
Abstract
In computed tomography (CT), the total variation (TV) constrained algebraic reconstruction technique (ART) can obtain better reconstruction quality when the projection data are sparse and noisy. However, the ART-TV algorithm remains time-consuming since it requires large numbers of iterations, especially for the reconstruction of high-resolution images. In this work, we propose a fast algorithm to calculate the system matrix for line intersection model and apply this algorithm to perform the forward-projection and back-projection operations of the ART. Then, we utilize the parallel computing techniques of multithreading and graphics processing units (GPU) to accelerate the ART iteration and the TV minimization, respectively. Numerical experiments show that our proposed parallel implementation approach is very efficient and accurate. For the reconstruction of a 2048 × 2048 image from 180 projection views of 2048 detector bins, it takes about 2.2 seconds to perform one iteration of the ART-TV algorithm using our proposed approach on a ten-core platform. Experimental results demonstrate that our new approach achieves a speedup of 23 times over the conventional single-threaded CPU implementation that using the Siddon algorithm.
Keywords
Introduction
Computed Tomography (CT) has been widely used in various fields, such as medical diagnosis, non-destructive testing and reverse engineering [1–6]. In general, the reconstruction algorithms of CT can be divided into two main categories: analytical algorithms and iterative algorithms. The analytical algorithms, such as the filtered back-projection (FBP) [7] and the FDK algorithms [8], are applied for the reconstruction from sufficient projection data. For insufficient or noisy projection data, however, the iterative algorithms have shown great potential in achieving better reconstruction quality. The disadvantage of iterative algorithms is their slow reconstruction speed. With the improvement of the computer performance and the emergence of new parallel computing techniques, the iterative algorithms have attracted far more attention over the past decades. Among those iterative algorithms, the algebraic reconstruction technique (ART), proposed by Gordon et al. [9], was the first algorithm applied in real CT system. Even today, the ART algorithm has been widely applied to solving the tomographic imaging problem of insufficient projection data. During the iteration of ART, the pixels are corrected ray by ray, such correction may cause striping artifacts. To overcome this problem, Andersen et al. [10] developed the simultaneous ART (SART) algorithm to suppress those artifacts. As a major refinement of ART, the SART algorithm can be effectively accelerated due to its intrinsic parallelism [11, 12].
The reconstruction quality of ART is usually better than that of the analytical methods when the required sufficient projection data are not available. However, for sparse-view CT reconstruction, the reconstruction results are usually not satisfactory even if we increase the number of iterations. Total variation (TV) minimization has been extensively utilized in image denoising and proven to be capable of preserving edge information [13–15]. In recent years, TV constrained method has been used in tomographic imaging for solving the sparse-view reconstruction problem. Sidky et al. [16] developed a total variation algorithm for accurate image reconstruction in fan-beam CT under a number of imperfect sampling situations. This algorithm consists of two phases: projection on convex sets (POCS) and minimization of the image TV. They pointed out that the ART algorithm is identical to their proposed TV algorithm except that the second phase is not performed. Zhang et al. [17] combined the ART algorithm and TV constraint (ART-TV) to improve the accuracy and robustness of the diffuse correlation tomography, in which the TV model is used to reduce the noise after each ART iteration. They claimed their approach can improve the overall quality of the reconstructed images. Huang et al. [18] proposed an improved ART-TV method, in which the priori-knowledge of north-south symmetry was incorporated into the reconstruction procedure. They used this method to reconstruct plasmaspheric He+ global density distribution from the two-dimensional simulated extreme ultraviolet images. Compared with the conventional method, the improved ART-TV method can effectively reconstruct images from imperfect projection data. To obtain high-quality CT images, Lin et al. [19] incorporated the prior values of CT scanning to the ART-TV iterative procedure and proposed an improved reconstruction algorithm named ART-TV-PI. They found both the mean square error and the radiation dose of the ART-TV-PI algorithm were significantly lower than those of the ART-TV algorithm.
Most of the ART-TV algorithms were studied and applied for two-dimensional reconstruction. Ertas et al. [20] investigated the performance of ART-TV2D and ART-TV3D in reconstructing a 3D phantom. For TV2D, the TV constraint was utilized for each slice independently. While for TV3D, the TV constraint was utilized considering all slices. Their research shows that the ART-TV3D performs better than ART-TV2D, and much better than ART algorithm. Later, they extended the ART algorithm by using non-local means and total variation for artifacts reduction. They found that better reconstructions can be obtained compared with conventional ART-TV algorithm [21].
To date, most researchers have paid more attention to the reconstruction quality of ART-TV. In practice, however, the reconstruction speed is still a problem, particularly for high-resolution or 3D images reconstruction. In the reconstruction procedure of ART, forward-projection and back-projection are two major operations, which depend on the chosen system model. One of the simplest system models is the line intersection model (LIM). Other system models, such as the distance-driven model and area (volume) integral model [22–26], take the finite size of the detector bins into account and could achieve better reconstruction quality. However, such models are more complicated and time-consuming than LIM in calculating the system matrix. For LIM-based ART, the classical Siddon algorithm is commonly used to calculate the corresponding system matrix [27]. Although it has been further improved [28, 29], the reconstruction speed of ART that using the Siddon algorithm remains unsatisfactory.
In this paper, we propose a fast algorithm to calculate the system matrix for line intersection model. On this basis, we use multi-core and graphics processing units (GPU) parallel computing techniques to accelerate the ART-TV algorithm. The rest of the paper is organized as follows. Section 2 introduces the TV constrained ART algorithm, then presents our algorithm as well as its parallel implementation for ART-TV. Section 3 gives numerical experiment results to evaluate the proposed method. Section 4 concludes the paper.
Methods
TV constrained ART algorithm
In this study, we focus on the reconstruction of the two-dimensional case. The CT reconstruction problem can be formulated as a linear equation system
To improve the reconstruction quality of ART from sparse-view projections, the TV constraint is usually incorporated into its reconstruction procedure. Thus, the reconstruction algorithm of TV constrained ART can be formulated as follows:
where ɛ is a small positive number.
The above two steps are implemented alternately until the termination condition is satisfied. Obviously, to improve the reconstruction speed of ART-TV algorithm, we should try to accelerate both the ART iteration and the TV minimization. Since the system matrix plays a crucial role during the iterative procedure of ART, we will firstly propose a fast algorithm to calculate the system matrix. Then we utilize the parallel computing technique to further accelerate the two steps. To perform the forward-projection and back-projection operations, we use two arrays, a and b, to store the pixel indices and their corresponding intersection lengths. In addition, the total number of elements is recorded into a variable n1.
The image f to be reconstructed can be represented by a square grid (i.e., reconstruction region), which consists of N = n×n pixels. Let f j be the image value of the jth pixel, where j is the pixel index, 0≤j < N. The ray SE is considered as a line segment connecting the X-ray focal spot S(x S , y S ) and the center E(x E , y E ) of a detection bin, as shown in Fig. 1. The equation of the ray SE can be written as g(x, y) = Ax + By + C = 0, where A = y E −y S , B = x S −x E , and C = y S ×x E −x S ×y E .

Reconstruction region and the arrangement of the image pixels.
First, we should determine whether the ray passes through the square grid. Obviously, when a ray passes through the reconstruction region, it will intersect with at least one of the two diagonals of the square grid, as shown by the dashed line in Fig. 1. For example, suppose SE intersects with diagonal PD, then the vertex P and D will lie on the two sides of SE respectively. In this case, we have g(−q, q)×g(q, −q) < 0. Likewise, if g(−q, −q)×g(q, q) < 0, then the ray intersects with the other diagonal.
When the ray SE passes through the reconstruction region, we need to determine the two intersection points of the ray with the sides of the square region and calculate their coordinates and pixel indices. Let L and R be the left and right intersection point, whose pixel indices are n L and n R , respectively. Let (x L , y L ) and (x R , y R ) denote their coordinates, here we suppose x L ≤ x R . If x E = x S , then the ray is perpendicular to the horizontal axis, and it will pass through n pixels. The pixel index n L within the first row can be calculated by n L =⌊(x L + q)/δ⌋. The pixel indices of other rows can be obtained by adding a constant integer n to n L in turn. The intersection lengths of all these pixels are δ. Let k denote the slope of the ray SE. If x E ≠ x S , then k = (y E − y S ) / (x E − x S ). Let y L denote the y-coordinate of the intersection point of SE with line x =−q, where y L = (A×q−C)/B. If |y L | < q, then point L intersects with the left side of the reconstruction region, where x L =−q, y L = y L , and n L = n×⌊(q− y L )/δ⌋. If y L > q, then point L intersects with the top side of the reconstruction region, where x L =−(B×q + C)/A, y L = q, and n L =⌊(x L + q)/δ⌋. If y L < -q, then point L intersects with the bottom side of the reconstruction region, where x L = (B×q−C)/A, y L =−q, and n L =⌊(x L + q)/δ⌋+ n×(n−1). The coordinates (x R , y R ) of point R, as well as its corresponding pixel index n R can be calculated in the same way as point L.
Without loss of generality, we consider the case of 0≤k≤1 in the following discussion. After calculating the intersection information of points L and R, we begin to calculate the pixel indices and the corresponding intersection lengths of those pixels that intersect with the ray SE. For ease of calculation, we denote the total length intercepted by a column as l
x
, and that intercepted by a row as l
y
, where
Next, we consider that the ray SE passes through only one row. If ⌊y L /δ⌋=⌊y R /δ⌋, then SE intersects with only one row. Let u and l denote the index and intersection length of the first pixel in a row, respectively. If point L is on the bottom side of the reconstruction region, then the intersection length l of pixel n L may be equal to l x , or less than l x , as shown in Fig. 2.
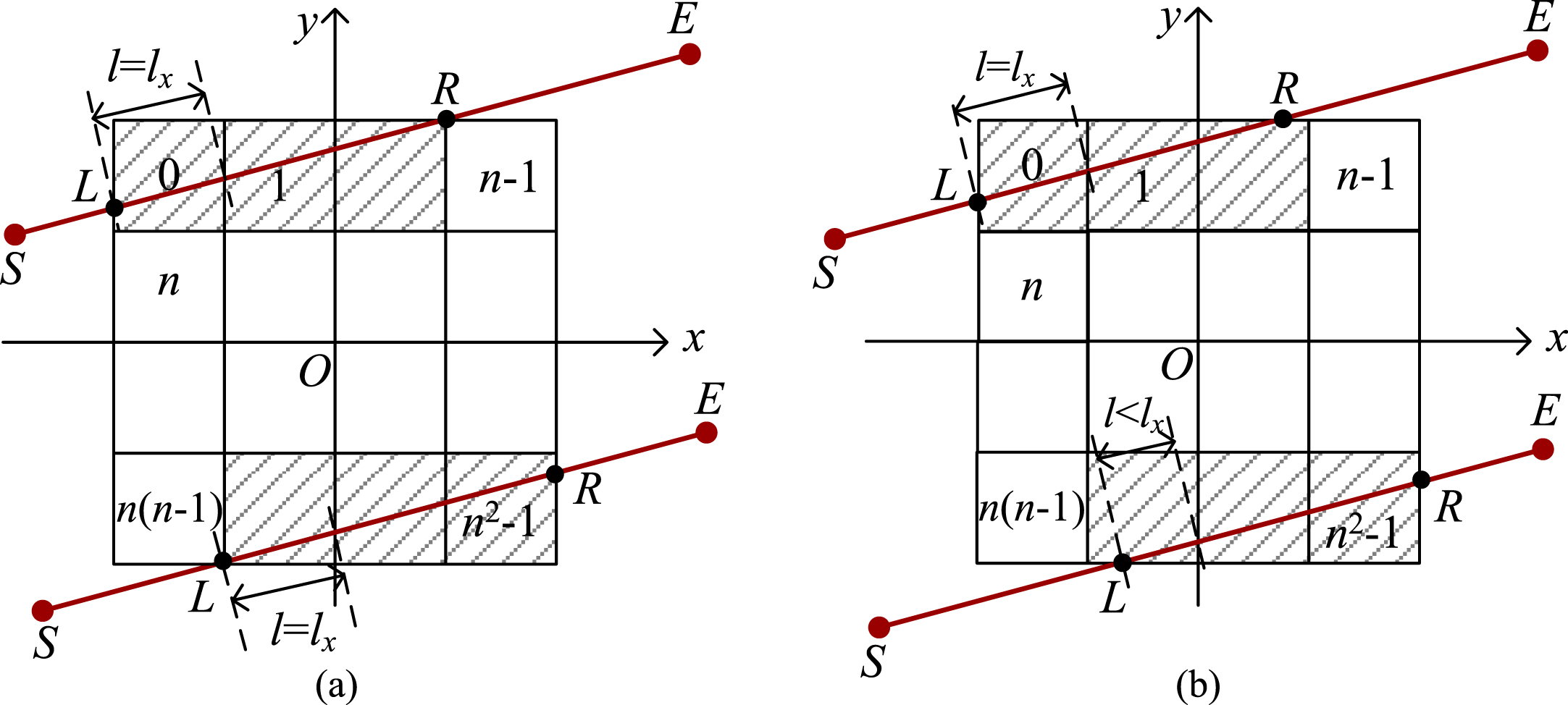
The ray passes through only one row. (a) shows the intersection lengths of the pixels are equal to l x . (b) shows the intersection length of the last pixel of the upper ray and that of the first pixel of the lower ray are less than l x .
For 0≤k ≤1, we have l = l x − (x L /δ -⌊x L /δ⌋)×l x . Then, for other pixels intersecting with SE in the same row, their pixel indices and intersection lengths can be easily calculated. If point R is on the top side of the reconstruction region, we can refer to the calculation of point L. To determine when to stop our algorithm, we define a remainder length denoted by l r . Once we have stored the intersection length of one or more pixels, the remainder length will be updated by subtracting the stored length. For this purpose, we calculate the length l0 from point R to point L and initialize l r to the value of l0. The pseudocode of the ray SE (0≤k≤1) passing through only one row is presented in Algorithm 1.
If ⌊y L /δ⌋ ≠ ⌊y R /δ⌋, the ray will pass through several rows of the square grid. We first determine the principal direction of SE according to its slope k. If |k|,> 1, then the principal direction is along the x-axis, otherwise, it is along the y-axis. For the case of 0≤k ≤1, the pixels are processed row by row. Let N y denote the maximum number of pixels whose intersection length is l x within the same row, and r y denote the remainder length except these N y pixels, where N y =⌊l y /l x ⌋, r y = l y − N y ×l x . When SE passes through a row, there are usually the following cases, as shown in Fig. 3.
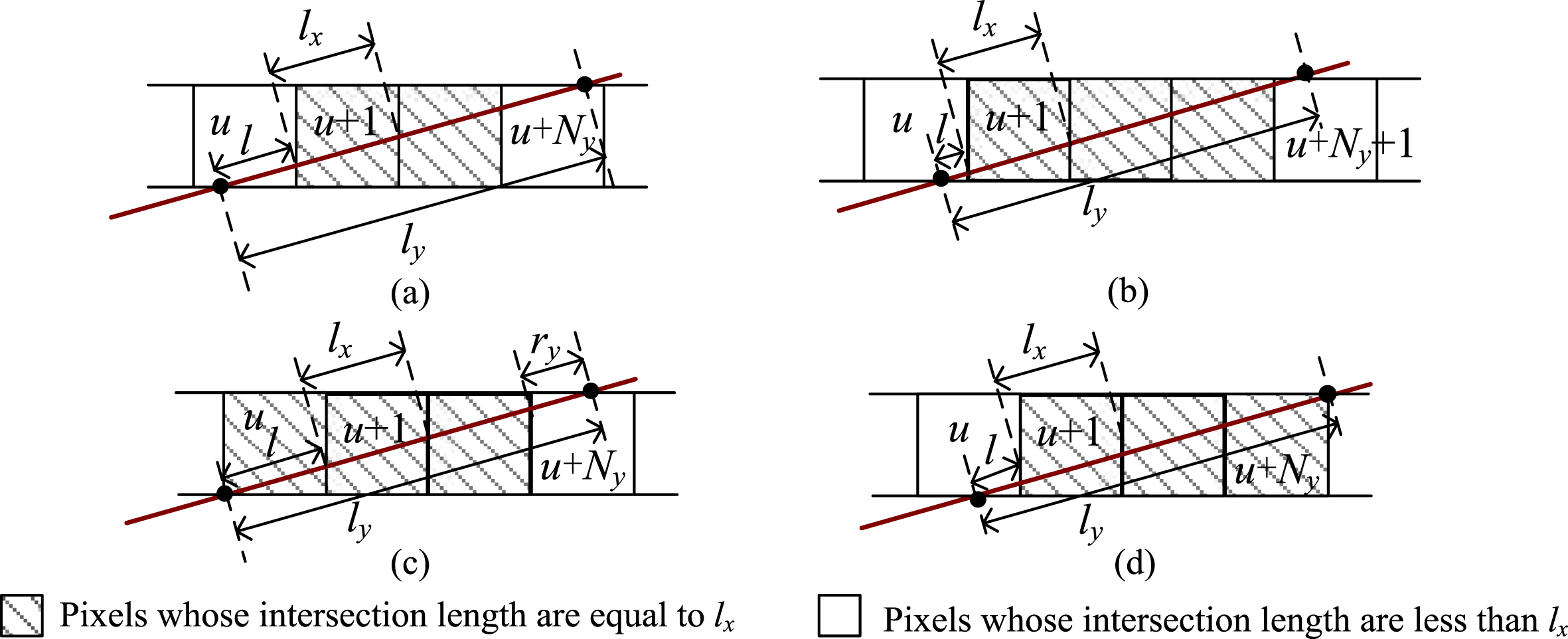
Different cases for the ray passing through a row. (a) shows the ray passes through N y + 1 pixels, where r y < l < l x . (b) shows the ray passes through N y + 2 pixels, where 0 < l < r y . (c) shows the ray passes through N y + 1 pixels, where l = l x . (d) shows the ray passes through N y + 1 pixels, where l = r y .
If r y < l < l x , as Fig. 3(a) shows, then the ray SE will pass through N y + 1 pixels. The index of the last pixel in the row is u + N y , whose intersection length is r y + l x −l. The intersection length of those pixels between u and u + N y are l x . If 0 < l < r y , as Fig. 3(b) shows, then the ray SE will pass through N y + 2 pixels. The index of the last pixel in the row is u + N y + 1, whose intersection length is r y −l. The intersection length of those pixels between u and u + N y + 1 are l x . If l = l x or l = r y , as Fig. 3(c) and 3(d) shows, then the ray SE will pass through N y + 1 pixels. If r y ≠ 0, the ray SE will pass through N y + 1 pixels and intersect with either the lower left vertex of the first pixel, or the upper right vertex of the last pixel. The pixel index of the last pixel in the row is u + N y . If r y = 0, then SE will pass through N y pixels and intersect with both the lower left vertex of pixel u and the upper right vertex of pixel u + N y −1. The intersection lengths of those pixels from u to u + N y −1 are l x .
According to the index and the intersection length of the last pixel, we can easily determine the intersection information of the first pixel of the next row to be processed. Hence, the above procedure will be repeated until l r is equal to zero. The pseudocode of the proposed algorithm for a given ray SE (0≤k≤1) passing through several rows is presented in Algorithm 2.
As mentioned above, the performance of ART-TV algorithm includes two steps: ART iteration and TV minimization. For ART, the iterative procedures are implemented in a particular sequence of projection views. Therefore, it is not appropriate for parallel implementation in general. However, for a given projection view, the reconstruction could be implemented in parallel providing that none of the pixels is updated by two or more rays simultaneously. Thus, we can decompose the reconstruction task of a given projection view into several subtasks. For simplicity, we just decompose the reconstruction task evenly by the index of detector bins. To avoid the access collision, the iteration of each subtask is performed according to the ascending or descending order of its bin indices. Then, we use multithreading technique to accelerate these subtasks. Open multi-processing (OpenMP) is a parallel programming model for shared memory multi-core platform. The OpenMP application programming interface (API) specifies a set of compiler directives and a library of subroutines, which enable us to easily parallelize the sequential code [30,31, 30,31]. In this work, we use the OpenMP to parallelize the implementation of ART. Let T n be the number of threads, and B n be the number of detector bins. Then, the pseudocode of the multithreading-based ART is presented in Algorithm 3.
In recent years, GPU parallel computing technique has been widely used in various fields of scientific computing [32–35]. The compute unified device architecture (CUDA), a C-like API, provides an easy way to develop parallel program for GPU. As discussed above, the TV minimization consists of four steps: computing d(w), computing the elements v s ,t of the partial derivative v, normalizing v, and updating image f. Therefore, we design three CUDA kernels, kernel_1, kernel_2 and kernel_3, to perform the TV minimization. The kernel_1 is to compute the partial derivative image v using Equation (6), kernel_2 is to normalize the partial derivative image, i.e. v = v/∥ v ∥ 2, and kernel_3 is to update image f using Equation (5). The pseudocode of the GPU accelerated TV minimization is presented in Algorithm 4.
Experiments and results
To evaluate the proposed algorithm and its parallel implementation for ART-TV, we performed experiments on both CPU and GPU. All codes were written with single precision by using C language under Visual Studio 2013 and CUDA 8.0. The experiments were carried out on a 10-core workstation configured with 3.30 GHz Intel CoreTM i9-7900X CPU and 48 GB of memory. An NVIDIA GeForce GTX 1080 Ti graphic card with 11 GB of GDDR5X memory and 3584 CUDA cores was installed in the workstation.
Efficiency of our proposed algorithm
We simulated a fan-beam CT system with a linear detector of 2048 bins spaced by 0.192 mm, 1150 mm source to detector distance, 650 mm source to origin distance, and 180 projection views over 360°. The two-dimensional FORBILD head phantom was used in the numerical experiments, and the simulated projection data were generated using analytical method from this phantom. To evaluate the efficiency of our method, we reconstructed the phantom using ART-TV algorithm with image sizes of 1024×1024 and 2048×2048. Correspondingly, the pixel sizes were 0.209×0.209 mm2 and 0.1045×0.1045 mm2, respectively. For comparison, we also used the Siddon method and the distance-driven method to calculate the system matrices. Table 1 shows the computation time of the three methods with one iteration.
Computation time of ART-TV using three methods (sec)
Computation time of ART-TV using three methods (sec)
For 1024×1024 images, as shown in Table 1, the forward projection using our method is 4.8 times and 1.7 times faster than that using the Siddon and the distance-driven methods, respectively. While for 2048×2048 images, our method is 4.3 times and 2.0 times faster than the Siddon and the distance-driven methods, respectively. Overall, for the reconstruction of 2048×2048 images, our method can obtain speedup factors of 2.6x and 1.6x compared with the Siddon and the distance-driven method, respectively. The results show that our method is very efficient compared with the Siddon method. It should be noted that the back-projection operation is fully determined by the elements of the system matrix calculated during the forward projection operation. As can be seen from Table 1, the computation time of the back-projection using Siddon’s method is almost the same as our proposed method for a given image.
The Siddon method contains two main time-consuming processes, i.e. merging the intersection parametric sets into an ordered set and calculating the pixel indices, which take up about 26% and 41% of the total computational time, respectively. These processes involve multiple operations, such as multiplication, division and integer rounding, which decrease the efficiency of Siddon’s method greatly. However, in our method, most of the pixel indices are calculated using only addition or subtraction operations. Besides, most intersection lengths are calculated by assigning a constant value l x or l y for a given ray. Therefore, our method can save a considerable amount of computation time compared with the Siddon method.
To evaluate the accuracy of our method, we performed the ART-TV reconstruction using the Siddon method and our method, respectively. The reconstruction image was 2048×2048, whose values were initialized to zero. The relaxation factor λ was set to 0.2, and the projections were accessed in a random permutation scheme. For the total variation, the regularization parameter α was set to 0.26, ɛ was set to 10–8, and the iteration number was 20. For comparison, we also reconstructed the phantom using the distance-driven method and the analytical FBP method. Note that, the Shepp-Logan filter and linear interpolation were used in the reconstruction of FBP. Figure 4 shows the reconstructed images using different methods.
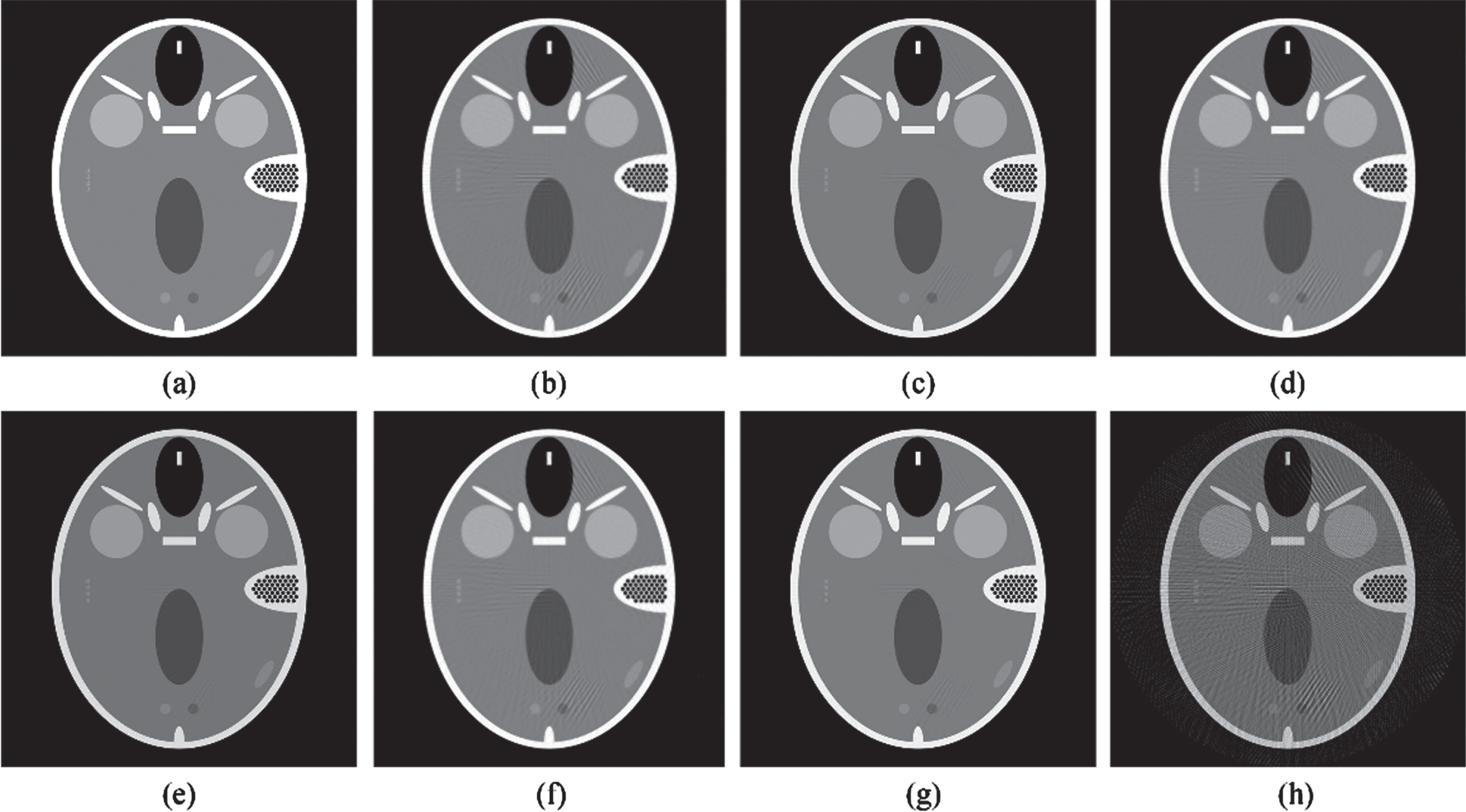
The original phantom and the reconstructed images. (a) shows the original phantom. (b) and (c) show the results using Siddon’s method after 10 and 80 iterations, respectively. (d) and (e) show the results using distance-driven method after 10 and 80 iterations, respectively. (f) and (g) show the results using our method after 10 and 80 iterations, respectively. (h) shows the result using FBP algorithm.
As can be seen from Fig. 4, the visual quality of the reconstructions using Siddon’s method, distance-driven method and our method is similar. With the increasing of the iteration number, the reconstruction quality is getting better. Because the projection data are incomplete for the analytical FBP algorithm, severe artifacts can be found in Fig. 4(h). To evaluate our method in a quantitative way, the normalized root mean square error (NRMS) and the normalized mean absolute error (NMA) were computed in the experiment. The formulas of the two errors are given by
Comparison of the NRMS and NMA of different methods
As can be seen from Table 2, the NRMS and NMA errors of our method are almost identical with those of Siddon’s method, which indicates that our method is very accurate in calculating the system matrix. Both errors of the distance-driven method are smaller than those of the LIM-based method for the same number of iterations, which demonstrates the superiority of the distance-driven method in iterative reconstruction. With the number of iterations increasing, both errors are becoming smaller. We can obtain satisfactory reconstruction results after large numbers of iterations. Moreover, the results show that the reconstruction quality of ART-TV method is much better than that of the conventional FBP algorithm for sparse-view projections.
In this experiment, different numbers of threads were used to accelerate the ART reconstruction for a 2048×2048 image. Meanwhile, the GPU-based method was used to accelerate the TV minimization, in which the size of the CUDA block was set to 16 ×16, and the grid was set to 128×128. Figure 5 shows the computation time of the parallel reconstruction after one iteration using the Siddon and our method.
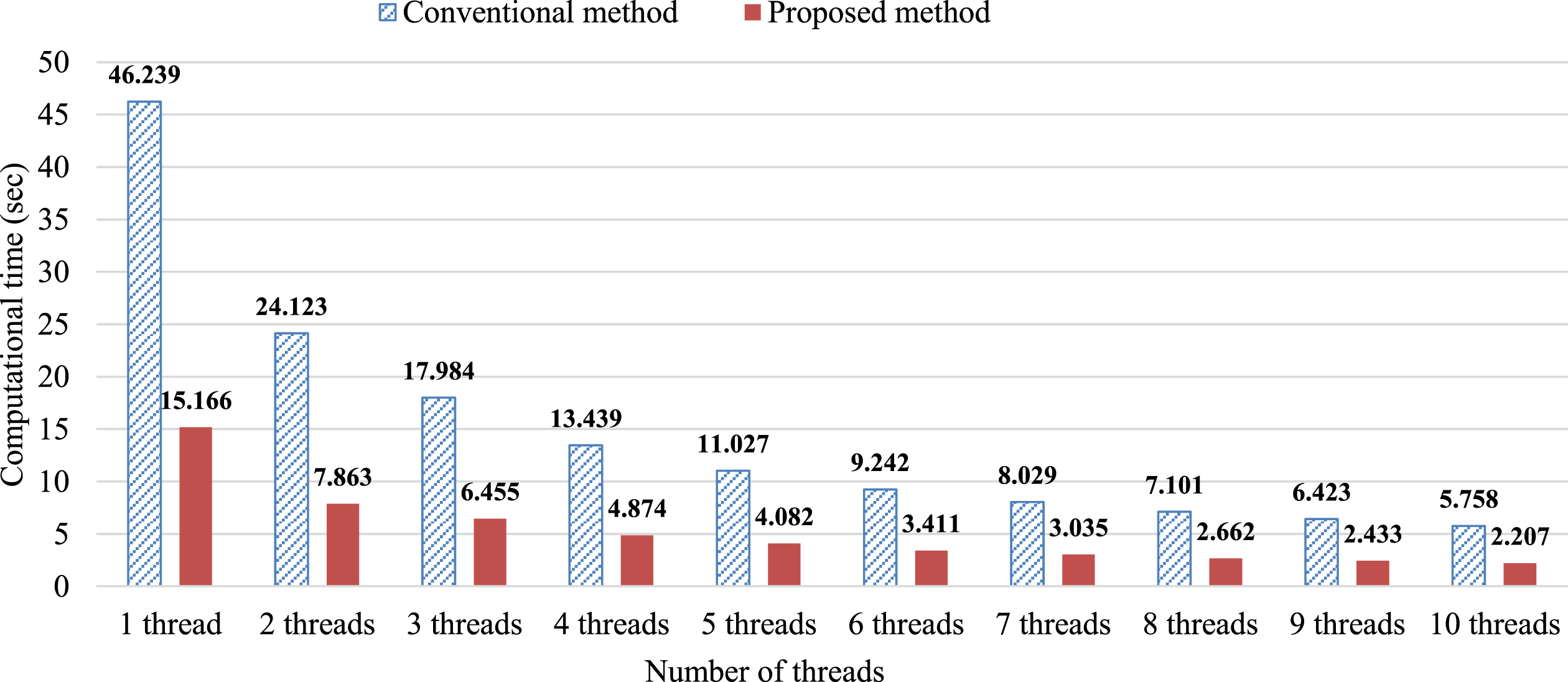
Computation time of the parallel reconstruction using the Siddon method and our method.
As can be seen from Fig. 5, the total reconstruction time using the Siddon method with one thread is 46.2 seconds, and that using the proposed method is 15.2 seconds. By using GPU implementation, the computation time of the TV minimization is reduced to less than 0.8 seconds. With the number of threads increasing, the computation time of the forward and backprojection process is gradually reduced. Using ten threads, the total reconstruction time of the proposed method is reduced to 2.2 seconds. We obtained a speedup factor of 23x compared with the conventional CPU implementation. To assess the reconstruction quality of the parallel reconstruction, Tables 3 and 4 show the NRMS and NMA errors of the two methods after 10 iterations with different numbers of threads.
Comparison of NRMS errors with different numbers of threads
Comparison of NMA errors with different numbers of threads
From Tables 3 and 4, we can see that our parallel reconstruction has almost the same accuracy as the conventional single-thread CPU reconstruction. The results show that our parallel implementation is efficient and accurate. Figure 6 shows the reconstructed images with 10 threads after 10 iterations and their profiles comparison of the two methods.
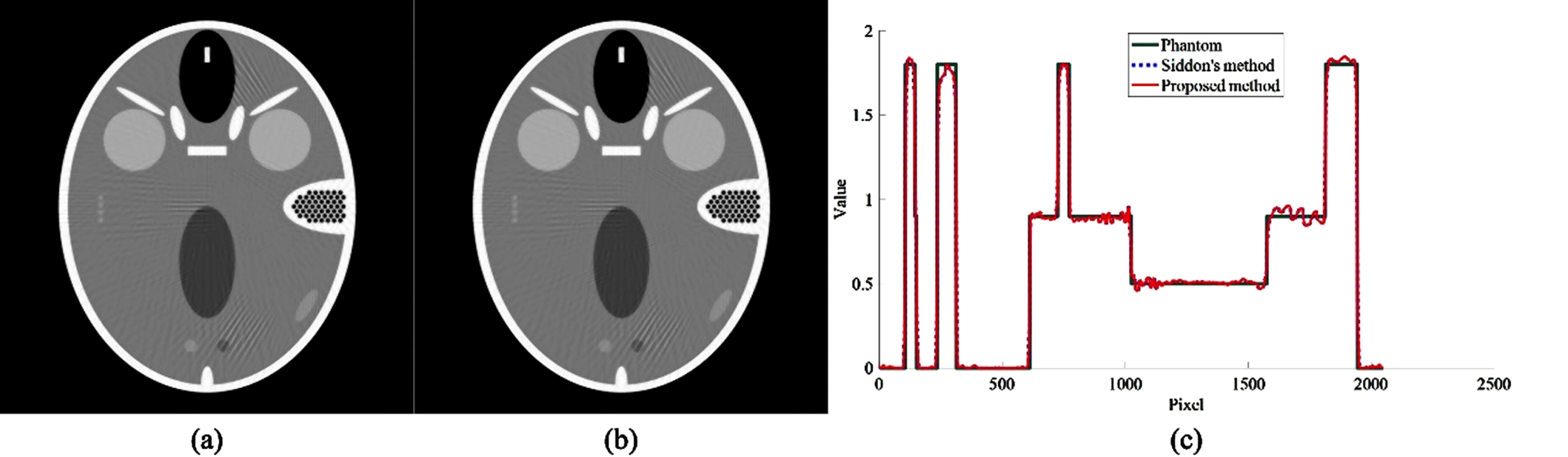
Reconstructed images and their profiles. (a) shows the parallel reconstruction using Siddon’s method. (b) shows the parallel reconstruction using our proposed method. (c) shows the central vertical profiles of the original phantom and the reconstructed images (a) and (b).
We have presented a fast forward-projection method for total variation constrained ART. Based on our method, we used the multi-thread technique to accelerate the iteration procedure of ART and used the CUDA-enabled GPU to accelerate the total variation process. We performed numerical experiments on both CPU and GPU to validate our method. The experimental results indicate that, for the reconstruction of 2048×2048 images form 180×2048 projections, it takes only 2.2 seconds to perform one iteration using our proposed method together with 10-core and GPU implementation. We obtained a speedup factor of 23x over the Siddon method with a single core CPU implementation. Moreover, we have shown that both our forward projection method and its parallel reconstruction method keep almost the same precision.
Note that our proposed method can perform efficient reconstruction for other iterative methods, such as SART, SIRT, and EM. In addition, it can be used for projection simulation from a digitized image, and artifact correction. Currently, cone-beam computed tomography (CBCT) has been widely used in many applications [36–38]. However, the reconstruction of the 3D total variation constrained ART would be very time-consuming, particularly for high resolution image. Thus, our future work will extend the proposed method to the three-dimensional case.
Footnotes
Acknowledgment
This research was supported by the National Natural Science Foundation of China (No. 61772421).