
Abstract
The “transportability” of laboratory findings to other instances than the original implementation entails the robustness of rates of observed behaviors and estimated treatment effects to changes in the specific research setting and in the sample under study. In four studies based on incentivized games of fairness, trust, and reciprocity, we evaluate (1) the sensitivity of laboratory results to locally recruited student-subject pools, (2) the comparability of behavioral data collected online and, under varying anonymity conditions, in the laboratory, (3) the generalizability of student-based results to the broader population, and (4) with a replication at Amazon Mechanical Turk, the stability of laboratory results across research contexts. For the class of laboratory designs using incentivized games as measurement instruments of prosocial behavior, we find that rates of behavior and the exact behavioral differences between decision situations do not transport beyond specific implementations. Most clearly, data obtained from standard participant pools differ significantly from those from the broader population. This undermines the use of empirically motivated laboratory studies to establish descriptive parameters of human behavior. Directions of the behavioral differences between games, in contrast, are remarkably robust to changes in samples and settings. Moreover, we find no evidence for either anonymity effects nor mode effects potentially biasing laboratory measurement. These results underscore the capacity of laboratory experiments to establish generalizable causal effects in theory-driven designs.
Keywords
Introduction
Laboratory experiments have a decisive methodological advantage over alternative modes of data generation in the social sciences: Group formation, randomization, and manipulation—while holding environmental factors constant—ease the testing of hypotheses regarding causes and effects (e.g., Falk and Heckman 2009; Shadish, Cook, and Campbell 2002; Webster and Sell 2014). Because of their support for causal inference (internal validity), many consider laboratory experiments the “gold standard” of scientific inquiry (e.g., Morgan and Winship 2015; Rubin 2008). 1 Note that our discussion of social experiments focuses on designs measuring actual behavior rather than behavioral intentions, attitudes, or opinions. In this tradition, laboratory research allows the elimination of plausible alternative explanations for results and generalization is directed to the support or nonsupport of theoretical principles (Thye 2014; Willer and Walker 2007; Zelditch 2014).
Others have criticized laboratory research in the social sciences due to its often questionable generalizability to the “real world” (external validity). In social science lab research, external validity refers first and foremost to lab–field generalizability and thus to the question whether individuals examined in the laboratory behave as they would in everyday life (Jackson and Cox 2013; Levitt and List 2007). This question is particularly relevant if one conceives of laboratory methods also as measuring instruments of certain types of behavior (e.g., Franzen and Pointner 2013; Glaeser et al. 2000; Rauhut and Winter 2010). Upstream requirements for external validity entail that laboratory results are robust to changes in both the specific research setup and the sample under study (Campbell and Stanley 1963; Cronbach 1982). These criteria convey the “transportability” (Pearl and Bareinboim 2014) of findings to other implementations beyond any specific design. After all, “[m]ost experiments are highly local but have general aspirations” (Shadish et al. 2002:18).
This article tests the minimal requirements for external validity of laboratory research in the social sciences. We conceptualize a laboratory design as a specific combination of subjects (units), stimuli (treatments), measurements (observations), and context (setting). This decomposition was first introduced by Cronbach (1982:78) and has been used by others (e.g., Gerber and Green 2012; Shadish et al. 2002) to evaluate experimental findings’ range of validity.
In four studies, we assess each dimension’s importance for establishing transportability: Study 1 varies units in a multilocation laboratory comparison conducted at two German universities, in Leipzig and Munich (pool generalizability). Study 2 targets observations and tests for comparability of behavioral data collected online and, under varying anonymity conditions, in the laboratory (mode generalizability). Study 3, a nationwide online implementation, again relates to units and tests our baseline results’ transportability to the broader population (sample generalizability). Study 4 concerns the setting of data collection (context generalizability) and—transporting our standardized decision situation into an online labor market—considers workers at Amazon’s crowdsourcing platform Mechanical Turk (MTurk). Different samples, modes, or settings may violate transportability in that they produce different rates of observed behaviors and—more worryingly for experimental research—heterogeneous treatment effects.
Our results ground on behavioral data collected in incentivized games of fairness, trust, and reciprocity from 2,664 subjects using the same decision interface. Throughout our four studies, we focus on two decision-making situations frequently used in the methodological research on laboratory designs: the dictator game (DG) and the trust game (TG). These games differ in complexity, carry the potential for socially desirable responses, and enable a direct comparison with an extant literature. Because socially acceptable (DG) and socially optimal (TG) behaviors diverge from first movers’ egoistic strategies, these games reveal expectations about valid norms of fairness (DG), trust, and reciprocity (TG) in a particular population and setting (Bicchieri 2006; Elster 2007). We compare behavior in these situations replicating the common finding that an investment opportunity (TG), rather than altruism (DG), motivates first movers to higher transfers. Our focus on the interplay between games advances prior studies on the transportability of lab results, allowing us to investigate how qualitative results (the ranking of mean transfers across games) and point estimates of behavioral differences between decision situations (the within-subject differences in transfers across games) generalize to other units, observations, and settings.
Detecting violations of transportability in laboratory designs constitutes a lively research area within experimental economics. This activity has led to significant advances in the way social scientists implement and interpret laboratory studies (see the overviews by Fréchette 2016; Galizzi and Navarro-Martínez 2018; Levitt and List 2007). These efforts have, however, remained selective, focusing on particular aspects of laboratory designs one at a time, such that results regarding lab findings’ sensitivity toward changes in implementation are often mixed. The “replication crisis” in the social sciences (Chang and Li 2015; Freese 2007; Open Science Collaboration 2015) reinforces the call for thorough tests of experimental reliability, more diverse samples, and taking into account of potentially heterogeneous treatment effects. The narrow variation of sociodemographics in standard experimental subject pools remains conspicuous (Druckman and Kam 2011; Henrich, Heine, and Norenzayan 2010; Peterson 2001), particularly when experimenters seek general insights into human behavior or estimate treatment effects that may interact with individuals’ background characteristics.
Against this backdrop, we systematically assess the transportability of laboratory results and map safe grounds for behavioral studies conducted both in the laboratory and online. In the remainder, we proceed as follows: In the second section, we use Cronbach’s (1982) decomposition of laboratory designs into units, treatments, observations, and settings to delineate how each dimension relates to the general desideratum of transportability. In the third section, we discuss established protocols useful in identifying threats to external validity in social science lab research. This review will motivate our own test strategies and highlight how our four studies complement the existing literature. In the fourth section, we outline our design. The fifth section presents our results. In the concluding section, we discuss our findings’ practical implications for experimenters in the social sciences.
Demands to Transportability
Cronbach (1982) defines laboratory designs as combinations of specific units, treatments, observations, and settings. The acronym utos refers to the particular “instances on which data are collected” (p. 78). Each dimension has consequences for the transportability of laboratory results (see also Shadish et al. 2002; we follow their simplified conceptualization).
Units refer to the participants of a laboratory study. For external validity, participants must be broadly representative of the target population to which one wishes to generalize. This implies random sampling from the target population and the use of inference statistics. Generalizability under nonrandom sampling requires—as a minimal condition—that sociodemographic characteristics relevant to sustaining expected treatment effects overlap in the subject pool and the target population.
Treatments represent the randomized stimuli participants are exposed to. Treatments should reproduce real-world conditions as closely as possible. It is most important for theory-driven experiments, however, that treatments closely represent the theoretical concepts under study (construct validity). In addition, treatments should be well calibrated. Subtle treatments, for example, induce the risk of experimenters mistaking a lack of treatment perception for a null result (treatment validity).
Observations denote the measurement of outcome variables. In laboratory studies, reactivity is a major measurement concern. Subjects’ feeling of being observed can shift measurements toward socially desirable outcomes (Pygmalion effect) and subjects potentially bias measurements by forming beliefs about the purpose of scientific inquiry (experimenter demand effect). Online experiments, which have recently become popular, offer increased anonymity but less control over the participants’ surroundings.
Settings characterize the context of data generation. Transportability, again, relates to the mapping of the laboratory setup to real-world conditions. The artificial lab context generally runs counter to this criterion but at least allows for “experimental realism”: Experimenters must implement theoretically relevant features in a way that allows participants to assign similar meanings as they would in natural contexts.
Cronbach’s dimensions indicate the range of validity for a given laboratory study. Results directly generalize to units, treatments, observations, and settings fully covered in the experiment (utos). Generalizations to conditions beyond those covered in the laboratory (which Cronbach terms UTOS) require additional bridging assumptions. The range of validity straddles, however, for conditions clearly deviating from the empirical implementation in at least one of these four dimensions. In such cases, Cronbach speaks of *UTOS. Here, the laboratory design no longer sustains transportability.
The main purpose of experimental research is to test causal relationships derived from theoretical hypotheses (Martin and Sell 1979; Willer and Walker 2007). External validity, however, is compromised if elements not randomized by the design, such as population, period, or setting, interact with the hypothesis under study (Zelditch 2014). Ideally, theory should inform about the scope of its application and delineate potential heterogeneous treatment effects to enable valid experimental tests. If underlying theories are incomplete—as in the case of “effect experiments” (Zelditch 2014:183)—the challenge of establishing external validity is much greater (Schram 2005). Behavioral economists, for example, frequently measure rates of behavior in incentivized decision situations from convenience samples in order to generalize regularities of human behavior (e.g., “social preferences”) or infer effects of “culture” on observed rates of behavior (see Kessler and Vesterlund 2013; Levitt and List 2007 for critique). Among other things, our research will underscore the problems associated with such empirically driven applications of laboratory designs.
Prior Results and Our Contribution
Following Cronbach’s (1982) typology as a structuring framework, we briefly discuss established designs for identifying threats to the transportability of laboratory results. We mainly draw on studies from experimental economics which, in the last decade, saw lively research on the methodological issues of laboratory research. We restrict our review to studies identifying potential violations based on protocols measuring prosocial behavior 2 and highlight how our four studies advance prior work.
Units
Multilocation experiments evaluate the sensitivity of laboratory results to locally recruited subject pools. Roth and colleagues’ (1991) parallel implementation of bargaining games at universities in Jerusalem, Ljubljana, Pittsburgh, and Tokyo is a classic in this domain. Close monitoring of local experimenters, careful translations, and the adjustment of stakes according to differences in purchasing power led the authors to conclude that “[b]ecause of the way the experiment was designed […] the differences in bargaining behavior among countries are not due to differences in languages, currencies, or experiments but may tentatively be attributed to cultural differences” (p. 1068). Many studies followed (e.g., Brandts, Saijo, and Schramand 2004; Henrich et al. 2001; Kocher et al. 2008), comparing elicited behaviors across locations; yet—just as in Roth et al. (1991)—they confound local pool effects with differences in nationality and culture. We fill this gap in study 1, comparing laboratory results across student-subject pools at two German universities in Leipzig and Munich.
A second design evaluates whether lab results from student participants transport to broader, more representative populations. Studies of this type invite nonstudent residents from the proximity of a university to participate in lab sessions (Anderson et al. 2013; Belot, Duch, and Miller 2015; Cappelen et al. 2015; Falk, Meier, and Zehnder 2013) and compare the results to control sessions featuring student participants. 3 These comparisons find students less generous, trustful, and cooperative than their nonstudent counterparts. Apparently, social-preference parameters estimated from student pools do not generalize to more general samples. 4 We complement these efforts in study 3, comparing our student baseline to findings from a nationwide implementation conducted over the Internet.
Observations
Subjects’ feelings of being observed can shift measurements toward socially desirable outcomes. A common strategy to assess reactivity in the laboratory relies on the variation of anonymity conditions. Extending from standard setups—which protect anonymity toward other subjects—Franzen and Pointner (2012) and Hoffman, McCabe, and Smith (1996) use procedures which ensure anonymity toward the experimenter as well (using blinds, anonymized envelopes, or randomized-response techniques). Both studies report decreased rates of socially desirable behavior under increased anonymity. Barmettler, Fehr, and Zehnder (2012), on the other hand, find no effect of anonymity toward the experimenter. We address subject reactivity with a manipulation of anonymity conditions in our two laboratories. If subjects’ feeling of being observed affects measurements in the laboratory, we should encounter less prosocial behavior with rising anonymity levels. Our manipulation does not aim at testing theoretical explanations of prosocial behavior (e.g., social control vs. internalized norms) but tests the comparability of data generated under different anonymization procedures commonly used in social science lab research.
Anonymity is also attainable through online experiments. These have become increasingly popular among social scientists due to both low costs and access to broad participant pools (e.g., Gosling et al. 2010; Rand 2012). Online experimenters, however, obtain no direct control over the participants’ surroundings, which may pose threats to internal validity (Clifford and Jerit 2014; Reips 2002). For example, subjects may find themselves observed by others during participation, search the Internet for eligible strategies, or disbelieve the supposed interaction with other human subjects. A rigorous test strategy for mode effects of data collection requires members of the same population to take part in the same study in either the lab or the online version. Drawing on student participants, Beramendi, Duch, and Matsuo (2016) find no mode effect on various outcome measures, including the DG and a modified version of the Public Goods Game. The authors, however, failed to randomize subjects effectively, leading to marked sociodemographic differences between lab and online participants. Hergueux and Jacquemet (2015), on the other hand, randomized students to parallel lab or online sessions. Their study finds higher rates of selfish behavior among lab subjects. In their study, however, online participants received payoff through PayPal and—being spared traveling to the physical lab—faced lower participation effort. We fix these issues in study 2, randomizing student subjects into either lab or online sessions while keeping participation effort constant across modes. We then compare our online results to lab results obtained under varying anonymity conditions.
Settings
Manipulations of the setting of data generation address the crucial issue of “real-world” generalizability. A growing number of studies compares lab behavior with choices made in concealed field experiments. In a rigorous variant of this design, researchers take efforts closely to map the artificial decision space (e.g., DG) onto the unobtrusive measurement (e.g., giving to a charity) and then exploit within-subject comparisons between settings. Typically, these studies find qualitative lab–field correspondence: Individuals who share, cooperate, or trust in the lab also exhibit more prosocial behavior in the field (e.g., Benz and Meier 2008; Englmaier and Gebhardt 2016; Franzen and Pointner 2013). Some implementations, however, report zero correlations (for a review, see Galizzi and Navarro-Martínez 2018) and, more importantly, the empirical evidence at hand is likely to suffer from publication bias (Coppock and Green 2015). An alternative design addressing the realism of experiments utilizes the sampling of professionals with relevant task experience (e.g., Alevy, Haigh, and List 2007; Fehr and List 2004; Potters and van Winden 2000) in “framed field experiments” (Harrison and List 2004:1014): Because legislators, managers, and traders import their day-to-day experiences into the experimental situation, instructions can trigger work-related frames and heuristics altering the context of the experiment (Fréchette 2015).
A related and recently popularized strategy to vary experimental settings makes use of the large and heterogeneous participant pool sustained at MTurk (e.g., Amir, Rand, and Gal 2012; Berinsky, Huber, and Lenz 2012; Crump, McDonnell, and Gureckis 2013). Many consider the platform a real online labor market (Horton, Rand, and Zeckhauser 2011; Rand 2012) in which workers seek profit-maximizing allocation of time and qualification. In addition, many workers at MTurk are experienced participants in social experiments (Chandler, Mueller, and Paolacci 2014; Rand et al. 2014) and the perceived social distance is likely to be larger among MTurk participants than among traditional laboratory subjects. As a result, experimenters can expect to observe different and more “rational” situational logics than what one is used to from physical laboratories. In study 4, we replicate our online implementation at MTurk to test the robustness of behavioral data collection against a change in the research setting.
Treatments
Methodological research on laboratory designs makes frequent use of two decision situations, the dictator game (DG) and the trust game (TG). In each situation, participants must choose between self-interested and socially desirable behaviors. The games are thus natural candidates for investigations into anonymity effects, mode effects, and the sensitivity of results to different samples and contexts.
In DG, a participant receives a monetary stake and can decide how much of the pie (0–100 percent) she passes to a receiver (Kahneman, Knetsch, and Thaler 1986). Experimenters typically interpret giving as a manifestation of prosocial preferences. TG, on the other hand, mimics an investment decision, thereby introducing the possibility of nonreciprocity by a second mover (Berg, Dickhaut, and McCabe 1995): A trustor and a trustee each receive a stake. The trustor can decide how much of her stake (0–100 percent ) she sends to the trustee. The experimenter doubles this amount. The trustee then decides how much of the doubled amount (0–100 percent) she sends back to the trustor. Placing trust depends on the trustor’s belief in the validity of a prosocial norm of reciprocity securing trustee’s trustworthiness. Unlike in DG, first movers are required to form expectations on second movers’ likelihood of reciprocation (Glaeser et al. 2000).
The two decision situations do not qualify as experiments due to their lack of treatments. The interplay between games, however, allows us to replicate the common finding (e.g., Camerer 2003; Camerer and Fehr 2004) that an investment opportunity (TG) motivates first movers to higher transfers than altruism (DG). We expect first movers to share more in TG than in DG. Specifically, we test whether the differences in mean transfers transport to different samples, modes, and settings. Substituting TG for DG varies a bundle of aspects (e.g., parametric vs. interactive decision situation, endowment for one vs. two players), and hence, our variation does not permit isolation of a narrow causal effect that is more typical of the sociological literature using experiments. Still the within-subject comparison across games provides an estimate of the “treatment” effect of changing from one decision situation to another. Our focus on this interplay extends prior studies of lab results’ transportability, as it allows us to investigate how qualitative results (the ranking of transfers across games) and behavioral differences between laboratory conditions (the within-subject differences in transfers across games) generalize to other units, observations, and settings.
Design
Table 1 summarizes the different study designs (see Online Appendix A1 for sample descriptives). We first describe the sampling of participants. Our procedures then include randomization, instructions, incentives, collection of survey data, and payoff.
Study Details.
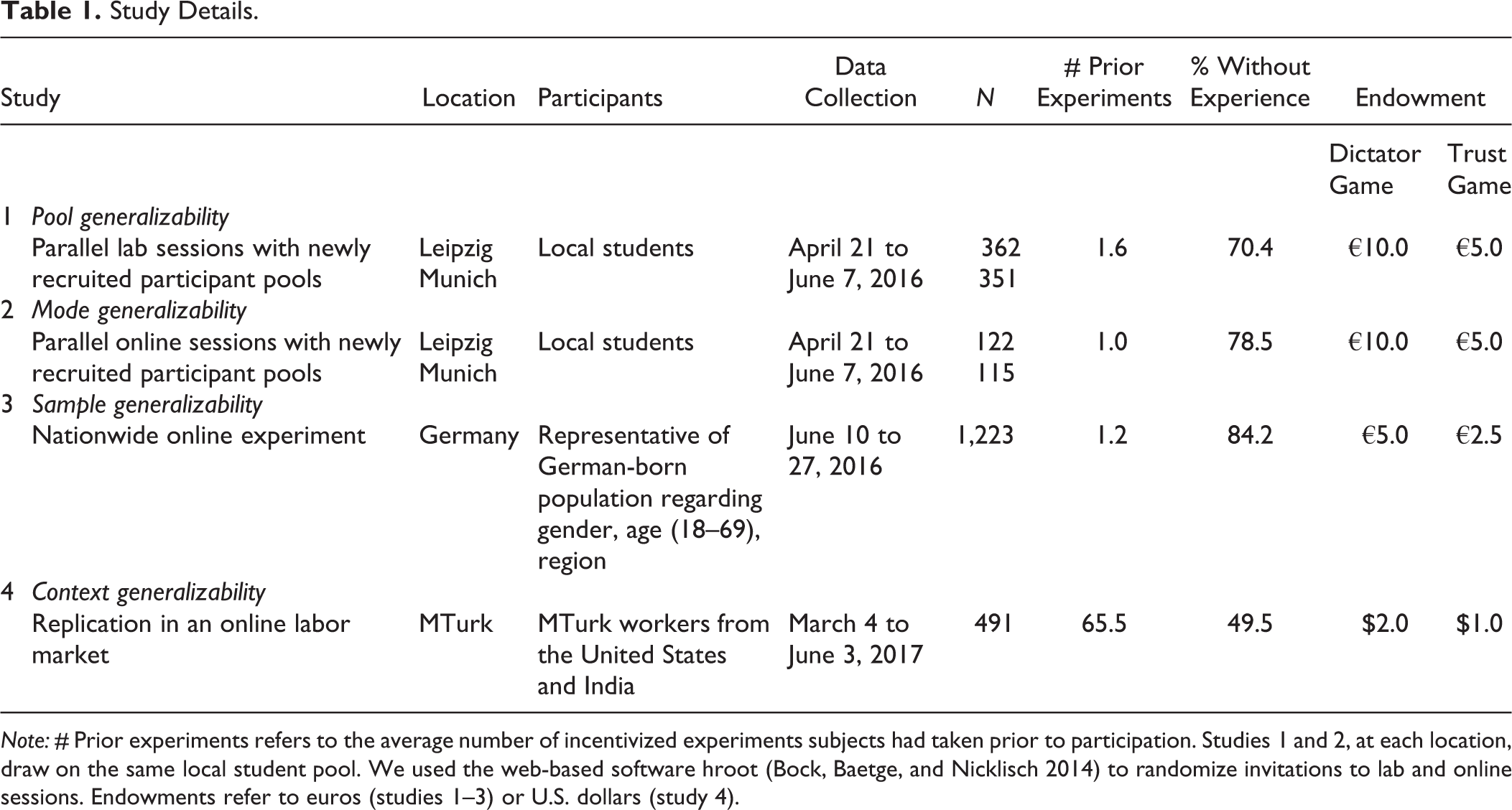
Note: # Prior experiments refers to the average number of incentivized experiments subjects had taken prior to participation. Studies 1 and 2, at each location, draw on the same local student pool. We used the web-based software hroot (Bock, Baetge, and Nicklisch 2014) to randomize invitations to lab and online sessions. Endowments refer to euros (studies 1–3) or U.S. dollars (study 4).
Sampling
For studies 1 and 2, we established two student-subject pools at universities in Leipzig and Munich. We standardized recruiting across both locations advertising sign-up in introductory lectures, campus cafeterias, and university websites. From each pool, we randomly selected registered students to participate in a given lab or online session synchronized across locations. In study 3, we examine a cross section of the German population sampled from Forsa’s offline-recruited online access panel. Forsa uses county-level random digit dialing to register participants who privately use the Internet at least once a week. Our sample is representative of the German-born population with regard to gender, age, and administrative district and highly heterogeneous with regard to education, occupation, and income. In study 4, we replicate our setup at MTurk, recruiting workers from the United States and from India. Both countries make up the largest shares of platform participants (Ipeirotis 2018). For each country, we advertised participation twice per day (early morning and late afternoon local time).
Randomization
Each subject participated in DG and TG. We randomized participants to sequences of games and first- and second-mover roles. The absence of feedback in-between games secured independence of sequential behavior, enabling within-subject comparison of decision situations. To neutralize reputation effects, we randomly matched participants to another anonymous participant for each decision. 5
Instructions
We standardized the decision interface in our four studies using a web-browser implementation based on the package SoSci Survey (www.soscisurvey.de). Our instructions map participants’ choices to payoffs as clearly as possible using GIF-animated examples but avoiding suggestion of specific strategies or frames. We only allowed individual transfers in each game to be multiples of 10 percent of the endowment (including 0 percent). In studies 1–3, we used instructions in German; study 4 uses similar instructions in English (see Online Appendix A6). We monitored understanding using control questions following each decision.
Incentives
In studies 1 and 2, we incentivized DG with €10; in TG, each player received an endowment of €5. Rather than keeping stakes constant across samples, we chose monetary incentives typical for the respective participant pool to counter self-selection based on monetary motivations; in studies 1 and 2, stakes also need to cover subjects’ effort to travel to the laboratory. In study 3, DG was worth €5 and each player in TG received an endowment of €2.5. In study 4, stakes were US$2 in DG and US$1 in TG. Critics may find fault at our heterogeneous stake levels pointing to the idea that observed prosociality may decrease in stake sizes. Prior evidence from laboratory (e.g., Camerer and Hogarth 1999; Carpenter, Verhoogen, and Burks 2005) and online studies (e.g., Amir et al. 2012; Keuschnigg, Bader, and Bracher 2016), however, indicates that—although monetary stakes increase selfishness compared to unincentivized games—differences in positive stakes have negligible effects on laboratory results in fairness and cooperation research.
Survey Data
We requested each participant to fill out a questionnaire including items on sociodemographics, experimental experience, and—in our online studies 2–4—the physical and social surroundings during participation (see Online Appendix A1). We administered the questionnaire at the end of each session.
Payoff
To compute individual payoff, we randomly drew one of ego’s (and partner’s) decisions in the games. We made randomized rewards (Bolle 1990) common knowledge in our instructions, explaining that each decision could fully determine a participant’s reward. In studies 1 and 2, we paid participants in cash at the end of each session. Payoff included a fixed showup fee of €2.50 and additional earnings of €5.13 on average (min = 0.00, max = 15.00). In study 3, participants received payoff in the form of an Amazon voucher, complying to Forsa’s standard payment scheme. We set the showup fee to 2.00, additional earnings average €2.83 (min = 0.00, max = 7.50). In study 4, workers received payoffs via MTurk. As typically done in online experiments at MTurk, we chose a showup fee of US$1, additional earnings average US$0.85 (min = 0.00, max = 3.00).
We introduced additional manipulations to identify both anonymity effects in laboratory data collection and a potential mode effect between laboratory and online data collection. We randomized each experimental treatment on the session level.
Anonymity
Each lab participant in Leipzig and Munich was presented with one of three anonymity conditions (see Online Appendix A7 for photographic documentation). (1) Low anonymity: In this control condition, workplaces had no shielding and participants could see one another while taking decisions (
Modes
We randomized student subjects in Leipzig and Munich to participate in either a laboratory or an online session. To avoid self-selection, we informed participants only after enrollment for a certain session about the respective mode of data collection. We held online sessions simultaneously to our laboratory sessions, thus neutralizing the “mode selection effect” and isolating the “mode measurement effect” (Hox, de Leeuw, and Klausch 2017:511). To homogenize participation effort, online participants (
Results
Figure 1 summarizes dictators’ and trustors’ average transfers (as percentages of their individual endowments) across studies. Pooled across samples, modes, and research contexts, the mean allocation in DG is 42.2 percent. Changing from DG to TG increases average transfers by 10.4 percentage points to 52.6 percent. 6
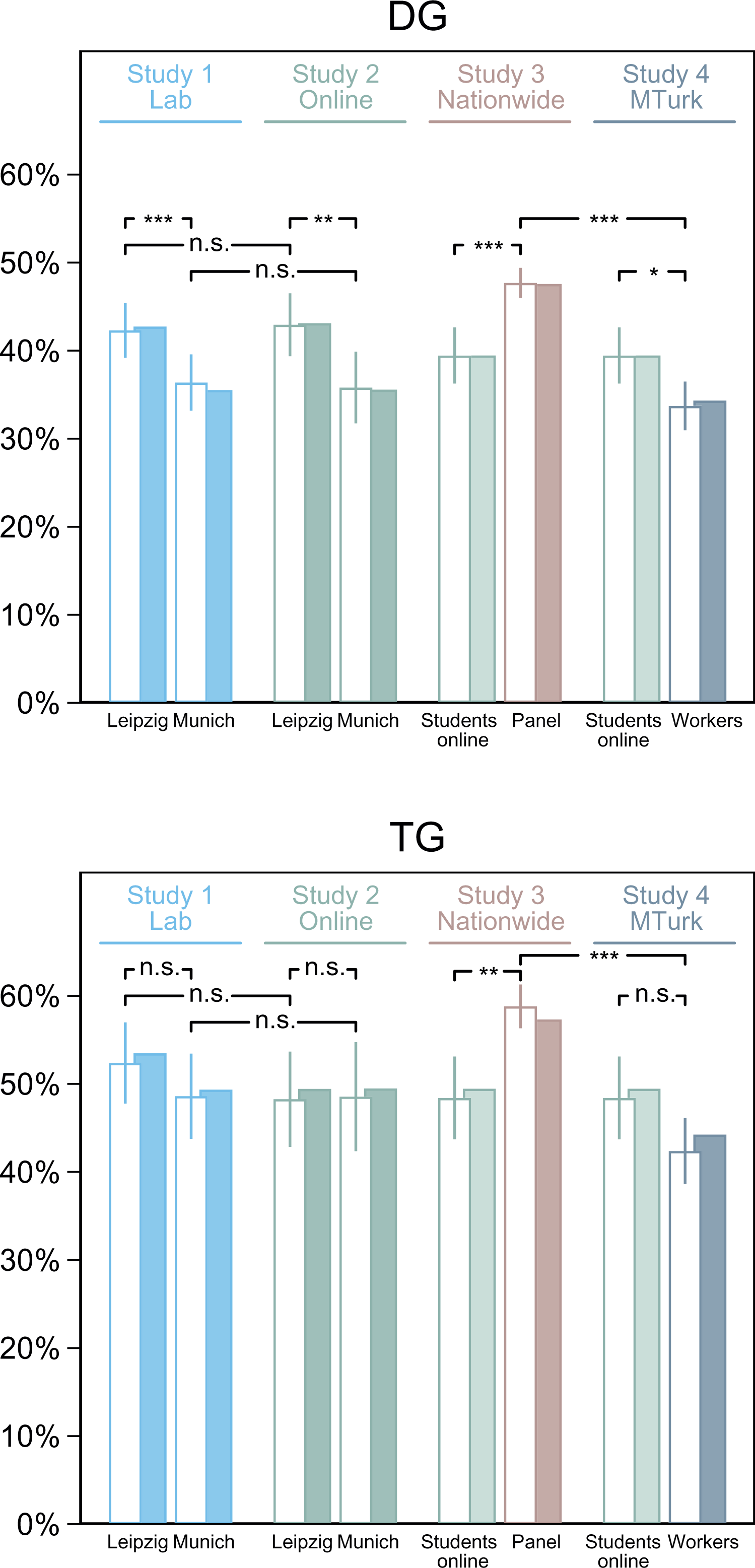
Quantitative results. Shaded bars show unconditional means of first-mover transfers in the dictator game (DG) and the trust game (TG), respectively. Blank bars represent conditional means obtained from ordinary least square (OLS) regressions keeping underlying sociodemographics constant. We include 95 percent confidence intervals and seven pairwise comparisons (t tests). ***p < .001, **p < .01, *p < .05. n.s. = nonsignificant.
To evaluate transportability of quantitative results, we test their sensitivity to locally recruited student-subject pools (study 1), the comparability of behavioral data collected online and, under varying anonymity conditions, in the laboratory (study 2), the generalizability of elicited behavior from student participants to the broader population (study 3), and the stability of results across settings (study 4). This entails running seven pairwise comparisons for both DG and TG as indicated in Figure 1. We report p values of two-sided t tests with robust standard errors throughout. To account for different sociodemographic compositions in our samples, we further adjust our measures by a list of participants’ background characteristics (see Online Appendix A2 for model specification). To speak of cross-sample differences in rates of observed behavior, those need to resist conditioning. Five of the seven pairwise comparisons return significant differences for DG, but only two of the seven do so for TG. 7
Pool Generalizability
In study 1, we find marked differences in mean DG allocations across student pools: In Leipzig, dictators allocate 42.7 percent on average; in Munich, they share only 35.5 percent of their endowment (see shaded bars in Figure 1, top panel). This gap remains after controlling for sociodemographic differences in local pool composition (blank bars; t = 4.44, p < .001). In TG, Leipzig students transfer 53.5 percent on average; in Munich, this rate is 49.3 percent. These rates are not significantly different under conditioning on sociodemographics (blank bars in Figure 1, bottom panel; t = 1.76, p = .079). Our synchronized test thus establishes pool generalizability for investment decisions. For altruistic donations, however, elicited behavior varies considerably between locations.
Mode Generalizability
In study 2, we find no evidence for a mode effect of data collection. For both games, elicited behavior is not significantly different irrespective of whether we run the study in a laboratory or online. This holds for student pools in both Leipzig (t = 0.36, p = .721 in DG; t = 1.52, p = .129 in TG) and Munich (t = 0.27, p = .785 in DG; t = 0.02, p = .987 in TG). These results further substantiate the cross-location difference found for DG in study 1: By shutting off potential experimenter effects and differences in labs’ physical appearance, the online design identifies the gap between locations as a genuine pool effect. Furthermore, because the gap resists conditioning on sociodemographics, unstable results across locations obviously do not stem from different pool compositions.
Anonymity
In Figure 2, we compare online results to the three anonymity conditions participants faced in our physical labs. 8 At each location, lab results do not differ across anonymity conditions. Setups creating anonymity toward other participants (standard anonymity; t = 0.48, p = .633 in DG; t = 1.13, p = .261 in TG) and, additionally, toward the experimenter (high anoymity; t = 0.04, p = .966 in DG; t = 0.61, p = .541 in TG) do not yield different results than a low-anonymity setup. Similarly important, the results from either anonymity condition do not differ significantly from our online implementations at both locations. 9 Anonymity effects, it seems, are not a major concern for laboratory research.

Anonymity conditions in the laboratory. Shaded bars show unconditional means of first-mover transfers in the dictator game (DG) and the trust game (TG), respectively. Blank bars represent conditional means obtained from OLS regressions keeping underlying sociodemographics constant. We include 95 percent confidence intervals. All pairwise comparisons between anonymity conditions are nonsignificant.
Sample Generalizability
In study 3, we contrast student-based results to those obtained in the broader population (Figure 1). Because we ran our nationwide study over the Internet, our online results among students provide the relevant benchmark. Even after controlling for sociodemographic differences, results for students (39.4 percent in DG; 48.4 percent in TG) do not generalize to a broader population sample, whose members on average share significantly more in both DG (47.7 percent; t = 3.72, p < .001) and TG (58.8 percent; t = 3.20, p = .001). Differences in comprehension of instructions may further aggravate direct comparisons between student and nonstudent samples. To test whether difficulties in understanding drive prosocial choices in our nationwide sample, we introduced a time-pressure/time-delay treatment for nonstudent participants. We report these results in Online Appendix A3 and find no statistically significant effect of this manipulation, suggesting that difficulties in understanding do not explain higher rates of prosocial behavior among non-students.
Context Generalizability
In study 4, we replicate our online implementation at MTurk to test the robustness of behavioral data collection against a change in the research setting (Figure 1). On average, crowdworkers allocate 33.7 percent in DG and transfer 42.4 percent in TG. Both rates are lower than the quantitative results obtained in our university-implemented setting using volunteer student participants (t = 2.41, p = .016 in DG; t = 1.76, p = .078 in TG) and participants from the broader population (t = 9.61, p < .001 in DG; t = 8.09, p < .001 in TG). Quantitative results, already heterogeneous across student and nonstudent samples, apparently do not transport to another setting. MTurk workers use more “rational” situational logics than we find among either students or members of the wider population in Germany. We find only little evidence, however, for different decision-making by experienced participants: Non-naive subjects in all studies, on average, share less in DG—but only 0.005 percentage points per prior experiment—while experience has zero effect in TG (see Online Appendix A2). Note that our results are robust to the adjustment for experience. Hence, experience cannot explain the behavioral differences between the crowdworkers and the participants in our remaining studies.
In Figure 3, we test for the stability of behavioral differences between decision situations across samples, modes, and settings. We focus on conditional means, keeping sociodemographic composition constant across studies. Shaded bars show average DG allocations. Blank bars on top represent first-mover transfers in TG. The difference between shaded and blank bars shows by how much, in each study, TG transfers exceed DG allocations. We include 95 percent confidence intervals for the difference in average transfers between DG and TG. Unlike our statistical tests above, which we based on between-subject comparison, we now use variation within subjects to test for significance of this “treatment” effect. Our main qualitative result is robust to changes in units, observations, and settings: In each study, average TG transfers exceed DG allocations substantially and significantly. The exact size of this difference, however, varies considerably. Among student participants in studies 1 and 2, differences between DG and TG are small in Leipzig (8.6 percentage points, t = 3.78, p < .001) but large in Munich (12.0 percentage points, t = 5.46, p < .001). In Munich, TG substantially increases transfers, compensating for the lower propensity to share in a situation of altruism. Using mean DG allocations as a baseline, the change to TG raises average transfers by 33.1 percent in Munich, but only by 20.2 percent in Leipzig (t = 1.96, p = .050). TG in the nationwide sample raises average sharing as measured in DG by 23.3 percent (t = 8.43, p < .001) and, at MTurk, by 25.6 percent (t = 5.16, p < .001).

Qualitative results. Shaded bars show conditional means of first-mover transfers in the dictator game (DG). Blank bars on top represent conditional means in the trust game (TG). 95 percent confidence intervals, here, indicate significance of the within-subject difference DG–TG (paired t tests).
Implications
In laboratory research, the benefits of artificiality—systematic variation of experimental conditions, control of confounders, and replicability—trade off with generalizability to the “real world.” We used Cronbach’s (1982) decomposition of experiments into units, treatments, observations, and settings to identify those parts of laboratory designs which undermine their external validity. Different samples, types of stimuli, measurement modes, and research contexts may violate transportability in that they produce varying rates of observed behaviors and—more worryingly for experimental research—heterogeneous treatment effects. In four studies, we assessed each dimension’s importance for establishing transportability.
We demonstrated that a common class of laboratory designs—interactive games measuring fairness, trust, and reciprocity—easily violates the transportability of percentage rates of observed behavior: First, synchronized lab implementations revealed substantial differences in elicited behavior between two locally recruited student-subject pools (study 1). This cross-location gap persists in alternative online implementations (study 2), which shut off potential experimenter effects and differences in labs’ physical appearances. One may thus speculate about regional idiosyncrasies bringing about specific patterns of behavior that jeopardize pool generalizability. Second, we find much higher rates of prosocial behavior among a broader population sample (study 3), indicating a lack of sample generalizability, as results yielded from student participants do not transport to a more representative population. Third, in a replication at MTurk (study 4), we find rates of prosocial behavior even lower than in our student samples. This clearly rejects context generalizability of quantitative results.
Even when keeping sociodemographics constant, data collected from the most frequently used participant groups, students and crowdworkers, differ significantly from those obtained from the broader population—and altruistic behavior as measured in the DG proved to be particularly sensitive to changes in units and settings. We chose stake levels typical for the respective participant pool. As a side effect, we cannot fully rule out the possibility that differences across samples and contexts may be partly due to differences in monetary incentives. Given the well-documented finding that specific sizes of positive stakes have negligible effects in interactive games of fairness, trust, and reciprocity (Johnson and Mislin 2011; Larney, Rotella, and Barclay 2019), it is highly unlikely that stake differences drive our results. In fact, we find the lowest level of prosocial behavior in the setup providing the smallest stakes (study 4)—a finding that runs counter the idea that prosociality decreases in stake sizes.
Our unstable quantitative results indicate that preference parameters (such as “prosociality”) measured in laboratory designs cannot be transported to other populations, and their use in establishing descriptive results about “human nature” is questionable. The heterogeneity in elicited behavior that we found for decision situations targeting prosociality presumably also affects laboratory studies using other types of decision situations. Hence, interpretations of marginal totals obtained in laboratory research remain descriptive and studies reporting an intervention’s consequence in absolute terms risk describing only highly local results. However, nobody in the social sciences would expect a volunteer sample of, say, student respondents to generate survey data identical to a random population sample. The local bound of descriptive results is thus not an exclusive feature of laboratory designs but mainly a sampling issue.
Against this cautionary backdrop, our results sustain an optimistic view for the external validity of theory-driven experiments focusing on the identification of causal effects. Qualitative results, in our case the finding that transfers in the TG on average exceed DG allocations, are remarkably robust across samples, measurement modes, and research contexts. The problem of unstable results reemerges, however, if experimenters estimate treatment effects from contrasting with an unstable control condition. In our studies, differences in mean transfers between DG and TG vary as altruistic decisions in DG interact with both the characteristics of the sample under consideration and the specific setting. If control conditions provide unstable measures like DG, point estimates of treatment effects may be seriously biased. Heterogeneous treatment effects then stem from an unstable control condition rather than from heterogeneous responses to the treatment itself.
Similarly important for practitioners, we find that specific implementations of a laboratory study do not distort its results. For our physical labs, we find no evidence for anonymity effects in data collection—although decisions concerning prosocial behavior should be particularly liable to social desirability bias. If we increase participant anonymity, rates of elicited behavior do not differ significantly from conditions lacking specific anonymization measures. Our results are thus in line with Barmettler et al. (2012), who question the necessity of complicated anonymization procedures in social science laboratories. Reactivity may still drive behavior, but we find no effect within the spectrum of anonymity precautions typically used in experiments. This suggests comparability of results from laboratory studies differing in this respect. Finally, we find full support for mode generalizability. Keeping participation effort constant across parallel lab and online sessions, participants from two student-subject pools generated similar data, irrespective of participating in the lab or online. Taking into account laboratory studies’ weak generalizability to a broader, more representative population, we believe that online experiments can serve as a sorely needed complement to laboratory designs in the social sciences.
To conclude, successful and meaningful laboratory research in sociology—just as in any other empirical discipline—requires joint efforts of ongoing replication. We can only regard laboratory results as well-established facts after their successful cross-validation, ideally in studies using complementary samples and designs. This also holds for our results, which we hope will be replicated in future studies using alternative decision situations frequently used in social science lab research.
Supplemental Material
Supplemental Material, Appendix_Transportability - On the Transportability of Laboratory Results
Supplemental Material, Appendix_Transportability for On the Transportability of Laboratory Results by Felix Bader, Bastian Baumeister, Roger Berger and Marc Keuschnigg in Sociological Methods & Research
Supplemental Material
Supplemental Material, Appendix_Transportability - On the Transportability of Laboratory Results
Supplemental Material, Appendix_Transportability for On the Transportability of Laboratory Results by Felix Bader, Bastian Baumeister, Roger Berger and Marc Keuschnigg in Sociological Methods & Research
Footnotes
Authors’ Note
Felix Bader and Marc Keuschnigg contributed equally to this work.
Acknowledgments
We thank Peter Hedström, Karl-Dieter Opp, Merlin Schaeffer, Tobias Wolbring, and three anonymous reviewers for valuable comments. We are grateful to Hanna Nau, Leona Przechomski, Lennart Rösemeier, Fabian Thiel, Janine Thiel, and Anna Wolf for excellent research assistance and to Marion Apelt and Regina Heindl for administrative support.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This project received financing through generous grants from the German Research Foundation (BE 2373/3-1 and KE 2020/2-1). Marc Keuschnigg further acknowledges funding from the European Research Council (324233), the Swedish Research Council (445-2013-7681, 340-2013-5460), and Riksbankens Jubileumsfond (M12-0301:1).
Supplemental Material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.