
Abstract
In order to overcome the problem of poor recovery and stability of traditional big data fault-tolerant technology, a fault-tolerant technology of big data cluster in distributed flow processing system is proposed. Using the target protocol to build the cache data fault-tolerant mechanism of the distributed flow processing system and the disk data fault-tolerant mechanism, so as to build the internal data fault-tolerant mechanism of the system. By using spark application framework, a fault-tolerant model of big data cluster is built to realize the fault-tolerant of big data cluster in distributed flow processing system. The experimental results show that compared with the traditional methods, the recovery rate of big data cluster fault-tolerant technology proposed in this paper is higher, the highest recovery efficiency is 99.83%, the stability is stronger, and it is more suitable for big data fault-tolerant processing of distributed flow processing system.
Keywords
Introduction
With the continuous expansion of the scale and capacity of the current data processing system, energy flow and information flow interact closely, which lays the foundation for intelligent data processing [6]. As a special data processing system, distributed flow processing system has the characteristics of high precision of monitoring data, obvious mass of monitoring information, centralized distribution of measurement points, wide fluctuation range of operation parameters, etc., which requires higher fault tolerance and stability of monitoring operation [14]. In order to enhance the data coordination and interaction ability of the distributed flow processing system, the application and investment of various intelligent and new-type monitoring equipment make the overall number of monitoring points show an explosive growth trend, and the structure also presents a complex and diversified development trend, posing a more severe challenge to the operation stability and data throughput of the distributed flow processing system [3]. At present, the distributed flow processing system is still unable to overcome the problems of large fluctuations in monitoring data and frequent load changes. Once the data fault tolerance of the system is insufficient, when some unexpected situations occur, such as monitoring data loss, data processing delay, etc., it is likely to cause false alarm information, missed alarm, delayed alarm, etc. of the system, or even lead to judgment errors of serious faults. And decision-making errors, which seriously threaten the operation safety of the system. Therefore, it is necessary to study the data fault tolerance technology of distributed flow processing system [5,7,20].
Reference [10] applies cloud theory to big data fault-tolerant technology. In this method, the application of data control deeply is analyzed, a fault-tolerant model for big data based on cloud theory is established, to realize data fault-tolerant in distributed flow processing system by combining quasi-synchronous checkpoint algorithm, synchronous checkpoint algorithm and independent checkpoint algorithm. However, the implementation process of this method is complex, so it is difficult to apply in a wide range. Reference [17] proposes an interactive two-stage evaluation evolutionary strategy for big data fault-tolerant mechanism. This method designs an architecture platform for three-module, heterogeneous and redundant fault-tolerant system, which effectively constructs the successful individual pool by evolving mechanism, so as to ensure the real-time repair ability of three redundant modules in the system when it is wrong. In order to further improve the generation efficiency of evolutionary individuals in the pool of successful individuals, an interactive two-stage evolutionary evaluation strategy was introduced to improve the performance of the system from two aspects: the fitness of evolutionary individuals and the heterogeneity between individuals. But the fault-tolerant stability of this method needs to be further improved. Reference [9] proposes a fault-tolerant technology for big data based on length filtering. According to the ratio of length of two records and the absence of attributes, it first excludes some data that can not constitute similar duplicate records, reduces the number of comparisons and improves the detection efficiency. Furthermore, a dynamic fault-tolerant method is proposed to calibrate the results of field similarity evaluation, and the problem of misjudgement due to missing attributes is solved, but the method has the problem of low recovery rate.
In order to solve the problems in the above methods, the fault tolerance technology of big data cluster in distributed flow processing system is proposed. The overall implementation scheme of the technology is as follows:
Establish the internal data fault tolerance mechanism of the system. Using the target protocol to build the cache data fault tolerance mechanism of the distributed flow processing system, and then using RAID5 to achieve the data redundancy of the distributed flow processing system, to complete the establishment of the disk data fault tolerance mechanism.
Specific composition of the target protocol.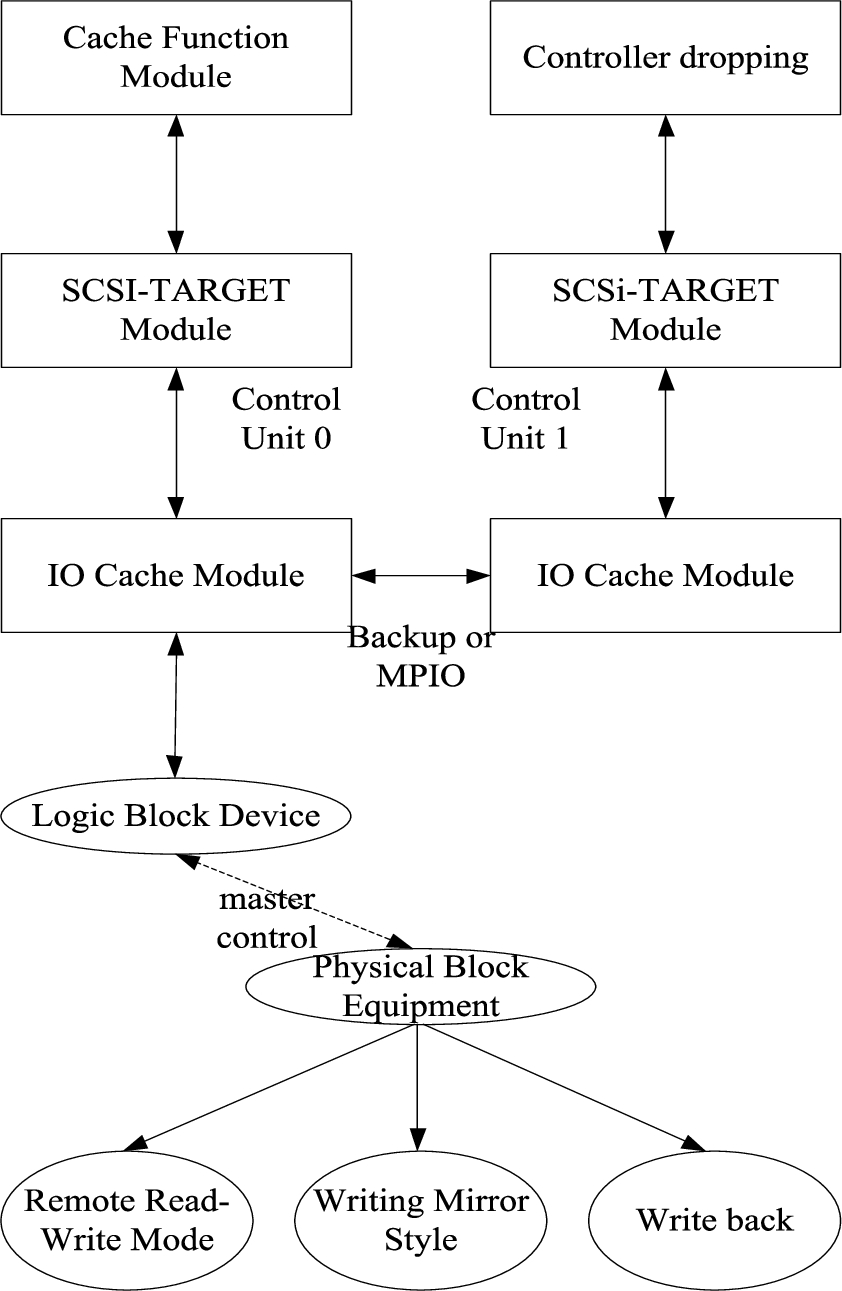
Establish a fault tolerance mechanism for data replication outside the system. Through data replication technology, the fault-tolerant mechanism of data replication outside the system is established.
Realize big data cluster fault tolerance. Using spark application framework to build the fault-tolerant model of big data cluster, and realize the fault-tolerant of big data cluster in distributed flow processing system.
Experimental verification. Taking recovery rate and fault-tolerant stability as comparative indexes, the proposed method is compared with reference [10], reference [17] and reference [9], and the experimental results are analyzed.
Conclusion.
Through the above scheme to achieve efficient and stable big data cluster processing.
Functions that can be achieved through interaction

Data processing flow of reading function.
Data processing of writing function in data reading and writing function.
Establish the data fault tolerance mechanism in the system
Establishment of fault-tolerant mechanism for cached data
Target protocol is used to build a fault-tolerant mechanism for caching data in distributed stream processing system. Target protocol includes controller compass. It can operate data according to user configuration and application data mode. Data operation mode includes remote read-write mode, write-mirror mode and write-back mode. Target protocol chooses the specific data operation mode according to the attributes of the system tier, the cache mode and the state of the controller. The structure of Target protocol is shown in Fig. 1.
For the internal control level of distributed flow processing system, it is necessary to use Target protocol to interact with cache subsystem, HA subsystem, management subsystem and block device driver in order to achieve fault-tolerant of cached data. The functions that can be achieved through interaction are shown in Table 1.
The IO caching function of cached data fault-tolerant mechanism needs to be realized by the caching function module in Target protocol. The function module can be logically divided into the following sub-modules, including remote backup and IO module, memory recovery and memory pool module, dirty page write-back module, pre-reading module, management configuration module and data read-write module. Data read-write function mainly includes remote data read-write and local data read-write, while cached data mainly refers to cardinal structure. Reading data can be divided into remote reading and proximal reading. The data processing flow is shown in Fig. 2.
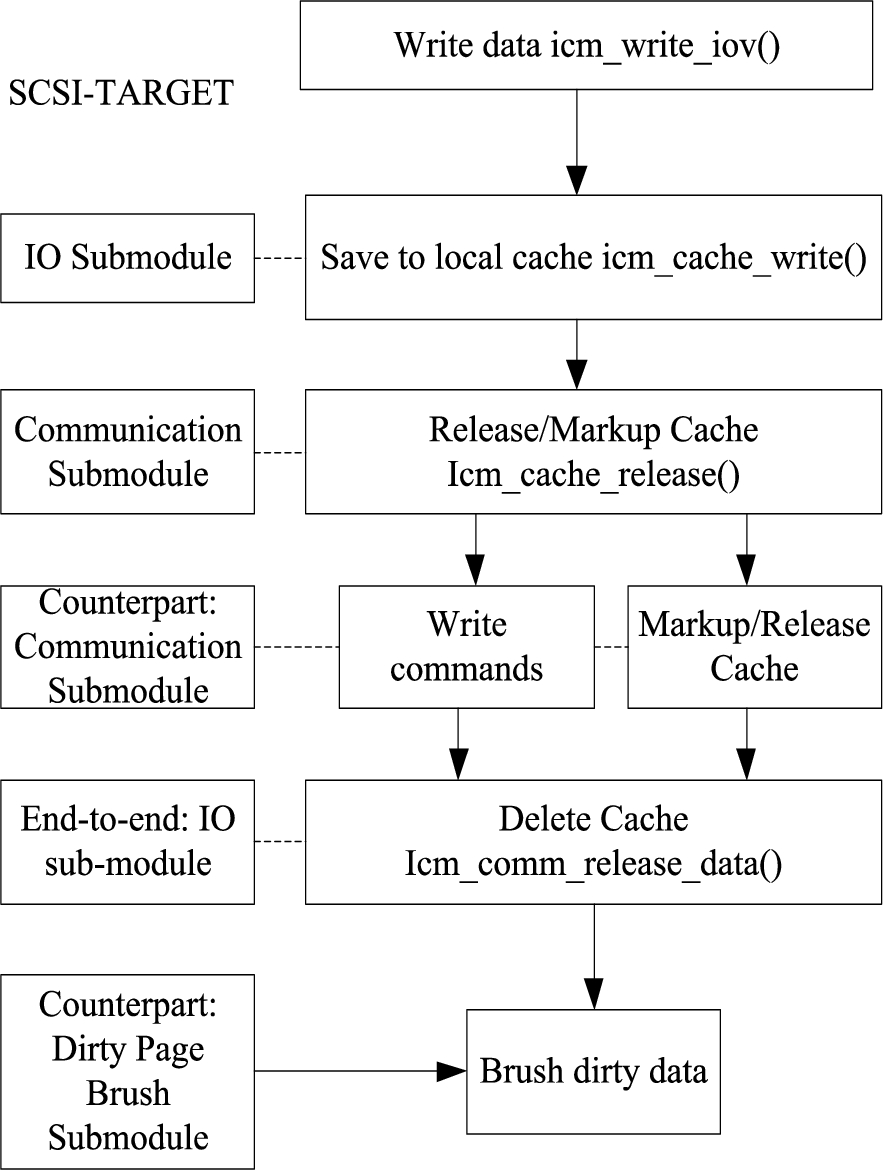
Writing data needs to be saved in the mirror and then transited to the main control. After completing the dirty data brushing, the mirror needs to be notified of the release of the backup data. Since dirty data brushing and writing operations must be kept asynchronous, in order to avoid releasing the newly backup data that has not been brushed incorrectly, it is necessary to define wrcount variable for each cached page unit to record the data version of the page [19]. The data processing process of the write function in the data reading and writing function is shown in Fig. 3.
The function of dirty page compass of cached data fault-tolerant mechanism needs to be realized by the controller compass module in Target protocol. The specific function of the controller compass module is shown in Table 2 [2].
The specific execution flow of -icm-pdflushn() function is shown in Fig. 4.
Establish internal disk data fault tolerance mechanism
The data redundancy of distributed stream processing system is realized by RAID5, and the fault-tolerant mechanism of disk data is established [12]. To realize system data redundancy, we first need to assign roles to two controllers of distributed flow processing system. They are regarded as clients and servers to construct disk data fault-tolerant mechanism. The specific structure is shown in Fig. 5.
Then, RAID processing and backup processing are carried out on the client and server, the system disk is patrolled by the client and server, and the parameters of patrol period, patrol rate and patrol scope are configured. Sync algorithm is used to record the data elements of the system disk, and fault-tolerant technology is used to process the data elements, so as to realize the establishment of the disk data fault-tolerant mechanism [15]. The calculation formula of Sync algorithm is as follows:
Specific functions of controller compass module
Specific functions of controller compass module
After completing the establishment of fault-tolerant mechanism of data within the system, the fault-tolerant mechanism of data replication outside the system is established through data replication technology. The data replication architecture is established mainly through remote data replication technology, and the fault-tolerant mechanism of external data replication is established by using remote replication mode of data replication architecture to replicate external data of the system [13]. Remote data replication technology can realize the data protection of distributed stream processing system. By remote replication of IP SAN and FC, system data can be copied. When the main site of the system is facing failure, it can backup and reverse copy the data quickly, and restore the data after the real failure of the main site. Remote data replication technology can be divided into asynchronous remote replication and synchronous remote replication. Asynchronous remote replication usually uses IP to copy data and provides data cross-regional protection service for distributed stream processing system, but its backup rate is usually slow, while synchronous remote replication usually carries out real-time backup of data, which can quickly restore interruption services, mainly by data copy using FC, but there is a distance limit [4]. Therefore, the data replication architecture is established by combining asynchronous remote replication with synchronous remote replication. The data replication architecture is shown in Fig. 6.

Execution flow of icm-pdflushn() function.

Specific structure of controller.
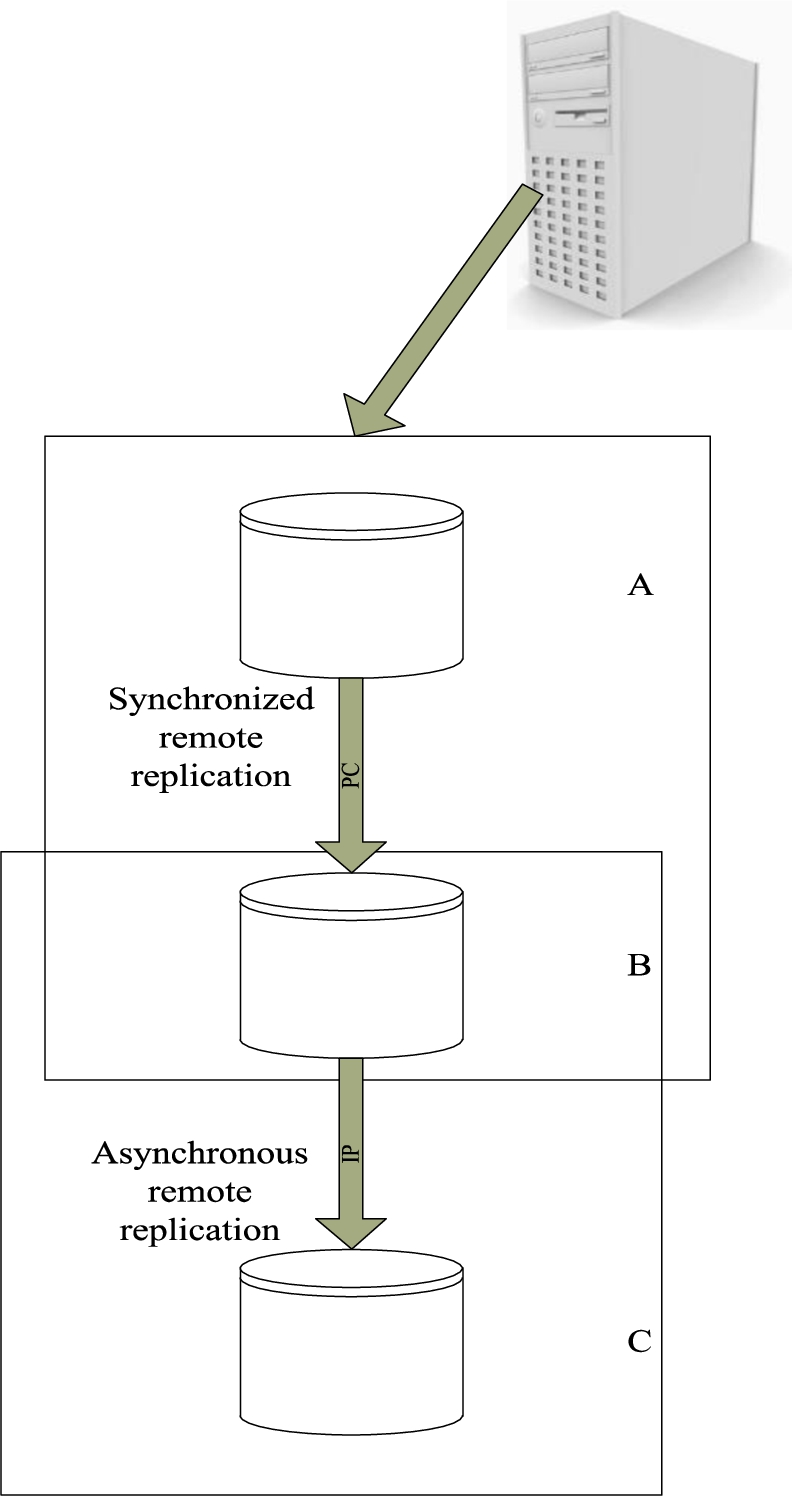
Architecture of established data replication system.
The remote replication mode in the data replication architecture is used to construct the fault-tolerant mechanism of external data replication. The remote replication mode includes asynchronous replication mode and synchronous replication mode. The fault-tolerant mechanism of external data replication has the functions of data replication and external data fault-tolerance [1].
According to the fault-tolerant mechanism of internal data and external data replication, and using Spark application framework to build a fault-tolerant model for big data cluster, the big data cluster fault-tolerant of distributed flow processing system is realized. There are four application frameworks in Spark application framework, namely, SQL interactive query application framework, Spark Streaming real-time flow processing application framework, MLlib machine learning application framework, GraphX graph computing application framework. Combining these application frameworks, a fault-tolerant model for big data clusters is constructed. Because the abstract data set RDD in Spark application framework can be applied to many applications, the resource consumption of daily management and data conversion in the operation and maintenance of distributed flow processing system is reduced [18]. The specific architecture of the fault-tolerant model for big data clusters is shown in Fig. 7.
Among them, the functions of the upper structure in the fault-tolerant model for big data clusters are as follows: SQL interactive query application framework, which is used for Hadoop data fault-tolerant query, with high query efficiency; Spark Streaming real-time flow processing application framework: which is used for fault-tolerant query of large-scale flow monitoring data through the bottom of Spark; MLlib machine learning application framework, which is a machine learning database for data fault-tolerant; GraphX Graph Computing application framework, which is a graph computing module for data fault-tolerant that supports Pregel computing model and Graphlab computing model [8].
There are three kinds of fault-tolerant modes in distributed flow processing system based on fault-tolerant model for big data cluster: Spark on Mesos cluster fault-tolerant mode, Spark Standalone cluster fault-tolerant mode and Spark on Yarn cluster fault-tolerant mode [11]. All three modes need to use abstract data set RDD for operator operation, and RDD for specific operator operation as shown in Table 3 [16].
Experimental verification
In order to test the performance of fault-tolerant technology for big data clusters in distributed flow processing system designed in this paper, a comparative experiment is designed.
The experimental environment of fault-tolerant technology for big data clusters under distributed flow processing system is simulated in laboratory. The specific test environment is shown in Fig. 8. There are two kinds of network structures in the test environment, including storage network structure and management network structure. The storage network structure mainly adopts FC data network, while the management network structure mainly uses IP/TCP network exchange. The management network console can monitor and configure the storage network structure using GUI. The fault-tolerant technology for big data clusters under distributed flow processing system is tested by using the built test environment.
In the test environment shown in Fig. 8, create a raid, select 128 KB stripe for it, and install raid and storage pool in the test environment. In the big data fault-tolerant experiment in the distributed flow processing system, in order to ensure the effectiveness of the experiment, the experimental scheme is set as follows: select 200 GB data in the NoSQL database, take recovery rate and fault-tolerant stability as the comparative index, and compare the proposed method with reference [10], reference [17] and reference [9] methods.
Recovery rate comparison
Comparing the recovery rates of the four methods, five experiments are carried out to compare the recovery rate of fault-tolerant technology for each big data, and the recovery rate is used to show the recovery of fault-tolerant technology for each big data. The experimental results are shown in Table 4.
According to the experimental results of recovery rate comparison in Table 4, the average recovery rate of literature [10] method is 63.03%; the average recovery rate of literature [17] method is 67.69%; the average recovery rate of literature [9] method is 65.47%; and the average recovery rate of big data cluster fault-tolerant technology in distributed flow processing system is 96.84%, that is to say, the recovery rate of big data cluster fault-tolerant technology in distributed flow processing system is far away. It is better than the literature comparison method, that is, the recoverability of big data cluster fault-tolerant technology is better than the traditional big data fault-tolerant technology under the distributed flow processing system, and the recovery performance is improved. Because this paper constructs the internal and external data fault-tolerant mechanism, which effectively improves the recovery rate of fault-tolerant.
Fault-tolerant stability comparison
In order to further prove the fault-tolerant performance of the proposed technology, the experimental verification is carried out with the fault-tolerant stability as the comparison indicator. The comparison results of the four methods are shown in Fig. 9.
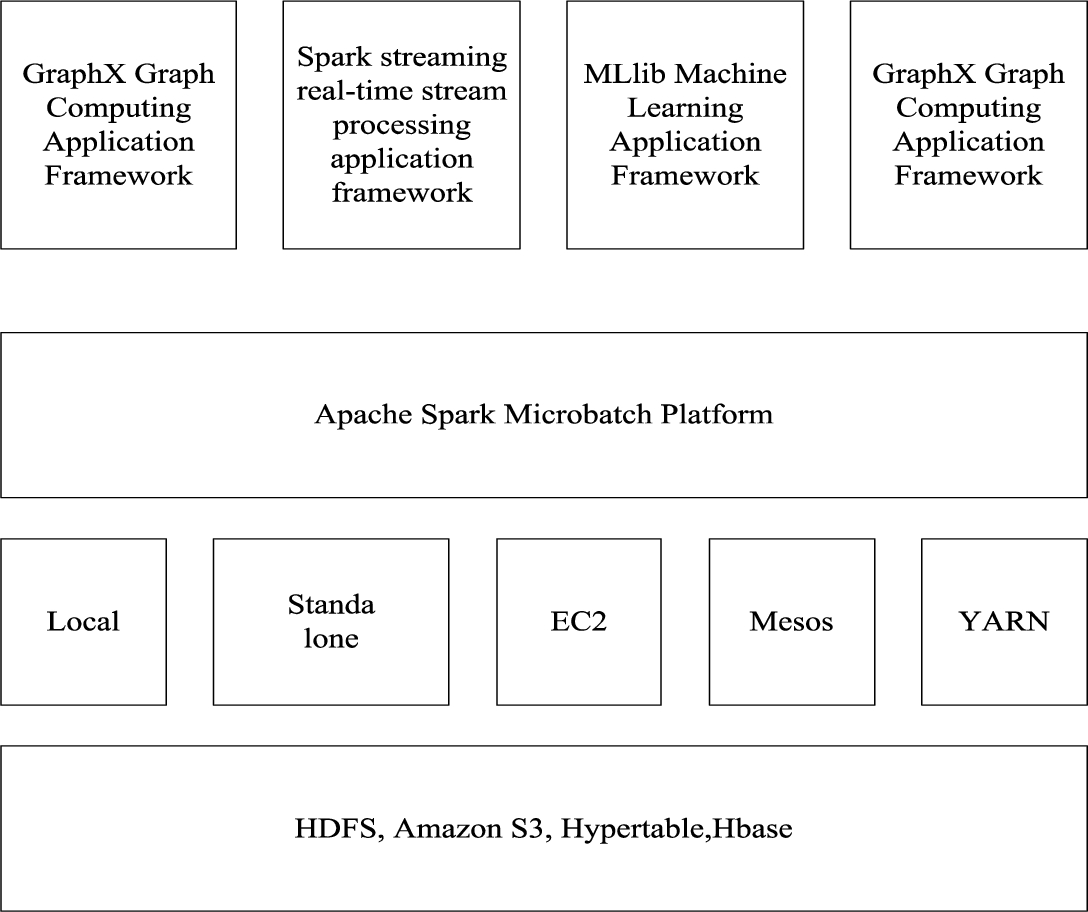
Specific architecture of fault-tolerant model for big data clusters.
Specific operator operations using RDD
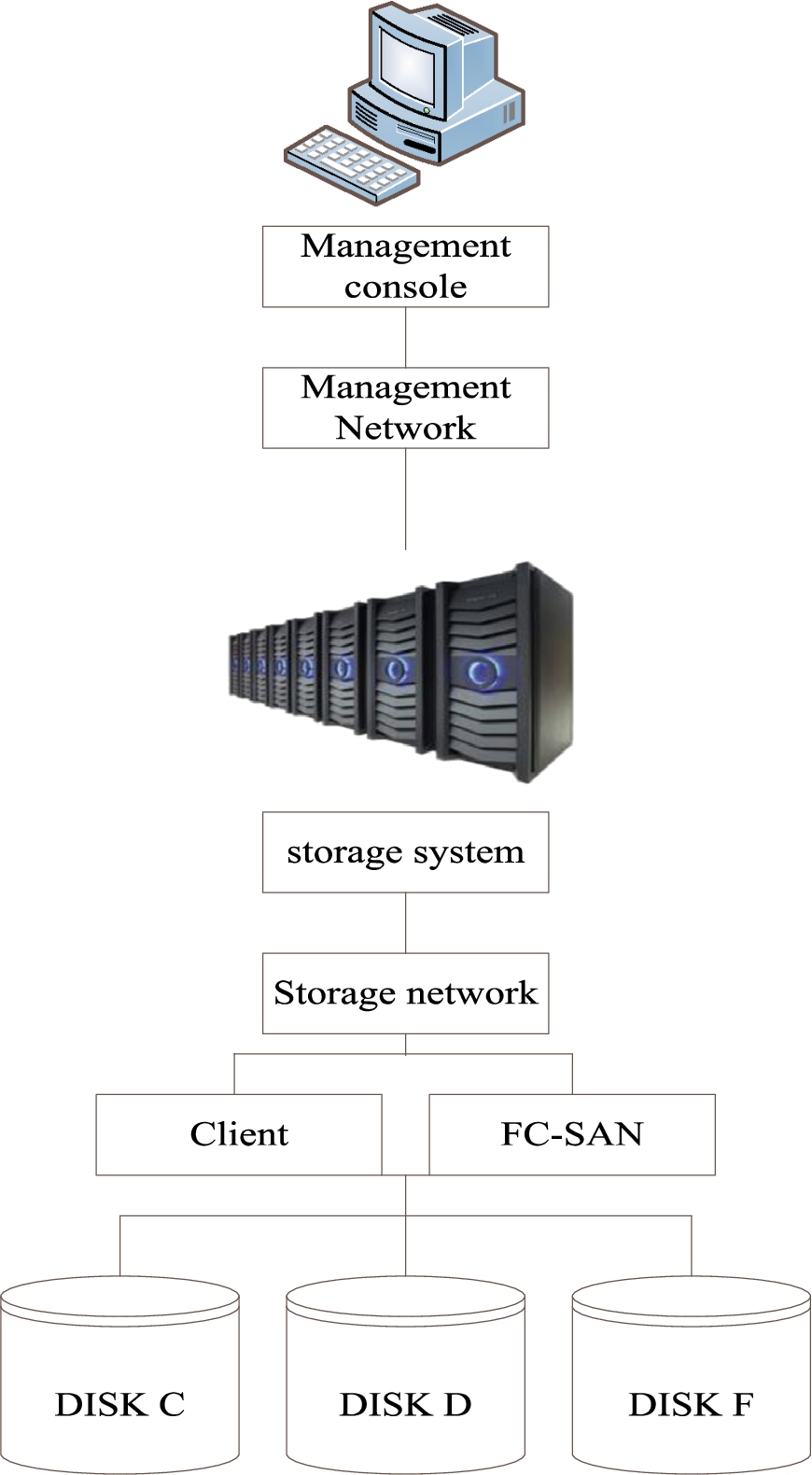
Specific test environment.
Comparison of experimental results of recovery rate
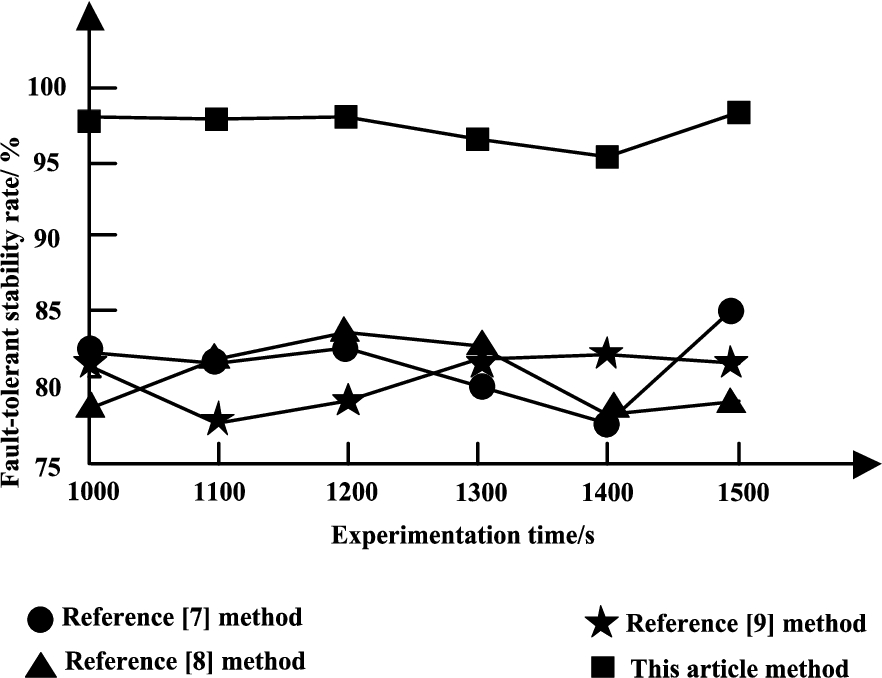
Comparison of fault-tolerant stability.
It can be seen from the analysis of Fig. 9 that with the increase of experimental time, the fault tolerance stability of this method is always higher than that of the three literature comparison methods, which shows that the proposed fault tolerance technology of big data cluster under the distributed flow processing system has high fault tolerance stability, can be widely used, and has high research value. Because this paper uses spark framework to build the fault-tolerant model of big data cluster, which contains three fault-tolerant models, greatly improving the stability of fault-tolerant.
The fault-tolerant technology of big data cluster under the distributed flow processing system through the establishment of the internal and external data fault-tolerant mechanism of the distributed flow processing system, the fault-tolerant model of big data cluster is constructed, thus realizing the fault-tolerant of big data cluster in the distributed flow processing system, and showing the recoverability superior to the traditional big data fault-tolerant technology, with an average recovery rate of 96.84%, realizing the recoverability. It is of great significance for big data processing of distributed stream processing system.
Footnotes
Acknowledgements
This work was supported by Gansu Natural Science Foundation “Research on Information Mining Mechanism of Anti-terrorism and Stability Maintenance in Gansu Province” under grant no 18JR3RA191.