
Abstract
Objects rarely appear in isolation in natural scenes. Although many studies have investigated how nearby objects influence perception in cluttered scenes (i.e., crowding), none has studied how nearby objects influence visually guided action. In Experiment 1, we found that participants could scale their grasp to the size of a crowded target even when they could not perceive its size, demonstrating for the first time that neurologically intact participants can use visual information that is not available to conscious report to scale their grasp to real objects in real scenes. In Experiments 2 and 3, we found that changing the eccentricity of the display and the orientation of the flankers had no effect on grasping but strongly affected perception. The differential effects of eccentricity and flanker orientation on perception and grasping show that the known differences in retinotopy between the ventral and dorsal streams are reflected in the way in which people deal with targets in cluttered scenes.
Keywords
In the laboratory, the presence of flanking objects has been shown to interfere with the ability to identify the features of a target presented in the periphery of the visual field. This phenomenon is called the crowding effect (Levi, 2008; Whitney & Levi, 2011). But crowding is not limited to the laboratory. In the real world, objects rarely appear in isolation, and crowding in cluttered scenes is an integral part of everyday life.
In crowded arrays, the features of the target and the flankers become mixed or averaged (Parkes, Lund, Angelucci, Solomon, & Morgan, 2001). The strength of the crowding effect depends on many factors, including the distance between flankers and target, the number of flankers, and their eccentricity (Chen et al., 2014; Levi, 2008; Whitney & Levi, 2011). Crowding can render a specific feature of the target “invisible”; that is, observers cannot identify the feature (He, Cavanagh, & Intriligator, 1996) even though they know the target is there (Liu, Jiang, Sun, & He, 2009).
Crowding has been considered a bottleneck for object recognition (Levi, 2008; Whitney & Levi, 2011). But vision is not only important for object recognition; it also plays a critical role in the control of object-directed actions such as reaching and grasping. Therefore, it is important to investigate how crowding influences actions directed toward a target. Does the effect of crowding on visually guided action simply reflect its effect on visual perception? There are reasons to believe that this might not be the case.
According to the influential two-visual-systems account (Goodale & Milner, 1992), visual perception of the world is mediated by the ventral stream projecting from early visual areas to the inferotemporal cortex, whereas the control of skilled actions is mediated by the dorsal stream projecting from early visual areas to the posterior parietal cortex. There are several critical differences in the functional organization of the ventral and dorsal streams. A recent neuroimaging study, for example, demonstrated that when a stimulus is made invisible by flash suppression, object-related activation is still present in the dorsal but not the ventral stream (Fang & He, 2005). Thus, one might expect that if a particular object feature were to be made perceptually invisible, the “unseen” feature could still modulate actions directed toward that object. In addition, some areas in the dorsal and ventral streams have clear differences in their retinotopic organization. For example, the fovea is overrepresented in areas of the ventral stream implicated in object recognition (Malach, Levy, & Hasson, 2002), whereas the entire visual field is more evenly represented in some action-related areas of the dorsal stream (Colby, Gattass, Olson, & Gross, 1988). Thus, if perceptual report depends more on the ventral stream and visual control of action depends more on the dorsal stream, one might expect that the spatial layout of a display would affect perception and action differently.
We tested these predictions in a series of experiments in which participants were presented with a 3-D target shown in the far periphery either in isolation (uncrowded) or surrounded by 3-D flanking objects (crowded). In Experiment 1, we examined whether or not participants could use “invisible” size information induced by crowding to guide their grasping. In Experiments 2 and 3, we examined how the eccentricity of the display and the orientation of the flankers influence the effects of crowding on grasping and perceptual estimation of target size.
Method
Participants
Ten participants (5 males, 5 females) took part in Experiment 1. Additional groups of 12 participants took part in Experiment 2 (6 males, 6 females) and Experiments 3a (3 males, 9 females) and 3b (6 males, 6 females). Previous studies in our laboratory and others have shown that 10 to 14 participants provide sufficient power for comparing visual perception with action measures (Aglioti, DeSouza, & Goodale, 1995; Binsted, Brownell, Vorontsova, Heath, & Saucier, 2007). Some of the participants took part in more than one experiment. All were right-handed and had normal or corrected-to-normal vision. Their ages ranged from 18 to 35 years. In all experiments, participants gave informed consent. The experiments were approved by the University of Western Ontario Ethics Review Board.
Apparatus and stimuli
In all the experiments, the stimuli were white plastic disks with diameters ranging from 2.25 cm to 4.75 cm, in 0.25-cm increments (11 disks in total). The thickness of the disks was 1 cm. The target disk was presented on a black table either in isolation (uncrowded) or surrounded by flankers (crowded; Fig. 1a). The flankers were randomly chosen from the remaining disks. All flankers were fixed on the table with Velcro. Only the target was movable. The target was raised 0.5 cm higher with a black foam pad, so that participants would not worry about bumping into the flankers. The layout of the stimuli varied across the experiments.
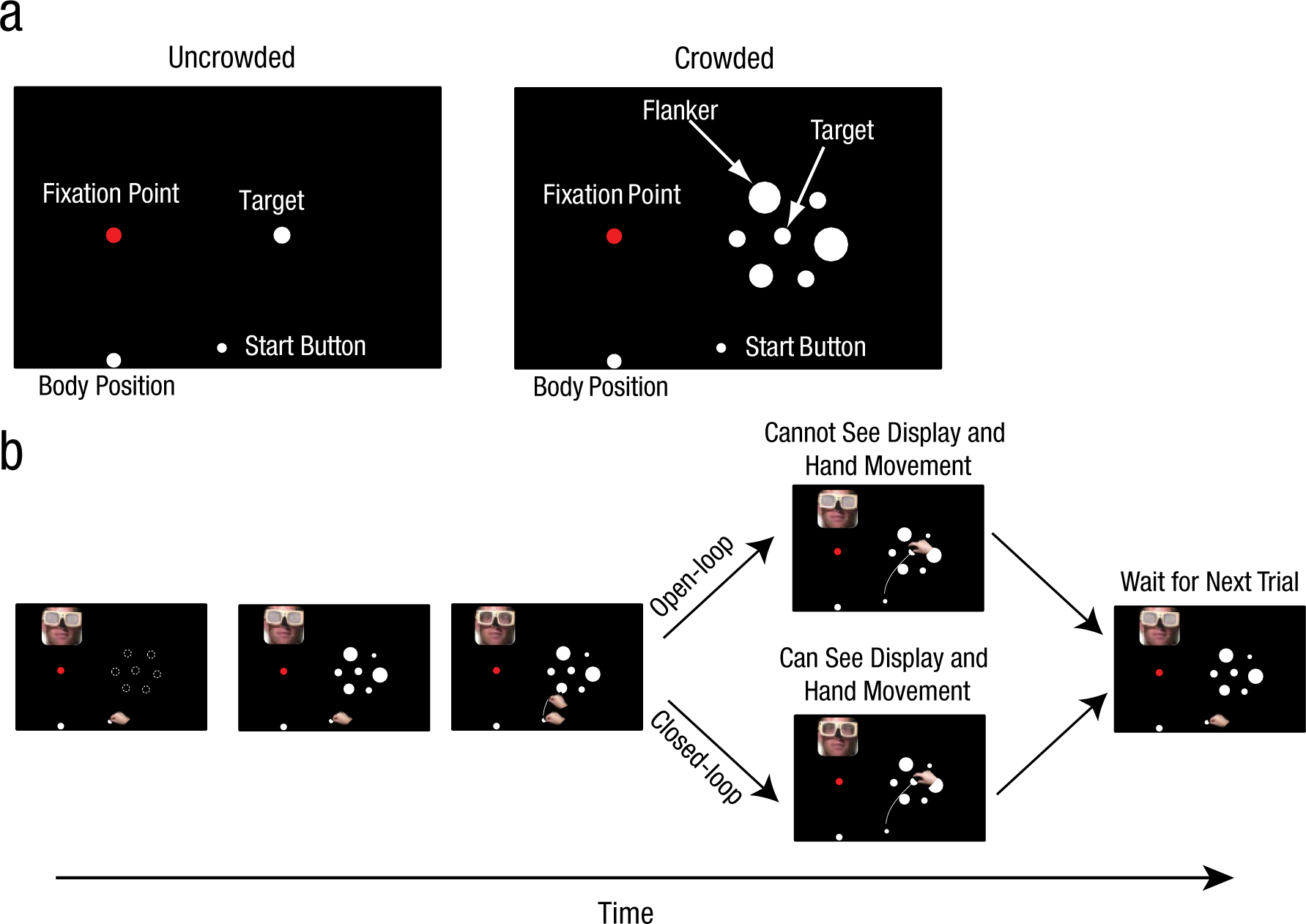
Illustration of the (a) layout and (b) procedure used in Experiment 1. In the uncrowded condition, a white target disk was presented in isolation. In the crowded condition, the disk was surrounded by other disks (flankers). At the start of each trial, the participant held down the start button, and the liquid-crystal goggles were closed. After the disks were placed on the table, the goggles opened, and the participant either reached out to grasp the target (shown here) or estimated its size manually. The insets showing the participant’s head indicate the status of the goggles at each stage of the procedure. On open-loop trials, the goggles closed as soon as the participant released the start button; on closed-loop trials, the goggles remained open for 3 s. The dashed circles in the diagram at the far left in (b) indicate the positions of the flankers and targets on all trials; the size of the flankers and the target varied from trial to trial. Only one example of a display is shown here.
Participants were seated in front of the table with their heads stabilized by a chin rest. They wore liquid-crystal goggles (PLATO goggles; Translucent Technologies, Toronto, Ontario, Canada) throughout the experiments so that we could control the visibility of the display and their moving hand. A start button was located 15 cm from the edge of the tabletop facing the participants. The 3-D positions of the fingers of the right hand were tracked with an OPTOTRAK system (Northern Digital, Waterloo, Ontario, Canada), with the infrared light-emitting diodes (IREDs) attached to the right corner of the thumbnail and the left corner of the index finger. The sample rate was 200 Hz.
Procedure and design
At the beginning of each trial, the goggles were closed (Fig. 1b). Participants held down the start button with the thumb and index finger pinched together. After the target disk (uncrowded condition) or target plus flanker disks (crowded condition) had been placed on the table, the goggles were opened. On action trials, participants were required to reach out and pick up the target disk with their thumb and index finger as quickly and as accurately as possible (grasping task). The OPTOTRAK was triggered as soon as the goggles were opened to record the entire grasping movement. On perceptual trials, participants were required to indicate the size of the target disk manually by opening their thumb and index finger a matching amount (manual estimation task). When participants signaled that they were satisfied with their estimate, the experimenter triggered the OPTOTRAK to record the data. We had participants pick up the disk after they had made their estimate to ensure that they had the same haptic feedback about the size of the target on perceptual trials as they did on action trials (Haffenden & Goodale, 1998).
On some trials, the goggles were closed as soon as the start button was released (open-loop), so that participants could not see their moving hand or the disks during the execution of the movement. On other trials, the goggles were closed 3 s after participants released the button (closed-loop), which permitted a full view of the moving hand and the target (Fig. 1b). Because participants could see their movements during the execution of the movements on closed-loop trials, they could adjust the initial programming of their grip aperture on the basis of on-line visual feedback. In contrast, because participants received no on-line feedback during open-loop trials, only the initial programming on the basis of visual information available before the movement began could influence their grip aperture. We included both open- and closed-loop conditions in Experiment 1 to investigate whether the availability of on-line visual feedback made any difference to the results. Only open-loop trials were included in the other experiments.
In Experiment 1, the fixation point was positioned directly in front of participants. The distance from their eyes to the fixation point was 45 cm. The target was either 3.00 cm or 3.75 cm in diameter and was presented along the horizontal meridian at an eccentricity of 30° to the right. There were six flankers located on the six corners of an imaginary hexagon with the target in the center (Fig. 1a). The center-to-center distance between flankers and target was 6.5 cm. There were 16 combinations of conditions and target sizes: 2 crowding conditions (crowded or uncrowded) × 2 tasks (grasping or manual estimation) × 2 viewing conditions (closed or open loop) × 2 target sizes (3.0 cm or 3.75 cm); each combination was presented 10 times (160 trials in total). Grasping trials and manual estimation trials were presented in two separate blocks each, with 40 experimental trials per block. Eight additional trials with two other target sizes (2.5 cm and 4.25 cm) were randomly interleaved with the 40 experimental trials in each block. Data from these additional trials were not analyzed; they were included to prevent participants from memorizing the two target sizes for which the data were analyzed. Experiment 1 consisted of 192 trials in total.
In Experiment 2, the stimulus display was in the same position (along the horizontal meridian), but the position of the fixation point was varied to manipulate the eccentricity of the display (Fig. 2a). The distance from participants’ eyes to the fixation point was 49 cm in the 20° eccentricity condition and 50 cm in the 10° and 30° eccentricity conditions. The target varied in size: 2.5 cm, 2.75 cm, 3.0 cm, 3.25 cm, or 3.5 cm in diameter. Five flankers surrounded the target. The center-to-center distance between flankers and target was 6.5 cm, as in Experiment 1. There were 60 combinations of conditions and target sizes (2 crowding conditions × 2 tasks × 3 eccentricities × 5 target sizes); each combination was presented five times, for a total of 300 trials. Trials for different eccentricities were blocked separately to avoid eye movements between trials.
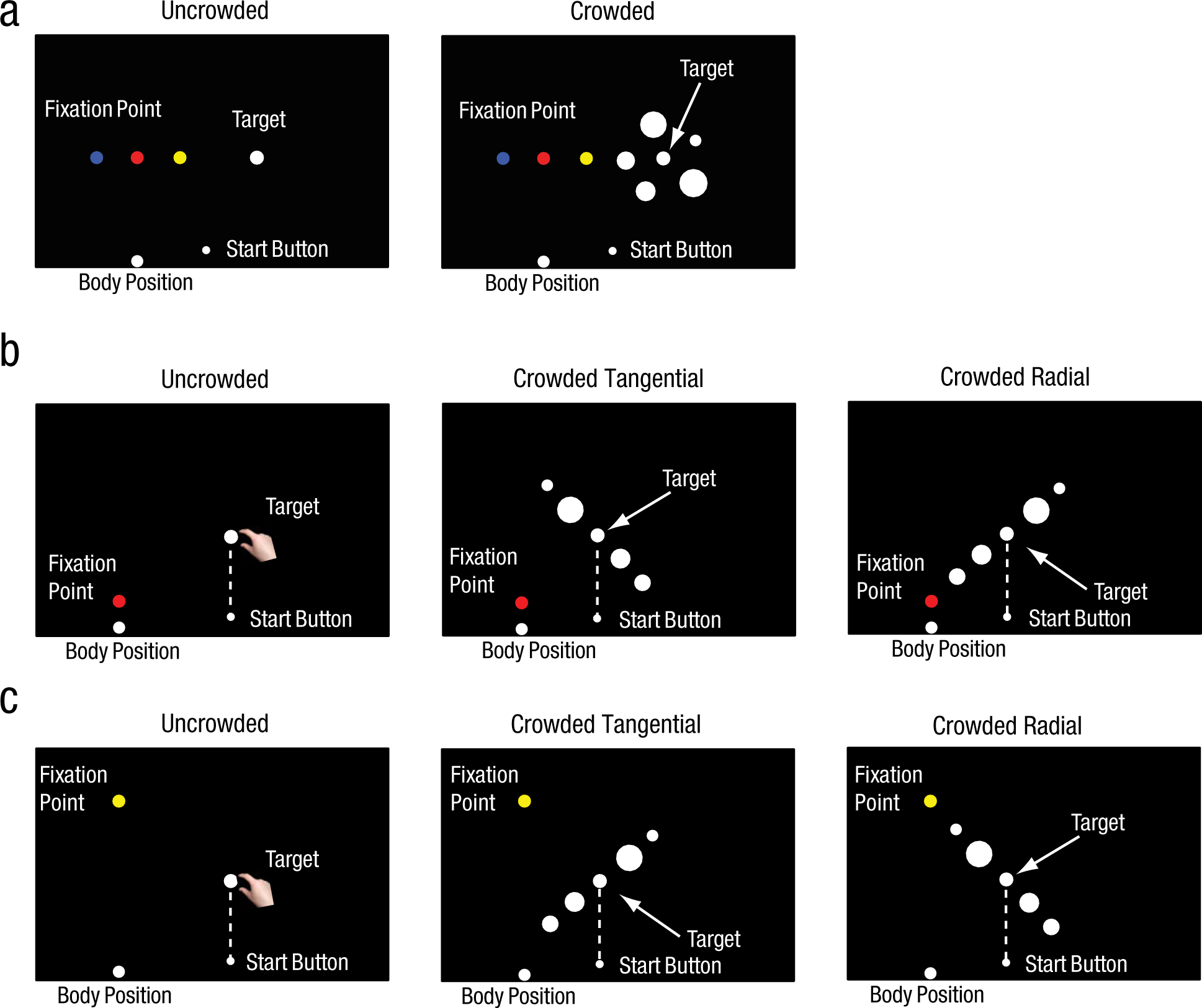
Illustration of the displays used in the uncrowded and crowded conditions of (a) Experiment 2, (b) Experiment 3a, and (c) Experiment 3b. In Experiment 2, the eccentricity of the displays was varied by moving the fixation point to different positions (yellow: 10° eccentricity; red: 20° eccentricity; blue: 30° eccentricity). In the crowded conditions of Experiment 3a, the flankers and target were either tangentially or radially positioned relative to the fixation point (red dot). In Experiment 3b, the fixation dot was moved (yellow dot) so that the tangential arrangement of Experiment 3a became the radial arrangement in Experiment 3b, and vice versa. The dashed lines in (b) and (c), which were not actually present in the displays, are included here to show that the target was positioned right in front of the start button.
In Experiments 3a and 3b, the flankers were oriented either radially or tangentially with respect to the fixation point. In the radial arrangement, the flankers were positioned on both sides of the target along a line extending from the fixation point through the target; in the tangential arrangement, the flankers were positioned on both sides of the target along a line that was perpendicular to the radial orientation. The target diameters were 2.5 cm, 2.75 cm, 3.0 cm, 3.25 cm, or 3.5 cm, as in Experiment 2. Only four flankers were used. The distance between adjacent disks (i.e., between the target and an adjacent flanker or between adjacent flankers) was 5.5 cm. In Experiment 3a, the target was placed at an eccentricity of 20° in the upper visual field (Fig. 2b). In Experiment 3b, the display remained in the same position, but the fixation point was moved above the display, so that the display was at an eccentricity of 17° in the lower visual field (Fig. 2c). The distance from the eyes to the fixation point was 39 cm in Experiment 3a and 46 cm in Experiment 3b. In both experiments, there were 30 combinations of conditions and target sizes: 3 stimulus conditions (uncrowded, crowded tangential, or crowded radial) × 2 tasks × 5 target sizes; each combination was presented six times, for a total of 180 trials.
In all experiments, perceptual trials and action trials were presented in different blocks, and the order of these blocks was randomized across participants. The crowded and uncrowded trials were presented in random order within each block of perception or action trials. All participants were given 10 to 30 min of training before the real experiment so that they could control their eye movements and get used to the tasks.
To make sure that participants were fixating properly, we opened the goggles before each block of trials and gave participants time enough to adjust their head orientation so that when the goggles were opened in the experiment itself they would be looking directly ahead at the fixation point. Then we asked them to maintain fixation and keep their head still throughout the block even when the goggles were closed. This fixation procedure was practiced before they started the main experiments. We confirmed that participants could remain fixated properly by asking them periodically during the experiments whether or not they had to refixate after the goggles were open. They reported no difficulty in maintaining fixation. Eye movements were visually monitored by means of a video camera in the practice phase, but not in the main experiments because the experimenter was preparing to place disks on the table. As participants saw the fixation point before the goggles were closed and could remember the position of the fixation point relative to their head position, they could maintain their gaze on the fixation point reasonably well (as revealed by the video camera in the practice phase), as long as they kept their head still. We confirmed that this was the case by recording the eye movements of an additional group of naive participants while they performed the tasks under the same conditions as in Experiment 1 (see Control Experiment 1 and the accompanying videos in the Supplemental Material available online).
Data collection and analysis
On perceptual trials, the distance between the IREDs on the index finger and thumb was recorded as soon as participants indicated that they were satisfied with their estimate. On action trials, the distance between the two IREDs was recorded throughout the entire movement. The peak grip aperture (PGA) during the approach to the object was extracted. PGA occurs well before the fingers make contact with the target object, is typically scaled to the size of that object, and is programmed before the movement begins (Jeannerod, 1986).
In Experiment 1, the manual estimates and the PGAs were averaged for each condition, for each target size, and for each individual. A four-way repeated measures analysis of variance (ANOVA) was used to analyze the main effects of crowding condition, viewing condition, task, and target size, as well as their interactions. Post hoc paired t tests (two-tailed) were also used to examine whether the manual estimates or PGAs differed significantly between the 3.0-cm and 3.75-cm targets. In Experiments 2, 3a, and 3b, the Pearson’s product-moment correlations between target sizes and manual estimates and between target sizes and PGAs were calculated for each participant. We then transformed all the correlation values to Fisher Z scores to perform statistical analyses. To quantify the influence of crowding at various eccentricities (10°, 20°, or 30°) in Experiment 2 and along different directions (radial or tangential) in Experiment 3, we normalized the Fisher Z scores for both manual estimates and PGAs against the scores in the corresponding uncrowded conditions: normalized Fisher Z = (Fisher Z in crowded condition)/(Fisher Z in uncrowded condition). We also conducted regression analyses on the same data (see the Supplemental Material for details). Because the slopes of the regression lines and the correlation coefficients revealed the same pattern of results, only correlation coefficients are reported here.
Results
Effects of crowding on perception and action
Experiment 1 was designed to explore the effects of crowding on perception and action, with a particular focus on whether participants could scale their grip aperture to the size of the target even when they could not consciously identify the size of the target. We carried out a four-way repeated measures ANOVA on the manual estimates and PGAs with task (estimation vs. grasping), crowding condition (uncrowded vs. crowded), viewing condition (closed- vs. open-loop), and target size (3.0 vs. 3.75 cm) as main factors. The significant interaction between task and crowding condition, F(1, 9) = 6.818, p = .028, suggested that crowding had different effects on performance of the grasping and manual estimation tasks. Not surprisingly, when the target was presented in isolation, participants were able to manually estimate the sizes of the two targets—and this was true for both closed-loop trials, t(9) = 7.23, p < .001, and open-loop trials, t(9) = 9.19, p < .001. Similarly, participants showed excellent grip scaling for targets presented in isolation on both closed-loop trials, t(9) = 4.29, p = .002, and open-loop trials, t(9) = 4.79, p = .001 (Fig. 3).
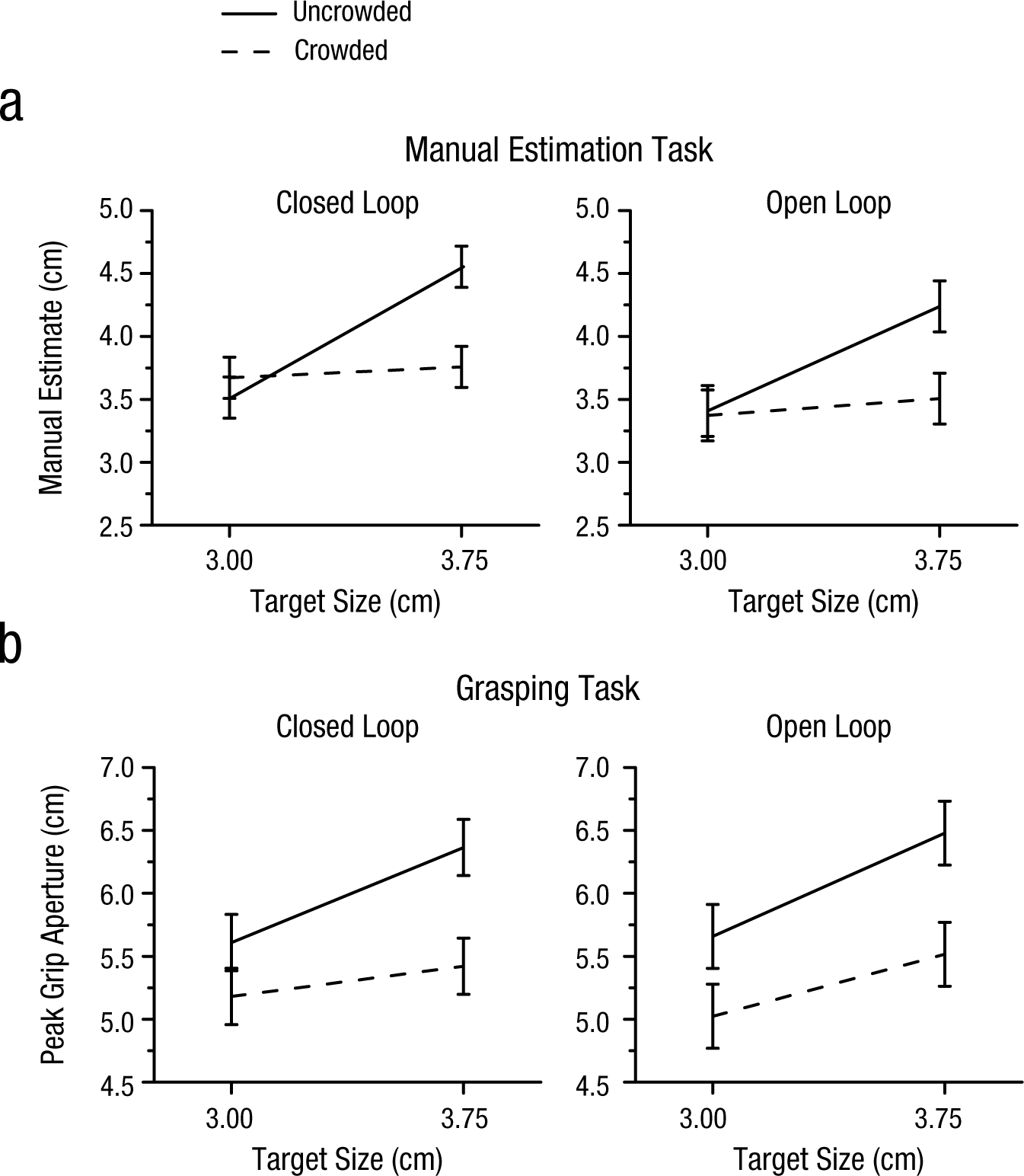
Results of Experiment 1: (a) mean manual estimates of target size and (b) mean peak grip apertures in the uncrowded and crowded conditions as a function of target size. Results are shown separately for the closed-loop (left column) and open-loop (right column) conditions. Error bars represent within-subjects 95% confidence intervals (Masson & Loftus, 2003).
Things were quite different, however, when the target disks were surrounded by flankers. In this condition, participants could no longer discriminate between the two disk sizes using a manual estimate—closed-loop trials: t(9) = 1.02, p = .334; open-loop trials: t(9) = 1.78, p = .108—presumably because the size of the target was perceptually invisible. (Note that we use the term invisible to refer to the fact that participants could not identify the size of the target, even though they were aware of its presence and position.) In contrast, when participants were asked to grasp the same targets, their PGAs were still scaled to target size—closed-loop trials: t(9) = 4.21, p = .002; open-loop trials: t(9) = 3.392, p = .008 (Fig. 3). This suggests that information about target size was still processed to guide grasping even when that information was perceptually invisible. In other words, grasping appeared to escape the effects of perceptual crowding, to some degree. It should be noted that the difference between the effects of crowding on grasping and manual estimation cannot have been due to differences in haptic feedback between the two tasks. As we mentioned earlier, participants were instructed to pick up the targets after they made their manual estimates. Therefore, the opportunity to use haptic feedback was available in both tasks.
Although participants could still scale their grip aperture when the size of the target was perceptually inaccessible, this does not mean that crowding had no effect whatsoever on grasping. The PGAs were smaller when the target was crowded than when it was presented in isolation, as demonstrated by the downward shift in overall PGA for crowded targets compared with uncrowded targets in both the closed- and open-loop conditions (see Fig. 3b). We suspect that the reason for this downward shift is that the flankers, which were real 3-D objects, were treated by the visuomotor system as obstacles.
To further explore the extent to which grip scaling was affected by crowding, for each participant we computed the slopes of the functions describing the relation between target size and PGA. We then compared the slopes for the uncrowded and crowded displays in both the open- and closed-loop conditions. In the closed-loop condition, the mean slopes for the uncrowded and crowded conditions were 1.007 and 0.319, respectively. In the open-loop condition, the mean slopes for the uncrowded and crowded conditions were 1.095 and 0.657. Thus, there was a large reduction in slope in the crowded condition compared with the uncrowded one (closed-loop: 68.34%; open loop: 40.00%). In both cases, the reduction in slope was significant—closed-loop condition: t(9) = 3.59, p = .006; open-loop condition: t(9) = 2.77, p = .022. The reduction in slope in the crowded condition could have been due in part to the possibility (noted earlier) that the flankers were treated as obstacles. The presence of obstacles might be expected to affect grasps directed at a larger object more than grasps directed at a smaller one. This remains only a speculation, however. In any case, it is important to emphasize that grip scaling was still present in the crowded condition; that is, the slope was significantly greater than zero.
The main effect of viewing condition was not significant, F(1, 9) = 2.144, p = .177, which suggests that visual feedback (or on-line adjustment) was not a critical factor. In other words, the inclusion of visual feedback did not improve the participants’ performance. They showed grip scaling in the crowded condition even when they programmed their responses entirely on the basis of visual information that was available before the movement began. Because the open-loop condition has the advantage of reducing the possibility of participants making saccades toward the display to gather more information during the execution of the grasping movement, we decided to use only open-loop trials in Experiments 2, 3a, and 3b.
Effects of eccentricity on perception and action under crowded conditions
Previous results have shown that the effect of crowding on perception increases with the eccentricity of the display (Levi, 2008; Whitney & Levi, 2011). In Experiment 2, we examined whether eccentricity also influences the effect of crowding on action. Eccentricity was varied by moving the fixation point closer to or further away from the stimulus display (Fig. 2a), while keeping the positions of the participants, start button, and stimulus display constant. We decided to move the fixation point, instead of the stimulus display, to make sure that the relative positions of the body, hand, and target were identical despite the changes in retinal eccentricity of the displays. This ensured that the biomechanical requirements for grasping in the three eccentricity conditions were identical. For all eccentricity conditions, we measured participants’ manual estimates and PGAs when the target was presented either in isolation or crowded by flankers. To better measure participants’ estimation and grasping abilities, we used five target sizes and calculated the correlations between the actual sizes and manual estimates on perceptual trials and between the actual sizes and PGAs on action trials. The higher the correlation, the better the estimation or grasping ability. The raw correlation values were converted to Fisher Z scores so that they could be linearly compared with each other and analyzed with the Z statistic (Fisher, 1915, 1921).
The left graph in Figure 4 shows the Fisher Z scores for all combinations of conditions. In the uncrowded condition, the correlations of both PGA and manual estimation with target size were high and did not decrease dramatically with eccentricity of the target. In the crowded condition, however, the correlations for the estimation task decreased sharply, to almost zero; in contrast, the correlations for grasping decreased just slightly. Because our goal was to explore the influence of crowding at different eccentricities, we normalized the Fisher Z score for each eccentricity in the crowded condition against the corresponding score in the uncrowded condition, to rule out a general influence of eccentricity on participants’ ability to estimate target size or scale their grasp even under uncrowded conditions. In other words, we wanted to isolate the effect of eccentricity on crowding in each case. All statistical analyses were performed on the normalized results (Fig. 4, right graph). A two-way repeated measures ANOVA with task (estimation vs. grasping) and eccentricity (10° vs. 20° vs. 30°) as main factors revealed a significant interaction, F(2, 22) = 4.57, p = .022. This suggested that the effects of crowding on grasping and manual estimation were differentially affected by changes in eccentricity. One-way repeated measures ANOVAs on the normalized Fisher Z scores revealed that although eccentricity had a highly significant effect on manual estimates, F(2, 22) = 13.01, p = .000, it had no effect on PGAs, F(2, 22) = 0.340, p = .716. This finding supports the idea that any influence of crowding on grip scaling is not affected by eccentricity.
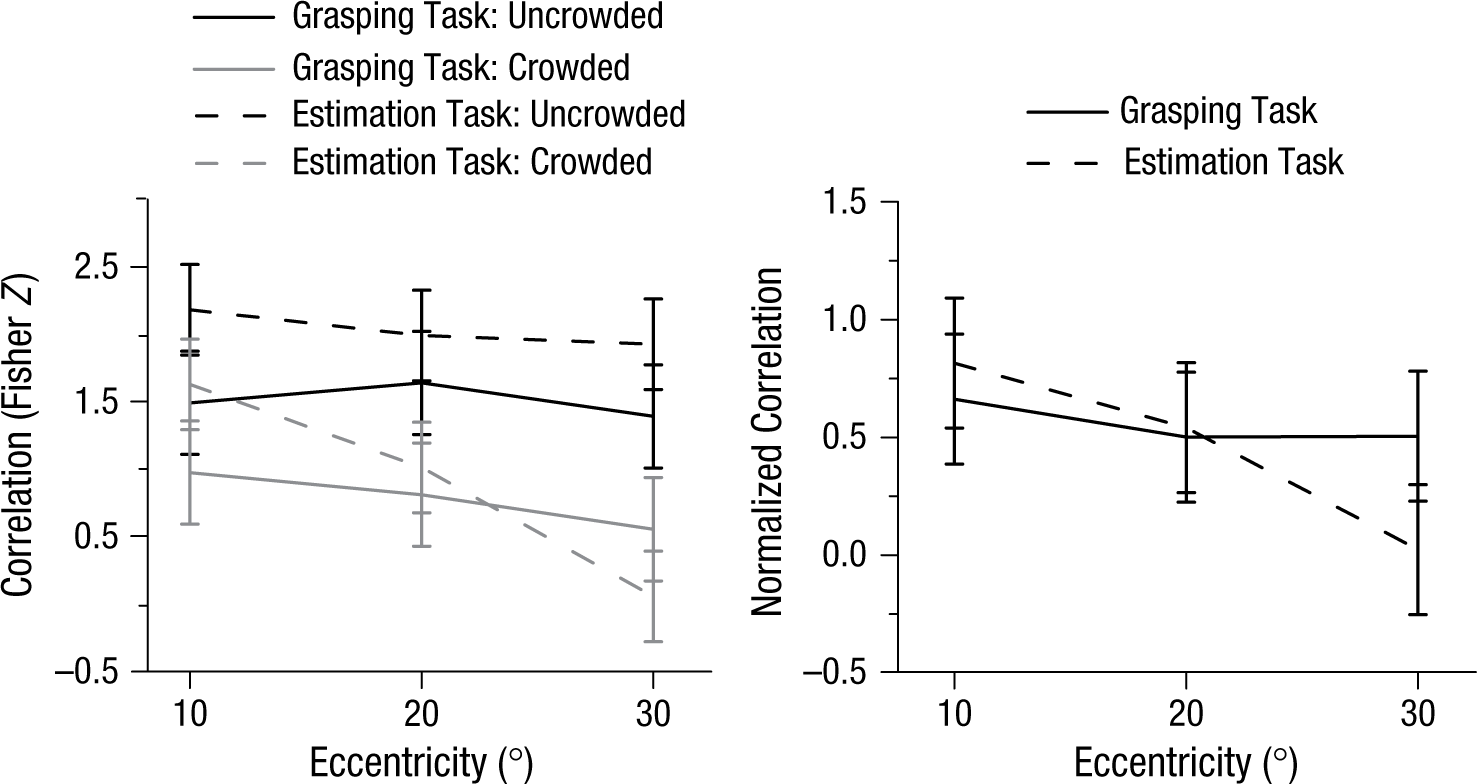
Results of Experiment 2. The panel on the left shows the Fisher Z scores for the correlations between peak grip aperture or manual estimation and target size as a function of eccentricity, separately for the crowded and uncrowded conditions. The panel on the right shows the Fisher Z scores for grasping and manual estimation in the crowded condition normalized against Z scores in the uncrowded condition. Error bars represent within-subjects 95% confidence intervals (Masson & Loftus, 2003).
The normalized Z scores (Fig. 4) indicate that the strength of the correlations between PGA and target size for the crowded displays was 50% to 66% of the strength of the correlations for the uncrowded displays.
Effects of flanker orientation on perception and action under crowded conditions
Another well-established property of perceptual crowding is its radial-tangential anisotropy: The crowding effect induced by flankers that extend along a radial vector from fixation is stronger than the crowding effect induced by flankers that extend along a tangential vector (Toet & Levi, 1992). In Experiments 3a and 3b, we tested whether this radial-tangential anisotropy is also evident in the effects of crowding on action. The target was presented either in isolation or with flankers that were placed along a vector with either a radial or a tangential orientation relative to fixation (Figs. 2b and 2c). As in Experiment 2, five target sizes were used. The correlations between the actual sizes of the targets and the manual estimates and between the actual sizes of the targets and the PGAs were calculated. These correlations were again converted to Fisher Z scores.
To reduce the possibility that the fingers of the grasping hand might be more likely to collide with the flankers in one display orientation than the other, we instructed participants to pick up each target across its “vertical” axis, which was oriented at 45° with respect to the tangential and radial orientations of the flankers. To make this grasping posture easier for the participants, we moved the start button so that it was always located immediately below the target. Nevertheless, it was still possible that the flankers would be more likely to interfere with grasping when they were arranged in one orientation than when they were arranged in the other orientation. To rule out this possibility, we carried out two experiments. In Experiment 3a, the fixation point was positioned below the display so that the target and flankers were located in the upper visual field (Fig. 2b). In Experiment 3b, the fixation point was moved above the display so that the target and flankers were in the lower visual field (Fig. 2c). Thus, the radial orientation of the target and flankers in Experiment 3a became the tangential orientation in Experiment 3b, and vice versa. These manipulations ensured that the potential effects of radial and tangential arrangements of the flankers on grasping would not be contaminated by biomechanical factors.
For both tasks, the Fisher Z scores for each orientation in the crowded condition were normalized against the corresponding scores in the uncrowded condition to reveal the pure effect of orientation on the strength of the crowding effect. We analyzed these normalized Z scores from Experiment 3a using a two-way repeated measures ANOVA with task (estimation vs. grasping) and flanker orientation (radial vs. tangential) as main factors. This analysis revealed a significant interaction, F(1, 11) = 6.10, p = .031, but no main effects. As in earlier studies (Levi, 2008; Toet & Levi, 1992; Whitney & Levi, 2011), manual estimates were more accurate in the tangential than the radial condition, t(11) = 3.158, p = .009 (Fig. 5a). Remarkably, however, not only did participants show significant scaling of their grip to target size in both the tangential and radial conditions, but also scaling did not differ significantly between the two conditions, t(11) = 1.118, p = .287. In Experiment 3b, manual estimates were more accurate for the tangential than the radial displays, t(11) = 3.169, p = .009 (Fig. 5b). Again, grip scaling was equivalent across these two conditions, t(11) = 0.158, p = .877, and the interaction between task and flanker orientation was significant, F(1, 11) = 4.91, p = .049.
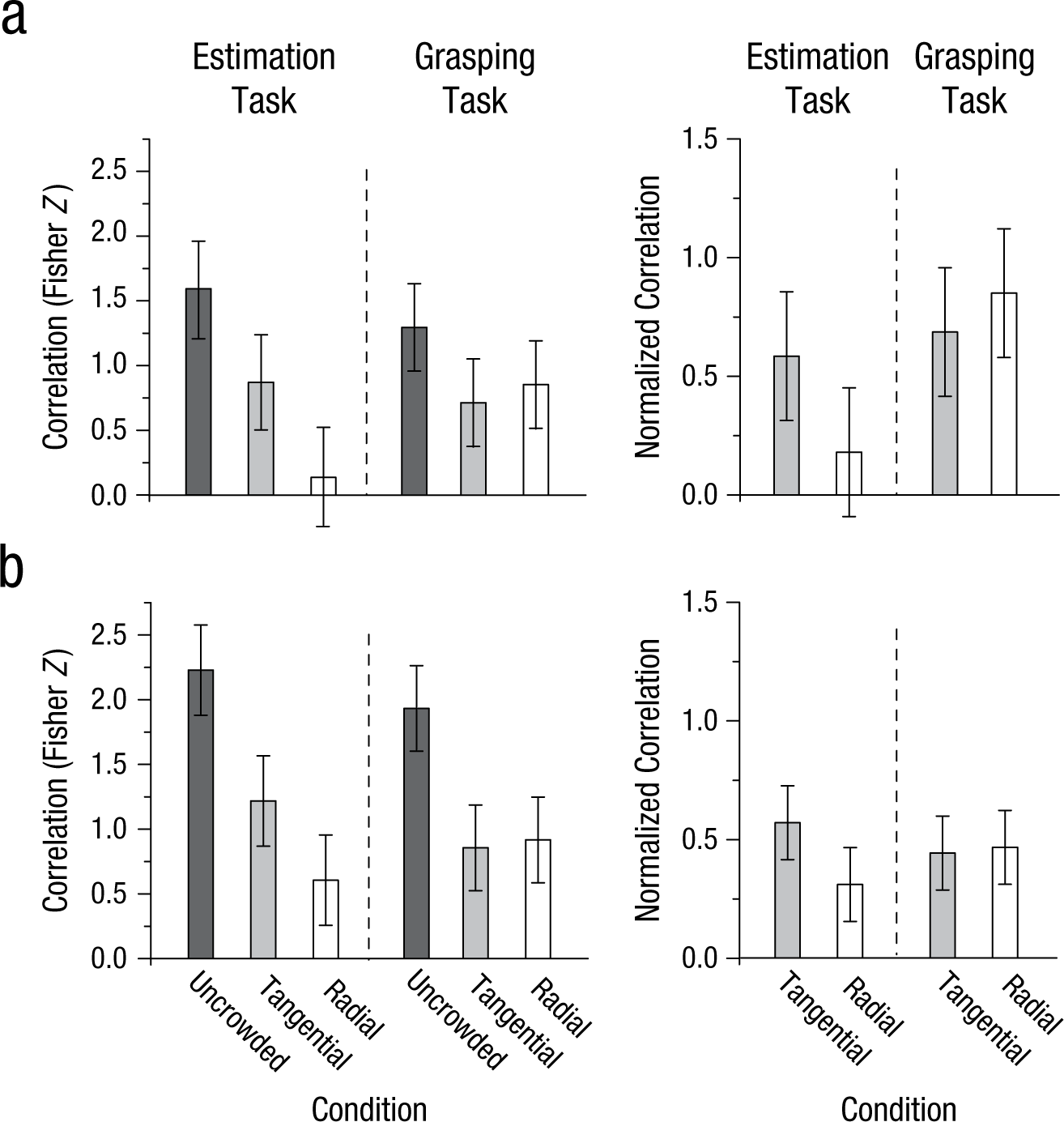
Results of (a) Experiment 3a (stimulus display presented in the upper visual field) and (b) Experiment 3b (stimulus display presented in the lower visual field). The graphs on the left show the Fisher Z scores for the correlations between manual estimation or peak grip aperture and target size in the uncrowded, crowded tangential, and crowded radial conditions. The graphs on the right show the Fisher Z scores for manual estimation and grasping in the crowded condition normalized against Z scores in the uncrowded condition. Error bars represent within-subjects 95% confidence intervals (Masson & Loftus, 2003).
In Experiment 3a, the mean Fisher Z scores for the correlations between PGA and target size in the crowded tangential and radial conditions were 69.7% and 85.0%, respectively, of the corresponding scores in the uncrowded condition (see the normalized correlations in Fig. 5a, right graph). In Experiment 3b, they were 43.1% and 45.6% of those in the uncrowded condition (Fig. 5b, right graph).
Discussion
In this study, we examined how crowding affects visually guided grasping in 3-D scenes. In Experiment 1, we showed that participants scaled their grasp to the size of the target in conditions in which the target’s size was not accessible to conscious report. This result suggests that the visual control of target-directed actions such as grasping can escape the effects of crowding, to some degree. In Experiment 2, we showed that changes in retinal eccentricity that had a significant effect on the visibility of target size had little effect on grip scaling. Finally, in Experiment 3, we showed that the well-known radial-tangential anisotropy that is evident in perceptual crowding (Toet & Levi, 1992) is not present for grip scaling.
In Experiment 1, we found that participants were able to grasp the target using perceptually invisible size information, but this does not mean that crowding had absolutely no effect on grasping. In fact, participants’ grip apertures were smaller overall and the slopes of the functions describing the relation between target size and PGA were somewhat smaller when targets were crowded than when they were presented in isolation. This reduced grip aperture probably reflects a strategy to avoid collision with the flankers (Chapman, Gallivan, Culham, & Goodale, 2011; Voudouris, Smeets, & Brenner, 2012). Nevertheless, the results of Experiment 1 clearly indicate that perceptually invisible information can still be employed to guide action.
In Experiments 2, 3a, and 3b, we were exploring how the eccentricity and the orientation of a display affect grasping, so we did not manipulate visibility of target size. In other words, the target’s size was often visible, but we manipulated the eccentricity and orientation of the display to see how that affected perceptual performance and grasping. We found that as the eccentricity of the display (Experiment 2) and the orientation of the flankers (Experiments 3a and 3b) changed, so did the strength of the crowding effect on perceptual estimates of target size. The strength of the crowding effect on grasping, however, remained constant.
Our study is, to the best of our knowledge, the first systematic study of real actions on 3-D objects in densely cluttered scenes. Although many studies have examined how crowding influences perception, none have examined how crowding influences real action. In an earlier study, Bulakowski, Post, and Whitney (2009) also examined the effects of crowding on both perception and action, but in their visuomotor task, participants pretended to grasp oriented bars presented on a computer monitor. In other words, their action task involved a pantomimed grasp (pretending to grasp bars on the monitor), rather than a real grasp (picking up 3-D objects on a tabletop). There is evidence that the two kinds of grasping engage different processes. For example, compared with pantomimed grasping, real grasping has been shown to be far less sensitive to pictorial illusions and an irrelevant dimension of the target object (Ganel & Goodale, 2003; Ganel, Tanzer, & Goodale, 2008). It has been suggested, therefore, that the visual control of pantomimed grasping engages perceptual processing in the ventral stream, whereas real grasping is mediated by encapsulated visuomotor mechanisms in the dorsal stream (Goodale, 2011; Milner & Goodale, 2006). This may explain why a striking dissociation in the effects of crowding on perception and action was found in our study, but not in the study by Bulakowski et al. To test this possibility, we conducted a screen version of Experiment 1 (i.e., images of 2-D targets and flankers were presented on a screen) and asked participants to pretend to grasp the targets. As found by Bulakowski et al., there was no dissociation between the effects of crowding on perception and action when a pantomimed grasp was employed (see Control Experiment 2 in the Supplemental Material).
In Experiment 1, the participants had no conscious perception of the target’s size—or even where the target stopped and a flanker began. Remarkably, however, even though they could not perceive the size of the target (or its edges), they scaled their grasp reliably when they picked it up. Even when we showed them their own data, several participants could not believe that they were doing so well. It should be noted that this is not simply another demonstration that actions escape visual illusions of size (Aglioti et al., 1995). In size-contrast illusions, people scale their grasp accurately to targets that they believe are larger or smaller than they really are. In other words, the perceptual error concerns the computation of size; the target, the flankers, and their edges are all clearly visible. Crowding, in which a target and flankers are viewed in the far periphery, is a very different situation. Observers cannot distinguish edges of the target from those of the flankers because they are all jumbled together (e.g., Levi & Carney, 2009; Martelli, Majaj, & Pelli, 2005; Pelli, Palomares, & Majaj, 2004). Therefore, our crowding study goes well beyond the previous studies of size-contrast illusions and shows that visual information available only unconsciously can influence actions.
Previous studies have shown that perceptually invisible information can influence actions such as pointing and reaching. For example, Binsted et al. (2007) found that healthy participants modulated movement time in a pointing task as a function of target size—even when the 2-D target was made invisible by object-substitution masking. Similarly, Roseboom and Arnold (2011) found that, after training and feedback, participants could learn to adjust their reaching hand to the orientation of a 2-D stimulus that was made invisible using binocular suppression. Our study, however, is the first to demonstrate that neurologically intact participants can use visual information that is not consciously accessible to scale their grasp to real 3-D objects in real scenes—and that this happens without any explicit training.
How can visual information that is not accessible to conscious report be used to guide actions? Neuroimaging has demonstrated that perceptually invisible stimuli will sometimes activate the dorsal stream independently of the ventral stream (Baseler, Morland, & Wandell, 1999; Fang & He, 2005). Exactly why this occurs is not well understood. There are certainly differences in the way in which retinal input reaches the two streams. Area V1 is the major conduit of visual input into the ventral stream (Girard & Bullier, 1989; Girard, Salin, & Bullier, 1991b; Rocha-Miranda, Bender, Gross, & Mishkin, 1975), which may explain why patients with V1 lesions no longer perceive objects in their affected visual field. In contrast, even though V1 sends major projections to the dorsal stream, visual signals can also reach the dorsal stream via other pathways that bypass V1. Evidence from neurophysiological and anatomical studies of the monkey as well as neuroimaging studies of patients with V1 lesions has shown that some of the signals that bypass V1 involve direct subcortical projections to MT (middle temporal area; Sincich, Park, Wohlgemuth, & Horton, 2004), V3A (Girard, Salin, & Bullier, 1991a), and parieto-occipital structures, such as V6 and V6A (Colby et al., 1988). These extrageniculostriate projections are likely the neural substrates for actions guided by visual information that is not consciously accessible.
In Experiments 2, 3a, and 3b, we showed that although changing display eccentricity and flanker orientation strongly affected perceptual estimation, such changes did not affect grasping. One possible reason for the large effect of eccentricity and flanker orientation on the strength of the crowding effect is the overrepresentation of central vision in V1 (cortical magnification); visual resolution is therefore reduced in the far periphery, and more so along radial than tangential vectors (Levi, 2008; Levi, Klein, & Aitsebaomo, 1985). Moreover, the cortical magnification of central vision in V1 is preserved, and even amplified, in downstream areas of the ventral stream, particularly those involved in object recognition (Malach et al., 2002). There is little evidence for cortical magnification of central vision in areas V6 and V6A, dorsal-stream areas that are thought to play a critical role in the visual control of reaching and grasping (Fattori, Breveglieri, Amoroso, & Galletti, 2004; Galletti, Kutz, Gamberini, Breveglieri, & Fattori, 2003). Area V6 has a relatively isotropic representation of the entire visual field in humans (Pitzalis et al., 2006) and monkeys (Colby et al., 1988), and V6A has an overrepresentation of the far periphery (Galletti, Fattori, Kutz, & Gamberini, 1999). In short, the differential effects of eccentricity and flanker orientation on perception versus grasping follow directly from known differences in the retinotopic organization of the ventral and dorsal streams.
In sum, we have demonstrated that crowding has quite different effects on grasping than it does on perceptual report. This striking difference suggests that visually guided action does not depend solely on conscious visual perception.
Footnotes
Acknowledgements
The authors thank Haitao Yang for his technical assistance.
Declaration of Conflicting Interests
The authors declared that they had no conflicts of interest with respect to their authorship or the publication of this article.
Funding
This work was funded by a Natural Sciences and Engineering Research Council of Canada grant (No. 6313) awarded to M. A. Goodale.
Open Practices
All data have been made publicly available via Open Science Framework and can be accessed at https://osf.io/29ytr/files/?view_only=d544d23261024c1099d7348de61ee990. The complete Open Practices Disclosure for this article can be found at http://pss.sagepub.com/content/by/supplemental-data. This article has received the badge for Open Data. More information about the Open Practices badges can be found at https://osf.io/tvyxz/wiki/view/ and ![]() .
.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.