
Abstract
BACKGROUND:
Recently, one promising approach to suppress noise/artifacts in low-dose CT (LDCT) images is the CNN-based approach, which learns the mapping function from LDCT to normal-dose CT (NDCT). However, most CNN-based methods are purely data-driven, thus lacking sufficient interpretability and often losing details.
OBJECTIVE:
To solve this problem, we propose a deep convolutional dictionary learning method for LDCT denoising, in which a novel convolutional dictionary learning model with adaptive window (CDL-AW) is designed, and a corresponding enhancement-based convolutional dictionary learning network (called ECDAW-Net) is constructed to unfold the CDL-AW model iteratively using the proximal gradient descent technique.
METHODS:
In detail, the adaptive window-constrained convolutional dictionary atom is proposed to alleviate spectrum leakage caused by data truncation during convolution. Furthermore, in the ECDAW-Net, a multi-scale edge extraction module that consists of LoG and Sobel convolution layers is proposed in the unfolding iteration, to supplement lost textures and details. Additionally, to further improve the detail retention ability, the ECDAW-Net is trained by the compound loss function of the pixel-level MSE loss and the proposed patch-level loss, which can assist to retain richer structural information.
RESULTS:
Applying ECDAW-Net to the Mayo dataset, we obtained the highest peak signal-to-noise ratio (33.94) and sub-optimal structural similarity (0.92).
CONCLUSIONS:
Compared with some state-of-art methods, the interpretable ECDAW-Net performs well in suppressing noise/artifacts and preserving textures of tissue.
Keywords
Introduction
Although X-ray computed tomography (CT) has been applied in medical imaging for the past decades, the radiation dose delivered to patients is raising more concerns. X-ray may lead to potential determinist and stochastic risks, such as genetic or cancerous diseases [1], thus X-ray CT radiation dose is required as low as reasonably achievable. However, low-dose CT (LDCT) images reconstructed by traditional methods, for example, filtered back projection (FBP), are contaminated with noise and streak artifacts. There are three categories to improve LDCT images: sinogram filtering technique, iterative reconstruction, and image post-processing after reconstruction. Since the post-processing method does not need to access projection data and does not depend on the scanning geometry of CT system, it has better portability. Therefore, how to estimate high-quality images from LDCT images has attracted increased attention. In this work, we focus on the post-processing category.
In the past decade, some excellent image processing techniques have been used in LDCT image processing, such as non-local means [2], block-matching 3D (BM3D) [3] and dictionary learning [4]. However, these traditional methods always suffer from difficult parameter setting issue and perform over-smoothing in the denoised images or introduce additional artifacts [5]. In recent years, deep learning has achieved great success in the field of image denoising. A growing number of researchers are exploring the role of convolutional neural network (CNN) in LDCT image processing [6, 7]. Chen et al. [8] suppressed noise and artifacts by using a CNN with an Encoder-decoder structure (REDCNN), which has slight model parameters and satisfactory inference time, but the noise removal capability is limited. Fan et al. [9] adopted quadratic neurons to construct an encoder-decoder structure, referred as the quadratic autoencoder (QAE), and improved model efficiency in LDCT denoising. By extracting the directional components of artifact via the directional wavelet transform, Kang [10] proposed a wavelet domain deep learning algorithm (WavNet) to suppress CT-specific noise, but some of the textures are not fully recovered. Later he proposed a wavelet domain residual network (WavResNet) to fully recover textures [11] and got improvements in both qualitative and quantitative analysis. Due to the irregular distribution of noise and artifacts in LDCT images, these two wavelet-based networks show some limitations, such as inferior denoising performance (blurred edges and details). To improve the ability to protect anatomical structures and textures in the process of denoising, Geng et al. [12] applied the content-noise complementary learning (CNCL) strategy and proposed a generative adversarial network (GAN), which demonstrated a robust generalization capability. Han et al. [13] proposed a GAN with a dual-encoder-single-decoder structure, in which a pyramid non-local attention module is designed in the main coding branch. Marcos et al. [14] proposed a GAN composed of spatial attention module and channel attention module. However, the unsatisfactory ability of noise description and unstable training process still surround GAN frameworks [5]. In [15], Liang et al. proposed EDCNN based on edge enhancement and dense connections. Benefiting from a trainable Sobel convolution, the quality of CT images processed by EDCNN is significantly improved. Jiang et al. [16] applied the frequency separation network to respectively recover the low and high frequency components in LDCT denoising and achieved inspiring noise/artifact removal while retaining the detailed information. Although CNN-based methods achieved promising results, they lack intuitive explanation because the process of fitting the mapping function is abstract [17–19].
Based on the cost function composed of data fidelity term and regularization terms, convolutional dictionary learning [19] is a good strategy to understand the logic of model optimization. The convolutional dictionary learns to represent images by utilizing convolution operation of a set of filters and their corresponding feature maps. After iterations of the cost function, the estimated image gradually approaches the optimal result through an optimization algorithm. Zheng [17] unfolded the iterations in convolutional dictionary learning using deep learning and proposed a framework of deep convolutional dictionary learning (Dcdicl) for Gaussian noise reduction in nature images and acquired sufficient interpretability and noise suppression. Wang et al. [18] adopted a concise rain convolutional dictionary model (RCDNet) to encode rain shapes and got inspiring de-raining performance. Fu et al. [20] proposed a model-driven deep unfolding method for JPEG artifacts and generated competitive deblocking results. Li et al. [21] used an online multi-scale convolutional sparse coding model to encode the snow in video, and finely delivered the sparse scattering and multi-scale shapes of real snow. Wang [22] also adopted the strategy of convolutional dictionary to represent metal artifacts in CT images. Liu et al. [23] combined the advantages of residual convolution network and convolutional dictionary learning and proposed an LDCT denoising model (DRCSC) to recover the high-frequency information. But their model still violates the mathematical constraint (convolutional dictionary D and DT are the rotation of each other), thus the interpretation is limited. Furthermore, they did not compare with some leading CNN methods, such as EDCNN. In our previous study [24], we proposed a transfer learning densely connected convolutional dictionary learning (TLD-CDL) framework for LDCT denoising, which has a good balance between noise reduction and the preservation of details.
It is worth noting that the convolution kernel and convolutional dictionary atom can be regarded as a special filter with a rectangular window of amplitude one, and its small size makes it susceptible to spectral leakage. Spectral leakage refers to the generation of additional amplitudes in multiple frequency bands. To solve the problem, Tomen et al. [25] suggested applying the standard Hamming window and proved that the convolution kernel employing Hamming window increases classification accuracy and improves robustness.
Inspired by the pioneering studies of convolutional dictionary learning and spectrum leakage, we propose a new convolutional dictionary learning with adaptive window (CDL-AW) to encode noise/artifacts in LDCT images, in which adaptive window is designed to solve the spectrum leakage. Then we propose an enhancement-based convolutional dictionary network with adaptive window (ECDAW-Net) to achieve the solution of CDL-AW model. At the same time, a multi-scale edge extraction module composed of trainable LoG and Sobel convolution layers is designed to suppress edge/texture blurring in the iterative process. And the compound loss is used to train the ECDAW-Net to further prevent the excessive smoothing of the image.
The remainder of this paper is organized as follows. Section 2 reviews convolutional dictionary learning and spectral leakage. In Section 3, the proposed CDL-AW model and ECDAW-Net are elaborated, including the proposed adaptive window, the optimization procedure, as well as the multi-scale edge extraction module. In Section 4, the experimental designs and representative results are given. Finally, we will discuss relevant issues and conclude this paper in Section 5.
Related work
Convolutional dictionary learning
Many CNN-based noise reduction methods aim to estimate the mapping function T from X to μ:
where X ∈ RH×W and μ ∈ RH×W are LDCT image and its noise/artifacts. However, the end-to-end direct mapping in (1) is not suitable, as the noise/ artifacts in LDCT images are related to the real signal and the denoised results are easy to be blurred. In addition, the noise reduction network constructed by (1) is unexplainable for LDCT denoising because of the difficulty in understanding the logic of internal operation mechanism.
In contrast, dictionary learning has a clear physical meaning (clear mathematical formula) for image denoising. Convolutional dictionary learning decomposes an image by using convolution operation instead of matrix multiplication used in patch-based dictionary learning [4]. The noise μ in LDCT image, with the size of H×W, can be represented as the summation of convolutions between a set of filters (also called convolutional dictionary) and their corresponding feature maps:
where ⊗ denotes convolution, D i ∈ Rk×k and Z i ∈ RH×W are the i-th filter (or convolutional dictionary atom) and its corresponding coefficient map, respectively. The optimal estimations of {D i } i=1,2,...,N and {Z i } i=1,2,...,N can be obtained by solving the following minimization problem:
where ‖Z i ‖ 1 is the regularization term and λ Z is the weighted parameter. This convolutional optimization strategy overcomes the redundancy of traditional patch-based dictionary learning and avoids the loss of underlying structure caused by image block vectorization. Several optimization methods can be used to solve the objective function in (3), including iterative shrinkage-threshold [26], alternating direction method of multipliers [27] and half-quadratic splitting [28].
Although the convolutional dictionary learning in (3) can obtain rotation-invariant features, it may be limited in some further applications [17, 24, 25, 29]. One reason is that the handcrafted sparse prior (e.g., L1 sparsity in (3)) is fixed, and the other reason is that it neglects analysis of dictionary filters design (e.g., size and shape) in the solution process.
Under the signal theory: the short signal observed in a finite window can be regarded as a long signal truncated by a rectangular window with an amplitude of 1, and the product of the signal itself and the spatial rectangular window is the convolution of their spectrum. Because the window function cannot be infinitely wide, that is, the spectrum cannot be an impulse function, the convolution in the frequency domain will inevitably produce broadening and sidelobe, which is called spectrum leakage. The two-dimensional convolution kernel can be thought of as being truncated by two one-dimensional rectangular windows of magnitude 1 by the product operation, thus the frequency domain characteristics of the rectangular signal will cause the dictionary kernel to have spectrum leakage in the frequency domain. The rectangular leakage may reduce the signal-to-noise ratio and blur the image. Convolutional dictionary atoms can be regarded as special filters with rectangular windows, which are easily affected by spectrum leakage in the process of truncated filtering. For this reason, the convolutional dictionary atom can be constrained designing a two-dimensional adaptive window function, and the image blur caused by spectrum leakage thus can be effectively alleviated.
As the rectangular function imports window artifacts to the frequency response in the form of “ripples”, Tomen [25] proposed to solve spectral leakage in CNNs by introducing the 2-dim Hamming window. The 1-dim Hamming window is defined in (4) and the 2-dim Hamming window is the outer product of two 1-dim Hamming windows.
where σ = 25/46 and M is the discrete sample. However, hand-designed window functions cannot get rid of the hyper-parameters, which often need to be manually adjusted according to the tasks.
Although the use of well-designed window functions to reduce spectral leakage is not new, its application in the systems based on convolutional dictionary learning has been ignored. The rich textures of CT images are distributed in different frequency bands, so spectrum leakage will inevitably dispute the visual performance. To fill this gap, we propose an adaptive window and incorporate it into the denoising model based on convolutional dictionary learning, namely the CDL-AW model, then design a convolutional dictionary network (ECDAW-Net) to realize the solution of the proposed CDL-AW model.
Adaptive window
Different CT images have different spectral characteristics, the window function with fixed parameters is difficult to fit all CT images, and the optimal parameters need to be debugged and determined repeatedly. Instead of using the standard Hamming window, we propose the adaptive window w by utilizing an adaptive coefficient matrix α to the 2-dim Hamming window wHam, namely,
where × and ⊙ are outer product and Hadamard product, α is a coefficient matrix which determined by the size of Hamming window. Taking M = 3 as an example, α has nine elements to adjust the Hamming window, as shown in Fig. 1(a). We get the adaptive α by setting it as a tensor with gradient information, thus it can be updated in the process of network backpropagation. In the process of convolutional sparse coding, the convolutional dictionary atom and w are multiplied by elements, which helps to make the truncated region smoother. In specific applications, the value of M is determined by the size of the convolutional dictionary atom. Figure 1(b) shows the process of a randomly assigned convolutional dictionary {D
i
}
i
= 1,2,…,N constrained by a set of adaptive 2-dim window {w
i
}
i
= 1,2,…,N, and the convolutional dictionary with adaptive window
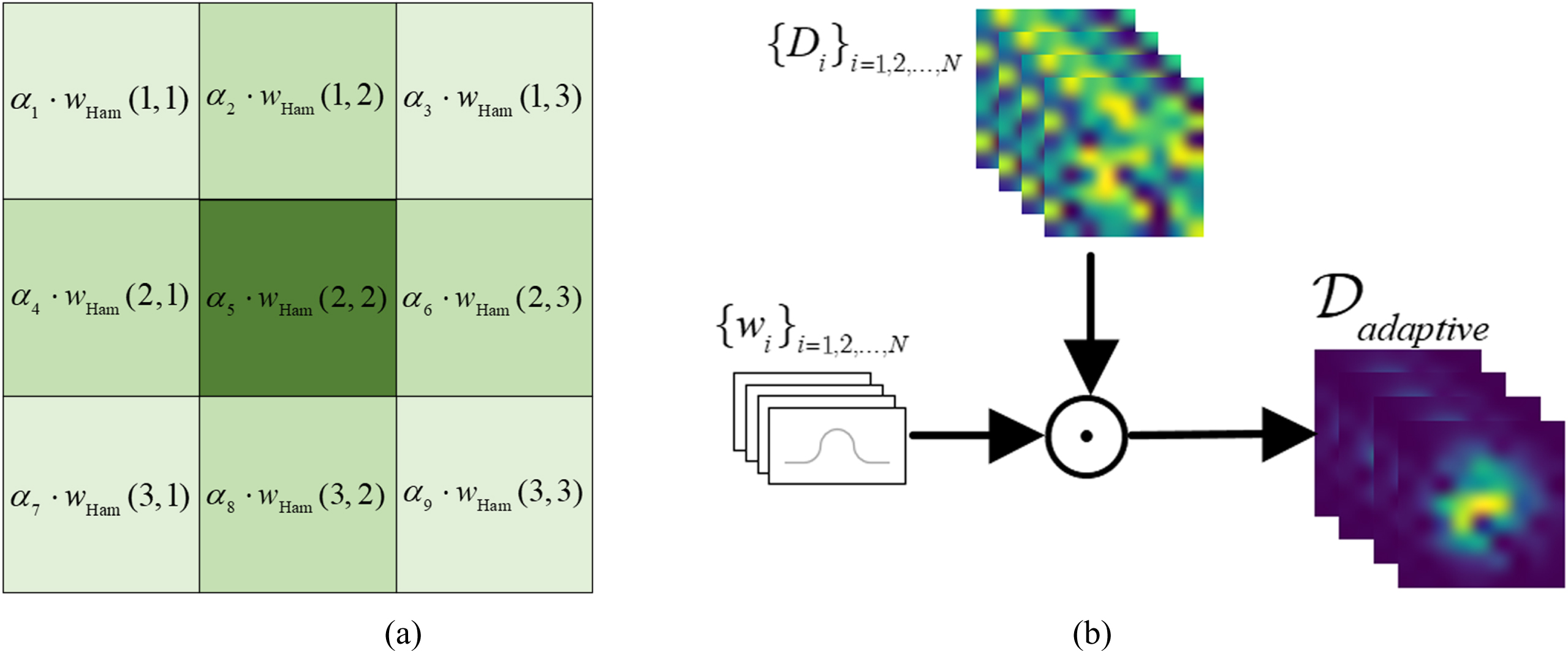
The windowing operation. (a) the adaptive window and (b) convolutional dictionary with the adaptive window.
where w
i
and D
i
can be constantly updated through network training. Thus, the
Like the noise model in (2), we sparsely represent noise and artifacts by the proposed
Then, the convolutional dictionary learning with adaptive window (CDL-AW) is proposed to predict the clean image Y from noisy image X by following minimization problem:
where
where
Moreover, by substituting
we can obtain the updating formulas (10-1) and (10-2) as:
where ⊗ T denotes the transposed convolution, prox (·) is the proximal operator dependent on the regularization terms. The solving process of CDL-AW is depicted in Algorithm 1:
The traditional methods of solving the proximal operator often require a complex computational process, such as the work in [29]. Therefore, we unfold the optimization algorithm iteratively by adopting two networks to construct the proximal operators, then propose the ECDAW-Net architecture.
1) Network design
As shown in Fig. 2, the proposed ECDAW-Net consists of S stages, corresponding to S iterations of the Algorithm 1 for solving (9). In each stage, we designed two networks,

The iteration process of ECDAW-Net.
Except for windowing, signals with a narrower spatial domain are more susceptible to spectral leakage, and the expansion of spatial width may help to acquire sharp boundaries. To extend the spatial width of convolution kernel in

The hybrid dilated module.
Especially, we elaborately designed the process marked by dotted rectangle in Fig. 2. Unlike the
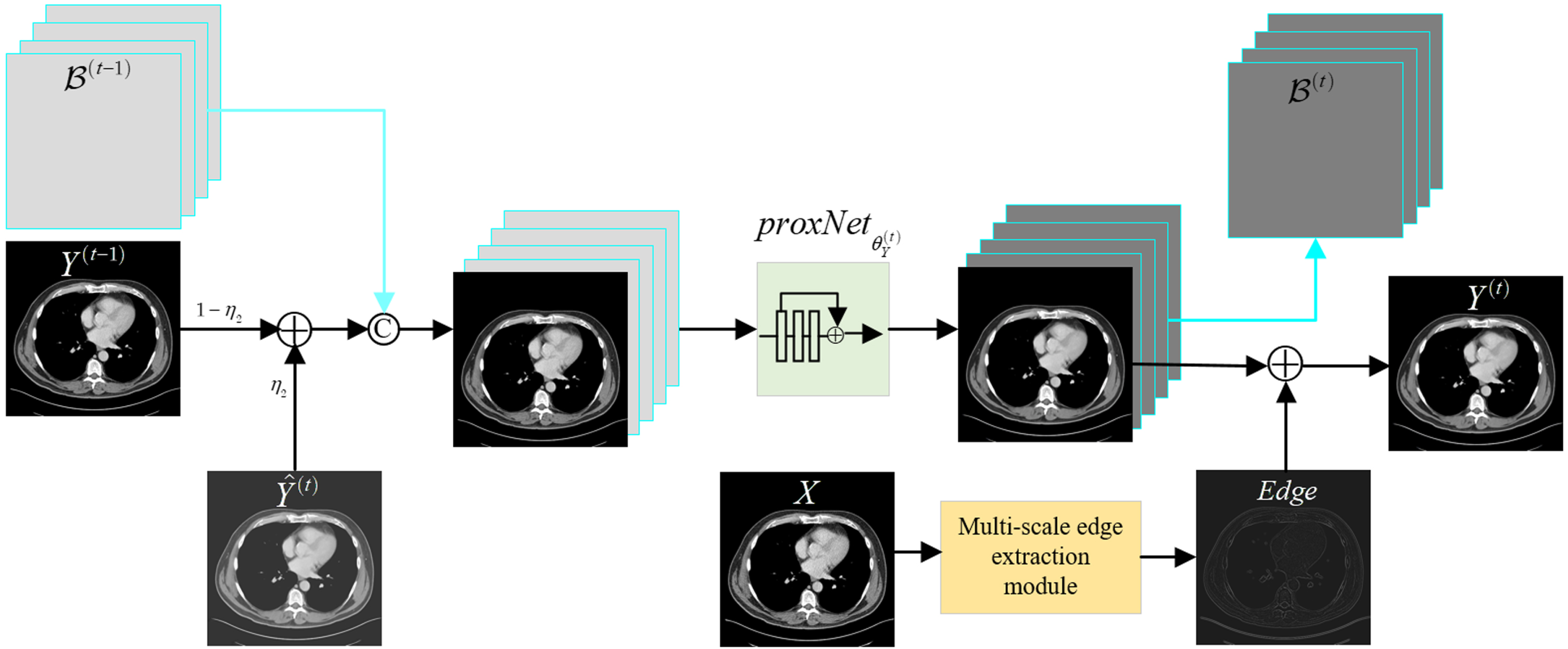
The process in red dotted rectangle in Fig. 2.
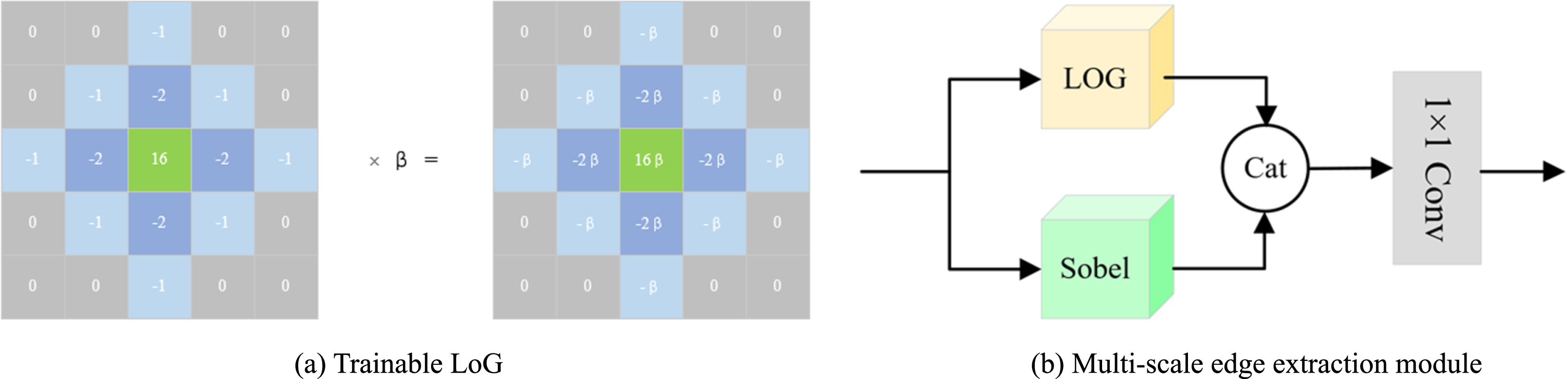
The multi-scale edge extraction module.
2) Training phase
equation 15 In the training phase, according to experimental experience, the number and the size of convolutional dictionary atom is 32 and 9×9, respectively. Too many convolutional dictionaries will not significantly improve performance but increase memory usage. A set of small convolution dictionaries are difficult to effectively represent streak artifacts, while the excessive size will affect the reference time of the model. Then, the convolutional dictionary is initialized with the random value between [0, 0.2]. The proposed adaptive window (M = 9) has the same number of channels as the convolutional dictionary. Besides, we set
where
The configuration of the proposed moudle (f: kernel size, s: stride, p: padding, d: dilation rate)
The compound loss
where τ is the weight parameter and set to 0.01 in this study, l Patch is the proposed local energy consistency loss based on image blocks, which is defined as the L1 norm of “local energy graph difference” between input I and output O. The energy graph is defined as follows:
where Nx,y is a neighborhood of the pixel (x, y). With the patch-level loss l Patch , the over-smoothing caused by pixel-level loss MSE is alleviated to some extent. To reduce the number of model parameters and the inference time, the total loss function only involves the sum of the errors in the first layer and the last layer. The total loss is weighted by the following stages:
where λ is the weight parameter. We assign less weight to the first stage to prevent its larger loss from weakening the role of subsequent stages, while higher weight for the last stage. Through trial-and-error experiments, λ1 = 0.1, λ2 = 0.9, and λ3 = 1 in this study.
All the experiments were implemented in Python with the Pytorch library. Equipped with a Linux computer (Intel Core i7-9700K CPU, RAM 32 G, NVIDIA GeForce RTX 2080 SUPER), we used the NVIDIA CUDA10.1 to accelerate the training processing.
In this section, we first describe the experiment setting. Then we compare our proposed method with other existing methods. Finally, we introduce the ablation study.
Experimental setting
We compare ECDAW-Net with the traditional method, typical leading deep learning-based methods, and the convolutional dictionary learning-based method, including, K-SVD [4], REDCNN [8], EDCNN [15], CTformer [35], QAE [9], CNCL [12] and TLD-CDL [24]. In particular, CTformer is the first pure Transformer architecture for LDCT denoising. For a fair comparison, we trained all networks with our training data. The dataset from “the 2016 NIH-AAPM-Mayo Clinic Low Dose CT Grand Challenge” [32], authorized by Mayo Clinic, and the Piglet dataset [33] are utilized to train our model. The Mayo dataset includes paired LDCT and corresponding normal-dose CT (NDCT) images with size of 512×512, collected from 10 patients. 760 pairs of CT images from 9 patients were randomly selected as the training datasets, and 35 images from one patient were randomly selected as the testing dataset. Furthermore, the proposed method was also evaluated on the piglet dataset from a GE scanner (Discovery CT750 HD), in which the images obtained under 300mAs are as the normal dose, and images with a range of different does (50%, 25%, 10%, and 5%) are LDCT images [34]. 400 pairs of piglet images (150mAs and 300mAs tube current) are randomly selected as the training dataset, and 50 images were selected from images with dose 25%, 10%, and 5%, respectively. In addition, we also tested our model on 40 real clinic LDCT images, which was approved by our hospital’s ethics committee.
For the Mayo and Piglet datasets, we judged the performance of the model by multiple quantitative measures as well as subjective evaluations by two radiologists. For clinical data, the subjective evaluation of two radiologists is directly relied upon. Six quality metrics are utilized for objective evaluation comparison between our ECDAW-Net and other methods mentioned above. The quality metrics include peak signal-to-noise ratio (PSNR), structural similarity (SSIM) [36], gradient magnitude similarity deviation (GMSD) [37], feature similarity (FSIM) [38], visual information fidelity (VIF) [39] and its multi-scale pixel domain implementation (VIFs) [39]. SSIM computes the product of luminance similarity, contrast similarity, and structural similarity, then predicts the image local quality at a position. A higher SSIM means better similarity between the denoised image and the reference image. FSIM combines the similarities of phase congruency maps and gradient magnitude maps between the reference and the processed image. VIF quantifies the information that could ideally be extracted by brain, and its score indicates the amount of shared information between the reference and processed images. As same as SSIM, the higher values of FSIM and VIF mean better image quality. GMSD indicates the pixel-wise similarity of the gradient magnitude maps between the reference and processed images, and a good processed result has a low GMSD score. The implementation of these comparison procedures is based on their official codes, and their parameters are set according to the recommendations of the papers.
Comparison with other methods
Mayo experiments
1) Visual assessment
Figures 6, 7 show the processed results of two representative slices (denoted as Case1 and Case2) from the Mayo test dataset by different methods. All CT images in axial view are displayed in the window [-160,240] HU. We also zoom three ROI (region of interesting) areas (marked by rectangles in Figs. 6(a) and 7(a)) for better comparison, as shown in Fig. 8. ROI1 and ROI2 are related to lesions and marked respectively by red and blue circles in Fig. 8, ROI3 shows soft tissue. From the NDCT images (Figs. 6(b) and 7(b)), we can observe clear lesions, but they are contaminated by serious artifacts and noise in the LDCT images, as shown in Figs. 6(a) and 7(a), thus are difficult to be outlined precisely. The denoising performance of KSVD is not significant (as shown in Figs. 6(c) and 7(c)), which acquired over-smoothing results (as shown in Fig. 8(c1)-(c3)). REDCNN shows a certain noise suppression, as shown in Figs. 6(d) and 7(d). From the images (e) in Figs. 6, 7, we can see that the result of EDCNN is more satisfactory in edge preserving, but the streak artifacts in ROI2 are still not completely suppressed (see the details marked by arrows in Fig. 8(e2)). Images (f) in Figs. 6, 7 show that CTformer can significantly suppress noise and artifacts, however, the lesions in ROI1 and ROI2 lost sharp boundaries (see (f1) and (f2) in Fig. 8). Results (g) and (i) in Figs. 6, 7 show that QAE and TLD-CDL removed most speckle noise in LDCT images, but still cannot remove artifacts effectively (see details in Fig. 8(g2) and (i2)). In contrast, CNCL and our ECDAW-Net obtain better results with effective noise/artifact removal and tissue/structure preserving. The contours of lesions in ROI1 and ROI2 (as shown in Fig. 8(h1)-(h2) and 8(j1)-(j2)) can be readily recognized. In addition, both CNCL and ECDAW-Net have satisfactory soft tissues in ROI3 (as shown in Fig. 8(h3) and 8(j3)), while textures of ECDAW-Net are the clearest. These results demonstrate that ECDAW-Net has an outstanding capacity for texture preservation and noise suppression.
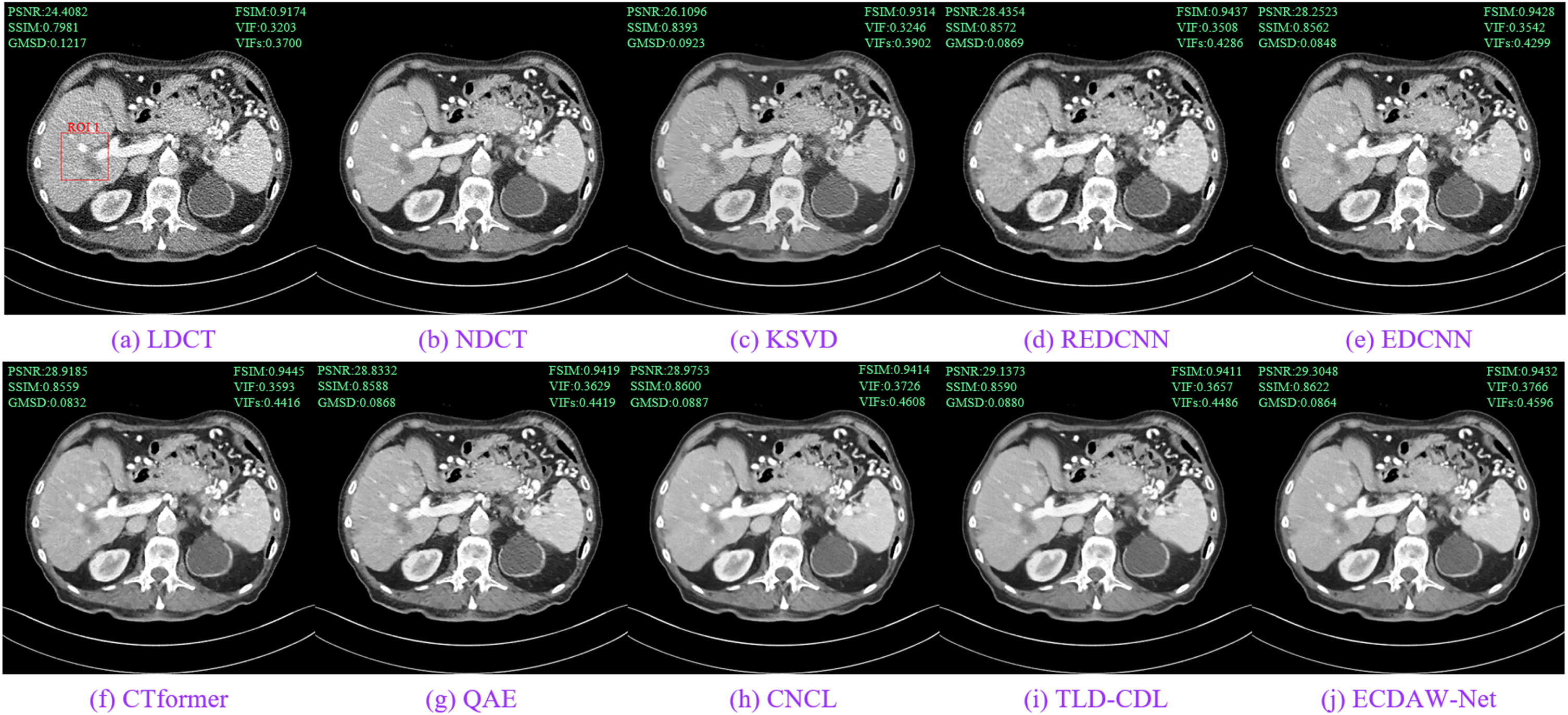
Comparison of processed images by different methods for Case1.

Comparison of processed images by different methods for Case2.

2) Quantitative assessment
Six objective metrics were used to evaluate the denoising performance of the proposed ECDAW-Net, and several competing denoising methods for objective comparison. The values of six metrics are tagged in the left-upper and right-upper corners in the images in Figs. 6, 7. In addition, all methods were conducted on 35 LDCT images from the test dataset. Table 2 shows the average values of metrics on all processed LDCT images obtained by different methods. The best and second-best values are indicated in red and blue, respectively. From Table 2, CNCL and KSVD are inferior on PSNR, but the gaps with KSVD, REDCNN, and EDCNN in other quantitative metrics are very small. For VIF and VIFs, KSVD and REDCNN have the lowest scores, which are consistent with the visual judgment of images over-smooth and low contrast. Although CNCL got inferior on PSNR, its SSIM, VIF, and VIFs have satisfactory values. QAE and CTformer are superior to the two typical CNN-based methods above. TLD-CDL and ECDAW-Net are ahead of other methods in all indicators, which proves that convolutional dictionary learning has an inspiring prospect in the domain of LDCT post-processing. Especially, ECDAW-Net has the best value for several metric, indicating that ECDAW-Net can achieve good noise/artifact suppression (PSNR), feature information preserving (FSIM, VIF, and VIFs), and its result is close to the corresponding NDCT image (GMSD).
Quantitative results of the different algorithm
To compare the distribution characteristics of different methods on the test dataset, we analyzed PSNR and SSIM through boxplots, as shown in Fig. 9. Boxplot summarizes a set of data through five statistics: maximum, minimum, the lower and upper quartiles, and the median values. By observing the widths of boxes and the distribution range of PSNR and SSIM in Fig. 9, we can conclude that the ECDAW-Net acquires superb robustness. From the perspective of gray line (median value) in the boxplots, different denoising methods are in the following order: (PSNR) EDCNN < KSVD < CNCL < REDCNN < CTformer < QAE < TLD-CDL < ECDAW-Net, (SSIM) EDCNN < KSVD < REDCNN < CTformer < QAE < CNCL < TLD-CDL/ECDAW-Net. The highest median values confirm the average quantization performance of ECDAW-Net.
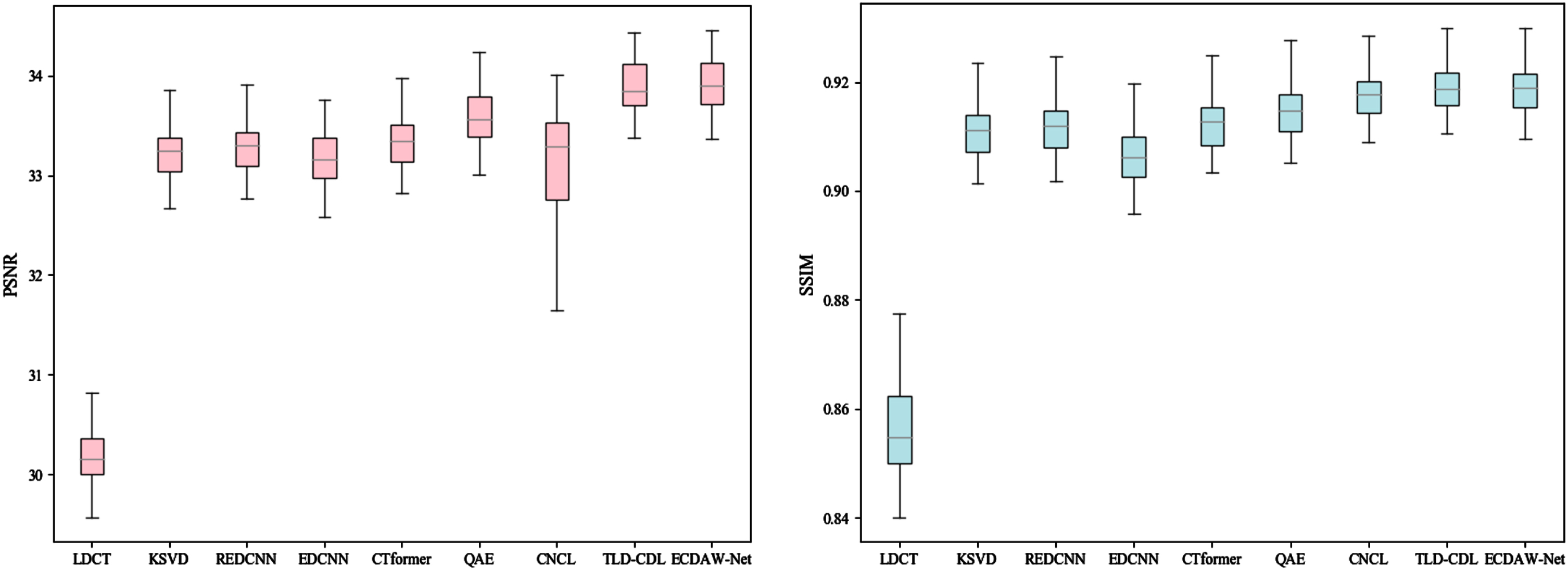
Boxplot of denoised results using different denoising methods on AAPM testing set.
Given that doctors tend to focus on ROIs related to medical diagnosis, we also quantify the performance of each method in ROIs using PSNR and SSIM, as shown in Fig. 10. Comparing the PSNR of each method in the same ROI, the proposed ECDAW-Net always has the leading quantitative performance. For SSIM, although there is no obvious difference in ROI1, ECDAW-Net is significantly ahead in ROI2 and ROI3. Although the EDCNN has a similar edge enhancement module and has SSIM scores that compete with the proposed ECDAW-Net, ECDAW-Net has higher PSNRs. Therefore, our ECDAW-Net outperforms all competing methods qualitatively and quantitatively, in the whole image and local regions as well.

Quantitative performance of three ROIs in Fig. 8.
In addition, we visualize PSNR and SSIM curves of models after different epochs on the test dataset, as shown in Fig. 11. Contrasted with those comparison methods which are trained nearly 100 epochs, it is seen that after only 20 epochs, our model acquires satisfactory performance, which demonstrates the efficiency of our strategy.
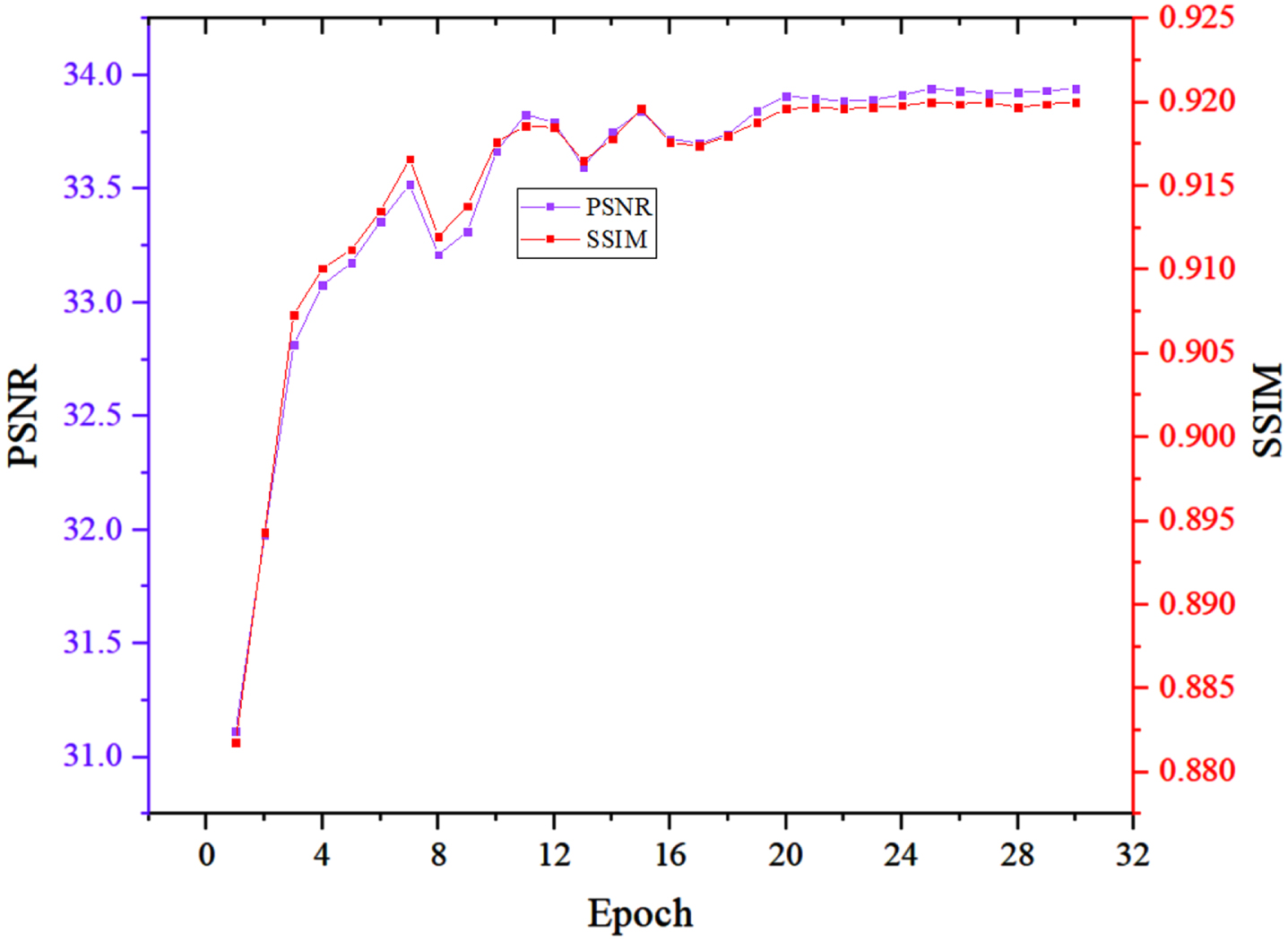
Visualization of PSNR and SSIM curves along with epoch on the test dataset.
1) Visual assessment
Figure 12 shows the processed results of the representative piglet slice (denoted as Case3) under different doses (50%, 25%, 10% and 5%) by different methods. All CT images are displayed in the window [40,400] HU. It shows that KSVD acquires over-smoothing results (as shown in Fig. 12(a1) and (b1)). Since we trained the dataset of 150mAs LDCT images, the CNN-based methods and convolutional dictionary-based methods can maintain a certain denoising performance when the test images are from datasets of 50% dose and 25% dose. In detail, REDCNN, CTformer and QAE blur details, see (a2), (a4) and (a5) in Fig. 12. EDCNN retains edges and details, but is inferior on noise suppression. TLD-CDL leads to over-smoothing in Fig. 12(a7) and (b7). The results of CNCL and the proposed ECDAW-Net are close to the corresponding NDCT image, when the tube current are 150 mAs and 75 mAs (as shown in Fig. 12(a6)-(b6) and (a8)-(b8)). However, when images are heavily polluted (30mAs and 15mAs), all methods cannot achieve satisfactory results.
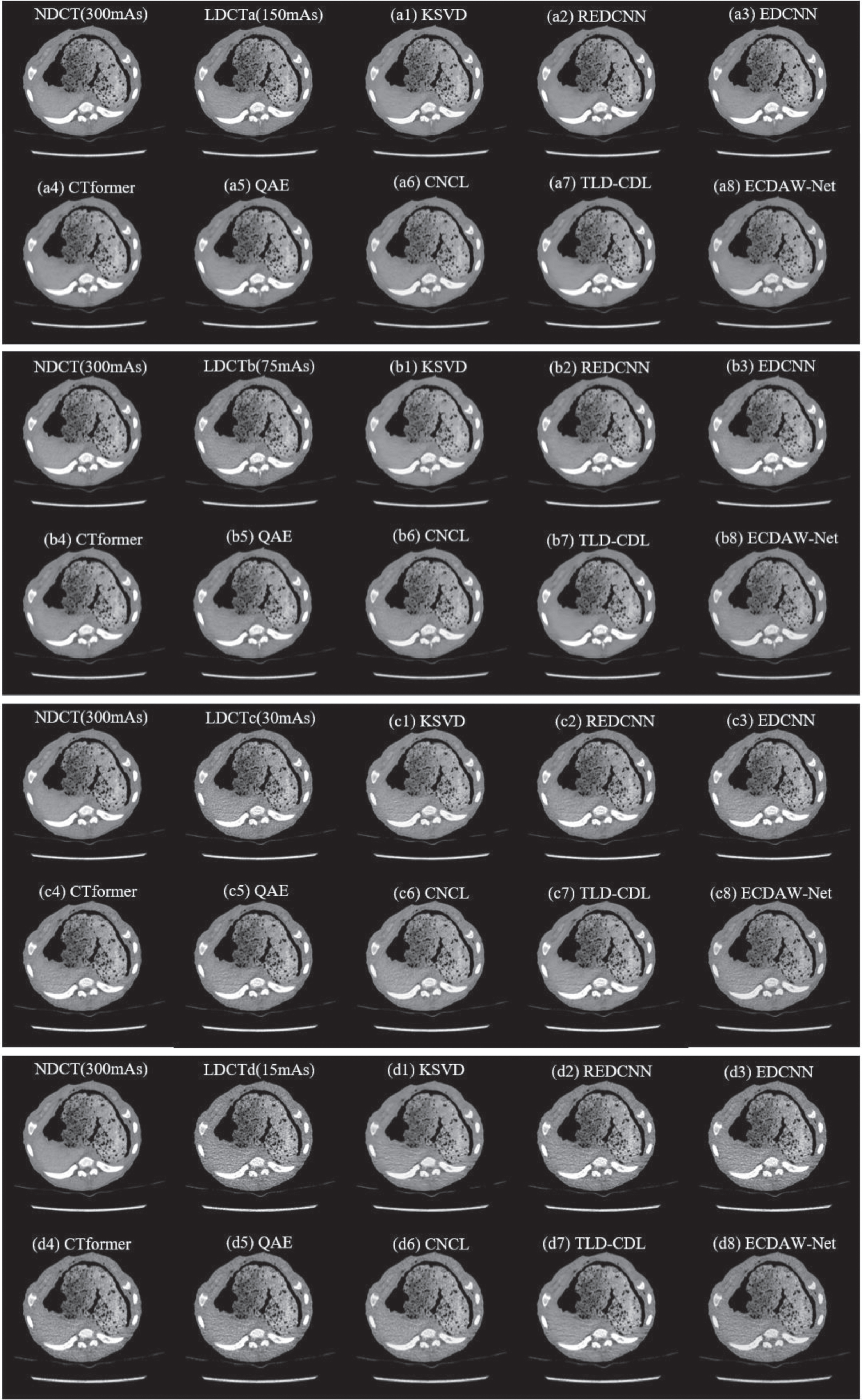
Comparison of processed images by different methods for Case3 on the Piglet dataset.
2) Quantitative assessment
Table 3 shows the average quantitative performance obtained by implementing the robustness verification experiments on the whole Piglet dataset. The best and second-best values are indicated in red and blue, respectively. The performance of KSVD and CNCL are inferior on PSNR, although CNCL gains the optimal and suboptimal values in some other indicators. REDCNN, EDCNN, CTformer, QAE and TLD-CDL are very close in all indicators, which is consistent with the visual judgment. When the noise is not very strong (150mAs and 75mAs), the proposed ECDAW-Net not only takes the lead in PSNR, but also most of the other indicators are in the forefront. Excluding VIF and VIFs, KSVD and TLD-CDL show leading indicator values when the tube current is 15mAs. This may be since these methods need to adjust noise -parameters according to the noise level.
Quantitative results of the different algorithm on piglet dataset
As shown in Fig. 13, we carried out a robustness verification experiment on the real clinic CT images and selected a representative slice (denoted as Case4). We also select two ROI areas (marked by rectangles in Fig. 13(a)) for better comparison and put them on the left-upper and right-upper corners. From the ROIs of LDCT image (such as Fig. 13(a)), serious artifacts/noise make texture and lesions (such as ROI5) difficult to be outlined precisely. The denoising result of KSVD can hardly see the texture. Another phenomenon we have observed in Fig. 13 is that the REDCNN, CTformer, and QAE can suppress noise and artifacts to some extent. CNCL, TLD-CDL and ECDAW-Net have the leading effect of noise suppression, and the lesions and tissue textures are well preserved, but CNCL still needs to be improved in brightness (such as ROI5 in Fig. 13(g)).
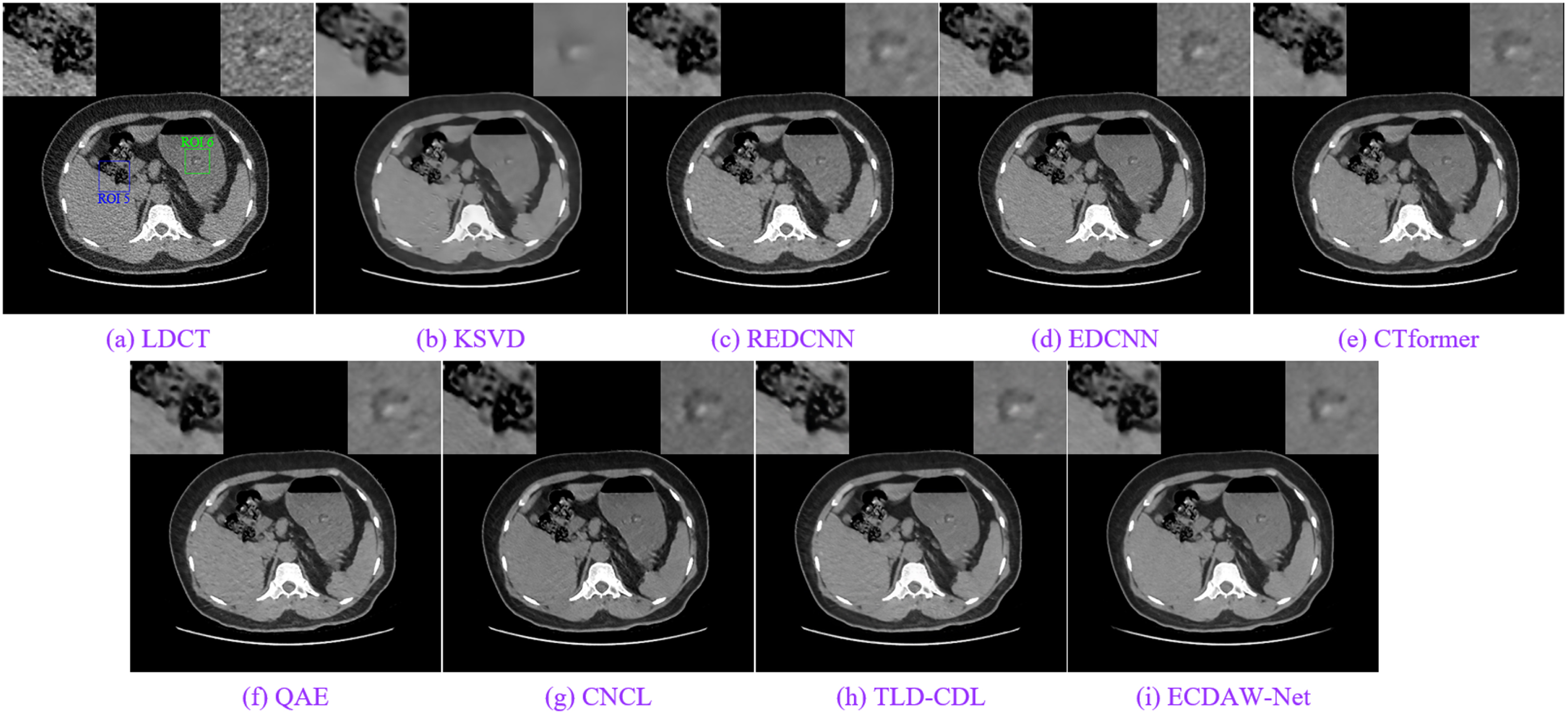
The denoised results for Case4. The display window is [-160,240] HU.
Model complexity is a major concern in LDCT denoising. We compared the trainable parameter numbers and testing time of all methods and show them in Table 4. The parameters are those trainable parameters that are updated during the backpropagation.
Numbers of parameters, inference times used in the compared models (M: million, s: second)
Numbers of parameters, inference times used in the compared models (M: million, s: second)
Concerning the model parameter, CNCL and TLD-CDL have the highest memory usage, which require more than 30 million parameters. This is because CNCL uses two deep learning predictors to learn the respective content, while TLD-CDL has multiple hyper-parameter prediction networks and model update networks. EDCNN and QAE have the smallest number of parameters. Although ECDAW-Net does not have the smallest memory usage, it is acceptable with only 3.46M. Concerning the testing time, EDCNN and QAE also have the fastest image processing speed. The proposed ECDAW-Net has almost six times speed than EDCNN but still less than 0.2 seconds, surprisingly followed by CNCL since the inference is only implemented by the generators. TLD-CDL and CTformer have the highest time cost of all the comparison methods. Overall, combined with the denoising performance and model efficiency, ECDAW-Net is competitive compared to other denoising algorithms.
In this part, ablation experiments were conducted on Mayo dataset, to analyze the impacts of all contributions in ECDAW-Net. Briefly, four ablation experiments are “w/o the compound loss” (the model is obtained by replacing the compound loss with MSE loss), “w/o the adaptive window” (the model is obtained by subtracting the adaptive window), “w/o the hybrid dilated module” (the model is obtained by replacing the hybrid dilated module with the normal 3×3 convolution), and “w/o the multi-scale edge extraction module” (the model is obtained by subtracting the multi-scale edge extraction module).
As shown in Fig. 14, we select another representative slice (denoted as Case5) from the Mayo dataset and zoom two ROI areas (marked by rectangles in Fig. 14) for better comparison. It can be seen from Fig. 14(c) and (d) that, without the adaptive window or replacing hybrid dilated module, the results are blurred and suffer from noise residues to various extents. The model only with MSE loss obtains a similar visual effect (as shown in Fig. 14(e)) compared with ECDAW-Net (Fig. 14(g)). Although the visual difference between Fig. 14(f) and (g) is also subtle, the ECDAW-Net is better at the edge of the lesion and artifact suppression (marked by red circles).

The denoised results obtained by performing the ablation experiments for Case5 on Mayo dataset. The display window is [-160,240] HU.
Table 5 indicates the average quantitative values of six metrics on the test image, the best and second-best values are indicated in red and blue, respectively. We can see that the proposed ECDAW-net achieves the best scores for each metric (except for GMSD), while the model without the multi-scale edge extraction module performs the second-best values except for GMSD and FSIM. It shows that the improvement in edge enhancement has a positive effect. The MSE loss only seeks to minimize gaps in pixel level, and the model with only MSE loss has inferior PSNR, SSIM, VIF, and VIFs, and gets the highest GMSD value. It indicates that the proposed compound loss strengthens the detail retention ability. From the observation of ECDAW-Net and the model obtained by replacing the hybrid dilated module with the normal convolution, the PSNR, and VIF values declined significantly, which accounts for the impact of the hybrid dilated module. In the comparison of ECDAW-Net and the model obtained by subtracting the adaptive window, the latter gets inferior values in all indicators (especially on PSNR, VIF, and VIFs), which is consistent with the visual judgment.
Quantitative performance of ablation studies (mean value)
This is a sign that the convolutional dictionary with the adaptive window is a reasonable solution for spectral leakage that is liable to disrupt the denoising performance. In words, the proposed ECDAW-Net is effective and meaningful.
Convolutional dictionary learning decomposes an image by using convolution operation instead of matrix multiplication in patch-based dictionary learning and considers the consistency constraint of pixels in overlapped patches. In this paper, we utilized the convolutional dictionary to represent noise and artifacts, and proposed the CDL-AW model in view of the unique advantages of convolutional dictionary learning, and designed the ECDAW-Net to solve the CDL-AW model according to proximal gradient optimization. Compared with most CNN-based LDCT denoising methods which perform like black-box, the proposed ECDAW-Net is more explainable, and one can understand the denoising process from Algorithm 1 and Fig. 2. In detail, we proposed an adaptive window to eliminate spectral leakage, and extended the spatial width by replacing the traditional convolution kernel with hybrid dilated module, which further reduces the influence of spectral leakage. Furthermore, the proposed multi-scale edge extraction module, composed of the learnable LoG convolution and Sobel convolution, has satisfactory effectiveness to compensate the edge information. In addition, instead of using L1 norm loss and MSE loss (both are in pixel-level) in most CNNs, we proposed the patch-level loss based on the local energy of image block, protecting the CT texture to a certain extent.
To better prove these points, we conducted comparative experiments on the Mayo dataset and the public Piglet dataset. The results show the proposed ECDAW-Net achieves inspiring noise/artifact removal while retaining detailed information. Compared with the comparative experiments mentioned in this paper, ECDAW-Net achieves the most satisfactory results in denoising and detail preservation and does not introduce additional artifacts in denoising like CTformer, and the restored tissue texture is closer to the NDCT image. In addition, we implement the real clinic experiments to explore application potential and the generality of our proposed method. It is proved that our method acquires acceptable model parameters and inference time, and has strong competitiveness compared with other methods. Finally, ablation studies were conducted and proved each improvement in the proposed architecture. The main contributions of this work are summarized as follows: A novel convolutional dictionary learning model with adaptive window (CDL-AW) is designed to relieve spectral leakage caused by data truncation during convolution, and its corresponding convolutional dictionary network (ECDAW-Net) is constructed to solve the CDL-AW model iteratively, with an explicit physical meaning. Since there is a certain correlation between the noise/artifacts and the inherent information, to restrain edge/texture blurring in iterations, we designed a multi-scale edge extraction module consisting of trainable LoG and Sobel convolution layers. In addition, a patch-level loss is proposed and combined with MSE (pixel-level) loss to train the ECDAW-Net, to further prevent image over-smoothing. Comparison experiments and the ablation studies show that the proposed ECDAW-Net achieves superb ability of noise/artifacts suppression and edge/detail preserving, and each improvement has a positive contribution.
Although the proposed ECDAW-Net acquires promising noise suppression and details preservation, our method trains a universal convolutional dictionary, which limits the flexibility of the image representation. In the future, more efforts will focus on how to adjust ECDAW-Net to an adaptive convolutional dictionary, that is, each input image has its own convolutional dictionary. Furthermore, our method requires the participation of paired CT images, which are not easy to obtain in practice, we will also try to design the architecture in an unsupervised manner and explore the scene of small samples.
Footnotes
Declaration of interest
The authors have no relevant financial or non-financial interests to disclose.
Acknowledgments
The authors would like to thank the editors and reviewers for improving the content of this article and thank the Mayo Clinic and the Ethics Committee for providing the data used.
Funding information
This work was supported in part by the National Key Research and Development Program of China under Grant (2022YFE0116700, 2022YFC2408500, and 2022YFC2401600), the Natural Science Foundation of Shanxi Province of China (202103021224204), Key Laboratory of Computer Network and Information Integration (Southeast University), Ministry of Education (K93-9-2022-02).