
Abstract
BACKGROUND:
Dual-energy computed tomography (DECT) has been widely used to improve identification of substances from different spectral information. Decomposition of the mixed test samples into two materials relies on a well-calibrated material decomposition function.
OBJECTIVE:
This work aims to establish and validate a data-driven algorithm for estimation of the decomposition function.
METHODS:
A deep neural network (DNN) consisting of two sub-nets is proposed to solve the projection decomposition problem. The compressing sub-net, substantially a stack auto-encoder (SAE), learns a compact representation of energy spectrum. The decomposing sub-net with a two-layer structure fits the nonlinear transform between energy projection and basic material thickness.
RESULTS:
The proposed DNN not only delivers image with lower standard deviation and higher quality in both simulated and real data, and also yields the best performance in cases mixed with photon noise. Moreover, DNN costs only 0.4 s to generate a decomposition solution of 360 × 512 size scale, which is about 200 times faster than the competing algorithms.
CONCLUSIONS:
The DNN model is applicable to the decomposition tasks with different dual energies. Experimental results demonstrated the strong function fitting ability of DNN. Thus, the Deep learning paradigm provides a promising approach to solve the nonlinear problem in DECT.
Introduction
Conventional X-ray imaging provides a representation of the examined object in terms of attenuation coefficient. This information is not sufficient to characterize precisely object in some practical applications. In recent years, the adoption of Dual-energy CT (DECT) has gained increased attention in public security and medical fields. Like single-energy CT, DECT technique provides a 3D dataset, and also has ability to extract the atomic numbers and electron densities instead of only the attenuation. Thus, it facilitates substances identification [1, 2] and medical diagnosis [3–5]. The capability of DECT depends on the principle that the attenuation coefficient is material and energy dependent. Material decomposition can be carried out on the images of the object scanned by rays of two distinct energies. Dual-energy equations can be easily written and solved for monochromatic energy, but become complex when considering realistic spectrum. The problem can be described by the following equations:
The dual-energy equations are difficult to solve in practice for the interfering noise in the imaging system. Several kinds of approaches have been proposed to solve the non-linear problem in Equation (1). One approach [6, 7] is to model the energy projections as polynomial functions of decomposed projections. The functions are usually solved by using iterative methods. This solution procedure has to be proceeded for every pixel, thus costing a great deal of time and calculation. Another approach [8, 9] obtains the decomposition projections based on tabulated value of (p L , p H )-(C1, C2), but it requires knowledge of the energy spectrum and becomes unstable in cases of excessively noisy data [9].
Recently, deep learning algorithm, which uses neural networks having a deep structure with three or more layers, has shown outstanding performance in a wide range of fields including computer vision, speech signal processing and artificial intelligence. Many researches have shown that Deep Neural Network (DNN) is widely applicable to feature extraction and classification tasks [10, 11], however, it requires a large amount of training data. Like other machine learning algorithms, DNN allows the user to improve the performance of the model based on empirical data. This characteristic enables DNNs to provide data-driven knowledge-enhancing abilities for solving some unstructured problems. We might not have enough high qulity tomographic data in the past. Most rearches in DECT attached great importance to the elaborated design of the method. With the development of imaging equipment, we are able to collect more high qulity image data. Machine learning method may be a reasonable alternative to the conventional hand-crafted methods in computed tomography. Thus, combination of tomographic imaging and machine learning promises to empower image analysis [12].
Some of the recent researches [13–15] have already applied conventional neural network to estimate (C1, C2) when given (p L , p H ). These algorithms use energy projection and corresponding basis material coefficient as sample pair to train a three-layer neural network. In testing process, the net takes (p L , p H ) as input and outputs the predicted (C1, C2). Experimental results have shown that neural network estimator had lower bias than linearized maximum likelihood estimator and a variance that achieved Cramèr-Rao lower bound [14]. These empirical algorithms have shown success of neural network on material decomposition. But these well performances were achieved under the condition of specified dual energy spectrums, one net for one dual energy pair. The net has to be retrained as long as one of the energy spectrum changes, which limits its application.
In this paper, we present a projection decomposition algorithm based on a deep learning neural network. We use a cascade model consisting of two sub neural nets to decompose the energy projections. The model is applicable to the decomposition task with different dual energy pairs. We demonstrate the effectiveness of our model by simulation and real experiment. Two conventional approaches are implemented and compared to the proposed algorithm in projection domain and image domain.
An overview of the proposed network is illustrated in Fig. 1. We attempt to model the relation between dual-energy spectrums, energy projections and basis material thicknesses via a deep neural network. The network consists of two parts, compressing net and decomposing net, which are cascade connected but trained independently. The compressing net is a stack auto-encoder (SAE) [16] with 150-40-10 layer structure. It transforms the energy spectrum

Overall architecture of the proposed network. The proposed network has a cascade architecture. The compressing net compresses the energy spectrum to a vector with 10 elements. A joint vector can be obtained by combining the compressed energy spectrum with pixel pair in energy projections. The decomposing net takes the joint vector as input and outputs the corresponding material coefficient.
The purpose of compressing operation is to find a more compact representation of energy spectrum. We found it was difficult to fit function (C1, C2) = f (
SAE is one of deep learning algorithms, which is easier trained and yields performance comparable to other deep generative models [17–19]. The ideal of SAE is to train each layer of deep net as an auto-encoder in bottom-up order. Auto-encoder, the basic unit to construct SAE, is simply a neural network that tries to copy its input to its output [20]. The architecture of a typical auto-encoder is illustrated in Fig. 2(a), which usually contains an encoder and a decoder. An input
A loss function L (
To compress energy spectrum, we design a 150-40-10 SAE composed of two encoders and two decoders as shown in Fig. 2(b). Sigmoid is selected as the neural activation function (y = sigmoid (x) =1/(1 + e-x)). So the Equation (2) can be written as:

The structure of auto-encoder and stack auto-encoder. Auto-encoder consists of an encoder and a decoder. The encoder transforms the input to feature vector
The process of training proposed compressing net can be described as follows. Firstly, auto-encoder 1 is trained until the loss function l1 (
The compressed spectrum and projection values are connected into a joint vector

The structure of decomposing net. The decomposing net is a conventional neural net with only one hidden layer. Its inputs are the dual energy spectrums and projections. The outputs are the corresponding basis material thicknesses.
The least mean square error is used as the loss function in the output layer. It follows the Equation (6) where
Experimental dataset
In order to train compressing net, we use SpekCalc software [22] to generate 405 energy spectrum samples with different tube types, energies and filter thicknesses. The value range and sampling step of each factor are listed in Table 1. Each energy spectrum sample is represented as a 150 dimensional vector and normalized to unit area. The 150 input data are sampled at the integer points in [1 kV, 150 kV]. The doses in this range account for a total of 0.95, while 0.82 in [1 kV, 100 kV]. Compressed form
A list of variables used to generate energy spectrum samples
A list of variables used to generate energy spectrum samples
Then, 100 pairs of (
In order to verify the validity of the proposed DNN above, we perform experiments on two phantoms. One is simulated data containing a cylindrical water and embedded aluminum. SpekCalc software is used to simulate the dual energy spectrum (100 kV with 0.4 mm Be and 2 mm Al filter, 140 kV with 0.4 mm Be and 12 mm Al filter). The other is a real cylindrical water bordering aluminum from QRM. Its energy projections are acquired from a real imaging system (120 kV, 200 kV with 5 mm Al filter). The system consists of a YXLON 225.48 source and a Varian 4030E flat panel detector. Figure 4 presents the phantoms and dual energy spectrums applied in both experiments. The energy spectrums are normalized to unit area. The value range of 151–200 kV in the high energy spectrum (200 kV) is omitted due to its small amplitudes and the requirement for input dimension of compressing net. Other geometric parameters of the system are listed in Table 2.

The phantoms and dual energy spectrums in simulation and real experiment. The phantom (left column) used in simulation is a water cylinder with embedded aluminum. The QRM phantom (right column) in real experiment contains a cylindrical aluminum and water. The energy spectrums drawn in the figure are normalized to unit area.
A list of geometric parameters used in the experiments
The decomposed projections in both experiments will be reconstructed by FBP. We compare our model with a recent fitting decomposition method [24] and a tabulation method [25] in both projection domain and image domain. We choose the following metrics to evaluate the performance of these methods. In Equations (7, 8 and 11), v
i
and
RMSE is the root-mean-square error between the expected value and measured value. MAD is the maximum absolute distance. The metrics are calculated from the whole region in decomposed projections and region-of-interest (ROI) in reconstructed images. RMSE and MAD are used to measure the robustness of the methods to the noises. The execution time of the decomposition algorithm is also chosen to be one evaluation metric.
Particularly, three more indicators are introduced into the evaluation for reconstructed images. The bias and standard deviation [14] relative to the ground-truth 70 kV attenuation coefficient (μ1 (70) and μ2 (70)) are adopted. The expressions are as follows:
Performances on dataset
We first explored the spectrum reconstruction error of compressing net. The output dimension of compressing net is varied from 4 to 12. For each dimension, the compressing net is trained for 10 times. All the training samples are then reconstructed by the decoders. Reconstruction RMSE is calculated and shown in Fig. 5. Outputs

Reconstruction RMSE performed by compressing net. The output dimension of

Examples of reconstructed spectrum and original energy spectrum. Several spectrum samples are generated by using SpekCalc software and plotted in the figure. The solid lines are the original energy spectrums and the dash lines are the spectrums reconstructed by the proposed SAE (150-40-10). It can been seen that the original energy spectrum has already been fit in small error.
The decomposing net is trained on dataset containing 345,870 training samples. We have tested the decomposing net with different structure. The number of node in nonlinear hidden layer is varied from 5 to 35 with 5 steps. Predicted RMSE on test dataset will not drop a lot after increasing the number of hidden node to 20 as displayed in Fig. 7 (left). So we choose 22-20-2 as the structure of decomposing net. The right graph in Fig. 7 shows the statistical results of decomposing net (20 nodes in hidden layer) on materials of various thicknesses. The RMSE is much larger at the point of material with small thickness. Generally, the decomposing net delivers more accurate value of aluminum than that of water.

The performance of decomposing net on test dataset. The left figure plots the variation curve between number of hidden nodes in decomposing net and RMSE of decomposed projection. We choose 22-20-2 as the structure of decomposing net. The right figure shows the RMSE distribution of the net in the case of different material thicknesses.
The projection decomposition experiment for simulated phantom was done on a computer with 32-core CPUs (Intel Xeon E5-2650, 2.60 GHz). The size of energy projection is 360 × 512. Table 3 lists the performances of the three methods. We also test the running speed of the three methods using projections with different sizes. The test results are listed in Table 4. The fitting method achieves the best accuracies in all metrics, however, it costs much running time. This is due to the high computational-complexity, since a fitting equation need to be solved for every voxel pair. The lookup table used in matching method is 0–40 mm (0.5 mm increments) water and 0–30 mm (0.5 mm increments) aluminum, which is the same as the one used to train decomposing net. But it performs lower accuracies and pool running speed than DNN. It is worth emphasizing that DNN runs significantly fast speed (excluding the training time) with moderate precision. DNN costs only 0.4 s to give a decomposition solution of 360 × 512 size scale, which is about 200 times faster than the fitting method.
Errors of decomposition results in simulation experiment
Errors of decomposition results in simulation experiment
Comparision of the costing time used by the methods
The material decomposition projections are used to reconstruct images via FBP. We calculate Hounsfield unit (HU) values of reconstructed images at 70 kV which are presented in Fig. 8. It can been seen that there is not much difference in vision between the results of DNN and fitting method. Both methods have achieved well material decomposition. The precision of lookup table is the main factor that affects the image quality of matching method.

Reconstruction results of simulated phantom. The reconstructed images of water and aluminum are obtained from the decomposed projections via FBP. The proposed network is compared with the fitting and matching method.
Table 5 lists the numerical comparison of reconstructed images. All the metrics are calculated in ROI of the material. DNN and fitting method perform lower RMSE, MAD, Bias and Std than the matching method. So their results are more accurate in image domain. Even though the decomposition accurcies of DNN are relatviely lower than fitting method, DNN achieves a competitive performance in image domain. DNN has the largest PSNR, which means that it produces reconstructed image with the best quality.
A list of quantitative evaluation on reconstructed images in simulation experiment
In order to further investigate the robustness of the proposed method, photon noise which is modeled as a Poisson process is introduced into the dual energy projections as follows:
where μ (70) is the attenuation coefficient of the material at 70 kV, c is the material coefficient.
Figure 9 shows the merged images under two photon noise levels. DNN and the matching method are more robust to the Poisson noise. However, some ring artifacts occur in the result of DNN. The fitting method suffers from serious streak artifacts.

The result of robustness test to Poisson noise. Reconstructed material coefficients under Poisson noises are merged into one image. Two different photon noise levels are tested in the experiment.
Table 6 lists the numerical comparison of reconstruction images under the condition of I L = 5 ×105 and I H = 5 ×105. The bias and standard deviation (STD) of fitting method become much greater in experiment with photon noise. So the fitting method is more sensitive to noise in projections, especially for material of water. DNN achieves the best results in the most evaluation metrics, indicating its high accuracies and image quality. All the methods have large MAD. This is due to the bad points in projections caused by the photon noise.
A list of reconstruction performance (with photon noise, I L = 5 ×105, I H = 1 ×106)
We used the same computing platform, compressing and decomposing net for the real phantom. The fitting method costs about 7 min to solve this 360 × 3200 decomposition problem, while DNN needs only 1.9 s. Figure 10 shows the results of decomposed projections. DNN and the fitting method results in varying degrees of noise in the aluminum image.
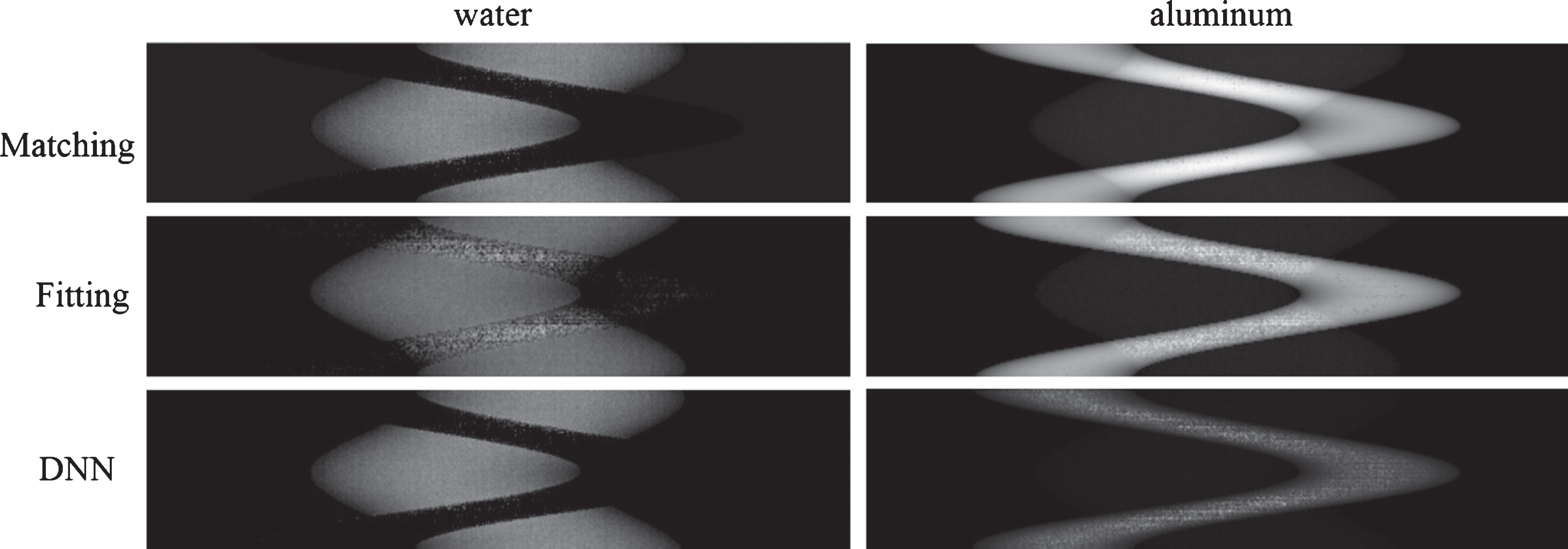
Results of the decomposed projections in real experiment. The size of decomposed projection in real experiment is 360 × 3200. The shape of each image is resized to a proper size for better display.
In the decomposition process, we found that it was difficult for the three methods to fit non-linear transform in the path with low thickness of material. This problem is reflected on the worse performance at the edges of water and aluminum shown in Fig. 11. The fitting method does relatively better at the contact position between two cyclineders. But there also obviously exists many noise points, especially the image of water. DNN generates similar reconstructed images with less noise as the matching method but dos not has the ring artifact caused by beam-harding effect.

Reconstruction results of real phantom. FBP is used to get the reconstructed images of QRM phantom. The reconstructed material coefficients are also merged into one image. The smaller cylinder is aluminum and the other is water.
Figure 12 plots the horizontal central profile of reconstructed images in Fig. 11. The true CT value of water is 0HU and aluminum is 2150HU. The results of DNN and matching method are close to each other, especially in water curve. The fitting method produces curves with greater fluctuation. This indicates that it is easily affected by photon fluctuation and scattring noise in imaging system. The mainly reason is that the noise may lead to the wrong solution of the fitting equation.
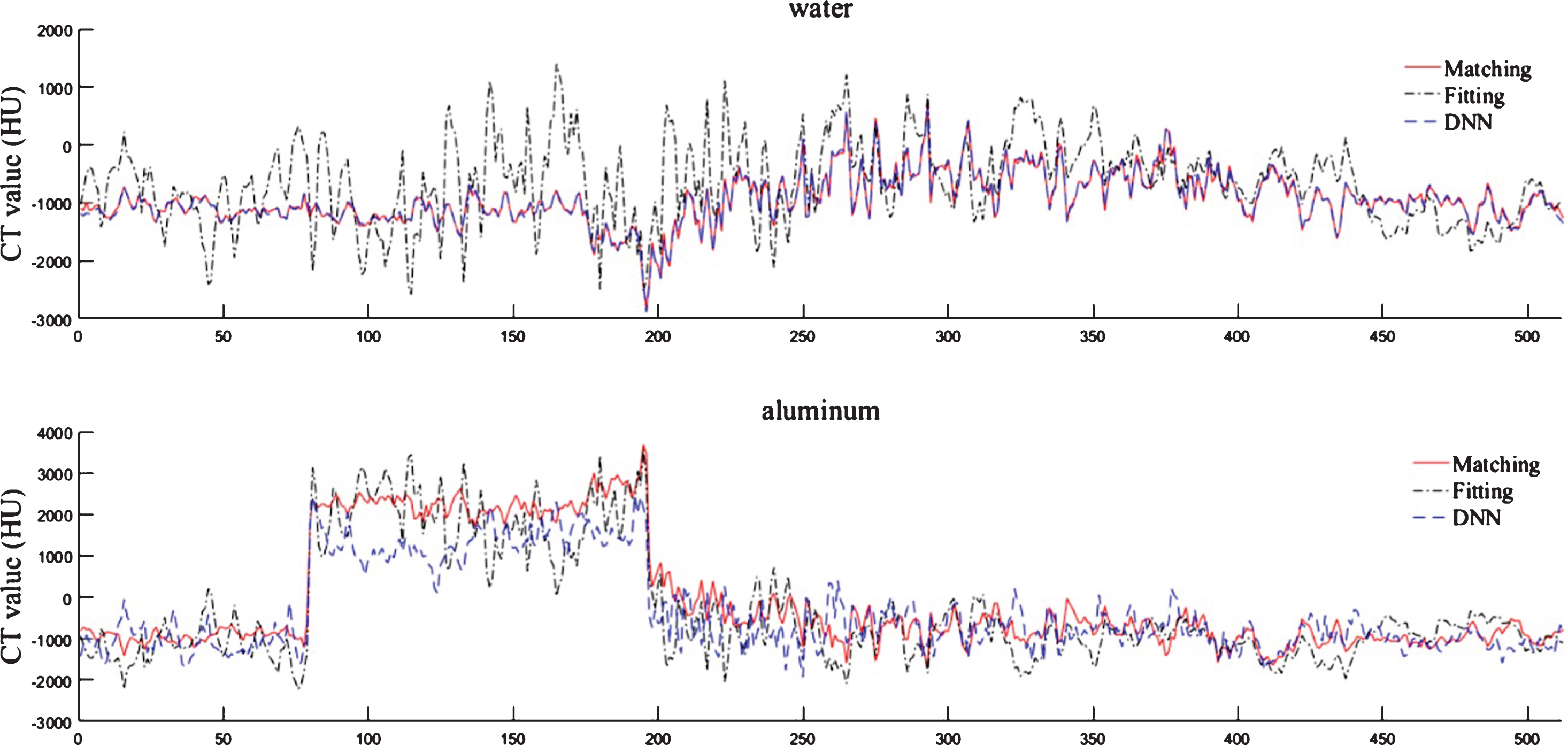
A comparison of central profile of reconstructed images. The Hounsfield unit (HU) values of reconstructed images are calculated. The figure draws the central profile in Fig. 9. The true CT value of water is 0HU and aluminum is 2150HU.
Quantitative evalution of performances on reconstructed images are summarized in Table 7. For the real phantom, we manually sketch out the water and aluminum region on the reconstructed images, to ensure that the metrics are also calculated in ROI. Because the lookup table confines the value of material coefficient to a certain range, the matching method would not give much worse output at some bad points, resulting its better MAD and RMSE. The fitting method has the largest MAD and standard deviation, indicating its sensitive to noises. DNN achieves moderate results and performs best on image quality. Generally, all the methods generate more accurate estimation of aluminum than water. For DNN, this is consistent with the results in the testing dataset, as shown in Fig. 7 (right).
A list of quantitative evaluation on reconstructed images in real experiment
The objective of this work is to develop and demonstrate a projection decomposition algorithm based on deep neural network. Two additional decomposition methods are implemented and compared with the proposed network. The experimental results have shown the characteristics of the three methods. For the matching method, the lookup table is a double-edged sword. Its advantage is making the method robust to the photon noise by confining the output value to a certain range and the disadvantages is decreasing the decomposition accuracies. The selection of lookup table needs to balance the precision and speed. Benefiting from the precisely solution of fitting equation, the fitting method achieves high accuracies in simulation and low bias in real experiment. However, it mainly suffers from the noise interferences and higher computational complexity.
The proposed network achieves a comparable performance with significantly fast speed. DNN performs better standard deviation and reconstructed image quality, especially in decomposition test with photon noise. The results in real experiment shown in Figs. 5 and 6 suggest that DNN behaves quit similar as the matching method. The calculation of decomposed images in both methods depends on the same lookup table. The value of parameters in DNN can be regard as a representation of the prior knowledge in lookup table. Compared to other decomposition algorithms based on neural network [13–15], the proposed algorithm introduces the energy spectrum into the modeling process. The network used in simulation and real experiments is the same one, which proves that it is applicable to different dual energies. The main drawback of DNN is the high bias, which is not consistent with the low bias results in [14]. We hypothesize that this is mainly caused by introduction of energy spectrums. Due to the unexplainable mechanism of deep neural network, it is difficult to understand how DNN works and how to improve the performance of current mode besides increasing more training data. Actually, even though we sampled more training data with low thickness of water or aluminum, the decomposing net still performed worse at the edge of phantom as shown in Fig. 5. In addition, selection of the hyper-parameter in the model is a matter of “trial and error”. Thus, it can be a very time-consuming process to choose the appropriate value of the parameter such as λ in Equation (4).
Conclusion and future work
We have developed a projection decomposition algorithm for dual-energy CT via deep neural network. The proposed network features significantly fast speed, low standard deviation and high image quality. It also need not be retrained in the case of different dual energy, thus has extensive application in comparison with other decomposition algorithms based on neural network.
We also recognize two directions of further work that could be done in the future. The first one is the increment learning or online learning of the decomposing net. The second one is the attempt of using convolutional neural network (CNN) to solve the material decomposition problem in image domain, since most current successes obtained by deep neural network in image processing field is contribute to CNN.
Footnotes
Acknowledgments
This work was supported by the national key research and development plan of China under grant 2017YFB1002502 and the National Natural Science Foundation of China (No.61601518 and No.61372172).