
Abstract
BACKGROUND:
Ulna and radius segmentation of dual-energy X-ray absorptiometry (DXA) images is essential for measuring bone mineral density (BMD).
OBJECTIVE:
To develop and test a novel deep learning network architecture for robust and efficient ulna and radius segmentation on DXA images.
METHODS:
This study used two datasets including 360 cases. The first dataset included 300 cases that were randomly divided into five groups for five-fold cross-validation. The second dataset including 60 cases was used for independent testing. A deep learning network architecture with dual residual dilated convolution module and feature fusion block based on residual U-Net (DFR-U-Net) to enhance segmentation accuracy of ulna and radius regions on DXA images was developed. The Dice similarity coefficient (DSC), Jaccard, and Hausdorff distance (HD) were used to evaluate the segmentation performance. A one-tailed paired t-test was used to assert the statistical significance of our method and the other deep learning-based methods (P < 0.05 indicates a statistical significance).
RESULTS:
The results demonstrated our method achieved the promising segmentation performance, with DSC of 98.56±0.40% and 98.86±0.25%, Jaccard of 97.14±0.75% and 97.73±0.48%, and HD of 6.41±11.67 pixels and 8.23±7.82 pixels for segmentation of ulna and radius, respectively. According to statistics data analysis results, our method yielded significantly higher performance than other deep learning-based methods.
CONCLUSIONS:
The proposed DFR-U-Net achieved higher segmentation performance for ulna and radius on DXA images than the previous work and other deep learning approaches. This methodology has potential to be applied to ulna and radius segmentation to help doctors measure BMD more accurately in the future
Keywords
Introduction
Dual-energy X-ray absorptiometry (DXA) usually diagnoses osteoporosis and predict the risk of fractures by measuring bone mineral density (BMD) in the proximal femur, ulna and radius of forearm, and lumbar spine [1, 2]. Currently, the BMD measurement from DXA is regarded as the gold standard method for the diagnosis of osteoporosis by the World Health Organization [3]. The key step for BMD measurement by DXA is to segment the bone’s region of interest (ROI). In the BMD measurement of the forearm, the ulna and radius are the ROI for segmentation, and the accuracy of BMD measurement is closely related to the accuracy of segmentation. Therefore, accurate ulna and radius segmentation is a very important process in measuring BMD. Moreover, improving its segmentation accuracy could useful for distal radius fractures in early diagnosis and treatment [4].
Previous studies used image processing approaches for ulna and radius segmentation using X-ray images [5–8]. However, the accuracy and robust of these methods need improvement. Many deep learning approaches were recently used for medical image segmentation and analysis [9–11]. Several deep learning methods were used for ulna and radius segmentation [12–14]. For example, the U-Net was applied to segment radius in wrist X-ray images [12], and it was also applied for ulna and radius on DXA images [13]. Full convolutional network (FCN) was used for ulna and radius segmentation using single energy X-ray imaging [14]. Our previous work proposed a residual deep learning method to segment ulna and radius regions on DXA images [15]. Compared with the previous deep learning-based approaches, the accuracy and stability of this method have improved for ulna and radius segmentation. However, the segmentation performance of the connection area between ulna and radius still needs to be improved. In addition, some novel and popular deep learning models and network architectures have been proposed and used in image segmentation, such as DeepLabV3 plus [16], nnU-Net [17], and TransUNet [18]. Whether these methods could further improve the accuracy of ulna and radius segmentation on DXA images remains to be verified.
This study proposed a new deep learning segmentation network with dual residual dilated convolution module and feature fusion block based on residual U-Net (DFR-U-Net). It has better segmentation performance for ulna and radius segmentation problem than previous deep learning methods, especially in the connection area of ulna and radius. The proposed dual residual dilated convolution module and feature fusion block were added to the network to enhance the segmentation accuracy.
Materials and methods
Materials
The Ethics Committee of Guizhou Medical University approved this study for ulna and radius segmentation on DXA images. The study collected images of 360 cases (males: 171, females: 189, ages: 36±13 years) using a dual-energy X-ray imaging device (Kanrota, Co., Ltd., China). Each case had a low- and high-energy X-ray image. The dataset, including all cases, was divided into two subsets, one with 300 cases used for training, validation, and testing, and the other with 60 cases used for independent testing. All datasets had a same dimensions of 576×768. The MIPAV V9.0.0 software (Medical Image Processing, Analysis, and Visualization, https://mipav.cit.nih.gov/) was used to annotate the ulna and radius regions by expert clinicians. The background, ulna and radius regions in the ground truth image were represented by 0, 1, and 2, respectively (see Fig. 1).

The DXA images (low- and high-energy) and corresponding ground truth images. The background, ulna and radius regions are labeled with the numbers 0, 1, and 2, respectively.
Data augmentation
The training set was augmented to prevent a network overfitting problem and improve segmentation performance. Considering the dataset characteristics, some augmentation methods were introduced regarding the image contrast. The augmentation methods consisted of vertical and horizontal scaling between 0.8 and 1.2, horizontal translation from –53 to 53 pixels, vertical translation from –57 to 57 pixels, random rotation between –20° and 20°, brightness and contrast transformation, elastic transformation, optical distortion, gamma transformation, histogram equalization, and contrast limited adaptive histogram equalization. The image samples for the training data became more diverse through the data augmentation. All data augmentation methods were only used during the training, and the number of images before training did not increase.
Network architecture
Figure 2 presents an overview of the designed DFR-U-Net architecture. The architecture primarily includes two parts, encoding and decoding parts. In the proposed architecture, encoding part included four max pooling layers and five double residual blocks. The decoding part included four transposed convolution layers and four single residual blocks. The double residual block and single residual block were designed based on ResNet [19], introduced into this network to alleviate vanishing gradients. Figure 3 shows the inner structure of the two blocks. Each double residual block consisted of two 1×1 convolution layers, four 3×3 convolution layers, six instance normalization layers [20], and four leaky ReLU (Rectified Linear Unit) layers. Each single residual block consisted of a 1×1 convolution layer, two 3×3 convolution layers, three instance normalization layers, and two leaky ReLU layers. Four skip connections concatenated feature maps between the output of the feature fusion block and the decoding part. The spatial information of the image lost in the down-sampling process can be obtained by using skip connections [21]. Finally, the feature map included three classes (background, ulna, and radius) was outputted by a 3-channel 1×1 convolution layer after the decoding part.
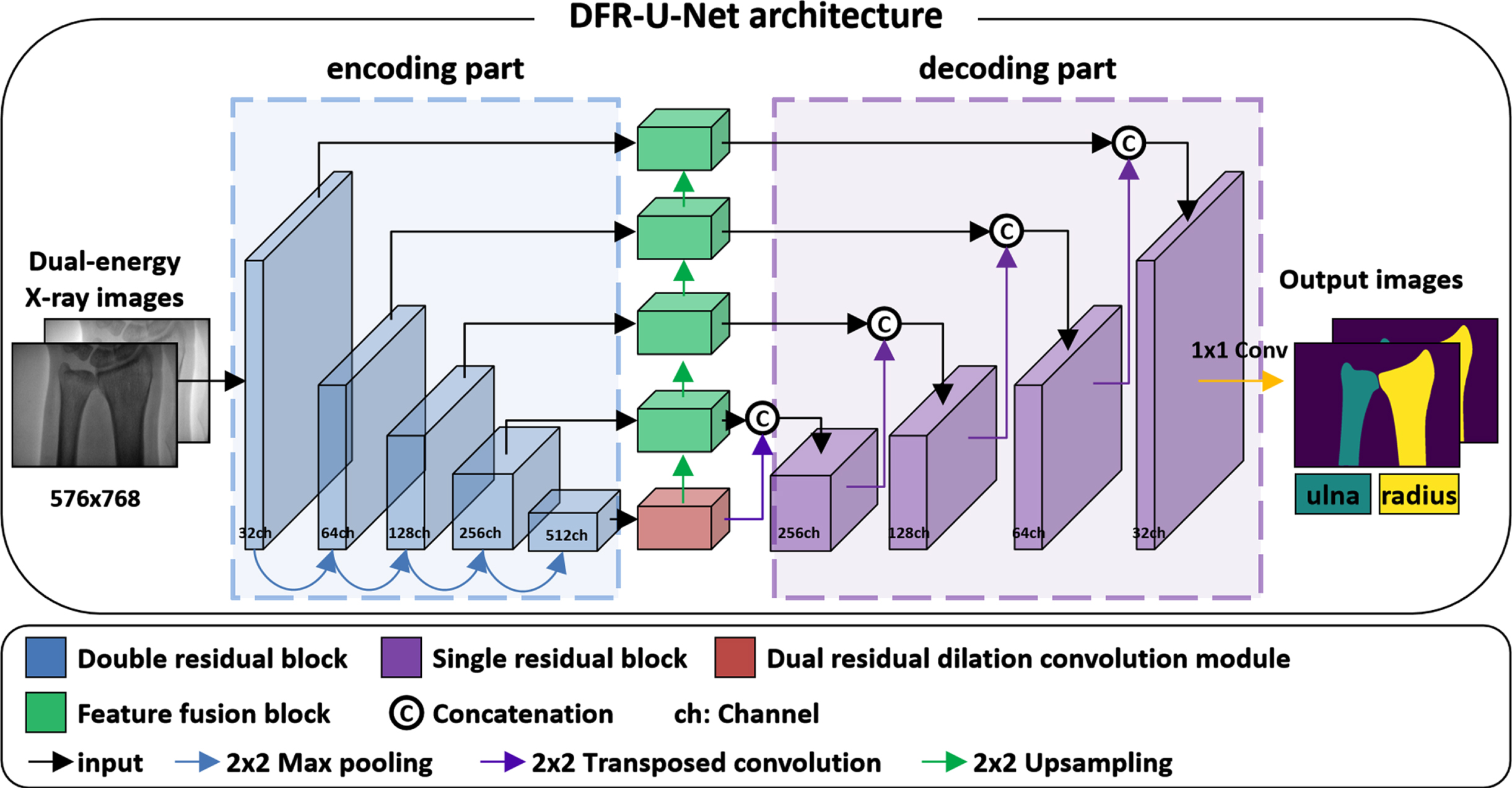
Overview of proposed DFR-U-Net architecture for ulna and radius segmentation. The main architecture includes encoding and decoding parts.
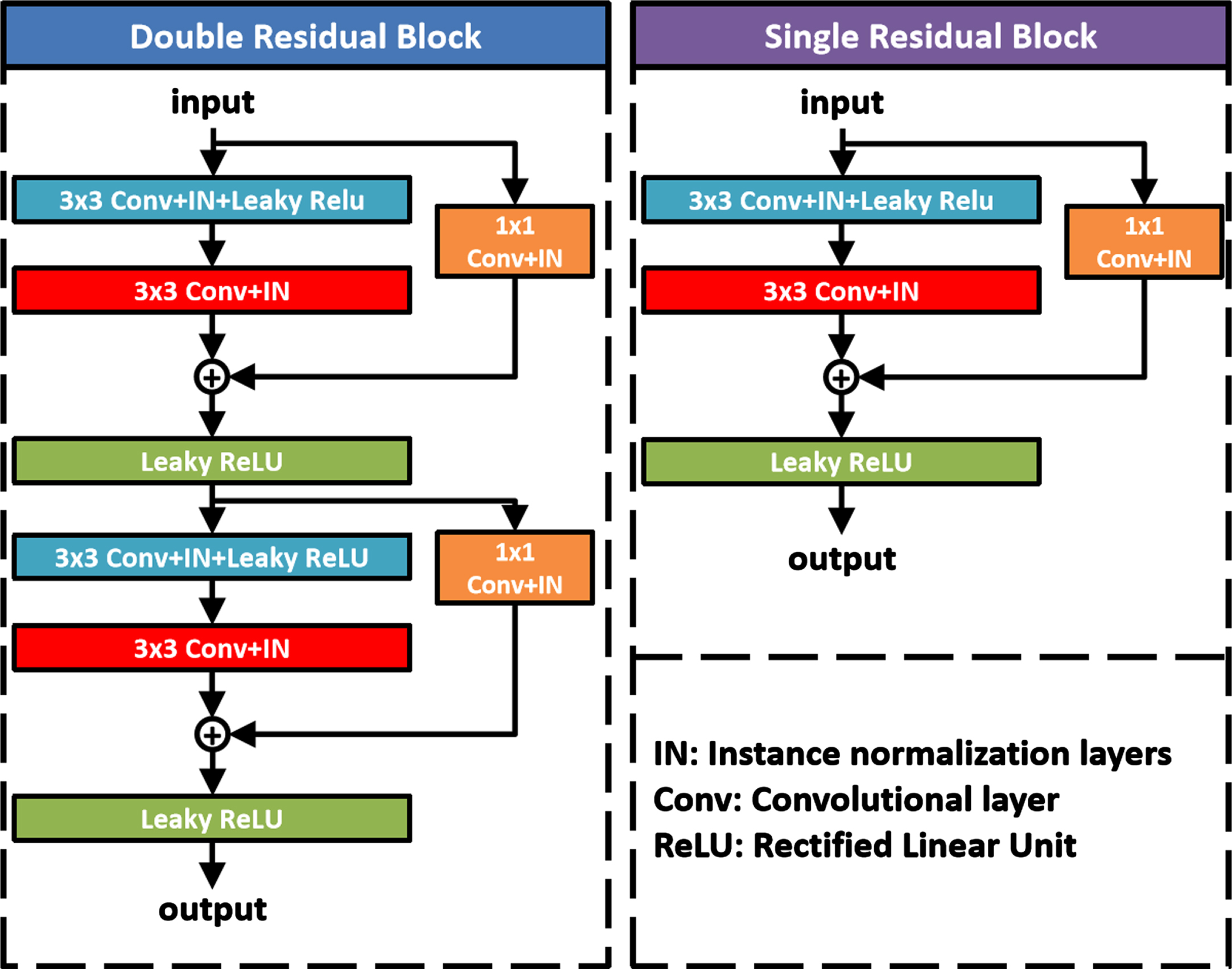
The inner structure of the designed double residual block and single residual block.
The designed dual residual dilated convolution module (Fig. 4) was used at the bottom of the main architecture to extract multi-scale feature maps [22] and obtain contextual information through a larger receptive field. The inner network was designed based on ResNet and atrous spatial pyramid pooling (ASPP) [23]. This module consists of four parallel parts: three parallel double residuals dilated convolution layers with dilation rates 6, 12, 18, and another parallel layer including a 1×1 convolution layer, a global average pooling layer, and a leaky ReLU layer. Each double residual dilated convolution layer included two 1×1 convolution layers, two 3×3 convolution layers with the same dilation rates, four instance normalization layers, and two leaky ReLU layers. The channels for the input image of this module was 512, the channels for the feature maps became 1024 through each of the first blocks of the residual dilated convolution layer, and the channels of feature maps became 512 through the second block of the residual dilated convolution layer. After the fourth parallel layer, an upsampling layer was used to restore the feature map to the size of the input image. The feature maps obtained by the four parallel layers were concatenated in the channel dimension and passed through an output layer which included a 1×1 convolution layer, a leaky ReLU layer, and an instance normalization layer.

Dual residual dilated convolution module. The inner structure consists of four parallel parts: three residual dilated convolution modules and one global average pooling layer.
In order to use the feature information from different modules, a feature fusion block was designed (Fig. 5). The feature fusion block included a 2×2 upsampling layer, two 3×3 convolution layers, two instance normalization layers, a leaky ReLU layer, and a SE (Squeeze and Excitation) block [24]. In this block, the feature maps of the encoding part (double residual block) and the dual residual dilated convolution module were fused through the addition layer. Then the SE block was utilized after the leaky ReLU layer so that the network could focus on more important feature information in the fused feature map.

Feature fusion block. The block fused the feature maps of the encoding part and the dual residual dilated convolution module through an addition layer and SE block.
The choice of loss function is important for the performance of segmentation. Thus, we used a robust loss function called Generalized Dice Loss (GDL) [25] to calculate loss value. The GDL is defined as follows:
The dataset of 300 cases with 600 images was randomly divided into five groups in the implementation phase, with 60 cases (120 images) in each group. Three groups were used for training, one group for validation, and one group for test. For model stability, another 60 independent cases (120 images) without training were used to test the segmentation model. The 5-fold cross-validation was used to evaluate each model. Our method was implemented by PyTorch 1.10.2 and ran in a server computer with four NVIDIA RTX 3090 GPUs.
In the training phase, the network was trained for 300 epochs, and batch sizes was set to 8. The training data of each epoch was shuffled during the training process. The stochastic gradient descent with warm restarts (SGDR) was used as the learning rate descent strategy [26], using an initial learning rate at 0.0003. The learning rate was decreased as follows:
where E i is the number of epochs between two warm restarts; E c is the number of epochs since the last warm restart; L t is the learning rate of current epoch; Lmin is the minimum learning rate; Lmax is the initial learning rate and the maximum learning rate. The number of epochs between the two warm restarts was set to 100 in this work. The learning rate would be set to the initial value at 101st and 201st epoch. The Ranger21 optimizer [27] was used to optimize the network and was regularized with L2 weight decay of 1×10–6. MADGRAD [28] was used as the core of the Ranger21 optimizer. The training process did not continue at 300 epochs when no improvement was observed on the metrics of the training and validation sets. It took about 12 hours to train 300 epochs. Finally, the model with the highest mean Jaccard and the lowest loss value on the validation data was used to evaluate the network’s performance in the testing data.
Three metrics were used to evaluate the similarity between the segmentation results and the ground truth. The metrics were Dice similarity coefficient (DSC), Jaccard and Hausdorff distance (HD) which were defined as follows:
A one-tailed paired t-test was conducted to assert the advantage of our method compared with the other deep learning-based methods (P < 0.05 indicates a statistical significance).
Results
Results of segmentation performance
The testing set, and independent testing set were applied to observe the segmentation performance of our DFR-U-Net model. Figure 6 shows several representative segmentation results of radius and ulna on DXA images. The segmentation performance of the proposed method was very close to the ground truth in the visual results.
Comparison with the state-of-the-art methods
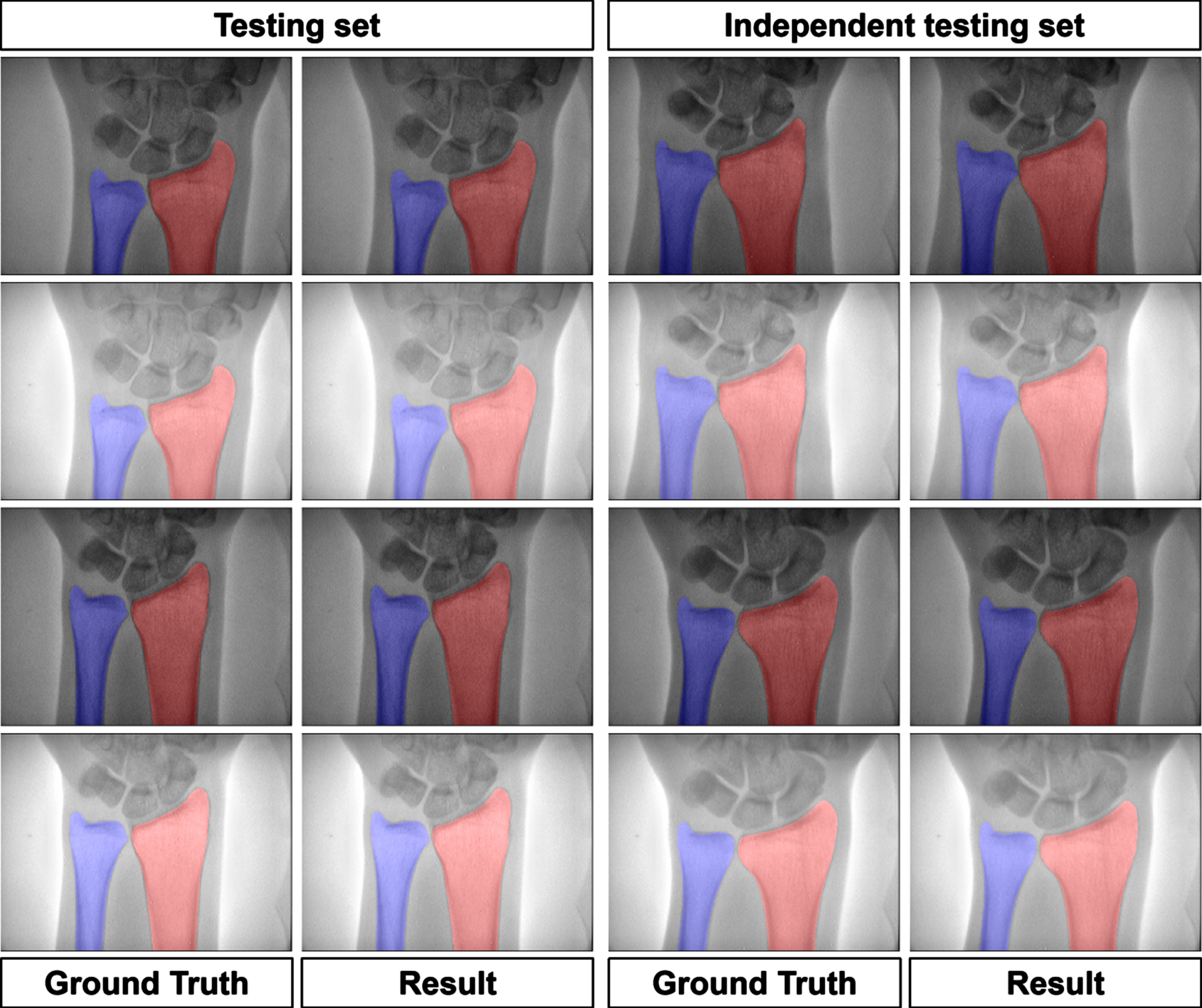
The visual segmentation results of DFR-U-Net. The first to fourth rows show the two cases’ DXA images in testing and independent testing set, respectively. The ground truth and segmentation results of ulna and radius are represented in blue and red regions, respectively.
In our previous work, the segmentation performance between U-Net, FCN was compared with a former network using the same datasets [15]. We compared our DFR-U-Net with three deep learning-based methods which are popularly used in medical image segmentation tasks, including DeepLabV3 plus [16], nnU-Net [17], and TransUNet [18]. These methods are carried out under the same experimental conditions, the same datasets, the same data augmentation, and the same training strategy without any pre-training. Figure 7 shows the segmentation results of our approach and other deep learning methods. Based on the visual results, all methods can accurately segment the regions of ulna and radius on DXA images. However, the proposed model has a better segmentation performance on the connection area of the ulna and radius when compared with other deep learning models.
To quantitatively evaluate the segmentation results, three hundred cases were randomly divided into five groups, with 60 cases in each group. In each fold cross-validation, one of the five groups is used as the testing set to compute DSC and Jaccard metrics. The segmentation results of DSC and Jaccard metrics obtained by each-fold cross-validation model are averaged as the final results, which are summarized in Table 1. The independent testing set was used to test the robustness of our method. As can be seen from the metrics, our method is the best-ranked method between the three popular networks and previous methods. Meanwhile, we calculate HD metric in the same way, the results in Table 2 shows that the proposed method has a smaller HD value, and less segmentation error.
Evaluation results of the previous work, three popular networks, and the current method
All results are presented with the mean values and standard deviation of 5-fold cross-validation, and bold values indicate the best result.
Evaluation results of the segmentation performance on boundaries of ulna and radius
The results are presented with the mean values and standard deviation of 5-fold cross-validation, and bold values indicate the best result.
Ablation experiments were conducted to validate the effectiveness of the key network modules. Under the same experimental conditions, five ablation experiments were conducted to validate the effectiveness of the designed feature fusion block and the dual residual dilated convolution module. The U-Net network was used as the baseline model (the initial number of filters was 32) to compare with the designed modules in the first ablation experiment. In addition, the instance normalization layer and the leaky ReLU layer were used instead of the batch normalization layer and ReLU layer of U-Net, respectively. In the second ablation experiment, all convolution units for encoding and decoding parts of the network architecture of first ablation experiment were replaced with dual residual block and single residual block, respectively. The dual residual dilated convolution module and feature fusion block were not used. The feature fusion block and dual residual dilated convolution module were added to previous network architecture of the second ablation experiment for the third and fourth ablation experiments, respectively. Both designed modules were used in the network architecture in the fifth ablation experiment. We also used 5-fold cross-validation to evaluate each experiment model (Table 3). The ablation experiment results indicated that the network architecture with dual residual dilated convolution module and feature fusion block performed at a higher accuracy, which was more robust than the network architecture without these two modules.
Results of the ablation experiments
Results of the ablation experiments
All results are presented with the mean values and standard deviation of 5-fold cross-validation, and bold values indicate the best result. (DRDCM: dual residual dilated convolution module; FFB: feature fusion block).
Since the evaluation metrics for previous methods are very high (DSC >97%, Jaccard >95%), resulting in that large improvements are very difficult to attain. In order to verify the superiority and effectiveness of our method compared with other deep learning methods, we conducted a one-tailed paired t-test over the evaluation metrics. The pair of results of each fold cross-validation from our method and other models are used to calculate the one-tailed paired t-test. Table 4 lists the statistical analysis results, and all the P-values<0.05, indicating a significant improvement.
Statistical analysis results between our model and other deep learning methods (P < 0.05 indicates significance)
Statistical analysis results between our model and other deep learning methods (P < 0.05 indicates significance)
BMD measurement is important for fracture risk assessment and osteoporosis treatment [29]. Accurate and automatic method for ulna and radius segmentation can contribute to diagnosis of osteoporosis. In our previous study, we proposed a residual deep learning network for the ulna and radius segmentation [15]. Compared with the previous approaches [13, 14], the accuracy and stability of our method have improved for ulna and radius segmentation. However, the segmentation accuracy in connection area of ulna and radius still needs to be optimized (see yellow box area in Fig. 7). Therefore, this study proposed a novel model with feature fusion block and dual residual dilated convolution module based on residual U-Net (DFR-U-Net) to enhance the segmentation accuracy on ulna and radius X-ray images. Compared with the previous works, the segmentation accuracy of the new network architecture was significantly improved in connection area of ulna and radius. The ablation experiment results also confirmed the effectiveness and robustness of the designed modules. The proposed network model achieves the best segmentation performance among known deep learning methods.
The main motivation of this work is to improve the segmentation performance of ulna and radius on DXA images. BMD measurement in the forearm depends on the segmentation accuracy of ulna and radius regions. However, uneven exposure, brightness difference, and noise may affect the segmentation performance on DXA images. Various data augmentation methods such as brightness and contrast augmentation were introduced to alleviate the impact of these problems on segmentation. In addition, according to Fig. 7, some images have unclear image boundaries on the connection area of ulna and radius, which leads to segmentation error from our former method, DeepLabV3+, nnU-Net, and TransUNet. In this proposed method, different feature maps were fused by designed modules to extract more image feature information and improve this region’s segmentation performance.

Visual comparison of the proposed method (DFR-U-Net) with other deep learning methods. The first to fourth rows show the two cases’ DXA images, respectively. The first to fifth columns are the segmentation results from different methods. The green line represents the ground truth. The blue and red line represent the segmentation result of ulna and radius, respectively. According to the visual comparisons, DFR-U-Net exhibited low segmentation error than other methods in the yellow box area.
Although the proposed network had better segmentation performance and exceeded some popular networks, several limitations exist. The datasets used in the experiment were from the same device, and the segmentation performance of this method on a multi-center and multi-device data needs to be verified. Another limitation was that the proposed method has more network parameters than previous work, resulting in a longer processing time (∼5 images per second). Compared with 15 images per second in our former method, it can still meet the needs of clinical real-time processing. More datasets will be collected to verify the method and further improve the segmentation performance in future work. Hopefully, this method can be beneficial for measuring BMD in the forearm and diagnosing osteoporosis, and can be extended into other medical image segmentation research.
This study proposed a novel deep learning method called DFR-U-Net for ulna and radius segmentation on DXA images. The feature fusion block and dual residual dilated convolution module was designed to improve the segmentation performance of the ulna and radius regions. Our algorithm had better stability without prior knowledge. The method was compared to other popular deep learning methods, but the model in this research achieved better segmentation results. In view of the segmentation performance of this method, it could be applied to measure BMD in clinical practices in the future.
Conflict of interest
The authors declare that there is no conflict of interest in this study.
Funding
This work was supported by Guizhou Provincial Science and Technology Projects (Qiankehejichu-ZK[2021]478 and ZK[2023]353, Qiankehepingtairencai[2021]5637), the Youth Science and Technology Talent Growth Project of Common University in Guizhou Province (Qianjiaohe KY[2021]180), the Excellent Young Talents Plan of Guizhou Medical University (2021-101), and National Natural Science Foundation of China (81960338).