
Abstract
Deep learning architectures based on self-attention have recently achieved and surpassed state of the art results in the task of unsupervised aspect extraction and topic modeling. While models such as neural attention-based aspect extraction (ABAE) have been successfully applied to user-generated texts, they are less coherent when applied to traditional data sources such as news articles and newsgroup documents. In this work, we introduce a simple approach based on sentence filtering in order to improve topical aspects learned from newsgroups-based content without modifying the basic mechanism of ABAE. We train a probabilistic classifier to distinguish between out-of-domain texts (outer dataset) and in-domain texts (target dataset). Then, during data preparation we filter out sentences that have a low probability of being in-domain and train the neural model on the remaining sentences. The positive effect of sentence filtering on topic coherence is demonstrated in comparison to aspect extraction models trained on unfiltered texts.
Introduction
Aspect extraction is an important task in sentiment analysis of, e.g., user reviews. The goal of aspect extraction is twofold: (1) to extract words/tokens describing features of the item the author shares their opinion about, (2) to attribute each extracted word/token to a group/cluster related to a certain feature. For example, given a sentence “The stew was delicious” from a restaurant review, one might extract “stew” as an aspect word representing the “food” aspect. The words “steak”, “borscht”, “fish” etc. could also be attributed to the aspect “food”.
Recent advances in neural attention-based architectures have made it into a method of choice for modern natural language processing. It is currently well established (see, e.g., [8, 15]) that neural models are able to identify latent topical aspects in user-generated texts in an unsupervised way. The purpose of topic modeling is to cluster words (generally speaking, tokens) of the input text into coherent topics, or aspects; e.g., the words criminal and federal are part of the topic justice for the domain of law journals, while oxidation and reaction are part of the topic chemistry for the domain of research papers. In probabilistic topic models, the topics/aspects are usually defined as distributions over words/tokens; the topic distribution can then serve as a compressed description of the document for other models.
Unsupervised methods for aspect extraction and topic modeling are an active field of research, especially since they can be applicable to texts in any domain. In particular, one model that has recently proved to be successful is the unsupervised neural attention-based aspect extraction model (ABAE) [8]. One of the most prominent advantages of attention-based models over traditional topic modes such as latent Dirichlet allocation (LDA) [4] is that the former encode word-occurrence statistics into word embeddings and apply an attention mechanism to remove irrelevant words, learning a set of aspect embeddings.
While recent studies on a set of user reviews have demonstrated that neural attention models can provide aspects of significantly higher quality than the classical LDA model or its modifications developed over the last decade (see, e.g., [8, Fig. 2]), we have found in recent research and practical experience (see Table 1 for an example) that these models have significant limitations on long texts such as, e.g., newsgroup posts as compared to user reviews on Amazon or similar.
One possible explanation for this effect lies in the style differences between the two domains. Review writers expressing opinions and describing items of value (whether those are venues, goods, events, or anything else) usually stay focused on the topic and do not venture into general exposition. This means that the implicit assumption of a sentence-based model such as ABAE [8] that every sentence relates to a single aspect usually makes sense.
On the contrary, newsgroup texts or longer reviews are “too general” compared to Amazon-like reviews, i.e., too many sentences are “general” (see sentence 3 in Table 3 for an example) and do not contain aspect words that ABAE or similar models are implicitly trained to encode and recover.
The attention mechanism imposes restrictions on the model: ABAE learns a poor representation of texts at the broad, general level rather than in terms of latent topics discovered from the collection. For a prolonged example, Table 1 shows sample topical aspect words extracted for the sci.electronics newsgroup from the 20 Newsgroups dataset. Each row in Table 1 contains eight most probable words for the corresponding aspect extracted by the ABAE model [8]. In the left column, Table 1 shows examples of poor topical aspects learned by directly applying ABAE on all sentences of newsgroup documents and topic words that are much more coherent and readily interpretable.
Sample aspects extracted from sci.electronics by ABAE [8]. Left: aspects extracted from all sentences; right: aspects extracted from selected sentences
Sample aspects extracted from sci.electronics by ABAE [8]. Left: aspects extracted from all sentences; right: aspects extracted from selected sentences
How can we extract better aspects in longer and more general texts, e.g., in newsgroup posts, with standard ABAE? In this work we propose an intuitive solution to this problem based on sentence filtering.
The idea is to train a simple binary probabilistic text classifier able to separate the texts of a particular (target) domain of interest from texts on other topics. For example, all news’ sentences about sport are labeled as in-domain texts for the target domain ‘sport’, while texts about politics, electronics or weather are considered as out-of-domain examples. This binary classifier allows to estimate the probability of each sentence to be an “in-domain” sentence in the target dataset. Sentences with scores lower than a certain threshold can then be treated as “out-of-domain” (general) ones and dropped from the training set for aspect extractors. Note that sentence classification here is not a goal in itself but serves as preprocessing for subsequent aspect extraction.
In this work we show that this simple technique allows to achieve better interpretability of the resulting aspects. For a clear example, see the right column of Table 1 that contains top words for aspects also extracted by ABAE but after the proposed preprocessing. Note that token sets in the two columns intersect often, but aspects in the left column are “noisier”, less coherent, and harder to interpret. The aspects become better as the model is not trying to encode sentences that could be attributed to any other domain and is free to concentrate on “relevant” sentences.
The paper is structured as follows. Section 2 briefly surveys related work. In Section 3, we begin with the model description, describing attention mechanisms and the existing ABAE model. In Section 4, we present an approach to sentence filtering using out-of-domain classification. The experimental setup and results on several datasets are presented in Section 5. We conclude with a summary of our results and possible future research directions in Section 6.
Topic modeling is a set of techniques intended to uncover the topical structure of a corpus of documents in an unsupervised manner; it has become the method of choice for a number of applications dealing with general text-level analysis. The most popular basic model is Latent Dirichlet Allocation (LDA) [4], and over the last decade and a half it has given rise to numerous extensions and generalizations. Various topic models have been applied to many kinds of documents, including research abstracts, newspaper archives, Wikipedia articles, user reviews, tweets, and other user-generated texts [3, 29].
Studies that are the nearest to our present work in terms of novel approaches for input (pre)processing without modifying the generative process of the probabilistic models themselves include, e.g., [11, 17]. In these studies, discovered topics were quantitatively evaluated in terms of topic coherence. Mehrotra et al. proposed a novel method of tweet pooling by hashtags in order to improve LDA topics [17]. Tweets were aggregated into “macro-documents”, and the macro-documents were used as training data to construct better LDA models. First, all tweets were pooled by existing hashtags. Second, unlabeled tweets were assigned with hashtags if the similarity score between an unlabeled and labeled tweet exceeds a confidence threshold (0.5 in [17]). The similarity score was based on TF or TF-IDF vector space representations. The authors concluded that the novel scheme of hashtag-based pooling leads to drastically improved topic modeling as compared to unpooled tweets, author-wise, or time-wise pooled. Krasnashchok and Jouili employed a term-weighting approach for the LDA input in order to promote named entities [11]. The authors artificially modified the frequencies of named entities in the 20 Newsgroups dataset without changing the weights of other terms. Experiments in the paper demonstrated that the proposed approach positively influences the overall topic quality. Loukachevitch et al. proposed a novel approach of computing word frequencies to use for LDA input based on thesaurus relations [14]. They hypothesised that if words from the same similarity set co-occur in the same document then their contribution into the document’s topics is higher, therefore their frequencies should be increased. The results showed that document frequencies really do influence the coherence of topic models, and the proposed approach improves it.
In this work, we concentrate on the ABAE model [8]. Since it was put forward in 2017, recent studies have utilized ABAE for various NLP tasks including rating prediction [22] and user profiling [19]. Unsupervised aspect extraction models such as ABAE [8] are shown to yield interpretable and coherent aspects for the reviews of various goods (usually tested on the Amazon reviews dataset), which are typically short and very focused on certain items of interest of the reviewer. Researchers from the Airbnb team applied ABAE to a large corpus of accommodation reviews in order to generate review summaries and user profiles [19]. They evaluated ABAE across these two tasks. For the first task of extractive summarization, they used sentence-level aspects inferred by ABAE to select representative review sentences for a given accommodation and a given aspect. For the second task, the authors used sentence-level aspects to compute user profiles by grouping all reviews coming from a given user.
Quantitative and qualitative analysis conducted in [19] showed that these user profiles are effective in reranking reviews and accommodations. Interestingly, the authors found that aspects inferred by the k-means baseline are relatively incoherent compared to ABAE. The k-means baseline works very well to identify frequent aspects, while ABAE is better for infrequent aspects.
Another recent model, Aspect-based Rating Prediction (AspeRa), has been proposed in [22] for learning rating- and text-aware recommender systems based on neural attention-based aspect extraction produced by the ABAE model, metric learning, and autoencoder-enriched learning. The proposed model outperformed state of the art aspect-based recommender systems on several real-world datasets of user reviews. Moreover, aspects discovered by AspeRa as a side product of the rating prediction task proved to be readily interpretable and, when evaluated in terms of standard topic coherence metrics, showed quality similar to LDA.
Neural architecture for aspect extraction
Attention mechanisms
Attention mechanisms had initially appeared in computer vision, but were quickly adapted to recurrent architectures used for natural language processing. There, attention mechanisms were introduced to overcome a commonly known flaw of RNNs, the lack of long-term memory: without additional modifications, RNNs can quickly forget early timesteps [10]. Attention serves as a kind of recall mechanism, allowing the network to recall different parts of the input when necessary. The already classical approach to attention was defined in [1]. A more recent and advanced version of attention, known as the Transformer, was presented in [27] and has already served as a basis for many extensions; the general idea of self-attention that we shall discuss further is extensively employed in that work.
The basic idea could be described as choosing the most “interesting” or “relevant” part of the input sequence to produce the current step of the output/the values in the next network layer. A soft alignment model produces attention weightsa
i
that control how much each input word influences the word currently being produced. The score a
i
indicates whether the network should be focusing on this specific word right now, and
More formally, the basic attention mechanism is defined as
Neural attention-based aspect extraction model
ABAE, the Neural Attention-Based Aspect Extraction Model [8] is a neural architecture intended to capture the topical content of input texts. Similar to classical topic modeling [4], the user chooses a finite number of topics (called aspects in this context), and the goal of ABAE is to learn the aspects themselves and the extent to which each document corresponds to each of the aspects.
In essence, the ABAE model is an autoencoder; the primary component of the ABAE loss function is the reconstruction loss between the (weighted) sum of word embeddings used as the sentence representation and a linear combination of aspect embeddings. The sentence embedding is weighted by the so-called self-attention, an attention mechanism where the values are embeddings of words in a sentence and the key
Figure 1 illustrates the ABAE model in more detail. The first step for each sentence s is to compute the sentence’s embedding
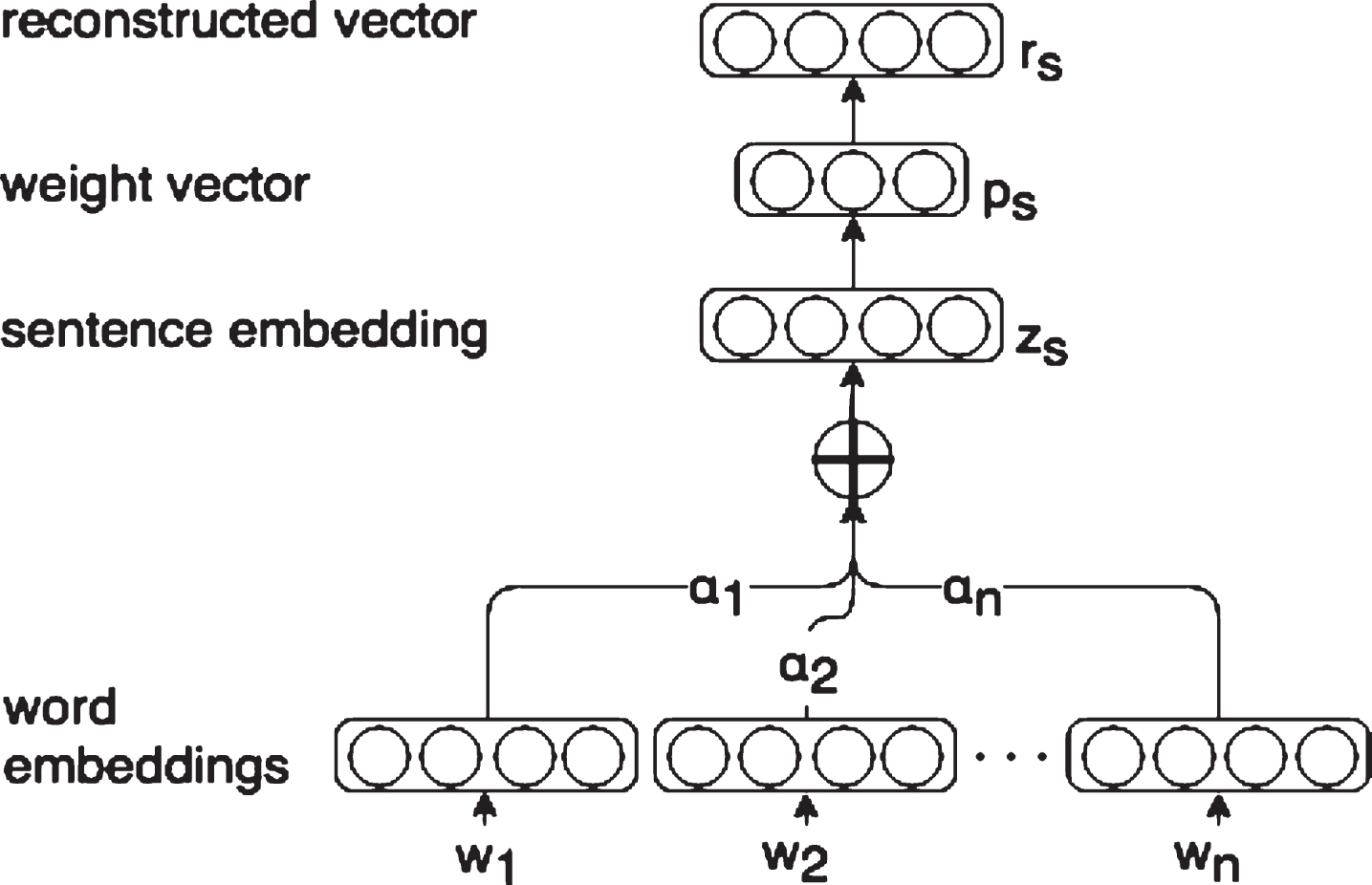
Architecture of the the neural attention-based aspect extraction model (ABAE) [8].
Then we compute attention weights a
i
as a multiplicative self-attention model:
Once one has computed the attention weights, one computes the text representation
The next step is to compute the aspect-based sentence representation
Each of k rows in matrix T represents a “topic embedding”. The original work by He et al. [8] suggests to initialize it with centroids of pre-trained word vectors clusters, grouped with the k-means algorithm [13, 26].
To train the model, ABAE defines the reconstruction error as the cosine distance between
As we have briefly outlined in the introduction, for longer texts such as newsgroup posts or articles we propose to select only certain sentences for training an unsupervised aspect extraction model.
Let us consider the case when we have a target collection of newsgroups (or other texts longer than the average user review) of one certain domain (ID for “in-domain”). For our preprocessing approach we propose to do the following: obtain a collection of out-of-domain texts OOD, split them into sentences; label the sentences from the target collection ID as the “in-domain” class; label the sentences from the OOD as the “out-of-domain” class; train a probabilistic binary classifier separating “in-domain” and “out-of-domain” classes; compute the “probabilities” (classifier scores) of each of the sentences from the target collection ID; choose a probability threshold θ and remove sentences that have a lower value of the probabilities computed above from the training set; train the unsupervised aspect extraction model (ABAE) on the filtered dataset ID
f
.
The procedure described above is very general. We could use any probabilistic classifier on steps (4)-(5), adopt any hyperparameter tuning scheme, and use different strategies for choosing the threshold for filtering the sentences. Note that we do not specify explicitly how exactly the out-of-domain data should be collected. As usual in modern natural language processing, we assume that such data can easily be collected on-demand and can include arbitrary texts. Therefore, although the classifiers are obviously trained in a supervised way, overall the proposed approach does not require any additional labeling and does not violate the unsupervised nature of aspect extraction.
In the next section, we describe the details of the exact approach used in our experiments and show our evaluation results.
Experimental evaluation
Evaluation metrics
In all experiments, we have evaluated the topics produced by ABAE and other topic models in our comparison in terms of topic coherence. The idea behind topic coherence is that a coherent topic will display words that tend to occur in the same documents. In other words, the most likely words in a coherent topic should have high mutual information. Document models with higher topic coherence are supposed to be the topic models with better interpretability.
We have employed standard topic coherence metrics:
CPMI (PMI-coherence) [20, 21]: having taken top N words from a topic/aspect, compute the average sum of PMIs for all
CNPMI [5]; this metric is similar to CPMI but employs the normalized PMI measure:
In both metrics, we compute probabilities using co-occurrence frequencies within a sliding window of 10 words.
Dataset
To demonstrate the feasibility of our approach, in our experiments we have used the benchmark 20 Newsgroups dataset 1 , which is essentially a collection of discussions on 20 selected topics (newsgroups). We consider this dataset as a diverse collection of documents. Figure 2 shows the complete list of selected newsgroups.
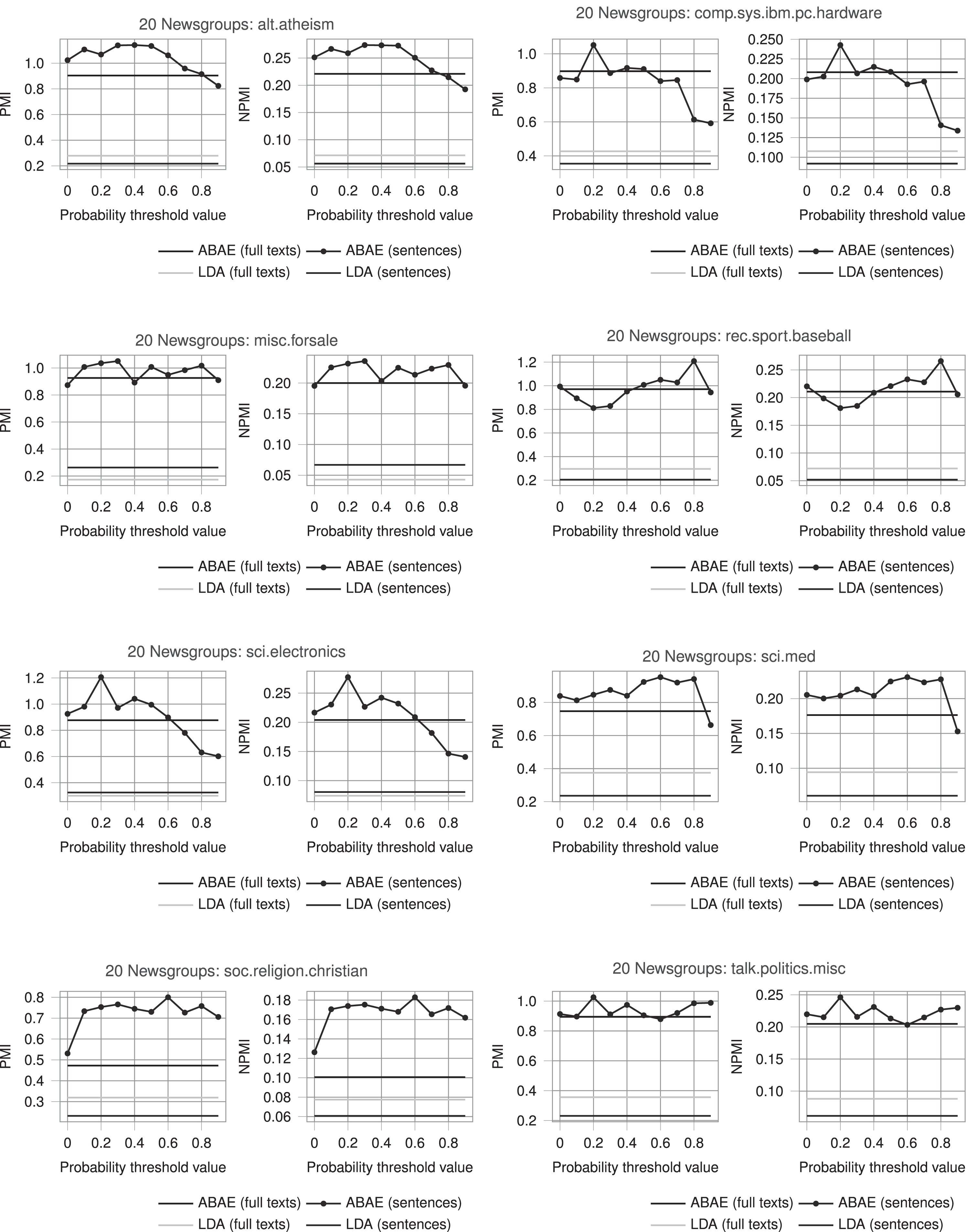
Evaluation of aspects extracted from the 20 Newsgroups collection by different topic models.
Each newsgroup represents a certain domain. For each, we removed all meta-information describing the messages and all quotations of previous messages. We have split all the messages into sentences using the NLTK [2]
For each newsgroup category, we have carried out the procedure described in Section 4.
Every newsgroup’s sentences were labeled as the “in-domain” class. All other newsgroups’ sentences in the preprocessed 20 Newsgroups dataset were considered an out-of-domain collection (not related to the particular domain) and labeled as “out-of-domain”. E.g. when preparing sentences for aspect extraction for sci . electronics, the texts of this newsgroup were treated as ID, and all other newsgroups alt . atheism, misc . forsale, etc. were concatenated and treated as OOD set.
As stated in Section 4, we require a probabilistic classifier for sentence selection. Despite there is a vast variety of advanced text classification methods, we have decided to adopt a very straightforward approach to demonstrate the feasibility of the general procedure proposed in this study. Hence, we have decided to present each sentence as a bag-of-words representation and use logistic regression as the probabilistic classifier, adopting the scikit-learn implementation [23]. The classifier was trained until convergence with the maximum number of iterations equal to 100. We have used all of ID and OOD for each newsgroup as train set. Since out-of-domain classification itself is not the main point of this work, we did not evaluate the classifiers predictions on any test sets. We note that we acknowledge that the classifiers’ quality may influence the overall results and leave this analysis in for future analysis.
The evaluation results of the binary classifier on the training sets are presented in Table 2. The results show that the model based on logistic regression and bag-of-words representations obtained 94% -98% accuracy. We also present samples of sentences with the obtained scores from the sci.electronics newsgroup in Table 3.
The evaluation results of the binary classifier on the training sets for each newsgroup
Out-of-domain classifier’s scores for sentences from the sci.electronics newsgroup
After applying the classifier, we have generated new datasets by filtering each of the chosen newsgroups by every score threshold from the set {0.0, 0.1, 0.2, . . . , 0.9}, where 0.0 means no filtering. As the threshold increases, the datasets are reduced in size; for example, for threshold 0.5 the Christianity (soc . religion . christian) dataset size is reduced by 55%.
Following ABAE [8], we set the ortho-regularization coefficient for the aspect matrix equal to 0.1. Since this model utilizes an aspect embedding matrix to approximate aspect words in the vocabulary, initialization of aspect embeddings is crucial. We adopted the approach described in the original work [8], initializing based on k-means clustering [13, 26]. In this method, all word vectors (i.e., word2vec) for the words occurring in input texts are clustered with k-means, and then rows of the aspect embedding matrix are initialized with centroids of the resulting clusters. We have used 15 aspects (topics) and 20 negative samples for learning phase following [8]. We trained the model for 10 epochs with a batch size of 256 on one GPU.
ABAE is initialized with the word2vec (SGNS) vectors, trained on the corresponding domain (newsgroup) for every newsgroup with the following settings: the dimension is 200, the window size equals 10, the number of negative samples equals 5, and only words with the minimal count of 2 are taken into account. We used the gensim library [24] to train the SGNS models. We adopted the OnlineLDA model [9] trained with the gensim library [24] with default parameters, using the same vocabulary and the same number of aspects as in ABAE.
Results
We have trained ABAE with sentences as input (as in the original paper [8]), using the filtered datasets generated as shown above.
The models we used for comparison as baselines are: ABAE trained on full texts of posts in the newsgroups; OnlineLDA trained on full texts of posts; OnlineLDA trained on sentences.
For every dataset, we have trained an aspect extraction model and computed two coherence metrics defined above using the software accompanying the paper [12].
Figure 2 contains the results across all datasets in the comparison. It clearly shows that in most cases it is possible to choose a filtering strategy to increase the topic coherence provided by the model.
Several interesting observations can be made based on these figures. First, the optimal threshold varies for different domains, yet for the most domains the threshold 0.2 increases coherence for extracted topics. Although there are exceptions (e.g. for the Baseball domain the 0.2 threshold does nothing), this fact needs further investigation. Generally, we can conclude that even this simplistic filtering technique improves the quality of an ABAE model with a reduction of data samples and therefore significantly reduced training time.
Second, the LDA baselines in comparison to each other show that full-text training data results in higher quality, which could be interpreted as proof that longer texts are more appropriate for the LDA model. Indeed, the LDA model generally was designed to work on texts longer than a typical sentence.
Third, interestingly, the ABAE model on full texts consistently shows better results than LDA baselines, despite the fact that it was designed to work on short texts (one or two sentences). Finally, one can clearly see that in all conducted experiments there is no significant difference in the results between PMI and NPMI coherence measures.
We have also experimented with other window sizes but found that the general form of the PMI and NPMI curves remains the same for all reasonable window sizes; see Figure 3 for an illustration.

Topic coherence as a function of the probability threshold value for the sci.electronics newsgroup for different window sizes.
In this work, we have presented a simple yet effective method of filtering out-of-domain sentences in order to improve the quality of ABAE-based models in newsgroup posts in terms of topic coherence. The presented results on the 20 Newsgroups dataset demonstrate that the proposed filtering method indeed improves the overall topic quality: ABAE trained on in-domain sentences discovers better topics than both LDA trained on either full texts or sentences and ABAE trained on both in-domain and out-of-domain sentences.
We see several potential directions for future work. First, there are more sophisticated topic models than the basic LDA, which could be even more sensitive to in- and out-of-domain data. We posit that the proposed technique can help some of them even more.
Second, another potential research direction could be to use more complex techniques for this in/out-of-domain classification, e.g., the method described in [25]. In general, we feel that the proposed filtering approach is a universal technique that can bring improvements across different topic models and neural architectures.
Finally, although we consider our claim fully supported by the evidence provided in this work, to make the proposed technique practical one also has to devise a reliable method of choosing the threshold. The threshold clearly depends on both the dataset and out-of-domain classification models. As the models are yet to be compared (see above), the technique for choosing the threshold is left for further study as well.