a central agent. Central agent integrates those local models to obtain the integrated model, and distributes it to all parties. Moreover, any party can upload his latest model again if he refines the local model with new data set.

The system model.
In our security model, in the worst case, the adversary knows all the data except for the inferred record, and all the records in the database are independent of each other. We further have three assumptions on this system model. First, the threat model of central agent is honest-but-curious, meaning that central agent exactly follows the proposed protocol, yet attempts to learn private information from its received data. Second, central agent owns powerful computing power to complete any complex operations. Third, each party has different privacy expectations for same scheme that subjects to the identical distribution.
Collaborative ensemble learning under differential privacy
In this section, we first give the framework of our proposed collaborative ensemble learning under differential privacy. Under this framework, we then propose the differentially private versions of two widely-used ensemble learning algorithms: random forests and adaptive boosting. Finally, we present our integration and distribution mechanisms at central agent for collaborative ensemble learning. The implemented framework on random forests and adaptive boosting are called collaborative random forests under differential privacy (CRFsDP) and collaborative adaptive boosting under differential privacy (CAdaBoostDP).
Framework
Now we introduce our framework of collaborative ensemble learning under differential privacy. As shown in Fig. 2, the framework includes four prime components:

Framework of collaborative ensemble learning under differential privacy.

CARTGenDP

CARTPrunDP
CART is a simple and efficient base classifier for ensemble classifier such as random forests and adaptive boosting. The structure of CART contains branch attribute variables and class variable. To publish CART, we must prevent these critical contents from leaking out. Therefore, we design a differentially private CART to solve this problem.
The basic idea of our proposed differentially private CART is adding noise to each node of the decision tree. The amount of noise is decided by a given privacy budget. We still follow the principle of CART, namely, generation and pruning. In the process of tree generation, more Laplace noises are added to the nodes that are closer to the leaf nodes. Algorithm 1 presents the details of generating CART under differential privacy (CARTGenDP), and Algorithm 2 presents the pruning process (CARTPrunDP).
Specifically, suppose a party allocates its privacy budget
Random forests under differential privacy
In this section, we propose a method of introducing differential privacy into random forests. The basic idea is intuitive: we utilize the proposed differentially private CART in previous section as the base classifier in random forests.
Differentially private random forests include two phases:

RFsDP
In this section, we propose a method of introducing differential privacy into another widely used ensemble learning algorithm: adaptive boosting (AdaBoost). The basic idea is also utilizing the proposed differentially private CART as the base classifier to build a boosting classifier.
Differentially private adaptive boosting includes two phases:

AdaBoostDP
When all parties build their local ensemble classifiers (i.e. RFsDP or AdaBoostDP in this paper), they must collaboratively and secretly construct integrated classifier over global data set with the help of central agent. In our proposed framework, each party sends differentially private ensemble model to the central agent instead of local data set for privacy concerns. Upon receiving local ensemble classifiers from all parties, the central agent integrates them to obtain the final classifier.
The weight of each local ensemble classifier in integration is determined by its accuracy and the proportion of its training data set to global data set. For example, when a party has very little amount of data, the accuracy of the trained classifier may be high enough probably due to overfitting. Therefore, we design the weighting function

Integration
After the integration, the central agent should distribute the final classifier to all parties to obtain a better performance on prediction. It is easy to distribute integrated classifier to all parities via network. Each party can also continually update its local ensemble classifier based on new data sets and periodically upload it to central agent to improve the performance of integrated classifier. Furthermore, if a new party enrolls in the system, he can contribute his local ensemble classifier to the central agent and only the integrated one needs to be updated and distributed again, or he can share the integrated classifier from the central agent directly.
We now give a further discussion on how to make the integration computation more secure. By now, our proposed solutions can ensure each party’s privacy of local ensemble model and data set, but each party should send the accuracy of local ensemble classifier
Theoretical analysis
In this section, we give theoretical analysis on our proposed solution, including privacy, utility, computational complexity and communication cost.
Privacy analysis
We analyze the privacy protection of our proposed scheme in three aspects: base classifier CART, ensemble classifier, and integrated final classifier.
First, we explain the privacy gained by CART. For our proposed differentially private base classifier CART,
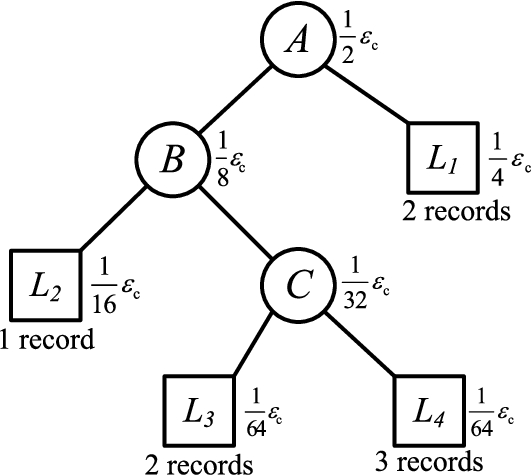
A differentially privacy CART and the privacy budget allocation to each node. Branch nodes are represented by circle, while leaf nodes by square.
Next, we analyze the privacy of each ensemble classifier. For a party with personalized privacy requirement
Last, we analyze the privacy constraint of integration at the central agent. Let
We analyze the utility of category aggregates between original and perturbed data. We use the widely-used root mean square error (RMSE), defined as
Time and communication costs
In this section we analyze the time and communication costs of our proposed differentially private ensemble learning algorithms. Table 2 tabulates the results for a clear view.
Time and communication costs
Time and communication costs
The time cost of our proposed schemes CRFsDP and CAdaBoostDP mainly involves two parts: building local ensemble model and model integration. Suppose
The communication cost of CRFsDP and CAdaBoostDP is the sum of payloads that each party sends to and receives from the central agent. Suppose
Configuration
We implement the proposed CRFsDP and CAdaBoostDP by Python programming language on an Intel i7-4510U PC with 8 GB RAM. We set
Data set
The experimental data set comes from the UCI machine learning repository [35]. The original data was from a famous bank and the targets were credit card holders of the bank. Table 3 is a brief description of 23 attributes in data set, and the class variable is binary which indicates that credit card holder is credible or not. The 80% of data set are used to train and the rest are for test.
Attributes description for credit card data set
Attributes description for credit card data set
In our experiments, we also evaluate the performance of a classifier by area under an ROC curve (AUC). Receiver operating characteristics (ROC) curve is useful to organize classifiers and visualize their performance, and area under an ROC curve (AUC) can reduce ROC performance to a single scalar value representing expected performance [10]. The value of AUC is between 0 and 1, and a value closer to 1 indicates better generalization capability of a classifier.
Results on different maximum CART height

Results on different maximum CART heights under the same privacy budget for each party.
We first explore the effect of maximum CART height on the performance of integrated classifier. In order to facilitate the demonstration of experimental results, we set same privacy budget for each party. In our experiment, we set the maximum height of CART
An obvious trend in Fig. 4 is that, given a fixed privacy budget ϵ, the values of
Different levels of privacy budgets
Different levels of privacy budgets
Then we analyze the effect of personalized privacy budget on the performance of classifier given a fixed height of CART. According to the analysis in previous section, we set
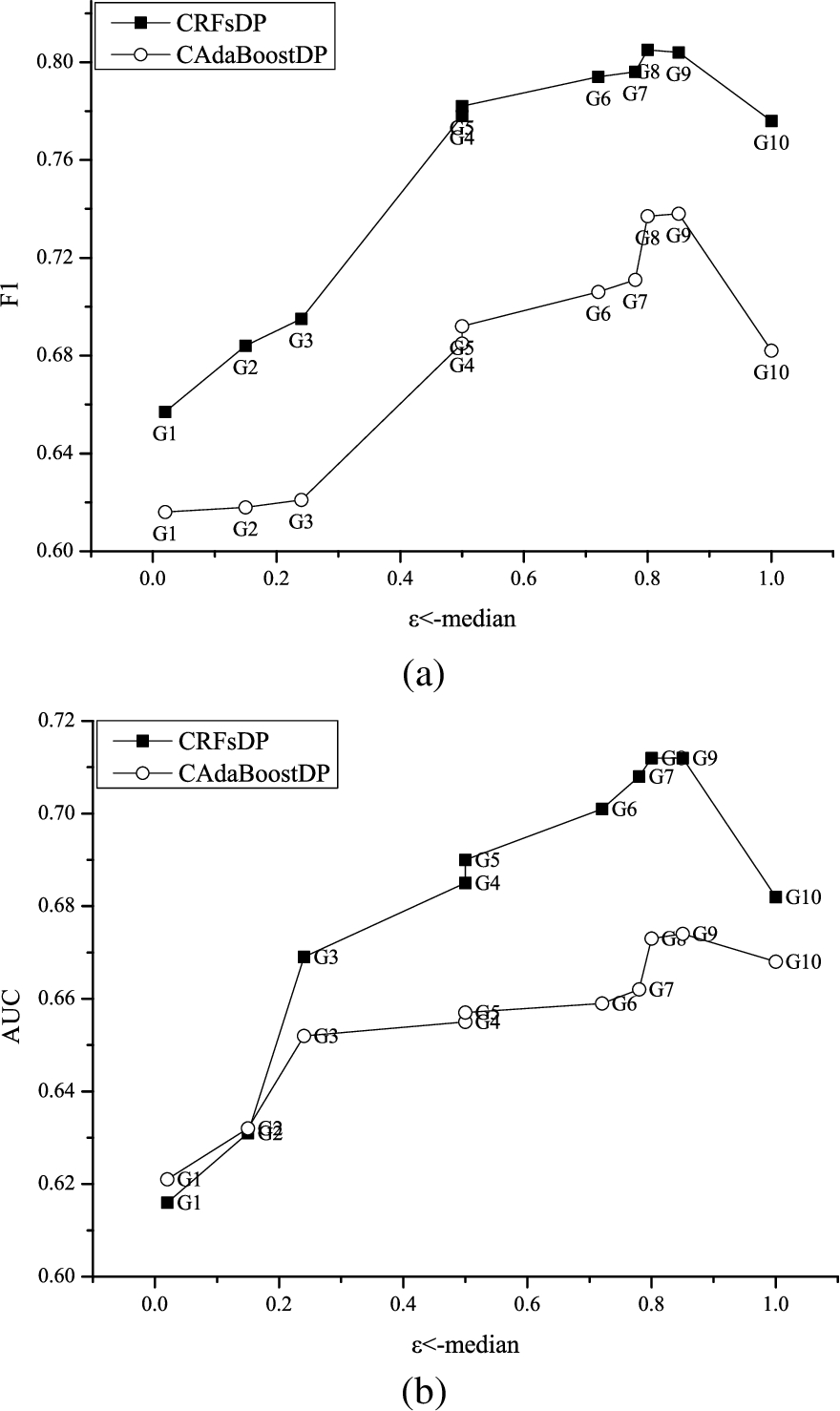
Results on different levels of personalized privacy budgets. The median of privacy budgets for each group is used to measure privacy level.
From Fig. 5, the values of

Results on execution time of the system under different numbers of parties.
Finally, we discuss the relationship between numbers of parties taking part in system and execution time of system. We set numbers of parties
In this paper, we investigate the problem of privacy-preserving ensemble learning. A framework of privacy-preserving collaborative ensemble learning based on differential privacy is proposed to provide personalized privacy protection over distributed data set. In the framework, each party builds local ensemble model and decides how much information to share with others by configuring personalized privacy budget. All parties send their differentially private models to the central agent to get final stronger integrated classifier. We also implement the framework on two widely-used ensemble learning algorithms: random forests and adaptive boosting. Theoretical analysis proves that the proposed scheme satisfies
Footnotes
Acknowledgements
The work in this paper was supported by the National Natural Science Foundation of China (No. 61672118), the Fundamental Research Funds for the Central Universities (No. 106112016CDJZR185513), and the Graduate Scientific Research and Innovation Foundation of Chongqing, China (Nos. CYS15029 and CYB16046).