
Abstract
In order to overcome the shortcomings of the traditional method of integrating historical data of library e-book borrowing, such as high delay and low integration throughput, this paper proposes a method of integrating historical data of library e-book borrowing based on big data technology. Based on big data technology, this method builds an integrated platform for library e-book borrowing, which consists of data layer, business layer, interface layer and application layer. Through the data layer, a series of borrowing historical data generated by the borrowing integration platform are collected, and data integration module is used to clean and filter the collected borrowing historical data of e-books. The data integration layer solves the local distortion and realizes the integrated processing of borrowed historical data. Experimental results show that the proposed method has the advantages of short time delay and low integration error rate, and the highest integration throughput can reach 97%.
Introduction
With the rapid development of information technology and data publishing, digital reading has become a very popular way of reading [20]. Especially with the gradual popularization of mobile terminals such as smart phones and tablets in recent years, e-book reading has broken the traditional physical space restrictions, brought new reading experience to people, changed the way of cultural transmission and preservation, and improved the convenience of reading [19]. Compared with paper books, e-books are widely welcomed by people for their advantages of easy carrying, fast dissemination and energy saving and environmental protection. According to the relevant survey, 87% of users have used digital reading service, and digital reading has a high popularity among netizens. In response to the diversified demand for digital reading, China’s three major operators provide diversified digital reading services through the construction of digital reading bases, responding to the digital reading market, such as QQ reading, panda reading and other e-book reading APP research and development. Mobile e-book reading app has always occupied the top five of all kinds of download websites. The prosperity of the digital reading market provides a new direction for the development of libraries. In order to develop towards the direction of digitalization and intellectualization, libraries carry out library e-book borrowing service on the basis of continuing the collection and circulation of paper books [9,17]. At present, foreign libraries borrow historical data of e-books. There are many integrated studies, and the research results are as follows:
Literature [15] proposes a method of integrating historical data of library e-book borrowing based on comprehensive threshold. This method divides the perception range of all e-book borrowing history data into two-dimensional network, integrates node energy and spatial threshold, forms comprehensive threshold, and introduces scheduling factor to integrate e-book borrowing history data. This method can integrate a large number of e-book borrowing historical data, but it has the problems of low throughput and long response time, and the practical application effect is not good. Literature [12] proposes a method of integrating historical data of library e-book borrowing based on hash coding. The hash coding theory is used to add the historical data integration nodes of library e-book borrowing, and distribute the data to each node to realize the integration of the historical data of e-book borrowing. This method can achieve data integration, but it takes a long time to integrate. Literature [7] proposes a method of integrating historical data of library e-book borrowing based on directional random walk. This method disperses the historical data of e-book borrowing into all network nodes according to the set steps of directional walker, and forms the integration package of e-book borrowing historical data. However, this method has the problem of high integration error rate in practical application.
Through research, it is found that the traditional method has serious data distortion and data loss in the process of integration of historical data of library e-book borrowing. To solve this problem, the large data technology is applied to all aspects of integration of historical data of e-book borrowing, and a middleware model integration method based on non-relational database is designed. In order to solve the problem of local distortion and data loss effectively, a method of integrating historical data of library e-book borrowing based on large data analysis is proposed. This method can eliminate the disorder and low-value information in these procedural and semi-structured data, acquire data behaviors such as borrowing relevance and access relevance, reveal readers’ reading rules, analyze readers’ reading preferences and other behaviors, improve service efficiency, optimize service level, provide better service for readers, and diversify personalized service.
Architecture design of library e-book loan integration platform
Big data technology refers to the application technology of big data, including all kinds of big data platforms, big data index system and other big data application technologies. The system of big data technology is huge and complex. The basic technology includes data collection, data preprocessing, distributed storage, NoSQL database, data warehouse, machine learning, parallel computing, visualization and other technical categories and different technical levels. The generalized big data processing framework is mainly divided into the following aspects: data collection and preprocessing, data storage, data cleaning, data query analysis and data visualization. Big data technology has the following characteristics:
able to process large amounts of data;
able to process different types of data. Big data technology can not only process a large number of simple data, but also process some complex data, such as text data, sound data, image data and so on;
the application of big data technology has the effect of low density and high value. For some scattered and various types of data, if the meaning expressed by the information cannot be analyzed in a short time, then big data analysis technology can be used to dig out the hidden value of the information, so as to facilitate the work and research or other USES, and facilitate the convenience and depth of data integration.
Therefore, this paper adopts big data technology to study the integrated method of library e-book borrowing.
The design of Library e-book borrowing integration platform architecture is based on large data analysis, taking the library as the main body of platform architecture, introducing open API design concept, following the principles of openness and expansibility, adopting modularization idea and compatible with App, Web and other forms of services [8], which build an independent and independent e-book borrowing integration platform. Data layer, business layer, interface layer and application layer together constitute the framework of Library e-book borrowing integration platform [3].
Data layer: Data layer designs big data analysis module based on big data analysis technology. It is mainly responsible for collecting a series of borrowing historical data generated by library e-book borrowing integration platform and forming a data decision platform based on big data. The source of Library e-books is the basis of data layer. The main form of acquisition is purchasing and leasing through user-driven (PDA), which can not only fully meet the needs of users, but also effectively save funds. With the rapid development of digital publishing industry and the emergence of new media forms, electronic book submission has become one of the sources of electronic number in libraries. By establishing a long-term preservation mechanism, it lays a foundation for the improvement of digital reading service system [5,13].
Business layer: responsible for managing the source of e-books, designing e-book borrowing services, revealing the related functions of e-books, and integrating the historical data of e-book borrowing. The core of business layer is to integrate and process the historical data of e-book borrowing through data integration module, so as to realize the behavior analysis of e-book readers based on big data. Duplicate management in business layer mainly includes design module function business, including digital copyright management, user management, content planning, recommendation business, etc.
E-book borrowing process
The borrowing process of e-books is shown in Fig. 1.
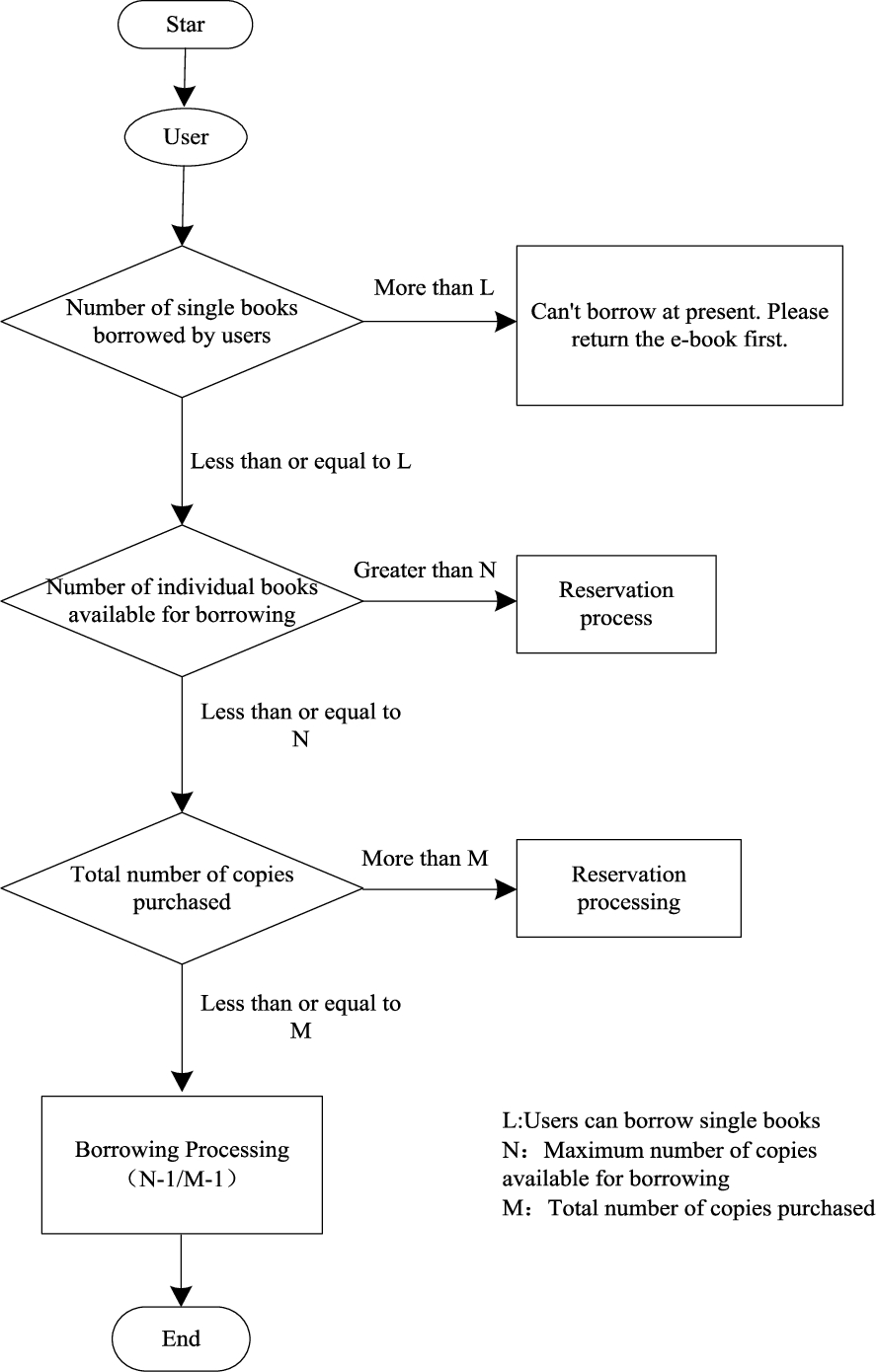
E-book borrowing process.
In order to avoid the long-term non-borrowing of purchased e-books and the occupation of the total number of copies, the e-books are purchased from the e-book suppliers according to the total number of copies of e-books, and a list of e-books is established. All the e-books in the list are added to the library e-book borrowing service platform, and the total number of e-books that can be borrowed as set (M) [11]. In order to solve the problem that the borrowing rate of popular e-books greatly affects the interests of e-book suppliers and take account of the utilization rate of e-books, a dynamic setting of the maximum number of borrowable copies (N) is adopted for some books in the e-book borrowing platform. When the number of individual borrowable copies is larger than the maximum number of borrowable copies (N), Users are required to make reservations for the e-book, dynamically adjust the maximum number of borrowed copies of the e-book according to the number of reservations, and provide relevant data support for future purchase of e-book [1,14].
In order to effectively improve the utilization rate of e-books, the service side also sets the borrowing period of e-books. When the reading period exceeds, the users will not be able to continue reading. Before the expiration, the users will be given relevant prompts, and the re-subscription button will be given to facilitate users to continue borrowing the e-book.
The library e-book borrowing process can set the number of e-book copies and the duration of e-book borrowing from both the client and the server. On the basis of not affecting the utilization rate of e-book, it can eliminate the concerns of e-book suppliers and set the parameters of e-book by dynamic setting method [6,18], regardless of future technological development and e-book use. How the market industry changes will not affect the operation of the platform.
The data integration module adopts the layered design with strong expansibility and high coupling to integrate the historical data of e-book borrowing. The layered design can increase, decrease and modify the real-time function modules on the premise of ensuring the functional operation, operability and security of the whole e-book borrowing historical data integration module. The architecture of the data integration module is shown in Fig. 2.

Architecture of data integration module.
As shown in Fig. 2, data integration module can be divided into management operation layer, data pre-cleaning and filtering layer, data integration layer and large data resource layer according to the concept of hierarchical design.
The management operation layer mainly provides an interface for administrators to facilitate the maintenance and management of integrated modules. It mainly includes basic parameter setting, data storage, data query and management, and operation functions.
Data pre-cleaning and filtering layer is the precondition of data integration layer. Mainly in order to eliminate the useless data in electronic borrowing historical data, retain high value and operability data [2]. The specific method is to set up the data cleaning and filtering rules in advance, to analyze the historical data of e-book borrowing based on big data thinking mode and following the comprehensive principle one by one, and to check the usability. The borrowing history data of e-books, which are cleaned and filtered, are stored in an external data repository.
Data integration layer is the core layer of data integration module. It mainly adopts the integration method based on non-relational database to realize the integration of electronic borrowing historical data. The historical data of e-book borrowing temporarily stored in the external data repository is extracted, and the historical data of e-book borrowing extracted is transformed by the conversion controller of the integrated control area [16]. The basic management layer accesses the historical data of e-book borrowing transformed by the integrated operation engine and stores it to the main number in the database, then complete the integration of library e-book borrowing history data.
Big data resource layer is composed of main database, temporary database, system database and big data resource. Due to the limitation of the same large data integration process, different time points and databases will produce different situations. Therefore, the generation of data synchronization mechanism is necessary. Data synchronization mechanism can ensure that the data of different databases remain the same at the same time, and improve the security and controllability of data.
In order to solve the data partial distortion and data loss caused by structured data conversion, the middleware based on non-relational database server is used to integrate the historical data of e-book borrowing [4,10]. The structure of integration model based on non-relational database is shown in Fig. 3.

Structural diagram of integration model based on non-relational database.
The integration model based on non-relational database is composed of data layer, middleware layer and user layer.
The data layer includes the interfaces of structured, semi-structured and unstructured historical data sources for library e-books borrowing.
The content of middleware layer is to respond to the requests for conversion, integration and query of the historical data structure of library e-book borrowing. It provides different data packers for different e-book borrowing historical data, and extracts the corresponding patterns and data of different e-book borrowing historical data sources. When new historical data of e-book borrowing is generated, the integration of historical data of e-book borrowing can be realized by adding data packers corresponding to the data. The non-relational database server processes the historical data of e-book borrowing, packages the historical data of Library e-book borrowing, and stores them in the collection of non-relational databases to provide access services to the outside world.
User interface layer is an interactive interface, which exists between users and platforms. The results of historical data query of e-book borrowing with different display modes and structures are presented.
At present, big data has entered the specific implementation stage from the theoretical research stage, and the organic combination of large data platform and mobile Internet is the general trend. Integrating big data analysis into the framework of Library e-book borrowing platform is conducive to the development of platform services and e-book procurement, and reflects the value of Library e-book borrowing platform. The platform business layer realizes reader behavior analysis based on big data according to data integration module. The flow chart of reader behavior analysis based on large data is shown in Fig. 4.

Flow chart of reader behavior analysis based on large data.
Based on the thinking mode of big data, the library e-book borrowing platform collects the historical data of e-book borrowing according to the comprehensive principle. For example, the server collects log data, website data that cannot be recorded in the log, etc. Data integration module is used to pre-process the collected e-book borrowing history data, such as data cleaning and filtering, and middleware model integration method based on non-relational database is used to integrate the pre-processed e-book borrowing history data. Finally, the integration results are displayed individually through the display layer to increase user experience and achieve intelligent recommendation.
In order to verify the practical application effect of the proposed integration method of library e-book borrowing history based on big data technology, a test is needed. The overall experimental scheme is as follows: setting experimental environment and experimental objects, obtaining experimental sample data, choosing literature [15] method and literature [12] method as experimental comparison method, testing the function and stability of the proposed method. On this basis, the throughput of different research methods is compared, and the higher the throughput is, the better the explanation is given. The stronger the data processing ability of this method is, the lower the response delay of different research methods is, the faster the responses speed of this method is. Then the shorter the integration time of different research methods is, the higher the integration efficiency of this method is. Finally, the integration of different methods is compared. The lower the error rate is, the higher the integration accuracy of the method is. The specific experimental process is as follows:
Statistical table of integration results of October e-book borrowing history data of Peking University students
Statistical table of integration results of October e-book borrowing history data of Peking University students
Taking the historical data of Library e-book borrowing of students from various colleges of Peking University in 2017 as the experimental object, this paper adopts the method of integrating the historical data of library e-book borrowing of students from various colleges of Peking University in October, and analyses the situation of library e-book borrowing of students from various colleges of Peking University. The integrated results statistics are as follows:
Take the above data as the experimental data, and take the first data at the beginning of the experiment as the initial data. From the data in Table 1, we can see that there are great differences in the number of e-books borrowed by various colleges of Peking University. The number of e-books borrowed by students from the college of arts, the college of physical education and the college of music is less, and the number of e-books borrowed per capita per month is 1.83, 1.70 and 0.61, respectively. The proportion of e-books borrowed by the colleges of journalism and media, economics and archaeology is 10.84%, 12.15% and 24.60%, respectively. Among them, 20 students in the college of archaeology borrow more than 30 e-books every month. Therefore, according to the individual characteristics of students, libraries can increase the allocation of relevant literature resources to meet students’ needs for information resources to the maximum extent.
In order to verify the performance of the E-book borrowing platform in the library of college of financial management in Peking University after integrating borrowed historical data, the functions of user login, e-book query, e-book reservation and e-book purchase are tested. The results are shown in Table 2.
Functional test results
According to the data in Table 2, the test function includes eight items, totally 28 function points, and the passing rate of each function point is 100%. The results show that the performance of the e-book borrowing platform in the library of college of financial management in Peking University after integrating borrowed historical data with this method is good, which shows the integration method in this paper. It can provide valuable data integration services for library e-book borrowing platform. The practical application value of this method is high.
At the same time, the stability of the library e-book borrowing platform analyzed in Table 3 is analyzed, and the software running time of the platform is tested. Table 3 is the stability test results.
Stability test results
Through the analysis of the data in Table 3, it can be seen that the stability requirement of the library e-book borrowing platform is that the software can run continuously for 24 hours, and the average running time of the actual test can reach 32 hours, which meets the stability requirement of the platform. It can be seen that the efficient data integration service provided by the data integration method in this paper guarantees the books.
Figure 5 is the throughput comparison of three methods for integrating historical data of Library e-book borrowing.

Throughput comparison results of three methods.
Figure 5 shows that the throughput of this method is much higher than that of the other two methods. The throughput of this method is up to 97%. The results show that the data processing ability of this method is strong.
Figure 6 is a comparison of response time delays of three methods for the integration of Library e-book borrowing history data.
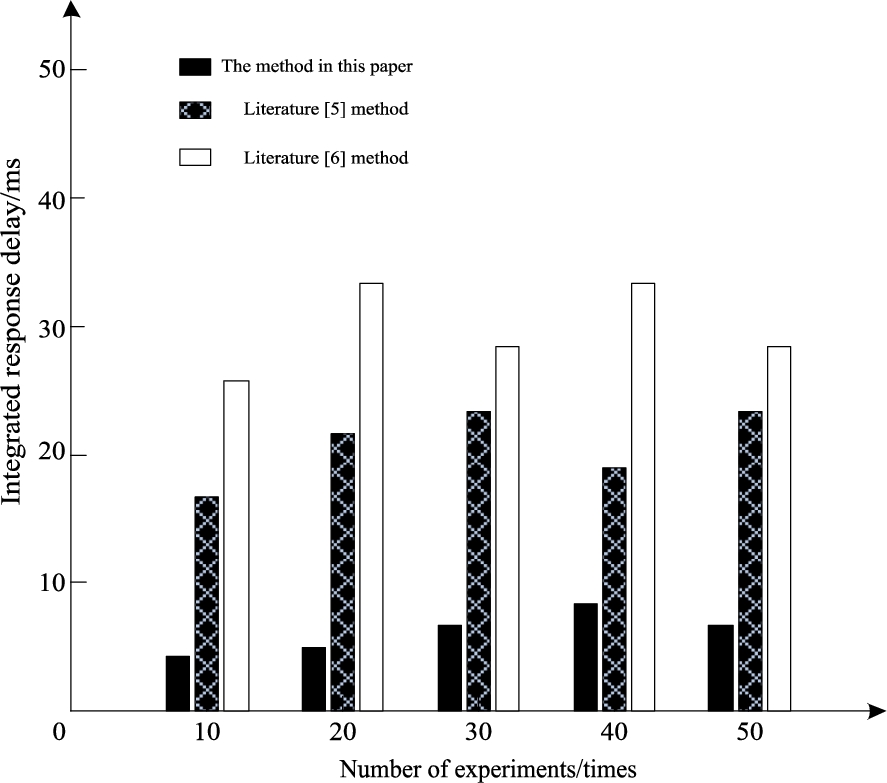
Comparison of response time delays of three methods.
Time comparison of three methods for integrating data of different sizes
From Fig. 6, we can see that the average time delay of integration of historical data of library e-book borrowing is about 21 ms by using literature [15], 31 ms by using literature [12]. However, the average time delay of the integration of Library e-book borrowing history data using this method is only about 6 ms, which is far less than the other two methods.
Table 4 compares the integration time required for the integration of historical data of library e-book borrowing in different data scales by three methods.
The analysis of Table 4 shows that under the same data entry, the integration time of historical data of Library e-book borrowing using this method is significantly less than that of literature [15] and literature [12]. When the data entry is
Figure 7 shows the error rate of integration of historical data of e-book lending in libraries by three methods under different historical window lengths.
It can be seen from Fig. 7 that the error rate of integrating historical data of library e-book borrowing with this method is significantly lower than that of literature [15] method and literature [12] method. Because the longer the history window is, the larger the data block is and the fewer windows need to be integrated, the integration error rate will decrease with the increase of the history window. Compared with literature [15] and literature [12], the error rate fluctuation of this method is reduced. When the window length is 40 s, the error rate of this method has dropped to about 2.5%, and the window length continues to increase. The error rate decreases slightly and the stability is good. The results show that the error rate and stability of the integration of historical data of Library e-book borrowing are small.
This paper studies the integration method of historical data of library e-book lending based on big data technology. The main advantage of this method lies in the application of big data technology to all aspects of the integration of historical data of e-book lending.
When designing the framework of the library e-book lending integration platform, the data layer of the platform designs the large data analysis module based on the big data analysis technology, which is responsible for collecting a series of borrowing historical data generated by the library e-book lending integration platform. It provides a basis for a series of processing of historical data of e-book borrowing in subsequent libraries.
Comparison of integration error rates of three methods.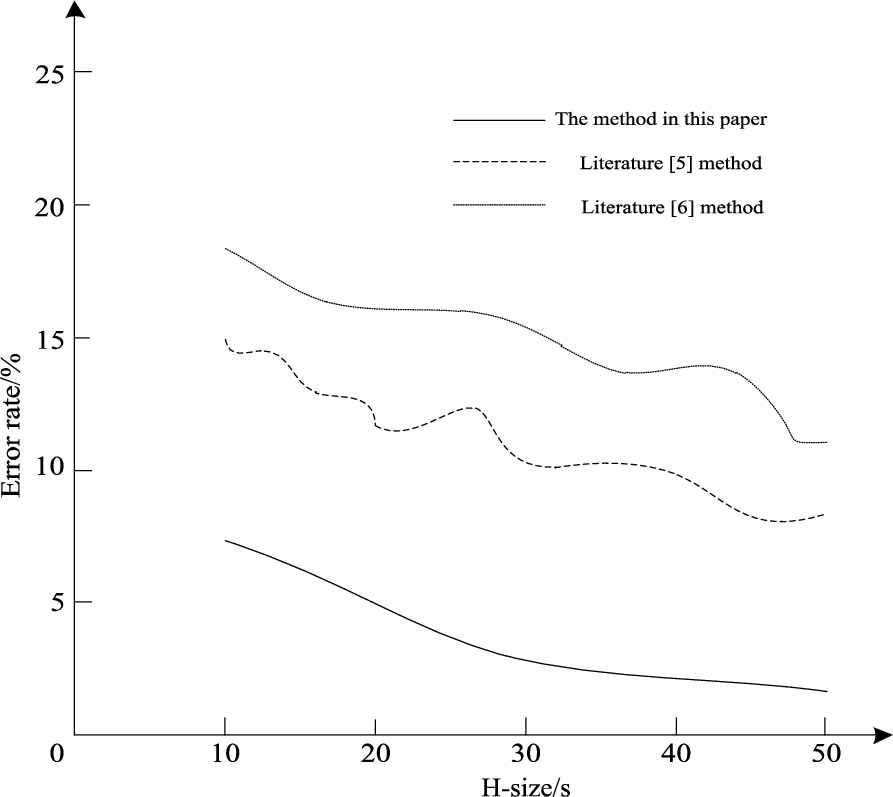
The integration layer in the data integration module adopts the middleware method based on non-relational database to realize the integration of library borrowing history data. The data layer of this method includes structured, semi-structured and unstructured interface of library electronic book borrowing history data source, and uses big data technology to integrate library borrowing history data. It fully collects and converts data structure through middleware layer, so as to realize the integration of historical data of e-book borrowing.
The experimental results show that the proposed method has the advantages of short time delay and low integration error rate, and the highest integration throughput can reach 97%. The practical application effect is good.
This method can reveal readers’ reading rules, analyze readers’ reading preferences and other behaviors, improve service efficiency, optimize service level, and better provide diversified personalized services for readers. It is a great progress of borrowing service and borrowing mode under the development of modern information technology.
In the future, the data processing and the service of the digital library will have obvious change, will be a shift from the traditional services such as information query, push in the vast amounts of data analysis and dig out the potential valuable information is of great significance, so as the library network, development of electronic, digital, intelligent and virtualization, further perfect the data library construction, library services provide more convenience for people.