
Abstract
One of the leading causes of death for people worldwide is liver cancer. Manually identifying the cancer tissue in the current situation is a challenging and time-consuming task. Assessing the tumor load, planning therapies, making predictions, and tracking the clinical response can all be done using the segmentation of liver lesions in Computed Tomography (CT) scans. In this paper we propose a new technique for liver cancer classification with CT image. This method consists of four stages like pre-processing, segmentation, feature extraction and classification. In the initial stage the input image will be pre processed for the quality enhancement. This preprocessed output will be subjected to the segmentation phase; here improved deep fuzzy clustering technique will be applied for image segmentation. Subsequently, the segmented image will be the input of the feature extraction phase, where the extracted features are named as Improved Gabor Transitional Pattern, Grey-Level Co-occurrence Matrix (GLCM), Statistical features and Convolutional Neural Network (CNN) based feature. Finally the extracted features are subjected to the classification stage, here the two types of classifiers used for classification that is Bi-GRU and Deep Maxout. In this phase we will apply the Crossover mutated COOT optimization (CMCO) for tuning the weights, So that we will improve the quality of the image. This proposed technique, present the best accuracy of disease identification. The CMCO gained the accuracy of 95.58%, which is preferable than AO = 92.16%, COA = 89.38%, TSA = 88.05%, AOA = 92.05% and COOT = 91.95%, respectively.
Keywords
Introduction
The latest statistics from the World Health Organization (WHO) show that liver cancer was the third most common cause of cancer mortality globally, posing a severe threat to the general public’s health [6,27]. Hepato cellular carcinoma (HCC), Intrahepatic cholangiocarcinoma (ICCA), fused Hepatocellular cholangiocarcinoma (HCCCCA), Fibrolamellar HCC (FLC), and the pediatric neoplasm hepato blastoma are just a few of the malignant tumors with a variety of histological characteristics and a poor prognosis that make up liver cancer [7,16]. In order to save people’s lives, early liver cancer identification and rehabilitation may benefit from the accessibility and availability of affordable diagnostic and treatment services [11,29].
The majority of the research for cancer detection using sensors has been concentrated on the identification of cancer biomarkers, which would necessitate sample processing to some extent. Direct serological detection, in contrast to this method of detection, has benefits including simplicity, speed of completion, and affordability. Unfortunately, there are still numerous technological obstacles to overcome before direct serological diagnosis of cancer can be effectively implemented using nanomaterials-enabled sensors [17]. Gene therapy is one novel treatment that has gained popularity and made significant advancements in HCC diagnosis, therapy, and prognosis with the growth of cellular and molecular biology. Smaller, single-stranded Ribonucleic acid (RNA) molecules known as MicroRNAs (miRNAs) were a novel class that is crucial regulators of cell biology [22].
They developed an intelligent bio sensing technique and constructed a nano sensing array as a Surface-enhanced Raman spectroscopy (SERS)-based sensor for the direct serological detection of liver disorders [14]. The liver was segmented and liver metastases were found using FCNN architecture for CT scans. Hybridized Fully Convolutional Neural Network (HFCNN) had also produced accurate results from arbitrary inputs with correspondingly effective inference and learning [21]. With the introduction of Computer Assisted Diagnosis (CAD), which replaced manual cancer detection’s drawbacks, it was possible to detect cancer automatically [2,8]. The majority of Machine Learning (ML) algorithms are now outperformed by Deep Learning (DL) approaches in medical applications, especially when working with large datasets [13]. These days, image processing is one of the most well-known areas of computing. It can be utilised in a variety of settings, including safety systems to evaluate people’s biometrics and the industry to control production [17]. Medical image analysis with computer assistance is very helpful in many areas of medicine, including diagnosis, monitoring, and therapy planning. The quantity of medical images that will be processed in clinical practice is growing as a result of society’s aging population and the widespread use of current imaging technology. Software solutions that accelerate the analysis of the medical image and make it useful and reproducible are greatly needed. The medical image is a significant component of the field, where image processing methods and artificial intelligence are used to crack problems.
The contribution of this paper as follows
The improved deep fuzzy clustering for image segmentation to improve the efficiency of liver disease classification.
In feature extraction phase, the improved Gabor Transitional Patter for extracting the features.
We combining the two classifiers that is Bi-GRU and Deep Maxout in the classification stage and introduce the Crossover mutated COOT optimization algorithm (CMCO) for tuning the weight in classification
This paper is organized as follows, literature review is described in Section 2, proposed architecture is shown in Section 3, Crossover Mutated COOT Optimization is explained in Section 4, the result and discussion is shown in Section 4, the conclusion is described in Section 5.
Literature review
In 2020, P.Gunasekhar and S. Vijayalakshmi [14] have presented DL method and optimization algorithms for identifying the best biomarker for skin cancer detection. Gain Ratio (GR), Chi-Square (Chi2), Symmetrical Uncertainty (SU), RF-W, RelieF (RF), and Information Gain (IG) are six different filtering methods that are taken into consideration while choosing features. The MSSO algorithm takes these chosen features and extracts two highly ranking features. The liver cancer tissues were successfully identified by the Sunflower Optimization-based deep neural network (DSFNN) technique thanks to the highly ranked characteristic. The analysis section comes to the conclusion that miRNA biomarkers with higher ranks are more effective at detecting cancer than those with lower rankings. The performance results obtained by the proposed DSFNN were compared with those of five other algorithms.
In 2020, Xin Dong et al. [12] proposed using the mathematically modeled Hybridized Fully Convolutional Neural Network (HFCNN) for liver tumor segmentation to address the current liver cancer problem. HFCNN has proven a efficient method for liver cancer identification. The difference between cancerous and non-cancerous lesions is essential, as the diagnostic and therapeutic approach were defined by the CT-based lesion-type definition. Experience, knowledge, and resources of the highest caliber are required. In order to distinguish between benign cysts and liver metastases from colorectal cancer in abdominal CT images of the liver, a DL approach was examined. The DL system illustrates the notion of lighting sections of a pre-trained DNN’s decision-making process.
In 2020, Hongyu Zhao et al. [31]. suggested an unique assay that uses DNA tetrahedron nanotags and FRET to simultaneously detect miRNA-21, miRNA-122, and miRNA-223 by switching from the nucleic acid stain TOTO-1 to three different organic dyes using a single laser stimulation wavelength (Cy3, Cy3.5, Cy5). To put it briefly, the vertices of DTN were designed with three adaptor oligos. The natural nucleic acid core of DTN can accept TOTO-1, a fluorescent donor. FRET oligos were fluorescent receptors made out of three organic dye-functionalized strands. When they combine with adaptor and FRET oligos on the vertices of DTN in the presence of target miRNAs, stable DNA tetrahedron nanotags are created. Due to TOTO-1’s confinement near three fluorescent dyes, DNA tetrahedron nanotags were successfully able to create FRET between TOTO-1 and the fluorescent dyes. Table 1 shows the Review on conventional methods.
Review on conventional methods
Review on conventional methods
In 2021, Ningtao Cheng et al. [9] have introduced a sensor that uses SERS and is based on ZnO nanopillars coated with an Au–Ag nanocomplex. The sensor’s analytical improvement factor of 1.02 107 allowed it to directly analyze serum SERS data in order to detect the biomolecular information of liver disorders. DL built a CNN classifier that can identify serum SERS spectra. They created an intelligent biosensing approach by integrating this sensor with CNN and achieved direct serological detection of liver disorders within 1 minute. The findings indicate that this technique can be improved for clinical liver disease detection and that it is a promising approach for monitoring liver cancer.
In 2021, Ningtao Cheng et al. [10] have used NBC and DNN modeling for quickly diagnosing liver cancer. If used with POCT, this chip might be able to sufficiently improve Raman signals. Spectrum-based DL was used to create a classification DNN model, which had an accuracy of 91% on a validation set of 100 external spectra. The model used 1140 serum SERS spectra, distributed evenly between HCC patients and healthy people. The biosensing chip and DNN-based intelligent platform have the potential for medical applications as well as generalizable utility in swiftly screening or detecting different cancer kinds.
In 2021, Amandeep Kaur et al. [18] established a multi-organ classification of 3D CT pictures of probable liver cancer patients by CNN. A CNN was used to classify CT liver cancer pictures. The radiation therapist will benefit most from the researcher’s primary contribution, which will enable them to concentrate on a select portion of the CT image data. This was accomplished by dividing the entire collection of 63503 CT pictures into three groups depending on the possibility that patients with liver cancer may have their cancer spread to other organs. Therefore, only 19453 of 44050 CT scans contained visible liver. With the help of the suggested procedure, patients with liver cancer were quickly diagnosed and treated.
In 2021, Santanu Roy et al. [26] suggested an unique unsupervised edge detection method for liver cancer prediction. The idea of estimating local SD was included in this unique edge detection technique in place of computing gradients. This unique method could effectively recover the nuclei edges, even at multi scale, because the local SD value was connected with the edge information of the image. The final segmented image was then refined using an adaptive morphological filter. The visual outcomes of the two datasets show that the suggested segmentation method circumvents the drawbacks of existing ML techniques. The proposed segmentation approach did, in fact, perform better than other nucleus segmentation techniques, as shown by the mean value of quality measures.
In 2022, Esam Othman et al. [24] suggested DL model employing CNNs for diagnosis of liver cancers from CT images. As a result, scientists were able to detect liver tumours in CT images using a hybrid model they had developed. It was noteworthy that this model performed well when evaluated on a small sample of data and produced accurate detection findings. Experts in this industry can use this model as a tool to support their decisions and reduce their work. Additionally, it saves the specialist’s time and effort in treating this particular type of cancer, particularly during annual periodic checkup campaigns.
In 2022, Rela et al. [25] have deployed the tumors are classified as LA or HCC using a variety of machine learning methods, including support vector machines (SVM), K-Nearest Neighbor (KNN), decision trees (DT), ensemble, and naïve Bayes (NB). Preprocessing, liver segmentation, feature extraction, and classification are the procedures needed for classification. To train the model, 68 CT scans from various hospitals in Tirupati are gathered. The models are then evaluated using metrics like accuracy, specificity, sensitivity, Matthew correlation coefficient (MCC), and F1-score, among others. It has been seen from the performance analysis of various classifiers that SVM classifier accuracy has increased by 10%.
In 2022, Alawneh et al. [4] have presents a computer-aided diagnosis system that classifies hepatic tumors as benign or malignant based on computed tomography imaging. To identify and categorize existing tumors as benign or malignant, a Convolutional Neural Network (CNN) is applied to the 3D segmented liver from the LiTS17 dataset. In order to classify the segmented liver, we suggest a novel light CNN with eight layers and just one conventional layer in this study. Two separate tracks use this proposed model; the first track uses deep learning classification and achieves 95.6% accuracy.
Medical personnel face hurdles while trying to diagnose, treat, predict outcomes for, and grade liver cancer from radiographs despite the significance of the classification of the disease. A highly textured border may be seen in an epithelial nucleus of a more advanced malignancy. The nucleus’ heavily textured or atypically formed border may exhibit major malignant tumor characteristics that are challenging to spot. Furthermore, it has been noted in some of the histopathology photos of the liver cancer dataset that RBC share similarities in size and form with epithelial nuclei, making it difficult to identify individual nuclei in these images. A number of application annoyances, such as the need for sample preprocessing, complex operational processes, and relatively high prices, would also be present for the liver cancer screening.
Proposed architecture
This paper proposed a novel technique for liver disease classification from CT image. The motive of this method is to improve the accuracy level for identifying the disease through CT image. It is implemented via four stages that is: pre processing, segmentation, feature extraction and classification. Figure 1 shows the proposed architecture of liver disease classification. The detailed description of the mentioned stages is explained in the following sections.

The proposed architecture of liver disease classification.
In preprocessing, we considering an input image as
CLAHE
It is suggested to reduce the amounts of over-amplified noise introduced by AHE using CLAHE. The slope of the transformation function corresponds to the degree of contrast amplification, which is identified by the transformation slop. Through the transformation function’s slope being clipped at a predetermined clip limit, CLAHE restricts these contrasts. After that, the histograms’ clipped portions are spread again. As a result, clipping and redistribution tend to improve and make images look more realistic while minimizing the amplitude of noise created by adaptive HE [28].
In this model, the histogram’s slope is cut at a pre-set threshold, which serves as a physical limiter on the amplitude of the noise. As a result, CLAHE works to reduce larger contrasts, which leads to a smoother histogram of the image. The contrast of the image is further improved by applying a clip-limit to each tile region, which reduces noise amplitude.
HE equalizes images by adding contrasts to all sections of the image, unlike AHE. To do this, the histogram’s high-intensity regions’ contrast is increased, and the low-intensity histogram regions’ contrast is compressed. By limiting the enhancement rate, the CLAHE algorithm seeks to solve the problem. When using global equalization and a small region of interest in a picture, these areas don’t typically show distinct boundaries with adjacent areas. By limiting the enhancement rate, the CLAHE algorithm attempts to solve the problem. The enhancement through HE technique is dependent on
Consequently, limiting the value of p(x) will limit the rate of augmentation. When the histogram’s slope is clipped, the number of bins is either increased or decreased based on the clip variable. With the aid of the clip limit parameter
The preprocessed output image is denoted as
Segmentation
The preprocessed output
Improved deep fuzzy clustering
Improved Deep Fuzzy clustering techniques have a major challenge in the measuring of pixel relatedness. The efficiency of picture segmentation will be increased in this study by just taking the closest-related pixels into account. It is a problem that edge information is not taken into account when calculating the distance between matching patches [30]. To be more precise, the neighbors of a pixel can each have a unique impact on the pixel in the centre. We provide a unique relatedness model, described in Algorithm 1, to address this issue. This model adds weighting for various directions to more accurately determine pixel relatedness.
In image segmentation process, we determine the pixel relatedness, only considering most closely related pixels to improve the efficiency without degrading the performance. If we consider all the pixels in the search window, definitely it will affect the efficiency, speed, and accuracy.
In Image segmentation process
The objective function of image segmentation process is conventionally computed by Euclidean distance. In this proposed work, the Euclidean distance is changed into improved cosine distance. Conventional cosine formula is represented in Eq. (8)
Improved cosine distance In improved cosine distance, first we calculated the distance value D, in Eq. (9). This distance value D is compared with the default threshold value 0.5. The improved cosine distance is formulated in Eq. (10).

Pseudo code of improved cosine distance
The segmented output
Improved Gabor transitional pattern
The segmented image was subjected to a Gabor filter, and features were extracted using LTP code that was generated from the filtered image. Eight distinct orientations of the image were given the Gabor filter, which was then applied, and the resulting filtered images were then superimposed to create one final image [3].
LTP creates a texture code by comparing the intensity transition between adjacent pixels moving in different directions at different levels. Given image
Gray level co-occurrence matrices (GLCM)
A well-known statistical technique for extracting second-order texture information from a picture is the GLCM. It is shown as a matrix, with the number of columns and rows corresponding to the number of distinct grey levels or pixel values in a picture of a surface [15]. It describes how often a certain grey level will appear in a specific spatial linear relationship with a different grey level inside the study area. In this proposed work, we extract some features like energy, contrast, correlation, homogeneity and dissimilarity. These features are explained as follows.
Energy The score increases as the image becomes more homogeneous. The image is meant to remain constant when the energy is equal to one. It is calculated in Eq. (12) where,
Contrast The term “contrast” is used to describe how an image’s input image’s intensity of a pixel and its neighbor is calculated. It is expressed in Eq. (16)
Correlation The correlation texture determines how linearly or spatially related adjacent pixels’ grey levels are to one another. The correlation is evaluated in Eq. (17), Where
Homogeneity An image’s local homogeneity is measured by homogeneity. It is high when both the local grey level and its inverse, GLCM, are uniform. Whether the supplied image is textured or not will determine whether it has a single value or a range of values. It is evaluated in Eq. (18).
Dissimilarity It is a textural aspect of a picture that is calculated by taking the image’s arrangement into account as expressed in terms of an angle. It is calculated in Eq. (19)
Statistical features
In feature extraction phase, we are considering some statistical features namely, mean, median, standard deviation, skewness and kurtosis.
Mean (
Median (
Standard deviation (
Skewness (
Kurtosis (
CNN based features
CNNs, a subset of deep feed-forward ANN, are frequently employed in computer vision tasks including image categorization [19]. CNN has input, convolutional, pooling, fully connected, and output layers, which sets it apart from a “simple” multilayer perception (MLP) network. Figure 2 shows the architecture of CNN model for Features Extraction.
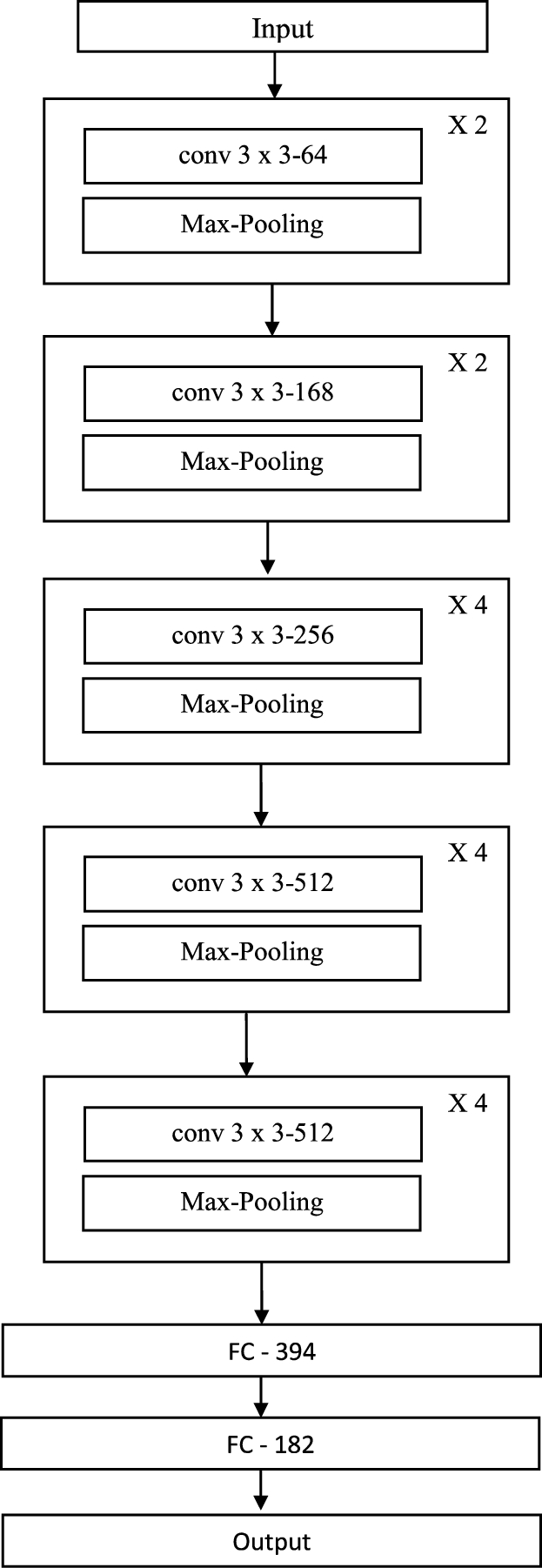
Architecture of CNN model for features extraction.
The CNN is fed an input image via the input layer. To prepare the input image as an acceptable data type for the CNN, it consists of a variety of low-level image processing operations. In order to ensure that a CNN can be computed efficiently, the size of the input image should ideally be a power of 2. But the most recent CNNs can also employ input images with irregular row-column dimensions.The output layer presents the extracted features from the input image.
In this classification stage, we combine two classifiers that is Bi-GRU and Deepmaxout network. Here the weight of both two classifiers can be tuned by using self improved COOT algorithm.
Bi-GRU
The processing of sequential data is a capability of RNNs. In addition, when dealing with new data, RNNs are able to draw some knowledge from earlier image [20]. Improved RNN models like the LSTM and GRU have strong modeling skills for long-term dependencies, while GRU is a less sophisticated variation than LSTM. A GRU is the combination of reset gate
Models having a bi-directional structure are able to use knowledge from the prior and the future while interpreting the data at hand. The first GRU starts moving forward at the beginning of the data series, while the second GRU starts moving backward at the end of the data series. Due to this, information from the past and the future might have an impact on the circumstances of the present. The bi-GRU is defined in the following Eq. (28), where
Deep maxout
In deep maxout neural network, every neuron has a group, which including of K candidate pieces [5]. Depending on the highest value, the neuron activation value is calculated, which is obtained from all k pieces. The link between the
Only the weights related to the component with the maximum activation within every group
Crossover mutated COOT optimization (CMCO)
In classification phase, the self improved COOT optimization algorithm is used to tune the weight of both two classifiers that is Bi-GRU and Deep Maxout.
The Coots are little waterfowl that belong to the Rallidae family of rails [23]. The underside of the tail is often white, but not always. Coots reveal a range of actions and behaviors when they are on the water. Using the movement of this coot on the water’s surface, a novel optimization technique is demonstrated in this research. Surf scoters sense a region of repulsion when coots move at angle to their movement direction. This suggests that coots approach quite close to this zone. When coots swarm on water, they move in three different ways. Each coot follows its front coot as a chain of coots glides across the water. Humans see the coots in the front of the flock as the group’s leaders since they are in charge of guiding the entire flock in the right direction. The four unique motions that birds make on the water’s surface are now taken into consideration. The movements are
Random swaying to one side or the other
Chain Movement
depending on the group leaders, changing the position
the group’s leaders directing them to the ideal location
Mathematical model The method starts from a random population. This random population is evaluated iteratively by the target function to provide the desired result. A collection of principles that form the basis of an optimization process also improves it. There is no assurance that a result will be discovered in a single run because population-based optimization techniques hunt for the right number of optimization issues. On the other hand, with enough random values and optimization steps, the chance of achieving the overall optimum increases. In Eq. (31), the population is generated by randomly in the space. Where, the coot’s position is denoted as
Using the objective function, it is necessary to assess each solution’s efficiency after the initial population is generated and each agent is placed. Group leaders are chosen from the
Proposed random swaying to one side or the other
We use Eq. (34) to select a random location within the search area and move the coot there to complete this movement.
This movement of the coot covers a wide portion of the search space. The algorithm can use this motion to escape the localized optimal if it ever catches itself there. Using Eq. (35), coot’s new location is calculated. Where
Chain movement
This movement can be created using the average position of two coots. Another method for establishing a chain movement is to calculate the distance of two coots and then it moves to the other distance that is half of that distance. We used the first method, and a equation (37) was calculate the coot’s new position. Where
Proposed method depending on the group leaders, changing the position
After shifting their postures to align with the group leaders, who are typically a few coots ahead of the group, the majority of the coots must advance towards the leaders. One conceivable question is if each coot’s position will change based on which leader is in control. The coots might adjust their position in light of the overall average of the leaders, which can be taken into consideration. Convergence happens too soon when using the average position. Using Eq. (38) implement this movement. Where coot’s index number is denoted as i, number of leaders denoted as
The group’s leaders directing them to the ideal location
To direct the group in the right direction, leaders must adjust their own position in respect to the objective. Using For Eq. (42) and Eq. (43), it is suggested that leadership roles be updated. This equation seeks out better locations in the immediate area of the present optimal point. By using this approach, you can move both in the direction of and far from the optimal location. Where, the best position is denoted as
To retain the randomness of the selection procedure, we treat each of these movements as if it were a random occurrence. During the course of the algorithm, the coot may begin to migrate in a chain or in the direction of group leaders.
In the end, the solution is discovered by applying arithmetic cross over. To integrate the two parent chromosomes linearly, a crossover operator in arithmetic is used. The crossover operator in arithmetic is a linear combination of the two parent chromosomes. An arithmetic crossover involves the selection of two chromosomes at random for crossover, which are subsequently united in a linear manner to produce two offspring. It is represented in Eq. (45). Where

Pseudo code of CMCO
Figure 3 shows the flowchart of the proposed model.
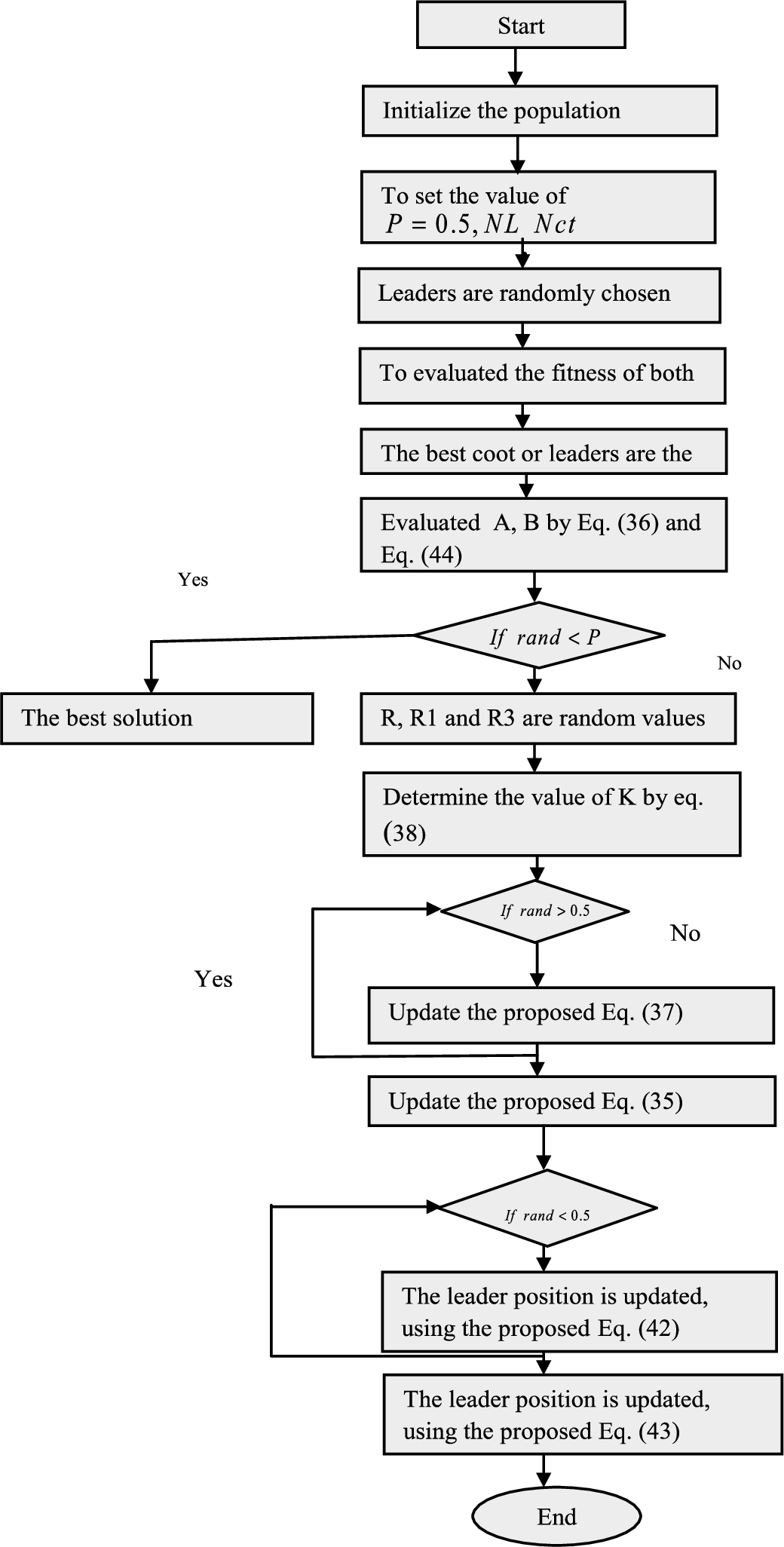
Flowchart of the proposed model.
Further, the investigation was carried out regarding positive measure, negative measure and other measures as well as the results related to the corresponding simulation were observed.
Simulation procedure
The proposed based Liver cancer classification model was executed in PYTHON and the dataset was gathered in [1]. The CMCO was estimated over the Aquila Optimizer (AO), Chimp Optimization Algorithm (COA), Tunicate Swarm Algorithm (TSA), Archimedes Optimization Algorithm (AOA) and COOT. The Liver Cancer classification images are displayed in Fig. 4.

Images for liver cancer classification a) input image b) preprocessed image c) conventional segmented image d) K-means segmented Image e) watershed segmented image f) CMCO segmented image.
“The DeepLesion dataset contains 32,120 axial computed tomography (CT) slices from 10,594 CT scans (studies) of 4,427 unique patients. There are 1–3 lesions in each image with accompanying bounding boxes and size measurements, adding up to 32,735 lesions altogether. The lesion annotations were mined from NIH’s picture archiving and communication system (PACS).”
Analysis on positive measure of CMCO over the standard methods by adjusting the learning percentage
The study on CMCO is computed over the extant schemes like AO, COA, TSA, AOA and COOT for diverse learning percentages are represented in Fig. 5. For enhanced system performance, the positive metric needs to be high. While assessing the Fig. 5, the CMCO and other established schemes have obtained maximal positive measure ratings i.e. greater than 80%. However, the CMCO accomplished the greater positive metric values than the current strategies. The CMCO obtained the greatest specificity at the 80th learning percentage is about 92.97%, this is superior to AO = 89.09%, COA = 86.11%, TSA = 84.43%, AOA = 88.59% and COOT = 88.73%, respectively. Regarding the Fig. 5(b), with the learning percentage of 90%, the models like AO, COA, TSA, AOA and COOT attained the minimal precision of 92.81%, 90.05%, 88.76%, 92.74% and 92.67%, whilst the CMCO reached the highest level of precision is 96.20%.
Furthermore, evaluating the sensitivity and accuracy measure of the CMCO and the traditional methodologies as well as the corresponding results are shown in Fig. 5(c) and 5(d). In the 70% of learning percentage, the CMCO generated the sensitivity of 95.17%, even though the standard schemes scored minimum sensitivity, including, AO is 92.05%, COA is 89.11%, TSA is 87.50%, AOA is 92.24% and COOT is 91.75%, respectively. Particularly, the CMCO obtained the sensitivity of 90.83% in the 60th learning percentage, although it attained the maximal sensitivity at the 90th learning percentage is 96.50%. For the learning percentage 90, the CMCO gained the accuracy of 95.58%, which is preferable than AO = 92.16%, COA = 89.38%, TSA = 88.05%, AOA = 92.05% and COOT = 91.95%, respectively. As we have accomplished improvements in segmentation with enhanced feature extraction, the resultants of the CMCO is more appealing than those of the others strategies.
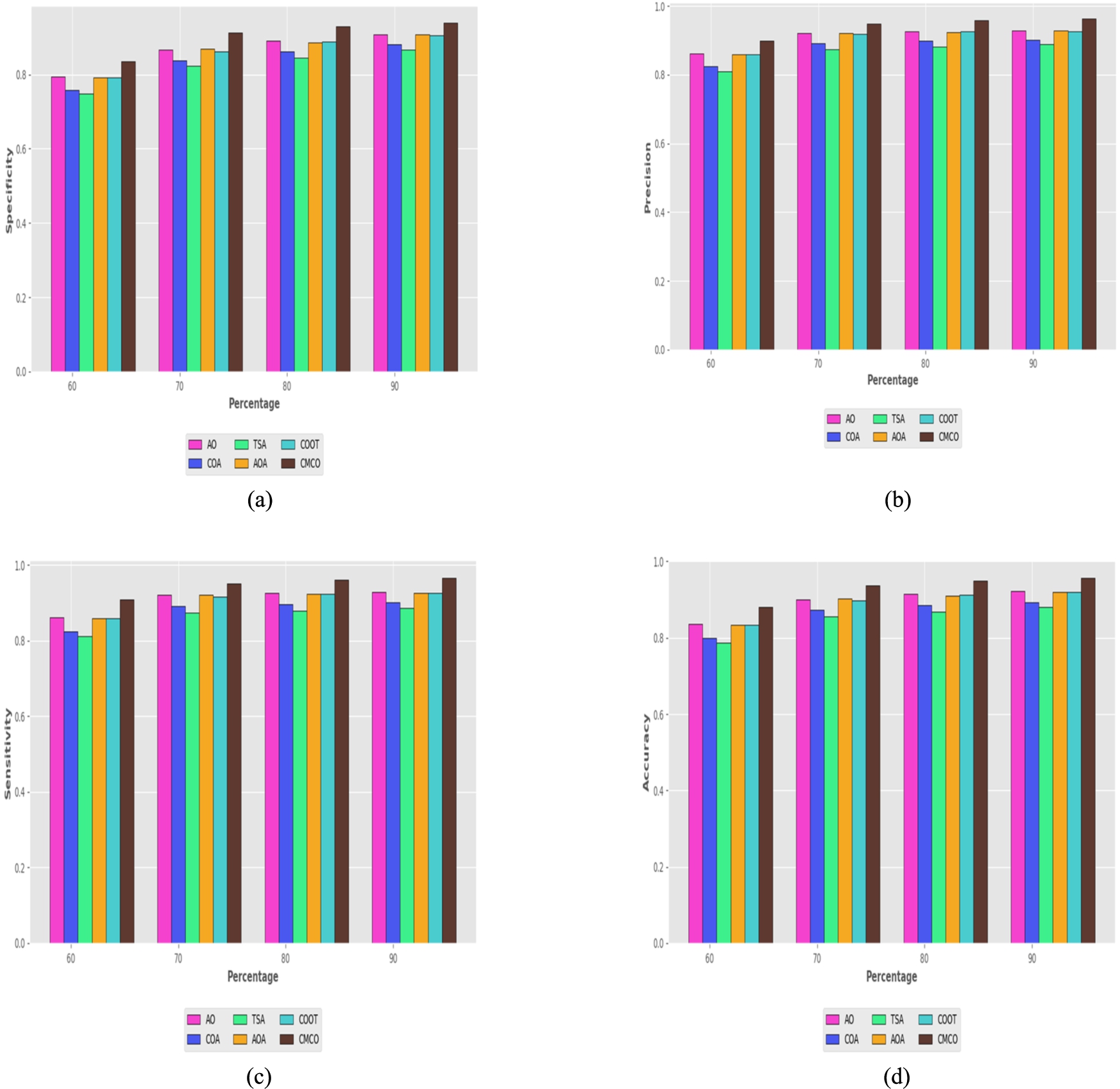
Assessment on positive measure of the CMCO versus traditional methods a) specificity b) precision c) sensitivity d) accuracy by varying the learning percentage.
The negative measure (FNR and FPR) analysis of the CMCO is conflicts with the AO, COA, TSA, AOA and COOT is exposed in Fig. 6. Here, the negative measures should be lower for better liver cancer classification system. Likewise, the CMCO attained the minimal FNR and FPR in almost all the learning percentages; thereby it is preferable approach for liver cancer classification. As stated by the Fig. 6(a), the FNR of the CMCO for the 80th learning percentage is 3.94191, whilst the traditional approaches attained the lowest FNR error rate, such as, AO = 7.249945, COA = 10.2411, TSA = 11.9651, AOA = 7.587618 and COOT = 7.495715, respectively. The minimal FPR is acquired by the CMCO ranging from 16.5334 to 6.18034. Particularly, at the 80% of learning percentage, the CMCO yielded the FPR of 7.029402, even though the AO = 10.9082, COA = 3.88575, TSA = 15.56878, AOA = 11.40086 and COOT = 11.26711, respectively. Nearly in all error measurements, the CMCO model shows its superior performance. This exhibits that the CMCO might be more specific with its contributions on resolving the specified classification problem more effectively.

Assessment on positive measure of the CMCO versus traditional methods a) FNR b) FPR by varying the learning percentage.
The other measure evaluation of the CMCO is compared to the AO, COA, TSA, AOA and COOT by adjusting the learning percentage and the findings are presented in Fig. 7. Here, the CMCO has generated better values than the other five previous algorithms. While fixing the learning percentage to 60%, the CMCO acquired the F-measure of 90.39%, even thought the AO is 86.13%, COA is 82.43%, TSA is 81.08%, AOA is 85.89% and COOT is 85.87%, respectively. Similarly, the NPV of the CMCO is 90.88% (Learning percentage = 90%), surpassing the AO = 90.88%, COA = 88.07%, TSA = 86.67%, AOA = 90.70% and COOT = 90.53%, respectively. Simultaneously, the CMCO attained the highest MCC of 91.65% at the 90% of learning percentage, whilst it attained 76.41%, 87.99% and 90.43% of precision at the 60, 70 and 80% of learning percentage. Nevertheless, the CMCO obtained the greatest MCC in all the learning percentages. This has clearly proven that the CMCO is efficacious in classifying liver cancer with improved segmentation as it has gotten the greatest other metrics compared to the other established approaches.
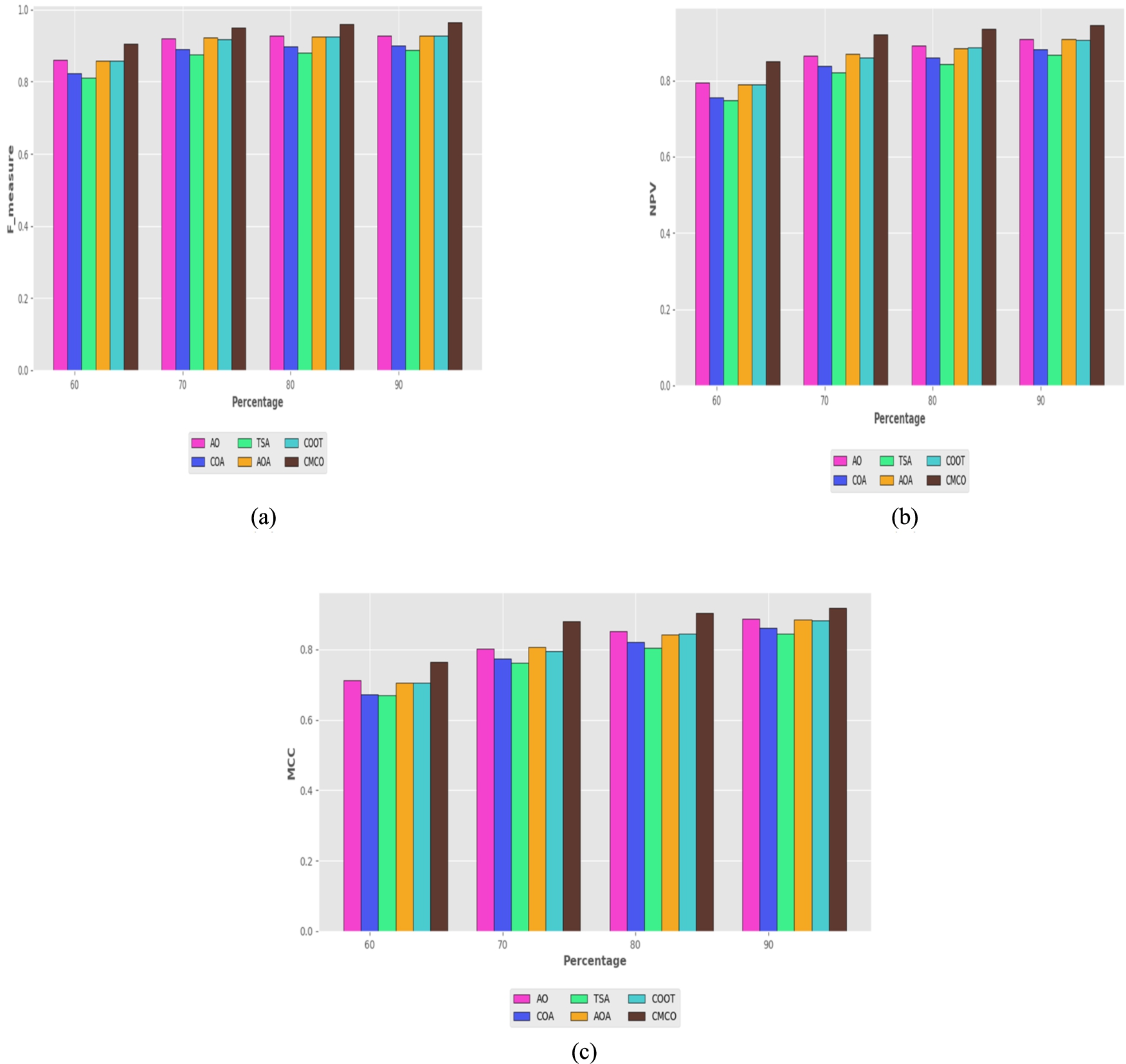
Assessment on positive measure of the CMCO versus traditional methods a) F-measure b) NPV c) MCC by varying the learning percentage.
The ablation study on CMCO, model with conventional segmentation, model with conventional LGTrP and model without optimization for distinctive measures are overviewed in Table 2. The accuracy of the model with conventional segmentation is 87.11%, model with conventional LGTrP is 86.25%, model without optimization is 81.70% and CMCO is 93.81%, respectively. Furthermore, the model with conventional segmentation, model with conventional LGTrP, model without optimization and CMCO recorded the FPR of 0.176463, 0.186841, 0.239737 and 0.087277, respectively. To improve the efficiency of the liver disease classification deep fuzzy clustering is used. For extracting the features, improved Gabor Transitional Pattern is used and the optimization is carried out to tune the weight of the classifiers. Further, it can be ascertained that the CMCO with the entire presented enhancement can contribute to incredible outcomes.
Ablation study on CMCO, model with conventional segmentation, model with conventional LGTrP and model without optimization for varied positive, negative and other measure
Ablation study on CMCO, model with conventional segmentation, model with conventional LGTrP and model without optimization for varied positive, negative and other measure
The performance of CMCO for Liver cancer classification is compared over KNN, CNN, RNN, Bi-GRU, Deep Maxout, HFCNN [12] and NBC-DNN [10] for various types of metrics is depicted in Table 3. In order for the system to perform effectively, both the positive and other metrics should be maximized, as well as the negative measure must be minimized. Especially, the precision of the CMCO is 94.74%, whilst the KNN = 86.09%, CNN = 85.47%, RNN = 84.28%, Bi-GRU = 85.57%, Deep Maxout = 86.47%, HFCNN = 79.52% and NBC-DNN = 75.63%, respectively. Moreover, the FNR of the CMCO is 0.048281, mean while the standard approaches like KNN, CNN, RNN, Bi-GRU, Deep Maxout, HFCNN and NBC-DNN obtained the FNR of 0.149833, 0.1546402, 0.159708, 0.155306, 0.085832, 0.127165 and 0.149468, respectively. Subsequently, the Accuracy, NPV and FPR acquired by the CMCO is 93.81%, 92.05% and 0.087277. This confirms that the CMCO provided improved accuracy with reduced error rate.
Classifier comparison on CMCO versus established classifiers for positive, negative and other measures
Classifier comparison on CMCO versus established classifiers for positive, negative and other measures
The statistical evaluation of the CMCO is associated to the AO, COA, TSA, AOA and COOT under the mean, standard deviation, maximum, median and minimum case scenario is represented in Table 4. Regarding the statistical evaluation, the CMCO obtained the lowest error value for liver cancer classification system than the conventional schemes. In accordance with the minimum case scenario, the CMCO generated the error rate of 1.075606, even though the traditional methodologies acquired maximal error rate, namely, AO is 1.091018, COA is 1.099898, TSA is 1.086785, AOA is 1.082553 and COOT is 1.080126, respectively. Additionally, the CMCO recorded the minimal error rate under the mean case scenario is 1.085719, though the AO is 1.103969, COA is 1.143674, TSA is 1.097733, AOA is 1.098426 and COOT is 1.090266, respectively. Finally, it establishes that the CMCO has the adequacy to diminish the error even in the complicated scenarios.
Statistical assessment on CMCO over the conventional schemes for mean, standard deviation, maximum, median and minimum case scenario
Statistical assessment on CMCO over the conventional schemes for mean, standard deviation, maximum, median and minimum case scenario
The convergence evaluation of the CMCO is assessed over the AO, COA, TSA, AOA and COOT is portrayed in Fig. 8. Here, the iteration ranges from 0 to 50. For an improved liver cancer categorization system, the error rate should be as low as possible. The CMCO and other classifiers acquired the highest error rate from the iteration 0 to 30, however as the number of iterations progressed, the error rate for all the classifiers dropped. Whatever, the error rate of the CMCO is 1.076, mean while the conventional approaches has obtained the highest error value, notably, AO = 1.098, COA = 1.087, TSA = 1.084, AOA = 1.082 and COOT = 1.080, respectively. The CMCO has asserted its advancement with better convergence rate and quickness to reach the error specified in the classification process.
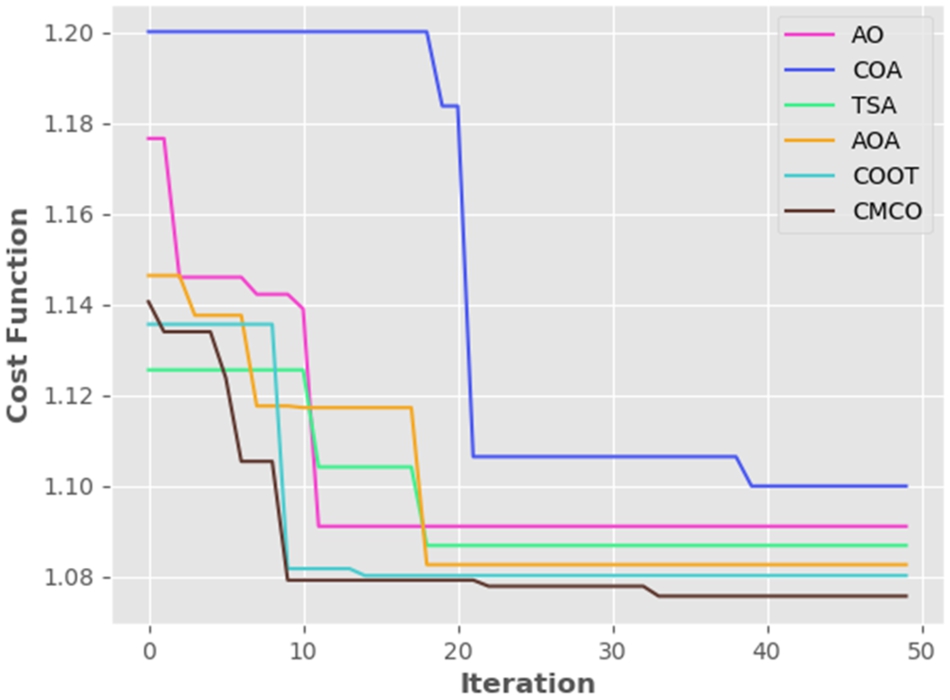
Convergence evaluation on CMCO versus traditional methodologies by modifying the iterations.
The receiver operating characteristic curve (ROC curve) is a graph that displays how well a classification model performs across all categorization levels. The abbreviation “Area under the ROC Curve” is AUC. In other words, AUC calculates the area in two dimensions underneath the complete ROC curve. Instead of assessing predictions’ absolute values, it assesses how well they are rated. Figure 9 deploys the ROC and AUC analysis.

ROC and AUC analysis.
Nomenclature
Liver cancer predication is one of the most challenging tasks of the doctors. Liver cancer is mostly identified by the using of X-ray images or CT images. This paper proposed the technique for liver disease classification using CT images. It consists of four stages like preprocessing, segmentation, feature extraction and classification. In preprocessing stage, the input image was preprocessed and the quality of the image was improved. The preprocessed output was the input of the segmentation phase, here improved Deep fuzzy clustering method was used for image segmentation. The segmented output was subjected to the input of the feature extraction phase, where the extracted features are improved Gabor transitional pattern, GLCM, statistical features and CNN based features. This extracted feature was subjected to the input of the classification stage. In classification state we applied a crossover muted COOT optimization (CMCO) for tuning the weights. Finally the output image was presented the best accuracy of disease classification. Doctors can more easily create treatment plans by successfully classifying the various levels of differentiation, allowing patients to receive care on time. It can simultaneously reduce medical staff workload and the amount of time needed to look through liver cancer histopathological images.