
Abstract
A project was developed to introduce the core principles of repeated-measures designs. Using the levels of processing approach to memory, students are prompted to engage in either shallow, moderate, or deep processing of 54 common nouns. An unexpected recall task then measures the number of words remembered in each condition. Data from 293 students from two universities across 16 years indicate that the exercise reliably produces significant differences across conditions. This exercise employs several methodological techniques that are used as a basis for class discussion such as counterbalancing, randomized-blocks designs, reduction of carryover and specific-item effects, and elimination of experimenter expectancy effects. In short, most of the design considerations that would be required of a repeated measures approach are represented, and students can identify their purposes and effects from having participated in the demonstration.
The research methods course is arguably one of the most important foundations of a psychology curriculum. However, instructors are sometimes torn between lecturing on abstract principles of the scientific method versus providing concrete examples of specific techniques. Achieving a balance between these two goals—using effective demonstrations that concisely illustrate research design elements—can provide students with an opportunity for authentic instruction. To that end, a project was developed to introduce the principles of repeated-measures designs, using the levels of processing approach to memory as a framework (Craik & Lockhart, 1972).
This project has been used at two universities, both of which offer research methods (with an accompanying weekly laboratory component) as a required core course in the psychology curriculum. At one school, approximately 45–60 students take research methods each semester, whereas at the other school, approximately 30–45 students take a yearlong research methods course (although not all students in all sections at either institution are exposed to the present exercise). Although the format and assignments for the course differ across these institutions, both courses emphasize a high degree of rigor, active participation in data collection and analysis, multiple manuscripts written in APA style, group collaborations, and a final poster session. In short, students have many opportunities to hone their quantitative and methodological skills. The present exercise offers one such opportunity and draws inspiration from previous suggestions (e.g., Bender & Shoptaugh, 2000; Chaffin & Herrmann, 1983; DeRosa, 1987; Jenkins, 1981).
Conducting the Exercise
Students are told during a prior class meeting that they will be participating in a required exercise that will form the basis for one of their graded project manuscripts. By this point in the semester, students are already familiar with the hallmarks of a true experiment: manipulating an independent variable, randomly assigning participants to conditions, and controlling extraneous variables (Leary, 2016). Students also have been introduced to the concept of repeated measures as a way of achieving these goals; that is, repeated-measures designs expose all participants to all levels of an independent variable, they obviate the need for random assignment, and they offer a way of controlling subject variance (Pelham & Blanton, 2013). This in-class exercise is therefore sensibly couched within a larger context of understanding experimental techniques.
Procedure
On the day of the exercise, students are asked to position themselves throughout the classroom with a clear view of the projection screen and are also cautioned to take the data collection seriously (as they would their participation in any other experiment). Students are reminded that although they’ll be supplying the responses, they also will be writing a manuscript based on the exercise; therefore, they are in the unique position of experiencing both the participants’ and the experimenter’s perspectives.
Each student receives one of the three response sheets. The sheets appear to be identical, with each one featuring instructions at the top, followed by 3 columns of 18 spaces each (for a total of 54 spaces). A Roman numeral I, II, or III is placed unobtrusively in the bottom right-hand corner. The instructions inform students that they will see on the projection screen a series of cue letters—A, B, or C—followed by common nouns (see Appendix A). Each cue letter will prompt students to make one of the three decisions about the word that follows: (1) count the number of vowels the word contains, (2) report the number of syllables the word contains, or (3) determine whether the object named is typically pleasant or unpleasant. Students are instructed to write a numeral in each space to give their response to Tasks 1 and 2 and to write either P or U in response to the third type of judgment. Importantly, these three judgments and the cue letters they correspond to are counterbalanced across participants, as will be described below.
The judgment tasks represent shallow, moderate, and deep levels of processing, respectively. Briefly, the levels of processing approach to understanding memory posits that as more work is applied to information entering the memory system, better retention for that information should occur (Craik & Lockhart, 1972; Craik & Tulving, 1975). Counting vowels is an orthographic task; a quick visual scan requires little effort to produce the correct answer. Assessing syllables is a phonological task; the word is sounded out mentally, requiring a bit more effort to reach an answer. Determining the pleasantness of a concept is a semantic task; the meaning of the word must be considered, and hence more cognitive resources are brought to bear on this decision. Therefore, students are required to engage in shallow, moderate, or deep processing of information, represented by an orthographic, phonological, or semantic task, operationalized as judging vowels, syllables, or pleasantness. None of these details, of course, are revealed to students during the exercise.
A PowerPoint display automatically presents the 54 cue letter/word prompt combinations. The slides are timed so that each cue letter is presented for exactly 3 s, and each word appears for exactly 5 s. At the conclusion of this presentation, students complete a distracter task for 30 s by circling each odd number on their response sheets and putting an X through each even number. This task serves to clear short-term memory (unbeknownst to the participants). Students are then given 5 min to complete an unanticipated recall task (writing as many words as possible from the presentation they had just seen) on the back of their response sheets. The sheets are collected, shuffled, and redistributed to students for scoring.
The general hypothesis is that words requiring a semantic judgment should be recalled more often than words requiring an orthographic or phonological judgment. (The total number of words recalled is of much less interest.) Specifically, there should be evidence that semantic recall is greater than phonological recall, which in turn is greater than orthographic recall, assessed by the number of words remembered in each of those three experimental conditions.
Scoring
While shuffling and redistributing the response sheets, the instructor asks students for their opinions about the true nature of the experiment. Most correctly guess that it has something to do with memory, although common conjectures focus on the categorization of the words (“lemon,” “orange,” and “walnut”) or the personal relevance of the words (“student,” “school,” and “book”). Eventually, some students will suggest that the amount of effort required for the judgments had an impact on recall, which opens the door to a discussion of the theory and hypothesis mentioned in the preceding paragraphs. In order to test that hypothesis, the responses need to be scored.
Students are shown a list of all the words associated with each cue letter and are instructed to write A, B, or C next to each word that was correctly recalled. Students then award one point for each word and compute a total recall score for each of the A, B, and C lists.
At this point in the discussion, the problem of specific-item effects is introduced. Specific-item effects occur when the results of an experiment depend on the particular stimulus materials that were used. In the present study, it could be that some words are simply easier to remember; perhaps stool is easier to remember than wardrobe. If that were true, and the word stool always appeared in the semantic condition, there would be no way to determine whether the better recall of stool was due to deep semantic processing or simply due to that specific item being more easily remembered all by itself. Therefore, we counterbalanced which words were assigned to which type of judgment. For one third of the participants, an A judgment was a P(honological) task, whereas for another one third an A judgment was a S(emantic) task and for the remaining one third an A judgment was an O(rthographic) task. (The same was true of the B and C judgments.) For each word that appeared, then, one third of the participants were making one type of decision, although this was not revealed to the students at the time. If a specific word had some property that made it particularly easy or difficult to remember, that property would be counterbalanced across the judgments of all the participants.
Because an A, B, or C judgment meant different things to different participants, the total recall scores for each type of judgment must be “decoded.” Students are told to find the Roman numerals I, II, or III on the front of the response sheet. This code signifies what an A, B, or C judgment meant for the person completing that sheet. Students then transform these judgments following this Latin Square design:
A = O B = P C = S A = S B = O C = P A = P B = S C = O
The data are now in a form in which the number of words correctly recalled in the orthographic, phonological, and semantic conditions can be directly compared across participants.
Discussing these methodological details presents an opportunity to share with students other elements of the experimental design. In particular, the concepts of order effects and counterbalancing arise. As with any repeated-measures design, either a fatigue or a practice effect might have occurred in the present experiment. With increased practice, students might recall the words presented later in the experiment better than the earlier ones; with the onset of fatigue, students might recall the later words more poorly than the earlier ones. If most of the semantic judgments were concentrated toward the end of the word list, and all those words were easier to recall due to a practice effect, then the order of the presentation would be determining the outcome rather than the action of the independent variable. To address this concern, the 54 words were divided into three 18-word blocks. Within each block, we randomly selected six A words, six B words, and six C words. Finally, we randomly assigned the order of the A, B, and C judgments within each 18-word block. In other words, the design ensured that an equal number of A, B, and C judgments occurred in each third of the word presentations but also made sure that the order of A, B, and C judgments was random within each third. This randomized-blocks design adds a further element of sophistication to the project.
Finally, students are reminded that an equal number of orthographic, phonological, and semantic words were presented throughout the experiment (i.e., 18 of each type) and that enough judgments overall (i.e., 54 total) were included to make the task internally valid. Examining their recall performance, students are sometimes chagrined when they realize there were 18 words to possibly remember in each category!
Results
Normative Data
Table 1 shows that students typically recall approximately two to three words in the orthographic condition (M = 2.29, SD = 1.61), two to four words in the phonological condition (M = 2.85, SD = 1.84), and five to eight words in the semantic condition (M = 7.07, SD = 2.42). As a percentage of the 18 words in each condition, that is approximately 13% of the orthographic judgments, 16% of the phonological judgments, and 39% of the semantic judgments. This would suggest that the outcomes of orthographic and phonological processing do not significantly differ, which is usually confirmed on a semester-by-semester basis. A repeated-measures analysis of variance followed by a Tukey post hoc test is performed by the students each semester (and serves as the basis for the Results section of their manuscripts) and generally reveals that although recall in the semantic condition reliably differs from the other two, differences in recall in the phonological and orthographic conditions do not exceed the post hoc standard. 1
Mean Recall of Words in the Orthographic (O), Phonological (P), and Semantic (S) Conditions of the Experiment.
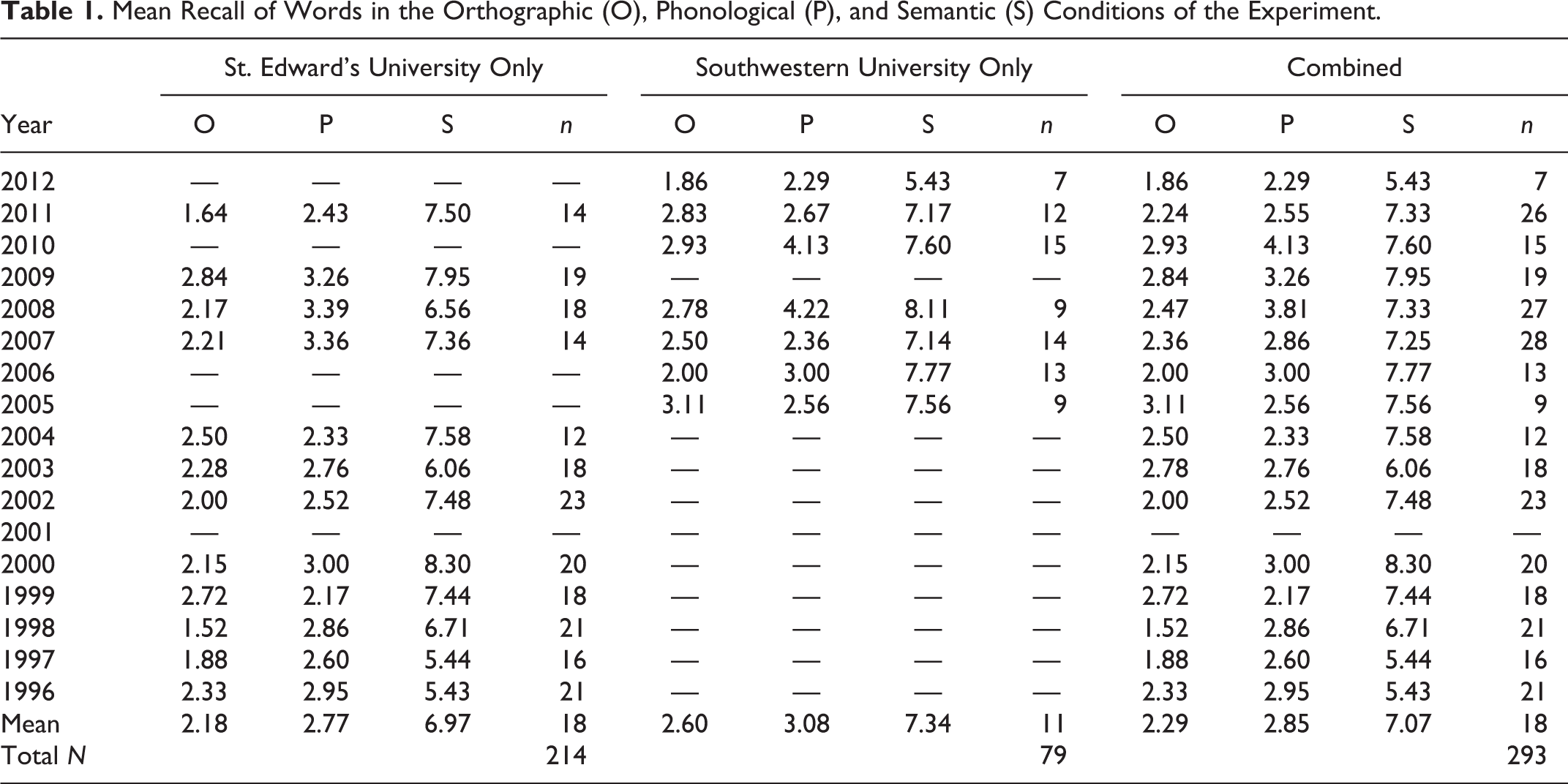
These results illustrate several principles for the students. First, the healthy F ratio that occurs shows the power of a repeated-measures design; robust effects are possible even with small sample sizes (in the present cases, anywhere from 7 to 23 students in a given semester). Second, post hoc tests reveal that although sometimes overall effects are statistically significant, comparisons between specific conditions may not be. This provides a more nuanced view of the research process; results are sometimes not in line with hypotheses. Although the exercise could easily be modified to consistently produce a significant effect between the orthographic and phonological conditions, we’ve chosen to leave it the way it is, to highlight the realism of the actual research process. Finally, the reasons for a lack of difference between orthographic and phonological processing give students food for thought. Because cognitive processing occurs along a continuum, students are spurred to propose other operationalizations that might produce reliable differences across all three conditions. For example, the orthographic task might be made simpler (“Determine if this is an English-language word”), thereby pulling it “down” from the phonological task, or the phonological task might be made more challenging (“Could this word be made into a gerund?”), thereby requiring slightly deeper processing. In any event, students can work through these proposed modifications in the Discussion sections of their manuscripts.
Effectiveness of the Exercise
To gauge whether students exposed to the exercise show reliable gains in understanding the core concepts presented, comparisons between two groups of Southwestern University students were analyzed. Both groups were enrolled in sections of research methods at the time of data collection, and both sections followed a comparable core curriculum. However, one group of students (n = 23) performed the levels of processing exercise, whereas the other group (n = 11) did not. This naturalistic experiment provided data on the effectiveness of the exercise.
Students completed 6 items (see Appendix B) that were embedded in their usual course examinations. Each item bears on an aspect of repeated-measures designs highlighted in the exercise and subsequent class discussion. Responses to each item were scored as either correct (1) or incorrect (0), providing mean scores between 0 and 1. The assessment items themselves represented a range of tasks; multiple choice (Items 1, 2, 4, and 5; a recognition task), write-in (Item 3; a recall task), and execution (Item 6; a production task). As shown in Table 2, in each case one-tailed independent groups t tests revealed that students who were exposed to the exercise were more likely to answer a relevant test item correctly compared to students who were not exposed to the exercise.
Performance on Relevant Assessment Items
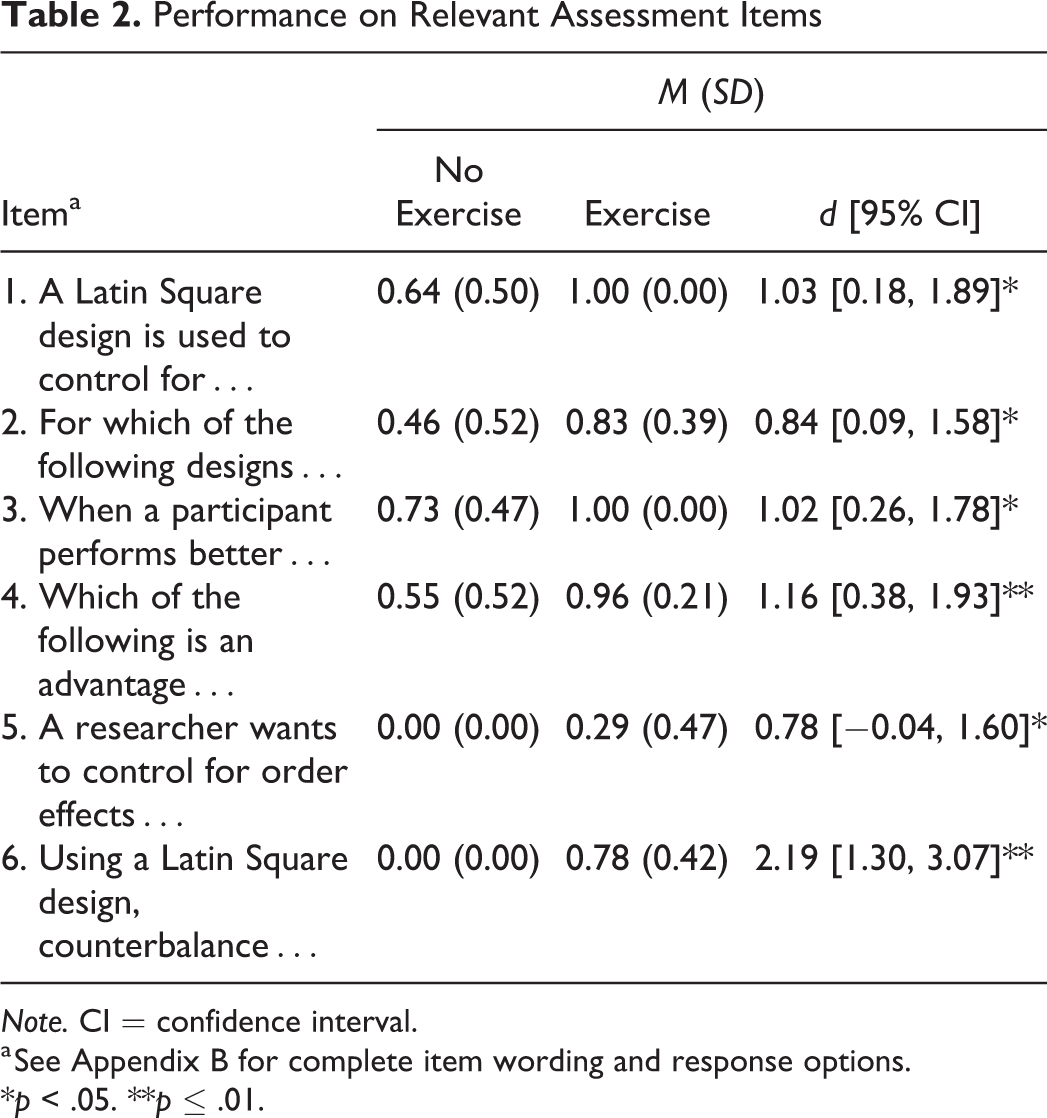
Note. CI = confidence interval.
a See Appendix B for complete item wording and response options.
*p < .05. **p ≤ .01.
Discussion
Instructors tend to gravitate toward projects and demonstrations that perform consistently, and this is one of them. The memory outcomes from the exercise show remarkable consistency across any of several dimensions (e.g., institutional characteristics, enrollment size, course length, instructors, decade administered). Furthermore, students exposed to the exercise perform better on exam items relevant to the exercise compared to peers in a comparable, nonexposed class. More importantly, the design, conduct, analysis, and explanation of the project incorporate all the fundamental aspects of repeated-measures designs: counterbalancing, order effects, randomized blocks, small numbers of participants, and so on. There is also room for class discussion to expand on some topics. For example, by administering the experiment in an automated fashion (using PowerPoint), the possibility of experimenter expectancy effects is minimized. Similarly, the distracter task to clear short-term memory can be the basis for discussing carryover effects in repeated-measures designs. Finally, although the primary use of this project has been to teach research methods, the subject matter of the demonstration makes it suitable for use in cognitive psychology, learning and memory, or general psychology courses. The experiment itself takes about half an hour to conduct (including instructions and scoring), allowing it to fit easily into class time or a laboratory section. By being more than just an in-class demonstration, however, it also serves as the basis for writing a more elaborate formal research report.
Footnotes
Appendix A
Words Used in the Levels of Processing Exercise.
| 1. BIKE | 2. MONTH | 3. MAGIC | 4. FOOT |
| 5. MONKEY | 6. CLOCK | 7. PAINT | 8. BUREAU |
| 9. BIRD | 10. LEMON | 11. FIRE | 12. TRAIL |
| 13. SOAP | 14. POCKET | 15. PENCIL | 16. TRAIN |
| 17. GRASS | 18. STORY | 19. BELT | 20. KITCHEN |
| 21. TRUNK | 22. COAL | 23. PIPE | 24. ORANGE |
| 25. COIN | 26. HAMMER | 27. DOOR | 28. CHURCH |
| 29. TRAVEL | 30. FISH | 31. WALNUT | 32. ARMY |
| 33. SILVER | 34. FARMER | 35. STUDENT | 36. SCHOOL |
| 37. GARBAGE | 38. SCHOLAR | 39. TRAP | 40. FLIGHT |
| 41. MISSION | 42. BOOK | 43. LIGHT | 44. SODA |
| 45. RABBIT | 46. MARKER | 47. FILM | 48. KNIFE |
| 49. PACKAGE | 50. DOLLAR | 51. CHAPTER | 52. KEY |
| 53. CUP | 54. HORSE |
Appendix B
Items Used for Assessing the Effectiveness of the Exercise.

| 1. A Latin Square design is used to control for: |
| (a) carryover effects |
| |
| (c) placebo effects |
| (d) all of the above |
| 2. For which of the following designs is random assignment LEAST relevant? |
| |
| (b) matched-subjects |
| (c) mixed-subjects |
| (d) between-subjects |
| 3. When a participant performs better on an experimental task as the experiment goes on, we refer to it as ( |
| 4. Which of the following is an advantage of repeated measures over randomized groups designs? |
| (a) carryover effects are less likely |
| (b) fewer experimental conditions are needed |
|
|
| (d) confounding is less likely |
| 5. A researcher wants to control for order effects in a 2 × 2 within-subjects design but has NEVER learned about using Latin Square designs. How many orders will she have to use? |
| (a) 4 |
| (b) 16 |
|
|
| (d) 40 |
| 6. Using a Latin Square design, counterbalance conditions A, B, C, and D in the space below. |
Note. Correct responses are in bold type.
Authors’ Note
A preliminary version of this article was presented at the annual meeting of the Association for Psychological Science, Chicago, IL, May 2012.
Acknowledgments
We thank Carin Perilloux for her help with data collection.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.