
Abstract
BACKGROUND:
C-arm fluoroscopy, as an effective diagnosis and treatment method for spine surgery, can help doctors perform surgery procedures more precisely. In clinical surgery, the surgeon often determines the specific surgical location by comparing C-arm X-ray images with digital radiography (DR) images. However, this heavily relies on the doctor’s experience.
OBJECTIVE:
In this study, we design a framework for automatic vertebrae detection as well as vertebral segment matching (VDVM) for the identification of vertebrae in C-arm X-ray images.
METHODS:
The proposed VDVM framework is mainly divided into two parts: vertebra detection and vertebra matching. In the first part, a data preprocessing method is used to improve the image quality of C-arm X-ray images and DR images. The YOLOv3 model is then used to detect the vertebrae, and the vertebral regions are extracted based on their position. In the second part, the Mobile-Unet model is first used to segment the vertebrae contour of the C-arm X-ray image and DR image based on vertebral regions respectively. The inclination angle of the contour is then calculated using the minimum bounding rectangle and corrected accordingly. Finally, a multi-vertebra strategy is applied to measure the visual information fidelity for the vertebral region, and the vertebrae are matched based on the measured results.
RESULTS:
We use 382 C-arm X-ray images and 203 full length X-ray images to train the vertebra detection model, and achieve a mAP of 0.87 in the test dataset of 31 C-arm X-ray images and 0.96 in the test dataset of 31 lumbar DR images. Finally, we achieve a vertebral segment matching accuracy of 0.733 on 31 C-arm X-ray images.
CONCLUSIONS:
A VDVM framework is proposed, which performs well for the detection of vertebrae and achieves good results in vertebral segment matching.
Introduction
At present, image-guided surgery (IGS) has been widely used in the field of spine surgery [1]. C-arm X-ray has become the main method for image-guided surgery due to its ability to update the position of instruments in real time and to provide the latest anatomical structures [2]. When performing surgery, a doctor will first perform a C-arm X-ray on the patient and determine the surgical location by determining the vertebral segments in the image. However, due to the narrow field of view of intraoperative X-ray images [3], it is difficult to find anatomical landmarks. At the same time, the low X-ray dose used for C-arm X-ray leads to poor image contrast. In addition, the presence of various types of noise [4] interferes with the images, making it difficult for the surgeon to directly identify C-arm X-ray images. Fig. 1. shows the examples of low contrast C-arm X-ray images. In such cases, the surgeon will compare the patient’s pre-operative images, such as DR/X-ray, computed tomography (CT), magnetic resonance imaging (MRI), etc., with the fluoroscopic images to ensure that the procedure is performed at the correct location. However, due to the morphological similarities between vertebrae, manual determination by observation requires highly specialized experience. Lack of experience may lead to errors in some cases. Therefore, reliable identification of C-arm X-ray images can effectively provide surgical guidance and improve surgical accuracy and efficiency.
Examples of low contrast C-arm X-ray images.
In recent years, benefiting from its advantages in image processing, deep learning has achieved rapid development in the field of medical images, including classification, detection, segmentation, and registration. Deep learning replaces the process of machine learning to manually adjust a large number of parameters, and can automatically learn multiple levels of image visual features [5], which effectively improves the efficiency of image processing. In the deep learning research, related to C-arm X-Ray images, there have been some good study results. Li et al. [6] used a feature fusion deep learning (FFDL) model to detect the lumbar spine in a C-arm X-ray image. The model combines the shape information and texture information of the lumbar spine through the Sobel kernel and the Gabor kernel, and finally outputs the detection result. Esfandiari et al. [7] segmented the pedicle screws in C-arm X-ray images using the U-Net model, and the results showed that the method was able to segment the screw axis effectively. Kausch et al. [8] proposed a CNN-based posture regression framework. The C-arm X-ray image can be automatically adjusted to the standard projection angle through two sequentially connected CNN models. Esteban et al. [9] proposed a deep learning framework for automatic alignment of C-arm X-ray and CT images, obtaining a registration success rate of more than 97%, making the results effective for intraoperative pose initialization.
There are several preoperative imaging modalities used for C-arm X-ray image comparisons, among which the comparison with DR/X-ray images is the most common. However, previous studies have focused on 2D/3D registration of C-arm X-ray images with CT or MRI images [8–11]. Unlike previous studies, we will focus on the feasibility of identifying C-arm X-ray images with DR images. We think that there is a certain degree of similarity in the morphology of vertebrae, and in rare cases, especially in the thoracic vertebrae, there may be a possibility of misjudgment during clinical surgery, so we want to use deep learning to identify C-arm X-ray images to provide more provide effective surgical assistance guidance for doctors. The main difficulty in achieving automatic recognition of C-arm X-ray images is due to that the perspective angle of the C-arm is different from that of the preoperative DR image. In some cases, the anatomical structures generated differ significantly from those in the DR images. Also, the pedicle screws implanted in some patients [12], as well as the markers used to identify the surgical location (metal wires, metal rods, scissors, etc.) partially fill the image and can be superimposed on the vertebral area, interfering with the overall identification task of the image. In addition, various types of noise (Gaussian, speckle, Poisson noise, etc.) make C-arm X-ray images different compared with DR images [4].
In this study, we propose a framework for automatic identification of vertebrae in C-arm X-ray images. First, we improve the overall similarity between C-arm X-ray images and DR images through preprocessing methods. Then, a detection model is used to localize the vertebrae, and the target area is cropped to minimize the proportion of the image area occupied by interfering objects. Next, a segmentation model is used to correct the angles of individual vertebrae to reduce the effect of shooting angle on the image. Finally, the vertebral segments are matched based on the image similarity metric for the purpose of C-arm X-ray image identification. We demonstrate the validity of the framework by having the identification results evaluated by spine surgery specialists. To summarize, our objective is to design a framework for automatic vertebrae detection and vertebral segment matching (VDVM) for the identification of vertebrae in C-arm X-ray images.
The rest of this paper is organized as follows. Section 2 introduces the dataset and the VDVM framework, including image preprocessing methods, deep learning models, and similarity metrics. Section 3 presents the VDVM experiments and the result evaluation metrics and analyzes the experimental results. Section 4 and 5 summarize the experimental results and analyze the challenges as well as suggest future work.
Dataset
There are no publicly available datasets, the images used in this study were collected from the Affiliated Hospital of Ningbo University Medical College and Ningbo Yinzhou No. 2 Hospital. We divide the images into four datasets based on image types, and the images are annotated by orthopedic experts using Labelme and Labelimg software for training and validation of different deep learning models, and the images from each dataset are illustrated in Fig. 2. and summarized in Table 1.
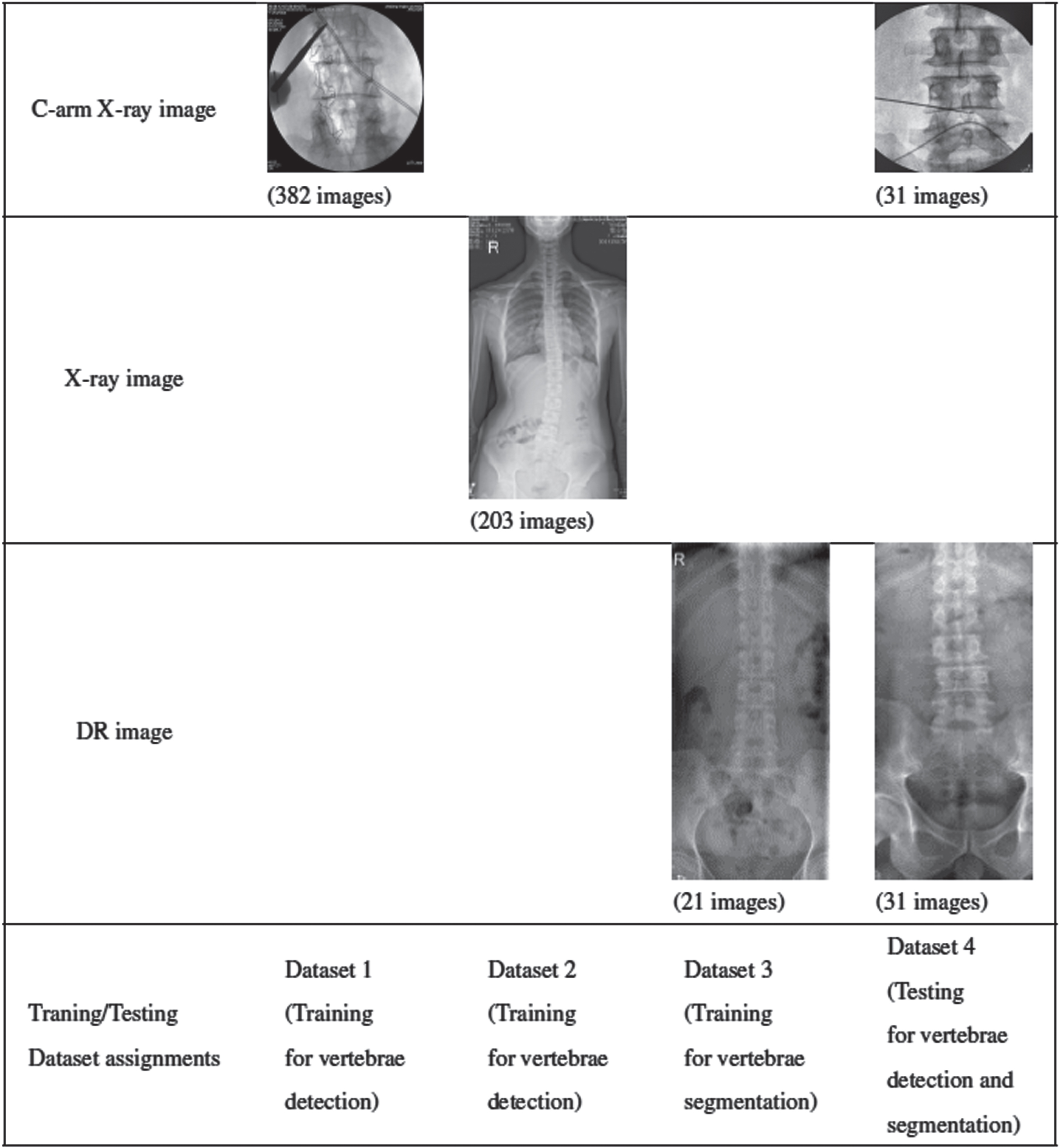
Illustrates of images and training/testing dataset assignments.
Datasets summary
Dataset 1 – This dataset contains 382 intraoperative C-arm images obtained by the C-arm X-ray machine, including C-arm images of the thoracic and lumbar regions, and is used for the training of the C-arm image vertebra detection model.
Dataset 2 – This dataset contains 203 full-length X-ray images taken before surgery. Due to the lack of available DR images, we use X-ray anteroposterior images instead of DR images for the training of the vertebrae detection of DR images.
Dataset 3 – This dataset contains 21 DR images taken before surgery, which are used for the training of the vertebral segmentation model. The images include part of the thoracic region and the complete lumbar region.
Dataset 4 – This dataset contains 31 sets of intraoperative C-arm images taken by mobile devices, as well as preoperative lumbar DR images of the same patient, for final experimental performance testing.
Both X-ray images and DR images are X-ray images. The difference between X-ray images and DR images used in this paper lies in the image quality and image display area. DR images usually have higher image quality. Because the DR system is digital, it can provide higher spatial resolution and contrast. However, the X-ray images used in this paper include the entire region from the head to the sacrum, while the DR images include only part of the thoracic region and the complete lumbar region.
VDVM focuses on the identification of C-arm images through deep learning methods, which is divided into two parts, detection of vertebrae and vertebral segment matching, and the main process is shown in Fig. 3. The main purpose of vertebrae identification is to determine the number of vertebral segments, and the purpose of vertebrae detection in this study is to locate the vertebrae region, so that the next step of vertebrae matching can be performed. In the vertebra detection step, the input C-arm X-ray images and DR images are firstly preprocessed, and then the vertebra detection is performed separately for both types of images through the YOLOv3 model. In the vertebrae segment matching step, the detected vertebral region is first cropped based on the detection results, and the cropped vertebrae images are segmented through the Mobile-Unet model. Based on the segmentation results, we measure the inclination angle of the vertebrae, correct and crop the vertebrae region based on the measured angle in the original image, match the corrected and cropped C-arm image with the DR image vertebrae. Based on the similarity measure as a result, the optimal matching result is obtained, and finally the vertebral joints are marked based on the matching result.
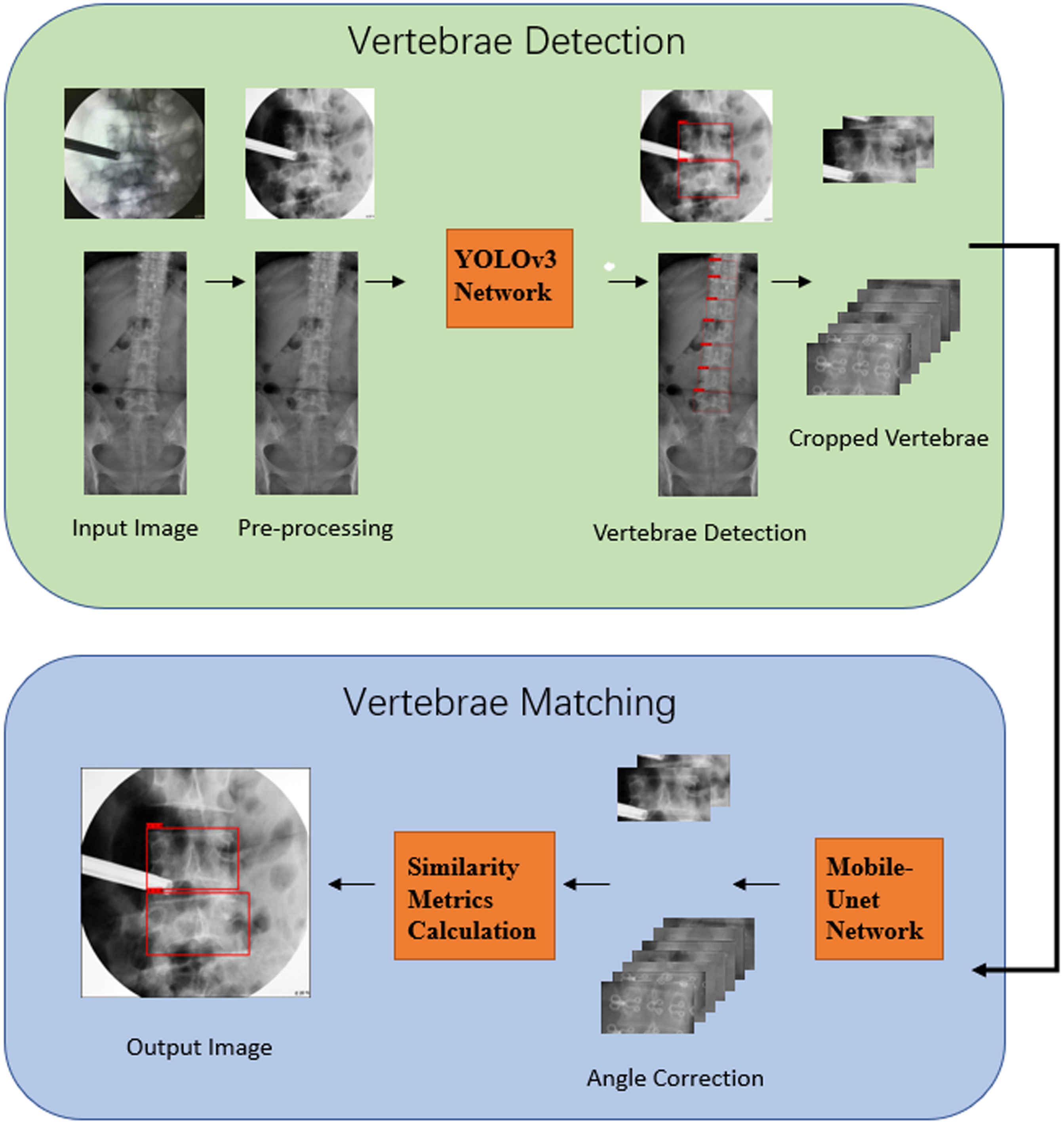
Main process of VDVM framework.
Data Preprocessing and Augmentation
In the vertebrae detection step, we use Dataset 1 and Dataset 2 for model training, and Dataset 4 for performance validation. For the C-arm images in Dataset 1 and Dataset 4, we resize the image to 512*512 pixels, and perform color inversion, median filtering, and histogram normalization to improve image quality. Due to the insufficient number of DR images available, we use the X-ray full-length films in Dataset 2 to make a simulated DR image training set. We perform region of interest (ROI) cropping of the images to ensure that the display range in the X-ray image approximates that of the DR images. The intensity histogram of the X-ray images based on the vertical direction is first obtained, and then the columns between the average intensity plus or minus 1.5 standard deviations (
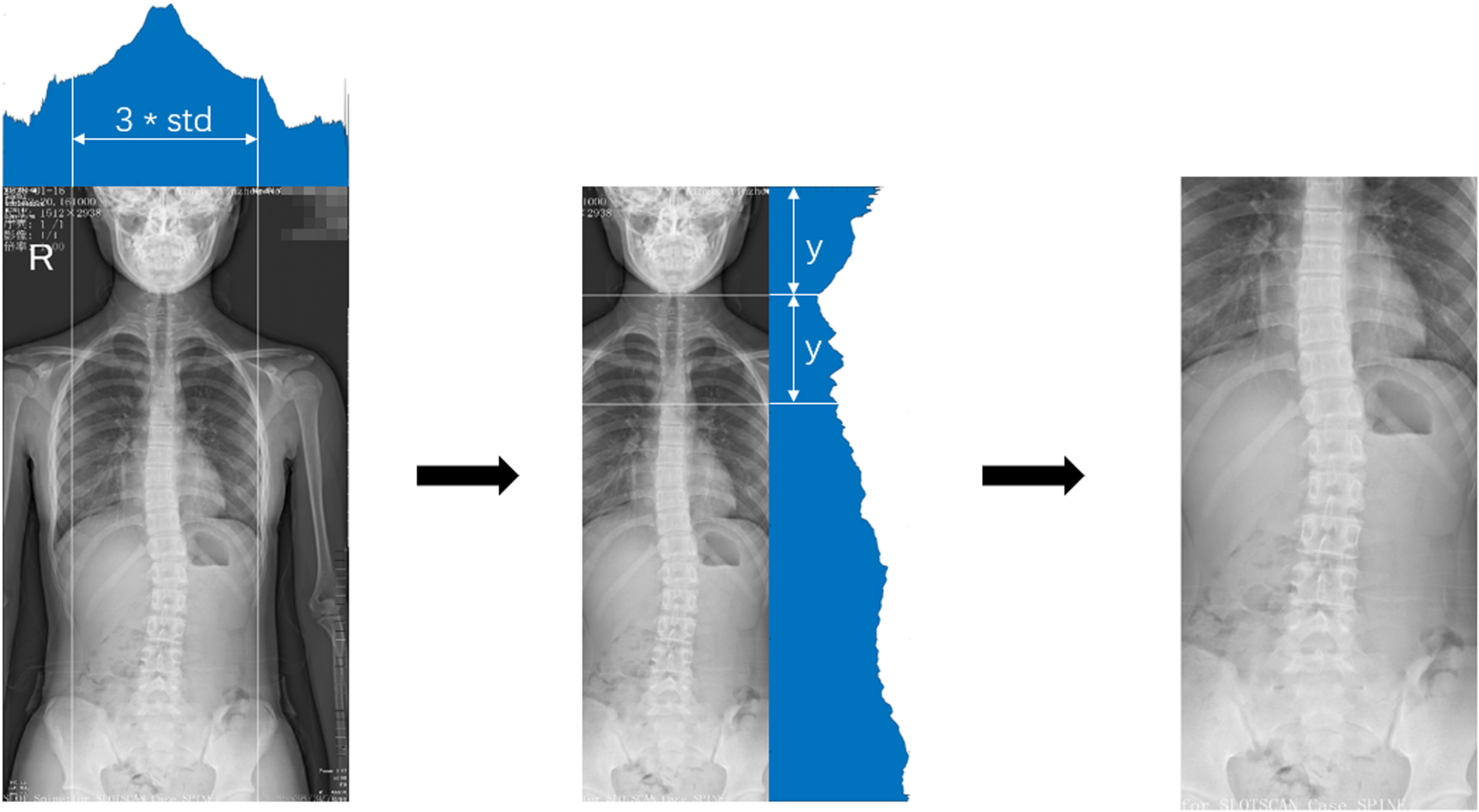
X-ray image cropping process.
We use YOLOv3 [13] as the vertebra detection model. YOLOv3 is an improved one-stage target detection algorithm based on YOLOv2 [14], where the candidate frame and feature extraction, target classification, and localization steps are done in a single unit. Compared with YOLOv2, YOLOv3 uses darknet-53 as the backbone network for extracting features. The first half of the network is a stack of convolutional layers and pooling layers, and the second half is a stack of residual blocks. The use of residual modules enables that network more convolutional layers can be added to further increase the depth and complexity of the network. In addition, to enhance the accuracy of the algorithm for small target detection, YOLOv3 uses a feature pyramid network (FPN) for feature fusion after feature extraction, which can capture feature information of different scales. The width, height, category labels and category probabilities of the predicted boxes are obtained using three different YOLO layers for different scales of boxes. YOLOv3 also uses the leaky ReLU activation function, which can alleviate the problem of gradient disappearance. Therefore, YOLOv3 has a faster detection rate in object detection tasks [15]. Fig. 5 shows the structure diagram of YOLOv3 set up in this paper.
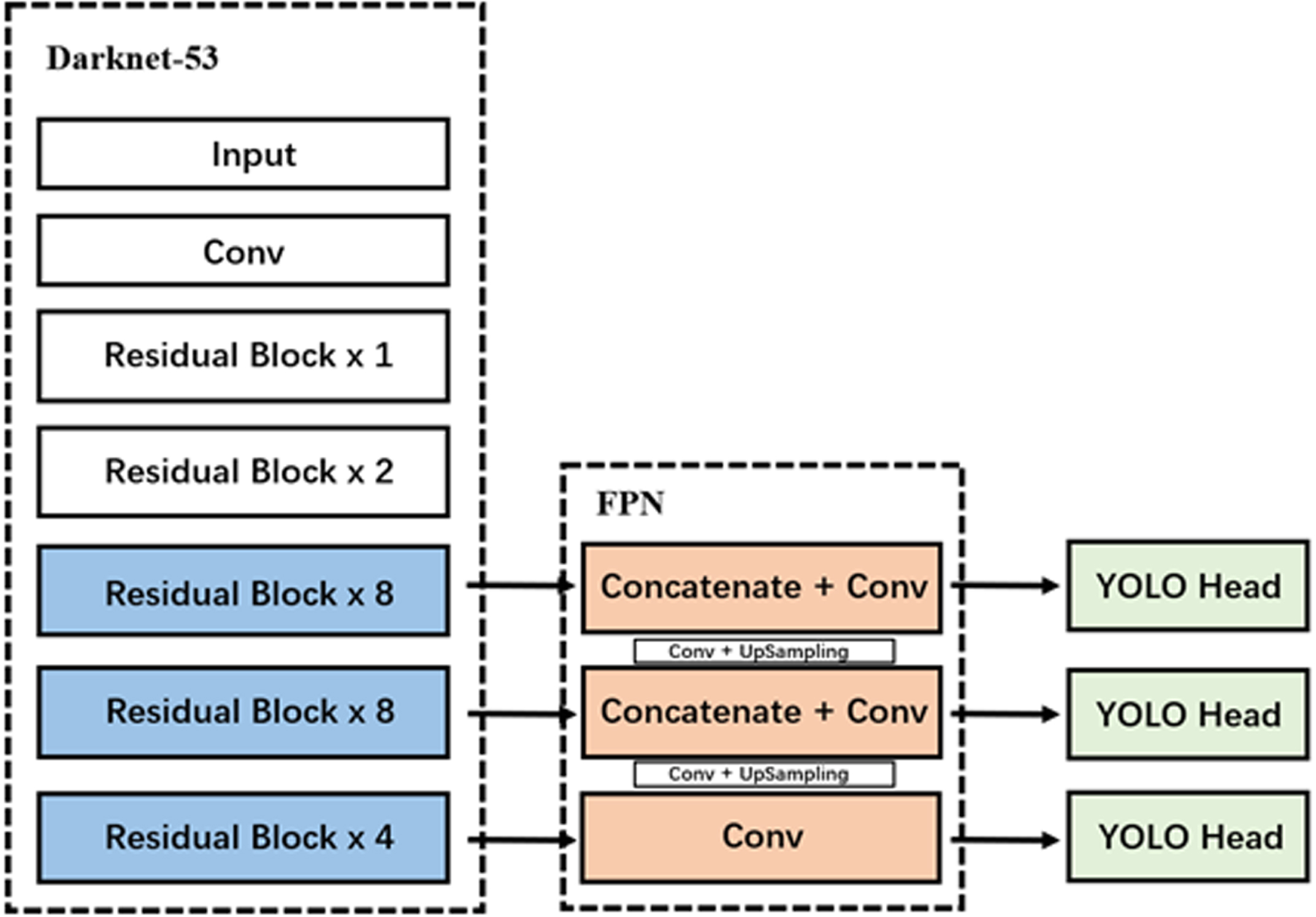
Structure diagram of YOLOv3.
Data Preprocessing and Augmentation
In the vertebrae segment matching step, we first perform vertebrae detection of C-arm image and DR image using the trained YOLOv3 model for pre-processed Dataset 1 and original Dataset 3, respectively, and then crop the vertebrae region based on the results of vertebrae detection. The cropped vertebrae images are resized to 64*128 pixels. We randomly select part of the vertebrae images in Dataset 1 and all vertebrae images in Dataset 3, totaling 416 images, and perform image augmentation through Gaussian blurring and Gaussian noise. After augmentation, the number of images is tripled, totaling 1248 images, and they are fed into the Mobile-Unet model in the 4:1 ratio of training set and test set.
Mobile-Unet Model
We use Mobile-Unet as the vertebral segmentation model. The Mobile-Unet network is based on the encoder-decoder structure of the U-Net [16] network, which is replaced by the MobileNetV2 [17] network structure in the encoder part, while retaining the original decoder structure of U-Net. U-Net was originally developed and used for biomedical image segmentation. The network consists of a contraction path on the left and an expansion path on the right, which are used for feature extraction and feature learning, respectively. Due to the fixed structure and simple image semantics of medical images, the small downsampling of U-Net results in a large degree of information reduction and enables more detailed image features to be obtained at low resolution. Meanwhile, the decoder of U-Net is able to fuse more low-level features through multiple upsampling and skip connection, so that the network can obtain more precise features at the image edges, which can effectively deal with the disadvantages of blurred edges and complex gradients of medical images [18, 19].
Since each matching requires segmentation of multiple vertebral images, which makes the matching efficiency lower compared to clinical manual matching, we use MobileNetV2 as the backbone network in the encoder part to improve the speed of model segmentation. MobileNetV2 is extended on the basis of MobileNet [20], which is an efficient lightweight convolutional neural network. MobileNet is characterized by the introduction of a depthwise separable convolution layer. Compared with standard convolution, depthwise separable convolution decomposes the convolution operation into depth wise convolution and point wise convolution, which can effectively reduce computing costs. MobileNetV2 introduces an inverted residual structure and a linear bottleneck. The inverted residual structure reduces the number of feature layer channels corresponding to the convolution kernel, thus reducing the computational effort. The linear bottleneck can embed the input into a low-dimensional subspace without using nonlinear transformation, reducing the depth of convolution and the resulting loss in accuracy [21].
Angle Correction
Due to the change of the perspective angle during the operation, the inclination degree and direction of the vertebral angle in the C-arm image and the DR image may not match. We adopt an angle correction method for the C-arm vertebral images to reduce the influence of the tilt angle on the vertebrae matching. After obtaining the vertebral segmentation result of the C-arm image, the minimum bounding rectangle of the vertebral segmentation contour is obtained first, and the parameters of the external rectangle including the length and width, the horizontal tilt angle and the center of the rectangle are calculated. Then, the center of the bounding rectangle in the original vertebral image is used as the rotation center, and the vertebral image is rotated against the tilt angle. Finally, the image is re-cropped based on the length and width of the rectangle to obtain an angle-corrected vertebral image, and the images are resized to 64*128 pixels. The angle correction process is shown in Fig. 6.

Angle correction process.
We use visual information fidelity (VIF) [22] as the similarity evaluation metric to compute multi-vertebra matching. VIF is a similarity evaluation metric based on natural scene statistics (NSS) for image evaluation from the perspective of information communication and sharing. VIF is statistically obtained from the mutual information
We adopt a multi-vertebra matching method to perform the vertebrae segment matching on the vertebral image, so as to ensure that the results are highly reliable. We first sort the vertebral regions detected in the DR image according to the horizontal position, and the last five vertebral regions are labeled as L1 to L5 from top to bottom, and the vertebral regions above L1 are labeled in descending order from T12 to top. At the same time, the vertebrae in the DR images are grouped sequentially from top to bottom based on the number of vertebrae detected in the C-arm images
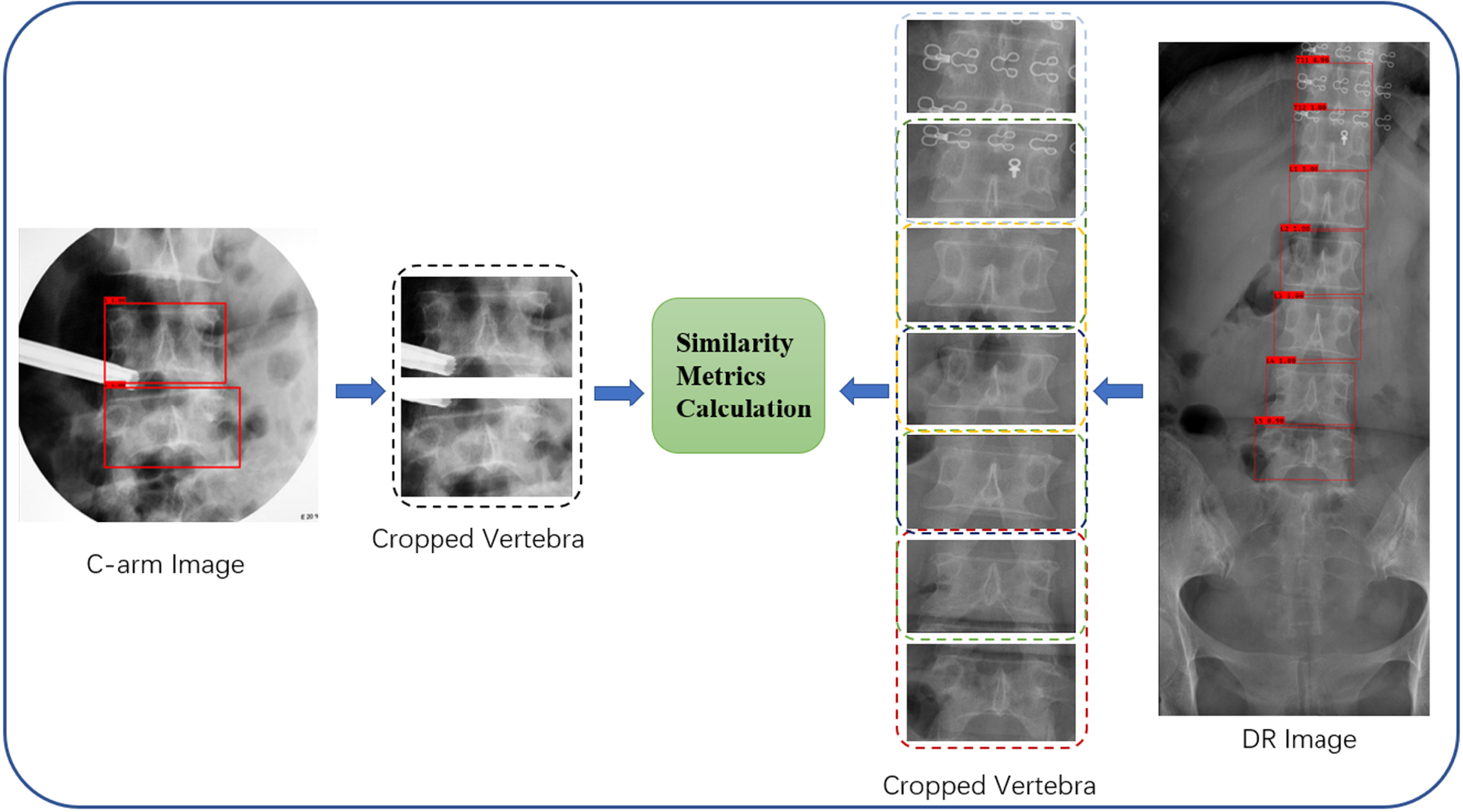
Multi-vertebra process.
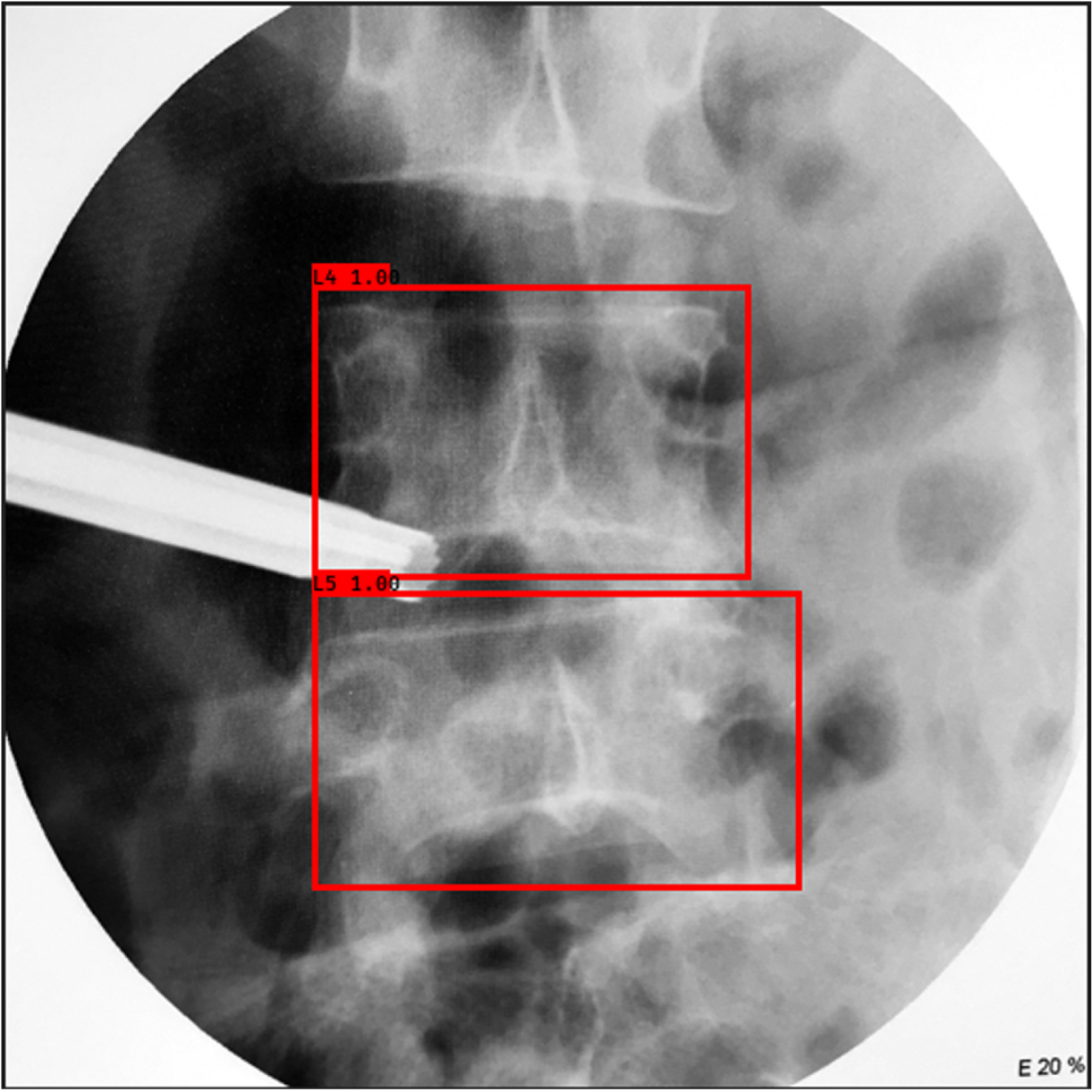
Result map (red) after image matching.
Experimental Setup
We performe all experiments in a computer equipped with an Intel i7-10700 CPU and an RTX-2070 Super graphics processor. We used the TensorFlow 1.14 deep learning framework to implement the YOLOv3 model and the Mobile-Unet model in our experiments. For the YOLOv3 model, we set the batch size to 4 and the learning rate to 0.001 in the freeze part, and set the batch size to 2 and the learning rate to 0.0001 in the unfreeze part. For the U-Net model, we set the batch size to 4 and the learning rate to 0.001. All models are trained using Adam as the optimizer and the categorical cross-entropy is used as the loss function.
Metrics
In the vertebra detection section, we use recall, F1-Score and average precision (mAP) as evaluation criteria and follow the metrics of true positive (TP, vertebra detected and matches ground-truth), false positive (FP, vertebra detected but does not match ground-truth) and false negative (FN, vertebra not detected but present in the ground-truth). Recall indicates the proportion of true positives in the overall predicted positive samples in the prediction results, which can reflect the under-prediction situation. The F1-score is calculated by combining true positives, false positives and false negatives, reflecting the boundary matching degree between the predicted results and the true value. The mAP first calculates the average precision (AP) of each class (vertebrae and background), and then averages the AP according to the number of classes N.
In the vertebral segment matching section, we use accuracy as the evaluation criterion, and the result was determined as True (T) when the predicted result in the C-arm image was consistent with the corresponding vertebral serial number in the DR image, and False (F) if otherwise.
In the vertebrae detection step, we measure the model performance with Dataset 4 as the validation set. The performance results are shown in Table 2, and the confusion matrix of vertebrae detection are shown in Fig. 9. Relatively speaking, the YOLOv3 model has better detection performance on the DR images than the C-arm X-ray images. In the detection performance of C-arm images, the YOLOv3 model obtained 0.87 mAP, 0.92 Recall, and 0.94 F1-score. In the detection performance of DR images, the YOLOv3 model obtained 0.96 mAP, 0.97 Recall, and 0.95 F1-score. Overall, the results show that VDVM has excellent performance in the vertebral bone detection task.
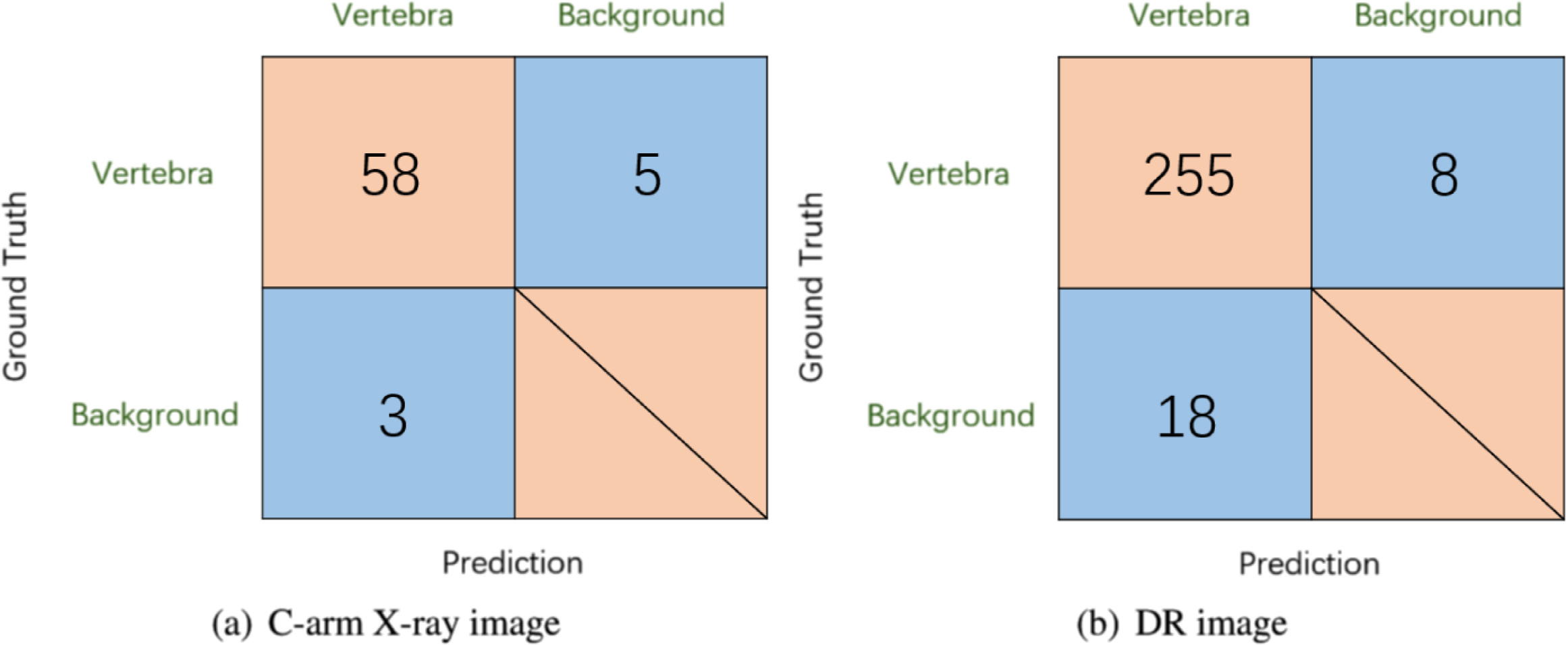
Confusion matrix of vertebrae detection.
Vertebrae detection result
In the vertebrae segment matching step, we set up a comparison experiment to examine the effect of angle correction of vertebrae on the matching accuracy. We performed similarity matching using VIF metrics for Dataset 4 without angle correction and with angle correction, as shown in Table 3, and we obtained matching accuracies of 0.65 and 0.73, respectively. The results indicate that the correction of vertebrae angle can noticeably improve the accuracy of vertebral segment matching, as well as that VDVM has adequate reliability in vertebrae segment matching. The final experimental rendering is shown in Fig. 10.
Vertebrae detection result
Vertebrae detection result
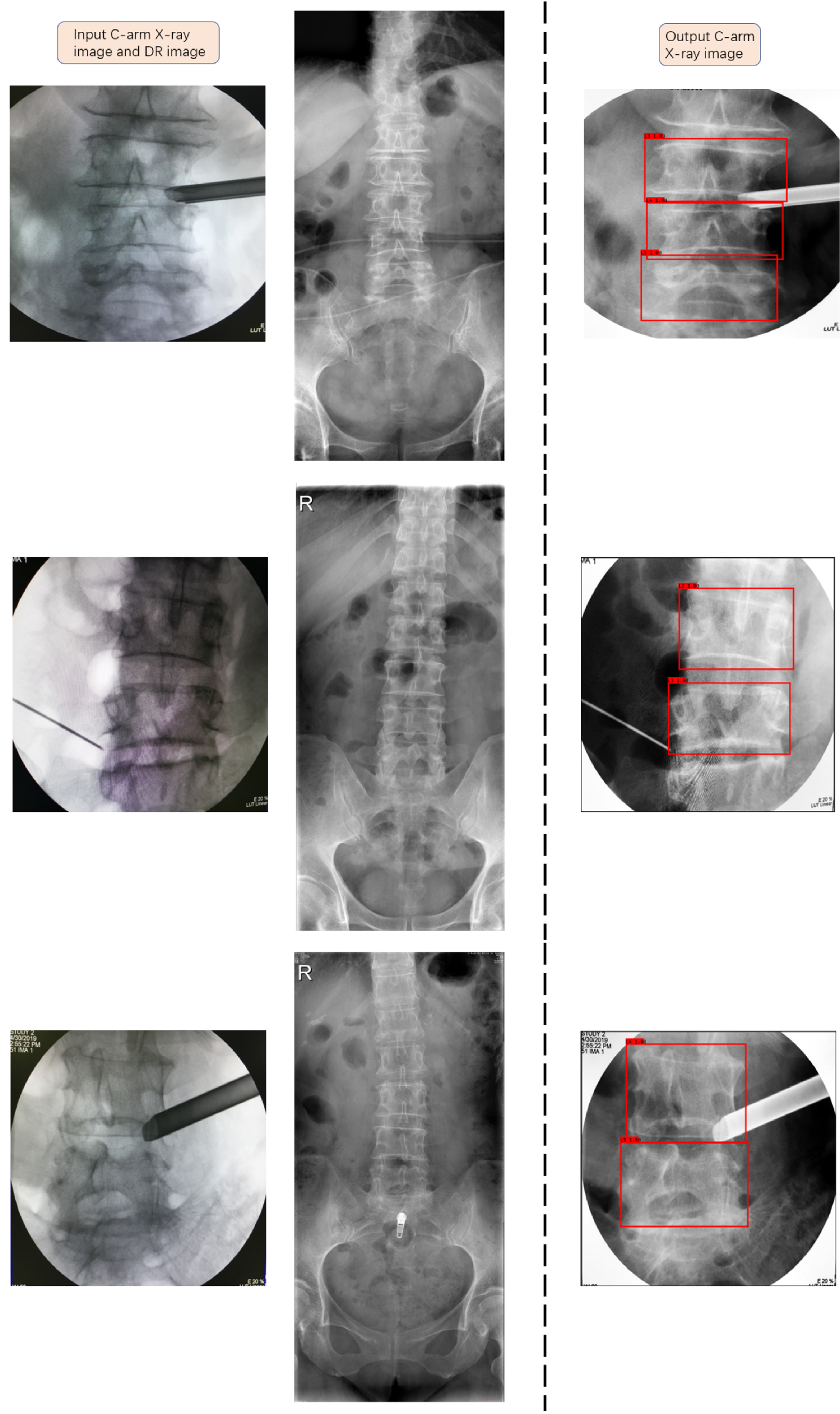
Experimental rendering.
Comparing DR images and C-arm X-ray images to determine the surgical location is a necessary step in spine surgery. Reliable C-arm X-ray image identification is of great significance for improving surgical safety and efficiency. In this research, we proposed a VDVM framework for C-arm image recognition based on deep learning methods, and examined the effectiveness of the framework through a dataset of C-arm X-ray images and DR images from the same patient. In the task of vertebra detection, we used the YOLOv3 model to detect the vertebra in the images. Since the C-arm X-ray images used for validation were obtained from mobile phones, the images have serious noise interference and image blur. We have performed image augmentation on the training set by adding Gaussian noise and Gaussian blur to make the model more robust. At the same time, the image quality is improved through the preprocessing method, and an mAP of 0.87 is obtained in the YOLOv3 model. Due to the lack of DR images, we cropped the full-length X-ray images and extracted the image area from the thoracic to the lumbar region as a simulated DR training set for training, and obtained an mAP of 0.96, which shows that the simulated training set can be effectively used for DR image detection task. In the vertebral segment matching task, we use the VIF metric to match the vertebrae. We segmented individual vertebral images based on Mobile-Unet, and performed angle correction based on the segmentation result to reduce the effect of vertebrae angle inconsistency between DR images and C-arm X-ray images. By comparing with the image matching results with the images without angle correction, it is demonstrated that vertebra correction can improve the accuracy of image matching, thereby improving the identification performance of the VDVM framework. In clinical surgery, the VDVM framework can identify C-arm X-ray images based on preoperative DR images and intraoperative C-arm X-ray images, thereby serving as an auxiliary means for clinicians to determine the area located by the C-arm X-ray machine. Comparing to previous studies, our study first applied the deep learning method to the identification of C-arm X-ray images and DR images, which expanded the application range of deep learning in C-arm X-ray images. The designed VDVM vertebra identification framework includes two parts: vertebra detection and vertebra matching, and the feasibility of the framework is confirmed through the analysis of experimental results.
There is room for further improvement in the vertebral segment matching performance of VDVM. As the C-arm images matched with the DR images were taken by mobile devices, resulting in variable image quality, the images were affected by factors including illumination, shooting angle, and noise. At the same time, due to the inconsistency of the intensity of the influencing factors, excessive and unified preprocessing will lead to blurred images and degrade the performance of the method. Therefore, we only performed median filtering in the preprocessing stage, and did not perform further processing for specific noise (ripple noise, Gaussian noise, etc.), illumination, and shooting angle. In addition, due to the influence of the perspective angle and intraoperative landmarks in the C-arm image itself, the vertebral shape in some images is very different from that in the DR image, and effective matching information cannot be obtained in a limited range of vertebrae. Finally, this experiment only used the front view of the image and did not use the lateral view of the image, and some vertebral information has not been effectively used.
Conclusions
In this study, we propose a new C-arm X-ray image identification framework VDVM, which includes two steps of vertebral detection and vertebral segment matching. The experimental results show that the framework can provide an accurate identification result. In the vertebral segment matching task, there is still room for further improvement in the accuracy of vertebral segment matching. In future work, we will further research the vertebral segment matching task in the direction of metric improvement, further improvement of image quality, and combined evaluation using front and lateral views.