
Abstract
Accurate short-term wind power prediction is of great significance for the scheduling and management of wind farms. This paper proposes a model for short-term wind power prediction. Firstly, on the basis of traditional long short-term memory network, the peephole connections is added. The improved long short-term memory network is more stable compared to traditional long short-term memory neural networks and is suitable for regression prediction. Secondly, chaotic mapping, adaptive weights, Cauchy mutation, and opposition-based learning strategies are introduced to improve the sparrow search algorithm, and applied to optimize the four hyper-parameters of the long short-term memory network, greatly improving the prediction accuracy of the network. The effectiveness of the model is validated using two short-term wind power datasets with sampling times of 10 and 30 minutes respectively, combined with some fitting curves and performance indicators. The comparison results indicate that the proposed short-term wind power prediction model has high prediction accuracy.
Keywords
Introduction
Background
Wind energy has excellent characteristics such as pollution-free, wide distribution, and large reserves, making it the most promising renewable energy source for large-scale development. Wind power generation, as the main development method of wind energy, has received widespread attention worldwide (Priyadarshi et al., 2024). The technology of wind power generation is becoming increasingly mature, and the degree of scale and commercialization is also gradually increasing. The rapid development of wind power generation has effectively alleviated the difficulties faced by sustainable energy development, resulting in huge economic and social benefits.
The intermittency, volatility, and randomness of wind energy determine that wind power has a large range of fluctuations and a fast rate of change. Therefore, the adverse effects of large-scale wind power grid connection on the power grid are constantly highlighted, posing higher requirements for the planning, scheduling, and operation of the power system. To effectively solve the problem of wind abandonment and improve the dispatch and operation capability of the power system, it is necessary to rely on accurate prediction of wind power output power. The accuracy of wind power prediction directly affects the scheduling optimization results of the power grid (Klaiber and Van Dinther, 2024). At present, the accuracy of wind power prediction is difficult to meet the requirements of scheduling operation, and wind turbines do not have the schedulability of conventional units. The reverse peak shaving characteristics of wind turbines will exacerbate the peak valley difference of system load, increasing the demand for system peak shaving capacity and backup capacity.
According to the time scale of prediction, wind power prediction is usually divided into short-term prediction, medium-term prediction, and long-term prediction. The time scale for short-term prediction is hours, usually predicting the output power in the next few hours 24–48 hours in advance, mainly for the convenience of power grid scheduling to adjust the scheduling plan in a timely manner and ensure power supply quality. Compared to wind power prediction at other time scales, short-term wind power prediction has greater theoretical and practical significance (Li et al., 2023a).
Related works
In recent years, many scholars have conducted research on short-term wind power prediction models. Usually, short-term wind power prediction can be divided into statistical method, intelligent prediction method, physical method, and combination and ensemble prediction method.
Statistical method. The basic idea of a prediction model based on statistical methods is to establish a mapping relationship between the input of the system (numerical weather prediction data, historical measured operating data) and wind power, which is usually a linear relationship that can be explicitly represented by a function. For example, using regression fitting method (Jing and Zhao, 2023), exponential smoothing method (Zheng and Jin, 2022), gray model (Liu et al., 2023a), etc. These models make predictions by capturing effective data and correlation information related to time and space in the data. The prediction accuracy of these method decrease with the increase of the prediction time scale. Statistical methods are generally more sensitive to parameters, have higher prediction accuracy for stationary time series, and have lower prediction accuracy for unstable wind power. The input data of statistical models are usually historical wind speed, wind power output data, and SCADA real-time data from a period prior to the prediction time, and numerical weather prediction data can be used as model input to improve the accuracy of wind power prediction to a certain extent. Due to the simple calculation process and model structure of statistical models, which have good stability in the short-term, they are often used as benchmark models in research to evaluate the predictive performance of other models. The persistence model is the most commonly used benchmark model in statistical models, used to evaluate other prediction models (Sun et al., 2014). It is only considered a valuable prediction method when the prediction accuracy of an advanced method is better than that of the persistence method. The autoregressive model is a widely used model in the early stages of wind power prediction development. In addition, the auto regressive moving average (ARMA) model has also been widely used (Li et al., 2014). Due to ARMA’s strict requirements for the stationarity of time series, wind power time series often cannot meet the stationarity conditions. In order to solve the non-stationary nature of wind power time series, auto regressive integrated moving average (ARIMA) model can be used to establish corresponding prediction models (Li et al., 2022). However, statistical models generally fit the linear relationship between wind power and input data, while in reality, the data is non-linear. Therefore, the accuracy of statistical models for predicting wind power is relatively limited.
Intelligent prediction method. Machine learning related models have also developed rapidly in the field of wind power prediction, such as artificial neural networks (Kari et al., 2023; Wang and Li, 2023), support vector machines (SVM) (Yu et al., 2023), Bayesian networks (Liu et al., 2023b), deep learning models (Niksa-Rynkiewicz et al., 2023; Wei et al., 2023; Xu et al., 2023), etc. Other methods such as Fuzzy logic models (Khasanzoda et al., 2022) and Kalman filter (Ishikawa et al., 2017) have also been applied in the prediction of wind power. The essence of intelligent methods is to establish the relationship between input vectors and output variables through learning and training a large amount of historical operational measured data. It is a black box model, rather than explicitly describing it in the form of analytical methods. The model built by this method is usually a nonlinear model, which can more accurately fit the nonlinear relationship and non-stationary nature between wind power and wind speed, as well as the wind power time series itself, reflecting the fluctuation characteristics of wind power, the prediction accuracy is high. Intelligent prediction models also have some shortcomings. Artificial neural networks require a large amount of historical data and tedious parameter adjustment processes. The accuracy of support vector machines is greatly influenced by parameters, resulting in complex training processes and long training times. Deep learning models require a large number of samples and high time complexity costs, which must also be considered. Fuzzy logic models have higher complexity and require longer processing time when there are many rules. Bayesian networks require the professional level and experience of modelers. The Kalman filter model requires information from the previous system.
Physical method. The essence of a physical model is to improve the resolution of a numerical weather prediction model (Zeng et al., 2023), enabling it to accurately predict weather parameters such as wind speed, direction, pressure, and temperature at a certain point (such as at each wind turbine). Based on the weather forecast variables such as wind speed, direction, pressure, and temperature predicted by the numerical weather prediction model, as well as geographic and terrain factors and contour lines around the wind farm, using micro meteorology theory and computational fluid dynamics methods, calculate meteorological information such as wind speed and direction at the height of the wind turbine hub, and then calculate the power prediction results for each wind turbine based on the power curve of the wind turbine. Due to the low update frequency of numerical weather prediction data, physical methods are more suitable for medium to long-term wind power prediction, but not for short-term wind power prediction (Saini et al., 2023). Meanwhile, many wind farms are unable to obtain meteorological data.
Combination and ensemble prediction method. A single prediction model for wind power prediction may have good prediction performance in specific prediction environments, but it can also lead to significant errors at certain measurement points and may not achieve high accuracy prediction results in all cases. Therefore, in order to optimize the prediction process and improve prediction accuracy, using a combination of multiple models has gradually become a popular research approach. Combination prediction methods can establish combination prediction models based on the technical characteristics and advantages of each model, overcome the limitations of individual prediction models, and effectively reduce the probability of large error points. According to the definition and modeling differences of combination prediction methods, they can be divided into four categories. The first method is a combination prediction method based on weight coefficients (Duan et al., 2022; Liu et al., 2022). The weighting process of wind power combination prediction is to allocate appropriate weight coefficients based on the relative effectiveness of each individual model, reflecting the importance of the model in the combination model. The second method is a combination prediction method based on data preprocessing. The data preprocessing model can decompose nonlinear wind power or wind speed time series into stable subsequences that are easy to analyze and predict. In addition, it can filter out irrelevant or residual feature quantities in the data, improve the quality of the original data, and avoid redundant calculation processes. Common decomposition algorithms include wavelet transform (Zhang et al., 2023), ensemble empirical model decomposition (Du et al., 2023), variational model decomposition (Qin et al., 2023), etc. The third method is a combination prediction method based on model parameter optimization. Parameter selection and optimization methods can play a certain role in improving the prediction performance during the model training process. Swarm algorithms are the most common optimization algorithms in wind power prediction. Some newest algorithms include whale optimization algorithm (Saeed et al., 2023), wolf optimization algorithm (Cai et al., 2023), sparrow optimization algorithm (Awadallah et al., 2023), etc.
Main work
This paper mainly discusses the prediction of short-term wind power. A prediction approach combining swarm intelligence optimization algorithm and deep learning model is adopted, with short-term wind power as the research object. The performance of the model is verified through actual collected wind farm data. In summary, the main innovations of this paper are as follows.
Choose an improved long short-term memory (LSTM) with peephole connections as the short-term wind power prediction model. Each gate in the improved LSTM can peek at the unit state, improving prediction accuracy.
On the basis of the standard sparrow search algorithm (SSA), an improved SSA (ISSA) is proposed by combining Cauchy mutation optimization and opposition-based learning. Compared with the standard SSA, it reduces the possibility of falling into local optimal, improves the convergence accuracy and development ability of the algorithm.
The ISSA is used to optimize the hyper-parameters of the improved LSTM model, greatly enhancing the predictive ability of the improved LSTM.
Structure of the paper
Other contents of this study are as follows. Section 2 introduces the basic theory of LSTM with peephole connections. Section 3 gives the introduction to the process of ISSA and tested its benchmark function. In Section 4, the implementation process of ISSA optimized improved LSTM for short-term wind power prediction is described. Section 5 verifies the effectiveness of the proposed short-term wind power prediction model. The last section gives the conclusion and future work.
LSTM with peephole connections
LSTM is essentially a type of recurrent neural network (RNN). However, RNN is unable to effectively utilize earlier historical information, resulting in long-term dependencies issues. LSTM addressed the shortcomings of RNN, as it can learn long-term dependencies (Li et al., 2024a). The LSTM has been designed to solve the problem of long-term dependencies, and the solution is that the LSTM network can remember longer historical information. Unlike RNN networks, LSTM has a different repetitive module structure. Neural networks typically have one layer, but LSTM has four layers and uses special processing methods for interaction.
Compared to RNN, LSTM can learn the target more effectively in cases of long time lag. However, if precise calculation of time is required in a long lag, LSTM cannot achieve it. This paper introduces an improved LSTM, which adds peephole connections to the traditional LSTM network model. The improved LSTM network is more stable compared to traditional LSTM networks and is more suitable for regression prediction problems such as short-term wind power. The structure of the improved LSTM network is shown in Figure 1. The implementation process of the forgetting gate is shown in equation (1). The implementation process of the input gate is shown in equations (2)∼(4). The structure of the output gate is shown in equations (5) & (6).






where
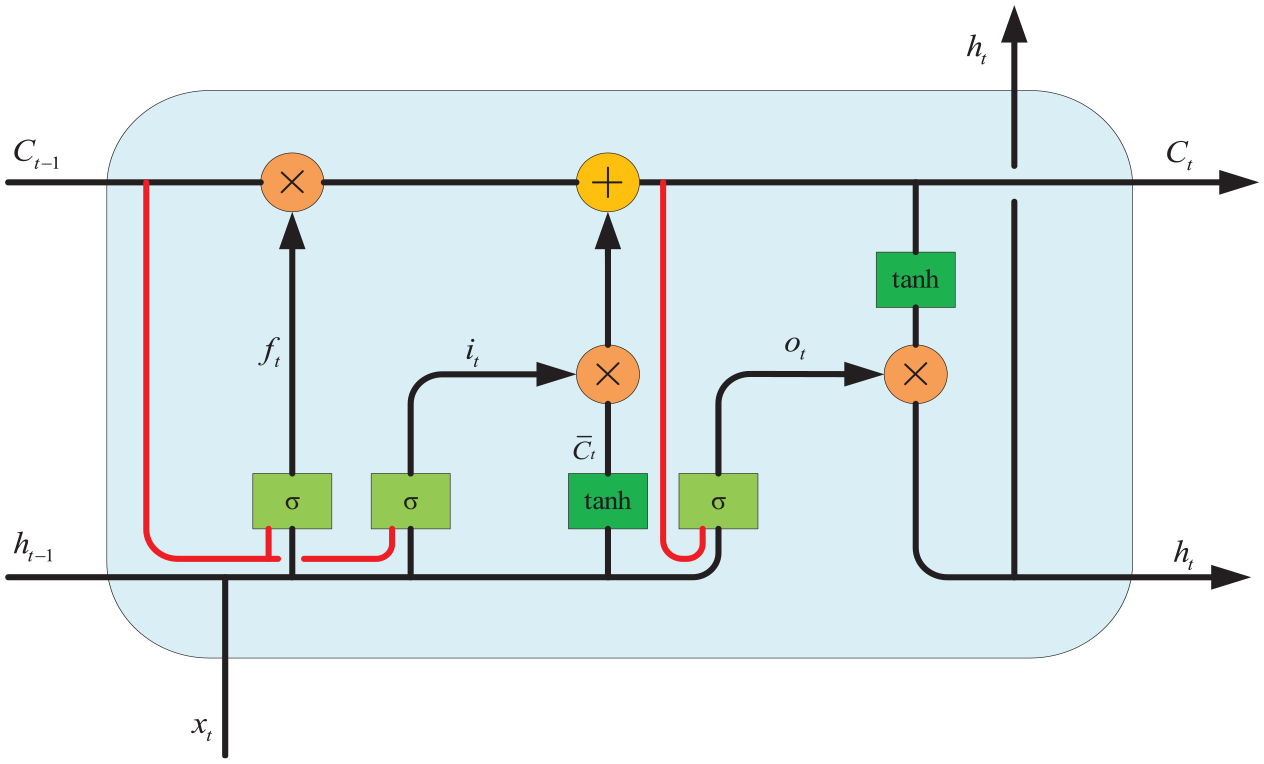
The structure of the LSTM with peephole connections.
The LSTM network contains one or more memory cells. It also includes three adaptive memory blocks with added gating units, which are shared by all cells in the block. The core of each memory cell has a cyclic self connecting linear unit called constant error carousel (CEC). CEC allows LSTM to be applied across large time lags (1000 discrete time steps or more) between objects, and this algorithm can directly obtain cell outputs. But if the output gate is disabled, the output will approach 0, and the lack of information may damage the performance of the network. Therefore, by adding peephole connections from CEC to the same memory block, LSTM cells can be expanded to examine their current internal state. Even if the target signal lacks information, the LSTM model can perform precise and stable learning without a mentor.
When LSTM networks are applied to regression prediction, many parameters affect the final performance. The most important parameters include number of neurons in the first layer LSTM unit (L1), number of neurons in the second layer LSTM unit (L2), learning rate (LR), and iterations (ITR). The three parameters L1, L2, and LR affect the performance of the LSTM network, while LR affects the speed of the LSTM network. This paper uses an ISSA to optimize the hyper-parameters of the LSTM network.
ISSA
In this section, improvements are made to SSA to achieve ISSA, and its performance is tested.
Implementation of ISSA
SSA is first proposed in 2020 as a new swarm intelligence optimization algorithm (Xue and Shen, 2020). Compared with other optimization algorithms such as particle swarm optimization or differential evolution, SSA has the advantages of fast iteration speed, fast convergence speed, accurate extreme value optimization, and high solving efficiency (Geng et al., 2023; Yue et al., 2023). On the other hand, SSA has shown superior capabilities in function optimization problems compared to swarm intelligence algorithms such as particle swarm optimization and gray wolf optimization. It also has the characteristics of easy implementation and adjustment, making it suitable for solving complex optimization problems with low dependence on initial solutions and adapting to different types of problems, such as capacity configuration of wind-solar-diesel-storage (Dong et al., 2022), path planning for mobile robots (Hou et al., 2024; Wei et al., 2024), node localization in wireless sensor networks (Zhang et al., 2022), and so forth. Therefore, this paper chooses SSA and improves it to apply to the parameter optimization of LSTM. The principle of SSA is as follows.
The set matrix is shown in equation (7).

where K is the number of sparrows,


where

where
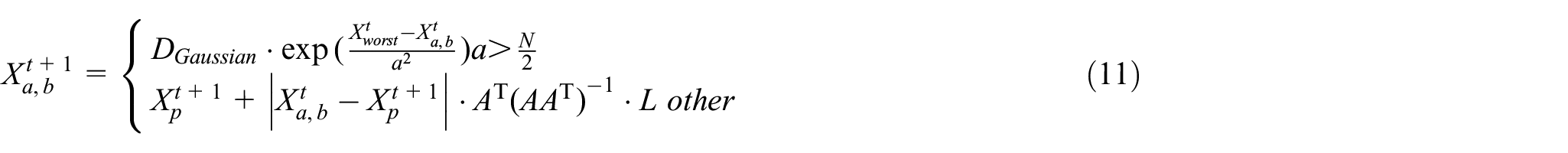
where

where,
Standard SSA has local extremum problems. Therefore, this paper proposes ISSA, which principles are as follows.
Sin chaotic initialization population
The population initialization of the sparrow algorithm is carried out using Sin chaotic, and the expression of the one-dimensional self-mapping of Sin chaotic is shown in equation (13).

Dynamic adaptive weight factor
In the initial stage of SSA, the discoverer keeps approaching the optimal solution, which limits the search range of the algorithm and leads to falling into local extremes. This paper introduces a dynamic weight factor, which has a larger value in the early stages of iteration and better global search ability. In the later stage of iteration, its value adaptively decreases, which is more conducive to local search. Meanwhile, the convergence speed has significantly improved. The expression for the weight factor is shown in equation (14). The updated location of the improved discoverer is shown in equation (15).


where
Improved update method for warning sparrows
The improved warning sparrow update method is shown in equation (16). According to equation (16), it can be seen that the improved update method expresses that if a sparrow is in the optimal position, it will move to a random position between the optimal and worst positions, or to a random position between itself and the optimal position, thereby increasing the diversity of optimization solutions.

The fusion of Cauchy mutation and opposition-based learning strategy
In order to help sparrows find the optimal solution, opposition-based learning strategy is integrated into the SSA. Its expression is shown in equations (17)∼(18).


where,
Introduce Cauchy variation into the equation of the target location. The Cauchy operator has better perturbation ability and improves the global optimization performance of the algorithm. The Cauchy mutation expression is shown in equation (19).

where

In order to further improve the optimization performance, this paper adopts a dynamic selection strategy to update the target position, which integrates reverse learning strategy and Cauchy mutation to transform with a certain probability and dynamically update the target position. The calculation formula for selecting probability

where
Finally, the greedy rule is introduced to compare the fitness values of two new and old positions and determine whether to update the positions. The greedy rule is shown in equation (22).

The specific implementation steps of the proposed ISSA are as follows.
Performance analysis of ISSA
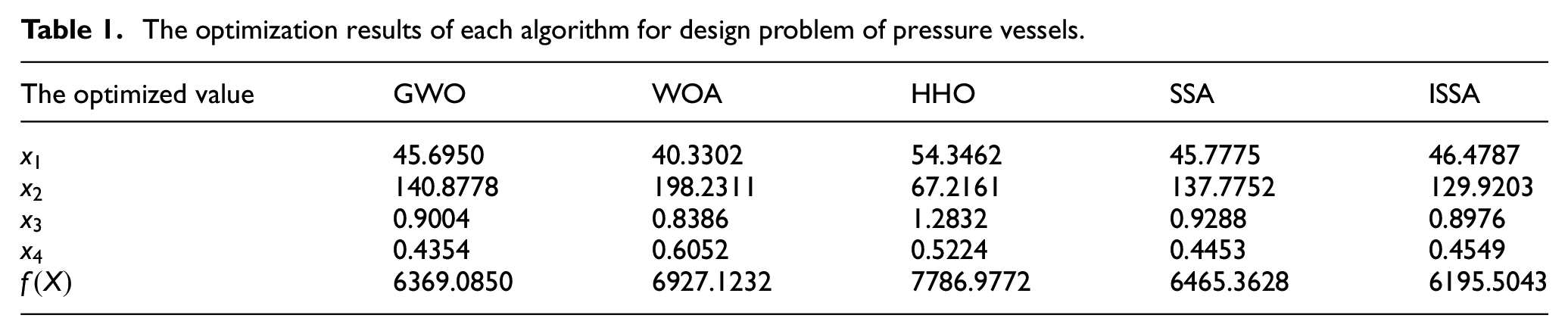
To verify the optimization performance of ISSA, the optimization design problem of pressure vessels is selected as a test case. The optimization design problem of pressure vessels is a well-known benchmark problem in engineering applications, which can be used to verify the optimization performance of the proposed ISSA. As shown in Figure 2, the optimization problem can be described as calculating the optimization design variables
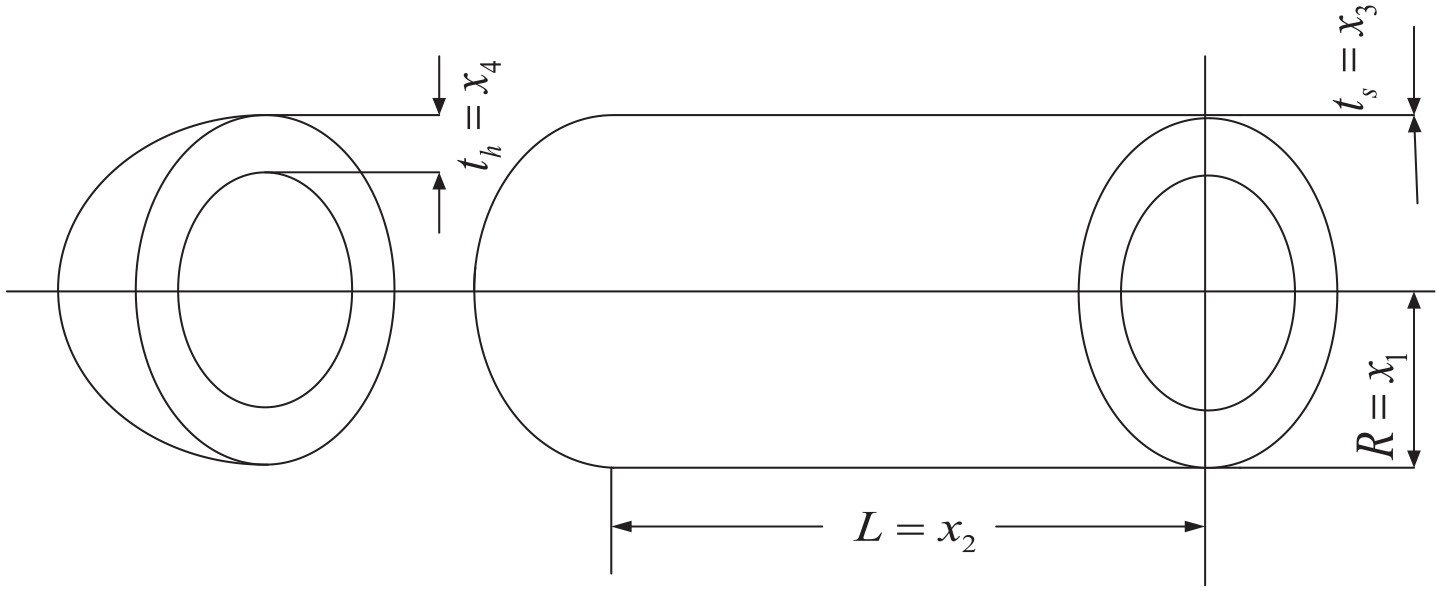
The optimization design problem of pressure vessels.
The process of container optimization design is as follows, with a search variable of

The constraints are as follows.

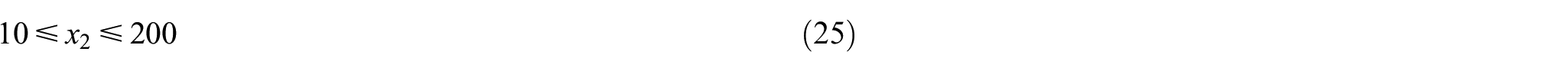






ISSA and SSA are used to optimize the design of pressure vessels separately. Set the iteration times of the two algorithms to 1000 times, the population size is 50, and optimize the average fitness curve after 10 times as shown in Figure 3. From Figure 3, it can be seen that the ISSA has faster convergence speed and better adaptability than the SSA. The results indicate that the ISSA proposed in this paper is effective. After optimization, the optimal solution obtained by the SSA is 45.7775, 137.7752, 0.9288, and 0.4453, and the optimal value of the objective function obtained is 6465.3628. The optimal solution obtained by ISSA is 46.4787, 129.9203, 0.8976, 0.4549, and the optimal value of the objective function obtained by ISSA algorithm is 6195.5043. From the optimization results, the proposed ISSA is more capable of finding the global optimal solution than SSA. Prove that ISSA has improved performance compared to the original SSA, therefore, the optimization of LSTM model by ISSA is feasible.

Fitness performance comparison between ISSA and SSA.
To further demonstrate the effectiveness of ISSA, gray wolf optimization (GWO) algorithm, whale optimization algorithm (WOA), and Harris Hawks Optimizer (HHO) are selected for comparison. The algorithms are also run 10 times, and the average value is taken as the final result. The maximum number of iterations is 1000, and the population size is 50. In GWO, a is 2 (linearly decreased over iterations). In WOA, a is 2 (linearly decreased over iterations). In HHO, β is 1.5. The optimization results are shown in Table 1. From the results in Table 1, it can be seen that ISSA performs better than SSA and other optimization algorithms, making it very suitable for hyper-parameters optimization in LSTM.
The optimization results of each algorithm for design problem of pressure vessels.
Designed prediction model
Based on the introduction of the above basic knowledge, the flow chart of the proposed wind power prediction model is shown in Figure 4.

The flow chart of the proposed wind power prediction model.
According to Figure 4, the specific implementation process of the designed short-term wind power prediction model is as follows.

Simulation and verification
The effectiveness of the prediction model is verified through actual wind power data. Compared with other prediction models, the comparison results fully demonstrate the effectiveness of this prediction model.
Dataset
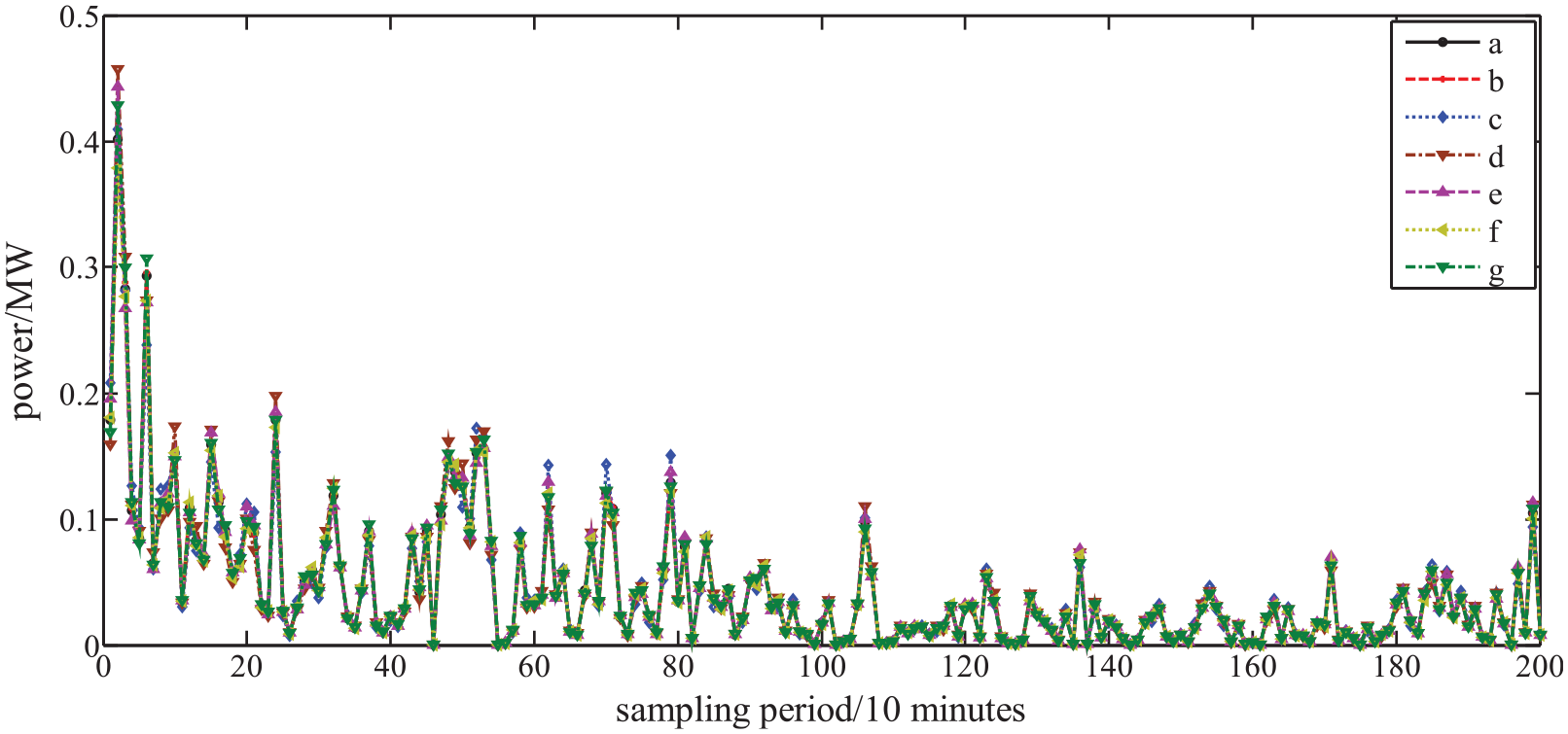
This paper collected two sets of short-term wind power datasets from Xintianbao Wind Farm in Tieling City, Liaoning Province, China. The sampling period of the first dataset is 10 minutes, from Unit 2 of the wind farm, named as dataset 1. The sampling period of the second dataset is 30 minutes, from Unit 8 of the wind farm, named as dataset 2. The length of both datasets is 1000. Use the first 800 sets of data as the training set and the last 200 sets of data as the test set. The two collected wind power datasets are shown in Figure 5. From the curve changes in the graph, it can be seen that short-term wind power exhibits non periodic, random, and nonlinear characteristics, making it suitable for verifying the performance of the prediction model.

The two collected wind power datasets.
Performance indicators
The performance of predictive models can be judged by some performance indicators. This study introduces the following eight widely used performance indicators to evaluate the effectiveness of the model (Li et al., 2024b).
RMSE

Mean absolute error (MAE)

Mean absolute percentile error (MAPE)

Relative root mean square error (RRMSE)

Square sum error (SSE)


Theil inequality coefficient (TIC)

The index of agreement (IA)

where,
On the other hand, this paper uses the Diebold-Mariano (DM) test to verify the accuracy of the prediction model under certain confidence levels (Sun et al., 2023). The premise of hypothesis testing is,


The statistical value of DM testing is equal to the following equation.

where
Results
Following the implementation steps of the prediction model introduced above, the LSTM with peephole connections network needs to be optimized first. The four parameters to be optimized and their set upper and lower bounds are
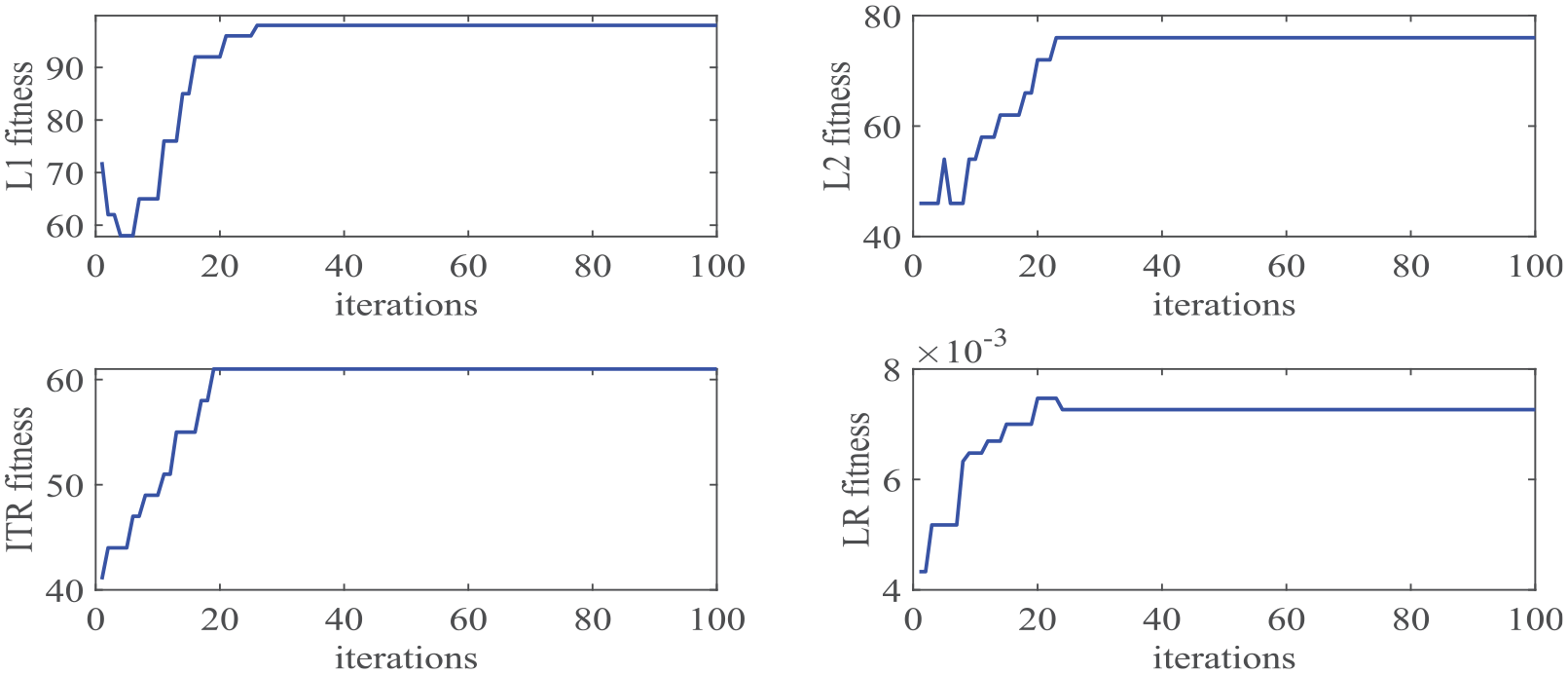
Fitness of hyper-parameters in LSTM network based on ISSA (dataset 1).
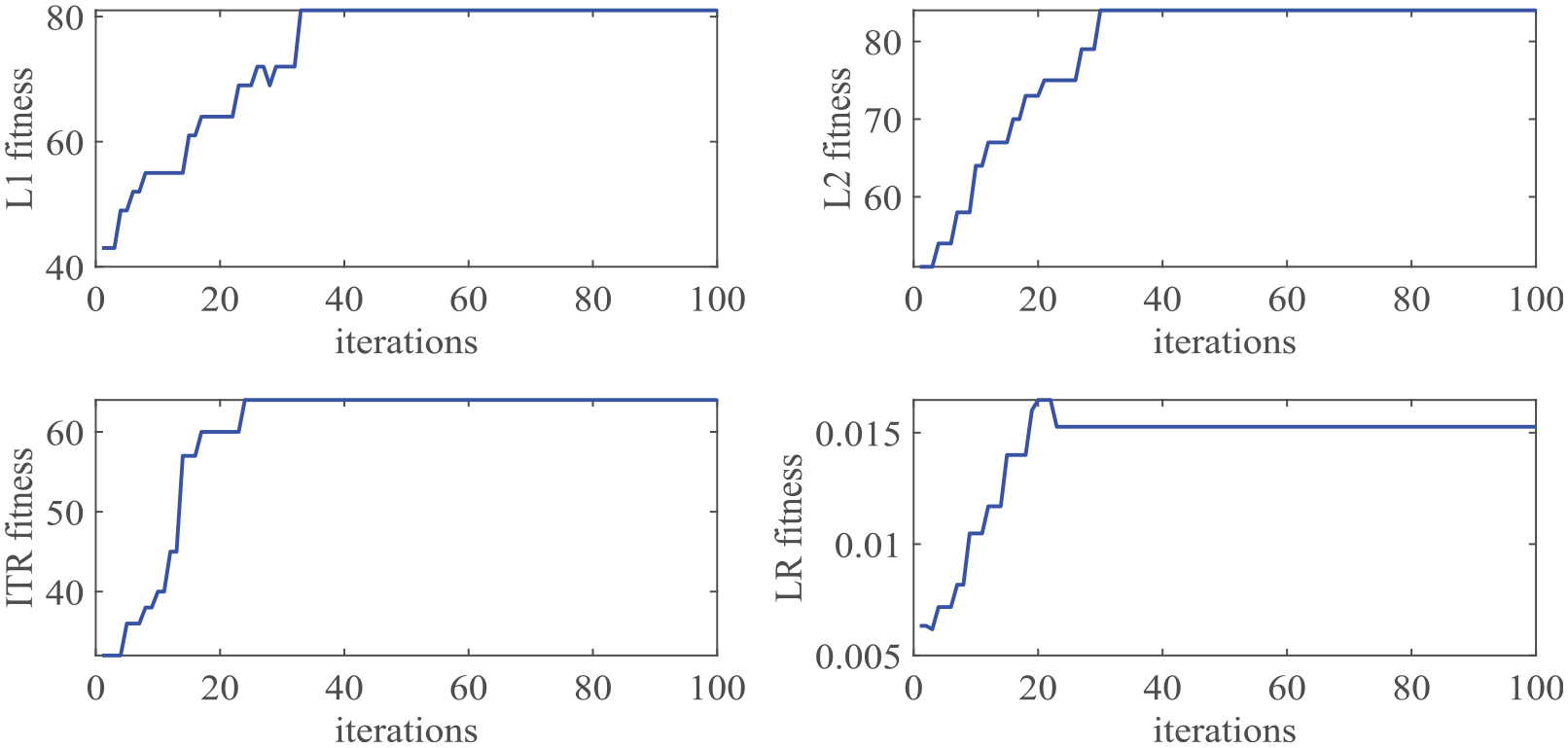
Fitness of hyper-parameters in LSTM network based on ISSA (dataset 2).
The optimized results.

This study selects the following five models for comparison to demonstrate the effectiveness of the proposed model. These models include ARIMA (Li et al., 2022), SVM (Yu et al., 2023), improved flower pollination algorithm optimized echo state network (IFPA-ESN) (Tang et al., 2021), PSO-LSTM (Zhao et al., 2024), and SSA-LSTM. For fair comparison, the parameters of these models are obtained through classical methods or methods introduced in the literature. For ARIMA, the AIC criterion is used to determine the order of the model. For SVM, the cross validation method class is used to determine the hyper-parameters of the model. For IFPA-ESN, the population size is 20, maximum number of iterations is 100, transition probability is 0.8, beta is 1.5, then IFPA is used to optimize ESN. For PSO-LSTM, the population size is 20, maximum number of iterations is 100, the weight coefficient is 0.8, and the acceleration factors are 2 and 1.5, PSO is used to optimize LSTM. For SSA-LSTM, the parameters are same with ISSA. The parameters of the 5 models are shown in Table 3.
The parameters of comparison models.

The ISSA optimized the parameters of the LSTM network and obtained the optimal values of four parameters. The optimized LSTM network was used to predict short-term wind power and obtain the final prediction result. The comparison curve between the predicted value and the actual value is shown in Figures 8 and 9. From the comparison results of the two graphs above, it can be seen that compared with the other five models, the ISSA-LSTM model can more accurately match the actual output and has better predictive performance compared to other models. The predicted values provided by this prediction method can more accurately reflect the actual short-term wind power.
Short-term wind power prediction of each model for dataset 1 ((a): actual value; (b): proposed model; (c): ARIMA; (d) SVM; (e) IFPA-ESN; (f) PSO-LSTM; (g) SSA-LSTM).
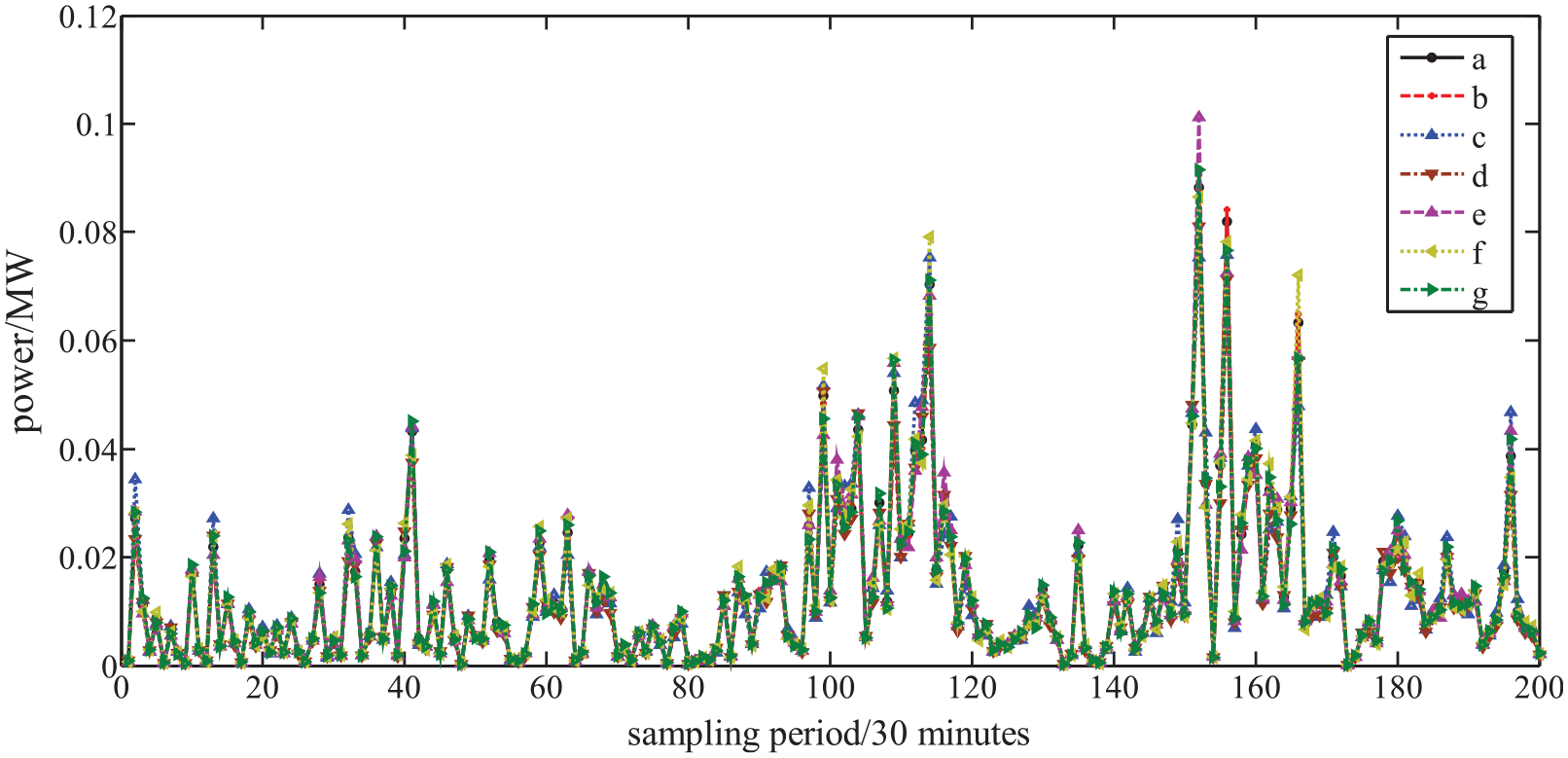
Short-term wind power prediction of each model for dataset 2 ((a) actual value, (b) proposed model, (c) ARIMA, (d) SVM, (e) IFPA-ESN, (f) PSO-LSTM, and (g) SSA-LSTM).
In order to observe the effectiveness of the proposed prediction model more intuitively, the prediction errors of each model for dataset 1 are shown in Figure 10, and the prediction errors for dataset 2 are shown in Figure 11. From Figure 10, it can be observed that the proposed prediction model has a smaller overall prediction error range, between [−0.0052, 0.0036]. Moreover, the fluctuation of errors during the prediction process is smaller compared to other models, and the prediction effect is more stable. The prediction error range of ARIMA is [−0.0290, 0.0549], and the prediction effect is poor. The error of SVM is basically between [−0.0552, 0.0200], and the error range of IFPA-ESN is basically within [−0.0415, 0.0209]. Although PSO-LSTM and SSA-LSTM have good stability performance, they have certain disadvantages in terms of stability and prediction accuracy compared to the proposed prediction models. From Figure 11, it can be observed that although the proposed model has some fluctuations in error, the overall error range is still far superior to other models, and the prediction accuracy also has a certain advantage. The prediction error range of the proposed model is mostly between [−0.0052, 0.0036], and the stability performance is good. In summary, the proposed model has certain advantages in stability and prediction accuracy.

Prediction errors of each model for dataset 1 ((a) proposed model, (b) ARIMA, (c) SVM, (d) IFPA-ESN, (e) PSO-LSTM, and (f) SSA-LSTM).
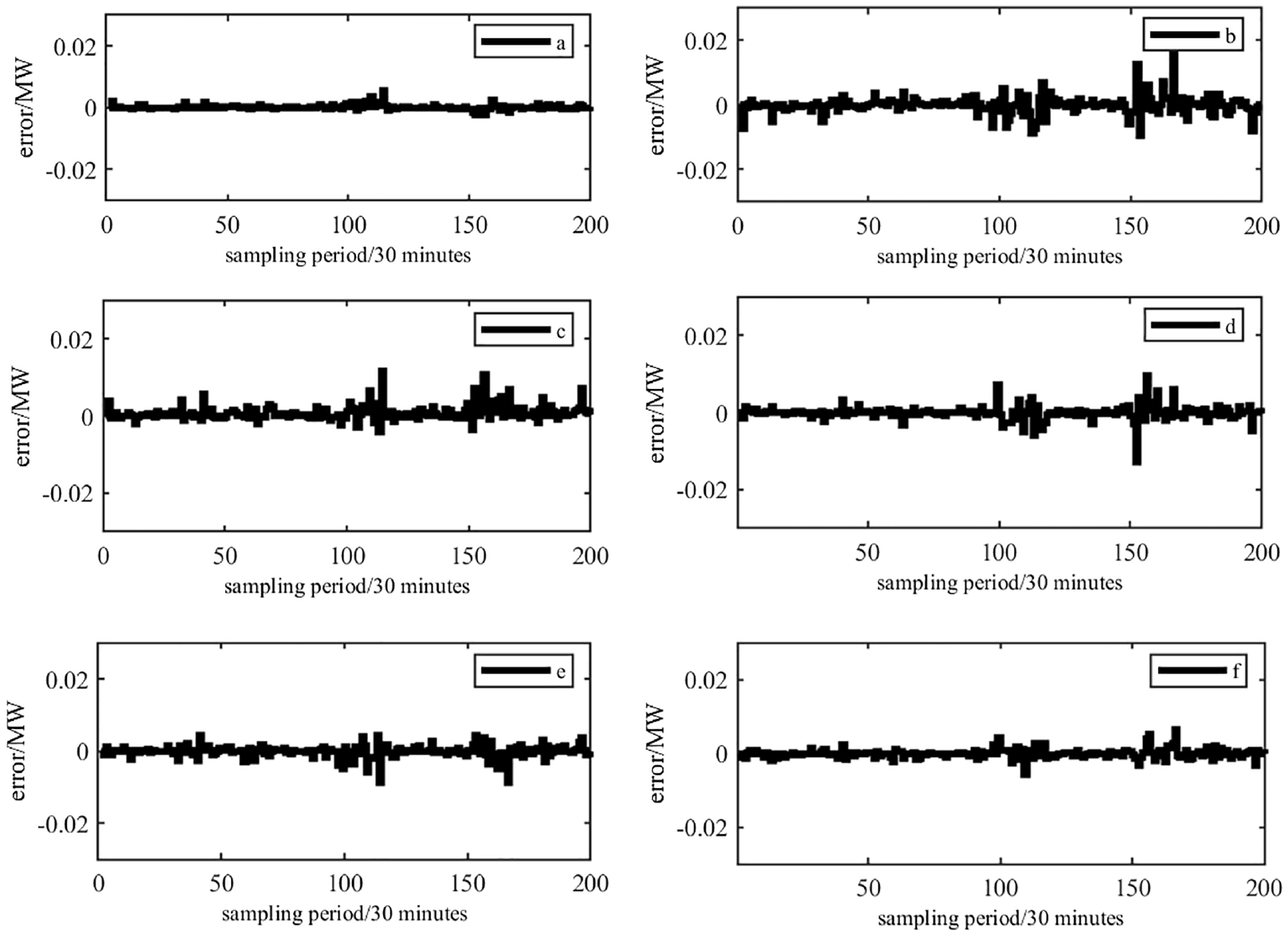
Prediction errors of each model for dataset 2 ((a) proposed model, (b) ARIMA, (c) SVM, (d) IFPA-ESN, (e) PSO-LSTM, and (f) SSA-LSTM).
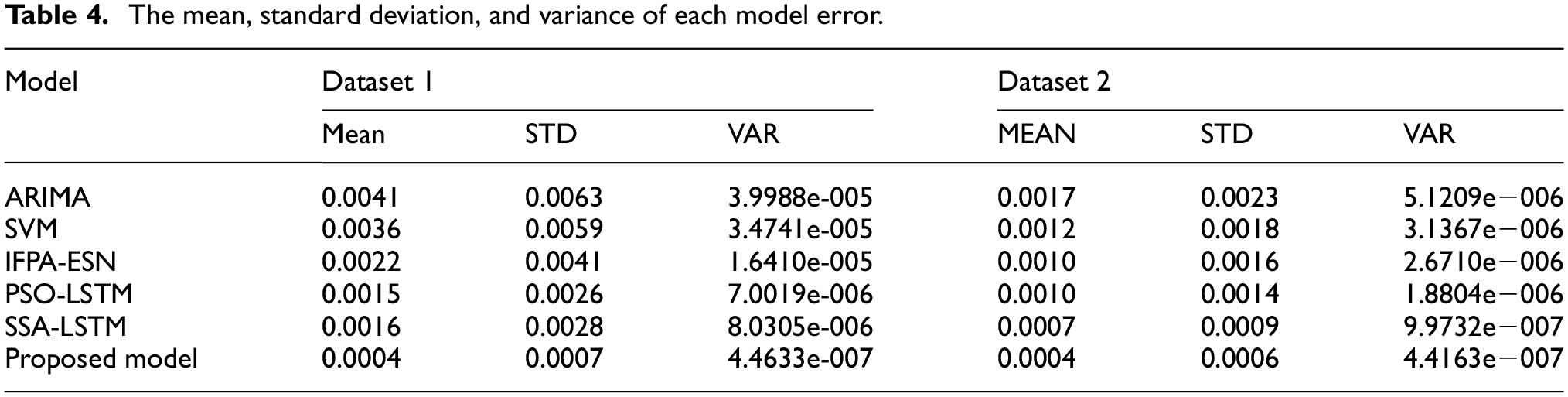
The mean value can reflect the concentration trend of model fitting errors, the standard deviation (STD) can reflect the degree of dispersion of fitting errors, and the variance (VAR) can reflect the fluctuation and stability of fitting errors. To avoid offsetting positive and negative errors, the absolute value of the error is used for calculation. Table 4 shows the mean, standard deviation, and variance of each model error.
The mean, standard deviation, and variance of each model error.
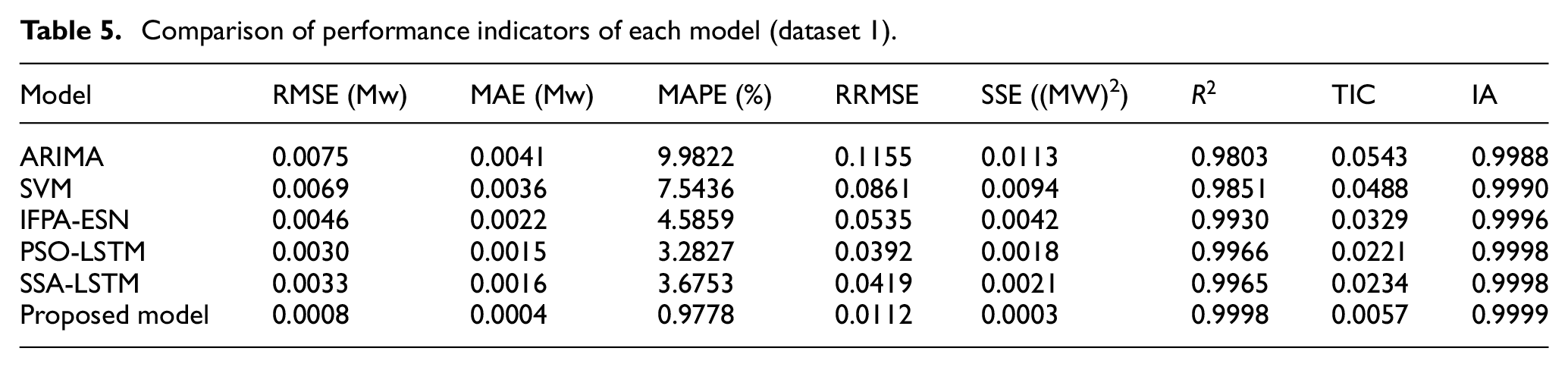
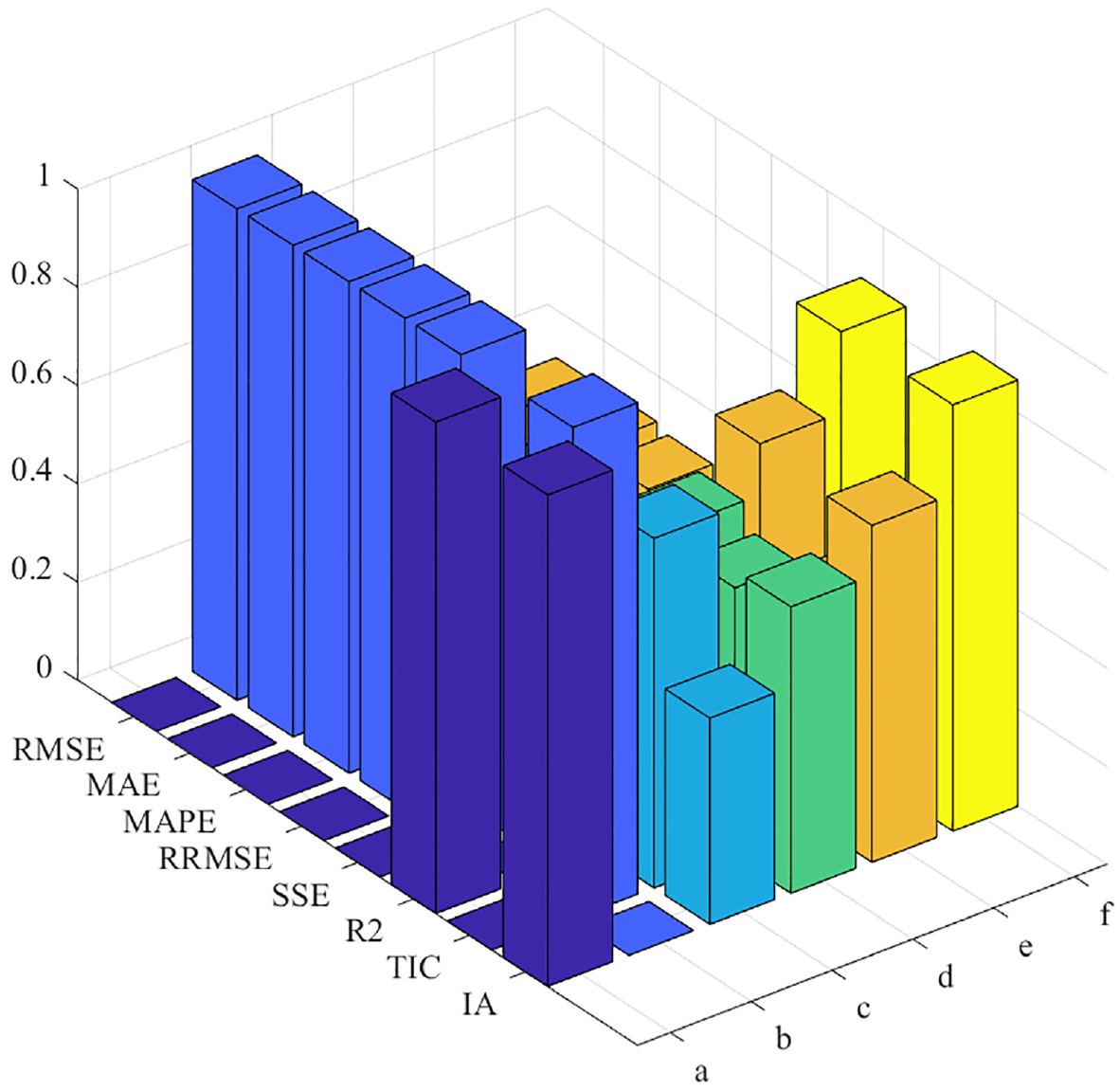
For the performance indicators used, the comparison results of dataset 1 are shown in Table 5. Similarly, the comparison results of dataset 2 are shown in Table 6. According to Table 5, it can be observed that the RMSE, MAE, MAPE, RRMSE, SSE, and TIC performance indicators of the proposed prediction model are all lower than the corresponding comparison models. Meanwhile, the IA and R2 of the proposed model are closer to 1. Overall, the proposed model has significant advantages in both prediction performance and fit. By observing Table 6, it can be seen that the performance indicators of the proposed prediction model also have advantages. Therefore, these performance indicators can prove that the proposed prediction model is an effective solution to the short-term wind power prediction problem.
Comparison of performance indicators of each model (dataset 1).
Comparison of performance indicators of each model (dataset 2).
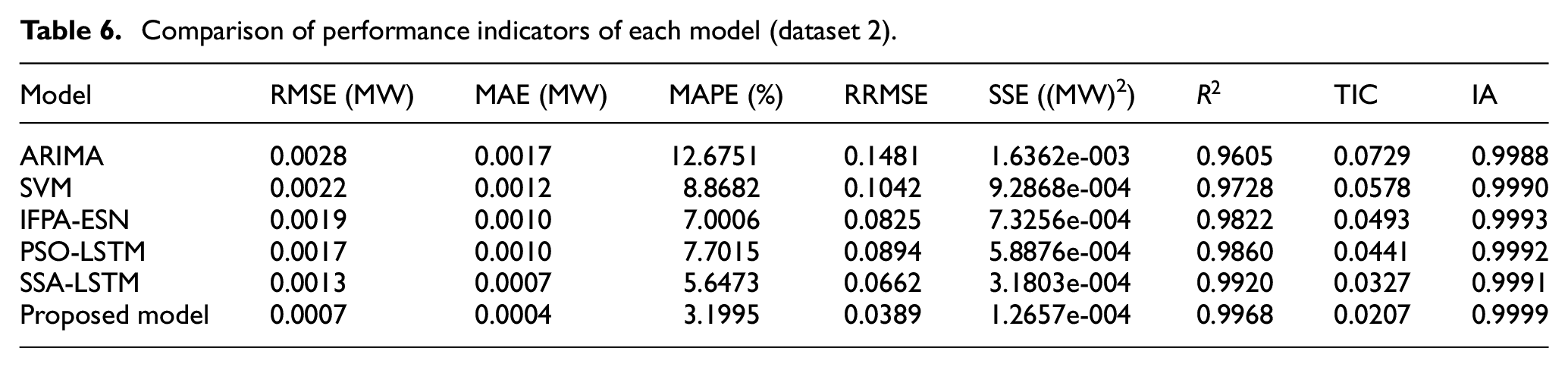
For a more intuitive comparison, Figures 12 and 13 show a comparison of the performance indicators of these prediction models (for the convenience of display, all performance indicators have been normalized to [0, 1]). Based on the above results in Tables and Figures, it can be concluded that the proposed ISSA-LSTM has better specific performance.

Performance indicators of each model for dataset 1 ((a) proposed model, (b) ARIMA, (c) SVM, (d) IFPA-ESN, (e) PSO-LSTM, and (f) SSA-LSTM).
Performance indicators of each model for dataset 2 ((a) proposed model, (b) ARIMA, (c) SVM, (d) IFPA-ESN, (e) PSO-LSTM, and (f) SSA-LSTM).
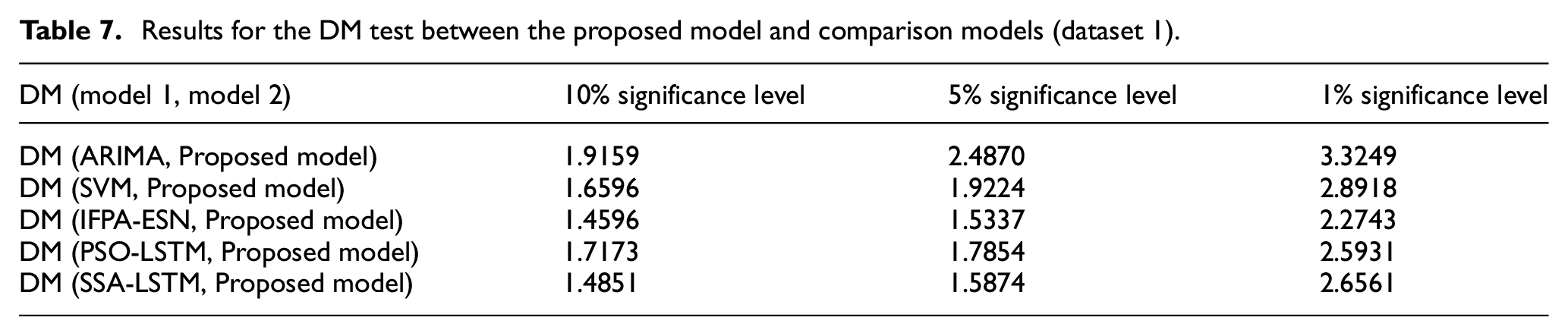
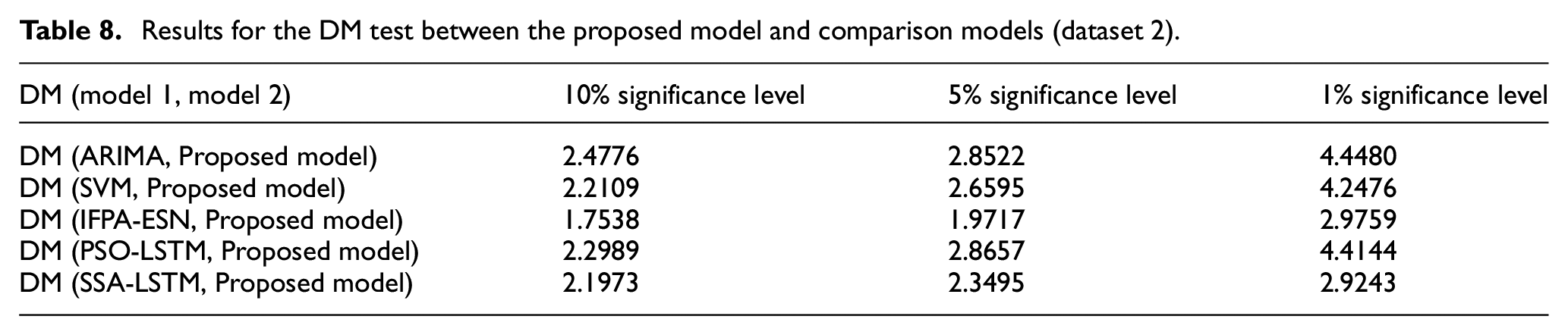
The DM test values of these prediction models with three typical significance levels are calculated and listed in Tables 7 and 8. From the results in Tables 7 and 8, it can be seen that the DM test values between the proposed prediction model and other models are all greater than 0. From this, it can be concluded that the proposed predictive model is significantly superior to other predictive models at different levels of significance.
Results for the DM test between the proposed model and comparison models (dataset 1).
Results for the DM test between the proposed model and comparison models (dataset 2).
The training and prediction times of each model for two datasets are shown in Table 9 (conducted 20 experiments and took the mean as the result). The configuration information of the simulation computer is as follows: CPU is Intel(R) Core(TM) i5-7300HQ CPU @ 2.50 GHz(2501 MHz), Memory is 8.00 GB (2400 MHz), Graphics card is NVIDIA GeForce GTX 1050 (4095 MB), simulation software is Matlab with version 2018b, operating system is Microsoft Windows 10 professional edition (64 bit). From the Table 9, it can be seen that PSO-LSSVM has the longest training time, followed by IFPA-LSTM, SSA-LSTM, and the time of the model in this paper is relatively close. The ARIMA model has the shortest time, followed by SVM. Although the training time of SVM and ARIMA is less than that of the proposed model, the prediction accuracy is far inferior to the proposed model. Although IFPA-LSTM and SSA-LSTM have certain advantages in terms of time consumption, their fitting degree with the true value curve is poor, and their stability is not as good as the model proposed in this paper. Although the model proposed in this article has a slightly longer prediction time, it fully meets the requirements compared to the sampling period and achieves good prediction results. For predicting time, there is not much difference among all models.
Training and prediction time of each model.

Based on the data fitting curve, prediction error, performance indicators, DM test, and the time required for the model, it can be seen that the proposed model has achieved the best prediction results compared to other models, proving that the proposed model is reliable and effective.
Conclusions
A prediction model was proposed and validated for short-term wind power prediction in this paper. An improved LSTM model has been proposed. Compared with traditional LSTM, each gate of the new LSTM can “peek” at the unit state, improving prediction accuracy. On the basis of the standard SSA, an ISSA is proposed by combining various strategies such as Cauchy mutation optimization, opposition-based learning and dynamic weighting to optimize the hyper-parameters of the LSTM network. Predict short-term wind speed through optimized LSTM. The performance of the model is validated through two sets of actual collected short-term wind power data. Compared with other models, multiple validation methods have demonstrated the excellent performance of the proposed prediction model, which is very suitable for practical wind farms.
Although the ISSA algorithm obtained the optimal hyper-parameters of LSTM in the experiment, which further improved the prediction results, there is still a problem of wasting a lot of time in the optimization process of the ISSA. In the future, reasonable trade-offs should be made or SSA should be further improved to seek a reasonable balance between computation time and prediction accuracy.
Footnotes
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This paper is supported by the Science Research Project of Liaoning Education Department (No. LJKZ0145).
Data availability statement
The data used to support the results of this study can be obtained from the corresponding author