
Abstract
One of the ways that celebs maintain their fame in the modern era is by posting updates and photos to social media platforms like Twitter, Instagram, and Facebook. Comments left on their posts, however, expose them to cyberbullying. Cyberbullying, as a form of electronic device-based harassment, negatively impacts the lives of individuals. Thirty famous people from the fields of acting, art, music, politics, sports, and writing were chosen for this research. These notable figures include the top five Twitter followers of Turkey in each demographic. Between December 2019 and December 2020, comment responses for each celebrity were collated. Using the Deep Learning model, we were able to detect abuse content with an accuracy of 89%. Additionally, the percentage of celebrities exposed to cyberbullying by group was presented.
Introduction
With the Internet being an indispensable part of our lives, personal social media accounts are actively used more than ever. Although the desire of people to share their personal opinions and interests has made social media an important source of information, the ideas shared through these personal accounts are not always welcomed positively. In some cases, negative comments that we call cyberbullying are also seen. Cyberbullying is defined as deliberate and continuous actions taken in an aggressive manner against vulnerable persons using many electronic methods such as the internet, e-mail, text message, blog, and social media messages [1]. In general, the most common acts of cyberbullying involve issues such as sexuality, gender difference, disability, racism, terrorism, personal character, belief, behavior, appearance, and weight [2].
Cyberbullying is a common occurrence on the internet. Generally, politically based views are subject to cyberbullying. Various studies estimate that 10% to 40% of internet users are victims of cyberbullying [3]. This value is really a remarkable rate. Some artificial intelligence detection studies are being carried out to overcome this problem. In this study, cyberbullying is detected from Twitter data through deep learning. First of all, 5 people followed mostly were selected from each professional group in Turkey. These professional groups consist of actors, artists, politicians, singers, sports, and writers. There are many responses to the tweets shared by these people on Twitter. A dataset was created by collecting the responses given to the tweet post by each Twitter user between December 2019 and December 2020. In this way, a total of 2.741.848 tweets were obtained from 30 Twitter users.
The study is conducted with Turkish tweets. To the best of our knowledge, there are not many sources on the Turkish twitter dataset. Although sufficient numbers of English study and dataset sources are available, Turkish sources are very limited. It is important that it is a study conducted with nearly 3 million tweets in Turkish. In addition, we observed that the most followed celebrities on Twitter are exposed to cyberbullying. Such a study on Turkish Celebrities has not been realized before. The results are also presented statistically. The statistical results of cyberbullying are observed between 3.48% and 0.24% which can be considered a high measure of exposure.
Cyberbullying is a common problem that primarily affects people who use social media. Even if it is not physical, being subjected to cyberbullying has a negative impact on people. Cyberbullying causes psychological symptoms such as sadness, loneliness, low self-esteem, suicidal ideation, and depression [4]. Cyberbullying is considered a crime and has legal consequences. In this study, it is seen that the cyberbullying that celebrities are exposed to is quite high. Especially politicians are exposed to hundreds of cyberbullying tweets. Apart from politicians, other groups such as singers, actors, and writers are exposed to cyberbullying a lot.
In the study, labeled datasets from previous studies were examined. These data were obtained by combining the data of two different studies [4,5]. Before applying deep learning models, we trained the data with shallow classifiers such as; Naive Bayes, AdaBoost, Random Forest, and Decision Tree. Among these models, the highest accuracy rate was obtained with Decision Tree as 86%. Following that, deep learning approaches were employed with labeled same data consisting of 14.114 tweets, and accuracy of 89% was obtained. Cyberbullying was detected by applying the obtained model to all professional groups. As a result, we observed that professional groups are exposed to cyberbullying with 1.66% of the replies to the tweets they share.
The remainder of the paper is organized as follows. Section 2 provides a brief review of the related work. In Section 3, materials and methods for the study are introduced with technical details. The result of the cyberbullying detection for Turkish celebrities is presented in Section 4 with related accuracy and the F1 Score of the model. Finally, Section 5 provides a discussion about the study, and concluding remarks are sketched in Section 6.
Summary table: studies of cyberbullying detection with social media data
Summary table: studies of cyberbullying detection with social media data
ML: Machine Learning, DL: Deep Learning, RS: Robust Statistics
Today, numerous studies in the fields of natural language processing and data mining have been conducted using Twitter data. With these data, sentiment analysis and cyberbullying detection are performed. We have arranged the studies in the literature by their distinguishing characteristics and presented them in Table 1. As an example of these studies, Xujuan Zhou et al. [6] proposed a method that integrates pining mining and context-based topic modeling to analyze Twitter data containing public opinions on social media. The study was conducted using Tweets data from the 2010 Australian Federal Election. Diri et al. [7] performed a sentiment analysis with Twitter, tweets captured with a certain keyword are automatically tagged as positive, negative, and neutral with both the dictionary and the n-gram model. The dictionary and character-based n-gram methods used were approximately 70% and 69% successful, respectively. Öztürk [8], in his thesis, determining cyberbullying for Turkish, created the largest Turkish dataset ever to detect cyberbullying texts and to show the effects of preprocessing, feature selection, and classifiers for the detection of cyberbullying from texts. In this study, the pre-processing step was applied and information acquisition and filter-based methods such as chi-square were used in feature selection. Among the classifiers, Naive Bayes was determined as the most successful method in detecting cyberbullying from texts written in Turkish. In another thesis, Çürük [9] conducted on the detection of cyberbullying with artificial intelligence algorithms to investigate the effects of preprocessing, feature extraction, feature selection, and classification methods on cyberbullying detection. In the classification section, different classifiers based on Artificial Neural Network (ANN) are proposed and their results are compared with each other. Chi2, RFE, MRMR, and ReliefF algorithms have been proposed as feature selection. Bandeh Ali Talpur et al. [10], used Twitter data to detect cyberbullying. While conducting this study, they tried the supervised machine learning method. It applied the Embedding, Sentiment, and Lexicon along with the PMI-semantic orientation. The extracted features were implemented with Naïve Bayes, KNN, Decision Tree, Random Forest, and Support Vector Machine algorithms. The study conducted by Balakrishnan et al. [11] tried to detect cyberbullying by taking advantage of the psychological characteristics of Twitter users’ emotions and feelings. User personalities were determined using the Big Five and Dark Triad models, while Naïve Bayes, Random Forest, and J48 machine learning classifiers were used to classify tweets into one of four categories. The results show that cyberbullying detection increased when personalities and emotions were used, but no similar effect was observed for emotion. Muneer et al. [12] experienced 7 machine learning algorithms with 37,373 unique twitter data sets. These algorithms consist of Naive Bayes, Random Forest, Logistic Regression, Support Vector Machine (SVM), Stochastic Gradient Descent (SGD), AdaBoost, and Light Gradient Boosting Machine (LGBM). F1 score, accuracy, precision, and recall values were found for all algorithms.
In the study, Agrawal et al. [13] conducted the first systematic analysis of cyberbullying detection using data from various social media platforms. Dataset consists of 12 thousand Formspring, 16 thousand Twitter, and over 100 thousand Wikipedia data. In another deep learning cyberbullying study, Al-Ajlan et al. [14] conducted the study using Twitter data. In the study, feature extraction and classification methods were not used, but the word vector was experienced. In this way, it was aimed to preserve the meaning of the word. In another cyberbullying study on social media, Chatzakou et al. [15] analyzed 2.1 million tweets of 1.2 million Twitter users of discussions on normal topics and compared these topics to more specifically selected hate-related topics. In another deep learning cyberbullying study, Sadiq et al. [16] applied a multi-layer perceptron method on deep learning, which is a combination of CNN-LSTM and CNN-BiLSTM. The statistical results showed that the model works with 92% accuracy. Gamback et al. [17] performed two CNN models created based on different input vector sets that were fed to the neural networks for training and classification. Word vectors based on semantic information were built utilizing an unsupervised strategy, word2Vec, and compared to a randomly generated vector baseline. Aroyehun et al. [18] used Facebook posts in order to develop a baseline model and a number of deep neural network models. They experimented with deep learning models of complexity ranging from CNN, LSTM, BiLSTM, CNN-LSTM, LSTM-CNN, CNN-BiLSTM to BiLSTM-CNN. Chatzakou et al. [19] tried to detect bullying and aggressive behavior using twitter data. In order to distinguish the offensive-type people from normal people, they proposes a robust methodology with the aim of extracting text, user and network-based attributes.
Our study is based on the tweets sent to the most followed celebrities on Twitter. Celebrities consist of 30 people from different professions that are the most followed in Turkey. Labeled data, which was previously used in other studies, was used for machine learning and deep learning. Not only machine learning models were used, but also deep learning. The trained models were applied to the twitter data of 30 celebrities. It is the first study with 3 million tweets for the 30 most followed celebrities in the Turkish language. The results of the study were also shown statistically.
Materials and methods for study
Data accessibility
The training twitter data set was created by combining the labeled data sets of two different studies. This data set consists of 14.114 data and the label has the values 1 (bullying) and 0 (not bullying). 80% of the data set was evaluated for training and 20% for testing. For twitter data that we will detect cyberbullying, the most popular celebrities were determined on Twitter. For this, socialbakers website which keeps statistical data was used [20]. The data of these twitter users were collected with the application called “twint”. Twitter users’ tweets and replies can be obtained with the advanced tool written in Python language, without the need for an API [21]. Replies of identified twitter users’ tweets were collected from December 2019 to December 2020. Table 2 shows how many tweets were obtained for which Twitter user. Consequently, a total of 2.741.848 tweets from 30 twitter users were collected.
Tweet replies counts for 6 professional groups
Tweet replies counts for 6 professional groups
Contents that are shared on social media often do not include grammar rules. That’s why preprocessing is significant before working on data. Figure 1 shows the result of the reply to a tweet after preprocessing. Fetched Twitter data with the Twint tool is in corrupted format. After the date, hashtag, Twitter username, image, and video links had been removed from the data set, the stop words were removed and all twitter content was converted to lowercase letters. All the pre-processed Twitter data were saved to the file in txt format. The same procedure was applied for labeled training data.
Proposed model
The purpose of the proposed approach is primarily to create a deep learning model with the labeled twitter data and then apply this model to the Twitter data that we gathered. Labeled Twitter data is divided into bullying or not bullying. First, 14.114 labeled twitter data was run for Machine Learning classifiers Naive Bayes, AdaBoost, Random Forest, and Decision Tree. Among these classifiers, Decision Tree got the highest success value with 86%. Naive Bayes and AdaBoost had 84% accuracy, and Random Forest had 85% accuracy. Later, the same labeled data were used for Deep Learning.
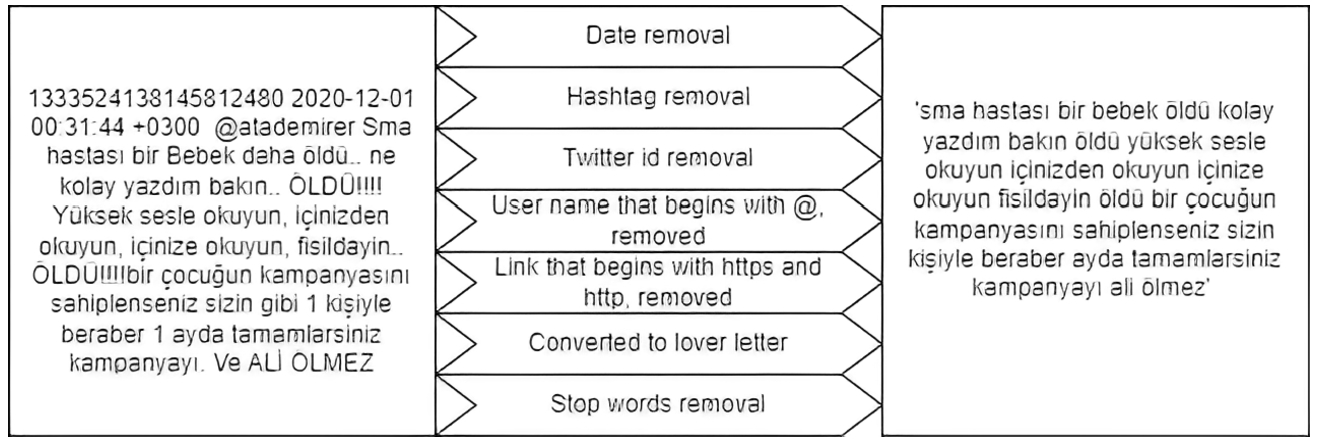
Preprocessing steps.

System architecture.
According to the system architecture of deep learning shown in Fig. 2, Word2Vec, one of the most popular techniques applied for feature extraction is used to capture the context of a word in a sentence or document.
The proposed LSTM (Long Term Short Term Memory) model’s architecture is shown in Fig. 3. The model consists of an embedding layer, the LSTM layer, and a Dense layer, a neural network fully connected with sigmoid as the activation function. Besides, dropouts and batch normalization are added between layers in order to prevent overfitting. Long Short-Term Memory networks, often called LSTMs, are a type of RNN that can learn long-term dependencies. LSTM was introduced by Hochreiter & Schmidhuber and It is especially preferred in the field of text mining.
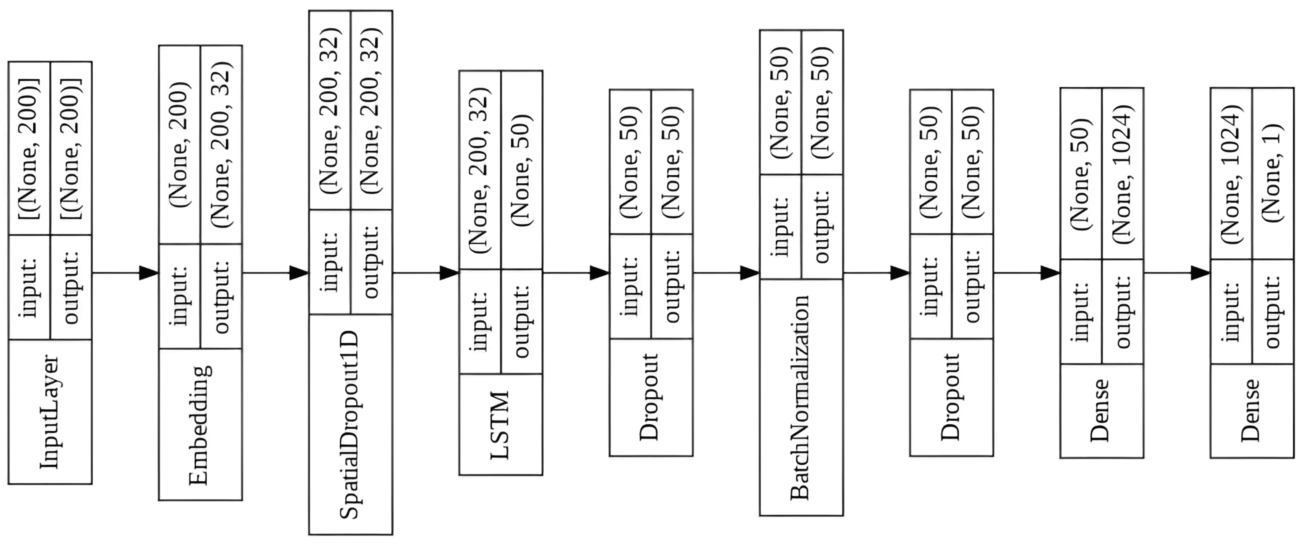
Model structure.
The sequential model was preferred because the output layer has one output tensor. We applied the tweets to Tokenizer() function. Tokenization means splitting the given sentence into an indexed or vectorized list of tokens. TensorFlow and Keras were used for modeling. In order to pass inputs of the same size, we used pad_sequences() function. We used LSTM (Long Short-Term Memory) for this model. It is a modified and sophisticated architecture of the RNNs. LSTMs can do high-range modeling dependencies with better accuracy than CNNs (Convolutional Neural Networks). Our architecture model has four main parts. We start with the embedding layer then we have the LSTM layer with 0.5 Dropout. Third, 0.2 Dropout, BatchNormalization(), and again 0.2 Dropout were added to avoid the overfitting problem. Finally, Dense (fully connected layers) were added for classification purposes and used a sigmoid activation function before the final output.
The model is trained for 5 epochs which attains a validation accuracy of 89%. For the LSTM model, a structure with 50 neurons was established and the dropout value was chosen as 0.5. Relu activation function was added between dropouts and batch normalization.
The obtained model was then applied to test data that we collected with Twint tool. This model was run for the Twitter data of 5 people from each profession group following the most on Twitter. The cyberbullying situation of these people will be shown in the next part, the evaluation.
Twitter cyberbullying rate for 6 professional groups
Twitter cyberbullying rate for 6 professional groups
twint was unable to extract enough data for this user.
The test dataset was created by collecting the responses given to the tweet post by each twitter user between December 2019 and December 2020. In this way, a total of 2.741.848 tweets were obtained from 30 twitter users. Table 3 shows the number of replies to each Twitter user’s share and the number of bullying twitter replies.
Statistical evaluation was calculated by percentage. As seen in equation (1), bullying tweets were divided into tweets and multiplied by 100. In this way, it was found that the percentage of each celebrity was exposed to cyberbullying. Statistical calculation was done for two purposes; First, who are the most cyberbullied celebrities? The second is which profession group of celebrities is exposed to more cyberbullying. According to Table 3, the 3 most exposed to cyberbullying are; Metin Uca (3.48%), Ahmet Davutoğlu (3.46%) and Hülya Avşar (3.40%). When we calculate it as a professional group, the first 3 are formed as follows; Writers (1.94%), Artists (1.83%), and Actors (1.80%). Celebrities who are least exposed to cyberbullying are as follows; Nuri Şahin (0.24%), Fahrettin Koca (0.34%) and Recep Tayyip Erdoğan (0.47%). Those who are least exposed to cyberbullying as a professional group; Singer (1.00%), Sports (1.67%), and Politicians (1.72%).
In particular, writers are the most cyberbullied, while singers the least. Government officials in Turkey while less exposed, opposition politicians are exposed to more cyberbullying. In Fig. 4, we see the percentage of cyberbullying that all celebrities are exposed to.

Bullying rate by celebrities.
Firstly, machine learning algorithms were tried in the study. Deep learning was chosen because similar machine learning studies were included in previous literature studies. In deep learning studies, CNN is generally used in image processing, while LSTM is used in text processing. That is why LSTM deep learning was chosen in this study.
As seen in Table 4, the AUC value was calculated as 0.95. This value was more effective than the values of 0.943 in [22], 0.817 in [23] and 0.815 in [19]. Besides, accuracy value was 0.89 and F1 Score was 0.87 after 5 Epochs. After the model was created, tweets of 30 celebrities belonging to 6 professional groups were used as inputs to the model. The results of celebrities with fewer records were checked by observation. Accordingly, it can be said that the results yield correct outputs. The most cyberbullied group was writers, while singers were the least. The names that are exposed to cyberbullying the most individually are MetinUca (3.48%), Ahmet Davutoğlu (3.46%), and Hülya Avşar (3.40%).
Accuracy, AUC, recall, precision and F1 score of proposed model
Accuracy, AUC, recall, precision and F1 score of proposed model
The present study provides cyberbullying detection against Turkish celebrities who have the most followers. To do this, we fetched 2.741.848 tweets replied to 30 celebrities by the Twint tool. This study is significant as this kind of cyberbullying detection had never been done before for the celebrities who have the most followers in Turkey. On the other hand, the compelling side of the study is that a large amount of data is collected from Twitter.
We used the ready dataset used for other machine learning studies in the stage of our training and test. The labeled dataset has 14.114 tweets. On the prepossessing side, we used the word2vec method in order to vectorize tweets. This method uses two combined methods, Skip Gram and Common Bag Of Words (CBOW).
LSTM, being the most used deep learning type in text classification studies was preferred. An extra dropout was added to forget some neurons, and then “Batch Normalization” was performed. Batch normalization was preferred because of its regulator. “Relu” was preferred as the activation function. We also tried “sigmoid” and “softmax” activation functions. For softmax, the accuracy values remained low, while the validation loss value did not go down to the desired level in the sigmoid function. Relu activation function results were observed more accurately than both. When the model was run, “binary cross-entropy” was selected as the loss function and “adam” was the optimizer.
As we tested the Twitter data of celebrities with the model, we also observed and evaluated the outcomes. There have been profanity and insulting expressions heard in Turkish. The greatest number of tweets containing cyberbullying are directed at politicians. The proportion of writers is the greatest. Statistically speaking, politicians engage in the most interaction on Twitter. They are not, however, the most vulnerable category of professionals to cyberbullying. Cyberbullying affects opposition politicians more than government officials. If we evaluate cyberbullying independently of professional groups, oppositions are, on average, more susceptible to it. There is between 3.48 and 0.24 percent cyberbullying of personalities. When examining the results, we do not identify any celebrities who are subjected to cyberbullying to a significant degree. In general, the values are relatively close.
Conclusion
As the popularity of social media platforms continues to rise, it has become clear that many false accounts are being used to spread upsetting cyberbullying content. We need cyberbullying content classification algorithms that work in the background to stop this from happening. There are a number of studies in the literature that address this problem and propose potential solutions, but not nearly enough of these studies examine Turkish social media messages. This is due to a lack of properly categorized social media statistics from Turkey. As can be seen in the part devoted to related work, the majority of cyberbullying research has been conducted in English. The research began by employing labeled pre-existing datasets for training the deep learning LSTM model. Different machine learning models, including Naive Bayes, AdaBoost, Random Forest, and Decision Tree, were tested on the labeled dataset. We found that the deep learning classifier had a better accuracy rate than the rest of the machine learning options. Using the obtained deep learning model on Twitter data collected with Twint, the researchers showed a number of statistical findings. Researchers found that writers were more likely to be targeted by cyberbullies than people in any other field. Still, we get that anybody can be a target of cyberbullying to some extent. Preventative research on artificial intelligence is required alongside cyberbullying monitoring efforts.
Footnotes
Acknowledgement
The Turkish Celebrities Cyberbullying DataSet can be found at GitHub via the following link