
Abstract
The legal judgments are always based on the description of the case, the legal document. However, retrieving and understanding large numbers of relevant legal documents is a time-consuming task for legal workers. The legal judgment prediction (LJP) focus on applying artificial intelligence technology to provide decision support for legal workers. The prison term prediction(PTP) is an important task in LJP which aims to predict the term of penalty utilizing machine learning methods, thus supporting the judgement. Long-Short Term Memory(LSTM) Networks are a special type of Recurrent Neural Networks(RNN) that are capable of handling long term dependencies without being affected by an unstable gradient. Mainstream RNN models such as LSTM and GRU can capture long-distance correlation but training is time-consuming, while traditional CNN can be trained in parallel but pay more attention to local information. Both have shortcomings in case description prediction. This paper proposes a prison term prediction model for legal documents. The model adds causal expansion convolution in general TextCNN to make the model not only limited to the most important keyword segment, but also focus on the text near the key segments and the corresponding logical relationship of this paragraph, thereby improving the predicting effect and the accuracy on the data set. The causal TextCNN in this paper can understand the causal logical relationship in the text, especially the relationship between the legal text and the prison term. Since the model uses all CNN convolutions, compared with traditional sequence models such as GRU and LSTM, it can be trained in parallel to improve the training speed and can handling long term. So causal convolution can make up for the shortcomings of TextCNN and RNN models. In summary, the PTP model based on causality is a good solution to this problem. In addition, the case description is usually longer than traditional natural language sentences and the key information related to the prison term is not limited to local words. Therefore, it is crucial to capture substantially longer memory for LJP domains where a long history is required. In this paper, we propose a Causality CNN-based Prison Term Prediction model based on fact descriptions, in which the Causal TextCNN method is applied to build long effective history sizes (i.e., the ability for the networks to look very far into the past to make a prediction) using a combination of very deep networks (augmented with residual layers) and dilated convolutions. The experimental results on a public data show that the proposed model outperforms several CNN and RNN based baselines.
Introduction
The recently developments of artificial intelligence in legal domain have brought benefits to legal workers for liberating from mass of paperwork as well as ordinary people who have legal issues. One of the typical applications of legal intelligence is the legal judgment prediction (LJP). As one of the important tasks in LJP, the prison term prediction(PTP) is to support legal workers on predicting the term of penalty for a certain type of criminal case by analyzing the textual fact description. At present, the counting unit of the prison term prediction task is month, and the numerical value is relatively scattered, which is difficult for the traditional regression prediction model, and is easy to cause a result with lower accuracy. With the development of deep learning in legal domain, LSTM [22], CNN [11] and TextCNN [10] methods are applied to help predicting the prison term.
The case description is a typical text sequence. Traditional sequence models (such as LSTM and RNN) are recursive architectures that capture infinitely long historical information, which usually leads to missing historical data. However, case descriptions are often longer than common sentences in other reading materials, and the key information related to the prison term not only exist locally. It is crucial to capture substantially longer memory for LJP domains where a long history is required. At the same time, because of the need to deal with sequence problems, ordinary CNN convolution is not applicable. In order to solve this problem, in this paper we not only hope to understand the semantic information from the long sequence text, but also to explore the relationship between the text and the prison term. For this purpose, this paper proposes a prison term prediction model based on causal dilated convolution, which can store long history information, explore the logical relationship between sentences around the most critical segments in the case description, and extract the most important local features.
The CNN-based PTP model proposed in this paper is based on TextCNN, and replaces the commonly used convolution kernel with causal dilated convolution, because the causal dilated network can capture long historical information from the text in the processing of sequence data. Although the traditional TextCNN neural network is suitable for extracting various kinds of different semantic information as data features from the rich semantic information of the text, it has a weak ability to obtain the relationship between the context of the text information. In this way, the combination of causal dilated convolution and TextCNN improves the model’s ability to extract the most relevant sentences in a long sequence of text. Experiments are conducted on a public real-world dataset, and our model has better performance than other popular baselines.
To summarize, we make the main contributions as follows:
We propose a novel model to extract features from both the local and the long history information in case descriptions for prison term prediction. To address these issues, we employ dilated causal convolution to get a big receptive field with small numbers of convolutional layers. We utilize features extracted in the accusation prediction task as external knowledge for prison term prediction. To achieve this, a feature fusion method is introduced to enhance the model effects. We conduct extensive experiments on a real-world dataset, and our model significantly outperforms other baselines.
Related work
Legal Judgment Prediction(LJP) is a typical Legal Artificial Intelligence task. In the past years, artificial intelligence solutions, especially language processing framework and methods are applying to various of LJP tasks as well as other domain. For instance, Zhou et al. [26] used an iterative method for personalized results adaptation in cross-language search. Peng et al. [18] introduced a framework for learning cross-lingual word embedding with topics. In LJP domain, Goncalves et al. [7] classified legal text in 3,000 categories based on a taxonomy of legal concepts. Machine learning is also a popular thread to explore LJP methods. A case-based reasoning system using KNN model [13] was presented to classify 12 common criminal charges in Taiwan. Lin et al. [12] take advantage of machine learning to identify robbery and intimidation cases and predict their sentences by considering manually defined legal factor labels. Liu et al. [14] introduced a preliminary article SVM classification step followed by re-ranking the results using word-level features and co-occurrence tendency among law articles. A linear SVM classifier [21] is applied to predict case judgments of the French Supreme Court, and reported the performance respectively in case ruling prediction, law area prediction, and time span prediction of ruling issued. Katz et al. [9] built randomized trees with features extracted from case profiles in predicting the US Supreme Court’s behavior. Recently, neural network-based methods have been proven with better results. Luo et al. [15] reported a neural network with attention mechanism to jointly implement the accusation prediction and the relevant article extraction, which has reasonable generalization ability on multiple fact descriptions. Pan et al. [17] propose multi-scale attention to handle the cases with multiple defendants. Besides, some researchers are exploring LJP using deep learning technology. Hu et al. [8] incorporate ten discriminative legal attributes to help predict low-frequency criminal charges. Chen et al. [2] exploit the gating mechanism to enhance the performance of the prison term prediction. Wang et al. [24] proposed a framework based on FastText and TextCNN to combine the deep learning with justice to predict accusation, which convert accusation prediction into a multi-label text classification problem. Tran et al. [23] adopt a CNN-based model with document and sentence level pooling, which achieves better performance on COLIEE 2018.
Causal Convolution is proposed as a new convolution method for the transient analysis of linear system described in the frequency-domain [1]. The method described is capable of handling arbitrary excitation signals, and may in principle be readily extended to more general nonlinear analysis. Many practicing fields are seen the utilization of causal convolutions in recent years. Cheng et al. [3] use causal convolutions for temporal feature learning towards better scalability in their works of action classification. For causal convolution, a problem is that many layers or large filters are needed to increase the receptive field of convolution. Dilated convolution can solve this problem. Oord et al. [16] in their work of WaveNet used a dilated causal convolutional neural network (DCCNN) to process one-dimensional time-series data, such as sound waves. A DCCNN model can efficiently exploit broad-range history to enable training of deeper networks and to accelerate convergence. Wang et al. [25] and Shivam K et al. [20] use DCCNN-based methods to forecasting water-level and wind speed, achieved better performance in their field. Daiya et la. [5] integrated an attention augmented dilated causal convolutional network to capture temporal dynamics of financial indicators. The development of causal convolution and legal intelligence inspires us to explore the possibility of applying relevant methods to LJP. Multi-label charge prediction in legal field is popular for predicting charge labels from case description. Wei et al. [6] proposed a relation learning hierarchical framework for multi-label charge prediction. Under the dynamic merging attention (DMA) model and the number learning network (NLN) model, the charge prediction performance is improved more than 3%–23%.
Problem description and definition
The prison term prediction is a typical regression prediction task. The predicted value of the prison term is affected by many factors in the relevant legal documents, such as the crime class, the degree of crime, the applicable legal provisions, the consequences of the crime, the motive of the crime, etc. Assuming that each factor is an independent case description, the sentence prediction task is to find a function that can obtain the closest value to the actual prison term based on these independent variables. PTP selects and filters the content of the case description, extracts the main key phrases from a large section of text, then analyzes and compares them, and finally infers the specific prison term. Suppose that the data set of the prison term prediction problem is
Prison term prediction model based on causality convolution
The framework of the causal based TPT model
The prison term prediction model proposed in this paper is based on the ability of TextCNN that can extract important local features from sequence texts. Causal convolution is used as a replacement for general convolutional layers. According to the characteristics of this task, the probability distributions of the corresponding accusations and legal provisions are applied as new features to the problem. Although TextCNN can extract important local features from the sequence text, for the prison term prediction model, it needs not just the most important keyword but the most relevant prison term and its corresponding logic so as to understand the judges’ sentencing standards and the logical relationship between criminal behavior and prison term.
Therefore, certain modifications are made on TextCNN method by replacing the commonly used convolution kernel with causal expansion convolution, because the latter can extract a large number of causal logic relationships from the text in terms of timing issues. Although TextCNN has weak ability to obtain the features of the relationship in the text, it is suitable for extracting all kinds of different semantic information as data features from the semantic information plentiful of text. The combination of both above ensures that it is able to extract the most relevant prison terms from the long sequence of texts and the corresponding features. Besides texts, additional features are also needed to enhance the information. By methods of late feature fusion, more accurate probabilistic distribution of accusations and legal provisions are merged into the extraction of causal logic features that meaningful to the prison term prediction, which further improves the effect and accuracy of the prediction. Accordingly, a Causality CNN-based Prison Term Prediction model, namely CNN-based PTP model, is proposed in this paper.
We separately define the word vector of the case description, the probabilistic distribution of accusations and legal provisions as
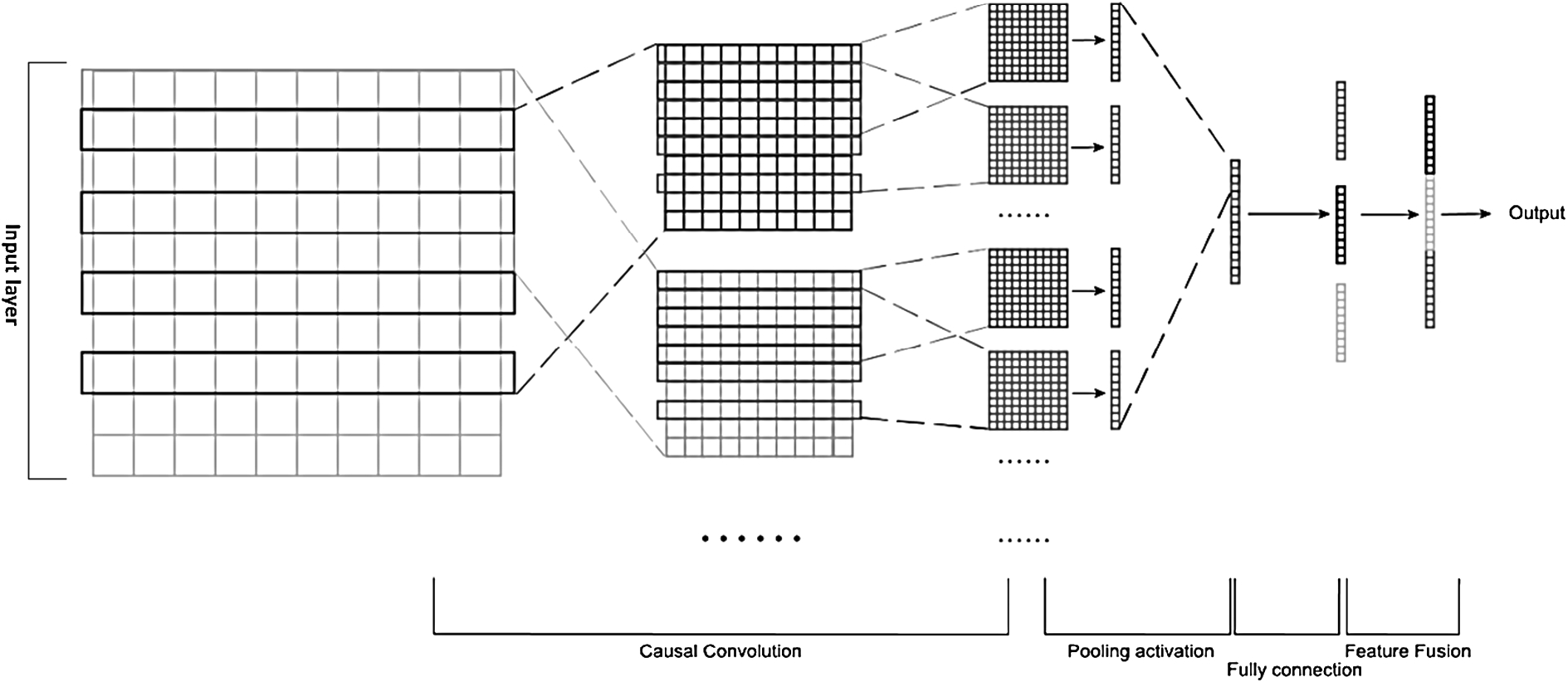
PTP model framework based on causality.
TextCNN
Before 2014, the CNN was generally considered that it belongs to the field of computer vision, but Kim made some changes to CNN and proposed a TextCNN model suitable for text classification. There are several significant differences between the TextCNN and the general CNN. At first, TextCNN has multiple convolution kernels in the same layer, which can extract various of different representations. At second, TextCNN highly compresses the extracted representations, and finally splicing the extracted high-dimensional features, so that the final extracted features have richer semantic expression. These differences make the TextCNN have better data feature extraction capabilities and stronger generalization performance than general CNN. However, it focuses on extracting local features and ignoring global features of the text.
Compared with the traditional CNN, this model is different in the way the input data are processed. Generally, the data processed by CNN is a two-dimensional image, so the convolution kernel often used to extract features sliding from left to right and from top to bottom. Although natural language also generates a two-dimensional vector after word embedding, it is meaningless to perform sliding convolution from left to right on the word vector. Therefore, the convolution kernel of TextCNN is often very wide, and only slides from top to bottom when extract features.
In addition, TextCNN also has basic neural network’s nonlinear mapping calculation and activation function calculation. Convolution calculation can use a small number of convolution kernels to extract more local information to obtain high-dimensional abstract feature representations without more preprocessing and reducing a large number of calculations. Pooling computing can extract relatively more important information from high-dimensional representations through receptive fields, and can also reduce model calculations and improve training speed. Non-linear mapping calculations and activation function calculations can provide a richer expression ability to map the features extracted from the previous calculations to a high-dimensional space.
Dilated causal convolution
Dilated causal convolution is proposed by Oord et al. [16] from Google and Deep Mind. The convolution is an improvement of the ordinary convolutional network. Because for the data of timing issues or text-related issues, most studies are accustomed to adopting variants based on recurrent neural networks (RNN), such as long and short-term memory networks (LSTM). This is because the inherent recurrent autoregressive structure of RNN perfectly represents this type of data, while the ordinary CNN cannot capture long-distance text information due to the limitation of the size of the convolution kernel. However, researches in recent years have shown that the convolutional architecture is also suitable for long-sequence text representation. For example, in the causal derivation convolution described in this paper, the convolution is a combination of two types of convolutions, namely causal convolution and dilated convolution. By stacking multiple convolution operations, the causal convolution operation can ensure that the prediction at time t is only related to the input
Causal convolution can ensure that
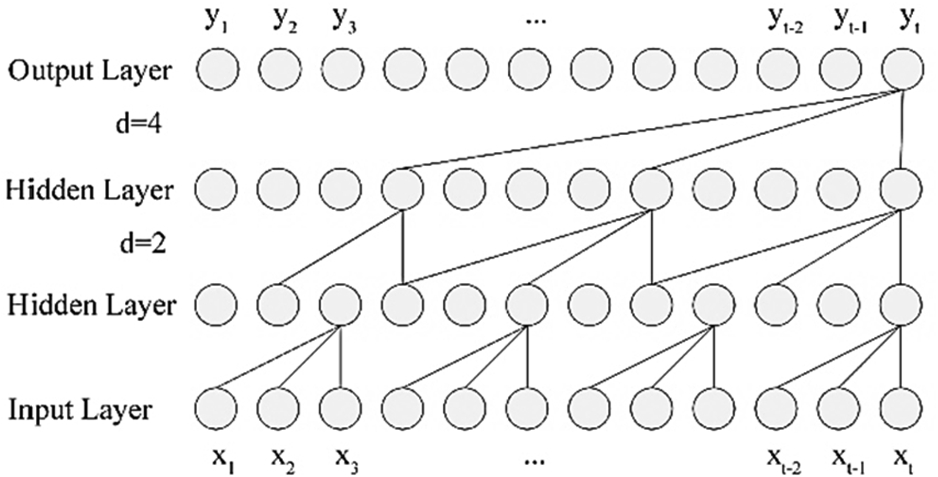
Dilated causal convolution.
Since causal convolution has a huge problem that in order to expand the receptive field of convolution, it has to superimpose very large numbers of convolutional layers or use very large windows, which will increase the complexity of the model, cause too much information loss and make it difficult to train to achieve the desired effect, so that the dilated convolution was born. The core idea of dilated convolution is to make the receptive field of the same size convolution kernel wider by skipping part of the inputs and performing interval sampling.
Combining with the causal convolution and the dilated convolution, the causal dilated convolution can get a very big receptive field with small numbers of convolutional layers, and can also capture longer dependencies on timing issues. The calculation example is shown in Eq. (1).
The description of the illegal act also has impact on the prediction of the prison term. Different features between the two facts can be identified and finally classified into the corresponding accusation, thus support for different prison term predicting results. In our previous work [6], with DMA (Dynamic Merging Attention) model, self-attention scores are obtained from case descriptions and legal provisions. Using different convolution kernels, these score matrices are dynamically extracted various features, which represents the similarity between the case description and its corresponding legal provisions and the difference between different legal provisions.
Another influential characteristic discussed in [6] is the co-occurrence relationship between the predicted accusations that defined as labels. Co-occurrence relationship refers to the phenomenon that if one kind of accusation prediction is the label described in a certain case, then another kind of accusation prediction will most likely also be the label of this case. In response to this situation, special mapping rules and convolutional networks are used to extract the co-occurrence relationship to automatically obtain the number of labels in the corresponding case. Learning similarity relationship, differential relationship and co-occurrence relationship can effectively alleviate the two difficulties of content confusion and dynamic tag numbers in multi-label accusation prediction, and can emerge into our PTR model by later feature fusion method.
In this paper, the model has obtained the extracted high-dimensional feature
Experiments
Data preprocessing
In order to objectively describe the effectiveness of the causality-based prison term prediction model, the experiment is based on the text of CAIL2018, one of the China’s largest public legal data sets. The experimental data comes from the data set of the China Law Research Cup competition (
The preprocessing process: 1) Clean up the text, delete abnormal data, meaningless stop words, specific time and other unimportant information; 2) Segmentation uses “jieba” word segmentation tool to divide one paragraph of case description into many small fragments in units of words; 3) Vectorization uses Word2Vec to get the corresponding word vector, and then splice to vector matrix.
Experiment settings and evaluation measures
Experimental setup
In order to compare the effectiveness of the causal TextCNN in the CPTP model and the effect of feature fusion, we compared the model with the baseline models. The following commonly used text prediction algorithms, CNN, TextCNN, LSTM and GRU are compared as the baseline system with the our PTP model to verify its effect.
Firstly, the number of words in the case description is set to 300. In the experiment, the Word2Vec word vector [19] is a training result of a mixture of Baidu Baike, Chinese Wikipedia, People’s Daily and other corpus. For all experiments, the “jieba” word segmentation tool is used to do some preprocessing jobs such as stop words filtering and the corresponding word segmentation. Moreover, the late fusion method is used to merge the additional features, the probability distribution of the corresponding accusations and legal provisions, with the features extracted from the CPTP model.
In the experiment, the number of convolution kernel widths of the TextCNN model are respectively set to 2, 3, 4, 5, the first layer node dimension of the fully connected layer is set to 1024, and the node dimension of the hidden layer of LSTM and GRU [4] is set to 1000. The adaptive learning rate adjustment algorithm (Adam) is used to update the model training parameters, the learning rate is set to 1e−4, the decay coefficient of the learning rate is set to 0.95, and the loss function is Cross-entropy.
Evaluation measures
The Evaluation measures used in the experiment are divided into two types, i.e., Score and the RMSE (Root Mean Squared Error) which are also used in CAIL 2018. The Score value is judged according to the distance between the predicted prison term and the standard prison term, supposing the predicted value is
It scores 1, when
RMSE is a measure of goodness of fit. As an evaluation index, it can measure the deviation between the observed value and the true value. It is calculated by the square root of the ratio of the square sum of the deviation of the observed value and the true value to the number of observations, as shown in Eq. (5).
Experimental results and analysis
Effectiveness of causal TextCNN
The comparison of the effectiveness of the causal TextCNN and other text categorization algorithms is shown in Table 1.
Comparison of text categorization algorithms
Comparison of text categorization algorithms
As can be seen from the above table, the result of Causal TextCNN is better than other commonly used algorithms in the two index. Taking Score as the evaluation index, the average value resulted by Causal TextCNN is higher than CNN, LSTM, GRU and TextCNN by 0.014, 0.024, 0.101 and 0.012. Taking RMSE as the evaluation index, the result of Causal TextCNN is 1.33, 3.13, 11.9 and 0.97 lower than that of CNN, GRU, LSTM, and TextCNN. This is because in the legal data set CAIL2018 used here, the text is long and difficult to understand, and there are strong causal logic relationships. The prediction ability of the trained model is relatively low, because these commonly used text prediction algorithms cannot understand the causal logic in the long sequence of texts, and thus cannot deduce the prison term well.
Our Causal TextCNN based on the TextCNN framework, is to use causal convolution to learn the causal logical relationship in long text sequences, especially the connection with the prison term, which makes it be able to explore the links between long sequence text and the prison term from multiple angles and so performs better on the testing data set.
In our previous work of accusation prediction [4], the description of illegal act and co-occurrence relationship used as external knowledge are proved to be an effective way to solve content confusion. Because the existing work extracts only the relevant knowledge (the legal provision) itself without considering the similarity relationship between the case description and its corresponding legal provisions, and the differential relationship between different provisions. We take the similarity relationship, the differential relationship and the co-occurrence relationship as the external knowledge for predicting prison term and use feature fusion method to test the efficiency of our model.
In order to demonstrate the effectiveness of feature fusion, the causal TextCNN is compared with some traditional text classification algorithms, CNN, TextCNN, LSTM, GRU before and after feature fusion. The Score and RMSE are used as evaluation index. The experimental results are shown in Table 2 and Table 3.
Score evaluation value before and after feature fusion (larger is better)
Score evaluation value before and after feature fusion (larger is better)
RMSE evaluation value before and after feature fusion (lower is better)
As can be seen from the above tables, after feature fusion, the accuracy of the causal TextCNN has increased significantly and is much higher than CNN, GRU, LSTM, and TextCNN. Taking Score as the evaluation index, the result value of causal TextCNN on the testing data set are 0.042, 0.053, 0.113, 0.027 higher than that of CNN, LSTM, GRU and TextCNN. Taking RMSE as the evaluation index, the result value of causal TextCNN on the data set are 6.51, 14.31, 11.9, 5.67 lower than that of CNN, GRU, LSTM, and TextCNN. Moreover, after the feature fusion, the causal TextCNN with the Score evaluation index is improved by 0.085, and with the RMSE evaluation index is improved by 10.18.
Through the results, the effectiveness of feature fusion can be demonstrated. By feature fusion, the model obtains more relevant information as an auxiliary decision-making.
Our CPTP model, short for Causality CNN-based Prison Term Prediction model is a regression model that predicts the corresponding prison term through legal documents. It is based on the TextCNN framework and uses causal convolution to replace the commonly used convolutional neural network to understand the causal logical relationship in the text, and can also understand the relationship between the texts and the prison term. In addition, features extracted from the corresponding accusations are merged with the features extracted from the CPTP model, which is further strengthen the capability of the text understanding and of the exploring of the causal relationship between the prison term and the accusations. Through testing on actual data sets, it is verified that the performance of the method proposed in this paper is significantly better than the popular baseline model.
In the future, it is possible to consider separately classifying and filtering the case of life sentence and death sentence before the prison term prediction to improve the prediction accuracy of the model. In addition, it’s also can be tried to utilize other text characteristics as features to enhance the model effect.