
Abstract
Objective:
To characterize the sensitivity and predictive value of predefined search terms for identifying documented goals-of-care discussions in health records of hospitalized patients with serious illness.
Methods:
We evaluated the performance of 30 previously published and investigator-defined search terms codified into regular expressions (a type of pattern-based text search) in detecting goals-of-care documentation in a 2974-note corpus of electronic health record notes belonging to 159 inpatients enrolled in a U.S. clinical trial over 2020–2021.
Results:
Compared to conventional chart abstraction, search terms for “goals of care” and synonyms such as “GOC” had poor sensitivity (range: 29.5–38.3%) and modest positive predictive value (PPV; range: 48.3–61.7%) for identifying notes with goals-of-care documentation. Combinations of search terms demonstrated modest performance (sensitivity 62.0%, PPV 59.4%, F1 0.61) but fell short of more complex natural language processing models.
Conclusion:
In certain contexts, predefined regular-expression-based search terms may have suboptimal sensitivity and predictive value for identifying documented goals-of-care discussions.
Introduction
Goals-of-care discussions are an important process measure in serious illness communication. 1 However, measuring documented goals-of-care discussions in unstructured electronic health record (EHR) data can be costly and labor-intensive. 2 One approach to reducing the burden of abstraction is using predefined search terms and patterns to identify text requiring further human abstraction, an approach that has been used to measure many outcomes and metrics from EHR text including goals-of-care documentation and advance care planning.3–11 Predefined search terms and patterns are often implemented using regular expressions, a type of search pattern that combines character patterns with wildcards, repetition rules, and logical operators to refine searches. Although regular expressions are easy to develop, highly transparent, and widely accessible, there are fewer data examining the sensitivity and predictive value of this approach against conventional whole-chart abstraction in measuring EHR-documented goals-of-care discussions for hospitalized patients.10–12 In this study, we evaluate the performance of predefined search terms for identifying documented goals-of-care discussions compared to manual abstraction for hospitalized patients with serious illness, using an existing corpus of manually abstracted EHR data.13,14
Methods
We conducted a secondary analysis of existing EHR data, comprising 2974 inpatient notes from 159 patients enrolled in a randomized trial of hospitalized patients aged ≥55 years with chronic life-limiting illness (defined by diagnosis codes 15 ) or aged ≥80 years. The parent trial enrolled all eligible patients hospitalized at a UW Medicine hospital (a Seattle-area health system) from April 2020 to March 2021 under a waiver of informed consent. Patients were randomized to usual care or a clinician-facing communication-priming intervention (Jumpstart Guide).13,14 The primary outcome was EHR documentation of a goals-of-care discussion, defined as a discussion of the “overarching aims of medical care for a patient” 16 beyond routine code status discussions or citation of historical advance care planning documents. In the trial, this outcome was measured using deep-learning natural language processing (NLP)-screened human abstraction, in which a deep-learning NLP model identified likely passages for human adjudication. 2
For the current study, we used a manually abstracted validation dataset from the parent trial to evaluate the performance of predefined search terms for measuring the same outcome. The validation sample comprised 159 trial participants whose records underwent conventional chart abstraction (without NLP) for the primary outcome. Due to challenges in reaching a prespecified subgroup enrollment target, this sample had been enriched for patients with Alzheimer’s disease and related dementias (ADRD; target proportion 50%) to support an interim subgroup analysis. To measure the reference outcome in the validation sample, four research coordinators manually reviewed and coded all sampled inpatient records using a qualitative data analysis platform and a predefined codebook. 2 Abstractors met weekly to review coding and ensure consistency. Records from the index hospitalization preceding randomization were included in the reference corpus but excluded from consideration for the trial outcome. The resulting manually abstracted 2974-note reference sample serves as the data source for this study, with manual abstraction used as the “gold standard” for the presence or absence of goals-of-care documentation.
To assess the performance of predefined search terms and patterns for identifying goals-of-care discussions, we assembled a broad-ranging list of 30 search terms, drawing from previously published search terms11,17 and investigator consensus.18–20 Search terms were codified into regular expressions and grouped into thematic categories. We then compared the binary outcome of regular-expression match against conventional chart abstraction results for goals-of-care documentation, evaluating both measures at the whole-note level. We characterized the performance of each search term using sensitivity (recall), positive predictive value (PPV; precision), and F1 (the harmonic mean of sensitivity and PPV), examining PPV and F1 in lieu of specificity because the latter provides limited insight into the prediction of rare outcomes compared to metrics that focus on true positives in sparse situations.21,22
We then evaluated the ensemble performance of combinations of search terms toward maximizing F1, employing a hierarchical approach to mitigate overfitting by reducing the size and dimensionality of the search space. We first identified the highest-performing combinations of search terms within each thematic category, and then evaluated ensembles of highest-performing search terms from all themes to identify search term sets with the best overall performance (Fig. 1). We also examined search term sets constrained to include terms from the specific themes of goals of care, advance care planning, and hospice or palliative care.

Hierarchical approach for evaluation of combinations of 30 search terms across 10 thematic categories. POLST, Physician Orders for Life-Sustaining Treatment.
Regular-expression matching and statistical analyses were performed using Stata/MP version 18.5 (StataCorp, stata.com). Manual chart abstraction was performed using Dedoose (SocioCultural Research Consultants, dedoose.com). Study procedures were approved by the University of Washington Institutional Review Board (STUDY00007031, STUDY00011002). The parent trial was registered with ClinicalTrials.gov (NCT04281784).
Results
Between April 23, 2020, and March 26, 2021, the parent trial 13 enrolled 2512 patients, of whom 159 were sampled in the reference dataset (Table 1). The mean age in the reference sample was 72.6 (standard deviation, 10.6) years, 42% were female, and the majority (65%) had two or more chronic life-limiting illness diagnoses. The sample was purposively enriched for patients with ADRD (80/159, 50%). The EHR note corpus for this patient sample consisted of 2974 notes, of which 295 (9.9%) notes from 54/159 (34%) patients contained documented goals-of-care discussions by manual abstraction.
Characteristics of Patient Sample
Chronic life-limiting illness diagnoses are not mutually exclusive.
We constructed an a priori list of 30 search terms and regular expressions that were grouped into 10 thematic categories and examined the prevalence and performance of each search term (Table 2). Notably, search terms for “goals of care” and similar constructs had poor sensitivity and PPV (search terms 1–3: sensitivity range: 29.5–38.3%, PPV range: 48.3–61.7%). Terms pertaining to code status were more highly prevalent in the dataset, with 37% of notes and 134/159 (84%) of patients’ charts containing the term “code status”; however, the PPV of these terms was low, as expected given that our operational definition of documented goals-of-care discussions excluded routine code status discussions or documentation. Search terms related to hospice care and comfort measures had excellent PPV but low sensitivity, likely as a consequence of their narrow scope. Within thematic categories, best-performing combinations of search terms demonstrated modest performance (Supplementary Table S1), with search terms in the goals-of-care category demonstrating 54.2% sensitivity, 51.0% PPV, and F1 = 0.53. Combinations of search terms across themes (Table 3) showed improved performance over within-theme search terms, with the highest-performing search term set demonstrating 62.0% sensitivity, 59.4% PPV, and F1 = 0.61. Constraining the search space to search term sets that included the goals-of-care category yielded a search term set demonstrating 76.6% sensitivity, 49.1% PPV, and F1 = 0.60.
Performance of Individual Search Terms
All phrases were evaluated as complete phrases, and no whole word matches were required. Comma-separated terms match any of the listed search terms.
Each search term was evaluated as a binary variable against manual abstraction, which found 295 (10%) notes with goals-of-care discussions.
These terms also matched hyphenated versions (e.g., “goals-of-care”).
These terms were treated as case-sensitive.
This term yielded identical results to search term no. 1 in the data and was omitted from further analysis.
These terms were not encountered in the sample and were omitted from further analysis.
These terms matched words sharing the same stem; characters within brackets were omitted from the search phrase and are only shown for readability.
ACP, advance care planning; CMO, comfort measures only; CPR, cardiopulmonary resuscitation; DNI, do not intubate; DNR, do not resuscitate; [D]POA, durable power of attorney; GOC, goals of care; POLST, Physician Orders for Life-Sustaining Treatment; QOL, quality of life.
Performance of Combinations of Search Terms Across Themes
All phrases were evaluated as complete phrases, and no whole word matches were required. Comma-separated terms match any of the listed search terms. See Table 2 for further details about individual search terms. For combinations with identical performance, the combination with the fewest terms is listed. Terms containing brackets searched for word stems; characters within brackets were omitted from the search phrase and are only shown for readability.
Discussion
In previous reports, our research group has described the use of various NLP models for identifying documented goals-of-care discussions in various note corpora.2,18,23 When comparing the performance of predefined search terms against a previously published 110-million-parameter deep-learning model based on Bio+Clinical BERT (Bidirectional Encoder Representations from Transformers) that was tested on the same corpus,2,24,25 we observed that the deep-learning model substantially outperformed all identified best-performing ensembles of predefined search terms (Fig. 2). Although the superior performance of deep-learning models over regular expressions is somewhat expected,26,27 more sophisticated NLP models also come with steep development costs as well as a lack of transparency that can raise concerns for the introduction of hidden biases.28–31
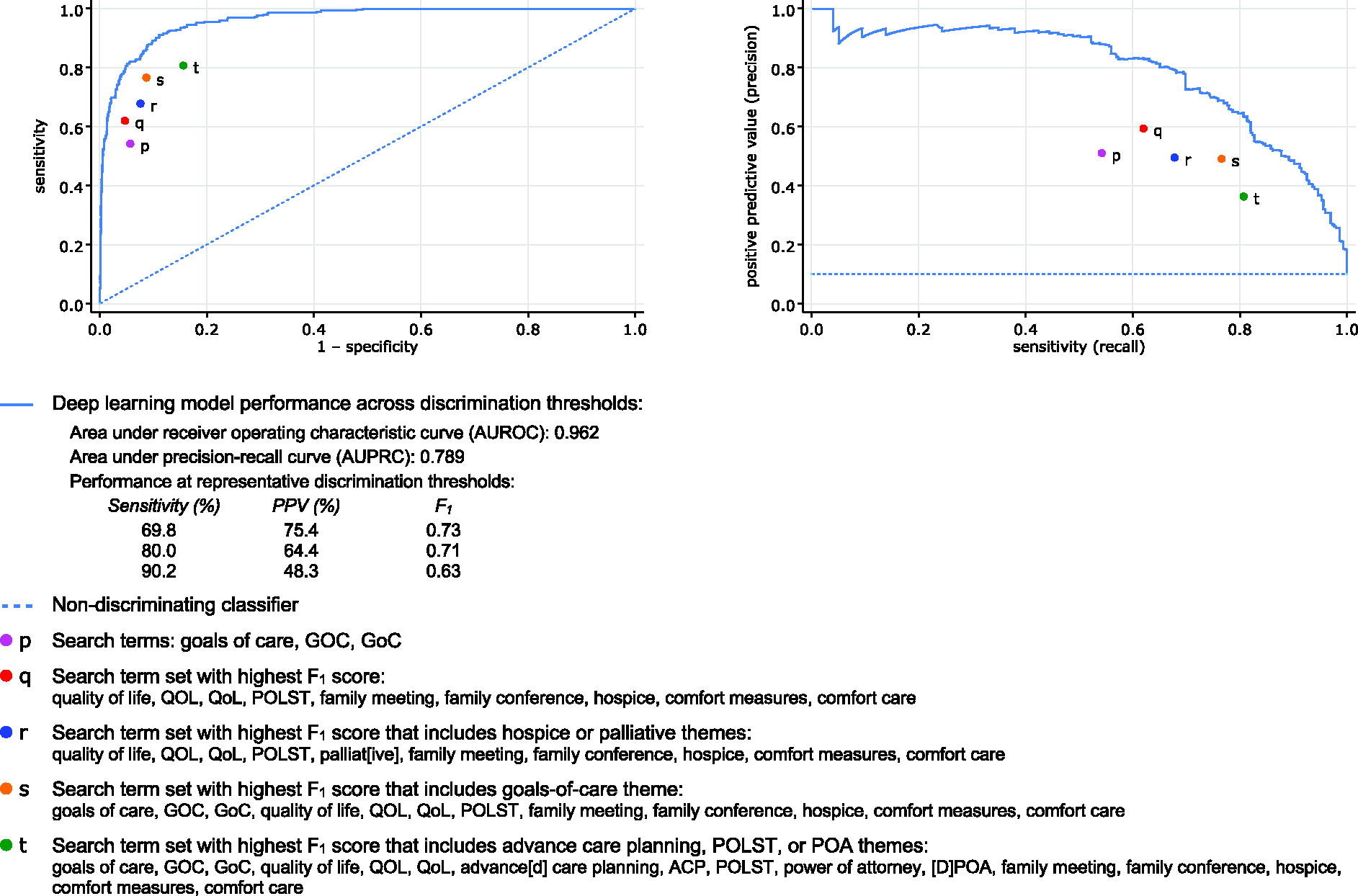
Comparison of search term performance with BERT-based deep-learning model.a aThe deep learning model is an instance of Bio+ClinicalBERT that was fine-tuned on a manually labeled external training set and is fully described and evaluated in a previous report. 2 Herein, the model is evaluated on this study’s 2974-note 159-patient corpus, which is a superset of the corpus tested in the previous report 2 that includes records from the index hospitalization preceding randomization for the parent trial. Sensitivity (i.e., recall) and positive predictive value (PPV; i.e., precision) are presented at observed discrimination thresholds with sensitivities closest to prespecified values of 70%, 80%, and 90%. BERT stands for Bidirectional Encoder Representations from Transformers (Google Research, 2018). 25
Given the plummeting explainability of more modern NLP models—which are often described as a “black box,” 31 and have even been known to confabulate responses 32 —it is tempting for clinical researchers to turn toward simpler, more explainable models such as those based on predefined search terms and regular expressions. Although such approaches may offer excellent performance for certain datasets and constructs, in other contexts such an approach may risk compromising reliability or even introducing bias in counterintuitive ways. We are frequently asked, “Can’t you just search for ‘goals of care’ in the medical record?” Within the confines of our study, which examined records of hospitalized patients in a single health system, our results suggest that “searching for ‘goals of care’” can compromise sensitivity to a surprising extent.
The low performance of intuitive search terms such as “goals of care” was somewhat surprising. However, in our abstraction work, we have frequently noted that clinicians often use the words “goals of care” in an aspirational or hypothetical sense—for example, “We should have a goals-of-care discussion,” or “Will consider this approach if consistent with goals of care,” with or without subsequent documentation of an actual a goals-of-care discussion with patients or family members. Conversely, inpatient clinicians often document in-depth goals-of-care discussions without actually using the term “goals of care” or its synonyms, as evidenced by the remarkably low sensitivity of goals-of-care-themed search terms for notes containing documented goals-of-care discussions.
Our study has several important limitations. First, our study sought to measure a linguistically complex construct, and for the purposes of its parent clinical trial, adopted a definition of goals-of-care documentation that is more stringent than some other definitions. More permissive definitions that include routine code status documentation may exhibit different performance than that observed in our study, and constructs of lesser complexity are likely to be more amenable to regular-expression-based strategies. Second, our study only measured a limited set of search terms. Other terms that may be used in the documentation of goals-of-care discussions may exhibit differing performance. Notably, our search terms do not capture many domains of goals-of-care documentation such as values, trade-offs, prognosis, and worries. However, these concepts are also linguistically even more complex, and likely to require more sophisticated means of measurement. Third, our data were collected from patients with serious illness hospitalized in a single multihospital health system in the Pacific Northwest. Documentation practices may differ in other health systems, regions, care settings (e.g., inpatient vs. outpatient), or with different EHR systems. Fourth, although our test corpus contained 2974 notes, they were collected from a relatively small sample of 159 patients that was enriched for patients with ADRD.
Conclusion
In a 159-patient, 2974-note sample of clinical notes collected from hospitalized patients with serious illness, predefined search terms implemented using regular expressions demonstrated poor sensitivity and PPV for identifying notes with documented goals-of-care discussions extending beyond routine code status discussions. In the inpatient setting, this construct may require more sophisticated NLP approaches to measure reliably, at the cost of explainability.
Footnotes
Acknowledgments
The authors are grateful for the contributions of the late J. Randall Curtis, MD, MPH, who was a founding principal investigator of this research program.
Authors’ Contributions
R.Y.L. had full access to all the data in the study and took responsibility for the integrity of the data and the accuracy of the data analysis.
Author Disclosure Statement
The authors have no conflicts of interest to disclose.
Funding Information
This work was supported by the National Institute on Aging (R01AG062441), the National Heart, Lung, and Blood Institute (K23HL161503, K12HL137940, T32HL125195), and the Cambia Health Foundation. Infrastructure support was provided by the Institute of Translational Health Science (National Center for Advancing Translational Sciences, UL1TR002319) and by the Pulmonary and Critical Care Medicine Fellowship Research Training Program of the University of Washington (T32HL007287). R.Y.L., A.M.U., K.S.L., J.S., T.C., W.B.L., D.G.D., R.A.E., and E.K.K. receive research funding from the National Institutes of Health. T.C. also reports receiving royalties from Springer Nature. The funding sources had no role in the design and conduct of the study; collection, management, analysis, and interpretation of the data; preparation, review, or approval of the article; and decision to submit the article for publication.