
Abstract
Context:
Developing scalable methods for conversation analytics is essential for health care communication science and quality improvement.
Purpose:
To assess the feasibility of automating the identification of a conversational feature, Connectional Silence, which is associated with important patient outcomes.
Methods:
Using audio recordings from the Palliative Care Communication Research Initiative cohort study, we develop and test an automated measurement pipeline comprising three machine-learning (ML) tools—a random forest algorithm and a custom convolutional neural network that operate in parallel on audio recordings, and subsequently a natural language processing algorithm that uses brief excerpts of automated speech-to-text transcripts.
Results:
Our ML pipeline identified Connectional Silence with an overall sensitivity of 84% and specificity of 92%. For Emotional and Invitational subtypes, we observed sensitivities of 68% and 67%, and specificities of 95% and 97%, respectively.
Conclusion:
These findings support the capacity for coordinated and complementary ML methods to fully automate the identification of Connectional Silence in natural hospital-based clinical conversations.
Introduction
Fostering human connection is fundamental to good clinical communication.1–3 Unfortunately, this happens infrequently in modern health care, particularly in serious and life-threatening illness. 4 Re-engineering health care will require systematic measurement and feedback about the quality of human connection in routine clinical interactions. Existing methods of conversation analytics are too cumbersome for effective use in the large-scale epidemiological studies in natural clinical settings necessary to guide implementation of such quality metrics. 5 In this study, we present work that addresses this need.
Defining directly observable characteristics of clinical conversations that reliably mark moments of human connection can be challenging3,6 because the ways in which connection can be felt by conversation participants are many and varied.7,8 Despite these empirical measurement considerations, directly observable moments of human connection between patients and their clinicians often arise in or around some of the pauses in a conversation, such as when people cease talking to honor the gravity of what is being discussed or to provide sufficient time for a seriously ill person to contemplate a response to a meaningful question.2,9–14 Our previous research has shown that Connectional Silences during clinical conversations are associated with improvement in seriously ill patients' self-reported quality of life, and with treatment decision making that honors their values. 9
Identifying Connectional Silences in audio recordings of conversations using traditional methods is highly labor intensive and requires skilled human coders. 11 Previous study demonstrates the feasibility of machine-learning (ML) to semiautomate the process of identifying possible moments of human connection by reducing the search space within which human coders focus their efforts. 11 In this study, we design and apply an ML pipeline to fully automate the identification of Connectional Silences using speech prosody and lexicon.
Methods
Overview
We created a pipeline of ML algorithms to automatically identify and subclassify Connectional Silences in natural clinical settings. To accomplish this, we used audio recordings from a multisite cohort study of palliative care consultations involving hospitalized people with advanced cancer. The first two ML algorithms used different types of acoustical features to predict conversational pauses in parallel from the same audio recordings. The third ML algorithm used brief portions of the automated speech-to-text transcripts immediately preceding predicted pauses to classify pause type. By operating on unique conversational features, each algorithm provides complementary information for identifying and classifying Connectional Silences.
This study was approved by the protection of human subjects review committee at the University of Vermont (Protocol 16-527).
Participants and palliative care communication research initiative study design
The palliative care communication research initiative (PCCRI) was a descriptive cohort study of naturally occurring specialty palliative care consultations at two academic medical centers on the West Coast and Northeast United States. 15 As part of the study, researchers recorded the initial consultation and up to two follow-up visits between 231 hospitalized persons with advanced cancer, their families (if present), and palliative care specialists (in total, 54 clinicians participated in the study). The criteria for participant inclusion in the study were a diagnosis of metastatic cancer, English speaking, 21 or more years of age, and the ability to consent for participation in the research or have a health care proxy who was able to consent. Patients with a “comfort measures only” designation on their medical orders or who were already receiving hospice care were ineligible. 15
Each conversation was recorded on an omnidirectional handheld digital recorder placed in an unobtrusive location in the patient's hospital room. Identifying participant information was removed from the audio files, but no effort was made to modify ambient sounds from the natural environment (which included hospital announcements, equipment beeping, TV/radio audio, and background conversations at the nurses' station and adjacent beds).
“Ground Truth” definition of pauses and connectional silences
We define a Pause as a two-second or longer duration of time when no conversation participant makes an audible attempt to hold or attain the speaking floor. 16 We used the minimum duration of two seconds to align with previous study that identifies this threshold as nearly culturally ubiquitous. 17
We define two subtypes of Connectional Silence after the conceptual study of Back et al. 13 and validated by Bartels et al. 12 and Durieux et al. 11
Emotional connectional silence
A Pause that follows a moment of gravity in the conversation, including either an expression of an emotion that seems unpleasant (e.g., anger, fear, or sadness) or information that the speaker seems to perceive as unfavorable (e.g., prognosis).
Invitational connectional silence
A Pause that occurs after a question relating to one of the following: personal values or identity; quality of life; treatment hopes, goals or preferences; prognosis; or death/dying.
For this study, we define three nonoverlapping classes of Pauses: Emotional Connectional Silences, Invitational Connectional Silences, and Nonconnectional Pauses (defined as any other moments considered to be Pauses). For all data in these analyses, two trained human coders independently identified Pauses 18 ; any disagreements were adjudicated by a third coder. We subsequently double-coded every confirmed Pause as an Emotional Connectional Silence, an Invitational Connectional Silence, or a Nonconnectional Pause, according to our definitions of these classes. To make this judgment for each Pause, human coders listened to an audio clip comprising the Pause, 10 seconds directly preceding the Pause, and 5 seconds directly after the Pause. We classified a Pause as a Connectional Silence (Emotional or Invitational) when both coders agreed or through subsequent adjudication. 11 Both coding methods, Pause identification and Pause classification, demonstrated strong inter-rater reliability.11,18
ML pipeline algorithm development
We demonstrate a new two-phase pipeline, using three types of ML algorithms: a random forest (RF), 19 a convolutional neural network (CNN), 20 and a natural language processing (NLP) method known as a bidirectional encoder representations from transformers (BERT). 21 Our data flow for the complete “ML Pipeline” is shown in Figure 1.
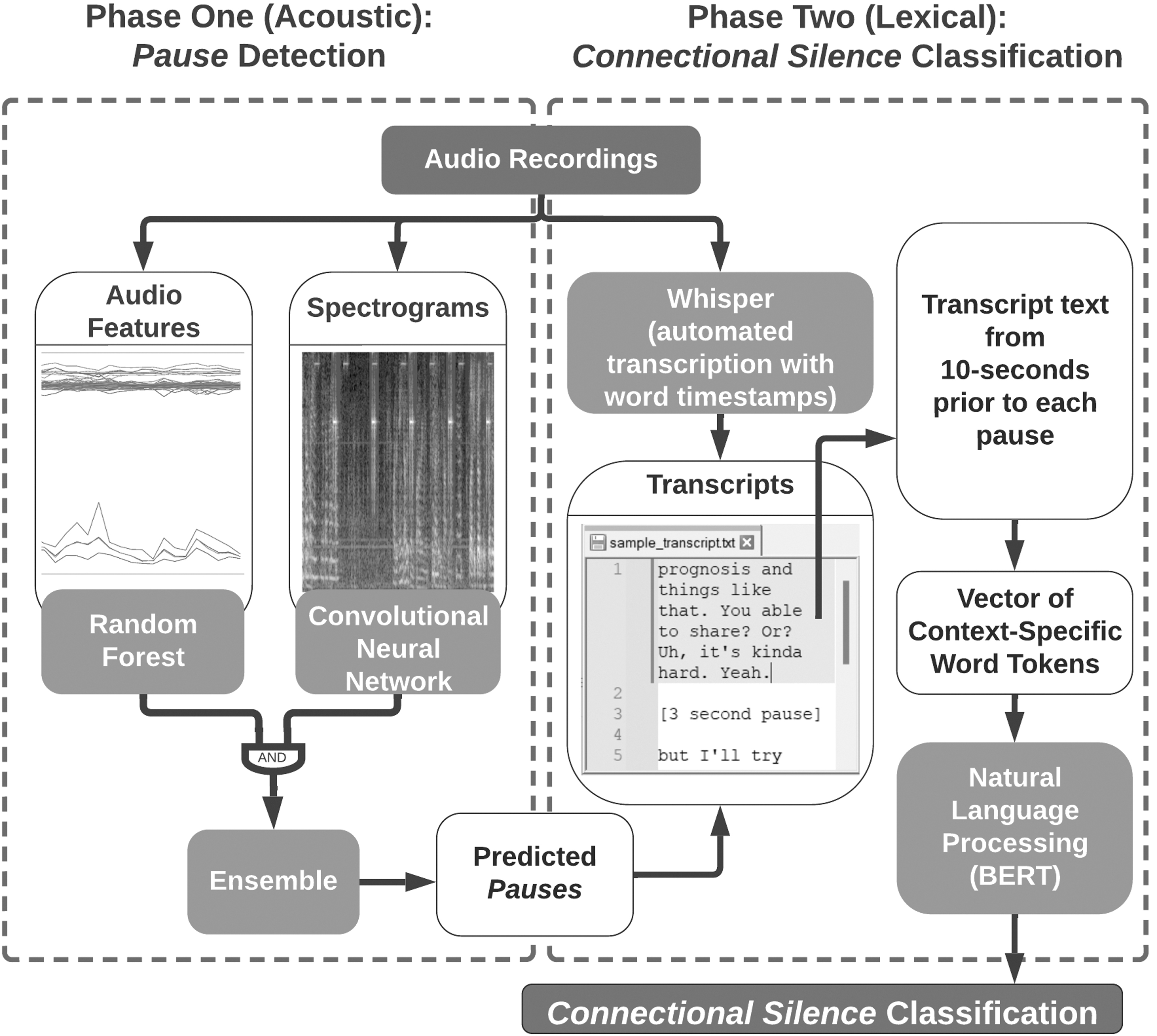
Schematic of the complete machine-learning pipeline.
In phase 1, we identify the occurrence of Pauses in audio recordings. The methodology combines predictions from our pretrained RF 18 with those of a CNN that is designed and trained to use different acoustic data (spectral images) than the RF. We refer to this combined RF-CNN algorithm as the “Ensemble” ML Pause prediction algorithm. In phase 2, we create automated speech-to-text transcription22,23 of the 10 seconds of conversation preceding each Pause predicted by phase 1 of the pipeline. We then feed these brief excerpts into the BERT NLP algorithm to classify which of the predicted Pauses represent moments of Connectional Silence and which do not.
The performance of the complete ML pipeline was assessed on the 203 of the 231 conversations for which all types of conversational pauses had been rigorously human coded. We excluded conversations from 28 participants because establishing the “ground truth” upon which to evaluate the pipeline performance was unreliable due to obscured patient voice (e.g., whispering while wearing high flow oxygen mask), substantial nonaudible methods of communication (e.g., white board and gestures), or nonaudible key conversation participant (e.g., clinician speaking with family member through telephone not using the speaker). We calculated standard epidemiological and NLP measures of test performance: sensitivity (a.k.a. recall), specificity, positive predictive value (a.k.a. precision), negative predictive value, and F1. Hereunder, we describe an overview of the ML pipeline and offer more technical details in the Supplementary Material.
Phase 1 (acoustic)
To identify the presence of a Pause, the RF and CNN algorithms independently classify each 0.5-second interval of audio into “speech” or “nonspeech” using very different types of acoustical features extracted from the same recordings. The previously trained RF 18 uses a set of 85 audio features comprising 5 summary statistics of 13 mel-frequency cepstral coefficients (MFCCs—a subjective scale for measuring pitch based on how human observers perceive sound), 24 zero-crossing rate, energy, energy entropy, and spectral entropy.
In contrast, the custom CNN directly evaluates spectral images of sound. The RF and CNN results are combined by retaining only those 0.5-second intervals where both the RF and CNN agree that no speech is present (“unanimous voting”). Consecutive 0.5-second intervals determined by both the RF and CNN as lacking any speech are then merged, and merged regions that are two seconds or longer are defined as “Ensemble-predicted Pauses.” Details on the training, validation, and testing of the CNN, RF, and Ensemble methods are presented in the Supplementary Material.
Phase 2 (lexical)
A BERT model is a state-of-the-art NLP algorithm 25 that is pretrained on large volumes of English language data to allow for efficient refinement on smaller sets of contextually specific data, such as ours here. We used 10 second excerpts of transcripts immediately preceding Ensemble-predicted Pauses as inputs to a BERT for classification. Transcripts had been automatically generated from the Whisper speech recognition system.22,23 We chose 10 seconds to align with the amount of data used by human coders to make their judgments about the “ground truth.” To minimize algorithmic bias, 26 we fine-tuned the BERT on a balanced subset of text excerpts directly preceding Invitational Connectional Silences, Emotional Connectional Silences, and Nonconnectional predictions. We used the trained and cross-validated BERT to classify all Ensemble-predicted Pauses into one of these three classes. Details on the training, validation, and testing of the BERT are presented in the Supplementary Material.
Lexical comparison of pipeline predictions
To explore the lexicon from the text excerpts that BERT used for classifying Ensemble-predicted Pauses, we calculated the proportions of words in this text from clinically relevant corpora (specifically, temporal referents 27 ; uncertainty terms 10 ; loneliness 28 ; symptom, treatment, and prognosis terms 27 ; and pronouns 29 ). We merged all text associated with each BERT-predicted class into a single text block. The word usage proportion for each corpus was calculated as the number of in-corpus words divided by the total number of words for each class. For comparison purposes, we also calculated word usage proportions for the complete transcripts.
Results
Sample characteristics are shown in Table 1 and represent the approximate distribution of age, gender, race, ethnicity, and educational completion of the palliative care consultation population at each study site. 15
Description of Sample
McGill Quality of Life Global Item asked preconsultation 38 (0–10 scale); strata not summing to 203 represent item nonresponse.
AA, African American; GED, General Education Development test; HS, high school.
The complete ML pipeline identified Connectional Silence with an overall sensitivity (recall) of 84% (453/539) and specificity of 92% (115,492/124,947), as shown in Table 2. Among all two-second intervals of audio evaluated by the ML pipeline, the prevalence of Connectional Silence was only 0.4% (539/125,486), contributing to a high negative predictive value (>99.9%; 115,492/115,578) and low positive predictive value (precision) (5%; 453/9908) and F1 (9%; 906/10,447), in this context.
Connectional Silence Machine-Learning Pipeline Performance
ML, machine-learning.
For the Emotional Connectional Silence subtype, we observed a sensitivity (recall) of 68% (207/304), specificity of 95% (119,338/125,182), negative predictive value of >99.9% (119,338/119,435), positive predictive value (precision) of 3% (207/6051), and F1 of 7% (414/6355). For the Invitational Connectional Silence subtype, we observed a sensitivity (recall) of 67% (157/235), specificity of 97% (121,551/125,251), negative predictive value of >99.9% (121,551/121,629), positive predictive value (precision) of 4% (157/3857), and F1 of 8% (314/4092).
Results for phase 1 (predicting Pauses) and phase 2 (classifying Pause types) are provided in the Supplementary Material.
As shown in Figure 2, the lexicon preceding Emotional Connectional Silences includes relatively more past speech than future speech, whereas the Invitational subtype has relatively more future speech than past speech. Compared with the Invitational subtype, the Emotional subtype included more first-person singular pronouns, past-tense speech, and loneliness words, but less future-tense speech and fewer uncertainty, symptom, treatment, and prognosis words. All of the aforementioned comparisons were statistically significant (chi-square p < 0.001).

Pre-event context lexicon prevalence by BERT classification. BERT, bidirectional encoder representations from transformers.
Discussion
Epidemiologically, the presence of Connectional Silence in serious illness conversations is associated with important patient-reported outcomes, including improvement in quality of life and preference-concordant treatment decisions. 9 In this study, we developed an ML pipeline of acoustic and lexical algorithms to automatically detect Connectional Silences from audio of real-life serious illness conversations in hospital settings. We found that the ML pipeline worked very well, missing very few moments of Connectional Silence while maintaining high specificity in categorizing types of automatically identified Pauses. This ML pipeline offers timely and important scientific innovation to study the epidemiology of Connectional Silence in large-scale natural clinical environments. In general, this study supports the concept that transformation of the same acoustic signal into multiple data types (e.g., MFCCs, spectral images, and lexical transcripts) may be quite valuable for ML performance in conversation analysis.
In the acoustic phase, we found that an Ensemble approach, combining RF and CNN algorithms, performed better than either method used individually. Specifically, this coordinated ML analyses of distinct forms of sound representation resulted in >3000 fewer false Pause predictions than the RF alone, and almost 9000 fewer false Pause predictions than the CNN alone while only sacrificing the detection of 1.6% of the Connectional Silences. Thus, using the Ensemble for Pause prediction saved an estimated human-coder time for Pause classification of about 23 hours over RF alone. 11 To our knowledge, this Ensemble approach is novel in automated Pause detection. Our findings are particularly promising because most prior study related to Pause identification has been conducted in low-noise or simulated settings rather than naturally noisy hospital settings with seriously ill patients.30–34
To fully automate the classification of Connectional Silence, we used speech-to-text processing22,23 to produce the brief (10 second) excerpts of transcript lexicon used in phase 2 of the ML pipeline. We observed large differences in the lexicon preceding distinct types of Pauses. However, while transcription algorithms have increasingly low error rates,35,36 even many state-of-the-art transcription services make word-level errors nearly twice as frequently when evaluating voices from Black compared with White speakers. 37 As such, we recommend careful attention to algorithmic fairness when considering automated transcription. Specifically, our ML pipeline requires two important next steps. First is testing in sufficiently large and diverse samples of participants, settings, and clinical situations to evaluate stratum-specific classification performance and direction of error. Second is linguistic and ethnographic evaluation of individual classification errors to discover, describe, correct, and minimize sources of racial and ethnic bias.
This study has important limitations. First, as mentioned earlier, our sample does not sufficiently represent the breadth in types of speaking and interactional norms relating to silence; racial, ethnic, or cultural backgrounds; institutional norms; or clinical situations. Further validation and potential refinement of the algorithms are necessary to ensure the representativeness of our findings among individuals with diverse backgrounds, clinical scenarios, and environmental factors. Doing so will help advance a major priority for health care communication science: to achieve equitable, meaningful, and scalable conversation analyses for large sample research and quality improvement initiatives. 5
Second, this study is based on audio and transcript data only and will likely misclassify moments of connection when exclusively nonaudible cues (e.g., brief eye contact and touch) might be observable by other means. Third, the handheld recorders used in this study were placed on a patient's bedside table and, therefore, captured the ambient sounds (including other human voices) of noisy hospital environments. Future study focused on pause detection and classification may benefit from directional or wearable microphones to minimize unnecessary background sounds.
In conclusion, an ML pipeline that uses different representations of acoustic and lexical conversation information can automatically identify moments of Connectional Silence in naturally occurring serious illness clinical conversations.
Footnotes
Acknowledgments
We thank the palliative care clinicians, patients, and families who participated in this research for their dedication to enhancing care for people with serious illness. The authors would like to acknowledge the contributions of other members of the Vermont Conversation Lab (Brigitte Durieux, Larry Clarfeld, Aidan Ryan, Lindsay Ross, Michelle Nyland) whose related work supported this article.
Funding Information
The original PCCRI from which data were used in this study was funded by a Research Scholar Grant from the American Cancer Society (RSG PCSM124655; PI: Robert Gramling). These analyses were supported by the Barrett Foundation and NSF Vermont EPSCoR grant numbers EPS-1101317 and NSF OIA 1556770 and the Holly & Bob Miller Endowed Chair in Palliative Medicine.
Author Disclosure Statement
No competing financial interests exist.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.