
Abstract
A crowd sensing network takes the use of the dense distribution, frequent encountering, and social property of mobile terminals in real society. In a crowd sensing network, the datasensing transmission is based on the collaborative opportunistic transmission, the final message data will be forwarded to the user who is willing to report data (e.g. high battery capacity and with low-cost Internet link equipment), and then report the perceptual data to the backdrop data center. In the mobile crowdsensing network, there is a big difference in the social ability of each node carrier, so that the data forwarding capability of each node is also different. In this paper, we first analyze the shortcomings of node based on node quantization. On these grounds, this paper proposes a data forwarding mechanism based on node function and node centricity, and gets its performance improved effectively, and reduces the energy consumption of nodes.
Introduction
With the widespread popularity of mobile intelligent terminal devices, the mobile terminals (such as smart phones, tablet personal computers, etc.) owned by people have integrated a variety of mobile sensors, enabling each person to get a strong sensing capability [10]. Besides, the mobile Internet (such as Wi-Fi, etc.) for data transmission is also used to form a new type of sensing network, the mobile crowdsensing networks [1]. Treating mobile sensing devices and deployed communication networks as the building foundation, mobile crowdsensing networks does not in charge of specialized deployment and post-maintenance parts, which can greatly reduce the building cost. Furthermore, the proliferation of mobile sensing devices like mobile phones, together with the regular mobility of human users, allows mobile crowdsensing networks to accomplish the massive sensing tasks at low cost. It can be seen that the research featuring mobile crowdsensing networks at present will help us to tackle the issue on cost reduction of large-scale sensing networks.
Nowadays, the unified standard of specific structure towards crowdsensing networks hasn’t been reached among all walks of life. Some researchers observe that privacy factor should be regarded as paramount consideration in order to preserve the privacy of participants; the initial data from them shouldn’t be submitted to cloud server without processing. Others argue that if participants get involved in data transactions, the heavy burden will be imposed on their mobile devices, causing the resources occupation problems. This will greatly affect their enthusiasm towards participating in sensing tasks. The typical mobile crowdsensing networks structure consists two parts: sensing platform and participants, as shown in Fig. 1.
We can see the perception layer, transport layer, as well as the processing application layer. Participating users can use smart phones (embedded sensors: GPS, gravity sensors, cameras, microphones, etc.), build-in-vehicle sensors (Vehicular GPS, ECU, etc.) or portable wearable electronic devices (such as iWatch) to collect sensed data [8], and submit them to the sensing platform, a platform users use mature mobile cellular network or Wi-Fi to communicate with.
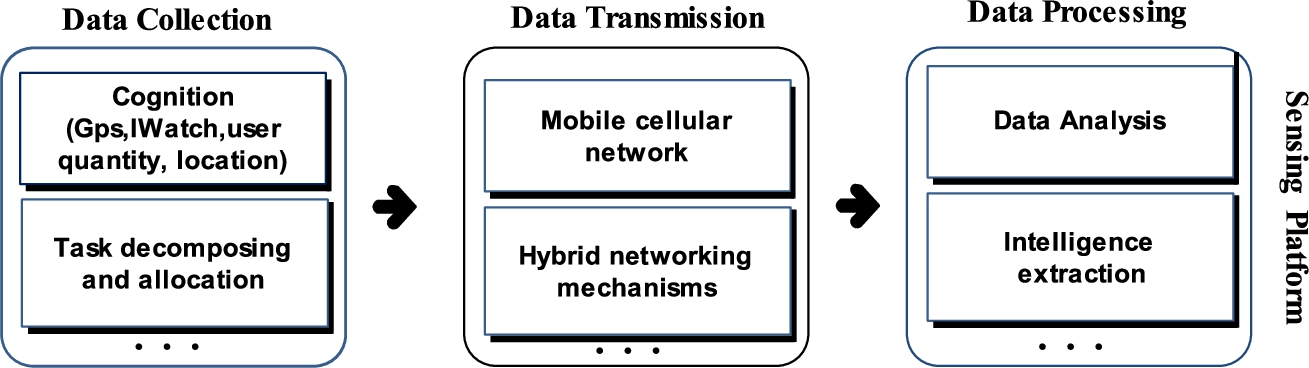
Mobile group awareness basic frames.
In the process of data transmission, when it comes to practical application, the centralized data collection model is adopted by multiple crowdsensing networks. That is, each mobile node connects to the Internet via cellular network or Wi-Fi and directly submits its own sensed data to the back-end data center. The pattern is shown in Fig. 2. Yet sensing applications often require continuous collection of large amounts of data, even large-scale multimedia data. This will consume much network flow and battery for users, leading to high data collection costs and reducing users’ participation enthusiasm.
Furthermore, assuming that the nodes are in the external environment, such as bad weather, or when there are few nodes in the initial stage of crowdsensing networks, the user’s range of activities will be severely limited, which will directly lead to a significant increase in the delay of message in data transmission process, and even fail to submit the message data successfully within the effective time.
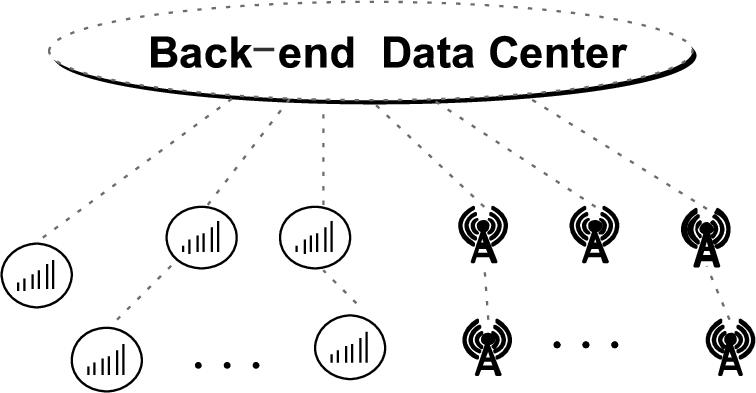
Centralized perception data reporting mode.
Considering all of the above mentioned, there are many problems in crowdsensing networks data transmission such as serious energy consumption of nodes, slow transmission of messages and increased pressure in cellular networks. All these issues, in practical application, are of high value for crowdsensing networks’ data forwarding mechanism; therefore it is necessary to design a more reasonable and efficient one. Also we can use the “opportunistic transmission” mode [2,10], “Store-Carry-Forward” mode, to transmit data in crowdsensing networks. However, there is still a challenging task left to select which nodes as transmission relays or which nodes as data reporting nodes to effectively optimize the data transmission mechanism of crowdsensing networks.
Firstly, this paper analyzes some social-based data forwarding mechanisms.
With certain social attributes, the carriers of nodes embrace some regularity in social activities; Hence the network node’s forwarding capability can be measured in the light of social attributes. Some related studies are as follows.
The key to the SimBet algorithm is to compare betweenness centrality with similarities of the network nodes to select the next-hop relay forwarding node [6].The network nodes, with high betweenness centrality, are described in SimBet algorithm and play the role of a bridge in data forwarding process.
About Social Based Multicasting algorithm, two major types of data dissemination problems contained in literature [5] are SM (Single data Multicast) and MM (Multiple data Multicast). The former is a node that sends a single message to several other nodes in the network while the latter sends multiple different messages. In order to choose the most plausible node in this two dissemination process as relay forwarding node, the researcher of this literature first describes the node’s contact process by Poisson process, then put forward the concept of using cumulative contact probability as the centrality metric, and apply this concept in quantifying the importance of a node in message transmission process. In the end, the author of the document transformed the problem of relay forwarding node in relay process into a unified knapsack problem, achieving their initial research objective: significantly reduce the forwarding times on the basis of guaranteeing the success rate of message delivery.
The Bubble Rap algorithm, proposed by literature [4], mainly discussed the comprehensive selection of relay nodes in message transmission process. The researchers of this document have proposed a variety of ways to quantify the centrality of network nodes. In the process of message transmission, the algorithm proposed in this document would choose the node with higher centrality as next-hop relay node, because the higher centrality means that the node has a greater chance of meeting more nodes, leading to greater probability to meet destination nodes and community nodes. We can see that choosing the node with higher centrality as the relay node can optimize the transmission process of a message.
In [7], the social relationship between nodes is measured by the contact frequency of the nodes. The more frequent nodes encounter, the closer the social relations is. When the contact frequency between nodes exceeds a given threshold, indicating that social relations are tight enough, and then each other will be added to the respective local cluster. In this way, each node will own a local cluster that contains close social relations nodes.
In [9], Motivated by the strong share ability of “circles of friends” in communication networks such as Facebook, Twitter, Wechat and so on, the authors take a real-life example to show that social relationships among nodes consist of explicit and implicit parts. The explicit part comes from direct contact among nodes, and the implicit part can be measured through the “circles of friends”. Based on effective measurement of social relationships, we propose a social-based clustering and routing scheme, in which each node selects the nodes with close social relationships to form a local cluster, and the self-control method is used to keep all cluster members always having close relationships with each other.
From the above analysis, we can see that with higher centrality, the average time of codes as relay forwarding nodes goes higher. (The message was successfully delivered). However, the average time of nodes with low centrality as relay forwarding nodes (message delivered successfully) has large scale as well. This shows that if use the centrality to quantify the importance of a node individually, we will ignore some nodes which could be relayed. If there is another quantized condition that can turn such this type of node into relay forwarding node, an optimization effect will be brought to the transmission of messages.
The functionality of nodes
The sensing data, under the collaboration of nodes, carry out the hop-by-hop transmission by means of “opportunistic forwarding” until message data is transmitted to a node which is available to submit data to the back-end data center. Then, this node will do the ultimate data submission process, as shown in Fig. 3.
In this paper, we propose the concept of node functionality (NF), which consists of two parts. First, avoid missing low-centrality but high-forwarding nodes. Second, judge whether the encountered node is S node or node that is easier to contact with S node. The functional value of a node is equal to the product of the centrality values of all other community nodes that meet within a time section. The functionality value can be compared to compensate for the lack of centrality only, as shown in formula (1).
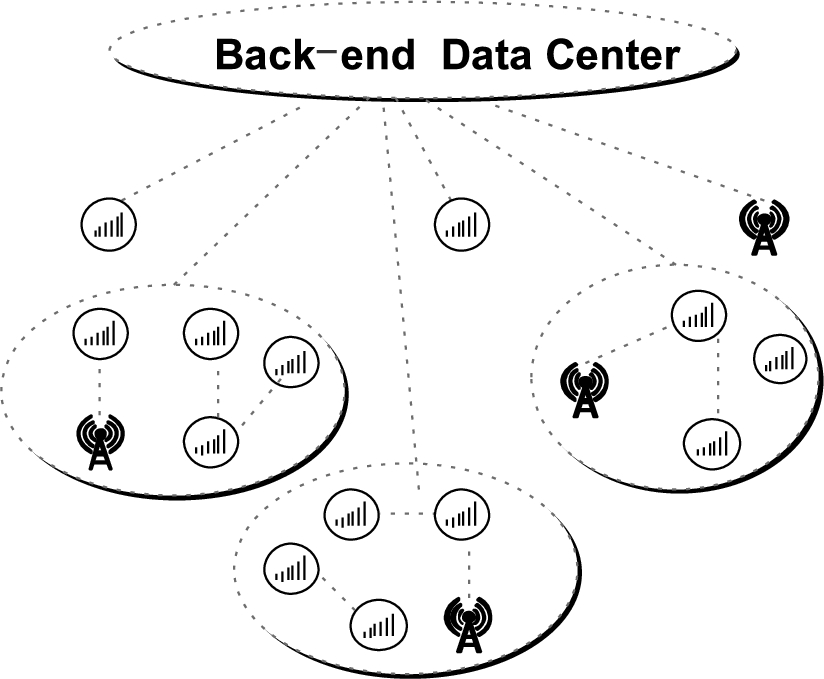
Improved perceptual data reporting mode.
Where
In this algorithm, when the message-carrying nodes meet other nodes, it need to consider the nodes centrality and functionality comprehensively to decide whether to forward or not, and transmit message data ultimately to network nodes that under the Wi-Fi environment. This will not only avoid missing the nodes that play a crucial role in data forwarding, but also reduce the average energy consumption of the network nodes, greatly optimizing the data forwarding mechanism of crowdsensing networks.
In our daily life, when a message-carrying node meets other nodes, a comprehensive decision on node’s centrality and functionality need to be made to select a relay node. According to relevant social behavior research, even though a large proportion of mobile phone users are not willing to submit the sensed data directly to the back-end data center, they are willing to forward the data to their friends through the social network for sharing. This type of nodes is called T nodes. When a node is in bad weather (such as storm, typhoon, etc.) or a situation that network node is scarce in the initial stage of network construction, and if the message carrying node is a T node, then the message data can be transmitted through the social network. The overall data transmission process is shown in Fig. 3.
Social utility metrics
When a message-carrying node encounters other nodes, a comprehensive alternative on node’s centrality and functionality needs to be made to select a next-hop relay forwarding node. Nodes with high centrality or utility are able to play the role of a bridge in network data transmission process. Nodes Betweenness Centrality: Network nodes do not move randomly, but do regular movement influenced by the carriers. We call this social nodes (The nodes mentioned in the rest of this paper are all social nodes unless given highlighted notes). It was proposed by Daly and Haahr [6] that quantifying the sociality of nodes by make use of betweenness centrality and similarities. Individuals’ nodes with high betweenness centrality come with high dominance capacity. On the network, such nodes perform better in data transmission and forwarding activities as relays. Assume that the set of nodes that node A can communicate with is represented by In social science, there have already been some confirmed conclusions: In real life, if there are multiple mutual friends between two people, this two are most likely to being friends. And the more people they both know, the more likely they are to know each other. Similarly, Watts and Strogatz proposed in [8] to describe this feature in terms of aggregation and network transitivity. Therefore, selecting this type of node as a forwarding node can improve data transmission efficiency. About nodes similarity, the node similarity is quantified by the number of intermediate nodes that both certain node and S node will contact with. If the set of nodes that have contact with node A and S node are There into On computer network, if the message source node cannot directly transmit data to node S, it is desirable to select the encountered node which has the highest probability to contact with node S, that is, if selecting the node with high utility value to act as the forwarding node, there will be a certain thing that the delay can be greatly reduced on the foundation of delivery success rate, for the reason that the node with high utility value has stronger communication and forwarding capabilities than other nodes. The utility value of nodes is expressed by both similarity factor value and betweenness centrality factor, and the value is generally less than 1 and greater than 0. Assume that the individual node A needs to transmit message data to the S node, and there is no direct communication path between these two nodes. If the node A meets another node F during the message transmission process, the node A relative to the betweenness centrality We can further conclude that the utility value ρ and σ denote the corresponding coefficients of the betweenness centrality
If a node and S are in the same community, they are more likely to encounter. And the success rate of message posting will increase if the data information is relayed by the nodes that being in the same community as Node S. In the classic Bubble Rap algorithm, Nodes with higher centrality are more likely to meet other nodes; hence this type of nodes meet Node S has greater proportion, just as same as it meets the nodes in its same community.
When message-carrying node encounter other node (not Node S), we should first compare the global node centrality values between this two nodes. If latter’s value is higher (with high global centrality, nodes are more easily to meet the nodes that being in the same community as Node S), then forward the message data to it.
If two nodes meet at the community that Node S belongs to, compare the local node centrality value of this two. If the encountered node is higher (with high centrality, nodes are more available to meet the node S), then the message data should be forwarded.
Unlike the forwarding process mentioned above, this paper makes reference to DFFC algorithm, which will consider the centrality and function of nodes comprehensively to select relay forwarding nodes. In DFFC algorithm, even if the centrality of the node is low, the node with high functionality will still be seen as relay node to forward data.
DFFC algorithm simulation experiment and result analysis
In this paper, the experimental data is used to simulate the DFFC algorithm, and then we analyze its performance. The DFFC algorithm is compared with the classic Bubble Rap algorithm in various aspects. The following parts describe the simulation process and results analysis in detail.
Simulation parameters
In this chapter, the simulation platform ONE [3] was used to compare the performance of the DFFC algorithm and the classical Bubble Rap algorithm. The experiment generated 6,000 messages randomly, and its size was evenly distributed between 10 kb and 80 kb. By default, each node’s buffer space was set to 10 MB. The main parameters of the experiment are shown in Table 1.
Simulation parameters
Simulation parameters
The success rate of message transmission
The most important goals of crowdsensing networks is submitting the message data from Node S to back-end data center in a reasonable time. The simulation experiment results of the transmission success rate of the two routing algorithms are shown in Fig. 4.
From the above figure, the message transmission success rate of the DFFC algorithm is significantly higher than that of the classic Bubble Rap algorithm.
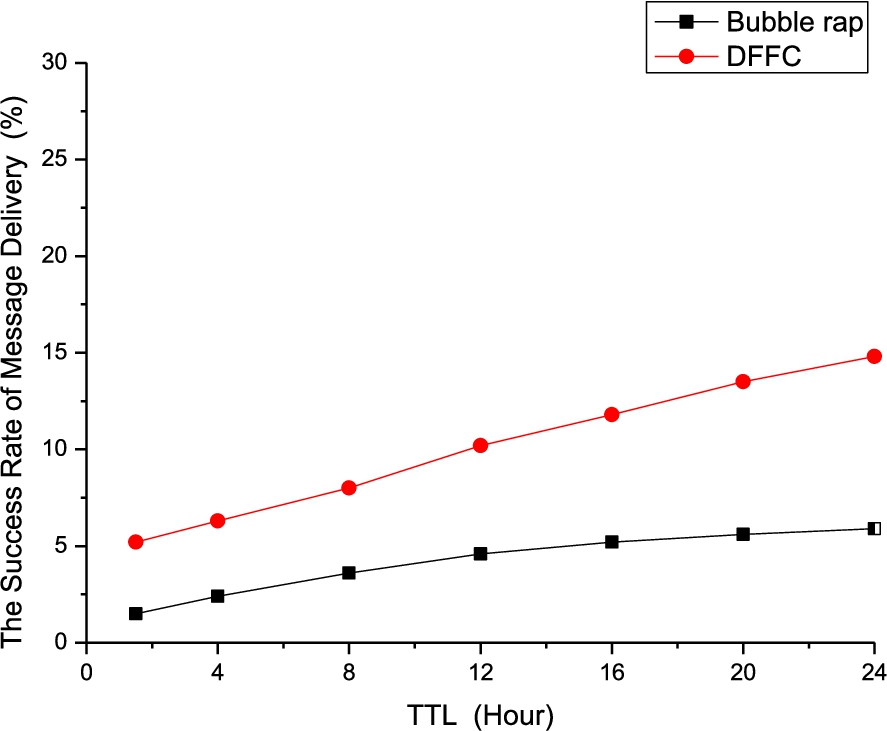
Two algorithms compare the success rate of transmission.
The average transmission delay is also a vital measurement index. It can measure the transmission capacity and transmission efficiency of an algorithm. The simulation result comparison of average transmission delay of the two routing algorithms is shown in Fig. 5.
It can be seen from Fig. 5 that under the condition of different message lifetime (TTL), the DFFC algorithm presented in this chapter has smaller fluctuation than the classic Bubble Rap algorithm. And the average transmission delay of DFFC algorithm is relatively small and much more stable.

Two algorithms compare the average transmission delay.
The routing overhead in this chapter is the ratio of the total number of messages in the entire network to the messages that have been posted to the node S. The simulation results of the two routing algorithms on message transmission costs are presented in Fig. 6.
From the figure above, it can be seen clearly that the message transmission cost of the DFFC algorithm is higher than that of the Bubble Rap algorithm. This is due to the addition of node functionality in DFFC algorithm, which allows more network nodes get involved in the task of message data transmission, improving the transmission cost of messages.
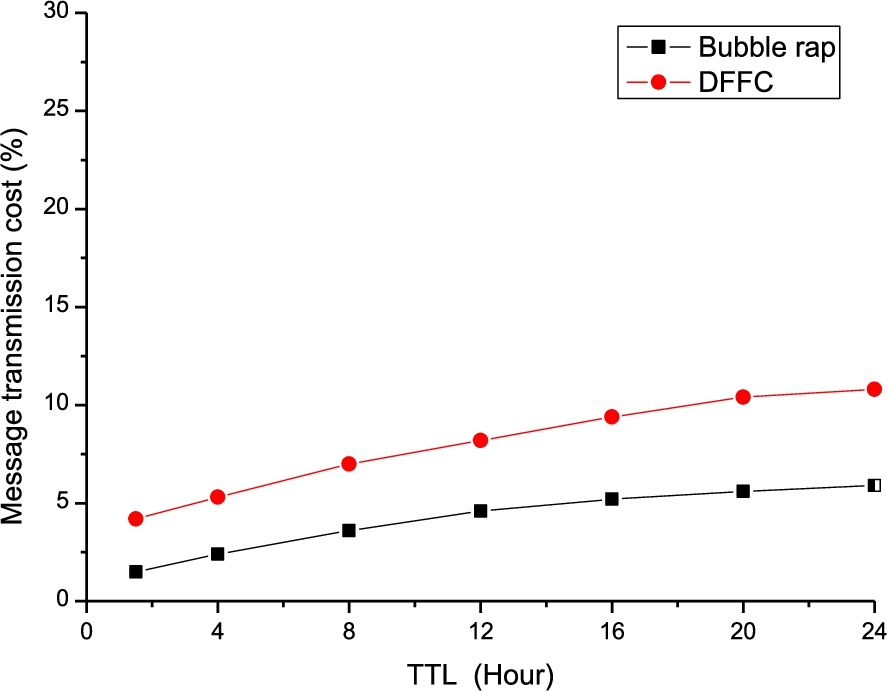
Two algorithms route cost comparison.
Most of crowdsensing network tasks belong to public service. For users, the incentives and benefits of participating in perceptive tasks are not evident enough. If the majority nodes are in the condition of high energy consumption, the enthusiasm of users who participate in sensing tasks will be directly curbed, and the coverage and availability will be influenced as well. Figure 7 shows the average energy consumption of nodes reported before and after improvement.
This data reporting process will undoubtedly increase the transmission cost of each participating user and reduce the user’s enthusiasm for participation. After the improvement, each piece of sensed data will be transmitted to the node S first, and then submitted to the back-end data center.
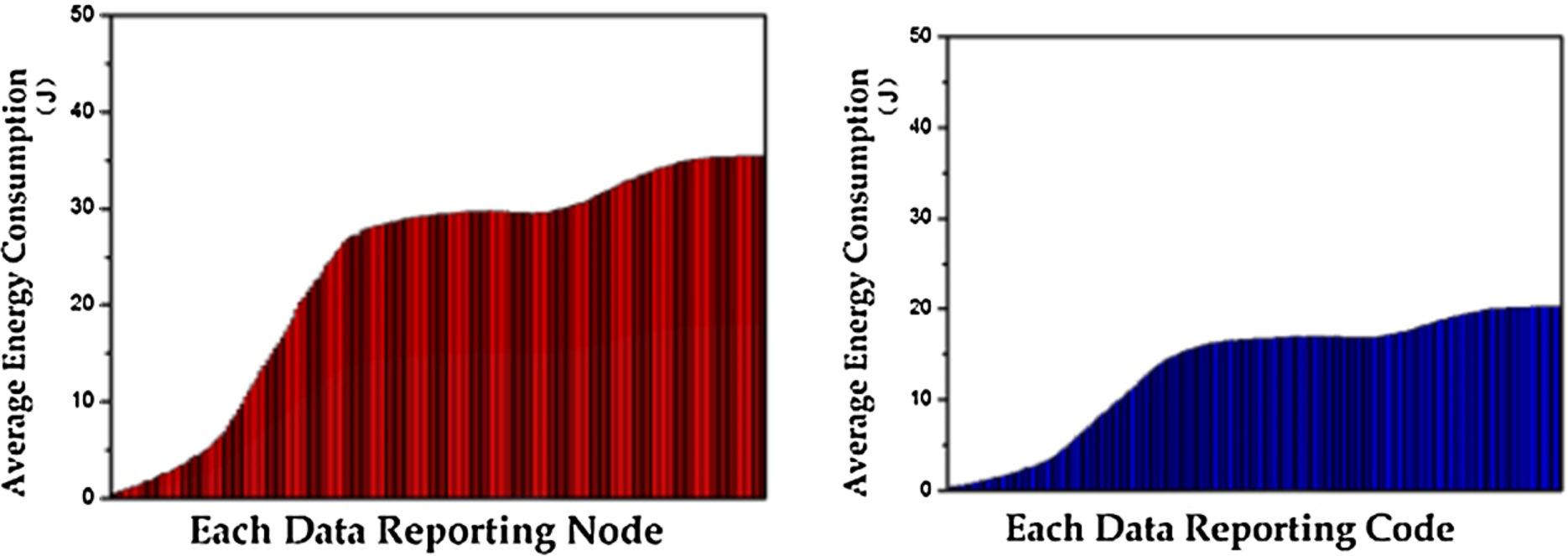
Comparison of two kinds of perceptual data reporting modes.
By analyzing the results of this simulation experiment, the success rate of message transmission and average transmission delay of DFFC algorithm is superior to that of Bubble Rap algorithm, but its transmission cost is slightly higher. Overall, the DFFC algorithm performs better than the Bubble Rap algorithm.
In mobile sensing, the “storage-carry-forward” opportunistic transmission mode is adopted to forward the data for the insufficiency of centralized data reporting. According to the further study of node-centric data forwarding algorithms, this paper proposes a Data Forwarding Mechanism (DFFC) which based upon node centrality and functionality. A comprehensive decision on node’s centrality and functionality is made to select a relay forwarding node, later on, the message is forwarded to Node S to accomplish the data message reporting process. At the end, the DFFC is compared with the Bubble Rap through simulation experiments, and then comes the simulation results: the DFFC algorithm has great optimization in the transmission success rate and message transmission delay, which can help to reduce the energy consumption of the nodes in network to a great extent.
Footnotes
Acknowledgements
This work was supported by Project 15B132 of the Hunan Provincial Department of Education (Outstanding Youth Project) and Scientific Research Fund of Hunan Provincial Education Department under project no. 14C0654.