
Abstract
Probabilistic topic models, which frequently represent topics as multinomial distributions over words, have been extensively used for discovering latent topics in text corpora. However, because topic models are entirely unsupervised, they may lead to topics that are not understandable in applications. Recently, several knowledge-based topic models have been proposed which primarily use word-level domain knowledge in the model to enhance the topic coherence and ignore the rich information carried by entities (e.g, persons, locations, organizations, etc.) associated with the documents. Additionally, there exists a vast amount of prior knowledge (background knowledge) represented as Linked Open Data (LOD) datasets and other ontologies, which can be incorporated into the topic models to produce coherent topics. In this paper, we introduce a novel regularization entity-based topic model (RETM), which integrates an ontology with an entity-based topic model (EntLDA) to increase the coherence of the identified topics through the topic modeling process. Our experimental results demonstrate the effectiveness of the proposed model in improving the coherence of topics.
Introduction
In recent years, a considerable effort has been dedicated to revealing a hidden thematic structure of high dimensional data vectors through the application of the statistical probabilistic techniques. In this context, the approaches such as probabilistic topic models have a long and successful history in statistical data analysis. Probabilistic topic models, such as Latent Dirichlet Allocation (LDA) [7] have been shown to be powerful techniques to analyze the content of documents and extract the underlying topics represented in the collection. In other words, at a very high level, in topic models, the patterns of co-occurrence of words in a text document will be discovered and the topics will be generated based on those words to describe the document. Topic models usually assume that individual documents are mixtures of one or more topics, while topics are probability distributions over the words. These models have been extensively used in a variety of text processing tasks, such as word sense disambiguation [8,19], relation extraction [39], text classification [17,21], and information retrieval [37]. Thus, topic models provide an effective framework for extracting the latent semantics from the unstructured text collection.
However, due to the fact that topic models are entirely unsupervised, purely statistical, data driven and that they cannot capture the correlations, they may produce topics that are not meaningful and understandable to humans or interpretable by applications. To cope with this problem, several knowledge-based topic models haven been proposed which are integrating prior domain knowledge into topic models. [3,4,10,20]. These models incorporate domain knowledge to improve the topic identification process and facilitate producing coherent topics. Chemudugunta et al. [10], for example, combined human-defined concepts with unsupervised topic modeling and came with Concept-Topic model (CTM). In fact, CTM extends the number of topics by adding human-generated concepts as special topics.
Andrzejewski et al. [3] proposed a model to incorporate the domain knowledge in the form of must-links and cannot-links into LDA. A must-link indicated that two words should be in the same topic, whereas a cannot-link stated that two words should not be in the same topic.
[20 ,22 ,30] introduced models that utilize prior knowledge in the form of seed words to direct the topic coherency. In [13], the author has applied Multi-Domain Knowledge that exploits multiple domains knowledge to enhance topic coherency in a new domain. [12] describes a model, called lexical semantic relations, that employs specific types of lexical knowledge.
Although the aforementioned topic model approaches use some kinds of prior knowledge, they essentially treat documents as bags of words and integrate solely word-level prior knowledge into the topic models. Furthermore, some of them make an assumption that the user knows the domain very well and can provide a proper knowledge for the domain, which not always can be applicable. Some improved version of those models have been proposed [16,28,35] to address the mentioned issues. In this context, documents are associated with richer aspects. For instance, news articles convey information about people, locations or events, research articles are linked with authors and venues, and social posts are associated with geo-locations and timestamps. In [35], the authors integrate the authorship information into the topic model and discover a topic mixture over the documents and authors. [28] proposed a model to learn the relationship between the topics and entities mentioned in the articles. In [16], authors introduced a topic model in order to link entity mentions in documents to their corresponding entities in the knowledge base.
Moreover, existing topic models do not utilize the vast amount of existing external knowledge bases which are available in the form of ontologies, such as DBpedia [6] and numerous other datasets in Linked Open Data (LOD).1
Another line of work combines topic modeling with graph structure of the data. [24] proposed a method to integrate a topic model with a harmonic regularizer [40] based on the network structure of the data. In [14], the authors introduced a topic model that incorporates heterogeneous information network. Our work differs from previous works in a way that we utilize the semantic graph of the entities in the ontology in order to regularize the topic model and discover coherent topics. The underlying intuition is that the entities classified into the same or similar domains in the ontology are semantically closely related to each other and should have similar topics. Accordingly, entities (i.e., ontology concepts and instances) occurring in a document along with the relationships between them create a semantic graph where can be combined with the entity topic model and a regularization framework for improving topic coherence.
In this paper, we propose a topic model which utilizes the DBpedia ontology to enhance the topic modeling process. Our aim is to leverage the semantic graph of concepts in DBpedia and combine their various properties with unsupervised topic models, such as LDA, in a well-founded manner. Although there are existing knowledge-based topic models [10] that use human-defined concepts hierarchies along with topic models, they basically focus on simple aspects of ontologies, i.e. associated vocabulary of concepts and hierarchical relations between concepts, and do not consider the rich aspects of ontology concepts such as non-hierarchical relations.
This general unified framework has many advantages, such as linking text documents to knowledge bases and LOD and discovering more coherent topics. We first presented our ontology-based topic model, EntLDA model, in [2] where we illustrated that incorporating ontological concepts with topic models improves topic coherence. In this paper, we elaborate on and extend these results. We also extensively explore the theoretical foundation of our ontology-based framework, demonstrating the effectiveness of our proposed model over two datasets.
In this section, we focus on some of the related concepts and definitions that we will discuss through the paper.
Semantic Web
The Semantic Web, which is defined as an extension to the current Web through the developed standards by the World Wide Web Consortium (W3C), was initiated by Tim Berners-Lee. These standards and techniques allow machines to understand and use the knowledge (semantics) behind the Web. In fact, the Web of data, (i.e., the Web with resources with relations), enables the information to be shared and reused across applications. In order to bring structure to the Web and allow information exchange across applications, the Semantic Web requires a few key technologies. In the following section, we outline a few fundamental Semantic Web technologies that are necessary for achieving the functionality previously mentioned.
Ontology
Ontologies have been designed as a way to express knowledge about a domain in the Semantic Web. Most ontologies are domain specific and are used to describe and represent an area of knowledge by integrating terms (classes) and the relations between those terms (properties). The knowledge can be understood by applications if the terms and relationships among these terms are defined clearly. It is done by applying ontology description languages such as the Resource Description Framework (RDF) with its associated Resource Description Framework Schema (RDFS) and the Web Ontology Language (OWL) to encode knowledge and semantics in the way that can be understandable by computer applications. RDFS provides a standard vocabulary that can be used to describe classes and properties in a specific domain while RDF has been designed to make statements about the domain’s resources in the form of <subject, predicate, object> triples. RDF and RDFS are the building blocks of the Semantic Web. For example, we can express the fact that “Washington is the Capital of the United States” as an RDF triple: <Washington, isCapitalOf, United States>, where its graph structure is represented in Fig. 1.

Graph structure of the example RDF statement.
Linked Open Data (LOD) is about creating typed links between data from various sources [5]. In other words, LOD is a method of publishing structured data in such a way that is interlinked with other data sources. Linked Open Data is based on the standard Web technologies such as HTTP, RDF, and URI. Tim Berners-Lee illustrated a set of rules for publishing linked data on the Web as follows:
Use URIs as the identifiers for things. Use HTTP so that the things can be looked up. Provide useful information when people look up a URI, using standards such as RDF, SPARQL, etc. Include links to other URIs, so that they can find more things.
Since Linked Open Data has been introduced, many organizations have published their datasets in the Linked Open Data format. One of the primary datasets in LOD is DBpedia[6]. DBpedia is an ontology (encoded in RDF) containing information extracted from Wikipedia and is publicly available on the Web. The DBpedia ontology is very useful and provides many advantages: it covers many domains; because it is automatically extracted from Wikipedia at regular intervals, it automatically evolves as Wikipedia changes; it is multilingual and provides localized versions in 125 languages. In all, it contains 3 billion triples out of which 580 million were extracted from the English edition of Wikipedia; because DBpedia is structured, it allows us to ask quite complex queries against its data. Hence, it should be feasible to leverage this invaluable knowledge in many data/text mining tasks. In fact, the rich knowledge sources such as ontologies in the Semantic Web have been extensively utilized in a variety of data mining and knowledge discovery tasks [9].
Probabilistic topic models
Probabilistic topic models are a set of algorithms that are used to uncover the hidden thematic structure from a collection of documents. The main idea of topic modeling is to create a probabilistic generative model for the corpus of text documents. In topic models, documents are mixtures of topics, where a topic is a probability distribution over words. The two main topic models are Probabilistic Latent Semantic Analysis (pLSA) and Latent Dirichlet Allocation (LDA). Hofmann (1999) [18] introduced pLSA for document modeling. pLSA model does not provide any probabilistic model at the document level which makes it difficult to generalize it to model new unseen documents. Blei et al. [7] extended this model by introducing a Dirichlet prior on mixture weights of topics per documents, and called the model Latent Dirichlet Allocation (LDA). In the next section, we briefly describe the LDA method.

LDA graphical model.
The Latent Dirichlet Allocation (LDA) is a generative probabilistic model for extracting thematic information (topics) from a collection of documents. LDA assumes that each document is made up of various topics, where each topic is a probability distribution over words. The graphical model of LDA is shown in Fig. 2 and the generative process is as follows:
For each topic For each document sample a topic distribution for each word sample a topic sample a word
Where α and β are parameters of the symmetric Dirichlet prior. In LDA model, as the words are generated from the topics and topics are generated from documents, the probability of a word w given a document d is defined as:
Related work
Probabilistic topic models, and in particular the Latent Dirichlet Allocation (LDA) [7] have been proved to be effective and widely used techniques in various text processing tasks. As they are naturally unsupervised and entirely statistical, they do not exploit any prior knowledge in the models.
Recently, several approaches have been proposed that integrate prior knowledge to direct the topic modeling process. For example, [3,19,20,30] apply word-level knowledge into topic models. [3] introduced DF-LDA that uses word-level domain knowledge in the form of must-links and cannot-links in LDA. A must-link indicated that two words should be in the same topic, whereas a cannot-link stated that two words should not be in the same topic. DF-LDA encodes the set of must-links and cannot-links associated with the domain knowledge using a Dirichlet Forest prior, replacing the Dirichlet prior over the topic-word multinomial distributions. In this case the user is allowed to control the strength of the domain knowledge.
Patterson et al. [30] leverages word features as side information to boost topic cohesion. The intuition is to treat word information as features instead of explicit restriction and to modify the smoothing prior over the topic distributions for words in such a way that correlation is stressed. In this way, we can learn the prior probability of how words are distributed over different topics based on how similar they are.
[20] described a topic model which uses word-level prior knowledge as the form of sets of seed words in order to find coherent topics. Seed words are user-provided words that represent the topics underlying the corpus. Seed topic information can be utilized to improve the topic-word probability distributions or it can be first transfered to the document level based on the document words and then be used for enhancing document-topic distributions, or it can be combined at topic and then document level.
Interactive Topic Modeling (ITM) [19] proposed a model that allows the user to incorporate knowledge interactively during the topic modeling process.
Some other related works include [13] which introduces the MDK-LDA model to use multiple domains knowledge to guide the topic modeling process. The knowledge is called s-set (semantic-set) and refers to a set of words sharing the same semantic meaning in the domain. In this context, each document is represented as mixture of topics whereas each topic is a distribution over semantic-sets.
In [12], the authors proposed GK-LDA, general knowledge-based model, which exploits general knowledge of lexical semantic relations in the topic model. Some of the lexical semantic relations are synonymy, antonymy, hyponymy, adjective-attribute, etc. They used synonym, antonym and adjective-attribute relations and show the advantages of utilizing these relations for discovering coherent topics.
The key point about the current approach, which is noticeable and makes it different from others, is applying ontologies as background knowledge in topic models. Although, the following works have tried to take the advantage of using ontologies in topics models but our work differs from those in the way that they use word-level prior knowledge whereas we exploit ontology concepts (i.e. concept-level knowledge) and their relationships directly in the topic model.
Boyd-Graber et al. [8] introduces LDAWN topic model which leverages WordNet knowledge for the word-sense disambiguation task. The basic intuition is that the words in a topics have similar meanings and therefore share paths within WordNet.
Chemudugunta et al. [10] describe CTM, the Concept-Topic model, which combines human-defined concepts with LDA. The key idea in their framework is topics from the statistical topic models and concepts of the ontology are both represented by a set of “focused” words and they use this similarity in their model. In [11], the authors extended the work and proposed HTCM, the Hierarchical Concept-Topic model, in order to leverage the known hierarchical structure among concepts.
In addition to the mentioned related works [14,24] combined statistical topic modeling with network analysis by regularizing the topic model with a regularization framework based on the network structure.
Our approach is somewhat similar to a few previous works, particularly [8,10,11] in terms of exploiting ontologies in the topic models and with [14,24] in terms of regularizing the topic model, yet it differs from all of them. In [8], the task is word-sense disambiguation whereas ours is to find coherent topics. CTM [10], uses tree-structured Open Directory Project2
In this paper we propose a novel entity-based topic model, EntLDA, which incorporates DBpedia ontology into the topic model in a systematic manner. In our model we exploit various properties of concepts and not only hierarchical relations but also lateral (other than hierarchical) relations between ontology concepts. EntLDA also accounts for entity mentions in documents and their corresponding DBpedia entities as labeled information in the generative process to constrain Dirichlet prior of document-entity and entity-topic in order to effectively improve topic coherency.
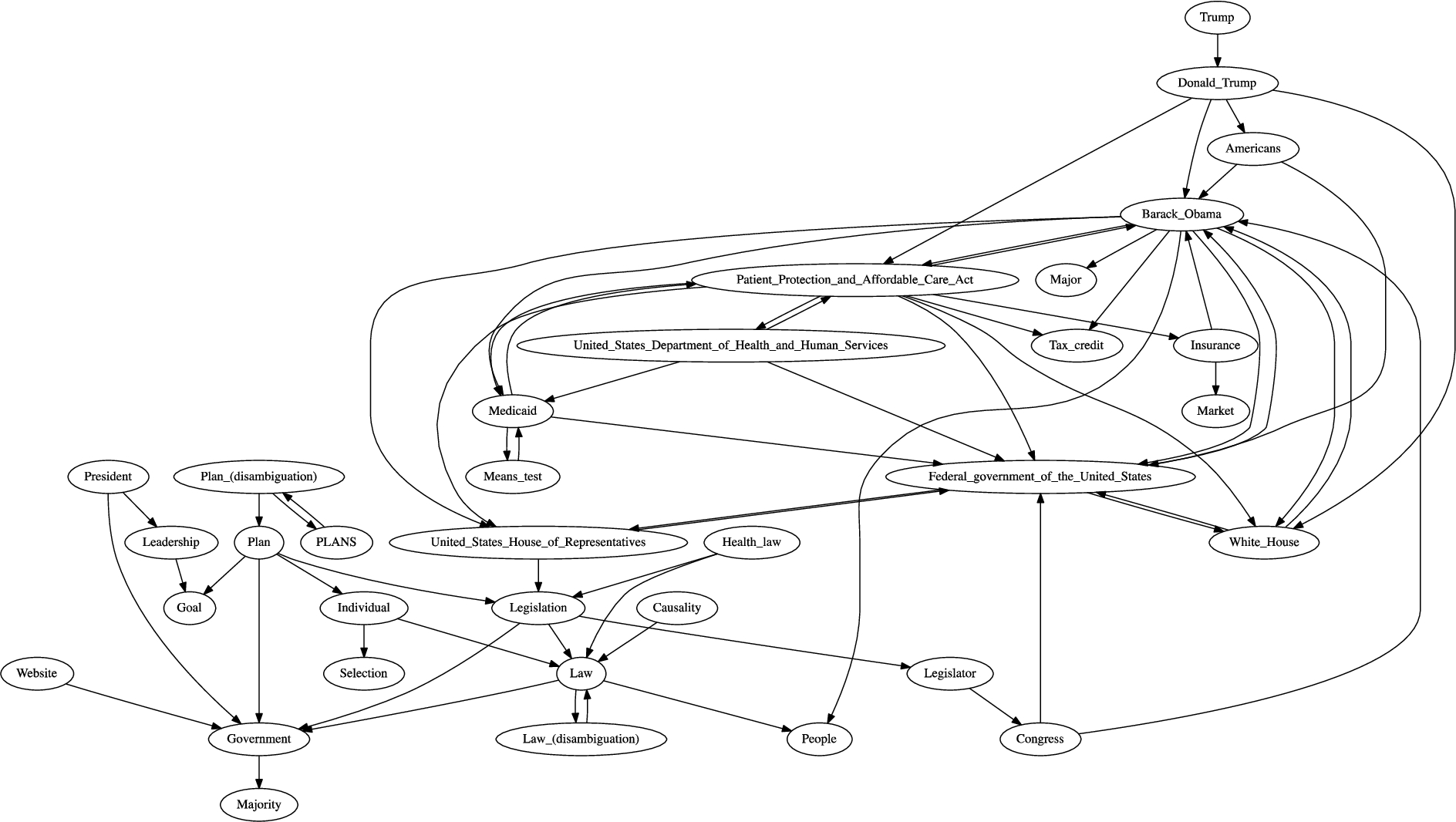
A fragment of the semantic graph from the example text.
In this section, the Entity Topic Model based on LDA (EntLDA) and its learning process will be described. We then define the entity network regularization and investigate how to integrate the entity topic model with the regularization framework.
Many topic models like LDA usually ignore the entities associated with the documents in the modeling process because the pure topic models are based on the idea that documents are made up of topics, while each topic is a probability distribution over the vocabulary. Unlike in LDA, in the proposed EntLDA, each document is a distribution over the entities (of the ontology) where each entity is a multinomial distribution over the topics and each topic is a probability distribution over the words. For example, in DBpedia ontology, each entity has a number of topics (categories) assigned to it. Hence, each entity is a mixture of different topics with various probabilities.
We highlight the fact that entities occurring in the document together with the relationships among them can determine the document’s topics. In other words, the underlying intuition behind our model is that documents are associated with entities carrying rich information about the topics of the document and utilizing this significant information is of great interest and can potentially improve the topic modeling and topic coherence.
For instance, the following is a fragment of a recent news article:
U.S.
As of the end of January, enrollment was down by about 500,000
The
The
The finding made it tougher for
The data released on Wednesday by part of the
Of those enrolled, 10.1 million
As Fig. 3 shows, we can recognize the entity mentions (underlined) in the document and induce relationships among them through applying the knowledge from the DBpedia ontology. This leads to the creation of a semantic graph of connected entities that were identified in the document. We combine the structure of such a semantic graph of entities with the probabilistic topic models in order to enhance the coherence of the discovered topics.
The EntLDA topic model
The novelty of the EntLDA model is in leveraging the potential role of the ontological knowledge associated with entities occurring in a document. This ontological knowledge about the entities (ontology concepts and relationships among them) is fully integrated into the EntLDA topic model. Effectively, this exploits the prior (ontological) knowledge in order to produce coherent topics automatically.
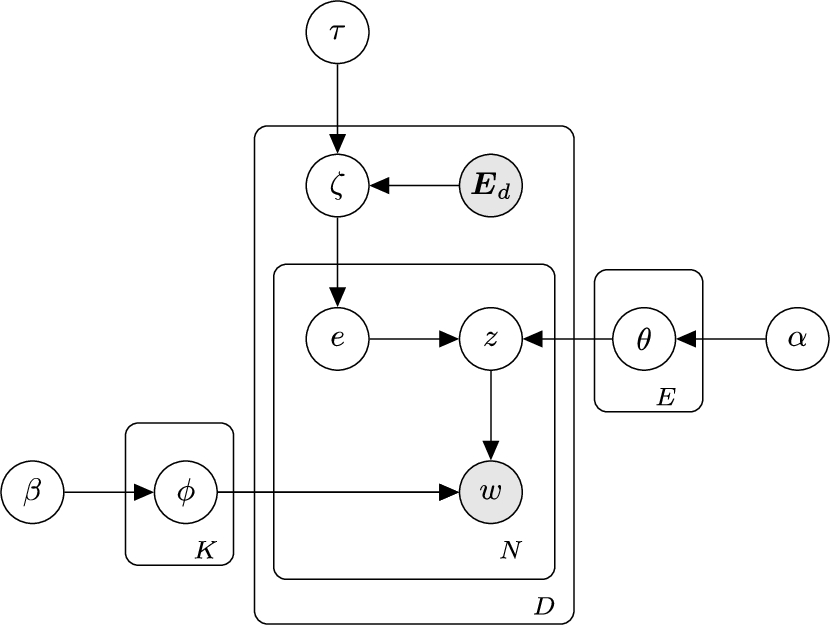
Graphical representation of EntLDA; symbols explained in Algorithm 1.

EntLDA topic model
Notation used in this paper
The graphical representation of EntLDA is shown in Fig. 4 and the generative process is defined in Algorithm 1. The notation used in this paper is summarized in Table 1.
It should be noted that in the generative process for each document d, instead of selecting an entity uniformly from
According to the model, we can write the joint distribution of all observed and hidden variables as follows:
In our EntLDA model, two sets of unknown parameters need to be estimated: (1) the E entity-topic distributions θ, and K topic-word distributions; and (2) the assigned topic
The posterior inference is defined as follows:
For a word token w at position i, its full conditional distribution can be written as:
After Gibbs sampling, we can easily estimate the topic-word distributions ϕ, entity-topic distributions θ and document-entity distributions ζ by:
Regularization framework for topic models
Resources on the World Wide Web (WWW) and in particular text documents are not only getting richer in content, but they also become extensively interconnected with users and other types of objects. This evolution of the Web leads to a network of data where, in addition to textual information available in documents, we often gain access to the associated network-like structure in the data. Bibliographic data and social networks are such examples where we have both textual documents and a network of multi-typed objects.
Although topic models have proven their utility in document analysis, they usually consider only the textual information and ignore the network structure present in the data. On the other hand, the interactions between objects in the network play an important role in revealing the rich semantics of the network and thus the document. Topic modeling based on network structure (regularized topic modeling) has been shown to be effective in extracting topics and discovering topical communities [14,23,24]. The basic idea is to combine topic modeling and social network analysis, and leverage the power of both the topic models and the discrete regularization, which increases the likelihood of discovering quality topics.
In the following section, we propose an ontology-based regularization framework that integrates the network structure of the entities in the documents with the topic models.
Regularization-Based Entity Topic Model
Our approach to regularization, which we call Regularization-Based Entity Topic Model (RETM), combines our EntLDA model with the semantic graph structure of the entities occurring in the documents. The key idea behind this method is that the entities in the ontology that are semantically closely related to each other, are categorized under the same or similar topics. Thus, we leverage the information in the individual documents, including entities mentioned in the document text, and integrate it with the graph structure of the ontology by regularizing the topic model based on the entity network. Particularly, entities appearing in a document that are semantically related to each other in the ontology should belong similar topics.

Parameter estimation
Entity network: An entity network associated with a collection of documents D is a graph
In order to minimize Eq. (11), we have to find a probabilistic topic model that fits the text collection D and also smoothes the topic distributions between the entities in the entity network. In the special case that
In this section, we describe the evaluation of the proposed Regularization Based Entity Topic Model (RETM) in two experiments using two different datasets. In Experiment 1, we compare the final result with three baseline models: LDA [7], EntLDA without regularization framework and GK-LDA [12]. For Experiment 2, we select the most coherent method from Experiment 1 and perform our experiment on a larger dataset.
From the selected method, LDA is the basic topic model to learn the topics from the corpus. EntLDA without regularization is just the proposed model excluding the regularization term (i.e.,
Data sets
We evaluated the proposed approach on two datasets of Reuters3
The second dataset is a collection of
Experiment 1. We removed punctuation, stopwords, numbers, and words occurring fewer than 10 times in the corpus through the pre-processing of the first dataset. Then, we created a
The Mallet toolkit5
Experiment 2. For the second experiment we went through the same procedure for data pre-processing of the second dataset as used in Experiment 1, except we selected the LDA model (best baseline in Experiment 1) for comparison of the final result on the larger dataset.
We have evaluated our RETM model (EntLDA with regularization) by comparing it to the selected baseline models. We used the topic coherence metric to evaluate the quality of the topics. Topic models are often evaluated using the perplexity measure [7] on held-out test data. In [9], Chang et al. reported that human judgments can sometimes be contrary to the perplexity measure. Also, Newman et al. [29], indicated that perplexity has limitations and may not reflect the semantic coherence of topics learned by the model. Additionally, perplexity only provides a measure of how well a model fits the data, which is different from our goal of finding coherent topics.
Quantitative analysis
For the quantitative evaluation, we applied a metric, namely topic coherence score, proposed by [26] for measuring the quality of topics. Arguably, this has become the most commonly used topic coherence evaluation method. Given a topic z and its top T words
Experiment 1. We performed several experiments with various values of ξ (
Table 2 shows the results for two topics
Topic coherence on top T words (Experiment 1). A higher coherence score means more coherent topics
Topic coherence on top T words (Experiment 1). A higher coherence score means more coherent topics
Table 3 illustrates the average topic coherence for the top words (ranges from 5 to 20) among all the models with different number of topics. RETM shows a significant improvement (p-value < 0.01 by t-test) over the LDA, GK-LDA, and EntLDA (without regularization) models.
Average topic coherence on top T words for various number of topics (Experiment 1)
Figure 5 shows that our RETM model consistently achieves higher topic coherence score over the baselines. Among the baseline models, LDA works better than GK-LDA and EntLDA without regularization (i.e.

Experiment 1: average topic coherence for all models (a higher coherence score means more coherent topics).
Experiment 2. According to the results of Experiment 1, LDA is the best baseline model among all the baseline models, therefore we evaluated our model by comparing it to LDA using a larger dataset (i.e., the second dataset). As Table 4 depicts, RETM shows better performance in comparison to LDA for different topics and top words. The overall evaluation between two models in Table 5 and Fig. 6 also confirm that the proposed model has better efficiency in a larger dataset.
Topic coherence on top T words (Experiment 2)
Average topic coherence on top T words for various number of topics

Experiment 2: average topic coherence between RETM and LDA (a higher coherence score means more coherent topics).

The effect of varying parameter ξ in the regularization framework for
In our method, we use the underlying regularization parameter ξ which effectively impacts the RETM model.
Figure 7 shows how the performance of RETM varies with changing the regularization parameter ξ. As we mentioned in Section 4.4, parameter ξ controls the balance between the data likelihood and the smoothness of the topic distribution over the entity network. When
Qualitative analysis
In this section, we describe some qualitative results to give an intuitive perspective on the performance of different models. Many of the topics are improved significantly, however, we show some sample examples. We further focus on sample topics of LDA and our RETM models, since the results of the other baselines were inferior. We selected a sample of topics with the top-10 words for each topic from an experiment with number of topics
Example topics from two domains, along with top-10 words under LDA and RETM models. The first row presents the manually generated labels. Italicized words indicate the words that are not likely to be relevant to the topics
Example topics from two domains, along with top-10 words under LDA and RETM models. The first row presents the manually generated labels. Italicized words indicate the words that are not likely to be relevant to the topics
In this paper, we proposed an entity topic model EntLDA and also RETM, which is EntLDA with a regularization network. Both models integrate the probabilistic topic models with the knowledge graph of an ontology in order to investigate and improve the task of discovering coherent topics. The proposed models effectively utilize the semantic graph of the ontology including entities and the relations among them and integrate this knowledge with the topic model to produce more coherent topics. We demonstrated the effectiveness of this model by conducting two different experiments. In Experiment 1, we evaluated our model against the baseline models (LDA, GK-LDA, and EntLDA) using a dataset of text collection contains 1243 news articles categorized into six primary topics from Reuters6
There are many interesting future directions of this work. We are particularly interested in investigating the application of the proposed model in “automatic topic labeling” [1] and text categorization tasks. Additionally, the models can be potentially used for entity classification [27], entity summarization [31,32], and profiling RDF datasets [33] tasks.