
Abstract
Nowadays, huge number of mammograms has been generated in hospitals for the diagnosis of breast cancer. Content-based image retrieval (CBIR) can contribute more reliable diagnosis by classifying the query mammograms and retrieving similar mammograms already annotated by diagnostic descriptions and treatment results. Since labels, artifacts, and pectoral muscles present in mammograms can bias the retrieval procedures, automated detection and exclusion of these image noise patterns and/or non-breast regions is an essential pre-processing step. In this study, an efficient and automated CBIR system of mammograms was developed and tested. First, the pre-processing steps including automatic labelling-artifact suppression, automatic pectoral muscle removal, and image enhancement using the adaptive median filter were applied. Next, pre-processed images were segmented using the co-occurrence thresholds based seeded region growing algorithm. Furthermore, a set of image features including shape, histogram based statistical, Gabor, wavelet, and Gray Level Co-occurrence Matrix (GLCM) features, was computed from the segmented region. In order to select the optimal features, a minimum redundancy maximum relevance (mRMR) feature selection method was then applied. Finally, similar images were retrieved using Euclidean distance similarity measure. The comparative experiments conducted with reference to benchmark mammographic images analysis society (MIAS) database confirmed the effectiveness of the proposed work concerning average precision of 72% and 61.30% for normal & abnormal classes of mammograms, respectively.
Keywords
Introduction
Breast cancer remains the leading cause of death in women worldwide, and after the age of 60 years the risk of developing it in women is very high [1, 2]. Mammography is a low dose X-ray mainly used to see inside the breast region. X-Ray Mammography has low cost, suitable for mass screening, and commonly used in clinical practice for screening and diagnostic purposes [3]. Screening mammography has been well suited and effective method for the diagnosis of abnormalities in the breast. It increases the survival rate by detecting the cancer in initial stage [4].
Huge number of mammograms has been generated in hospitals creating a need to develop an automated tool which may help radiologists to retrieve and analyse current images with past stored images. Basically, content-based image retrieval is a technique for retrieving similar images based on the visual information of current image. The use of content-based mammogram retrieval system may help radiologist by providing relevant supporting details from prior known cases, potentially leading to improvement in their diagnostic accuracy [5]. These systems provide similar images according to a certain pattern, which may be texture, color, shape or other important content. However, CBIR methods are usually developed for application specific (due to limitation of used features), so these methods are not always applicable between different kinds of medical modality.
Medical image retrieval and classifications are very important for computer aided diagnosis (CAD). Basically, this tool is fully automated computer processing procedures, used for improving diagnostic information, which may help for analysis and detection of breast cancer [6, 7]. They could help the radiologists in the interpretation of the mammograms by finding similar mammograms out of a database to compare the current case with past cases. Mainly, a CAD system consists of enhancement- segmentation (pre-processing), relevant feature extraction and classification in which, pre-processing and feature extraction is the most important phase where we extract informative low-level descriptors, which may helpful for high-level interpretation and knowledge discovery from the mammogram.
Generally, human interventions are involved in content-based mammogram retrieval, because the presence of labels, artifacts, pectoral muscles, tags and scratches in the X-ray mammogram, misguided the existing segmentation algorithms, and they are unable to segment accurate pathology-bearing regions. So, for analysing the mammogram, the region of interest (ROI) is manually cropped from the breast area for avoiding unwanted tags, labels, and pectoral muscles [8]. But this manual pre-processing requires too much time and are expensive to implement. Several research on mammogram image retrieval system are based on this manual cropping for avoiding the unwanted tags, labels and pectoral muscles [5, 9–12].
For segmentation of the mammogram, it is necessary to find the accurate region of interest (lesions) from the mammograms. These masses or abnormalities can be of various types such as Circumscribed masses, Speculated, micro-calcifications, normal or other miscellaneous types [13]. Since the visual appearance of all the mammograms are significantly closed to each other. So it becomes difficult to correctly segment the region of interest, hence the results of the retrieval are generally less accurate [14]. Due to this, the big challenges in CBIR are to automatically find the accurate region of interests with efficient features.
Breast tumor and non-tumor segmentations are one of the most important and crucial stages in medical image analysis. Usually, pixels inside mass mammograms have highest intensity and continuous variation. So, these characteristics imply a region growing procedure to segment masses in mammograms, in which masses are segmented by grouping the pixels or sub-regions to get bigger regions [15]. For example, if a similarity measure of the two adjacent pixels is greater than a defined threshold, these pixels are considered as visually similar and thus are grouped together [16]. The grouping of neighboring pixels continues until no similar pixels remain. However, selection of appropriate initial seed is a very important issue. Moreover, compared to the detection of seed points for a mammogram, selection of an appropriate value for the threshold is a more considerable problem, because the threshold can affect the boundary information of the benign and malignancy masses [17, 18]. In spite of these problems, during the region growing process (as a region-based method in boundary extraction) the intensity, spatial distribution and connectivity information are considered. Wei et al. [15], proposed a boundary segmentation technique based on region growing for content-based mammogram retrieval system. The brightest pixels in an ROI were considered as seed points. Determination of the threshold was done experimentally in which 100 images were tested using different thresholds and then the final threshold was set. In this work, we have proposed co-occurrence based termination criteria for region growing, which is explained in section-2.
Further, success of accurately retrieval of mammograms depends on what features that are extracted from mammograms and fed into the retrieval model. Hence, we need to transform processed images into features that are better representing the task of retrieval. In this study, we have extracted shape features with different combination of textures. However, the normal and abnormal mammograms contain some similar characteristics. It is practical to eliminate similar features between normal and abnormal mammograms. So, we examine most relevant features using mRMR feature selection method.
In this work, we analyze different segmentation methods like region growing, fuzzy C-means [19], Otsu thresh-holding methods [20]. Herein, different morphological operators are prior applied for pre-processing. Gray-level histograms of the mammogram are also adjusted to reduce the false positive and false negative lesion segmentation of the mammograms.
The objective of this study is carried out in five steps viz.: Automatically remove the artifacts, labels, pectoral muscles, and suppress the noises without human intervention. Proposed GLCM contrast based selective thresholds for the termination of region growing algorithm. This segmentation approach is based on the improvement of region growing to preserve boundary information Extract the texture and shape features. Select informative features using mRMR feature selection. Retrieving similar mammograms relevant to the query image.
This paper is organized as follows; Section 2 presents the proposed methodology, Section 3 sheds some light on results analysis, and finally, Section 4 is concluding section with some further discussions.
Methods and models
The proposed CBIR framework is divided into two parts, off-line feature extraction and on-line image retrieval as shown in Fig. 1. In the component of off-line feature extraction, images are automatically pre-processed by removing the artifacts, labels, pectoral muscles, and noises. Further, segment the mammograms automatically and find its informative ROIs. Furthermore, features from ROIs are extracted and mRMR feature selection technique is adopted for finding the most relevant features. These features are described as feature vectors of the images, constitute a feature dataset stored in the database. In the component of on-line image retrieval, the user or the radiologist can submit a query image to the CBIR system to search for desired images having similar content. The system pre-process and represents this query with another feature vector with same processes. The similarities between the feature vectors of the query and those of the images in the feature dataset are then computed and sorted. This similarity is computed using Euclidean distance similarity measure. After this system ranks the search results in non-decreasing order of the Euclidean distance and returns the results that are most similar to the query.
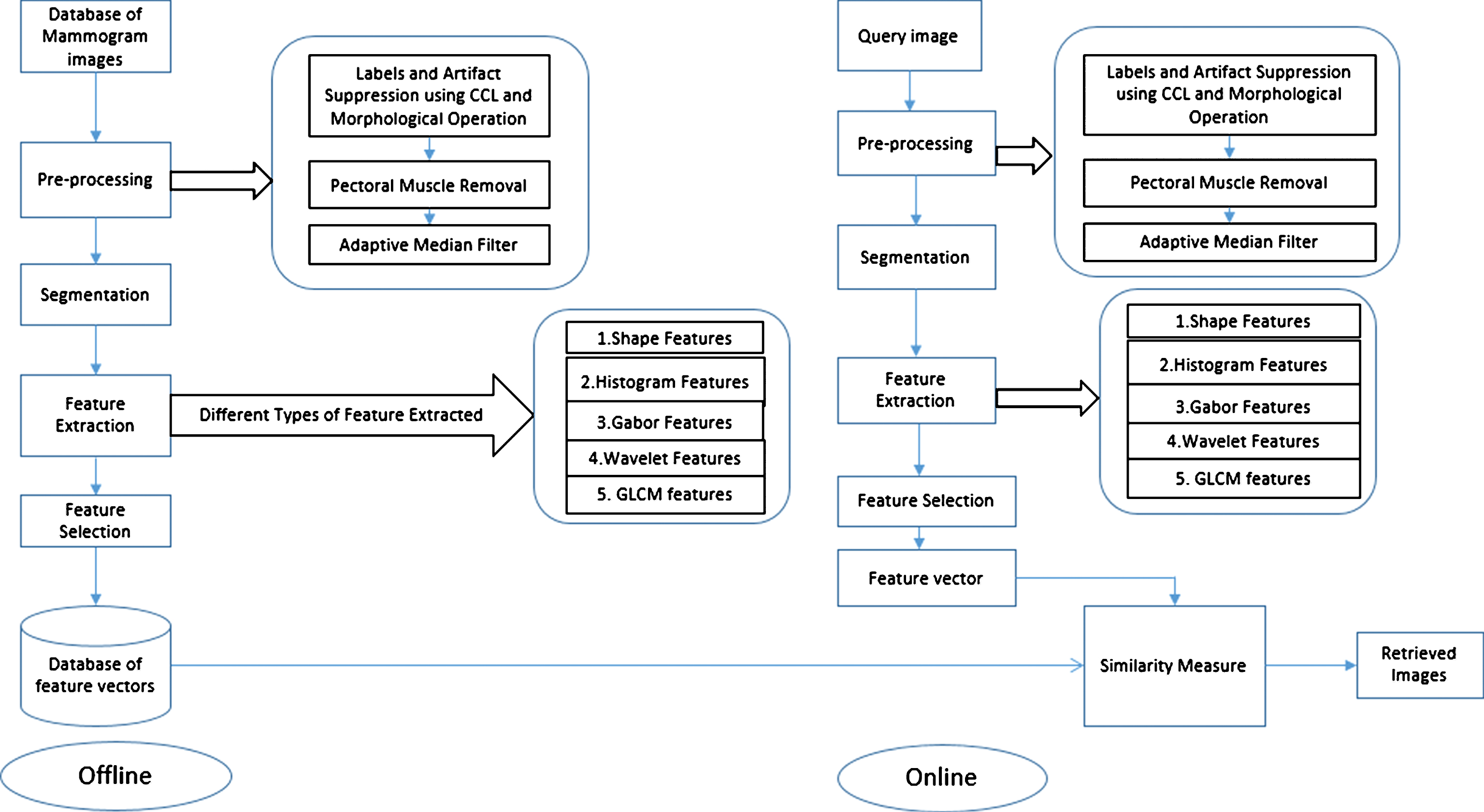
Proposed working diagram.
Mammograms are difficult images to interpret, and a pre-processing phase is necessary to improve the quality of the images and make the feature extraction and image segmentation phases more reliable. Many mammographic images are affected by artifacts, such as; tags, scratches, opaque marker, labels, and scanning artifact which are necessary to remove in order for the segmentation to work effectively. Moreover, pectoral muscle of mammograms is also removed because textures of pectoral muscle in some mammograms have similar appearance as abnormalities, leading to incorrect segmentations. Proposed pre-processing methodologies are explained in sections 2.1.1 and 2.1.2.
Label and artifact suppression using connected componet labeling and morphological operations
We have used a very simple method of connected component labeling (CCL), thresholding and morphological operations to remove radiopaque artifacts such as scratches, marker, wedges and labels in the mammograms. In this method, the gray-level mammogram image is transformed to binary image with a relatively small global threshold. This global threshold is obtained using Otsu’s method, which selects the threshold to minimize the intra-class variance of the black and white pixels [20]. Further, it has been found that mammograms in the database have different, left and right Mediolateral Oblique (MLO) view. So, we have flipped all left MLO views images by 180° for the ease of pre-processing. A complete procedure for the removal of artifacts and labels is given below.
An algorithm for artifacts and label suppression:
Convert gray level mammogram images in binary using global threshold. These binary objects consist of the radiopaque artifacts and the breast profile region. Flip the left Mediolateral Oblique view images by 180° (if exist). Find the labels matrix L that contains labels for the 8-connected objects found in the black and white mammogram. Using label matrix L, calculate the actual number of pixels (Area) for all regions (objects). Find the object with maximum connected pixels (largest area) in each image. Further, removes all connected objects in the binary image that have less number of pixels as compared to the largest area. After step-vi, we get a mask for each image. Further, for smoothing of this mask, remove isolated pixels (i.e. individual 1 s that are surrounded by 0 s), and fill the holes, if exist. Finally, pixel-wise multiply this mask with binary image and remove all the labels, scratches, and other artifacts.
Figure 2 (a-j) show the consecutive outcomes of proposed pre-processing steps on two sample images of MIAS database. In which, Fig. 2a shows the first sample image (id-mdb271) with label-marker in upper right corner; Fig. 2b is 180° flip of original image. Figure 2c shows the output of step-iii, connected labels with different regions. Further, Fig. 2d reflects the mask (maximum area morphological filtered image, output of step vii), and finally Fig. 2e shows the final label-marker and other artifacts suppressed image. Figure 2f shows, another MIAS database image (id-mdb51) with labels and scratches, which is pre-processed with same procedures and final result is shown in Fig. 2j.
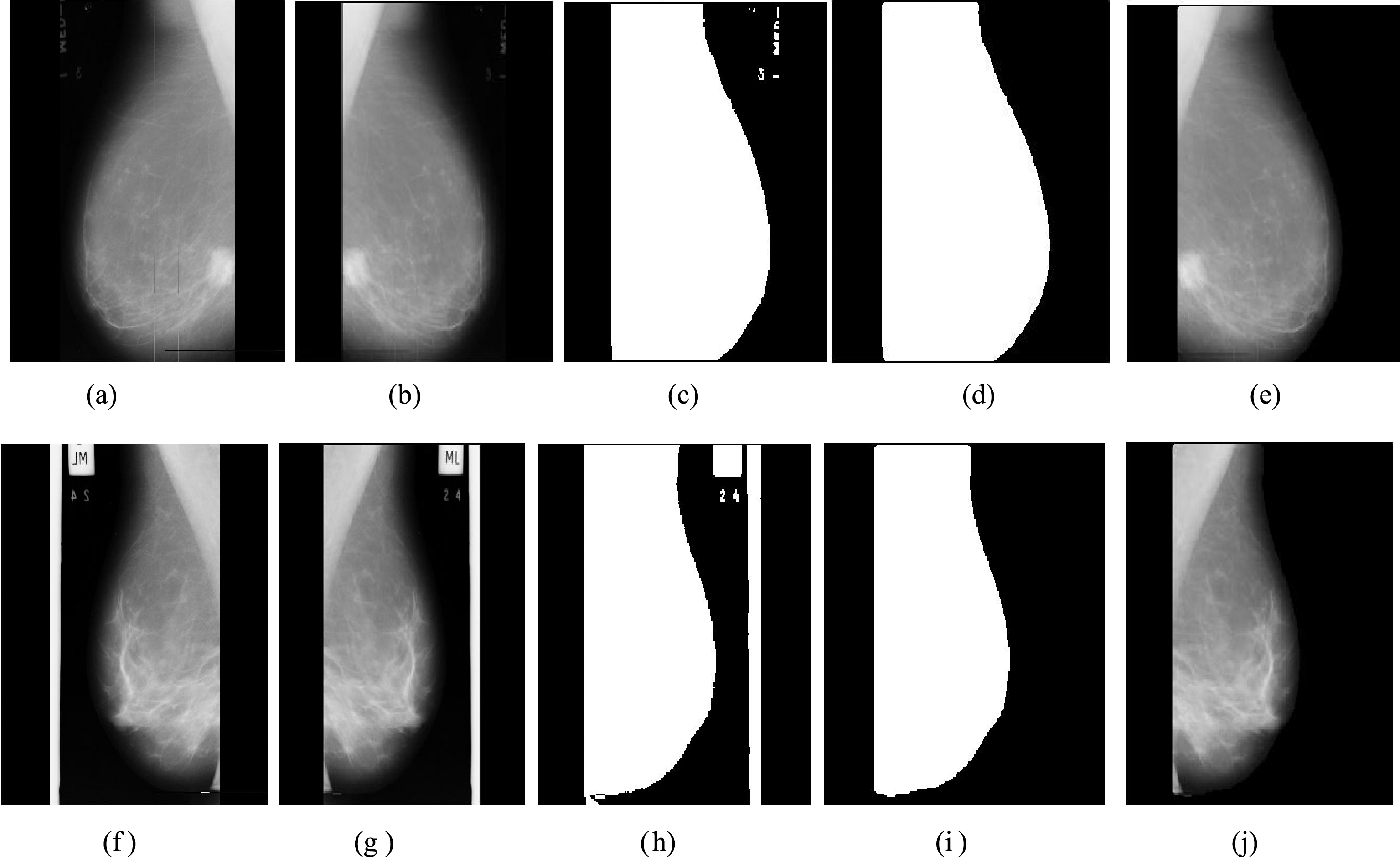
(a-j) Artifacts suppression steps for two different sample images.
The pectoral muscle is a thick, fan-shaped muscle, appears as a triangular opacity across the upper posterior margin [21]. It reduces the bias of mammographic density estimation and will enable region-specific processing in lesion detection programs [22]. The texture of the pectoral muscle may also be similar to some abnormalities and may cause false positives in the detection and retrieval of suspicious masses [23].
Previous work related to pectoral muscle suppression used Hough Transform [24, 25], assuming that the boundary between the pectoral muscle and the breast can be approximated by a straight line. Ferrari et al. [26] proposed a polynomial modelling based method for the removal of pectoral muscle.
Here, we have used a new approach for the removal of pectoral muscle in which first, we apply adaptive k-means algorithm [27] for finding the regions of an image. Further, find a seed point in the pectoral region and apply region growing algorithm with very small threshold. (This is done so that only the pectoral muscle is segmented and then consequently removed). Further, adaptive median filter has been found to smooth the non-repulsive noise from 2D signals without blurring edges and preserving image details [28]. So this is particularly suitable for enhancing mammogram images, hence used by proposed work.
An algorithm for pectoral muscle removal and smoothing:
Take the artifacts and label suppressed image as an input, and find all the different regions present in the image using adaptive k-means algorithm. Then select the any occurrence of non-zero intensity value in the center of pectoral region rows as the seed point to extract the pectoral muscle. Using this seed point, we apply region-growing algorithm with very low threshold. This region growing algorithm returns the segmented pectoral region. Take the complement of segmented pectoral region. Further, extract the segmented pectoral muscle region by pixel-wise multiplying the complement of segmented region with input image. Apply adaptive median filter to smooth the images.
Figure 3 (a-h) show the further consecutive outcomes of proposed pectoral muscles removal and smoothing steps, in which Fig. 3a shows the input image for this phase (output of artifacts and label suppression phase for mdb271, shown in Fig. 2e). Figure 3b, shows the segmented pectoral muscle after step-iii, further complement of this segmented region is pixel-wise multiply with input image, and pectoral region is consecutively removed, output shown in Fig. 3c. Finally, adaptive median filtered image is shown in Fig. 3d. Figure 3e is another input image (output of artifacts and label suppression phase for mdb51, shown in Fig. 2j). Figure 3(f-h), show results of segmented pectoral region, pectoral muscle removal, and adaptive median filtered image, respectively.

(a-h) Pectoral muscle removal and smoothing for both sample images.
Image segmentation refers to extraction of region of interest for further feature extraction. The various image segmentation techniques [29] can be categorized as thresholding method, region based methods, clustering approaches: such as k-means clustering, fuzzy C-means clustering, and texture based methods etc.
In this paper, we have modified the seeded region-growing segmentation algorithm by designing new termination criteria. A region growing method seeks to add the neighboring pixels to the region around a pre-chosen seed if they satisfy certain intensity based criterion. In our algorithm, after removing pectoral muscle and Adaptive median filtering steps, we choose the brightest pixel in the remaining mammogram as the initial seed point. In many cases, it is found, this seed lies within the suspected lesion region. The similarity criterion used is based on intensity based gray level threshold. The region is grown until all the pixels for which intensity difference with seed is less than the threshold are added. Being inspired by Wei et al. [15] where determination of the threshold was done experimentally in which pixel intensities of random images are tested using different thresholds and then the final threshold was set. Here, we have used another limiting criterion using gray level co-occurrence matrix (GLCM) based contrast [30].
Contrast values are calculated using Equation (1) where i, j are the indices for GLCM matrix and C (i, j) is corresponding co-occurrence values. These quantitative values of variations in local neighbourhood help in finding the threshold values for the termination of region growing based segmentation. As we know that, performance of GLCM features depends upon pixel relation between pixel neighbouring and angles. In this work, we have calculated the gray level co-occurrence matrixes at displacement distances of 1 and 5 pixels from four angles (0°, 45°, 90° and 135°). Using all these matrixes, we have calculated the final Contrast, which measures the intensity between a pixel and its neighbor over the whole image. It is 0 for areas with identical image and is high where there are large differences in gray tone.
According to the mammographic society of MIAS database [2], there are three classes of background tissue mammograms- Dense (D), Glandular-Dense (GD), and Fatty (F). During experimental analysis on MIAS database, it has been noted that abnormal Dense and Glandular-Dense mammograms have larger brighter region (Contras >1.8) as compared to Fatty mammograms. Fatty mammograms have limited bright region in specific position and Contrast usually lies between 0.5 to 1.8. The quantitative values of ground truth details based on background tissues are given in Table 1.
MIAS database details based on background tissue images
Figure 4 shows the sample images of MIAS database, where 4(a) shows Dense mammogram having Contrast = 2.67, Fig. 4(b) shows Glandular-Dense Image having Contrast = 1.85, Fig. 4(c) and 4(d), show Fatty images with Contrast value = 1.13 and 0.69. As per the proposed region growing algorithm, we choose the brightest pixel in the mammogram as the initial seed point, and the region is grown (added) until all the pixels for which intensity difference with seed is less than the threshold. In order to prevent the region from growing indefinitely large (as in case of Dense and Glandular tissues), we have used limiting criterion by reducing the threshold value as t = 0.13. For Fatty images, there are specific brighter region in small limited area, so we have used higher threshold value t = 0.20 for growing the algorithm to find more accurate ROI.
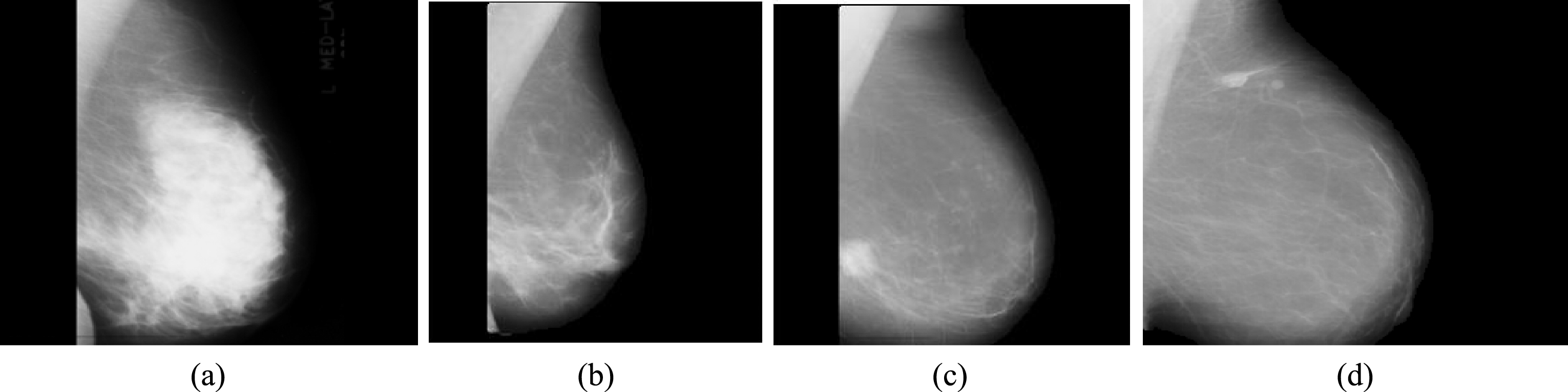
Sample images based on background tissues.
An algorithm for segmentation based on modified region algorithm:
Take pre-processed images, and find (x, y) = seed point, which is the point with maximum intensity value. Calculate the Contrast of the mammograms using GLCM and Equation-1. Depending on the type of mammogram, the threshold t for the termination of region growing algorithm is determined. If the Contrast is higher than 1.8 then threshold is taken as t = 0.13. Else if the Contrast< = 1.8, then threshold value is set as t = 0.20. Run region growing algorithm using seed point and selected threshold t. The new point, from 4- neighboring pixels, is added to the segmented region if the distance (intensity difference) is less than threshold t. Repeat the step-iv until the distance between seed point and the neighboring pixel is higher than threshold t.
Figure 5(a-d)show the final outcomes of proposed segmentation for both images. In which, firstly, we have taken an input image shown in Fig. 5a, which is an output of pectoral muscle removal and smoothing phase for mdb271. Finally, Fig. 5b shows the result of proposed segmentation, easily detected the informative ROI part of mammogram. Figure 5c shows another pectoral muscle removed cum filtered sample image of MIAS database, and Fig. 5d shows the final segmented image.
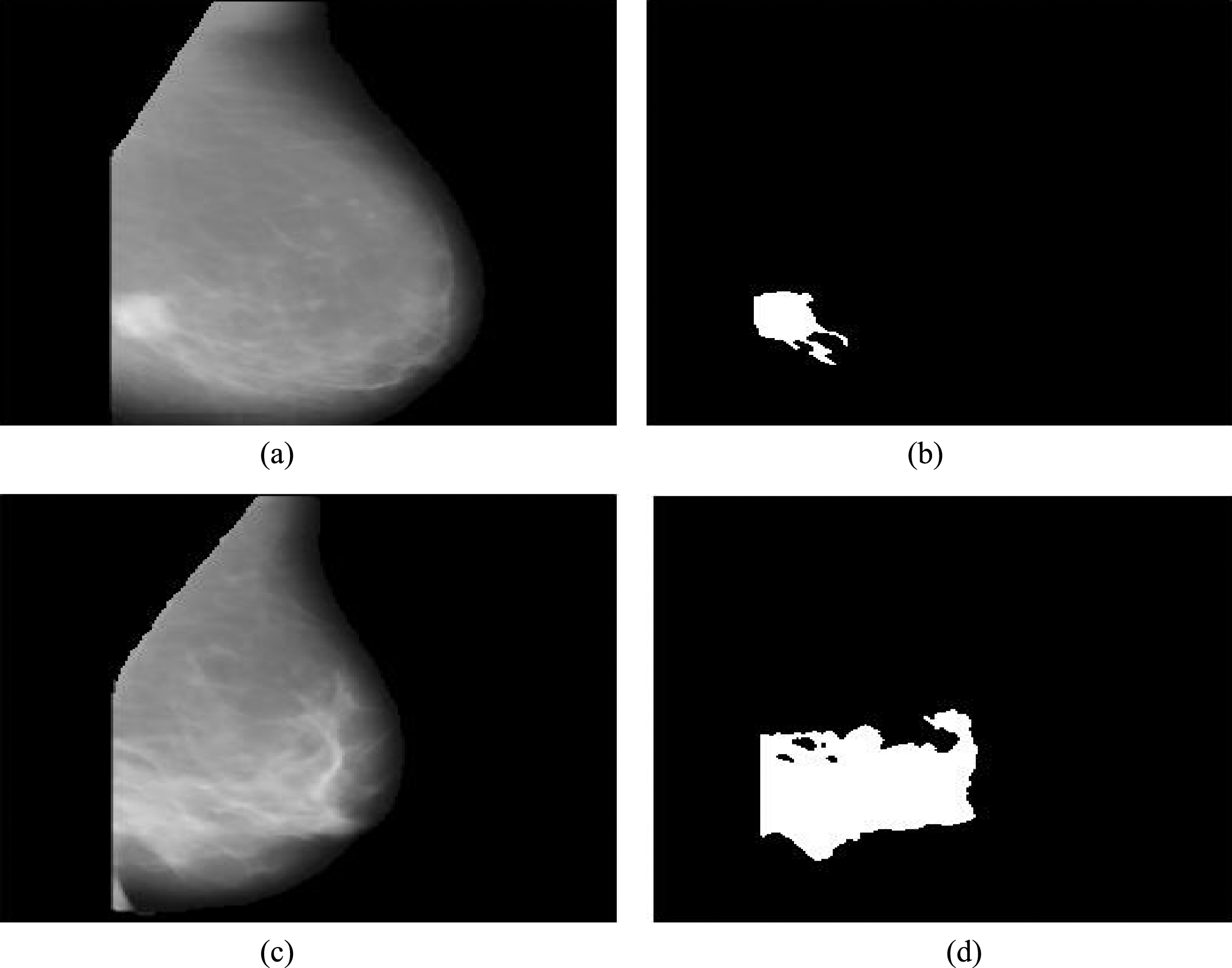
(a-d) Segmentation of both sample images.
Features are the most useful information of an image, plays a major role in medical image analysis. For better characterization, used feature set contains statistical, shape, wavelet, Gabor and GLCM features. These features are extracted from the each segmented ROI, which include 8 geometric features (1–8), 5 histogram-based statistical features (9–13), 48 Gabor features (14–61), 40 wavelet features (62–101), and 21 GLCM (102–122) features. Summarized details of all these features are given in Table 2.
List and description of computed image features
List and description of computed image features
Geometric or shape feature describe the geometric properties of the masses. In medical diagnosis for breast cancer detection, geometric features are essential to recognize any object, regardless of breast size. A simple geometric property includes image area, position, and orientation, centroid, etc. For each mammogram of database, we have extracted 8 region properties that are Area, Euler Number, Centroid, Eccentricity, Perimeter, Filled Area, Convex Area, and Orientation.
Histogram based statistical features
Statistical texture analysis is based on statistical properties of intensity histogram without considering spatial dependence. The histogram of the image gives summary of the statistical information about the image. Statistical features give more promising information in pattern classification and retrieval area. It characterizes texture by the statistical distribution of the image gray level intensity [6]. The useful statistical features from each mammogram (X) having i, j indices are extracted which details are given in Table 3.
Histogram based statistical features
Histogram based statistical features
Gabor wavelet is widely adopted to extract texture feature from the images and has been shown to be very efficient for the retrieval and classification of mammogram [31]. Basically Gabor filters are group of wavelets, with each wavelet capturing energy at a specific orientation and specific frequency. In order to extract textural micro patterns in breast mammograms, Gabor filters can be tuned with different orientations and scales. The general function of 2-D Gabor filter family represented as a Gaussian kernel and modulated by an oriented complex sinusoidal wave [32] is described as follows:
After applying Gabor filters on the images with different orientation at different scale, we obtain an array of transformed coefficients. Mean square energy, Mean amplitude of these Gabor coefficients are used to represent the homogenous texture feature for the each image of mammogram.
Wavelet provides a very sparse and efficient representation for image [33]. It is frequently used for mammogram classification and retrieval due to easy detection of useful local and transient properties [34]. Wavelet transform analyses the texture of mammogram by decomposing it into detail and approximation coefficients. In this paper, we have taken 3-level decomposition of low pass approximation of Coiflet wavelet. Afterwards standard deviation and mean of this transform coefficient are used as a feature vector. Figure 6 shows the 3 level decomposition of LL (Low-Low) sub- band, where first an image is decomposing into four bands, LL, LH (Low-High), HL (High-Low), and HH (High-High), then after LL sub-band of image is further decomposed and process repeated at 3 levels.
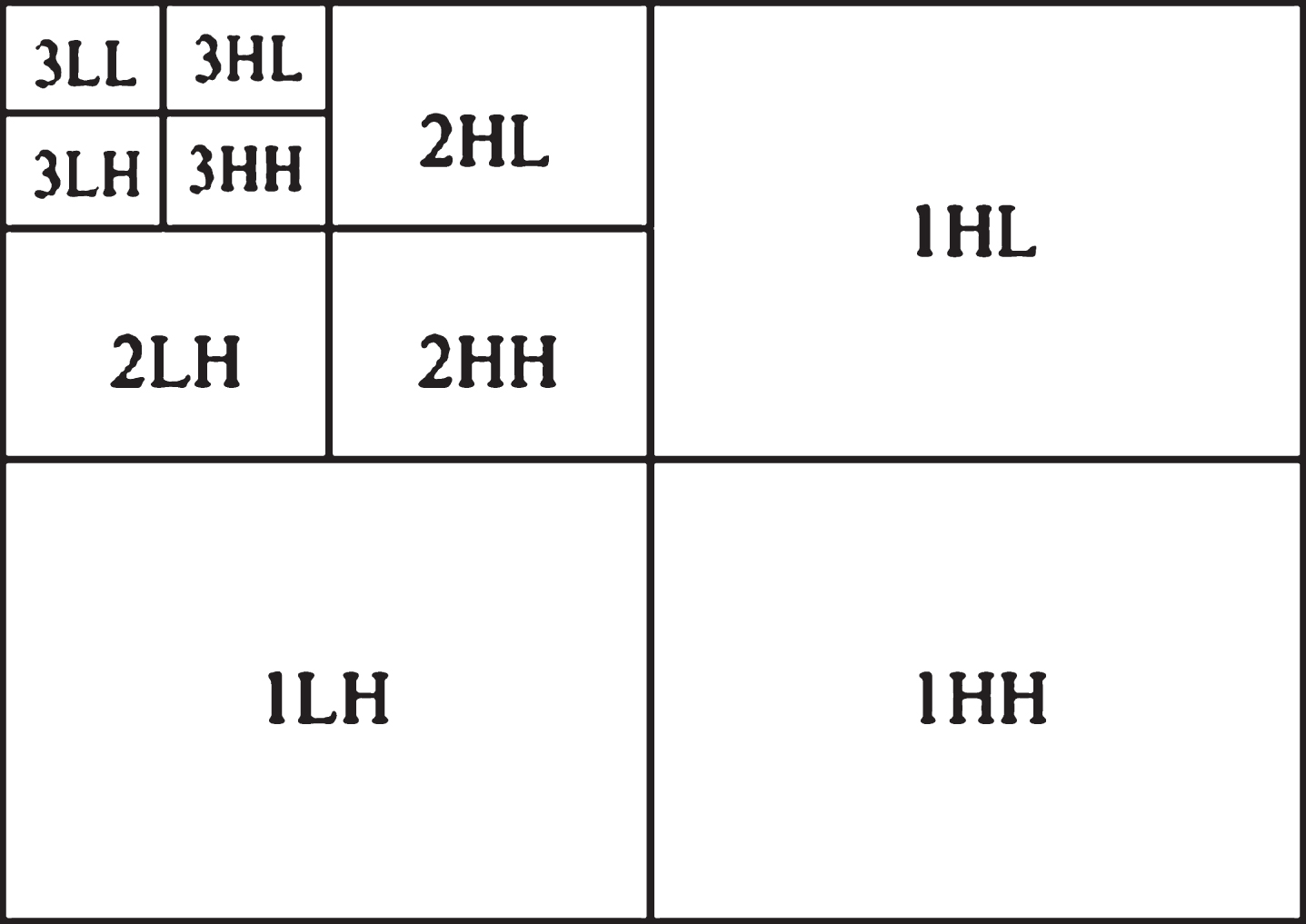
3-level wavelet decomposition.
Mean and standard deviation are calculated using following equations:
GLCM is a statistical approach for computing the co-occurrence probability of different combinations of grey levels in an image, which plays an important role in the retrieval of mammograms [31]. The matrix element C (p, q|Δx, Δy) is the relative frequency, where two pixels are separated by a pixel distance (Δx, Δy) within a given neighborhood, one with intensity p and the other withintensity q.
Let I (x, y) is an image with size M × N and gray levels G ranging from 0 to G - 1. Then GLCM matrix (C) for an image I, parameterized by an offset (Δx, Δy) is defined as [30, 35]:
For finding the most informative feature subset, here we have used minimum redundancy maximum relevance (mRMR) filter method [38]. The mRMR feature selection method select an informative subset of feature in which each feature has minimal redundancy with other features and maximal relevance with target class of each mammogram. In this method the informative set of features is obtained by calculating the mutual information (MI) between the features and the class variable, and between the features themselves.
For binary classification (Normal or Abnormal class of mammogram) the class variable C
k
is 0 or 1. The mutual information between two features denoted by Fx and Fy is calculated as:
Similarly, the mutual information between target variable c and feature Fx is calculated as:
Then for calculating minimum redundancy, we have to minimize the total redundancy of all features selected by Min (Redundancy), where
Also the maximum relevance condition is to maximize the total relevance between all features in S and target vector (class). It is calculated as Max (Relevance) where
Here, first feature having the highest MI (Fx, c) is selected according to Equation (9) and the rest of the features are selected in incremental way where earlier selected features are remain in the features set. The optimal subset of features is selected by optimizing the Equations (8) and (9) simultaneously through mutual information difference (MID) criteria:
As a result, we select only those features whose difference of Relevance-Redundancy is high. Thus, MID is the basic scheme to search for the next feature in mRMR optimization conditions. Pang et al. (2005) had used simple sequential selection (incremental-heuristic) algorithm where the first feature is selected which have highest Relevance. The rest features which are satisfying the MID criterion are selected in an incremental way.
For the retrieval of desired content based mammograms, all the above discussed features are extracted and mRMR filter based feature selection technique is adopted for finding the most relevant features. Here, we have selected only 35 most informative features out of 122, because during experimental analysis this paper analyzed the retrieval performance on all selected features and got best retrieval performance for first 35 high ranked features (where rank is decided by MID criteria).
Thus, the final feature set for one image = [F1, F2 F3 … … … … F35]
Feature matrix of n number of images = n × 35
We can write this feature vectors into n × m representation, where n is the number of images and m is the number of features. So, proposed feature vector can be expressed in a matrix such as:
This feature set (FS) is described as feature vectors of the images and store in database for indexing. For the image retrieval a query image feature vectors are extracted as same procedure. Afterwards, the similarity measures from every feature vector in the database to query image feature vector is calculated and stored. Finally, sort the values of similarity measure in increasing order and retrieve most relevant images.
Similarity measure, Euclidean distance (ED) is calculated as:
Experimental dataset
We have used Mammographic Images Analysis Society database where all ground truth details of mammographic images (size 1024*1024 pixels) are given with corresponding id’s [2]. This database contains 115 images from Abnormal and 207 images from Normal classes and these ground truth information are used for the analysis of normal and abnormal mammogram retrieval. Abnormal mammograms are further divided into six classes-asymmetric cases, architectural distortion, circumscribed masses, ill-defined masses, calcification region, and spiculated masses.
Metrics used for performance evaluations
The performance of a CBIR system is generally measured in terms of its precision and recall. Precision (P) is a measure of how well the system discriminates images of the same class from other classes i.e. retrieve only those images that are relevant. It can be calculated as:
Recall (R) is a measure of the ability of the system to retrieve all images that are relevant. It can be calculated as:
The retrieved results may change depending on different thresholds as discussed in segmentation section. Here, we have drawn Precision-Recall (P - R) curves to show how the results can vary based on the choice of these thresholds. The P - R curves for mentioned Contrast intervals and thresholds are shown in Figs. 7 and 8. In Fig. 7, retrieval of 6 different thresholds t = 0.07, t = 0.09, t = 0.11, t = 0.13, t = 0.15, and t = 0.17 are tested for the Contrast>1.8. As we already know that only for the Dense and Glandular Dense images Contrast is greater than 1.8. So in this P-R graph random 10 (5-Dense and 5-Glandular Dense) abnormal mammograms are fired as queries and total number of retrieved images are set as 100. From the P-R curve it is clear that retrieval performance is best for t = 0.13.

Image retrieval performance on different thresholds for Contrast >1.8.
As we know that only for Fatty mammograms Contrast is less than 1.8. So in this P-R curve 5 random fatty mammograms are taken as queries and retrieval of six different thresholds t = 0.14, t = 0.16, t = 0.18, t = 0.20, t = 0.22 and t = 0.24 are tested. From the Fig. 8, it is clear that t = 0.20 is best for the fatty mammograms. So, from all these results, it is confirmed that the used threshold t = 0.13 and t = 0.20 are best for the image retrieval as well as segmentation.
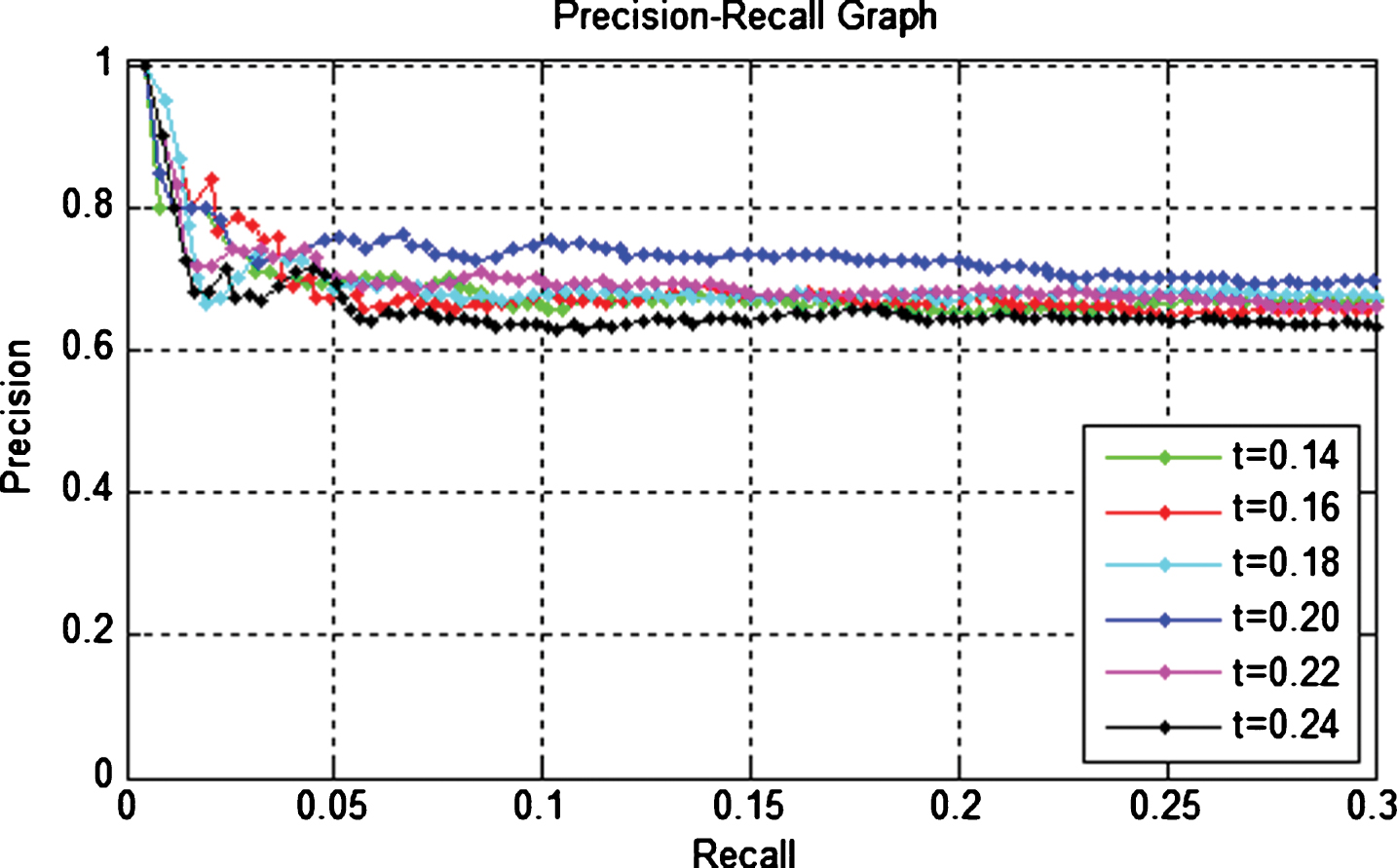
Image retrieval performance on different thresholds for Contrast <1.8.
From the P-R curves, it is proved that the used thresholds t = 0.13 and t = 0.20 is significantly better for the retrieval. So we have used both thresholds for our retrieval. In the Fig. 9a,b retrieval performances are also tested for normal and abnormal mammograms, where according to the mammograms, threshold t = 0.13 and 0.20 are automatically detected and applied by the proposed seeded region growing segmentation. In this comparative study, the experiments are carried out to select 10 random mammograms as query and number of retrieved images set as 40. Here, it is clearly visible that average precision and recall of proposed framework are consistently encouraging for 40 images retrieval. From these comparative analyses with other segmentation approaches, it is confirmed that the proposed thresholds based seeded region growing is better than all.

(a) Average precision-Number of retrieved image and (b) average recall-Number of retrieved image.
In the existing literature of mammogram image retrieval, generally the performances of retrieval system are analyzed for abnormal and normal class images, in which retrieval of abnormal images is quite important since it helps radiologists easily detect the similar cancerous mammograms out of a database to compare the current case with past cases. In order to compare our method with other state-of-art methods, average precision and recall rates are calculated for 15 images of retrieval. Here, we have taken 20 independent images (10 from each class) as different queries; belong to two types, Normal or Abnormal (Benign or Malignant). In this paper, the proposed approach is compared with four prominent mammogram retrieval approaches, introduced in the next section, namely Wei et al. [9]; Wei et al. [10]; Sun J et al. [11]; Wiesmuller et al. [12].
For the implementation of Wei et al. [9], we have used 4 different gray level co-occurrence matrices, constructed in order to compute each ROI in the 0°, 45°, 90°, and 135° directions, each with unit pixel distance of 5. Further, 11 Haralick statistical features are computed from each matrix and Euclidean distance based similarity measure is used for retrieval.
For the implementation of Wei et al. [10], we have used Gabor filtering (Orientation = 6, Frequency = 4) on the underlying image, applied probability distribution and then computes Contrast, Angular second moment, Inverse difference Moment, Entropy, Variance and Correlation based statistical features to describe the textural pattern of the mammogram. Further ED is used as a similarity measure. For the article Sun and Zhang [11], texture structure of mammographic image was firstly extracted by the maximum and minimum of local intensity. Then, a new texture feature based on gradient differences in 8-connected neighbours is introduced. Further combined with the weighted moments, the new descriptor was given as an index for mammographic image retrieval. For the implementation of Wiesmuller and Chandy [12], gray level aura matrix is computed from each ROI to capture the texture information. Afterwards for finding the most relevant mammograms, Euclidean distance similarity from every feature vector in the database to the query image feature vector is calculated.
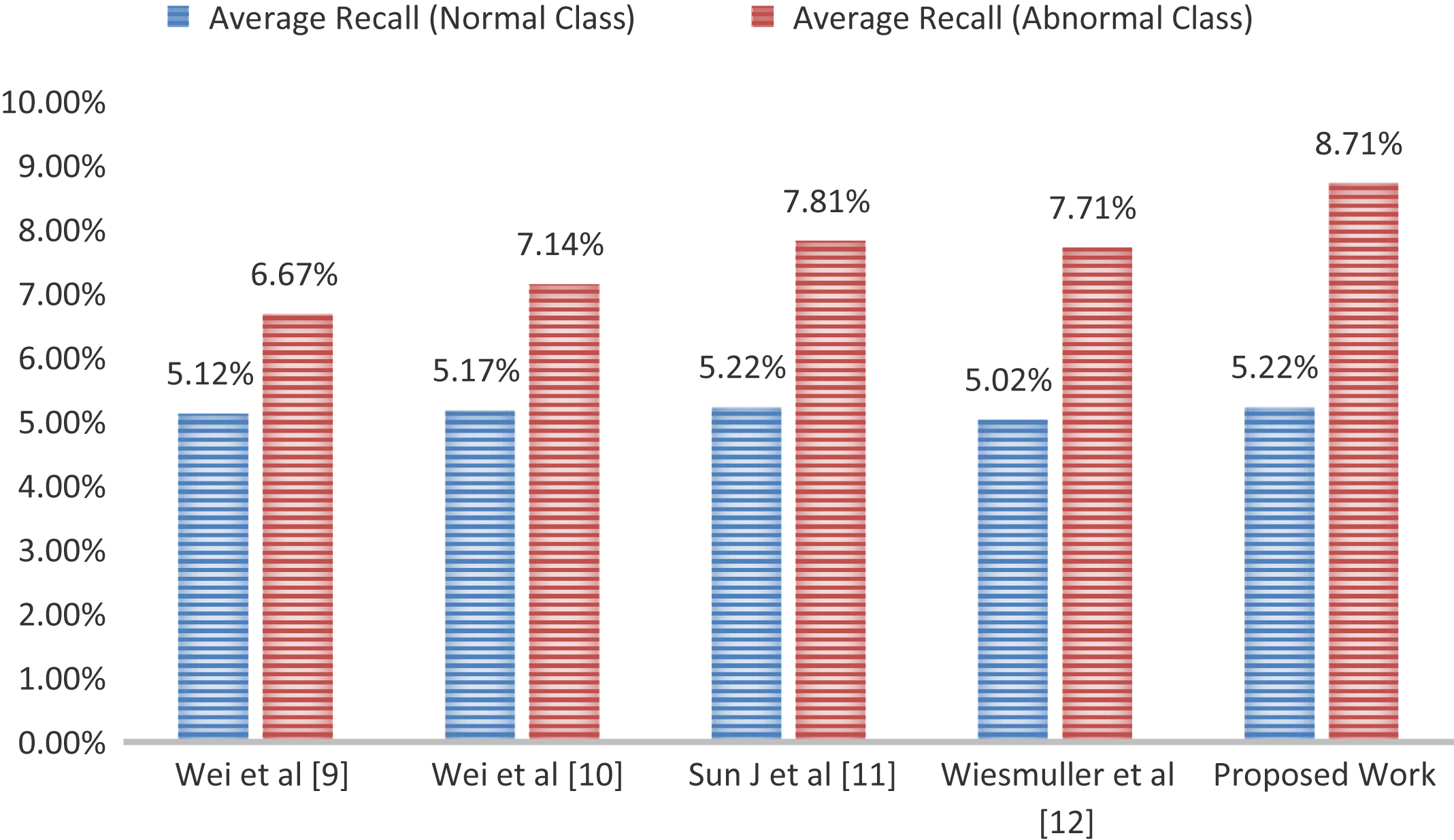
From the Figs. 10 and 11, it is clear that our method is able to retrieve more relevant images than the listed competing methods. This paper work gives encouraging results, 72% average precision for normal class, and 61.3% for abnormal class. As class-wise comparison with other methods, it is clearly visible that the proposed method has significant improvements in average precision and recall for abnormal class mammograms and slightly improvements for normal class mammograms.

Class-wise average precision for normal and abnormal image retrieval.
Class-wise average recall for normal and abnormal image retrieval.
According to the reported results in Table 4 as overall mean of average precision and average recall of both normal and abnormal classes, the performance measures of proposed approach is found better in comparison to the other mammogram image retrieval methods. The overall average precision of proposed approach is better by 7.98%, 5.95%, 3.35%, and 5% with respect to overall average precision of approaches introduced by Wei et al. [9]; Wei et al. [10]; Sun J et al. [11]; Wiesmuller et al. [12], respectively. Also the overall recall of proposed approach is better by 1.08%, 0.82%, 0.42%, and 0.61% with respect to overall average recall of approaches introduced by Wei et al. (2005); Wei et al. (2007); Sun J et al. (2008); Wiesmuller et al. (2010), respectively. Here, we are analyzing the retrieval performance for 15 images, so maximum relevant images can be retrieved are 15. Therefore, quantitative values of recall will be always less because the number of retrieved relevant image is always divided by the total number of relevant images in the database. Due to this, we got surprising results for abnormal images. Although, precision of this class images are less than normal class but recall is significantly encouraging (shown in Figs. 10 and 11). The reason, behind this improvement is the number of abnormal images in the database, which is nearly half of normal images. Due to this, precision and recall are used together for performance evaluation.
Overall mean of average precision and average recall of both classes
Figure 12 shows the snapshot of image retrieval for four sample queries, in which Fig. 12a shows the retrieval for a healthy query, where all retrieved images belong to the healthy class. It reflects the 100% retrieval rate for this sample query. Figure 12b shows that retrieval for abnormal query belongs to the Ill-defined masses (malignant) where out of 10, 7 images are correctly retrieved. Figure 12c shows the retrieval for suspicious circumscribed mass (benign) where all the retrieved images are relevant to the query. Figure 12d shows the retrieval for abnormal query, which belongs to the class of architectural distortion (malignant), where 8 images are correctly retrieved. So these retrieval snapshot gives the glimpse of effectiveness for the proposed work.
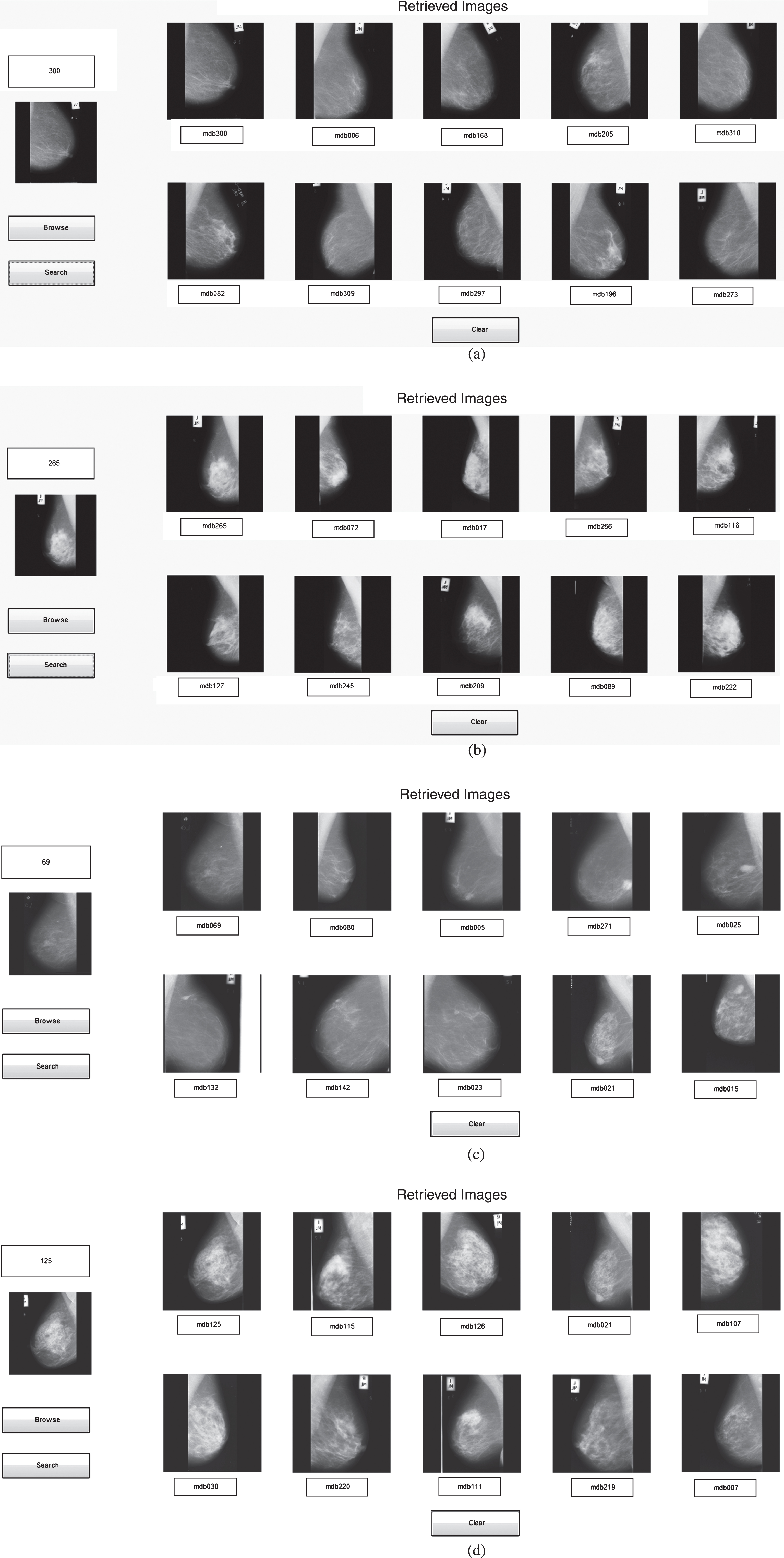
Image retrieval for healthy query (a), for abnormal (Malignant-Ill-defined masses) query (b), for abnormal (Suspicious: Circumscribed Masses) query (c) and for abnormal (Malignant: Architectural Distortion) query (d).
As opposed to textual indexing, CBIR system retrieves images based on visual content which is highly benefited for early detection and diagnosis of cancer in mammograms. Designing an automated approach dealing with segmenting of breast region in mammograms has proven to be a difficult task. Here, we have approached the problem from connected component labelling, morphological image processing, adaptive k-means, and seeded region growing perspective. There are number of factors which make it difficult for segmentation, start with image acquisition parameters, such as exposure time and energy level, which influence the quality of the image. These factors introduce imaging artifacts, in the form of noise, scratches, labels, and wedges, which may interfere with the interpretation process. Further, segmentation of the breast region (ROI) from the background is hampered by the tapering nature of the breast. There are three key contributions of the work presented in this paper. Firstly, fully automated removal of artifacts, labels, scratches, and pectoral muscles. Secondly, modified region growing for an efficient segmentation to provide perfect breast contour representation for breast profile region and finally, the retrieval framework. Proposed segmentation for retrieval was found significantly better than Otsu, fuzzy C- means, and region growing based approaches with same set of features. Further, we compared the retrieval results with four state-of-art methods and found that the proposed work was better than listed competing methods.