
Abstract
Recently, low-dose computed tomography (CT) has become highly desirable due to the increasing attention paid to the potential risks of excessive radiation of the regular dose CT. However, ensuring image quality while reducing the radiation dose in the low-dose CT imaging is a major challenge. Compared to classical filtered back-projection (FBP) algorithms, statistical iterative reconstruction (SIR) methods for modeling measurement statistics and imaging geometry can significantly reduce the radiation dose, while maintaining the image quality in a variety of CT applications. To facilitate low-dose CT imaging, we in this study proposed an improved statistical iterative reconstruction scheme based on the penalized weighted least squares (PWLS) standard combined with total variation (TV) minimization and sparse dictionary learning (DL), which is named as a method of PWLS-TV-DL. To evaluate this PWLS-TV-DL method, we performed experiments on digital phantoms and physical phantoms, and analyzed the results in terms of image quality and calculation. The results show that the proposed method is better than the comparison methods, which indicates the potential of applying this PWLS-TV-DL method to reconstruct low-dose CT images.
Keywords
Introduction
X-ray computed tomography (CT) provides clear information on the attenuation of X-rays in different human body tissues at a millimeter scale, thus providing rich information on human organs for clinical diagnosis and prevention. CT has become an indispensable tool in the radiology diagnosis field [2]. However, as popularity of CT tomography has grown for clinical diagnosis, the problem of the radiation dose delivered during CT scans has attracted increasing attention. A large number of clinical studies have shown that CT radiation doses beyond the normal range can cause metabolic abnormalities and diseases such as cancer [3]. This is because a CT radiation dose accumulates over time; thus, repeated CT scans significantly increase the probability of carcinogenesis, which highlights the importance of low-dose CT. Low-dose CT reduces the radiation delivered to the patient by reducing the X-ray tube load setting or reducing the number of projections. However, lowering the dose has the side effect of adding noise and stripe artifacts to the reconstructed image, which reduces the quality of CT reconstruction and affects the clinician’s ability to diagnose abnormal tissues. Therefore, obtaining high-quality diagnostic CT images from low-dose or sparse view acquisitions is an important and much-studied research topic in the field of medical imaging.
At present, two main strategies exist to achieve low-dose CT (LDCT). The first strategy is to reduce the X-ray flux towards each detector element while the number of X-ray attenuation measurements is sufficient, and the second strategy is to decrease the number of X-ray attenuation measurements while the X-ray flux towards each detector element is normal. The first strategy is implemented by adjusting the tube current, tube voltage and exposure time of an X-ray tube. The second strategy produces insufficient projection data, suffering from few-view or limited-angle. Both of these strategies will lead to reconstruction results with artifacts. Thus, both strategies have high requirements for reconstruction algorithms and represent a major opportunity for algorithmic research.
Various techniques have been extensively investigated to reduce the radiation dose in CT examinations. Among them, statistical iterative reconstruction (SIR) methods that model the measurement statistics and imaging geometry allow the radiation dose to be reduced significantly while maintaining image quality in various CT applications compared with the filtered back-projection (FBP) reconstruction algorithm [4, 5]. Total variation (TV) has become a more popular form of prior knowledge than FBP. TV prior knowledge is based on the piecewise constant property of the CT image, which indicates that the image should have a small TV value. In practice, TV-based methods such as the adaptive steepest descent projection to convex set (ASD-POCS) method reconstruct CT images by solving TV minimization problems and use iterative optimization to find the minimal TV solutions [6–12].
Dictionary learning (DL) has attracted much attention in recent years. Some methods have incorporated dictionary learning into an iterative reconstruction framework [13–16], such as adaptive dictionary-based statistical iterative reconstruction (ADSIR) and 3D dictionary learning (3D-DL) [17]. The combination of dictionary learning with iterative reconstruction in these methods not only helps to improve the imaging performance but also increases the computational complexity due to their nested iterations. Other methods treat dictionary learning as postprocessing to reduce artifacts in images reconstructed with FBP, such as artifact suppression dictionary learning (ASDL) algorithms [18–25].
The statistical iterative reconstruction (SIR) method for modeling measurement statistics and imaging geometry can significantly reduce the radiation dose while maintaining image quality in various CT applications. The cost function of SIR consists of data fidelity and regularization terms. We use the TV regularization model based on the PWLS standard in which the weighted least squares (WLS) fidelity term considers the exact relationship between the variance and the mean of the projection data in the presence of electronic background noise. TV regularization uses the piecewise constant assumption (PCA), which can reconstruct high-quality CT images by TV minimization measured by sparse view without introducing significant artifacts. However, TV minimization cannot distinguish between real structure and image noise. Therefore, some structures may be lost or distorted, and block artifacts are generated in the reconstructed image. The inherent flaws of the TV minimization method prompted us to study other sparse representations, combined with dictionary learning (DL), and the sparse representation in redundant dictionaries achieved significant improvements. The DL method has significant effects in maintaining structure and suppressing image noise.
In this paper, we present an improved low-dose CT statistical iterative reconstruction method. Our goal is to reconstruct a sufficiently detailed image from a low-dose projection, reconstruct the intermediate image using TV minimization under the Penalized Weighted Least Squares (PWLS) standard [26], and postprocess the result using sparse coding dictionary learning to remove residual noise and produce clinically acceptable CT images. For simplicity, we term the proposed method “PWLS-TV-DL.” The novelty of PWLS-TV-DL is twofold. First, the weighted least squares fidelity term considers the exact relationship between the variance and the mean of the projection data in the presence of electronic background noise. Second, we present a novel algorithm for image reconstruction from few-view data utilizing the PWLS coupled with dictionary learning, sparse representation and TV minimization on two interconnected levels. The sparse constraint in terms of TV minimization has already led to good results for low-dose CT reconstruction and it is a global requirement, but it cannot directly reflect object structures. Compared to the discrete gradient transform used in the TV method, dictionary learning has been shown to be an effective approach to sparse representation. The sparse constraint in terms of a redundant dictionary is incorporated into an objective function in a statistical iterative reconstruction framework, and the dictionary can be adaptively defined during the reconstruction process. Moreover, unlike conventional image processing techniques that process an image pixel by pixel, the dictionary-based methods process an image patch by patch. Thus, it naturally and adaptively imposes strong structural constraints. By integrating TV and DL into the same frame to achieve a sparser representation of the signal, the introduction of an adaptively learned dictionary alleviates the artifacts caused by the piecewise constant assumption and allows accurate restoration of images with complex structures. Qualitative and quantitative evaluations were carried out on digital and physical phantoms, and the results are presented in terms of accuracy and resolution.
The rest of this paper is organized as follows. Section 2 states the PWLS image reconstruction model, TV minimization, DL-based CT reconstruction, and the PWLS-TV-DL algorithm workflow, along with the experimental setup and evaluation metrics. In Section 3, we present the results of the PWLS-TV-DL algorithm and comparison methods on simulation experiments and physical experiments, respectively. Finally, a discussion and conclusion are given in Section 4.
Methods
PWLS criteria for CT image reconstruction
The penalized weighted least-squares (PWLS) approach for iterative reconstruction of X-ray CT images was studied by Herman, Sauer and Bouman [27]. Based on the noise properties of CT projection data, the PWLS criterion for CT image reconstruction can be written as follows:
Based on our previous works, in this study, the variance of
Total variation was first proposed by Rudin in the image denoising model in [28], which was used to measure image characteristics with up to a certain order of differentiation. Mathematically, the original TV of an image x can be defined as follows:
Dictionary learning has the advantage of adaptability, allowing the dictionary to be approximated to the maximum initial signal. An efficient dictionary should also be characterized by multiscale, geometric invariance and redundancy. An adaptive dictionary with the above advantages is beneficial for sparse signal representation because richer dictionary features with greater similarity to the signal to be processed increase the probability of accurate signal approximation with fewer atoms.
The main purpose of the K-SVD algorithm is to train a suitable dictionary based on the training image samples so that the dictionary sparsely represents the training sample images. The objective function can be stated as [29]:
When the sparse coefficient calculation is completed, the K-SVD algorithm begins to update the dictionary to further reduce the error. The dictionary is updated individually for each matrix atom.
The DL heuristic uses a group of pixels, instead of a single pixel, as the minimum unit in the process. Under DL, the CT reconstruction problem can be stated as follows:
Mathematically, Equation (6) contains three subproblems.
The first subproblem is as follows:
This subproblem is called atom matching. With an image x, we must find the sparse representation w j with the dictionary D0, and the number of nonzero elements in w j is fewer than that in ρ. We use the orthogonal matching pursuit to solve this problem.
The second subproblem is as follows:
This subproblem is a TV minimization problem involving two constraints: nonnegativity x ≥ 0 and data fidelity
The third subproblem is as follows:
This subproblem involves updating the image. The closed-form solution to this problem is as follows:
We formulate the CT reconstruction problem using DL and discuss the strategy for dictionary construction. In this section, we provide the implementation details of our PWLS–TV–DL algorithm.
The proposed algorithm consists of PWLS reconstruction, TV minimization and DL. PWLS serves as the reconstruction algorithm, and both TV minimization and DL serve as regularization terms. PWLS with TV minimization can reconstruct high-quality CT images by sparse view measurement, but the real structure and image noise cannot be distinguished, causing some structures to be lost or distorted, and block artifacts are generated in the reconstructed image. Integrating TV and DL into the same frame to achieve a sparser representation of the signal and the introduction of an adaptively learned dictionary alleviate the artifacts caused by the piecewise constant assumption and allow accurate restoration of images with complex structures.
TV minimization can be implemented using the gradient descent method. The magnitude of the gradient can be approximately expressed as follows:
The image TV can be defined as ∥x ∥
TV
= ∑
i
∑
j
τi,j. The steepest descent direction is then defined by
Then, TV minimization can be stated as follows:
The DL process includes atom matching and image updating. In the atom matching part, we need to find the sparse representation (SR) for each patch in the target image by the orthogonal matching pursuit (OMP) algorithm [30]. Because our dictionary is relatively large, searching the entire dictionary is impractical. However, a practical solution can be obtained in two steps. Initial dictionary D0; Use the OMP algorithm to find a local w
j
that minimizes the local reconstruction error:
The OMP algorithm terminates when
In the image updating part, the w
j
in terms of the dictionary D0 is used for updating an image patch x
j
= D0w
j
; then, the updated image patches are recorded in a matrix. The image patch values are not written back to the target image until all the image patches have been updated and recorded. Finally, image x is updated as follows:
The workflow for the PWLS–TV–DL algorithm is summarized in Table 1.
Workflow for the PWLS-TV–DL algorithm
Experimental setup
To evaluate the performance of the PWLS-TV-DL method for CT image reconstruction, we conducted experiments on the digital extended cardiac-torso (XCAT) phantom and the Catphan physical phantom.
Digital XCAT phantom
Figure 1(a) shows a slice of the XCAT phantom. We chose a geometry that was representative of a monoenergetic fan-beam CT scanner setup with a circular orbit to acquire 1160 projection views over 2π. The number of channels per view was 672. The distance from the detector arrays to the X-ray source was 1040 mm, and the distance from the rotation center to the X-ray source was 570 mm. The reconstructed images were composed of 512×512 square pixels. Each projection datum along an X-ray through the sectional image was calculated based on the known densities and intersection areas of the ray with the geometric shapes of the objects in the sectional image.
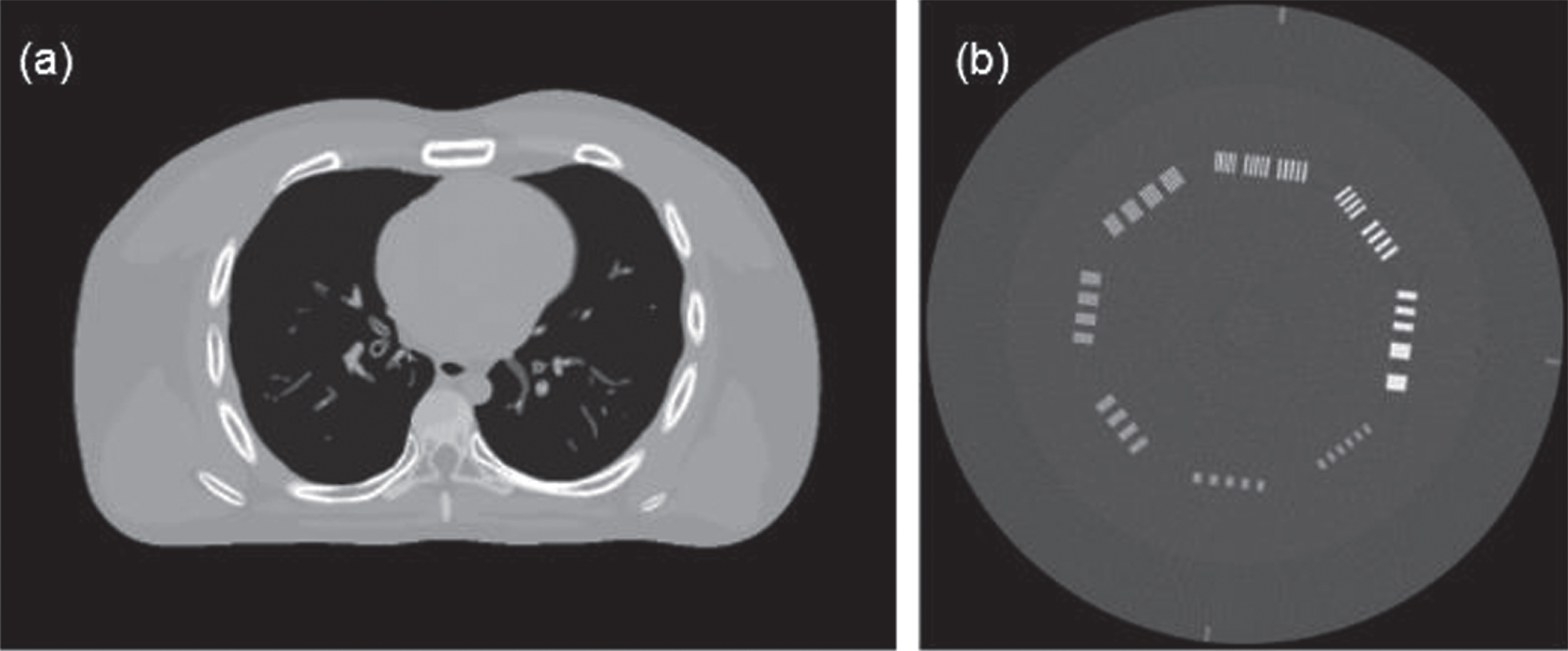
Digital and physical phantoms used in the studies: (a) a slice of the digital XCAT phantom; (b) the standard image reconstructed by the FBP method of the CTP714 module in the CatPhan-700.
Similar to previous studies (Wang et al. 2006) [31], we first simulated the noise-free sonogram data ŷ and then generated the noisy transmission measurement I according to the statistical model of the prelogarithm projection data, that is,
Figure 1(b) shows the standard image reconstructed by the FBP method of the CTP714 module in the CatPhan-700 (Phantom Laboratory Inc., Salem, NY, USA). The experiment was performed on an in-house CT imaging bench. The system had a rotating-anode tungsten target diagnostic level X-ray tube (Varex G-242, Varex Imaging Corporation, UT, USA) and was operated in 120.00 kV continuous fluoroscopy mode with a 0.40 mm nominal focal spot. The X-ray tube current was set to 11.00 mA. The collimated beam had a vertical height of 25.00 mm at the rotation center. The X-ray detector was an energy-resolving photon-counting detector (XC-Hydra FX50, XCounter AB, Sweden) made from cadmium telluride (CdTe) with an imaging area of 512.00 mm×6.00 mm and a native element dimension of 0.10 mm×0.10 mm. The detector signal accumulation period was 0.10 seconds. The projection datasets were acquired with a 1×1 detector binning mode and were rebinned to 6×6 during the postprocessing procedures. Because there was no need to discriminate the photon energies, the detector was operated and calibrated with only a single energy threshold (10.00 keV). The source-to-detector distance was 1500.00 mm, and the source-to-rotation center was 1000.00 mm.
Performance evaluation
We also applied numeric metrics for objective assessment. The first metric is the peak signal-to-noise ratio (PSNR), which is defined based on the mean square error (MSE), where x is the reconstructed image, y is the reference image, N is the number of pixels, and MAX is the maximum pixel value [32]. PSNR is measured in decibel (dB) units; a larger value represents less image distortion.
The second metric is the structural similarity index (SSIM) [33], which measures the similarity between two images by considering the luminance l, contrast c, and structural information s, as follows:
The third metric is the root mean square error (RMSE), which indicates the difference between the reconstructed image and the ground truth image and characterizes the reconstruction accuracy.
In addition to image quality comparisons, the computational cost of the proposed method was evaluated in our study. All the experiments were implemented using MATLAB 2016b and executed on a PC with an Intel Core i7-6700 CPU @ 3.40 GHz and 16.0 GB of memory.
As observed from the objective function, parameter β is the penalty factor that controls the proportion of the penalty term. In this experiment, the constant step size was set to 1. In the DL process, the size of the patch is set to 6*6. For the method of this paper, parameter β is set by observing the experimental results, and its value will also be discussed in subsequent experiments.
Performance evaluation on digital phantom
In the digital phantom study, the original phantom data were directly used as the ground-truth image. As mentioned above, low-dose CT can be implemented by lowering the tube current or reducing projection views. To achieve a more comprehensive study, we tested the proposed method using a low-current case and a sparse-view case.
Experiment in a low-current case
In the low-current case, the incident photon count was set to b
i
= 1.0 × 105 photons per ray, and 360 views over 360° were simulated. The imaging results of the tested methods are shown in Fig. 2. The PWLS result in Fig. 2(a) contains heavy noise in the entire reconstructed region. Even worse, some small structures are covered almost entirely by noise, which can cause misdiagnosis in the clinic. Figure 2(b) shows the image reconstructed by PWLS-DL. This result is better than that of PWLS, but it still contains some noise. As shown in Fig. 2(c), the image is much cleaner after being denoised by TV, but the edges in the image are seriously blurred compared those in the true image in Fig. 1(a). In contrast, it is easy to see in Fig. 2(d) that the image reconstructed by PWLS-TV-DL effectively suppresses noise and artifacts. As the number of iterations increases, the RMSE value decreases. Obviously, the proposed method is better than the other methods.
Imaging results of different methods on the digital XCAT: (a) PWLS; (b) PWLS-DL; (c) PWLS-TV (β= 6); (d) PWLS-TV-DL (β= 8).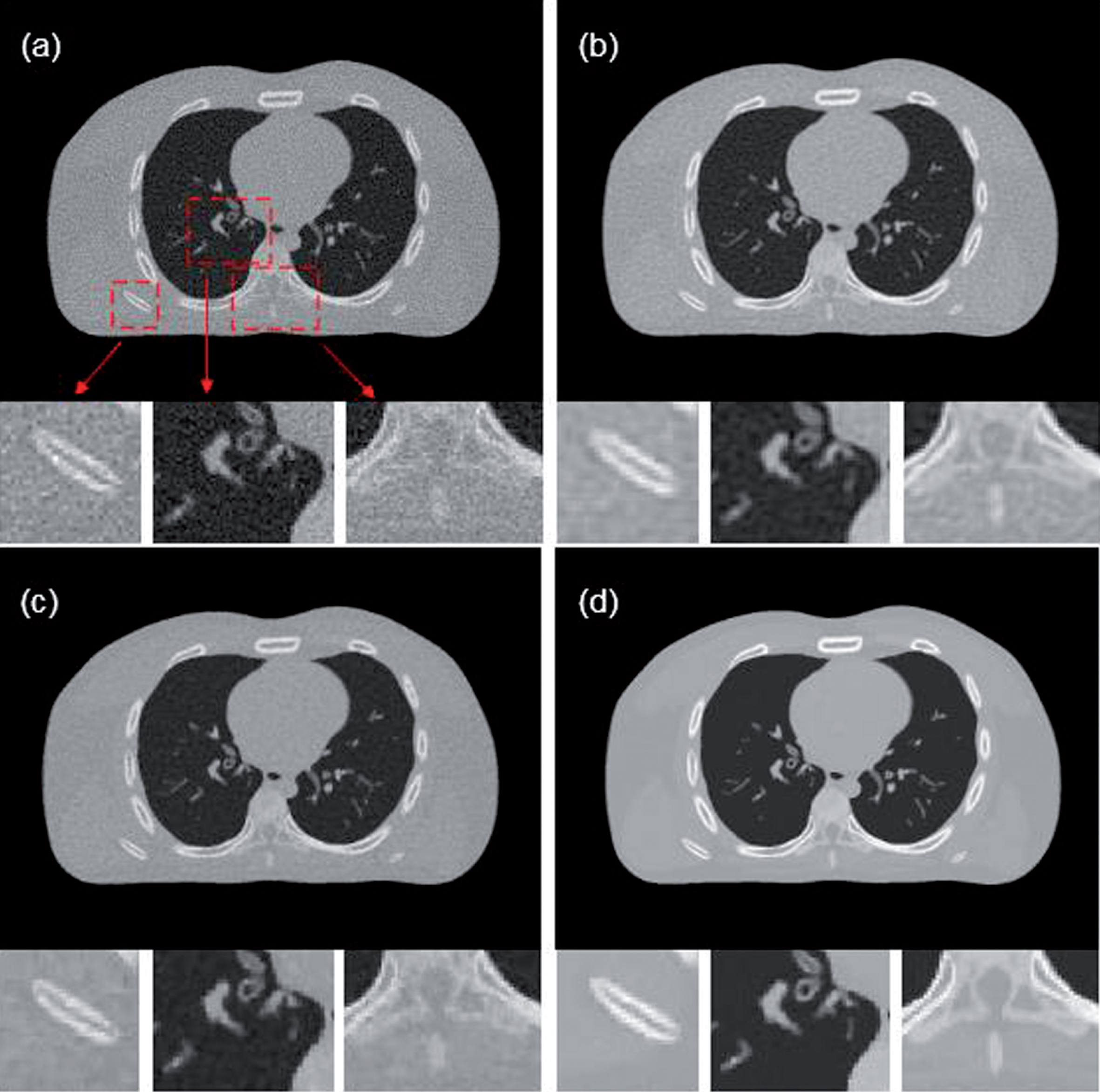
Numeric results on XCAT (view = 360 b i = 1.0×105)
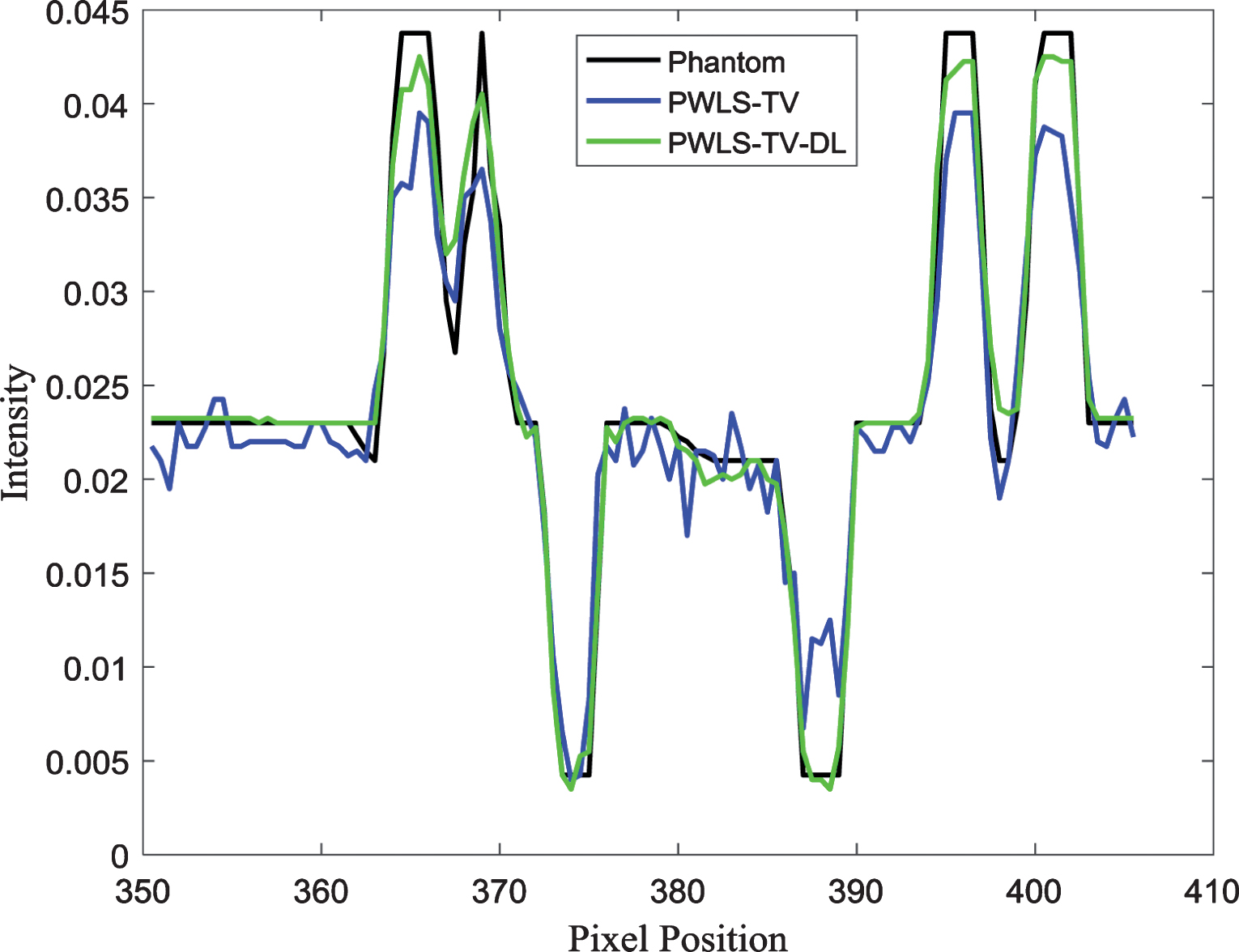
The profile images and residual images are compared in Figs. 3 and 4, respectively. Clearly, the PWLS-TV-DL curve is closer to the Phantom curve. The results show that the proposed method can achieve better-quality images than those of the compared methods.
The curves of RMSE values versus the number of iterations. The profiles were located at the pixel positions x from 350 to 410 and y= 350. The Phantom curve represents the profile of the true image in Fig. 1(a). The PWLS-TV curve represents the profile of the reconstructed image using the PWLS-TV method in Fig. 2(c). The PWLS-TV-DL curve represents the profile of the reconstructed image using the PWLS-TV-DL method, as shown in Fig. 2(d).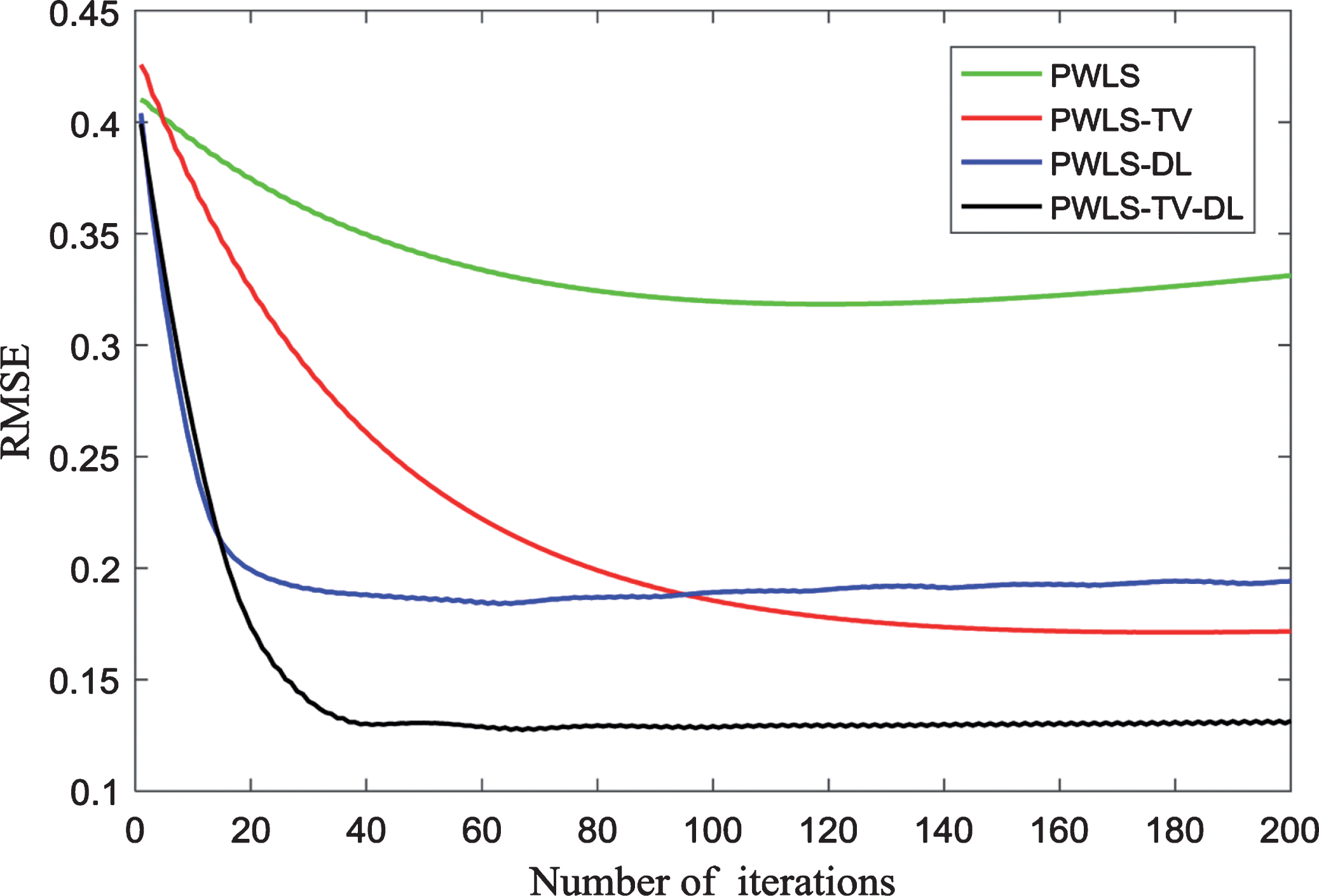
In the sparse-view case, the incident photon count was set to b
i
= 1.0×106 photons per ray, and 180 projections were used for sparse-view reconstruction [1]. The imaging results of the tested methods are shown in Fig. 6. The PWLS result in Fig. 6(a) contains heavy noise in the entire reconstructed region. Figure 6(b and c) show the image reconstructed by PWLS-DL and PWLS-TV, respectively. Both results are better than that of PWLS but still contain some noise. In contrast, as shown in Fig. 6(d), the image reconstructed by PWLS-TV-DL suppresses noise and artifacts.
Residual images of the reconstructed results based on the PWLS method, the PWLS-DL method, the PWLS-TV method, and the PWLS-TV-DL method with 200 iterations on the simulation XCAT data. All the images are displayed in the same window. Imaging results of different methods on the digital XCAT: (a) PWLS; (b) PWLS-DL; (c) PWLS-TV (β= 2); and (d) PWLS-TV-DL (β= 4).

Numeric results on XCAT (view = 180 b i = 1.0×106)
The residual images are compared in Fig. 7. Clearly, the results show that the proposed method can achieve better-quality images.
Residual images of the reconstructed results based on the PWLS method: (a) PWLS; (b) PWLS-DL; (c) PWLS-TV; and (d) PWLS-TV-DL. All the images are displayed in the same window.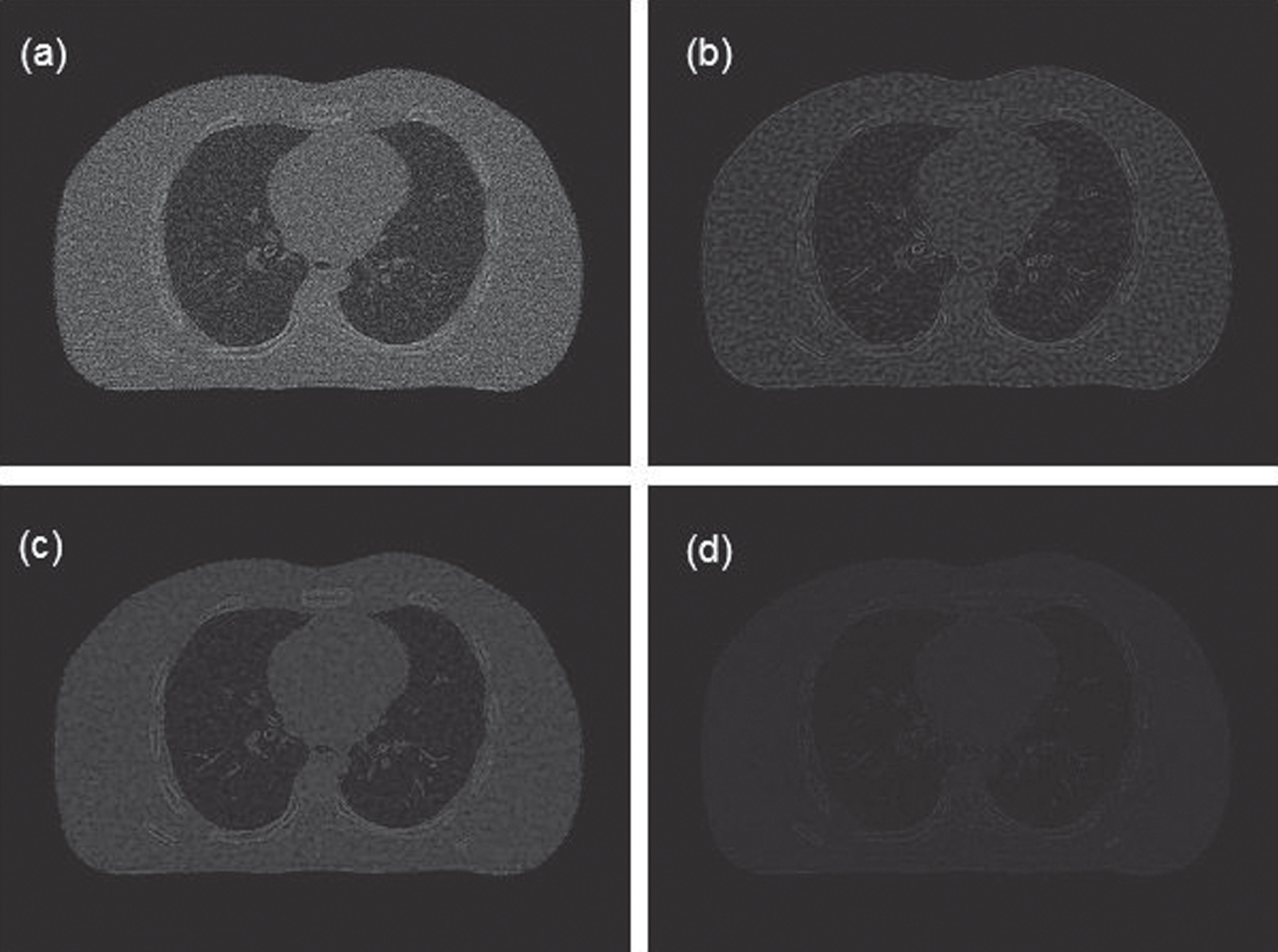
Experiment in a sparse-view case
In the physical phantom study, an image reconstructed with 720 views by the FBP method was used as the true image. To further evaluate the proposed method, we also investigated a much worse case, where the view was lowered to 120.
The results are shown in Fig. 8. The PWLS image Fig. 8(a) contains obvious artifacts. In the PWLS-DL Fig. 8(b) and PWLS-TV Fig. 8(c) images, some artifacts are almost completely missing. As shown in Fig. 8(d), PWLS-TV-DL achieves an acceptable result— almost the same as the true image. Based on Fig. 9, the image quality index obviously improves as the number of iterations increases.
Imaging results of the CTP714 module in the CatPhan-700: (a) Image reconstructed from the PWLS algorithm; (b) Image reconstructed from the PWLS-DL algorithm; (c) Image reconstructed from the PWLS-TV algorithm; (d) Image reconstructed from the PWLS-TV-DL algorithm. The curves of the RMSE values versus the number of iterations.
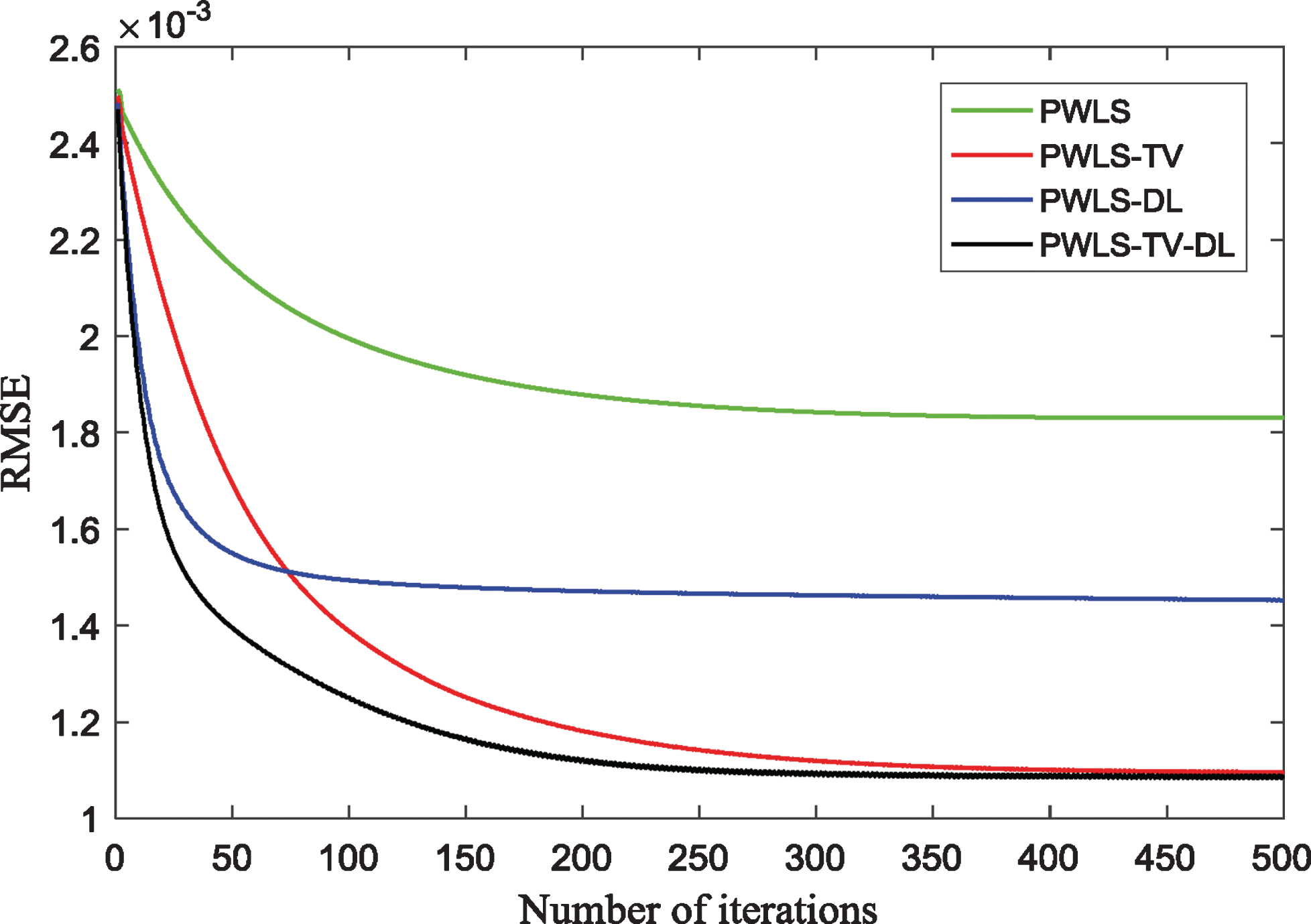
Numeric results on Catphan (120 views, 11 mA, 0.1 s)

Residual images of the reconstructed results based on the PWLS method, the PWLS-DL method, the PWLS-TV method, and the PWLS-TV-DL method with 500 iterations. All the images are displayed in the same window.
In reality, an interesting question of practical importance is as follows: given a total radiation dose, what is the best manner to distribute the dose— would delivering the dose to more view angles with a low mAs/view be better, or would distributing the total dose with a higher mAs/view be better [34]? In this study, we fixed the total radiation dose level to 99 mAs. Two cases for distributing this total dose were used: (180 views, 5.5 mA, 0.1 s) and (90 views, 11 mA, 0.1 s). The reconstructed images are shown in Figs. 11 and 12, respectively. In these images, we can see that in both cases, PWLS-TV-DL provides better reconstruction results than the other methods, with fewer streaking artifacts.
Imaging results of different methods in the case of 180 views and 5.5 mA: (a) PWLS; (b) PWLS-DL; (c) PWLS-TV (β= 0.01); and (d) PWLS-TV-DL (β= 0.02). Imaging results of different methods in the case of 90 views and 11 mA: (a) PWLS; (b) PWLS-DL; (c) PWLS-TV (β= 0.01); and (d) PWLS-TV-DL (β= 0.02).

Numeric results on Catphan (180 views, 5.5 mA)
Numeric results on Catphan (90 views, 11 mA)
In this study, based on the PWLS standard, we proposed and demonstrated a new low-dose CT reconstruction solution by combining TV minimization and sparse dictionary learning. First, an intermediate image is reconstructed using TV minimization; then, it is postprocessed using dictionary learning to remove residual noise and produce a clinically acceptable CT image. As demonstrated by the simulation and physical experiment results, compared with reconstruction methods such as PWLS, PWLS-DL and PWLS-TV, the proposed method improves the quality of reconstructed images and produces smaller RMSE and larger PSNR and SSIM values. However, the main shortcoming of the PWLS-TV-DL algorithm is that matrix update in dictionary learning increases the computational burden and requires a long running time. To solve this problem, a fast computer and dedicated hardware are required. In the future, we believe that iterative-based image reconstructions such as the PWLS-TV-DL algorithm will be widely used in medical clinics [35].
Footnotes
Acknowledgments
This work was supported by the Guangdong Special Support Program of China (2017TQ04R395), the National Natural Science Foundation of China (81871441), the Natural Science Foundation of Guangdong Province in China (2017A030313743), the Guangdong International Science and Technology Cooperation Project of China (2018A050506064) and the Basic Research Program of Shenzhen in China (JCYJ20160608153434110, JCYJ20150831154213680).