
Abstract
The total variation (TV) regularization has been widely used in statistically iterative cone-beam computed tomography (CBCT) reconstruction, showing ability to preserve object edges. However, the TV regularization can also produce staircase effect and tend to over-smooth the reconstructed images due to its piecewise constant assumption. In this study, we proposed to use the structure tensor total variation (STV) that penalizes the eigenvalues of the structure tensor for CBCT reconstruction. The STV penalty extends the TV penalty, with many important properties maintained such as convexity and rotation and translation invariance. The STV penalty utilizes gradient information more effectively and has a stronger ability to capture local image structural variation. The objective function was constructed with the penalized weighted least-square (PWLS) strategy and the gradient descent (GD) method was used to optimize the objective function. Besides, we investigated whether the norms involved in the STV penalty affected the reconstruction performance and found that the l1-norm gave the better performance than the l2-norm and l ∞-norm. We also examined performance of the STV penalties constructed using different kernel functions and found that the STV with the Gaussian kernel had the best performance, and the STVs with Uniform, Logistic, and Sigmoid kernels had similar performance to each other. We evaluated our reconstruction method with the STV penalty on computer simulated phantoms and physical phantoms. The results demonstrated that STV led to better reconstruction performance than TV, both visually and quantitatively. For the Catphan 600 physical phantom, the STV1 penalty was 175% and 623% better than the low-dose FDK and the high-dose FDK, and 14% better than the TV penalty at the matched noise level, according to the average contrast-to-noise ratio (CNR); while for the Compressed Sensing simulation phantom, the peak signal to noise ratio (PSNR) of reconstructed results using STV1, STV2, and STV ∞ were 40.67 dB, 38.72 dB, and 37.40 dB, respectively, all being significantly better than 36.84 dB using TV.
Introduction
Cone-beam computed tomography (CBCT) has already been increasingly used in image guided radiation therapy [1] to obtain patients’ updated anatomy at the treatment position. However, overuse of the CBCT imaging during a course of radiotherapy treatment may bring excessive X-ray radiation to patients [2, 3]. Using lower mAs scan protocols in CBCT projection is a widely used method to reduce the radiation dose [4]. However, it degrades the quality of the reconstruction image [5, 6] because of the increasing noise level. Low dose CBCT reconstruction with better image quality is highly desired in the clinic.
CBCT image reconstruction algorithms include analytic reconstruction methods and iterative reconstruction methods. In the development of the analytical algorithms, Tuy first proposed a practical cone-beam inverse transformation formula, which established the mathematical connections between the projection data and the reconstructed image [7]. Feldkamp et al. proposed the FDK algorithm to approximate the three-dimensional image reconstruction in 1984 [8]. In 1991, Grangeat proposed the Grangeat reconstruction algorithm based on the circular scan trajectory [9]. In 2001, Katsevich proposed a reconstruction algorithm that was easy to implement based on the helical scan trajectory [10]. Among them, the FDK algorithm has been the mainstream in practical applications. This algorithm is simple and computationally efficient, but vulnerable to noise and easy to produce artifacts.
Iterative reconstruction methods include non-statistical iterative reconstruction methods and statistical iterative reconstruction (SIR) methods. Non-statistical iterative methods, such as the algebraic reconstruction technique (ART) [11], achieves image reconstruction by solving a system of linear equations, which can give fairly accurate solutions once these equations are compatible. However, in practice, because of the existence of noise, these equations are always not compatible, so the solutions obtained by such method are rather unstable.
In statistical iterative algorithms, the objective functions are constructed using noise statistical characteristics and the prior knowledge, based on the Bayesian theory [12]. An objective function includes a term that is called the penalty term reflecting the prior constraint on the solutions. The penalty term affects the quality of the reconstruction results greatly. Some commonly used penalty terms are the isotropic quadratic penalty [13], Huber penalty [14], total variation (TV) penalty [15, 16], and so on. SIR algorithms based on the prior information have been widely utilized for low-dose CBCT imaging [17, 18]. The quality of the obtained image by SIR is generally superior to that of the FDK method, with much less artifacts and lower noise.
The TV penalty has great popularity in various image-related inverse problem, thanks to its great performance in both suppressing noise and preserving edges. However, the TV regularization sometimes produces the staircase effect and tend to over-smooth the image due to its piecewise constant assumption [19, 20]. To avoid the staircase effect, several penalties have been proposed, such as ATV [21], TGV [22], NLTV [23], and Hessian [24, 25].
In this article, we introduced the structure tensor total variation (STV) that penalizes the eigenvalues of the structure tensor into the objective function to utilize the gradient information more effectively for CBCT reconstruction. The STV penalty extends the TV penalty, with many important properties maintained like convexity and rotation and translation invariance [26]. The STV penalty has a stronger ability in capturing the structural variation among local areas, leading to reconstruction of a high quality. We constructed the objective function with the penalized weighted least-square (PWLS) and employed the gradient descent (GD) method for the associated optimization problem. We evaluated the proposed statistical reconstruction method with the STV penalty on computer simulated phantoms and physical phantoms. The results demonstrated the outstanding ability of the STV penalty over the TV penalty.
Mathemtical models
PWLS Image Reconstruction
Assuming that the incident photon number of the X-ray is I o , and the detected photon number is I d . According to the Beer law [2], we can get the relation between the incident and detected photon number:
Taking a logarithm transform over (4) and using the maximum a posteriori estimate, we can get the objective function for CBCT reconstruction [4]:
The structure tensor [26], the most common tensor, is defined as the spatial average of the outer product of the gradient with itself at point x of the image (the attenuation coefficients) u:
Gaussian kernel:
Logistic Kernel:
Let λ
i
be the eigenvalues of the structure tensor S
g
u (
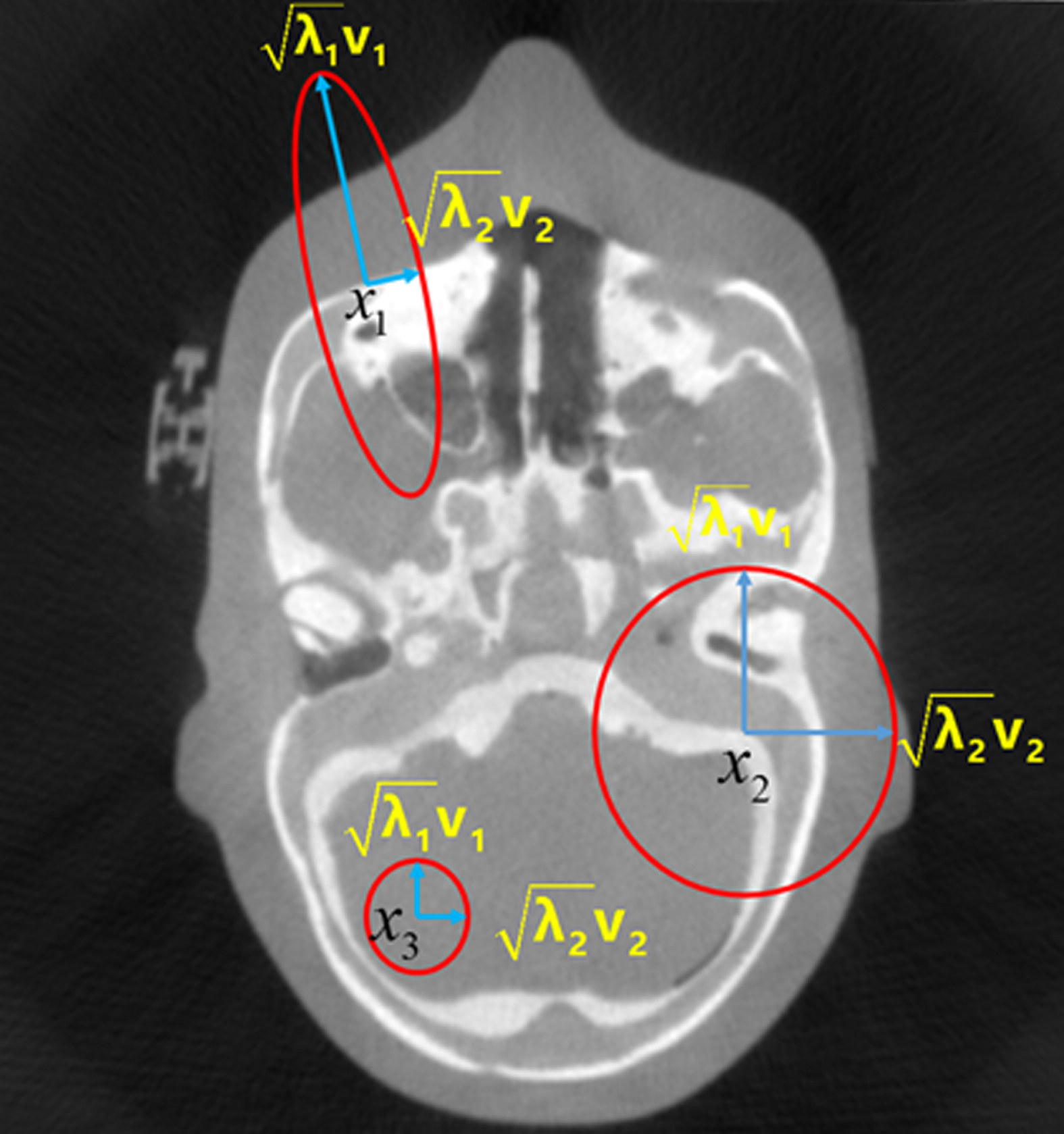
Structure Tensor.
For a given point x in the image, when both the eigenvalues λ1 and λ2 of the structure tensor are small, the intensity change in any direction near this point is small. In other words, the local neighborhood centered on x tends to be smooth. When λ1 is large and λ2 is small, the image intensity in the local neighborhood varies greatly in one direction, indicating the existence of obvious edge structure characteristics. When both λ1 and λ2 are large, the image intensity changes quickly in all directions, suggesting that the current point is an image corner.
The TV penalty [27] has demonstrated state-of-the-art performance in preserving edges of the reconstructed image, and is defined as:
In this study, to design regularization terms that integrate the local image intensity variation around each pixel, we constructed penalties using a combination of eigenvalues of the structure tensor, as follows [26]:
The STV generalizes several existing image regularization methods. Specifically, noting that when g (x) is the Dirac delta δ (x), all the penalties with different orders are equal to TV. The STV provides more robust and coherent measures of an image than TV, as these measures include the intensity variations in all directions over the local neighborhood. In this way, STV is in general more suitable for describing the local image geometry and leads to better results in CBCT reconstruction.
It was shown that the STV penalties maintain many favorable properties of TV, i.e. translation and rotation invariant, 1-homogeneous, and convex [26].
The difficulty in the calculation of the projection matrix A is that it is too enormous to store. So, a proper algorithm to calculate A effectively is essential. The Siddon’s algorithm [28] is widely used to calculate the projection matrix A for its simplicity in calculation. In this work we adopted the separable footprint (SF) [29] algorithm to calculate matrix A, which is faster than the Siddon’s algorithm. We calculated the entries of the matrix A whenever we need it rather than storing it.
Minimization of objective function
Objective Function in CBCT Reconstruction
Employing the STV penalties (8) in the objective function (5), we can obtain:
Hence, the CBCT reconstruction becomes a minimization problem of the objective function (9) and we tested three cases with p = 1, 2, ∞ in this study.
Lefkimmiatis et al. used the STV penalty for nature image denoising and deblur, and proposed to optimize the corresponding objective function through a patch-based Jacobian operator [26]. The optimization algorithm they employed combined the majorization-minmization (MM) [30] method, MFISTA [31] method and primal-dual [32] method.
We note that the algorithm used by Lefkimmiatis et al. in [26] is computationally expensive for CBCT reconstruction in practice. To optimize the objective function (9) with a simpler and faster method, we intended to calculate its gradient firstly. The most intractable part in the gradient calculation of the objective function (9) came from the STV penalty. Consider the following functional:
Applying (11) to CBCT reconstruction, we could calculate the gradient of the objective function (9) as follows:
Case 1. For p = 1, i.e.
Case 2. For p = 2, i.e.
Case 3. For p =∞, i.e.
Given the gradient in Equation (12), we could optimize the objective functional (9) with the gradient descent (GD) method directly. Our proposed algorithm for CBCT reconstruction using STV are summarized as follows.
Algorithm: CBCT Reconstruction Using STV
For the convenience of the readers, we summarize the notations used in the Algorithm below.
y: projection data;
A: projection (system) matrix;
τ: positive regularization parameter (τ > 0);
Σ: diagonal noise covariance matrix;
g: kernel with a specific size and shape;
α: step length determined by backtracking one-dimensional search method;
M: maximum iteration number.
Note that we took the FDK reconstruction to initialize u, namely, u0 = FDK(y).
We evaluated our methods on two simulated phantoms and two physical phantoms. For CBCT reconstruction, the regularization parameter τ in Equation (5) always plays a role to balance the image resolution and noise level. To have a reasonable comparison of the performance of different penalties, we adjusted this parameter for each phantom to keep all the reconstruction results to have a similar noise level [24, 34].
Simulated Phantom
The two computer simulation phantoms were the Compressed Sensing (CS) phantom and a modified Shepp-Logan phantom, respectively. Figure 2(a) and Fig. 4(a) show one representative slice of the CS phantom and the Shepp-Logan phantom, respectively. The CS phantom has 350×350×16 pixels, and the physical size of each pixel is 0.776×0.776×0.776 mm3. The projection of the CS phantom covers 360 angles, with each angle having 800×200 pixels. The Shepp-Logan phantom has 350×350×16 pixels, and the voxel size is 0.776×0.776×0.776 mm3. The projection of Shepp-Logan phantom covers 360 angles and have 500×500 pixels for each angle. The source-to-axial distance is 100 cm and the source-to-detector is 150 cm for both CS phantom and Sheep-Logan phantom. Note that most of commercial CBCT systems for image-guided radiation therapy use such a geometry design. For each phantom, the incident photon number in (3) was set to be 1×104 to simulate the low dose case and the Gaussian noise according to the model (3) was added to the projection data.

A representative slice of the CS phantom using different penalties.
SSIM map of the CS phantom using different penalties.

A representative slice of the Shepp-Logan phantom using different penalties.
The commercial calibration phantom CatPhan 600 (The Phantom Laboratory, Inc., Salem, NY) and the anthropomorphic head phantom were tested in our experiment, respectively. Figure 6(a) and Fig. 7(b) demonstrate one typical slice of the CatPhan 600 phantom and the anthropomorphic head phantom, respectively. The CatPhan 600 phantom covers 350×350×16 pixels, with each pixel having a physical size of 0.776×0.776×0.776 mm3. The projection of the CatPhan 600 phantom covers 634 angles and each angle has 1024×768 pixels. The anthropomorphic head phantom covers 550×550×32 pixels, and each pixel has a physical size of 0.338×0.338×0.338 mm3. The projection of the anthropomorphic head phantom has 1024×768 pixels and covers 678 angles. The source-to-axial distance is 100 cm and the source-to-detector distance is 150 cm for both phantoms. For each phantom, the tube voltage was 125 kVp and the tube current was 10 mA (low dose) and 80 mA (high dose), respectively, lasting for 10 ms at each projection scan.

Profiles through the ellipsoid object in Figure 4(a).

A representative slice of the Catphan 600 phantom using different penalties.

A representative slice of the head phantom using different penalties.
In this study, we adopted the peak signal to noise ratio (PSNR), the improvement signal to noise ratio (ISNR), the contrast-to-noise ratio (CNR), and the structural similarity (SSIM) indexes for evaluation [24].
PSNR is defined as
ISNR is defined as
CNR is defined as
SSIM is defined as
CS Phantom
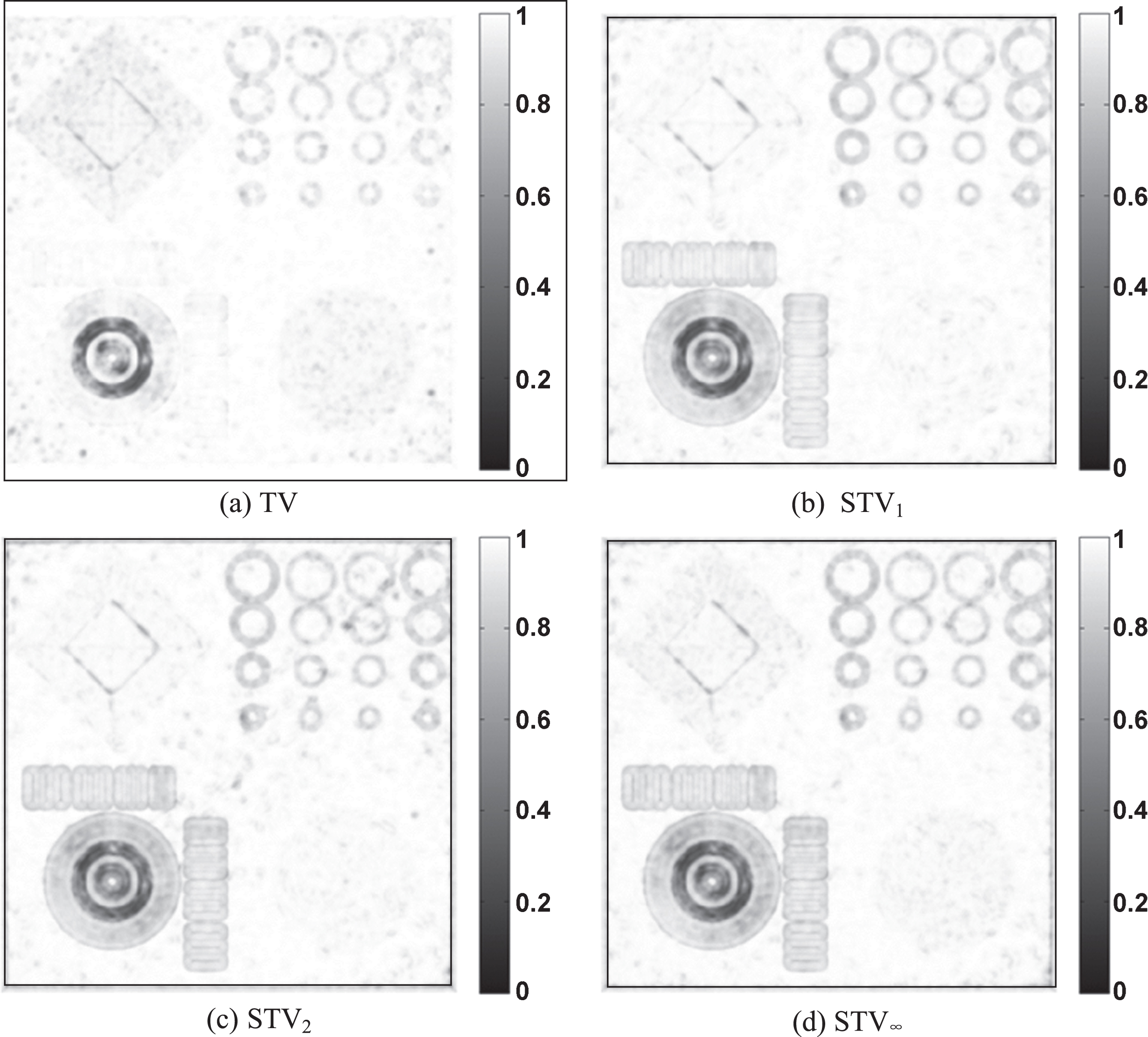
Figure 2 shows a typical slice of the images of the CS phantom reconstructed by different penalties. Figure 2(a) shows the original image, and Fig. 2(b) shows the FDK reconstruction image. Figure 2(c-f) show the reconstruction images by the TV penalty, the STV1 penalty (p = 1), the STV2 penalty (p = 2), and the STV ∞ penalty (p =∞), respectively. The smaller red rectangle in Fig. 2(a) denotes the ROI, enlarged and displayed in the lower right corner of Fig. 2(a) (same for Figs. 2(b-f)). Figure 2 indicates that the reconstruction images using the TV penalty produced piecewise-constant regions obviously, while all the three STV penalties could avoid the staircase effect effectively.
Table 1 lists the values of PSNR, ISNR, mean SSIM (the average SSIM values) of the ROI in Fig. 1(a) with different penalties. The quality of the reconstruction results by the three STV penalties were better than TV according to these three indexes. Among the three STV penalties, the STV1 had the best evaluation indexes.
The evaluation indexes of the reconstruction of CS phantom using different penalties
The evaluation indexes of the reconstruction of CS phantom using different penalties
Figure 3 shows the SSIM map of the reconstructed image using different penalties over the original image. In the octahedral region (the upper left part), the reconstruction images by the STV penalties have higher SSIM values (whiter) than that those of the TV penalty, indicating a better preserving of regions with smooth intensity transition. However, at the barcode areas (the lower left part), the TV penalty had higher SSIM values, indicating a better ability in preserving sharp edges.
Table 2 lists the values of PSNR, ISNR, mean SSIM of the ROI in Fig. 1(a) using the STV1 penalty with different Gaussian kernels. As we can see, the reconstructed performance of the STV penalty varied with the size and shape of the used kernel. A too sharp kernel leaded a low reconstruction quality such as those in Table 2 with variance 0.5 and 1, respectively. In Table 2, the Gaussian kernel with size 7×7 and variance 2 had the best performance.
The evaluation indexes of the reconstruction of CS phantom using STV1 with different Gaussian kernels
It is also interesting to see how other types of kernels other than Gaussian kernels perform in CBCT reconstruction when using STV penalties. For comparison, we also used the Uniform kernel, the Logistic kernel, and the Sigmoid kernel to construct the STV1 penalty.
Table 3 lists the values of PSNR, ISNR, mean SSIM of the ROI in Fig. 1(a) using STV1 penalties with different types of kernels, all with size 7×7. As we can see, the Gaussian kernel (with variance 2) had the best performance, while the other three types of kernels had similar performance (but all were worse than Gaussian). If not specified, we used Gaussian kernel to construct the STV penalties elsewhere for experiments in this study.
The evaluation indexes of the reconstruction of CS phantom using STV1 with different kernels
Figure 4 displays a typical slice of the reconstructed images by different penalties for the modified Shepp-Logan phantom. Figure 4(a) displays the original image, and Fig. 4(b) displays the FDK reconstruction image. Figure 4(c-f) displays the reconstruction image by the TV penalty, the STV1 penalty, the STV2 penalty and the STV ∞ penalty, respectively. The smaller blue rectangle in Fig. 4(a) denotes the ROI, enlarged and displayed in the lower right corner of Fig. 4(a) (same for Figs. 4(b-f)). Figure 4 indicates that the reconstruction images using the STV penalties are all smoother than the reconstruction image using the TV penalty. Note that TV leaded to significant staircase effect.
Figure 5 shows the intensity profiles along the red line (shown in Fig. 4(a)) through the ellipsoid of the reconstruction images. These profiles show that the reconstruction image using the TV penalty produced piecewise-constant regions, while the reconstructed images using the STV penalties were smoother than the TV result.
Catphan 600 Phantom
Figure 6 shows a slice of the reconstruction results obtained by different penalties for the Catphan 600 phantom. Figure 6(a) shows the reconstruction image by FDK with a high-dose protocol (80 mA/10 ms). Figure 6(b) shows the reconstruction image by FDK with a low-dose protocol (10 mA/10 ms). Figure 6(c-f) shows the low-dose reconstruction image by the TV penalty, the STV1 penalty, the STV2 penalty, and the STV ∞ penalty, respectively. The white rectangle in Fig. 6(a) denotes the region to be used to calculate noise level. Figure 6 indicates that the reconstruction images using the TV and STV penalties all have a good ability in suppressing noise.
Furthermore, we chose four ROIs indicated by arrows in Fig. 6(a) to calculate CNR for a quantitative comparison. Table 4 listed the CNR of the four different regions with different penalties for low-dose reconstruction. As we can see, in most cases the STV results have higher CNR values than those from the TV results and both the high-dose and low-dose FDK results, indicating that the STV penalties had a good ability in preserving the contrast of the objects. At the same time, the STV1 penalty has higher CNR values than those of the STV2 and STV ∞ penalties. Particularly, when averaged on the four ROIs, the improvement of the CNR of the STV1 penalty over the TV penalty, the low-dose FDK and the high-dose FDK is 14%, 175%, and 623%, respectively.
CNRs of different ROIs in Fig. 4(a)
CNRs of different ROIs in Fig. 4(a)
Figure 7 shows a slice of the reconstruction results obtained by different penalties for the head phantom. Figure 7(a) and (b) display the reconstruction images by FDK with the high-dose protocol (80 mA/10 ms), and the low-dose protocol (10 mA/10 ms), respectively. Figure 7(c-f) display the low-dose reconstruction image by the TV penalty, the STV1 penalty, the STV2 penalty, and by the STV ∞ penalty, respectively. The blue rectangle in Fig. 7(a) denotes the region to be used to calculate the noise level.
The ROI is indicated by the red rectangle in Fig. 7(a) to calculate SSIM. We can see in Fig. 8 that the mean SSIM of those STV penalties are higher than that of the TV penalty, indicating that the STV penalties have a better ability in preserving regions with gradual intensity transitions than the TV penalty. The STV1 penalty had the best mean SSIM of the reconstructions result.

SSIM maps of the Anthropomorphic head phantom using different penalties.
In the study, we proposed to use the STV penalty for statistical iterative CBCT reconstruction based on the PWLS criteria. Experimental results suggested that the STV penalty can significantly suppress the staircase effect, and had better reconstruction performance than the TV penalty. Among the orders 1, 2 and ∞, the STV1 penalty constructed using norm with order 1 (i.e., the l1-norm) had the best reconstruction quality. In addition, we examined the performance of STV penalties constructed using different kernel functions and found that the STV with the Gaussian kernel had the best performance, and the STVs with the Uniform kernel, the Logistic kernel, and the Sigmoid kernel had worse performance.
Compared with the TV penalty, the key characteristic of the STV penalty is that the involved structure tensor is able to encode richer image structural information over a local neighborhood. With this richer information combined in the objective function, imaging noises and artifacts can be better removed and more image textures and features can be preserved.
To construct the STV penalty, we selected the first order structure tensors that utilize the first order gradient image information in this study. The STV penalty constructed using higher structure tensors might provide better performance for CBCT reconstruction, particularly for image regions with gradual intensity transition. This will be our future research topic. The gradient descent (GD) was used for the associated optimization problem for its simplicity in this study. More efficient optimization procedures as well as the GPU implementation can be contemplated to improve the computational speed for clinical applications in the future.
Footnotes
Acknowledgments
This work was supported in part by National Natural Science Foundation of China (NNSFC), under Grant Nos. 61375018 and 61672253. J. Wang was supported in part by grants from the Cancer Prevention and Research Institute of Texas (RP160661) and the National Institute of Biomedical Imaging and Bioengineering (R01 EB020366).