
Abstract
Domain adaptation aims to solve the problems of lacking labels. Most existing works of domain adaptation mainly focus on aligning the feature distributions between the source and target domain. However, in the field of Natural Language Processing, some of the words in different domains convey different sentiment. Thus not all features of the source domain should be transferred, and it would cause negative transfer when aligning the untransferable features. To address this issue, we propose a Correlation Alignment with Attention mechanism for unsupervised Domain Adaptation (CAADA) model. In the model, an attention mechanism is introduced into the transfer process for domain adaptation, which can capture the positively transferable features in source and target domain. Moreover, the CORrelation ALignment (CORAL) loss is utilized to minimize the domain discrepancy by aligning the second-order statistics of the positively transferable features extracted by the attention mechanism. Extensive experiments on the Amazon review dataset demonstrate the effectiveness of CAADA method.
Introduction
Neural network based models have achieved great success in many fields, such as natural language processing [1,2] and computer vision [3]. However, because of the domain shift, these models trained on the large-scale labeled datasets have a low generation in novel tasks and datasets. Domain adaptation [4], a field belonging to transfer learning, aims to utilize the knowledge extracted from the label-rich source domain to improve the performance on the target domain with scarce annotation data, which can reduce the negative effect raised from domain shift.
Earlier methods of domain adaptation focus to learn domain-invariant feature representations by minimizing the domain discrepancy between the source and target domain, such as Transfer Kernel Learning [5], Transfer Component Analysis [6]. Recently, neural network based models have been widely used in domain adaptation. Long et al. [7] proposed a deep convolutional neural network for domain adaptation which utilizes multiple kernels selection for averaging embedding matching. Ganin et al. [8] proposed an adversarial framework for domain adaptation which introduces adversarial training to extract domain-invariant features. The feature extractor is trained to minimize the classification loss and fool the discriminator, which is trained to distinguish the data from the source or target domain. Zhou et al. [9] proposed a Deep Unsupervised Convolutional Domain Adaptation (DUCDA) method which consists of two correlation statistics loss for aligning distributions and measuring the domain discrepancy between the source and target domain.
The aforementioned works mainly align the feature distributions between the source and target domain. However, not all features of the source domain should be transferred. For example, “convenient” and “clean” are frequency words in the kitchen domain; however, these words are rare in the books domain. Moreover, some of the words in different domains convey different sentiment. For instance, in DVDs domain, the word “unpredictable” in “unpredictable storyline!” is a positive word. But in the electronics domain, “unpredictable” is a negative word. If the model aligns the untransferable features, it may occur negative transfer.
To address the above problem, we propose an attention transfer process for domain adaptation which can align features in a selective way. An attention mechanism is introduced into our model to capture the positively transferable features of source domain which is benefit for target domain. In order to minimize the domain discrepancy, we utilize CORAL loss to align the second-order statistics of the positively transferable features extracted by the attention mechanism. Experimental results demonstrate that our model can effectively improve the performance of domain adaptation.
In summary, the main contributions of this paper are as follows:
We propose an attention transfer process for domain adaptation which introduces an attention mechanism into the model to capture the positively transferable features in the source and target domain. Besides, CORAL loss is introduced into this model for minimizing the domain discrepancy which further improves the robustness of CAADA.
We evaluate our model on Amazon reviews datasets, and experimental results show that our approach outperforms other baseline methods.
The remaining of the paper is organized as follows. In Section 2, we presents the related works on domain adaptation. In Section 3, we briefly describe the proposed method. In Section 4, we present implementation process and experimental results. Finally, Section 5 provides the conclusion of this study.
Related work
In recent years, domain adaptation has become a promising direction. We focus on unsupervised domain adaptation methods and attention mechanism.
Unsupervised domain adaptation
Unsupervised domain adaptation, as a special case of transfer learning, aims to utilize the knowledge extracted from the source domain with abundant labeled data to improve the performance of target domain with no labeled data. Training a classifier using labeled source data and then fine-tuning the classifier in target labeled data is the most common practice. Many works use the Maximum Mean Discrepancy (MMD) to minimize the distance between source and target domain. Specifically, Tzeng et al. [10] proposed a CNN-based model for domain adaptation. This model introduces an adaptation layer and a domain confusion loss which aim to learn semantically meaningful and domain-invariant features respectively. However, this model only used single-kernel MMD to decrease the domain discrepancy. Based on this model, Zhou et al. [11] proposed to use multi-kernel Maximum Mean Discrepancy (MK-MMD) for minimizing the domain discrepancy between the source and target domain. In contrast to this two methods, our method introduce CORAL to minimize the domain discrepancy which can align the second-order statistics of source and target domain. The proposed method also achieves better results on the popular benchmark dataset.
Attention mechanism
Attention mechanism has made great success in network architectures which can capture important features. Successive works on attention mechanism include machine translation [12], image segmentation [13]. The key idea of attention mechanism is that not all low-level position contributes a equal importance for the high-level representation. Recently, attention mechanism is also used in domain adaptation. Wang et al. [14] proposed a multi-adversarial domain adaptation method. This model introduces transferable local attention and transferable global attention which aim to highlight transferable regions and highlight transferable images respectively. Li et al. [15] proposed hierarchical attention transfer mechanism for domain adaptation which can transfer attentions for emotions across domains to decrease the domain discrepancy. These methods has a similar working procedure to ours. However, our approach is simpler. The feature learning, classifier learning and domain adaptation are in a unified architecture with a single back-propagation.
The notation and denotation
The notation and denotation
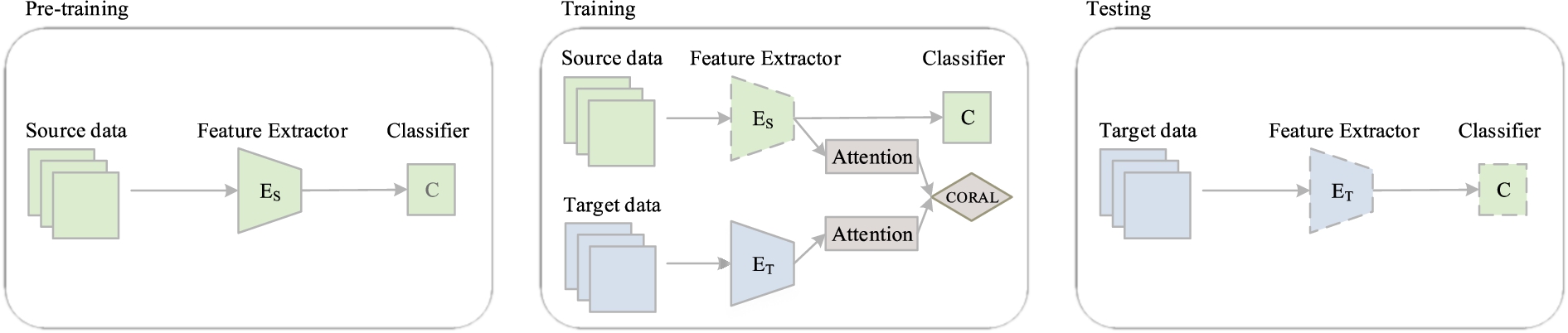
An overview of CAADA approach. Dashed lines indicate fixed network parameters.
Task description and notations
In unsupervised domain adaptation, we have a source domain
Overview
CAADA method consists of feature extractors
Attention mechanism
Since not all features of the source domain should be transferred, and it would
cause negative transfer when aligning the untransferable features. In this
paper, we introduce an attention mechanism into the transfer process for domain
adaptation to capture the positively transferable features of the source domain
which is benefit for target domain. The attention mechanism on the source stream
can be formulated as
Correlation alignment
To minimize the domain discrepancy, we introduce the CORrelation ALignment
(CORAL) [16] loss into our model
by aligning the second-order statistics of the positively transferable features
extracted by the attention mechanism on the source and target stream, which can
align the positively transferable features of both domain. CORAL has achieved
good performance in domain adaptation [17,18]. We suppose that
Overall objective
The overall objective function of our proposed model can be formulated as
follows.
Experiments
Dataset
We evaluate our model on the Amazon reviews benchmark datasets [19], which have been widely used in domain adaptation. The dataset1
contains reviews of four different categories of products: books (Statistics of the Amazon review dataset including the number of document, labeled and unlabeled reviews for each domain as well as the ration of negative samples in the unlabeled data
We compare our proposed model CAADA with the several baseline approaches. The
compared methods are listed as follows:
Implementation details
In this paper, we use multi-layer perceptron (MLP) as our basic network. For each
task, feature extractors
Experimental results
The results on the 12 unsupervised domain adaptation tasks of different methods are shown in Table 3. From this table, we can see that our proposed model CAADA achieves the best performances among all the models. SONLY method achieves a poor performance with 75.69% on average because of no adaptive. JDOT method achieves 78.70% on average due to its poor transformation between the source and target domain, while CAADA can capture the positively transferable features and align them better. Compared to the MMD method, CAADA outperforms it by 4.13% on average which demonstrates CORAL superior to MMD in some extent. In order to validate the effectiveness of attention mechanism, we compare with variants of CAADA. We can see that CAADA outperforms CADA by 1.03% on average. This proves that attention mechanism can capture the positively transferable features and further enhance feature transferability of CAADA.
Accuracy (%) of our method with competing approaches on the Amazon
reviews dataset
Accuracy (%) of our method with competing approaches on the Amazon reviews dataset
In the following, we investigate the effects of the hyper-parameter
α which is sampled from

Performance at different α of CAADA.
In order to investigate the influence of labeled data size, we experiment with different ratios (20%, 40%, 60%, 80%, 100%) of labeled data. The dynamic performance of our method (CAADA) and SONLY on task E → K is shown in Fig. 3. We can observe that the accuracy of CAADA and SONLY methods increase as the ratio of labeled data increases. However, the CAADA outperforms SONLY whatever the ratio of labeled data is. This demonstrates that our approach can transfer knowledge from source domain to improve the performance of target domain. Moreover, the accuracy of our method CAADA with 60% labeled data still outperforms SONLY with 100% labeled data. This further proves that our proposed model can reduce the need for large-scale labeled datasets by utilizing domain adaptation.

Accuracy on task E → K of our method (CAADA) and SONLY with different ratios of labeled data.

The t-SNE visualization on the distribution of source and target domain in the hidden space. The red and blue points denote the positive and negative instances of source domain, purple and darkcyan points denote the positive and negative instances of target domain.
To get an intuitive understanding of the learned features of CAADA, we visualize the distribution of the source and target domain learned by CADA and CAADA on tasks D → B and E → K using t-SNE embeddings [23] in Fig. 4. We can observe that the representations learned by CADA has a great overlap between the domain D and B, E and K. The positive and negative instances of source and target domain are mix together very well. While the representations learned by CAADA has both overlapping and non-overlapping areas which selectively align features between the source and target domain. Owing to not all features of source domain should be transferred, and it would cause negative transfer when aligning the untransferable features. Attention mechanism can force model to learn the positively transferable features which can enhance the feature transferability and robustness of CAADA. Moreover, the category boundaries of the source and target domain in both methods are clear. The red (purple) and blue (darkcyan) points are separated very well.
Conclusions
In this paper, we propose a Correlation Alignment with Attention mechanism for unsupervised Domain Adaptation (CAADA) method. In our approach, we introduce an attention mechanism into transfer process for domain adaptation to capture the positively transferable features which is benefit for target domain. Besides, CORAL loss is used to minimize the domain discrepancy by aligning the second-order statistics of the positively transferable features extracted by attention mechanism on the source and target stream which can align the positively transferable features between both domain and further enhance the robustness of CAADA. The experiments on Amazon reviews benchmark corpora demonstrate that our method CAADA outperforms other baseline methods and can effectively improve the performance of domain adaptation.
This work introduces a simple transfer process and achieves a good results. In the future, we plan to combine the domain adaptation with reinforcement learning to capture the positively transferable features in source and target domain.
Footnotes
Acknowledgements
This work is supported in part by the Shandong Natural Science Foundation (No. ZR2017LF004, No. ZR2018LF002), National Natural Science Foundation of China (No. 31500669), Shandong Provincial Higher Education Science and Technology Plan Project (No. J16LN20).