
Abstract
Correspondence studies are popular tools for assessing discrimination against minorities, for example, in the labor market. Typically, two fake Curriculum Vitae (CVs) are sent to multiple job openings. The CVs are equivalent except for a mark identifying the disadvantaged. While it is straightforward to establish discrimination from minorities’ lower response rates, it is often unclear what its source may be. Discrimination may result as much from employers’ aversion toward a minority, as from perceptions that members have lower or more dispersed abilities that are unstandardizable in a CV. We refine existing methodologies to propose a wider-scope method capable of disentangling these three sources of discrimination and establish its face validity applying it to a correspondence study aimed at assessing labor market discrimination against ex-convicts in a local market.
Introduction
Audit studies are increasingly popular tools for assessing discrimination in employment (Bertrand and Mullainathan 2004; Pager 2003), housing decisions (Ewens, Tomlin, and Wang 2014), credit approvals (Dymski 2006), or consumer market transactions (Rich 2014). Typically, two demands (for a job, rental, credit, or product) are sent to a random sample of decision makers from fake applicants. Applicants’ merits are matched in everything, except their having or not a trait which may trigger the discriminatory practices that the experimenter aims to observe from decision makers. This trait is generally a mark/stigma signaling membership into a socially disadvantaged group—a minority, thereafter 1 —such as women (Correll, Benard, and Paik 2007), an ethnic group (Booth, Leigh, and Varganova 2012; Pager 2003), or ex-convicts (Uggen et al. 2014). If decisions on the applications are significantly less favorable for minorities, discrimination is established.
The main difficulty in audit studies is not to find discrimination but to identify its various sources: from an aversion toward minorities—taste discrimination (Becker 1971)—to rational assessments about differences between minority and majority members in typical productivities—first-moment statistical discrimination—or in the variability of such productivities within groups—second-moment statistical discrimination (Heckman 1998; Heckman and Siegelman 1993; Neumark 2012).
While there have been some proposed solutions to distinguish taste from first-moment statistical discrimination—see, for example, Altonji and Perriet (2001), Lahey (2008), or Ewens, Tomlin, and Wang (2014)—and these two from second-moment statistical discrimination (Neumark 2012), to this date, a comprehensive approach combining them into a single method does not exist. The main contribution of this article is to propose such a method, one that allows estimating the three forms of discrimination provided some (testable) assumptions hold. We demonstrate its validity for the simplest form of an audit study—a correspondence study in which the outcome is to be or not to be selected for further screening—and for discrimination in the labor market.
This article is organized as follows. In the first part, we follow Heckman and Siegelman (1993), Heckman (1998), and Neumark (2012) to formalize the problems for separating the three forms of discrimination. In the second part, we review the existing solutions to these problems and propose our own. In the third part of this article, we show method’s usefulness by applying it to data from a correspondence study aimed at detecting discrimination against ex-convicts in a local labor market. Method’s strengths and weaknesses are discussed in the final section.
Taste Discrimination
Taste discrimination is typically defined as resulting from prejudice—a response expressing animus or aversion against an out-group that is not based on reason but on emotion (Lang and Lehman 2012).
Aversion is just one among the possible factors accounting for employers’ decisions to select a candidate for further screening. Heckman and Siegelman (1993) and Heckman (1998) proposed a probabilistic model of employers’ decision-making in which their selection decisions depend not only on prejudicial assessments of candidate’s appeal to employers but also on objective evaluations of candidate’s potential productivity. These evaluations are partly based on qualifications that can be standardized in a CV—on “observables.” They also depend on error-prone guesses about candidates’ unstandardizable qualifications—“unobservables”—based on clues rooted in experience.
More formally, let employer’s decision Y to select a candidate for a job interview depend on an underlying continuous variable Y* capturing candidate’s appeal to employers.
2
This appeal varies according to candidate’s productivity P, such that Y*(P). Candidates will be selected (y = 1), if their appeal equals or exceeds a minimum cutoff level c set by the employer (if Y* ≥ c). Let candidate’s productivity, in turn, depend on a set of candidate’s observable (X
1) and unobservable (
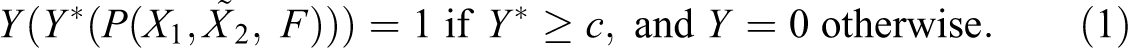
Correspondence studies hypothesize that candidates’ appeal depends both on their productivities (P) and on group membership (G). Minorities are less appealing and less likely to be selected than other candidates. Thus, under the alternative hypothesis:
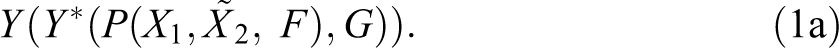
If we assume, for simplicity, that Y* is linear on P and G and that candidates’ productivity-related qualifications are uncorrelated with group membership

If minority candidates are coded as 1 (
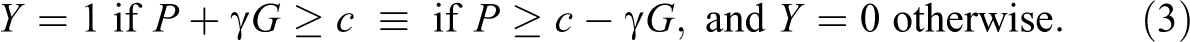
In sum, employers who discriminate minorities because they distaste them apply two cutoffs:
Heckman and Siegelman (1993) argued against interpreting differences in minorities and nonminorities’ appeal to employers in correspondence studies as unequivocally capturing taste discrimination, due to undesired selection effects that cannot be effectively controlled with matching. Matching guarantees that the paired candidates demanding a job are equivalent on observables, except for the mark signaling membership into the minority. However, nothing guarantees that employers perceive the pair as having similar unobservables. Perceptions about the distributions of unobservables across groups, rather than aversion, may lead employers to discriminate against minorities. These perceptions may be about group differences in the mean levels or the dispersion of unobservables. The former lead to first-moment statistical discrimination; the latter, to second-moment statistical discrimination.
First-moment Statistical Discrimination
“First-moment statistical discrimination” (Neumark 2012) is typically portrayed as stemming from rational assessments of in- and out-groups’ stereotypical qualifications, as derived from experience (Levitt 2004). One first manifestation is when employers perceive the mean of the unobservables in the minority to differ from nonminorities’.
As assumed above and demonstrated by Heckman (1998), to estimate
Suppose, for simplicity, that as in Heckman (1998), candidates’ productivities—on which employers base their selection decisions—are a linear function of, first, individuals’

We place a tilde above
In a correspondence study, experimenters fix candidates’ observables in the CVs, generally at similar levels across job offers, as they are not interested in estimating the effect of
Let the relationship between productivity and candidates’ characteristics be deterministic
4
regarding

Put differently, the productivities corresponding to candidates’

where
Let’s assume that employers perceive the means of the normal distributions of unobservable-related productivities to be the same for minorities and nonminorities, that is, that
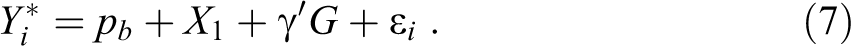
However, if employers thought that minorities have lower (or higher) average productivities linked to unobservables than other candidates

where
One possibility not contemplated in Heckman’s (1998) formalization of first-moment statistical discrimination is that employers may believe that the contribution of unobservables to productivity is different in each group.
6
For example, they might think that hiring minorities may affect negatively the productivities of others workers who hold prejudices against them—see Ewens et al. (2014) for a similar formalization. These beliefs about the different contribution of unobservables’ to groups’ productivities may be important in shaping employers’ assessments of their different productivities. If these beliefs exist, then:
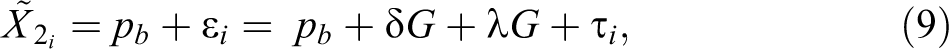
where
Correspondingly, a candidate’s score on the underlying scale of appeal to employers will be:
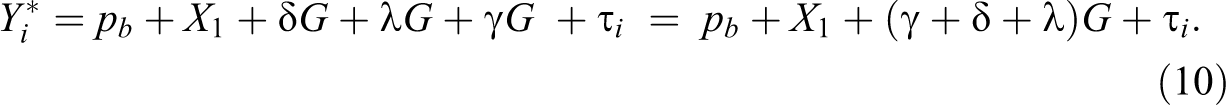
If equation (10) holds,
Second-moment Statistical Discrimination
A second problem in correspondence studies is experimenters’ implicit assumption that the variance in employers’ perceptions of candidates’ unobservables is the same among nonminorities and minorities
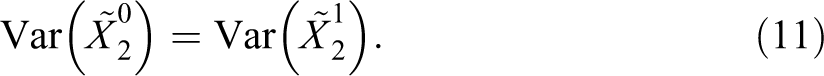
However, employers may perceive that minorities differ more (or less) among themselves in unobservables than nonminorities. For example, experimenters may feel more uncertain about candidates’ unobservables when they belong to groups they know less. As argued by Heckman (1998), if employers perceived groups’ distributions of unobservables as being normally distributed but having different variances, their perceptions would result in different callback probabilities for each group, even if they applied the same selection cutoff to both and thought that both have the same average levels of unobservables (i.e., even if there was neither taste not first-moment statistical discrimination). 7
When groups’ variances differ, it is difficult to predict which group will experience a lower callback probability, for this will depend on whether employers’ selection cutoff is below or above the mean of candidates’ unobservables, and on which group has higher variance. Our problem is how to distinguish this second-moment statistical form of discrimination from the other types.
Suppose that employers exert taste discrimination against minorities but not first-moment statistical discrimination. Further suppose that, as assumed in a typical correspondence study,
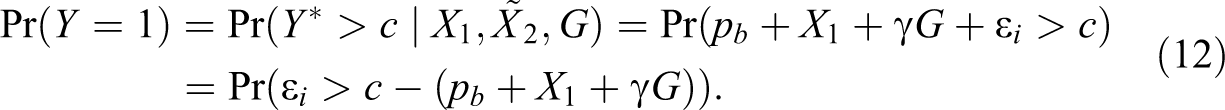
To identify the probit coefficients, they must be expressed in units of standard deviation of, in our case, the random variable
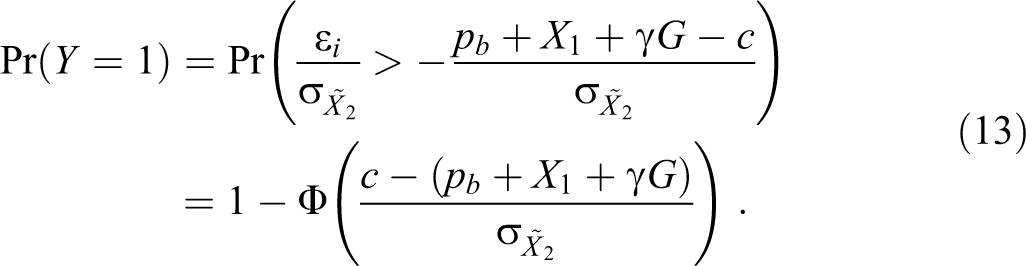
where
In probit models, we cannot know the real variance of the underlying variable
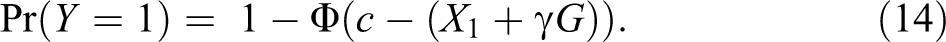
If
In contrast, suppose that employers perceive that the variance of candidates’ unobservables differs in the two groups
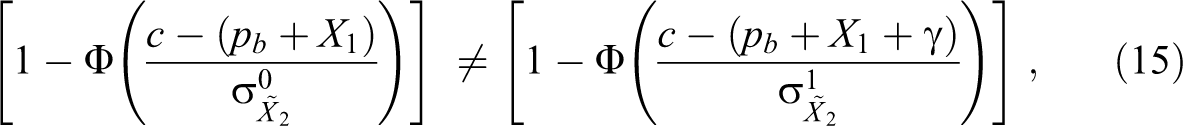
except if:
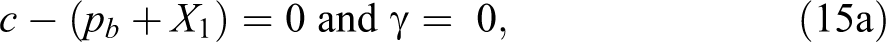
or if
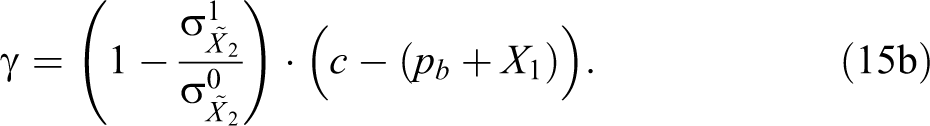
Equation (
15b) results from algebraically finding the value of
Neumark (2012) proposed an equivalent formalization of the problem by making unobservables’ variances a function of group membership in a heteroscedastic probit model:

with
The callback probability expressed in equation (13) could then be reexpressed as:
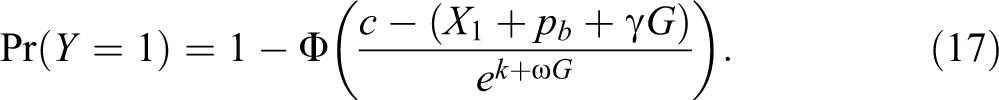
Standardizing equation (17) in relation to nonminorities’ parameters, that is, setting the mean
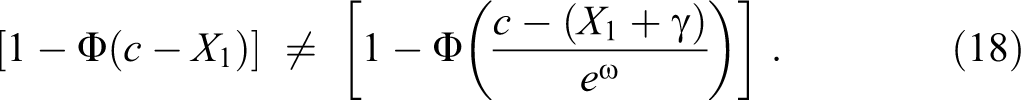
Like equation (15) above, expression (18) states that callback probabilities differ for minorities and nonminorities, unless:

or:
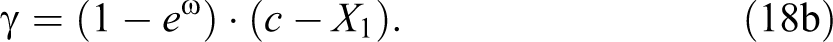
Except for the normalizing assumption
Distinguishing First-moment Statistical Discrimination from Taste Discrimination
The solutions applied in the literature to distinguish first-moment statistical discrimination from taste discrimination take into account their typical definitions—see Guryan and Charles (2013) and Neumark (2016) for recent reviews of this work. Here, we focus only on solutions using correspondence studies, but there have been other innovative approaches to separate statistical from taste discrimination that rely on lab experiments or a combination of field, lab experiments, and surveys (Anderson and Haupert 1999; Castillo and Petrie 2010; Fershtman and Gneezy 2001; Lahey and Oxley 2016; Levitt 2004; List 2004; Masclet, Peterle, and Larribeau 2012; Zussman 2013). The basic intuition behind these solutions, regardless of the methodology they employ, is that if taste discrimination is based on emotion and statistical discrimination rests on reason, only the latter could generate changes in employers’ selection decisions when candidates’ personal merits are experimentally manipulated, signaling that employers act rationally and react to the new information they receive.
As shown previously, in correspondence studies in which candidates are matched on observables, first-moment statistical discrimination ensues when employers perceive that groups differ in average levels of
To estimate
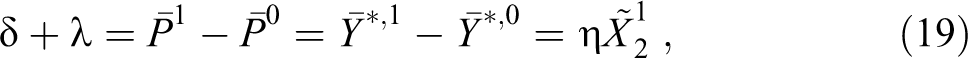
where the superscripts 1 and 0 stand, respectively, for the minority and the nonminority.
In expression (19),
The drawbacks of testing for
Our recommendation is to vary minorities’ levels of observables, under the premise that deficits/surpluses in productivities linked to unobservables can be offset with higher/lower observables (we show how to test this premise below). This solution respects Heckman’s assumption that observables and unobservables are uncorrelated (that

However, adding variation in minorities’
Introducing variation in observables also in the majority group can control for differences between minority and majority members in observables. The experimenter could, for example, set two (or more) levels of observables for candidates applying to each job, sending more than two applications to each opening, and distinguish minority and majority members in each set—for precedents of multiple applications, see Bertrand and Mullainathan (2004), Booth, Leigh, and Varganova (2012), or Ewens et al. (2014). This means adding a coefficient
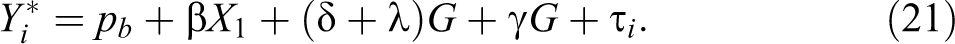
Adding the same variation in
In contrast, we argue that an interaction effect between the level of observables and minority membership should also be expected in the absence of second-moment statistical discrimination, provided that employers select for further screening all (or the first n) candidates who pass a single productivity cutoff, regardless of by how much they exceed it. 11 There is evidence that this selection model is widespread, especially in the first phase of multistage selection processes, and that it helps minorities to overcome deficits in some qualifications with surpluses in others (De Corte, Lievens, and Sackett 2007; Finch, Edwards, and Wallace 2009; Sackett et al. 2001).
If the cutoff can be passed with different bundles of observables and unobservables because what matters to employers is that the selected candidates certify meeting an acceptable threshold of productivity, not how they reach it, then any perceived group differences in productivities would manifest in an interaction effect between the level of observables and group membership. The reason for this interaction effect is the censoring of candidates’ productivities when they exceed the level (c) of the cutoff required to be selected. This censoring makes employers assign the same potential productivity to all candidates who pass the cutoff—the one needed to pass it. It makes the difference in candidates’ observables induced experimentally by the tester larger than the difference in candidates’ productivities actually considered by the employer when selecting candidates

where
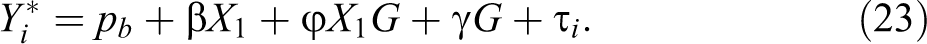
As in the case of
Equation (
23) is the basis for calculating the penalty, in selection probabilities, that employers’ inflict on (non)minorities for each less unit of observables, if their deficits in unobservables are measured in these units. This adjustment can be obtained by calculating the partial effect or change in probability associated with
To calculate the difference in the partial effect of belonging to a minority across levels of observables, we first restate equation (23) in terms of callback probabilities rather than propensities.
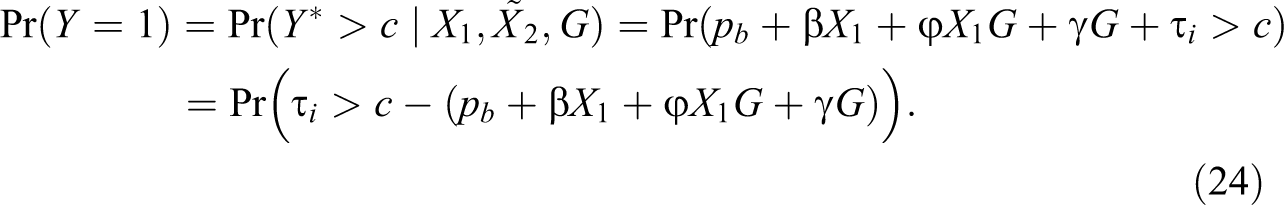
If we standardize and set

where
The interaction effect is the change in this partial effect across higher and lower levels of observables. If we treat group membership as a continuous variable, as we will do later for reasons to be explained, this interaction effect can be formalized as in Greene (2010): 12
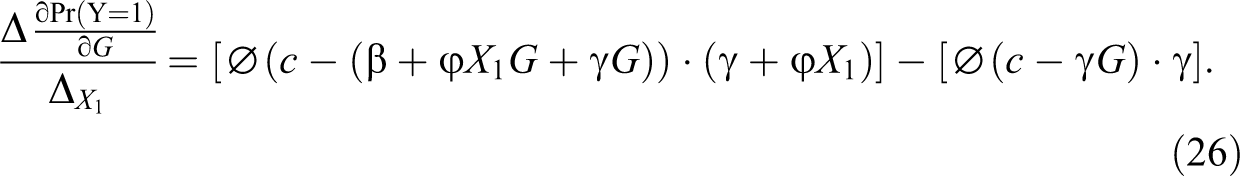
The interaction effect is an estimate of first-moment statistical discrimination. Its interpretation depends on the sign of the coefficient
The interpretation of the baseline estimate of taste discrimination also depends on the sign of the interaction effect. If there is no interaction, the partial effect of group membership should be calculated using equation (25) for an (unobserved) candidate with average observables. The difference in groups’ average callback probabilities driven by
If
If
This decomposition is valid only if the assumption that observables and unobservables are exchangeable holds. This can be tested by assessing the soundness of the threshold selection model described above. In this model, all candidates passing a productivity cutoff on a composite measure are selected for further screening, regardless of by how much they exceed it, and thus can compensate deficits in some qualifications with surpluses in others. As noted, the cutoff shall generate an interaction effect between the level of observables and group membership whenever employers perceive that groups differ in productivity. If we could independently assess the validity of this model, the interaction effect could be more unambiguously interpreted as capturing first-moment statistical discrimination.
The introduction of variation in
Neumark’s Method to Estimate Second-moment Statistical Discrimination
The success of our method to separate first-moment statistical discrimination from taste discrimination depends on the estimate of the former not capturing differences in groups’ variances instead of in their means. We have shown that when groups differ in their standard deviation, the estimate of taste + first-moment statistical discrimination, and hence also of their decomposition, is biased. This could be avoided by estimating the ratio
We also showed that in order to estimate this ratio, experimenters must observe how groups’ callback probabilities change as the distance
This is the very same variation in candidates’ observables we used above to separate taste from first-moment statistical discrimination. The coincidence is unsurprising. The ratio
To make this separation, Neumark first estimates the difference

By moving unobservables’ mean up or down employers’ cutoff, experimenters can calculate the ratio
As Neumark (2012) shows, the same results ensue when running a heteroscedastic probit model that (1) estimates the effect on callback probabilities of different levels of observables and group membership and (2) considers the variance of unobservables to differ across groups (see equation [17] above):
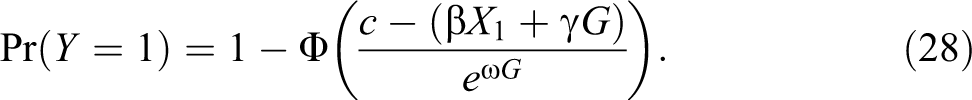
Compared to the model shown before in equation (17), the one in equation (28) contains one additional parameter
If group membership is treated as an interval rather than a categorical variable, the average partial effect of group membership in the heteroscedastic model (28) equals (Greene and Hensher 2010; Neumark 2012):
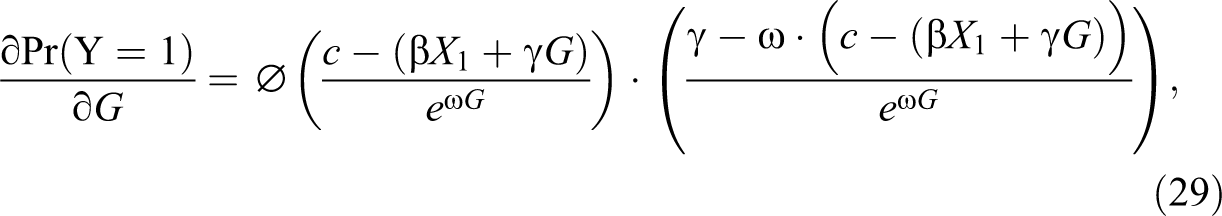
where
Neumark (2012:1140) shows that expression (29) can be decomposed into two additive parts capturing the contributions of taste + first-moment and second-moment statistical discrimination to the total partial effect of group membership:
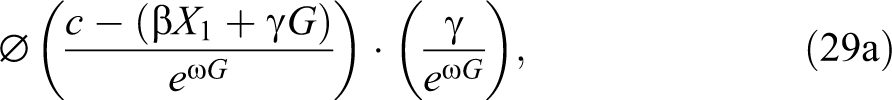
plus:
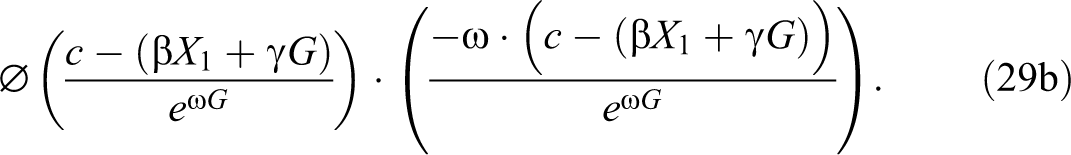
If
As noted, Neumark (2012) assumes that the difference across groups in the effects of candidates’ observables on callback propensities can be attributed exclusively to differences in their variances. He also argues that this assumption is testable (Neumark 2012:1139) provided other variables are added as controls to a standard probit model that includes all two-way interaction effects with group membership. If the ratios of the effects of these controls in the two groups were equal among themselves and equal to the ratio of the effect of candidates’ levels of observables in each group (as established in a Wald test), the hypothesis that they are driven by the same ratio of the variances would be confirmed. However, as Neumark (2012:1140) recognizes, the validity of the test depends on the assumption that no other plausible reason may explain similarities in the ratios. We next argue that this reason does indeed exist.
Disentangling the Three Forms of Discrimination
We argued above that when employers exert first-moment statistical discrimination, they perceive groups as differing in average unobservables and act upon these perceptions. This should produce the same interaction effect between group membership and the level of observables proposed by Neumark to identify second-moment statistical discrimination. Hence, the level of observables cannot be used to estimate the ratio of groups’ variances.
Instead, we propose using other variables which can also change the distance
First, the selection ratio (number of selected applicants relative to the number demanding it) could be estimated from the proportion of applicants selected for further screening within the pool of fake candidates applying to each job. (In tight labor markets with low response rates, the number of fake candidates could be increased without matching them on observables, thus reducing the number of jobs with no callbacks). Alternatively, the ratio might be obtained from employers’ direct responses to ad hoc questions in the posttreatment surveys that often complement correspondence studies (Pager and Quilian 2005; Uggen et al. 2014).
Second, the selection ratio could be estimated with the number of applications received by the employer at the time the experimenter sends her applications. Studies have shown that employers lower their selection ratio when there are more applicants (Connerley 2013; Le et al. 2007; Schmidt and Hunter 1998). In correspondence studies that use online job-search services, applicants’ number is sometimes readily available in the job add. 13 When unavailable, it might be approximated. Job search providers often publish quarterly or annual data on the numbers of applications processed by their engines in different occupations/sectors. 14 These numbers could be assigned to all jobs applied to within the same occupations/sectors and used as proxies of the number of applications received by each.
The ratio of the effect of the selection ratio on the probability of being selected in one group to the other will provide a valid estimate of the relative ratio of their variances only if the variable used to vary the cutoff is not a function of some omitted variable which also captures the difference between minorities and nonminorities’ mean productivities, that is, only if it does not capture first-moment discrimination. One such omitted variable could be the level of observables required in the job. It is reasonable to expect employers to increase their selection ratios and to differentiate less among candidates from different groups in jobs that require higher qualifications since there will be fewer applicants. Controlling for job’s required levels of qualifications can solve this problem.
After selecting the variable
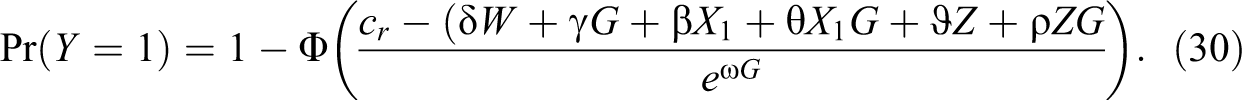
If
The total effect of group membership can be expressed as a change in probability and decomposed into its constitutive parts using Neumark’s method (treating group membership as a continuous variable). Compared to the decomposition carried out in equations (29a) and (29b) above, this one additionally estimates how group membership modifies the partial effect of candidates’ levels of observables. We do it in two steps.
First, we estimate the total partial effect of group membership to separate second-moment statistical discrimination from the other forms of discrimination and from the combined effect of group membership and the controls (if these were significant). If we set:
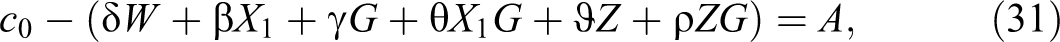
then the partial or marginal effect is:

plus
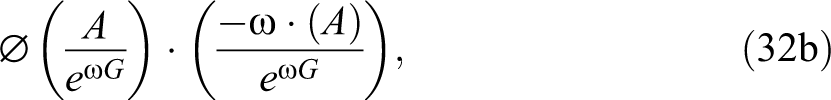
where, as before,
The first product
Second, we estimate the interaction effect, or how much the change in callback probability induced by group membership changes with candidates’ observables. If we treat G as an interval variable and set:
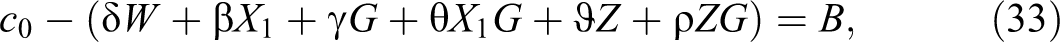
and
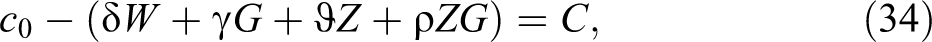
and after rearranging terms, the formula for the interaction effect is:

plus
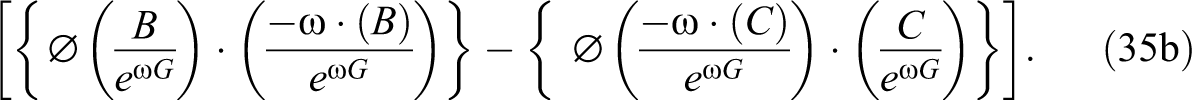
Equation (
35a) provides an estimate of first-moment statistical discrimination but its interpretation depends on the sign of the interaction effect. If
The estimate of the baseline level of taste discrimination depends on the sign of the interaction effect. If
Finally, expression (35b) shows how much do differences in callback probabilities between groups differ at higher and lower levels of observables because of groups’ different variances. These differences will occur if both forms of statistical discrimination are present because the selection threshold cuts across the normal distributions of unobservables at different points in each group.
Application
We now illustrate the applicability of the method using data from a correspondence study performed between May 2012 and February 2013 in Barcelona’s metropolitan area. The study aimed at assessing discrimination against ex-prisoners in this labor market.
There is an ongoing scholarly debate about the penalty that ex-convicts suffer after release due to the stigma of their criminal records, especially when trying to find a job, and the possibly negative consequences on recidivism (Pager 2003). We aimed to contribute to this debate by assessing the degree and source of discrimination faced by males—who make up 93 percent of the prison population in Spain—in Barcelona’s labor market. This market, the second in size in the country, is dominated by the manufacturing and tourist industries, and at the time of the study was suffering from a severe economic crisis resulting in unemployment rates of over 20 percent. This had an effect on the rates of positive responses in the correspondence study, of only 6 percent.
Because of study’s objectives, the sampling universe was restricted to the mid to low complexity jobs that typical (young, mid to lowly educated) male ex-convicts apply for, 16 as reported in previous studies tracking ex-convicts’ employment histories in the region (Alós-Moner et al. 2011).
Faked CVs were sent to a random sample of 601 job openings posted on a top online job search engine. Budget restrictions limited the sample size, especially since the correspondence study was only one of several other research activities dedicated to studying the impact of criminal records on ex-convicts.
Different from most correspondence studies, we sent four fake applications to each opening. One pair contained CVs with lower observables than the other. These varied according to job requirements but approximated a “typical” ex-convict’s profile (Alós-Moner et al. 2011)—compulsory secondary school and work experience in five short-term jobs. In contrast, the better qualified pair had high school degrees complemented with vocational education and longer (six years) and more continuous (three long-term jobs) employment careers. Within each pair, one CV provided clear clues that the candidate had served time in prison (e.g., personal recommendations from prison officials/professionals or training certificates from penitentiary institutions). All four applications were sent in the same day. The application order and other traits of little substantial interest (e.g., photos, personal identifiers) were randomly assigned to applicants.
The dependent variable was whether or not the applicant was selected for further screening. We collected other valuable information on the applicant and the job offer. The main applicants’ characteristics were fixed by design: having or not having criminal records and lower or higher observables. Job characteristics included the number of applicants who had applied to the job at the time the first fake application was sent and the number of openings available for that job—an information readily available from the job search engine. From both, we created a composite index, standardized in the analyses, measuring the number of applicants per opening. We also recorded if the level of education required for the job was above or below the median for all jobs. Finally, we recorded the sector/industry in which the job was categorized by the search engine. Table 1 displays basic descriptive statistics and the rates of callbacks received across variables’ values.
Descriptives.

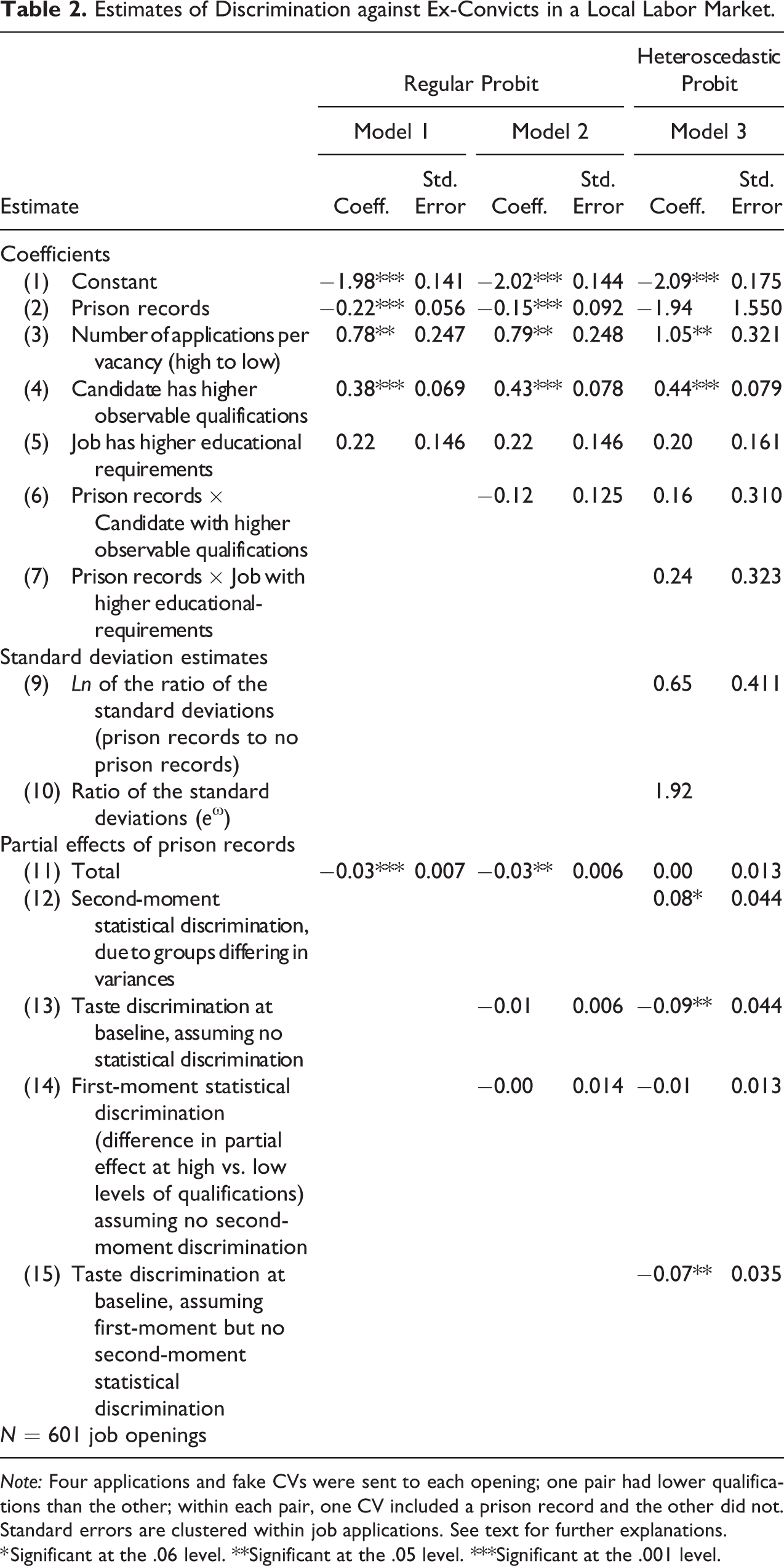
Table 2 presents the study’s main results. We focus on their methodological implications rather than their substantive interpretation. Standard errors for all models are clustered within jobs.
Estimates of Discrimination against Ex-Convicts in a Local Labor Market.
Note: Four applications and fake CVs were sent to each opening; one pair had lower qualifications than the other; within each pair, one CV included a prison record and the other did not. Standard errors are clustered within job applications. See text for further explanations.
* Significant at the .06 level. **Significant at the .05 level. ***Significant at the .001 level.
Model 1 shows the effect of having a prison record on the underlying variable
Model 2 aims at separating first-moment statistical discrimination from taste discrimination, without considering that there may also be second-moment statistical discrimination. We do it by adding to the previous regular probit an interaction effect between criminal records and applicant’s level of observables. We expect this interaction to provide a measure of how much employers rely on stereotypes about ex-convicts’ productivities linked to unobservables to select them. The interaction is negative, pointing toward an intensification of discrimination at higher levels of observables, but small and nonsignificant, also when expressed as a change in probability.
Model 3 is a heteroscedastic probit that allows callback variances to differ by group. This helps estimate second-moment statistical discrimination and identify the other two forms of discrimination without bias. We add two interaction effects between criminal records, on the one hand, and candidates’ observables and job educational requirements, on the other, to ensure that the estimate of the ratio of the variances is unaffected by employers’ beliefs that deficits in unobservables can be offset or exacerbated with higher observables.
Since employers apply different selection ratios in different jobs and select different proportions of applicants in each (see Table 1), the group with higher dispersion has a relative advantage in jobs with higher selection ratios that give more opportunities to unusual applicants. Model 3 (like models 1 and 2 before) shows that this group is made of ex-convicts, who have the highest relative variance (see row 10 in Table 2). Ex-convicts’ variance is almost twice as large as the other applicants’. The estimate is only significant when expressed as a marginal change in probability (row 12 in Table 2). We conclude that there is second-moment statistical discrimination and that ex-convicts benefit from it. The higher uncertainties that employers have about ex-convicts’ unobservables play to the latter’s advantage in jobs in which employers value more the unobserved qualifications of a candidate and increase their selection ratios to raise their chance to meet candidates with such unobservables. The effect is important. It increases ex-convicts callback probability by 9 percentage points (3 times their marginal probability).
Since there is heteroscedasticity, all estimates in models 1 and 2 were biased. The decomposition of taste and first-order statistical discrimination carried out in model 2 was also biased, if only slightly, as the interaction effect between criminal records and candidates’ levels of observables, and the corresponding group differences in the partial effects of observables, remain nonsignificant in model 3.
The most marked change is in the estimate of taste discrimination at baseline. We provide two such estimates—one discarding (row 13), and one considering (row 15), the nonsignificant difference in the partial effect of criminal records at the two levels of observables. In both cases, the marginal effect is significant and negative. Ex-convicts experience taste discrimination. Its impact on their probability of being selected is important, as the penalty is more than three times the marginal penalty estimated for ex-convicts in model 1, which included all forms of (positive and negative) discrimination.
The results indicate that in the local market that we studied, employers discriminate against ex-convicts on moral grounds. Were it not because employers think that an average ex-convict is as productive as another based on their unobservables (although they can predict such productivity less accurately for ex-convicts), and were it not because in this market they give higher weight to unobservables, widening the range of candidates considered for an interview, the discrimination of ex-convicts on the grounds of their moral wrongdoings would be revealed in its true magnitude.
Table 3 shows the results of sensitivity analyses aimed at assessing the robustness of the findings and the plausibility of the assumptions on which they lie. In model 4, we show the results of using a proxy for the number of applications per vacancy instead of the actual number to estimate the selection cutoff and the ratio of the variances of the two groups. As noted, many search engines omit this number in the job offer. However, they often publish reports on the number of applications processed in a term (typically a year) broken by sector. Our proxy assigns to each job the sum of the mean number of applications received by jobs in the same sector and year (in z scores times −1) 17 and of the proportion of callbacks received among the pool of applications sent to each job (also in z scores). The latter—we argued above—should increase as applications decrease. Row 12 of Table 3 reports the results of a Wald test comparing the fit of model 3 in Table 1, which uses the actual number of applications per vacancy, with that of model 4 in Table 3, which uses the proxy just described. The differences are not significant. We conclude that our method is robust to using aggregate information on the number of applications per sector.
Sensitivity Analyses.

a Parameters estimate for higher cutoffs are available upon request.
b Index created by adding the standardized scores of “mean # of yearly applications in jobs within the same sector” to the “# of callbacks in each job applied for” times −1.
c Probability for a directional z test.
* Significant at the .10 level. **Significant at the .05 level. ***Significant at the .001 level.
In model 5, we reestimate model 3 of Table 1 using another type of heterogeneous choice models—a heteroscedastic ordered probit (Williams 2009)—which corrects for the impact that omitting relevant independent variables has on the scaling of the variance at baseline in probit models (Mood 2010). It does so by reestimating coefficients net of the value of the constant (Williams 2009, 2010). Because we sent four CVs to each job and recorded the date and time when each applicant received a callback (if he did), we could generate a new dependent variable measuring the call order—from 0 (never called) to 4 (called in first place). Because there were very few cases in which all four fake applicants were selected, we recoded the variable into three values (1 = never called, 2 = called in fourth or third place, and 3 = called in second or first place). As shown in model 5, while there are some changes in the estimates of the independent variables, they are minor, confirming that the results are robust.
In row 13 of Table 3, we report results from a homogeneity tests evaluating the assumption that the interaction effect between the number of applicants per opening and group membership is driving the ratio of the group variances calculated in model 3 of Table 2. If it did, as noted by Neumark (2012) and discussed before, the ratio of the effect of the number of applicants per opening among non-ex-convicts and ex-convicts should approximate the ratio of the effect of job’s educational requirements in each group in the full two-way interaction probit model 6 of Table 3 (this is just a reparametrization of the heteroscedastic model run in model 3 of Table 2). Test results are reassuring since the differences are insignificant.
Finally, in row 14 of Table 3, we report the results of testing the validity of the threshold model of selection, one where candidates’ merits are relevant for predicting their being selected but not the order in which they are selected. The results of the test are significant and in the expected direction, giving more credence to the interpretation that group differences in the effect of candidates’ qualifications on their appeal to employers indicate the presence of first-order statistical discrimination.
Summary and Discussion
In this article, we discussed some important interpretative problems associated with correspondence studies aimed at measuring labor market discrimination and proposed a comprehensive method to solve them. We reviewed and reformalized the two problems that make it difficult to interpret minorities’ typically lower selection rates as indicating that employers distaste them and apply a higher selection cutoff to them. First, lower rates may indicate that employers perceive minorities to have lower average productivities linked to unobservables, leading to first-moment statistical discrimination. Second, employers might perceive minorities to be more or less similar to each other in unobservables than nonminorities. Depending on which group is perceived as having higher variance and on how high do employers set the selection cutoff, higher or lower callback rates may ensue—a case of second-moment statistical discrimination.
Neumark (2012) proposed a solution to separate second-moment statistical discrimination from the other two by introducing variation in applicants’ levels of observables. This variation, he argued, allows estimating the relative ratio of groups’ variances in a heteroscedastic probit model. If employers selected larger proportions of applicants with higher observables, any relative differences across groups in how much or less candidates with different observables are likely to be selected should provide an estimate of the ratio of groups’ variances and of second-moment statistical discrimination.
We questioned Neumark’s reliance on variations in the intensity of discrimination at different levels of observables to estimate second-moment statistical discrimination, since these variations could also reflect employers’ perceptions of groups’ different average productivities linked to unobservables. Instead, we proposed to rely on variations in the intensity of discrimination across jobs differing in the number of applicants. This number has been shown to alter employers’ selection ratios and the weight given to unobservables in their hiring strategies—higher when selecting more candidates for screening. Variations in the level of discrimination across jobs with different selection ratios help identify the group with the largest variance—the one benefitting the most from higher selection ratios—and estimate second-moment statistical discrimination. The plausibility of alternative explanations can be tested using Neumark homogeneity test (2012).
In contrast, we relied on variations in the level of discrimination at different levels of observables to identify first-moment statistical discrimination. Such an interaction effect should be expected if employers selected for further screening all (or the first n) applicants that pass a minimum qualification threshold, rather than in order of qualifications, and if they thought that groups differ in productivities, as measured in some composite index where deficits in unobservables can be (partly) compensated with surpluses in observables. We proposed to test the plausibility of the threshold model of selection by observing if among the selected candidates those with higher qualifications are called first. If they did not, this would give more credence to the claim that differences in the level of discrimination across candidates with different observables capture first-moment statistical discrimination.
Our main contribution has been to integrate both procedures into a unified heteroscedastic probit model that makes the variance a function of group membership. In this model, taste discrimination is estimated residually, as discrimination that cannot be accounted for by stereotypes about the distribution of unobservables across groups. We showed how to estimate it depending on the direction and intensity of the two forms of statistical discrimination.
Applying this method, we uncovered a credible story about the sources of discrimination against ex-convicts in a local market. We showed that this discrimination was based on aversion (distaste) toward ex-convicts due to their past wrongdoings, not on higher uncertainties about their unobserved qualifications, which instead played to their advantage, and not on stereotypes about their average productivities, which were perceived to be similar to non-ex-convicts’. This has policy implications. Tackling distaste toward ex-convicts may be difficult and affect ex-convicts’ chances of regaining a decent life and avoid reoffending. More research is necessary to ascertain if channeling ex-convicts toward jobs in which certified qualifications are less important, and where they have higher chances of being hired, could help overcome their stigma.
Our method to separate the three forms of discrimination can be improved by minimizing measurement and specification errors, especially since heteroscedastic models are notorious for magnifying them (Keele and Park 2006). First, the variables in the model could be better measured. The dependent variable could be measured ordinally, by reporting the callback order of the candidates in designs that send more than two applications to each job, as we did in the sensitivity analyses. Applicants’ observables could be measured on an interval scale, rather than as a dichotomy, making the test of the interaction effect between group membership and the level of observables less dependent on tester’s choices.
Second, more variables could be added to better measure each form of discrimination. For example, in well budgeted studies, it might be possible to alternate different qualification across candidates applying to similar jobs and test their contribution to explaining first-moment statistical discrimination. Other job characteristics could be used to construct proxies of jobs’ selection ratios when the number of applicants in each is unavailable. We provided an example in the sensitivity analyses by using a proxy that combined the rate of callbacks obtained in each job with the average number of candidates applying for jobs in the same sector.
Third, miss-specification tests could also be refined. Neumark’s (2012) homogeneity tests, as he himself proposed, could be applied to subsets of controls which effects are unlikely to change across groups for reasons different to their variance, like some random variables used in the study (application order, pictures assigned to applicants, etc.). The test of the threshold model of selection could be complemented with another directly testing for the exchangeability of unobservables and observables. For example, the tester could add some unobservables to some candidates CV’s and observe how their impact on selection probabilities changes as candidates’ observables are experimentally modified.
While there is room for improvement, we hope to have contributed to strengthening the methodological foundations of correspondence studies and discrimination research.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Grant RecerCaixa 2013. “La regulación de los antecedentes penales”. Funded by La Caixa and ACUP.” Grant DER2015-64403-P. “Enforcement and supervision of sentences”. Funded by the Spanish Ministry of Economy & Competitiveness and FEDER (EU).