
Abstract
Followee recommendation is a problem rapidly gaining importance in Twitter as well as in other micro-blogging communities. Hence, understanding how users select whom to follow becomes crucial for designing accurate and personalised recommendation strategies. This work aims at shedding some light on how homophily drives the formation of user relationships by studying the influence of diverse recommendation factors on tie formation. The selected recommendation factors were studied considering multiple alternatives for assessing them in terms of user similarity. A data analysis comparing the similarity among Twitter users and their followees, regarding two commonly used followee recommendation factors (topology and content) was performed in the context of a followee recommendation task. This study is among the firsts to analyse the effect of the different criteria for followee recommendation in micro-blogging communities, and the importance of thoroughly analysing the different aspects of user relationships to define the concept of user similarity. The study showed how the choice of the different factors and assessment alternatives affects followee recommendation. It also verified the existence of certain patterns regarding friends and random users’ similarities, which can condition the adequacy of the available similarity metrics.
1. Introduction
The rapid growth and exponential usage of social digital media increased the popularity of micro-blogging platforms, characterised by linked social entities, which have become an important part of the daily life of millions of users around the world. A representative example is Twitter, in which social entities are subscribed users and links between them are following relationships, not necessarily reciprocal. Generally, these relationships are driven by the phenomenon of homophily, which establishes that people tend to strengthen their connection to other similar individuals [1]. In social networking sites, users follow other users with no need for that relation to be reciprocated or even accepted. In fact, most users tend to avoid the disturbance from uninteresting users, thus they may not follow their followees back [2].
Homophily has been extensively studied in sociology literature [1,3] by conducting surveys on human subjects. Traditionally, homophily has been analysed in terms of user similarity, which in turn has been used to explain concepts such as community development, segregation and mobility. However, this raises two concerns. First, how to define and quantify the concept of similarity given the broad spectrum of alternatives. Second, due to the nature of the sociological studies and the experimental evaluation, their conclusions might not be extensible to the online world and, particularly, social media. Relationships in social media might be formed on the same basis than in the real world. However, given the differences between those two environments, it might be difficult to determine whether the same factors governing relationships in the real world also influence relationships in social media [4]. For example, in the case of face-to-face relationships, those with others having similar interests or opinions can be promoted by the exposure to socio-demographically similar people in places such as schools, universities, workplaces or even neighbourhoods [5]. However, in online environments, users usually know others only through their profiles.
The differences between the real and online environments pose the question regarding which are the primary factors that drive homophily in online social networks (OSNs), and how they affect the formation of new ties. As socio-demographic information is rarely present on social media data, it is necessary to focus on the role of users’ interests and behaviour as homophily drivers. Understanding what fosters the formation of social relations in OSNs becomes crucial for accurately assessing user similarity and hence defining precise and personalised strategies to be applied in recommendation systems. Moreover, the exponential growth of online activity hinders the ability of users to find relevant and reliable information, which creates a potential overload and prevents timely access to items of interest. This has increased the demand for recommender systems, which act as information filtering systems handling the problem of information overload that users normally encounter by providing them with personalised recommendations. A recurrent topic in recommender systems research is the generation of metrics to accurately assess the similarity between users or items [6].
A review of a wide range of works applying the concepts of homophily and user similarity for recommendation tasks [7–12], among others, has shown that the reliance on such concepts was not justified either by a conceptual analysis of the involved similarity aspects or users’ context. Moreover, most works were based on similarity metrics stemming from other research areas such as geometry, biology or economics.
Motivated by the explicit differences between the real and online worlds and the lack of a systematic study of homophily in OSNs, this study aims at understanding how people connect in micro-blogging platforms by analysing the importance of different behavioural aspects and interests of users for adequately characterising social ties. Specifically, this study is founded on the following research questions. First, whether homophily principles drive the formation of social ties, that is, whether users establishing social ties share similar characteristics. Second, which factors drive the formation of social ties, that is, how to effectively measure user similarity. Third, considering that similarity can be based on distinct aspects of users’ interests and behaviour, how the different aspects contribute to strengthen the homophily among friends. Fourth, whether user similarity is restricted to friends, that is, how similarity among friends compares to similarity with other random social network users. To answer these questions, the concept of user similarity was explored in terms of a statistical analysis of diverse traditionally used similarity metrics, not only by assessing the relation between users and their friends, but also the relation between a user and the rest of the online community.
The rest of this work is organised as follows. The ‘Literature review’ section presents related research. The ‘Hypotheses and research model’ section describes the defined hypothesis and the research model based on two data dimensions. The ‘Research method’ section provides a description of the study methodology by describing the collected dataset and how the hypotheses were tested. The ‘Data analysis and findings’ section analyses the followee preferences of the studied users regarding the different recommendation factors across the diverse similarity metrics. Then, the ‘Discussion and implications’ section discusses the findings and some practical implications. Finally, the ‘Conclusion’ section summarises the conclusions drawn from this study.
2. Literature review
The homophily principle has been extensively studied in the context of real-world data by conducting numerous surveys with human subjects. For example, McPherson et al. [1] studied how the similarity between individuals in terms of socio-demographic characteristics (e.g. geographical and locality factors) can foster the development of social ties, but neglect the relevance of users’ interests. Selfhout et al. [13] leveraged on the reinforcement-affect theory to state that similarities in terms of feelings, views and opinions can trigger implicit responses that increase people’s attraction. The effect of the Big Five personality dimensions on the formation of dyads is studied by Cuperman and Ickes [14] and Selfhout et al. [15], suggesting that each dimension has an important and differentiated role in friendship selection. Both studies focused on demonstrating the existence of similarities between individuals in a dyad, but did not explore the similarity with outsiders. The mentioned studies have in common that all of them were conducted in a physical world scenario by surveying groups of human subjects [4]. Often, subjects belonged to specific geographical locations, with similar socio-demographic characteristics. Thereby, ties were subjected to social influence, which inherently favoured the conclusions of the studies, hindering their applicability to the online domain.
The advent of OSNs has offered new strategies to evaluate the homophily theories on a much wider scale. For example, Singla and Richardson [7] applied data mining techniques to the study of a MSN Messenger network and discovered that people chatting together share personal characteristics, such as demographic data and queries to search engines (which were regarded as users’ interests). Findings also showed that people who do not necessarily chat together but have common friends also tend to share some similar characteristics. Gilbert and Karahalios [8] defined variables regarding user demographics and interactions to predict tie strength on Facebook. Tommasel et al. [16] studied the impact of personality in the friendship selection process in Twitter verifying the hypotheses presented in literature [14,15]. Tang et al. [17] defined user similarity in terms of gender and geographic location as a driver for retweeting behaviour. Zubiaga et al. [18] also showed that homophily plays an important role in determining with whom to connect, as users predominantly choose to follow and interact with others from the same national identity.
The described studies have mainly focused on the existence of coincidences among demographic information that might be either unavailable or untrustworthy in OSNs. It was even argued that this way of assessing homophily can put minority groups at a disadvantage by restricting their ability to establish links with a majority group or to access novel information [19]. Conversely, one of the strongest factors for evaluating homophily in the virtual world, although often neglected in physical world studies, is the matching interests of individuals. Several approaches have been proposed in the literature to recommend users worth following defining user similarity in terms of users’ interests [20], network topology [5,21–24], personality [9] and popularity [25,26], geographical location [27,28], the content users publish [10] or even emotions [29]. These works assumed the existence of homophily and only studied the performance of the selected similarity metrics in relation to the precision of recommendations, without analysing the adequacy of the metrics for measuring similarity, that is, whether such metrics could accurately represent user similarity or whether according to those metrics homophily also existed among strangers.
In OSNs, several metadata elements have been used for quantifying homophily. Aiello et al. [30] studied the presence of homophily in three systems that combine social tagging with OSNs (Flickr, Last.fm and aNobii). The analysis suggested that users with similar interests had more probability to be friends, and therefore topical similarity among users based solely on their annotation metadata should be predictive of social links. Xu and Zhou [31] showed the homophily effects through hashtags, where users engaging with certain hashtags have higher chance of forming ties. Two patterns of homophily through hashtags were identified in this work. On one hand, hashtag homophily can be established between two users sharing the same hashtags as they are more probable to form ties. On the contrary, a pattern where homophily alienates users who do not share the same hashtags, have a lower likelihood of forming ties. Korkmaz et al. [32] observed the effect of homophily in individuals’ willingness to participate in collective actions in Facebook (e.g. protests). Šćepanović et al. [33] carried out an in-depth investigation on the role of semantic homophily in a network of Twitter mentions. A temporal analysis of communication reveals that links persisting over several months present stable properties, such as semantic (content similarity) and status (social influence) similarity between source and receiver, which are not observed in short-lived links.
Finally, Bisgin et al. [4] aimed at exploring the principle of homophily based solely on topic similarity over the used tags. The study considered three social networks BlogCatalog, Last.fm and LiveJournal. At a dyadic level, their results showed that people sharing a social tie often do not share interests. At a community level, the authors found that people did not only have similar interests with other members of the same communities, but also to the whole population, suggesting that homophily also existed with outsiders. According to the authors, this implied that communities evolve based on the tie density of groups of users that do not have distinctive interests. Moreover, studies over a random rewired version of the dataset suggested that ties were not driven by homophily. Overall, results seemed to contradict the assumption that homophily fosters the formation of social ties. This study raised several concerns regarding whether conventional theories established based on real-world observations hold when analysing OSNs. However, the study lacked conceptually of how to assess similarity, as it implicitly assumed that users’ interests are only expressed using tags.
Despite the evidence that similarity fosters the attraction between individuals, the explanation of such effect continues to be the subject of debate [3]. For example, existing models are unable to explain why attraction occurs more in laboratory than in field studies, or the lack of attraction even in the presence of similarity regarding the negative traits. In addition, there has been a doubt on why similarity regarding peripheral factors does not lead to less attraction than similarity on important factors [3]. Similar concerns have been expressed regarding online social relations [4]. This raises a question on how to effectively model similarity, and what is the effect of such perceived similarity. However, the studies over OSNs data have merely relied on the phenomenon of homophily by applying similarity metrics without studying their pertinence and relevance to the task to be performed. Moreover, to the best of our knowledge, no previous study has explicitly analysed the characteristics of the missing relations in social networks, that is, how similarity behaves among strangers.
3. Hypotheses and research model
Motivated by the observed differences between the real and online worlds, this work proposes a systematic and novel study of homophily in OSNs aiming at discovering how homophily is reflected on the established online social relations, that is, how traditionally used similarity metrics capture the essence of homophily. To determine the strength of homophily, ties are analysed from a wider point of view by not only assessing the characteristics of friendships, but also, how people relate to strangers in terms of their similarity.
Founded on previous sociology and psychology research that established the existence of homophily on real-world friendship relations [1,14,34], and to answer the motivational research questions, this study centres on the existence of homophily in OSNs in the context of a friend prediction task. According to the findings in McPherson et al. [1], homophily can be expressed in diverse manners. For example, geography, race, religion, age and even belief were shown to influence the formation of social ties by fostering interaction and attraction between individuals. Regarding OSNs, Thelwall [35] also established the existence of socio-demographical (e.g. religion, age, country and ethnicity) homophily in MySpace. Interestingly, Verbrugge [36] found that the factors driving homophily might change according to the characteristics of the analysed group of individuals. For example, social ties among adults in some cities in Germany were more structured by work occupation than those in United States. In addition, in Taiwan, relations complied with the normatives and social values governing daily life [37].
In the context of OSNs, users’ interests and behaviour are traditionally analysed in terms of topological or content-based factors. Although a systematic study on the effect of each possible factor has not been performed in the literature, the results of followee recommendation suggest variations in the precision of recommendations according to the selected factor. For example, Armentano et al. [10] reported better precision results for content-based factors than for topological ones. On the contrary, Hannon et al. [38] reported that the combination of topology with content-based information achieved worse results than topology. Hence, each factor might not be equally important to every individual.
This study is guided by two hypotheses, which do not only refer to the criteria under analysis, but also to the intrinsic characteristics of users and social media sites that might influence their preferences. For example, users’ behaviour (in terms of number of friends or the level of posting participation) might alter their friendship preferences. To verify the defined hypotheses, it is necessary not only to study the similarity between users across diverse metrics, but also how such similarity between friends compares to the similarity with other random OSN users.
As previously stated, in real-world studies it was found that although social ties are effectively driven by homophily regardless of the different geographic locations, the specific characteristics of both the environment in which the interactions occur and the involved individuals might have an effect over the factors leading to homophily. For instance, regarding socio-demographic factors, gender homophily was shown to be lower on Anglosajon societies when compared with African American and Hispanics ones [1]. In addition, Cuevas et al. [28] claimed that location and language dictated the degree of geographic homophily. For example, users in countries with languages different from English (such as Brazil) exhibited a higher level of geographic homophily in their relations than users in English-speaking countries (such as UK or Canada), who tended to relate with users in other countries. Following this notion, it could be inferred that the same situation applies to OSNs, that is, the environmental characteristics of the OSN under analysis, which encourage certain types of activities, might condition the factors driving the formation of social ties. In this regard, the first hypothesis states that:
Specifically, in an information centric network, that is, an OSN that is guided by the desire of consuming information (e.g. Twitter), the content similarity between users will be higher than the topological one. Conversely, in a friendship-based network (e.g. Facebook), relationships will be driven by topological factors. In this context, Armentano et al. [10] and Hannon et al. [38] reported contradicting results on whether content-based or topology factors achieved the highest precision in Twitter recommendations. On the contrary, in Facebook, similar interests or socio-demographic characteristics achieved worse precision than recommendations based on topological factors [39]. Recently, Dong et al. [40] argued that structural diversity of common neighbourhoods had a positive influence in networks such as LinkedIn or BlogCatalog (i.e. content-oriented networks), while it had a negative influence in networks such as Facebook and Friendster (i.e. social oriented networks). As the level of user participation (measured as the number of followees, tweets or interactions, among other possibilities) might also impact on the characteristics of selected followees, this hypothesis aims at verifying whether content-based relations have greater relevance in information-oriented networks, and whether such impact is related to user participation in the social network.
As exposed in previous works, the factors driving homophily are not unique and might inter-relate with interesting effects. In real-world studies, the combination of several factors was shown to make social relations less probable than what the individual factors would have suggested [41]. Similarly, in OSNs, friendships might attend, possibly simultaneously, to several reasons. For example, individuals might choose to follow some individuals because they share mutual friends, others because they are celebrities or others because they publish interesting information, among other possible explanations. Besides having multiple and diverse factors, there are multiple alternatives for assessing each of them. For example, topological similarity can be measured by considering neighbour-based, path-based or random walk-based metrics [42]. Similarly, content-based similarity can be computed by diverse metrics based on the actual content people post, the used tags, the comments people leave on others’ content or even the writing style. For example, Armentano et al. [10] and Hannon et al. [38] analysed content homophily based on the pre-processed content of tweets, whereas Chechev and Georgiev [20] considered the hashtags and links in tweets, obtaining contradicting results. In this context, the second hypothesis states that:
This hypothesis deepens on the concept of user similarity aiming at exposing the fact that choosing the relevant recommendation factors is not sufficient for guaranteeing high-quality recommendations. In this context, it explores the importance of adequately defining the concept of user similarity in the context of the followee recommendation problem.
4. Research method
The influence of homophily in the formation of new social ties in the microblogging community was studied by analysing the characteristics and effects of diverse user similarity definitions. To that end, two of the most commonly used similarity factors in followee and friendship prediction were modelled. First, topological factors on which most of the traditional link prediction algorithms rely on. Second, content-based factors, which reflect the interest of users regarding the information they share and consume.
Twitter was the social networking site chosen for assessing the impact of the followee recommendation factors and similarity metrics. The rationale behind this decision is that it is embedded in everyday social and communicative interactions around the world, and its role as a public, global and real-time communication provides a glimpse on contemporary society as such [43]. Twitter’s easiness of use has converted it into a media for sharing news or reports about events of the everyday life through politics or emergencies. This is completed by the possibility to access its data, in comparison to the data of other social networking sites. Almost
To guarantee both meaningful content-based profiles and an extensive topological network, several restrictions were imposed on users to be selected. First, users must have more than 10 followees and more than 10 published tweets regardless of whether the tweets were originally posted by the user or they are retweets. Second, the user account must have been listed as English, and the first set of retrieved tweets also must have been written in English. For determining tweets’ language, the first 200 downloaded tweets of each user (or less, depending on the total number of published tweets) were analysed using TextCat. 1
For all target users and their followees, user account information, tweets, favourite tweets, followees and followers were retrieved from Twitter, through the Twitter API. 2 Table 1 summarises user statistics. For average values, the standard deviation is shown between parentheses, exposing that the number of tweets, followees and followers are distributed over a great range of values. In the analysed dataset, 25% of the target users have fewer than 36 followees, and 50% of the users fewer than 125. This implies that the dataset covers a wide spectrum of users, ranging from users only seeking information (i.e. users with a few followees) to celebrities (i.e. users with many followees). For each target user, a set of randomly selected non-followed users was also collected to analyse the correspondence between the similarities between users and their followees, and the similarities with other strangers, or users who might not have been of interest to target users. In all cases, for each target user, a number of non-followed users equal to the double the number of actual followees were selected, provided that the similarities between such users and the target ones had a random distribution. Randomness was analysed with the Wald–Wolfowitz test for continuous data as defined in te study by Corder and Foreman [45]. As no order exists between the events, that is, the target user similarity with each of the newly selected users, randomness was tested against both trends and first-order negative serial correlation. In the former case, the similarity distribution was tested against itself at different times.
Data collection general statistics.

Tweets’ terms were filtered according to two text-processing strategies to build the content-based profiles. The first one (
As previously mentioned, this study is based on two factors that are commonly used in followee and friendship prediction: topological (see section ‘Topological factors’) and content-based factors (see section ‘Content-based factors’).
4.1. Topological factors
Most link prediction algorithms are based on topological features. Generally, these algorithms consider user’s neighbourhood or topological paths for computing user similarity. Table 2 presents the neighbourhood metrics and local similarity indexes based on topological features [47] that were included and analysed in this study. The first three metrics correspond to neighbourhood metrics, whereas the rest correspond to local similarity indexes.
Assessing topological similarity.

where,
4.2. Content-based factors
Micro-blogging platforms have become a popular communication tool among Internet users. Millions of users share opinions, details of their personal life or discuss with other users through millions of messages posted daily, converting these platforms into both informational and social networks [48]. In most sites, users establish social relations by choosing friends and subscribing to the content they publish. Hence, content arises as an important factor for recommending who to follow, as users probably become friends with whom they share content preferences. Users’ interests can be defined considering profiles based on the content they publish, or the content they read or consider interesting. Whereas the first alternative assesses users’ interests regarding the information they create and publish, the second one analyses users’ interests in terms of the information they consume, that is, the information they marked as interesting. These profiles will be referred as publishing profile and reading profile, respectively.
In Twitter, content is represented by the tweets users write. The set of tweets

The publishing profile of a user considers all published tweets, assuming that users post about things that are interesting to them and want others to read. Formally, the publishing profile of user

The goal of building a reading profile is to accurately capture users’ interests regarding the information they consume. In Twitter, if a user likes to read tweets regarding a certain topic, he or she is expected to follow users tweeting on those topics. However, followees could tweet about multiple topics, which might not all be of interest to users. Thus, it is important to identify the specific tweets that users considered interesting. Twitter provides two mechanisms for expressing interest and engagement on other users’ tweets. First, analogously as when bookmarking websites, tweets can be marked as favourites. Second, tweets can be retweeted, that is, they are reposted or forwarded to other Twitter users. When users retweet, such tweet is visible to their followers, meaning that the original tweet is shared with more people. Hence, favourited and retweeted tweets are key mechanisms for information diffusion, conveying the information users are actually interested in consuming [49].
This leads to two alternatives for creating the reading profile of a user


In turn, both alternatives can be combined as

comprising all the favourited and retweeted tweets of user
User profiles are represented following the traditional vector space model [50], in which each vector dimension corresponds to an individual term appearing in the considered set of tweets weighted by its frequency of appearance. Note that weighting strategies requiring knowledge of the full tweet collection, such as term frequency-inverse document frequency (TF-IDF) cannot be applied. As profiles are intended to be used in real-time settings, posts would be constantly arriving, leading to two implications. First, there is no fixed available document corpus on which the IDF computation is based. Second, if the data collection is considered to expand every time new tweets are known, the TF-IDF score of each feature has to be periodically computed resulting in an inefficient approach. Note that, not only the statistics of terms in the newly arriving tweet would be computed, but also the IDF statistics of the other terms should also be updated. Thus, although some information regarding the overall terms’ relevance might be lost, in highly dynamic environments it is preferable to use more efficient weighting schemes, such as term frequency.
Once profiles are built, the similarity between them can be computed using the cosine similarity metric [50]. For followee recommendation, the profile of target users should be matched to those of the potential followees. For example, the
5. Data analysis and findings
The following sections describe the data analysis performed to study the influence of the different factors and similarity definitions in followee selection. The analysis focuses on understanding how user similarity conditions friendship, whether similarity patterns exist between friends and how such similarities compare to the similarity with other randomly non-followed users. To that end, two hypotheses were defined. The first one aims at determining whether content-based relations have greater relevance in information-oriented networks, and whether such impact is related to user participation in the social network. In this context, for each factor (i.e. topology and content), the overall followee similarity distribution is presented and compared with the overall similarity distribution with randomly non-followed users. Outliers can be defined as observations that lie at an abnormal distance from the other values in the distribution, that is, they are dissimilar to the majority of the remaining data points. In this case, outliers represent similarities between users and their followees that significantly differ from the remaining similarities. In this context, such similarities could be removed as they might not represent the characteristics of the majority of the users, forcing a skewing of the data distributions towards either the low or high values. Outliers were detected following Tukey’s method [51], which is applicable to both normal or skewed data as it does not make any assumption regarding the data distribution.
For followee recommendation, a pool of potential followees to be recommended was built for each target user by including the actual followees and the set of randomly selected users. Then, potential followees were ranked according to the chosen similarity metric and selected by the recommendation algorithm. The quality of recommendations was evaluated by analysing whether the actual followees were recommended, that is, whether the selected factor and similarity metrics were enough for adequately identifying users who were already deemed as interesting. Particularly, it was evaluated by selecting the top-
In all cases requiring the analysis of the significance of the observed differences, statistical tests were used based on the study by Corder and Foreman [45]. Sample normality was evaluated by analysing their skewness, kurtosis and performing both the Shapiro and the Anderson–Darling tests.
The similarity metrics achieving the highest recommendation precision were analysed to determine whether the level of user participation has an effect on the characteristics of selected followees. To that end, target users were grouped into four equal parts delimited by the first quartile, median and third quartile, according to their number of followees or published tweets. In this context, considering all users sorted in ascending order according to either the number of followees or the number of published tweets, the median represents the value that separates 50% of the higher values from 50% of the lower ones, that is, represents the value in the middle of the distribution. Then, the first quartile represents the median of the first half of the data distribution, marking the point at which 25% of the values (either the number of followees or the number of published tweets) are lower than the first quartile and the remaining 75% are higher. Similarly, the third quartile represents the median of the second half of the data marking the point at which 75% of the values are lower and the remaining 25% are higher. User grouping was based on quartiles because they are not based on the supposition of a symmetric distribution of data and not influenced by data outliers. Thereby, the interquartile range is an adequate and robust statistic when data are skew (as the mean and average values in Table 1 show), or when the data characteristics are not known in advance [51].
The second hypothesis explores the concept of user similarity and how it influences friendship. Considering the distribution patterns in both friend and randomly selected users, user similarity’s effectiveness was studied across diverse metrics in a followee recommendation task.
5.1. Analysis of topological factors
Figure 1 presents the similarity distribution for each topological metric described in this section, for both the actual followees and the randomly selected non-followed users. The similarity distributions of Leicht–Holme–Newman Index (LHNI) are not included as they were at least two magnitude orders smaller than the other chosen metrics. For each metric, the randomness of its score distribution was tested using the Wald–Wolfowitz test. For all target users, results showed that followees were not chosen at random, that is, their similarities did not correspond to a random distribution. As Figure 1 shows, the similarity distributions are higher for the similarity indexes than for the neighbourhood metrics. However, for both metric types, similarities were lower than

Similarity distribution for the topology factor. (a) Similarities of target users with actual followees. (b) Similarities of target users with random users.
Besides analysing the non-randomness of distributions, the statistical difference between the similarity distributions of the actual followees and the randomly selected users was analysed. The Mann–Whitney test for unrelated samples was used, setting the confidence value (p-value) to 0.01 and defining the null and the alternative hypotheses. The null hypothesis stated that no difference existed among the similarity distributions, that is, the similarity distribution of the actual followees and the random users were equal. Conversely, the alternative hypothesis stated that there was a non-incidental difference between both distributions. For each metric, more than 95% of the target users showed significant differences in the distributions. In other words, there was approximately 5% of the target users, who despite not choosing friends at random, did not show a significant pattern of similarities with the followees that allowed distinguishing them from randomly selected users. This shows that there are some users who do not seem to engage with followees according to their topological similarity. In addition, as Figure 1 depicts, the one-sided statistical test showed that similarity distribution with the actual followees was higher than that of the randomly selected users.
In addition, it was tested whether the metrics measured different aspects of user similarity, that is, whether their results were unrelated. The Wilcoxon test for related samples was used, setting the p-value to 0.01, and defining the null and the alternative hypotheses. The null hypothesis stated that no difference existed among the similarity metrics, whereas the alternative one stated that each metric had a distinctive score, different from the other metrics. Cliffs’s Delta was used to quantify the effect size between the compared similarities. Table 3 summarises the observed effect sizes, where an empty cell means that the observed differences were not statistically significant, while in the other cases there exists a significant statistical difference with a confidence of 0.01. As it can be observed, the null hypothesis was rejected for most pairs of metrics with a few exceptions. In this regard, no difference was shown between Salton and Sørensen, Hub Depressed Index (HDI), LHNI and Common neighbours, and between HDI and Hub Promoted Index (HPI). In other cases, even though there existed a significant difference, the effect was negligible. That was the case of Common Neighbours, Common Followees and Common Followers, and Common Followees and HDI. As the table shows, there is a statistically significant difference between the scores observed for the similarity indexes and neighbourhood metrics. These differences can be explained in terms of how metrics are defined. As Table 2 shows, when comparing Common Neighbours with the similarity indexes, they only differ in the denominators. Moreover, the denominators of most of the similarity indexes are always lower than those of the neighbourhood metric, as the degree of union of the set of neighbours is presumably going to be higher than the degree of either set, or to the half of the sum of both degrees (as in Sørensen). The only exception to this is situation LHNI, in which the product of both degrees should be higher than the union of the degrees, yielding a higher denominator and thus lower similarity scores than Common Neighbours.
Analysis of differences between topological similarities
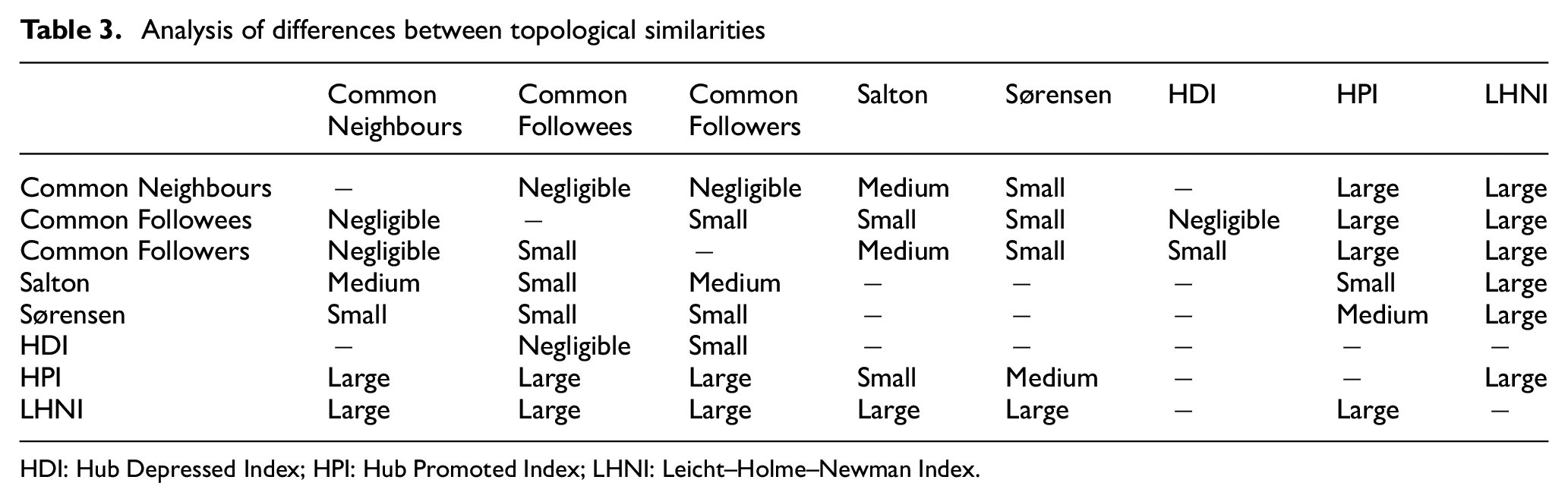
HDI: Hub Depressed Index; HPI: Hub Promoted Index; LHNI: Leicht–Holme–Newman Index.
Figure 2 shows the precision results of using the presented metrics in the context of a recommendation task. As shown, precision ranged between 0.97 and 1.0, which could imply that all metrics could accurately distinguish between the actual followees and the random non-followed users. This distinction could be due to the different similarity distributions shown by the followees and the non-followees. As Figure 1 showed, non-followees had a significantly lower similarity distribution, because of which, when sorting by similarity, those users were mostly ranked at the bottom of the ranking, and thus were not selected for recommendation.
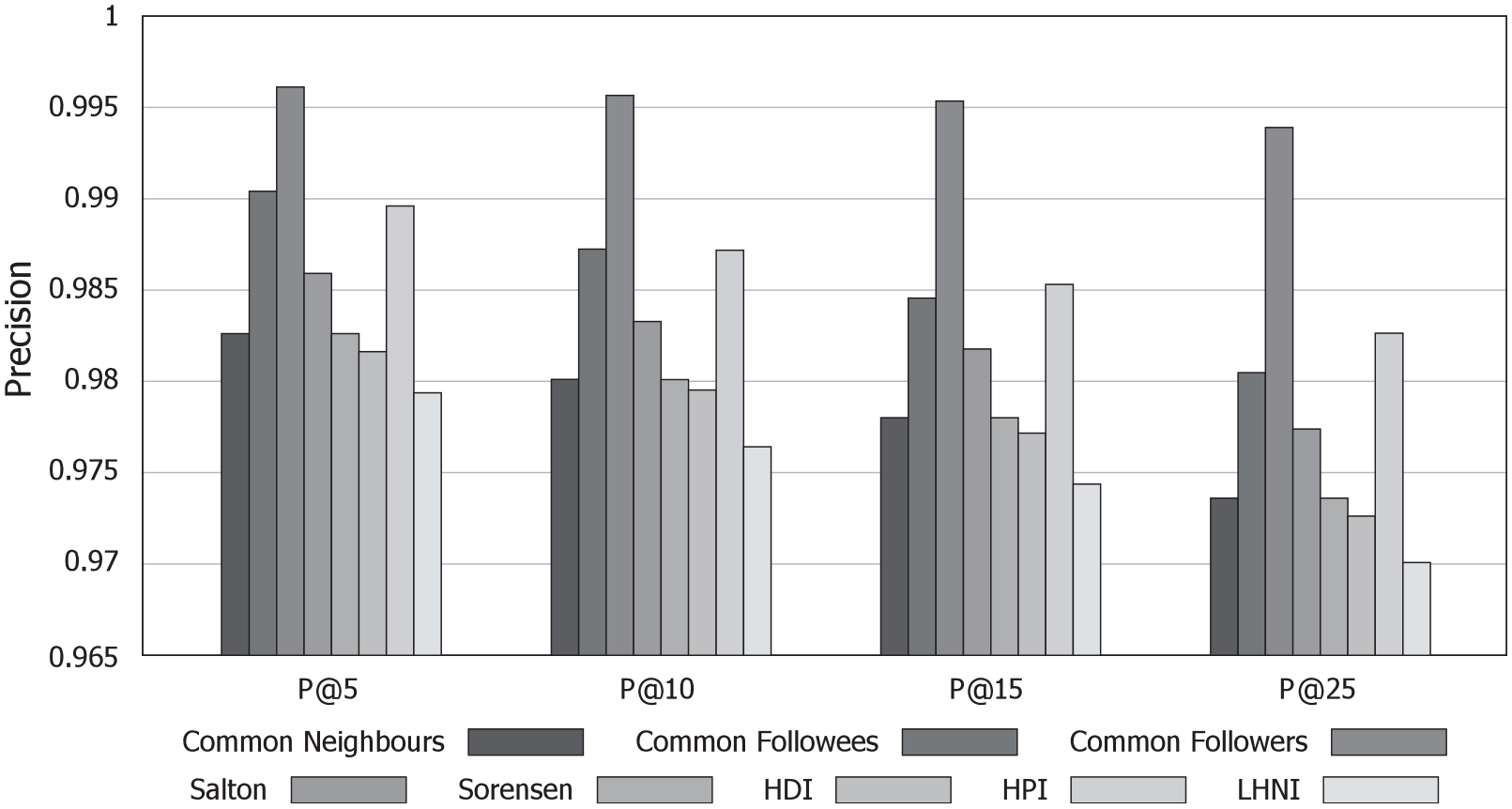
Comparison of precision results for the topology factor.
A statistical analysis of the observed differences based on the Wilcoxon test with a confidence of 0.01 was performed for each top-N. The analysis showed that although differences in almost all cases were statistically significant, their effect size was negligible. This implies that regardless of their similarity distribution, in most cases metrics behaved alike during recommendation. A few exceptions were found as the length of the ranking increased. When considering the top-25, the differences between precision results showed small to medium effect sizes, for example, when comparing Common Followers with some of the similarity indexes. In this context, it could be inferred that as the number of users to recommend, and thus the number of potential mistakes increases, the selection of the similarity metric to use becomes relevant for achieving the best possible recommendation results. On the contrary, those pairs of metrics that did not show statistically significant differences for their similarities, did not show statistically significant differences regarding their recommendation results.
Finally, regarding how user behaviour (expressed as the level of user participation on the social network) affects followee selection of followees, Figure 3 presents the Common Followees similarity distribution for the target users divided according to the statistical distribution of their number of followees or number of published tweets. Each group in the figure represents a quartile. As previously mentioned, quartiles divide a distribution into four equal parts, in which the first quartile represents the value separating the 25% lower and 75% of higher data values, the median separates the lower and higher halves and the third quartile the 75% lower and 25% of higher data values. This metric was chosen for illustrating the effect of user behaviour as it is one of the most commonly used topological metrics in the literature. As observed, the number of shared tweets does not significantly affect the topological similarity distribution, implying that the publishing activity is not strictly related to the topological characteristics of the chosen followees. This could be due to the fact that as users publish more, they might be more interested in befriending users according to the shared content regardless of the topological similarity. In addition, this interrelation between content aspects and topological similarities could indicate the existence of different sub-groups of followees, which are selected according to different criteria.
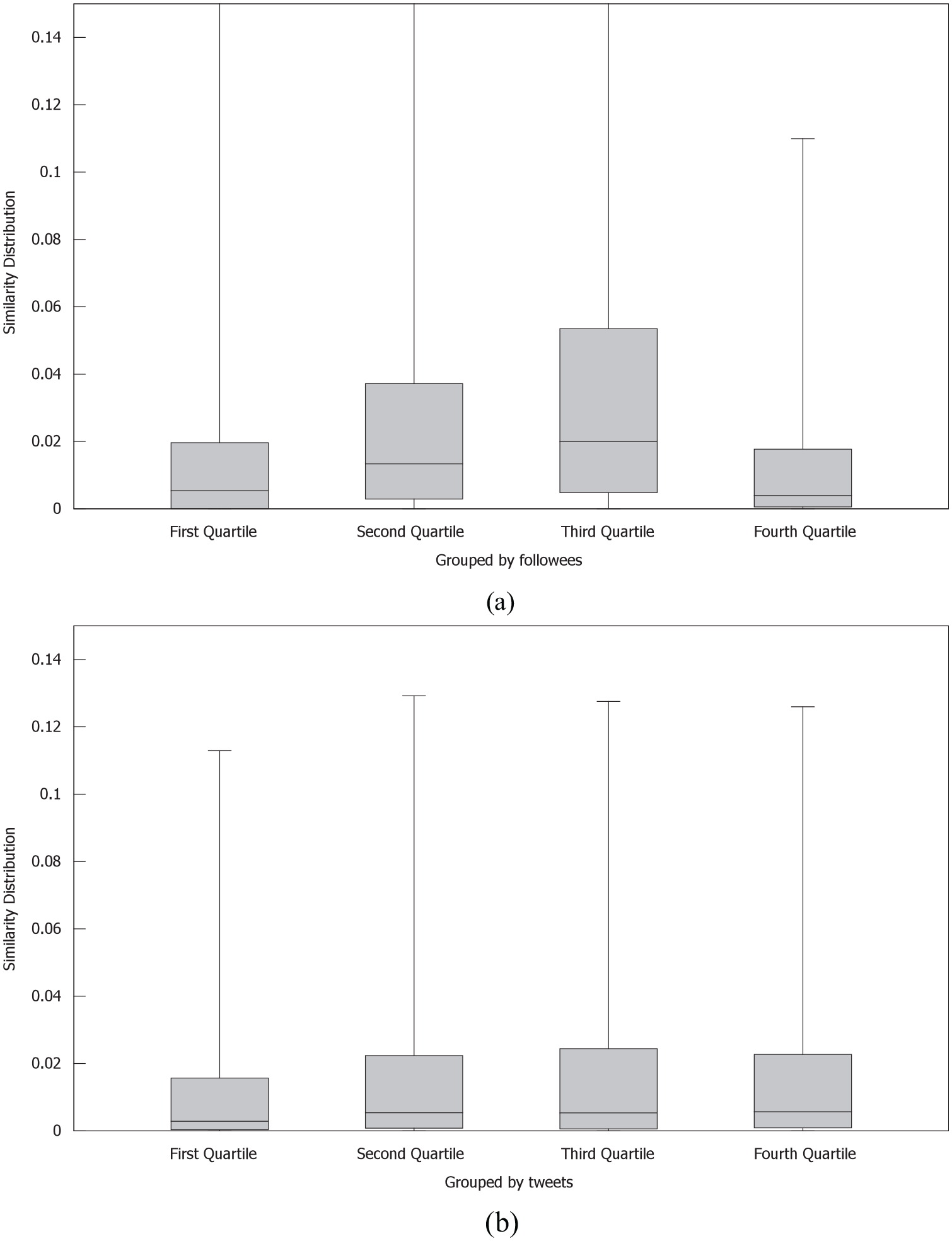
Influence of user behaviour in topology-based similarity. (a) Grouped by number of tweets. (b) Grouped by number of followees.
On the contrary, when grouping users according to their number of followees, at first, as the number of followees increases, the similarity distribution also increases. This could be caused by different phenomena. Even though Twitter is mostly a content-based network, at first, when users create their account, in most cases, they are recommended users that can be found in their email contacts (provided they granted the access to it) or contacts in other social media site (for example, Instagram includes in contact suggestions Facebook friends). In this case, it is expected that topological similarity will increase as more followees are added as they mostly belong to the same network and are probably connected. As a next step, recommendations will include followees-of-followees, which in case of being accepted will increase similarity even more with the already selected followees. Nonetheless, it might occur that after users add everyone in their close topology network, they might start expressing interest for the shared content instead of the topology, which would be accompanied by higher content and lower topological similarity.
5.2. Analysis of content-based factors
To analyse the content-based factors, the different user profiling strategies based on users’ interests were combined. Figure 4 presents the similarity distribution for each combination of the profiling strategies described in the “Content-based factors” section for both the actual followees and the randomly selected non-followed users. As depicted, content-based similarities spanned over a higher range of values than the topological ones. While topological similarities spanned between 0 and 0.4, content-based similarities spanned up to 0.95. This could be related to the content-based nature of Twitter, in which the content users share is a stronger motivation than proximity for following others. This is also fostered by the echo chamber and filter bubbles phenomena [52] that states that users tend to relate to others confirming their narratives and holding similar beliefs, which manifests through stronger content-based similarities. In this sense, similar to the expanded topological recommendations, as users start befriending others sharing a particular content, they would probably be recommended users sharing similar content. In addition, this implies that topological and content-based similarities do not share the same space, and thus cannot be directly combined into a single ranking for recommendation. For each metric, it was tested whether their distribution was random using the Wald–Wolfowitz test. In all cases, results showed that similarities did not have a random distribution, that is, followees were not chosen at random.
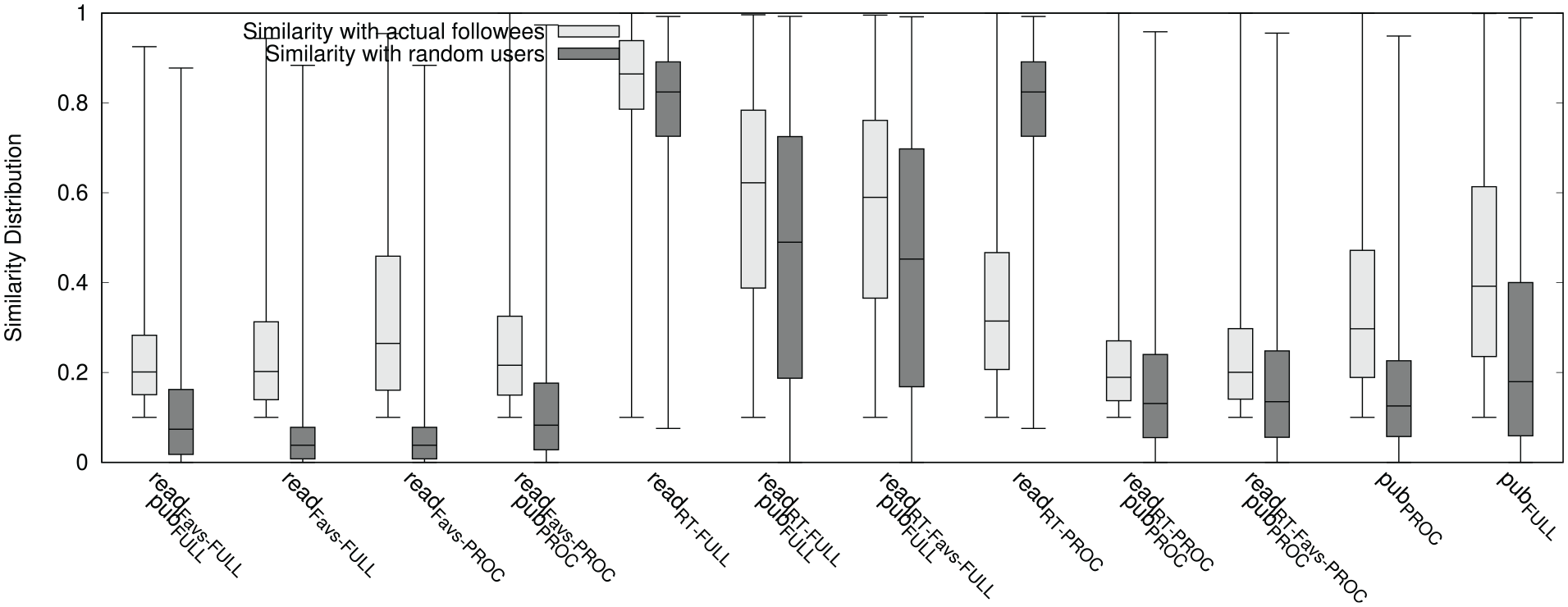
Similarity distributions of target users with followees and random users for the content-based factor.
As Figure 4 shows, regardless of the selected profiling strategy, the full text of tweets lead to higher similarities between target users and their followees. As similarity decreases with the reduction of syntactic variations of words imposed by the
As for the topological factors, the differences between the similarity distributions of the actual followees and the randomly selected users were analysed with the Mann–Whitney test for unrelated samples. Results varied according to the analysed profiling strategy. Regarding
Similar to the topology factor, for each similarity metric it was tested whether differences existed between the similarity scores obtained for each actual followee by means of the Wilcoxon test for related samples. The observed effect sizes are summarised in Table 4. Results showed that there was a statistically significant difference between the results of each pair of profiles. Nonetheless, despite being statistically different, such differences were, in some cases, negligible. In the other cases, the compared profiling alternatives were unrelated, which shows that they effectively analyse different and independent aspects of user similarity. Particularly,
Analysis of differences between content-based similarities.

Figure 5 depicts the precision results for all the combinations of profiling strategies which, as can be observed, are lower than those obtained for the topology metrics. Note that having high similarity distributions does not necessarily translate into high precision results. For example, the highest quality recommendations were not obtained for
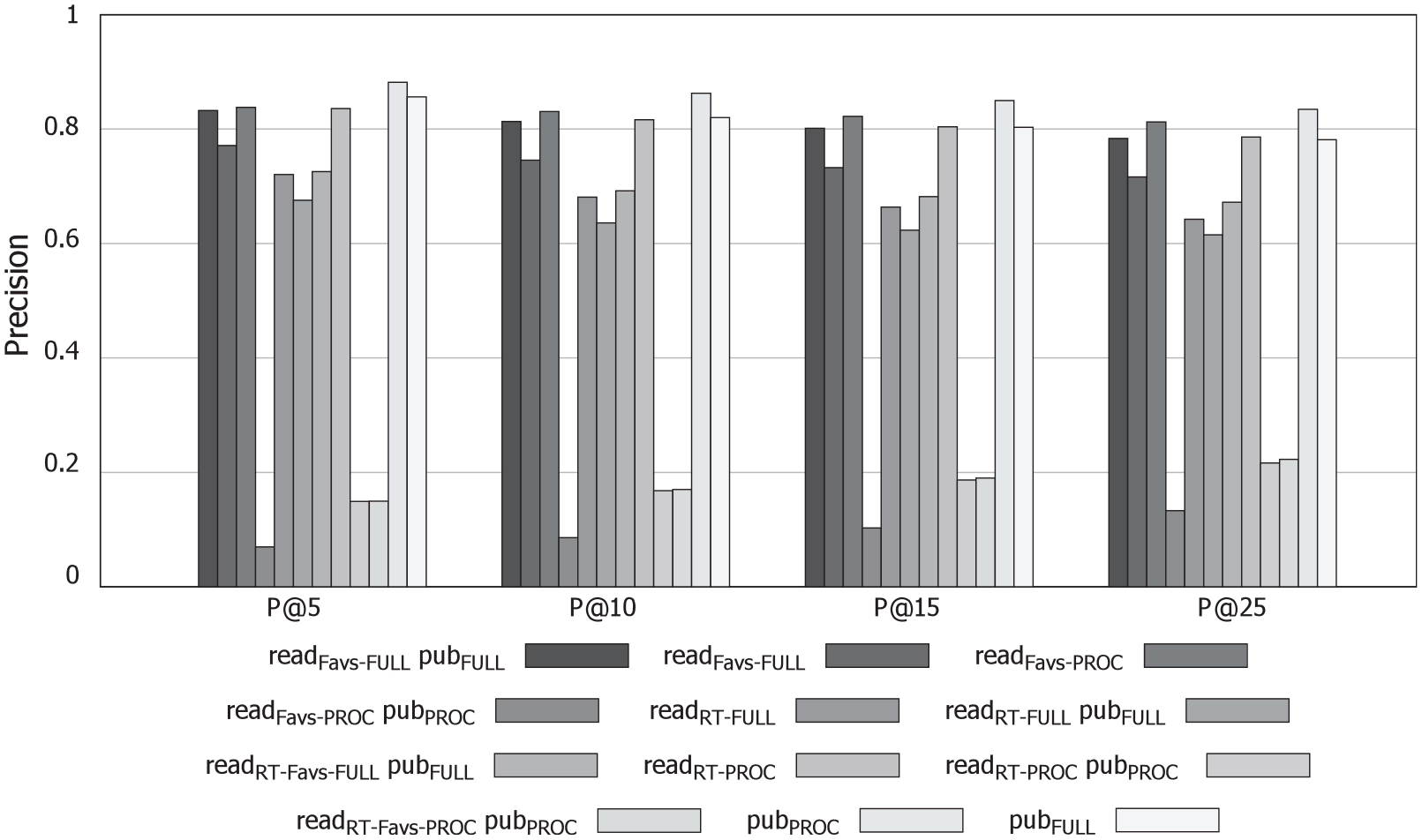
Comparison of precision results for the content-based factor.
Analysis of precision differences between content-based similarities.

Finally, Figure 6 presents the similarity distribution for
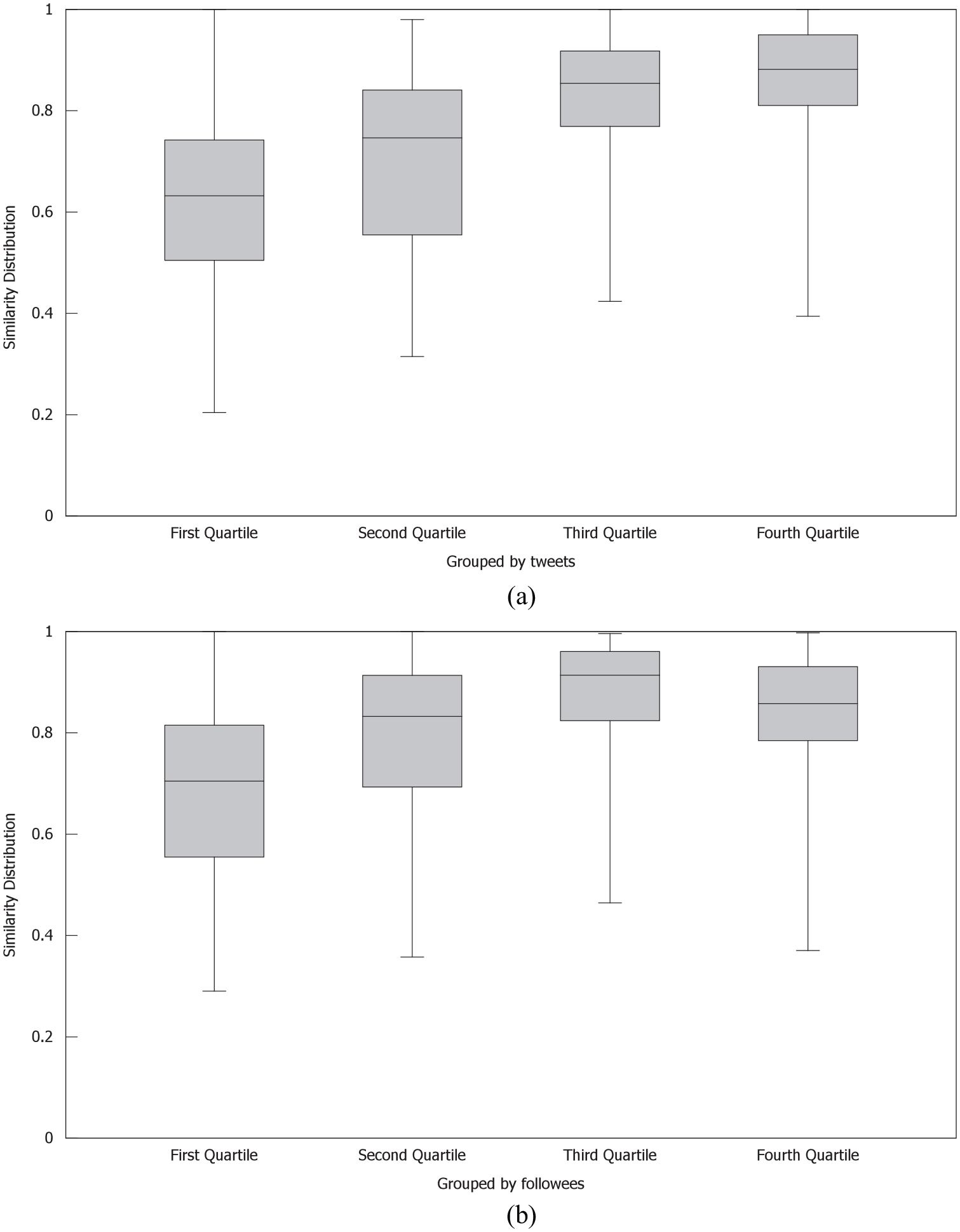
Influence of user behaviour in content-based similarity. (a) Grouped by number of followees. (b) Grouped by number of tweets.
6. Discussion and implications
In this section, an analysis of each of the proposed hypotheses that guided the study in relation with the obtained results is presented. Finally, the implications and possible applications of the performed data analysis are stated.
6.1. Homophily according to diverse recommendation factors
The first hypothesis aimed at verifying whether in information centric networks user relations are guided by information needs. It also aimed at verifying whether the user participation level (defined as the number of established social relations or actually published tweets) had an impact on the characteristics of selected followees.
As the data analysis showed, content-based similarities spanned over a greater range of values than the topological ones. Particularly,
While it might be desirable that the selected followees have unique characteristics, which would help to distinguish them from other users, if similarity distributions are different, metrics will not be reliable for this task. On the contrary, finding that random users have similar characteristics to the actually selected followees could generate noise, hindering the search of actual interesting users. This is evidenced by the precision results obtained. The similarity between the friend and random populations had an effect on the quality of recommendations expressed by their precision, which could also explain the diversity of results obtained by the studies aiming at recommending followees in Twitter [10,38].
The effect of the described phenomenon is noticeable on the diverse content-based profiling strategies and can be explained by the content-guided nature of Twitter. As shown, user activity had a greater impact on the content-related factors than on the topological one. When considering topology, followee selection was not affected by the number of posted tweets. However, the higher the number of followees, the higher are the similarities with the target user. In this regard, having more followees increased the number of users with whom the neighbourhoods were shared. However, for those users having the highest followee numbers, similarities had a similar distribution to that of the users on the first quartile. These results suggest that not all followees are chosen by their topological similarity, as they tended to share few topological ties with their followees. If that would be the case, target users with the highest followee number should also share the highest similarities with their followees.
Regarding the content-related factor, results showed that as the number of published tweets increased, the spanning range of similarities shrank, implying that highly participative users tend to choose followees sharing the same interests with lower dispersion. Similar to the previous case, the similarity spanning range was wider for those users in the first two quartiles, meaning that users who mostly read content do not focus over a unique topic, instead they choose to follow users posting information covering a great range of topics, which are probably not worthy of retweeting. These results agree with those in the study by Choudhury [53] and Dey et al. [55], which stated that as the number of followees increased, content-similarity in dyads also tended to first increase. The analysis allows inferring that the motivations for choosing followees are not unique nor static, and might change according to users’ activities. Moreover, it can be inferred that followee selection might not respond to a unique factor. These results are in agreement with those in the study by Verbrugge [36], which concurred on the existence of different motivations for starting friendships according to environmental characteristics. These motivations for forming new ties might also be related to the characteristics of the social network under analysis. For example, García-Martín and García-Sáchez [56] found differences in the motivations for using either Facebook and Twitter, which effected the type of people with whom users interacted. According to the study, young Spanish people used more Facebook than Twitter for social purposes involving friends and relatives, while they used more Twitter than Facebook for communicating with strangers.
According to Feld and colleagues [57,58], the relevant aspects of the social environment can be regarded as foci around which individuals organise their social relations. Hence, people connecting around a particular focus of activity tend to present similar behaviour regarding such activity. In the context of Twitter, the focus or activity would be sharing content. As a result, it is expected that users in a dyad share similar posting behaviour, which could translate into high content-based similarity. At the same time, people associated with the same focus may vary widely on traits that are not core to the activities of the focus [58,59]. In this regard, as the focus of Twitter is not the establishment of social relations, it is expected that the structural similarity would be lower that the content-based ones. In agreement to the study by Antheunis et al. [60], exhibiting lower similarities does not necessarily imply that similarity is not an important predictor of the quality of online friendships, as exposed by the precision results obtained.
Although there is no consensus regarding why homophily seems to occur between strangers, this phenomenon could be explained in terms of the foci around which the relations occur (i.e. the content driven nature of Twitter) [58]. As all users are motivated to share content, it is expected that content similarity might be higher that structural similarity among strangers. Moreover, results are also in agreement with those in the study by Launay and Dunbar [61], which stated that the number of people with whom traits are shared, that is, similar people, can influence the homophily towards strangers. Particularly, the authors showed that when users relate with a more exclusive group (i.e. a small group in which not necessarily all users are explicitly related), homophily among users is higher, whereas when users relate with more inclusive groups (i.e. big groups), homophily tends to decrease. In this context, the exclusiveness of groups can be measured in terms of number of followees. The analysis showed that, although the same tendencies are observed, as the number of followees increased the median of the similarity distribution with strangers was lower than that for the actual followees, implying a differentiation between users and their surrounding context.
The previous results allowed to validate the hypothesis that the characteristics of the context on which social relations are developed influence the exhibited homophily. These results agree with those found for real-world social relations, in that not every factor yields the same degree of homophily. Particularly, the characteristics of the social networks influence user behaviour, which in turn affects the characteristics of the selected followees. As a result, it can be stated that in an information centric network, social ties are guided by the desire of consuming and sharing information. Also, followee selection was shown to be affected by user behaviour, which means that interests are not static and that followee selection can be motivated not only by the context of the social network but also by users’ behaviour and interests. More importantly, these results allowed to verify the existence of relationship patterns found for real-world relations in an online environment, showing a consistency between offline and online behaviour.
6.2. Deciding on the user similarity metric
The second hypothesis aimed at demonstrating that identifying the most relevant predictive factor (e.g. content or topology) is not sufficient for guaranteeing high-quality recommendations. To this aim, the differences among the diverse alternatives for measuring the similarity between users were explored.
For both recommendation factors, the spanning range of similarities was not directly related to the quality of recommendations. In both cases, the fact that the similarities among target users and their actual followees was low for a metric, did not imply that such metric would achieve low precision results, as is the case of LHNI and
It is also interesting to analyse the elements that each metric takes into account. For instance, LHNI penalises user similarity if any of the neighbourhoods sizes is big, leading to extremely low values if either user has many followees, while HPI penalises similarity using the minimum neighbourhood size. Although those metrics presented the lowest and highest similarity distributions respectively, they can be misleading in analysing Twitter topological similarity.
The statistical analysis of the dependence among the similarity metrics showed that several topology metrics were statistically dependent. Although the metrics assess different aspects of social relations, they are intrinsically related, which leads to similar score distributions and even recommendation quality. Conversely, no statistical relationship was found among the similarities based on the diverse content-based profiling strategies, implying that each of them assesses diverse aspects of user interests.
Precision results for the topology metrics apparently implied that all metrics were capable of accurately distinguishing between the actual followees and the random set of users. However, as the random population had lower median results than the actual followees, they would be never discovered by the recommendation algorithm, as ranking users according to their similarity would place the actual followees in the first positions (as they are more similar to target users), leaving the random users at the end of the ranking, thus obtaining high precision results. Hence, it could be inferred that only assessing the precision of recommendations could be misleading for understanding the followee phenomenon.
As regards the content-related factors, recommendation quality was lower than that of the topological metrics. This could be due to the resemblance of the similarity distributions between the actual followees and the randomly selected users, which hinders the possibilities of finding the actual followees as they are all similar. Interestingly, the lowest precision results were obtained in most cases when considering the processed tweets. However, this implies that reducing the syntactic variations of words and only keeping verbs and nouns results in lower similarity values, implying that the higher similarity scores could be due to tweets sharing non-meaningful words and stopwords, instead of being actually content related. The most accurate recommendations were obtained when considering
These results validated the hypothesis that the concept of user similarity has to be carefully analysed as metrics could be biased, and hence not being useful for accurately assessing the relationship between target users and their followees. Moreover, results showed how choosing the wrong metric could affect the recommendation task by hindering the accurate search of potential followees.
6.3. Implications
The main goal of this study was to shed some light on the relative importance of different aspects of users’ online behaviour, such as social relationships and published content, in the accurate prediction of followees. The findings of this study allowed to verify each of the defined hypotheses, and established the correspondences between the studies over real-world relations and OSNs [36,57,58,60,61]. The study also allowed to verify the importance of considering the characteristics of the environment in relation to the characteristics of strangers and the similarities towards them to effectively assess the factors guiding the friend selection. Consequently, the performed data analysis showed the existence of patterns between the level of user activity in the micro-blogging site and the characteristics of the selected followees.
The findings indicate that tie formation is not a simple process. Instead, it is related to the intrinsic nature and interests of users, and at the same time is conditioned by the environment in which social ties arise. Although ties are built based on common interests, those interests might not be evident or easily distinguished among all possible factors. The strength of this study is the performed analysis of the homophilic friendship formation on two levels. First, analysing the factors driving the homophilic relations in connection with the environment and user behaviour. Second, the specific measurement of homophily, that is, the impact of adequately choosing how to measure user similarity. In turn, this allows to discover with whom users would want to become friends and with whom they actually become friends, which sheds light on the underlying processes.
Several contributions arise from this study. First, the study broadens the analysis of the homophily effect to the context of OSNs, showing that many processes originally described for real-world relationships also hold in online networking sites. The obtained results allow to examine the real-world friendship theories and enrich them. Although numerous studies have been based on the concept of homophily, none of them performed a systematic analysis of such phenomenon and the factors driving it. Second, guidelines for choosing which factors to include in the recommendation system can be derived, as well as how to measure such factors. This is also relevant in terms of the considerations needed to effectively evaluate the performed recommendations. Third, the study regarding the similarity metrics could help to refine existing recommendation algorithms by allowing to adequately measure and weigh user similarity. Fourth, as user behaviour was shown to condition the characteristics of selected users by showing that preferences might respond to a combination of the diverse factors (as expressed by Block and Grund [41]), the findings of this study could be used for designing recommendation strategies that combine and adapt the importance of recommendation factors to each users’ characteristics. Fifth, the performed analysis allowed to infer that user interests are dynamic and change over time as users share more content and follow more users, implying that the selection of recommendation factors should be also dynamic to cope with the changing behaviour of users. As a result, the findings could be the cornerstone for understanding how users select their followees and thus designing strategies for improving the performance of followee recommendation systems. The implications are not only useful in the context of friend recommendation but also for product recommendation, within friendship networks. Companies can use these findings to design efficient marketing strategies for social media.
7. Conclusion
Given the exponential number of active users in micro-blogging communities, a careful analysis of the criteria to guide the accurate selection and recommendation of potential followees is crucial. The findings indicate that tie formation is not only related to the intrinsic nature and interests of users, but also conditioned by the surrounding environment. Although ties are built based on common interests, such interests might not be easily distinguished among all possible factors. The strength of this study is that it analysed the process of homophilic friendship formation on two levels. First, the factors driving the homophilic ties in relation with the environment and user behaviour. Second, the specific measurement of homophily, that is, the impact of adequately choosing how to measure user similarity. In turn, this allows to discover with whom users would want to become friends, and with whom they actually become friends.
The performed analysis allowed to verify the proposed hypotheses, and hence answer the research questions guiding the study. The first question focused on whether the formation of social ties was influenced by user similarity. Evidence of similarity between users and their friends was found confirming the existence of homophily among them. In addition, users and their friends were shown to present different similarity patterns according to the diverse factors under analysis, which have distinctive effects over followee selection. This agrees with social theories defined for real-world friendships related to the traits driving tie formation, answering the second research question. Moreover, the study showed a relationship between the characteristics of social networks, and the behaviour and manifestation of user interests when selecting followees, hinting the answer to the third question referring to whether all aspects contribute to strengthen friend homophily. In this regard, the study stated the importance of analysing the level of users’ activity and participation for assessing the similarity with other users, and how the definition of user similarity affects the quality of the potentially recommended followees. These findings demonstrate the importance of OSN’s characteristics and users’ behaviour for performing the best recommendations. Finally, the study shed light on the relationship between users and strangers, and the reasons fostering the similarity coincidences. These results answered the fourth question highlighting the importance of considering the environmental characteristics in terms of strangers and the similarities towards them to effectively assess the factors guiding friend selection.
This work presents some limitations. First, recommendation factors were individually considered. However, users might base their decision of choosing a followee on several and distinctive reasons. As a result, not every followee is relevant according to all factors, implying that the importance of each factor varies according to each user’s interests and behaviour, as hinted by the performed data analysis. Future works should analyse how to combine the multiple factors. Second, evaluation was only performed on an offline setting in which only positive examples are available (i.e. the actual user followees). In this context, the lack of an explicit relation between two users can be considered as an implicit indication that they are not interested in each other. However, such absence could be due to the fact that users have not yet discovered each other. In such case, even though the recommendation would still be counted as an incorrect one by precision and hit-rate metrics, it could be appropriate and valuable. The same situation applies for the analysis of the similarity distributions of actual and random non-followed users. Hence, it would be interesting to test the hypotheses in an online environment with explicit feedback from users.
Finally, this study raises interesting questions for future research. First, which is the combined effect of the recommendation factors, that is, whether combining the factors allows to find other patterns of social ties. Second, whether the findings hold in other similar environments, that is, whether users in different content-driven social networking sites share the same behavioural tendencies. This study focuses only on one social networking site disregarding the possibility of users having multiple profiles in diverse sites. Hence, it would be interesting to study how users behave in different types of networks. For example, whether users having both Twitter and Facebook accounts maintain their behaviour across the different networking sites, or they are influenced by the environmental characteristics.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work has been partially funded by ANPCyT, through project PICT-2018-03323.