
Abstract
Visual methodologies for researching organizational life have grown in popularity over the past decade, with conceptual and methodological foundations now well documented. However, analytical critique has not kept pace, and so in this article we offer grounded visual pattern analysis (GVPA) as a rigorous means of analysis that mines the discursive meanings of individual photographs and the visual patterns apparent across multiple still images. We illustrate GVPA’s value through an ethnographic field study investigating the relationship between workplace environments and identity formation among hair salon workers in the United Kingdom. Specifically, we explain how to combine the strengths of both “dialogical” and “archaeological” approaches to visual research, which have hitherto been seen as distinct endeavors. We argue this is particularly valuable in field studies addressing material turns in organization studies, such as studies of space, strategy-as-practice, embodied cognition, and servicescape aesthetics. The article concludes by putting forward a series of potential directions for the future of visual organizational research based on the bridging of Meyer et al.’s five different methodological approaches.
Keywords
Despite much methodological commentary, analytical protocols for the investigation of still, field-study photographs remain underdeveloped (Catalani & Minkler, 2010; Drew & Guillemin, 2014; Prosser & Loxley, 2008; Ray & Smith, 2012). This article follows calls for more sustained consideration of visual analysis issues (Prosser & Loxley, 2008; Ray & Smith, 2012) by asking, “How can organizational researchers generate grounded, robust, and analytically sound findings from their visual field study data?” This is necessary to legitimize visual methods’ use in organization and management research where institutional pressures (such as research quality audits and institutional review boards) increasingly require qualitative techniques to be systematic in order to be regarded as valid (Cassell & Symon, 2012, p. 4). In this article, we use the terms field and field study in an anthropological sense, to refer to the particular empirical context from which data are generated.
Our aim is to critically explicate “grounded visual pattern analysis” (GVPA) as a way to combine the strengths of “dialogic” and “archaeological” approaches to visual analysis (Meyer, Höllerer, Jancsary, & Van Leeuwen, 2013). Dialogic approaches (Meyer et al., 2013, p. 513) are generally valued for their ability to generate rich and extensive verbal or written reflection around the content of field-study photographs and what they symbolize to their photographers. Thus the data generated from dialogic analysis are a textual narrative about the meaning and significance of the photograph—and this meaning is “grounded” in the context in which it was produced (hence the grounded element of GVPA). By contrast, archaeological approaches to visual analysis (Meyer et al., 2013) see the data as being within the image itself—to be mined by researcher(s) for traces of the “sedimented social knowledge” (p. 502) that informed the image’s production. Bringing these two approaches together through GVPA allows us to explore organizational worlds not only by investigating the meanings photographs have for their photographers (either researchers taking photographs during fieldwork, and/or by field-study participants themselves), but by paying attention to the broader field- (sample-) level meanings interpreted from analysis of collections of photographs, which we are calling “image-sets.” A further contribution of this article is therefore the bringing together of hitherto disparate analytical methods in order to deepen and broaden the data it is possible to generate from field-study photographs. 1
The rest of this article proceeds as follows. The next section gives an in-depth explanation of the value of bridging the “dialogic” and “archaeological” approaches to visual materials and explains why we have chosen to combine these particular two of Meyer et al.’s five approaches, before moving to discuss the conceptual underpinnings of GVPA. We then operationalize this methodologically using an empirical example from our own photographic field-study research on the role of organizational space in hairdressers’ experiences of their identities at work (Shortt, 2010, 2015; Shortt & Warren, 2012). We describe how the data from this study were interrogated through GVPA, comprising a dialogic analysis followed by four field-level archaeological analytical activities—(a) grouping, (b) ordering, (c) structured viewing, and (d) theorizing—which together make up GVPA. Finally, we discuss the conceptual significance of GVPA with particular relevance to a variety of material agendas in organization studies and suggest possibilities for alternative bridgings of Meyer et al.’s (2013) visual approaches in relation to a wide range of organizational research topics.
Conceptual Underpinnings for GVPA: Bridging Dialogical and Archaeological Approaches
To show the diverse ways visuals have been conceptualized by business and management researchers to date, Meyer et al.’s (2013, p. 503) article undertakes a comprehensive mapping of the emerging field of visual organization studies by classifying research into five approaches, summarized as follows: Archaeological—using preexisting images to reconstruct underlying meaning structures evident from their visual features Practice—investigating how visual artifacts are a constitutive part of organizational life Strategic—analysis of how images are used by organizations as a means of persuasion Dialogical—the use of images as a means to stimulate discussion about organizational life Documenting—images generated as records/visual field notes, by researchers and/or organizations themselves
After detailed discussion of each approach and its value for organizational research, Meyer et al. (2013) go on to point out the potential for “cross-fertilization between and integration of these approaches…. Much benefit [therefore] lies in such systematic bridging of methodological traditions” (p. 533). Meyer et al.’s article was published at the time we were formulating our GVPA approach, and we were struck by how our emerging ideas fitted into two of their categories (dialogical and archaeological). These categories gave us a language with which to articulate and differentiate the kinds of visual meaning that we recognized in our empirical work with GVPA, and which we expand on further below. We also recognized that GVPA responded to their call for methodological bridging, and as such, this section explains more about the value of this particular combination of approaches in support of the rest of our argument. However, this subsequently led us to speculate on what other “bridgings” might be possible, and we return to this at the end of the article as part of our discussion on future directions for GVPA. For now, we continue with our discussion of the conceptual underpinnings of photographic field studies and particularly the dialogical and archaeological approaches.
Introducing the Dialogical Approach
Because photographs are best seen as ethnographic artifacts whose meaning and significance is cocreated and contextually embedded (Pink, 2007), most photographic field studies take an interpretivist stance, utilizing qualitative methodologies (Davison, McLean, & Warren, 2012). In other words, it is hard for anyone outside the research interaction to “see” the meaning of a photograph, apart from to recognize its generic features and guess at what it is intended to communicate. In contrast, realist researchers argue photographs can have a more iconic relationship with what they depict (Collier, 2001; Wagner, 1979a, 2001). From an interpretive stance, the realist approach is a “myth of transparency” (Bell & Davison, 2013, p. 174) that glosses over the fact that photographs are more accurately cultural artifacts rich with the hallmarks of their producers—photographs are “made” and not “taken” (Warren, 2002). As such, they are useful in the research process for encouraging researcher reflection and/or opening up discussion with research participants, with a kind of can-opener effect (Parker, 2009), as Meyer et al.’s (2013) “dialogic” approach describes. This emphasis on subjectivity and dialogue mirrors the assumptions underpinning constructivist views of meaning as the outcome of intersubjective exchange (Berger & Luckman, 1967), locating visual meaning as foundational in the social construction of reality (Meyer et al., 2013, p. 492).
As outlined above, field-study photography is generally seen as useful in generating dialogue with the field, either in the form of visual field-notes recorded by the researcher as they actively engage with (rather than just document) the research site, or as prompts to elicit research participants’ views during an interview setting (Buchanan, 2001; Parker, 2009; Wagner, 1979b). More participative variations ask study participants to present and discuss photographs they have made themselves during photo-interviews (Warren, 2002), or by annotating images that are then sent to the researchers (e.g., Bramming, Gorm-Hansen, Bojesen, & Gylling Olesen, 2012). In doing so, the aim is to foreground study participants’ views of the research topic over the researchers’ impressions (Warren, 2002, 2005, 2008). These “photovoice” methods (Catalani & Minkler, 2010; Wang & Burris, 1997) are particularly useful for investigating inequalities, marginalized occupational groups, or those less able to express themselves in language. Bolton, Pole, and Mizen’s (2001) study of child workers and Gallo’s (2002) investigation of immigrant’s experiences of work are now classic examples. More recently, Slutskaya, Simpson, and Hughes (2012) found that asking male, working-class butchers to take photographs that depicted their work enabled them to engage in subsequent research interviews that were more expressive and aesthetic in character than has been the case during earlier verbal interviews. These narratives are then analyzed using regular qualitative techniques such as coding (Charmaz & Mitchell, 2007), template analysis (King, 2012), narrative analysis (Chase, 2005), or discourse analysis (Oswick, Putnam, & Phillips, 2004). The photographs themselves, however, are usually relegated to the status of illustration in research outputs, if indeed they are included at all (Catalani & Minkler, 2010; Drew & Guillemin, 2014). However, what a dialogic approach is less suited to is identifying alternative meaning structures in the visual content of the field-study photographs, a subject to which we now turn.
Introducing the Archaeological Approach
The popular adage “a picture is worth a thousand words” is instructive here to draw attention to the “visual mode of meaning” (Meyer et al., 2013, pp. 492-493) an image has, separate from its capacity to generate dialogue. This visual meaning mode, has variously been described in aesthetic thinking as “presentational symbolism” (Langer, 1957, p. 97), a “silent speech” (Rancière, 2007, p. 13), conveying an “atmosphere” (Biehl-Missal, 2013, p. 359), or “puncturing” the viewer with a disturbing or intensely personal meaning not experienced by others (Barthes, 1982, p. 43). As a matter of course, we “read” images as having socioculturally anchored meaning(s), signified through the image’s visual features independently of any explanation from the producer of the image. This is how images “speak for themselves” and how we know what a photograph “is of,” for example.
This accords with Meyer et al.’s (2013, p. 502) “archaeological” view of images as containing “sedimented social knowledge.” Archaeological analyses are more usually applied to preexisting organization-generated images yet we argue they may also be valuable in investigating field study photographs. Product advertisements (N. Campbell, 2012; Garland, Huising, & Streuben, 2013; Schroeder, 2012), firm advertisements (De Cock, Baker, & Volkmann, 2011), recruitment brochures (Hancock, 2005), company annual reports (Davison, 2007; Swan, 2010), and websites (Elliot & Robinson, 2014) have all been archaeologically analyzed using frameworks developed from visual culture, communication, media studies, and art criticism. These tools pick apart the structure, attributes, signs, and composition of strategic organizational images (e.g., Kress & Van Leeuwen, 2006) with the aim of uncovering how such images reflect, mask, or constitute social reality (Meyer et al., 2013, p. 506). This process does not involve the producer of the image explaining their motivation for doing so, and proceeds from the assumption that the image-producers do not intentionally use “hidden messages,” but merely produce images according to the prevailing aesthetic and social conventions of the time (Schroeder & Borgerson, 2012). These manifest themselves in the creator’s choice of subjects, styles, or compositions, and perhaps the easiest way to recognize “sedimented social knowledge” (Meyer et al., 2013, p. 502) in images is to look at old advertisements. Portrayals of race and gender in historical photographs, and the implicit assumptions therein, seem incongruous, and even shocking and “spoof-like” when viewed from the vantage point of modern-day society, for example (e.g., Grady, 2007).
We wish to extend the archaeological approach to field-study photographs, by arguing that researchers and participants cannot help but frame and compose their shots in ways that reveal unacknowledged dimensions of the “unspoken practices” (Gylfe, Franck, LeBaron, & Mantere, 2016, p. 135) of their visual (and broader) culture, in the same way as organizationally produced images can be mined for the substrata of cultural traces their producers implicitly leave. This is in addition to the fact that photographers in field studies make active choices to photograph certain spaces, people, scenes, objects, and so on so we can assume that these symbols and artifacts hold some kind of communicative meaning and are not just arbitrary selections. These can of course be partly explored in the dialogical phase through memoing, reflection, questioning, and discussion as appropriate. But as we have found in the course of our practice as visual researchers, archaeological meaning is not necessarily apparent from viewing individual images in isolation. Sedimented social knowledge becomes much more apparent when photographs are viewed together as a group or in juxtaposition with one another, since differing interpretations are generated (e.g., different visual meanings), depending on how the images are configured.
Thus, applying an archaeological analysis to photographs from field studies, “open[s] up possibilities for the systematic reconstruction of implicit and taken-for-granted understandings and values” (Meyer, 2013, p. 506) apparent at the field (or sample) level that might not have come to light through dialogue with individuals alone. Conversely, what a solely archaeological analysis would miss is the discursive meanings images have for their producers. Since organizational field studies are highly context-dependent and usually center on the experiences and socially shared meanings of their members, this would be a significant omission. It is for these reasons that we advocate the bridging of the two approaches in GVPA as a method that combines: an interpretivist “dialogic” commitment that the social and personal (discursive) meanings of photographs can only properly be attributed by their photographers; qualitative analysis of photographers’ spoken or written narratives explaining what the image means (since they are expressions of the photographer’s subjective view of the sociomaterial world); an “archaeological” recognition that it is important that photographs are “of” something, with “sedimented social meaning”; which emphasizes the need for viewing collections of photographs (image-sets) that show us field-level visual meanings. The “montage” or juxtaposition of images creates a new way of seeing the phenomena studied.
The next section presents a worked example of GVPA, detailing the decisions a researcher needs to make throughout the process: (a) how to group photographs, (b) how to order photographs, (c) how to undertake a structured viewing, and (d) how to impute theoretical significance. These stages are also summarized in Table 2. We then return to conceptual considerations, after we present our empirical example, reflecting on further “bridging” of methods that might offer alternative routes for visual analysis in the future. As part of this, we show how GVPA is particularly relevant for researchers exploring material and aesthetic dimensions of organizational worlds in a variety of disciplinary contexts.
Characteristics of Field-Study Sample.

Key Decisions in Grounded Visual Pattern Analysis.

Grounded Visual Pattern Analysis (GVPA): An Illustration Using a Field Study Exploring Work Space and Identity Construction
The illustrative field study we discuss here investigates employees’ experiences of their work space and how this shapes and colonizes their identities. The study is based on hairdressers working in hair salons, and the research questions include the following: What spaces (and objects) do hairdressers identify as meaningful to them and why? What do these spaces (and objects) convey about the identities of hairdressers? The field study was conducted by Harriet, the first author of this article, over a period of 9 months in five different hairdressing salons in London and the South West, in the United Kingdom. The salons ranged in size and prestige from a small one-room operation to a large, prestigious salon catering for upmarket clients and celebrities. A total of 43 male and female hairdressers, across a wide age range (17 to 50 years), were included in the research. These included less experienced junior hairdressers (including trainees) and more experienced stylists and colorists holding senior positions in their respective workplaces. The sample was chosen to maximize variation between different workplace contexts, increasing the robustness of the findings. At the time of the data collection (2008-2009), access to smartphones was less commonplace than the present day, and given the scope and size of the study, providing each participant with a digital camera was not possible in this case for financial and practical reasons. Thus, Harriet gave each participant a disposable film camera and asked them to take up to 12 images of spaces that were meaningful to them and said something about “who they were.” Many chose to capture more than 12 images since the disposable cameras allowed for a total of 21 exposures. Table 1 shows the characteristics of the sample used in this study:
After the photographs had been developed, one-to-one, face-to-face, photo-interviews were conducted by Harriet with each participant, where their images were discussed and conversations audio recorded according to the conventions of the dialogical approach we outline above. The data were then subject to an analytical process which (some years later) we termed GVPA. First, a dialogic analysis was carried out, where themes were generated from the analysis of narratives about the photographs (as is the case in most photographic field studies). And second, an archaeological visual pattern analysis was carried out, where the photographs were viewed as an image-set to investigate their manifest content and attributes beyond the individual level. This second stage was carried out by Harriet, but it would also be possible for more than one researcher to undertake pattern analyses independently to corroborate findings and improve the robustness of interpretations. This approach was usefully undertaken by Garland et al. (2013) in the early stages of their analysis of print advertisements for environmentally friendly cars.
Dialogic Analysis Stage
As we noted above, our emphasis in this article is on the GVPA stages that follow a dialogical analysis of the photographs, so the following account is necessarily brief. At this stage the photographers attribute meanings to the images they have produced. Be it researcher- or participant-generated, the photograph is subject to interrogation not necessarily in terms of what is in the image, but rather what the image means, represents, or symbolizes. All the hairdressers chose to view their photographs as printed hard copies (rather than as electronic files on a laptop), and each photograph was ascribed a meaning through conversation about it. A memo was made, and the discussions were audio-recorded. Following this, themes were generated across the data set, with words and phrases from the transcripts of the photo-interviews were used to develop the themes (Saldaña, 2012). This could equally have been done on the basis of memos made against researcher-generated photographs (e.g., Buchanan, 2001). Once again, it is important to note that the theme generated may be very different to what is depicted in the content of the image in a representational sense. For example, in this field study, a photograph of a toilet actually meant “hiding place” to its photographer and was consequently coded as “hide away from others,” which then became part of the wider theme “spaces for privacy and being hidden.”
The theme we are using for illustrative purposes here is “spaces for privacy and being hidden.” Through their photographs, the hairdressers spoke of how they found spaces for quiet moments and how they establish private, hidden territories to relax alone (Shortt, 2010). This is where most visual analysis ends and where the dialogic approach leaves its data analysis. The visual element of the research has played its part in generating textual data, which are coded, themed, and interpreted into findings and discussion (Harper, 2002; Radley & Taylor, 2003). However, we suggest the visual still has much value to add to photographic field studies by generating further data based on the depicted, collective content of photographs that were discussed as relating to each theme that emerged from the dialogic analysis. The photographic content of these themes we refer to as “image-sets”—that is all the photographs that have been determined as communicating that particular theme. These “image-sets” cut across the study as we discuss further below, and could include photographs taken at different times, in different places, and, in the case of participant-generated photographs, by different people.
Archaeological Visual Pattern Analysis Stage
The second iteration in GVPA begins to introduce an archaeological approach to the content that has been chosen by the photographer to represent the meanings they have previously ascribed. As outlined above, visual pattern analysis is undertaken on an aggregate level rather than at the level of the individual image; photographs are now viewed together, as a set, and not separately. This is because the content of individual photographs is acknowledged during reflective memoing, or discussions with the photographer in the dialogic stage (e.g., “What is this a photo of?,” “Why did you choose to photograph this object?,” etc.). It is not until all the images are viewed as a set that broader field-level patterns based on the images as a collection might be apparent (Collier, 2001). Kress and Van Leeuwen’s (2006, p. 215) description of a musical performance is helpful to understand the potential significance of viewing images collectively. They explain how a musical composition has to be performed for us to hear it—we cannot separate composition and performance. To draw parallels with visual pattern analysis then, each individual photograph in the set could be considered as a “note” in a musical composition that when “played” (viewed together) performs a collective meaning that cannot entirely be reduced to the sum of its parts. Thus, the value of visual pattern analysis is to reconstruct field-level meanings—by bringing together photographs from the same theme, but from different people, points in time, data generation points/episodes, and so on. In the case of the hairdressers’ study described here, these image-sets were assembled from all the photographs taken by the study participants that Harriet had coded to a particular theme after dialogic analysis. We say more about this process below, and as Meyer et al. (2013, p. 489, our emphasis) sum up, “It is the specific performativity of visuals and visual discourse—working differently from other modes of communication—that holds ample potential.” For example, Warren (2002, p. 237) shows how arranging photographs of the “same” thing, taken from different aesthetic perspectives—representational, expressive, point of view, etc.—gives an impression that better holds the multiplicity of the phenomena the images were intended to represent, and avoids reducing it to any one image, which then comes to stand as a defining icon of it. Marcus’s (1995) technique of “montage” makes similar claims and the power of multiple photographs grouped together is famously illustrated in the photographic art of David Hockney, who created a number of photomontages or “joiners,” as he referred to them—to describe images connected by meaning (Hockney, 1983). He wanted to show how using several still images better depicts space, time, and narrative when arranged and overlapped to create a complex “story.” Hockney’s “joiners” engender an uncanny sense of movement, time, and memories and illustrate well how multiple still photographs of the “same” thing generate new meanings when arranged together that are not apparent when the individual images are viewed in isolation (Shortt, 2012).
The following four steps explain how a researcher could approach the visual pattern analysis stage and the key decisions they would make (see also Table 2). We also explain how this process is archaeological—in suggesting the underlying meaning structures indicated from analyzing the image-sets. To reiterate, this is where the value of the archaeological approach lies—showing shared, field-level data interpreted from the visual features of the photographs when viewed together. As we note above, it would also be possible for multiple analysts to undertake the following steps. This could usefully highlight further interpretations, or confirm consensus. It is also feasible for one analyst to undertake the dialogic stage of GVPA, with a different researcher(s) carrying out the archaeological stage, providing they know what the theme of the image-set is. This approach could work well for larger projects, or where the study is being undertaken by a research team.
Grouping
The first step is to group together all the photographs associated with a particular theme. The purpose of doing this is to generate a collection of photographs that were all taken to communicate a particular sentiment or issue as identified in the dialogical stage. This offers a chance to look at how the dialogical meaning has been visualized, offering a window onto the underlying meaning structures across the sample and/or study. This first step is necessary before analysis can begin. With hard copies, photographs could be arranged on a tabletop or pinboard, or an electronic method could be used, such as an Excel spreadsheet or PowerPoint slide with images embedded side by side in a montage as was done with our worked example (see Figure 1). A key decision here is to decide which photographs should be in the set and which, if any, should be excluded (Collier, 2001). This should be fairly unproblematic given that the themes generated during dialogic analysis will include photographs to which the dialogue refers, and it is these photographs that should be included in the set. This is the case with the hairdressers’ study here—Harriet gathered together all the photographs that were used to communicate the theme “spaces for privacy and being hidden.” It may be that only parts of photographs refer to the theme of the set, and the researcher could therefore select only that part of the photograph for inclusion. We would urge caution in this regard, however, since information about the photographers’ position vis-à-vis the scene, the framing and context of the image as a whole and the composition of the image will be lost if it is cropped. Another potential consideration is where photographs “float” between one of more themes as dialogue often expands and digresses during discussions (Warren, 2005). Our advice here is to duplicate such photographs in order to include them in as many sets as necessary to capture the range of meanings attributed to them during the dialogic phase. Conversely, we would only advocate excluding a photograph if the discussion was too tangential or incidental to be considered to actually be about the image.

Thematic set for visual pattern analysis—spaces for privacy and being hidden.
Ordering
The second key decision in the process is to decide how the photographs in the set will be laid out. Will you order them by photographer? Or chronologically? Or select them randomly to place next to one another? Pink (2007, p. 129) notes the importance of ordering in her discussion of storing (digital) photographs generated during a field study, explaining that the shooting order might be important to preserve and would be lost if file names are given to the images that change the order they appear in a folder on a computer (see also Parmeggiani, 2009). We make a similar point here—the shooting order might reflect a particular route through a building for example, and therefore if there is one than more photographer involved in generating the data, the set would need to be ordered sequentially by photographer, then by shooting order. However in the case of a “day in the life” type study, time of day could be used to order all photographs taken early morning, lunchtime, midafternoon, and so on. 2 Although these seem like small decisions, they are nonetheless important because meanings of images are affected by the context they are viewed within, and especially what they are placed next to as we introduced above using Kress and Van Leeuwen’s (2006, p. 215) metaphor of a musical performance. More concretely here, Sørensen’s (2014, p. 60) method of “juxtaposition” explains how a researcher could deliberately select images to place next to one another, in order to raise “ethical or political questions” about organizational life, creating new ways of seeing hidden organizational practices. Thus, photographs placed and viewed in relation to one another generate a collective meaning that transcends that of any one image.
Figure 1 shows all the photographs that were taken to communicate the illustrative theme from the hairdresser’s study—“spaces for privacy and being hidden.” These were grouped as hard copy images and randomly placed next to each other rather than preserving any kind of narrative through them, because what Harriet found striking about the collections was the unusual content of the photographs. She may well have chosen a different approach if she were explicitly looking at spatial routines, for example, when a chronological ordering might have been important to preserve. Once the photographs have been arranged into image-sets by theme, they are ready to be archaeologically mined for the patterns they may reveal, which in turn will indicate the presence of underlying meaning structures that add to an understanding of the data. The next two steps discuss this in more depth.
Structured viewing
In GVPA, a structured viewing treats the elements of photographs as a “range of signifying resources” (Kress & Van Leeuwen, 2006, p. 215) across aggregate sets. It is less concerned with counting, recording and cataloguing each unit of analytical significance as was undertaken by Höllerer, Jancsary, Meyer, and Vettori (2013) for example. We already know the photographs’ discursive meanings from the dialogue about them and their subsequent aggregation into descriptive themes. This contrasts with what is more usually undertaken in the archaeological approach, where individual images are pulled apart in forensic detail in order to establish meaning based on the visual mode, or “silent speech” (Ranciere, 2006) of the image. In the regular archaeological approach, it is the researcher who is imbuing the image with meaning based on their analyses of its structural and formal properties and what they signify—usually done using content or semiotic techniques drawn from media and communication studies (Meyer et al., 2013, p. 505).
However, structured viewing in GVPA reverses this, and instead identifies the material signifiers (in this case, the physical objects and spaces) that communicate these meanings and that are common or otherwise patterned across the field-level data, asking, “What might be the sedimented social meanings underlying these patterns?” Collier (2001, p. 38) helpfully encourages such an approach when examining the “content and character” of images in visual research, asking the researcher to “listen to the overtones and subtleties [of data]…trust your feelings and impressions…view images in their entirety…[be] influenced by this final exposure to the whole” (p. 39, italics added). The rest of this section explains this process more fully.
However, we pause here to consider how a researcher might deal with the potentially large number of observations that structured viewing can generate—particularly if the image-set includes a lot of photographs. Ray and Smith (2012, pp. 302-304) advocate using a computer software package to undertake annotation in order to categorize, cross tabulate and otherwise make sense of the features of individual images which will then be used to generate Nvivo themes (see also Parmeggiani, 2009). Individual images could be coded electronically according to a wide variety of variables and then aggregated and combined to produce field-level patterns across the data set. This is something that a researcher could do using Nvivo or QDA miner or perhaps by using an algorithm as, for example, Höllerer et al. (2013, p. 150) demonstrate using large quantities of visual data (1,652 individual images). In their article, they too advocate visual analyses for field-level formations rather than only analysis of individual images (or a small sample) and use coding and network analysis in order to reveal how visual discourses contribute to the “emergence of field-level logics” (p. 139) in corporate social responsibility. 3 Their study usefully demonstrates how computer-assisted coding provides one way of analyzing images to produced field-level patterns.
However, their ambitious analysis nonetheless remains within the archaeological approach whereas GVPA aims to ground these wider interpretations from the data, within their dialogic origins. An alternative approach, and one that we adopt in the current study, is to embark on manual recording of observations and the physical handling of the image-sets (see Figure 3 below). This is perhaps a more appropriate method if the study is one that is more concerned with the “aesthetic effect” of the image-set—by this we mean if the study in question requires the researcher to be visually attuned to the representational, expressive, artistic, composed components of the image-set and its collective performance, in addition to the subtleties seen in the features’ “content and character” (Collier, 2001, p. 38) and of the group of images as a whole. This might be lost (or not so easy to see) if the researcher is coding individual images one by one and then relying on software alone to aggregate and produce field-level patterns.

Symbolic viewing.

Compositional viewing.
Returning to the manual approach used in the example field study, the rest of this section explains how structured viewing can be further divided; namely symbolic viewing and compositional viewing. 4
Symbolic viewing
The first stage in identifying patterns in the image-set is to consider what are the material objects and spaces that photographer(s) has used to communicate the dialogic meaning? What similarities and differences can be seen in the image-set? What is striking or unusual? What has been foregrounded or placed in the background?
In Figure 2, to begin with we see the hairdressers’ photographs of cupboards, toilets and tucked-away corners of their salons. As the theme of the image-set is “spaces for privacy and being hidden” these places might not seem so surprising. But there are also corridors and stairwells depicted, as well as spaces typically used for transitioning—there are walkways, steps, cobbled streets, doors, gates, and foyers, for example, and a pattern emerges that shows us these workers “escaping” in spaces that are on the very edges of the salon or indeed within somewhat public spaces far removed from work; even on the pavement, a side street or a doorway. The symbolic viewing therefore reveals a pattern in Figure 2 suggesting the hairdressers’ share a propensity to photograph semipublic, semiprivate spaces, no matter whether they work in a large flashy salon, or a small one-room location. This pattern is evident from viewing the material signifiers chosen by the hairdressers across the photographs from all 43 hairdressers, working in all five salons that were generated to communicate this theme. Given this variation, the patterns we see in the image-set are surely significant as indicating underlying meaning structures shaped by their visual (occupational) cultures. With this in mind, we argue for the following interpretations:
Hairdressers are always “on show” in spaces that are usually designed exclusively with the client in mind. Their work is inherently visible, watched by each other, clients, passers-by outside—reflected, refracted and multiplied by mirrors. From Figure 2 we see how they go to great lengths to find places away from these gazes—even if these are cramped or less-than-desirable resting spots. We might conclude that acceptance of this constant visibility comes at a psychic cost—necessitating creative spatial escapes—and that this is a shared social meaning, sedimented in the visual features of the image-set. As the space of the salon is for the client, it is clear from these photographs that the hairdressers remove themselves from it when it comes to their needs—they understand the space is not really for them. We suggest this taps into wider discourses of consumer sovereignty—even standing or sitting on the street (on fire-exit steps or in public doorways) is preferable to using “front stage” salon comforts, for example, sofas, or relaxation spaces. Even the “back-stage” staff rooms provided by the salons are spaces, identified by the hairdressers, as problematic—they are either spaces that double-up as storage areas for products (and thus arguably still a space for the client), or spaces that carry social expectations for meeting others and engaging in wider group conversations.
Compositional viewing
Next, and using the same image-set, the researcher investigates how the unacknowledged aesthetic preferences and material/visual culture of the photographers manifest themselves through the photographs they have taken and what their significance might be—further illuminating “underlying meaning structures” (Meyer et al., 2013, p. 502) but this time by looking not so much at what the photograph depicts, but how the photograph was made. For example, are there similar framings, camera angles, positions of photographer, aesthetic effects (representational/expressive/artistic/composed, etc.) in evidence across the image-set? If so, what does this tell us about how the photographer situates themselves in relation to the material environment in order to communicate through it?
Figure 3 shows the manually recorded observations from the compositional analysis of the theme “spaces for privacy and being hidden.” The most striking feature of the set (as indicated by the notes above, see Figure 3) is perhaps the aesthetic tone of the photographs. There are no bright colors, no staged photographs—and this imparts a strong sense of everydayness. This image-set suggests a “gritty reality” to the hairdressers’ experiences—even when their “on stage” work is, for many, performed in ostensibly glitzy salons. This overall collective effect from the image-set is only really apparent when all the photographs are viewed together—it is what “strikes” you from “exposure to the whole” as Collier (2001, p. 38) advocates. Indeed, it may be useful to mix up the ordering of the image-set for this stage of structured viewing to suggest new impressions, given all that we have argued about meaning and juxtaposition in collections of images in Step 2, “ordering,” above.
Turning attention to the camera angle and positioning of the photographers across the image-set, we can see that the hairdressers took pictures “of” the spaces they wanted to show, the view through the open doors, up at the windows, out onto the street, for example. The perspective of the photographs indicates that most are standing, not sitting, but they did not stand inside the spaces and take photographs looking back out, or at the view they might have once inside. The effect of this is that we see what they see when they enter their hiding place, not while they are resting in it. There is a pattern of straight-ahead camera angles across the majority of the photographs and with the exception of one photograph taken on an angle, there appears to be little attempt to stylize or make the pictures “arty” in any way as contemporary visual culture often encourages.
The final notable pattern we ascertain from this image-set is that the photographers appear to be alone when taking the photographs (although we cannot know for sure whether anyone was standing with or behind them, this is certainly the impression). This reinforces the solitary nature of escape being conveyed here (although other forms of escape were also communicated by other themes, see Shortt, 2010, for more detail). In this case, this image-set does not suggest an impression that the hairdressers seek places for social escape and/or shared privacy, but that being alone is important. Thinking further about what these observations might tell us about the underlying meaning structures the hairdressers are drawing upon in constructing their photographs, we make the following interpretations: The notion of contrast is significant, we suggest. Hairdressers are engaged in the business of creating beautiful, stylish impressions in the course of their work, and they seek escape from this by returning to the “messy everydayness” which in conjunction with the dialogic data we might read as being a kind of psychic relief from being “on display.” Thus, the photographs they use to convey this are not glamorous, staged or carefully constructed, but represent instead the unglamorous ordinariness that they enjoy in their workplaces. We can connect this to the “consumer sovereignty” point made above from the symbolic viewing, that the salon space is not theirs, but these spaces are. We can also now extend it to reinforce the meaning structure that the authentic, human, person-at-work (one who is hiding, seeking privacy and escape) belongs in the off-stage spaces—or at least away from the colonizing effects of company branding, and “front-stage” aestheticized spatial discourses. Interestingly, we are also only being shown these spaces through the photographs, and not really taken inside them. We are being given a tour by looking through the doorways at these spaces, and not really being invited to share in the experience of hiding. So while these spaces can be shown to others, using them is an intensely personal matter and not one that the photographers are so willing to represent. Solitude is clearly of utmost importance, even when taking photographs for a research project.
Theorizing
The final stage in GVPA is to ask, “How have the patterns identified in the image-sets above extended the dialogical data?” In our illustrative case, what more do these patterns tell us about “spaces for privacy and being hidden” than the hairdressers recounted in their dialogues with Harriet about their photographs? Put another way, how does this fourth and final step in GVPA help build conceptual contributions from photographic methods, above and beyond purely empirical ones (Drew & Guillemin, 2014)?
From our dialogical data we know that hairdressers seek “hiding spaces,” but it is only after a visual pattern analysis that we see patterns in where and how individuals go to regroup, recharge, and quietly rest away from the glare of client surveillance. Tracing outward to theory then, it is clear the patterns in the meaning structures identified above are of peripheral spaces and their occupation is “on the edge”—hairdressers’ “identity-work spaces” are, therefore, liminal ones (Iedema, Long, & Carroll, 2010; Shortt, 2015; Taylor & Spicer, 2007). Liminal spaces are those undefined limbo-like spaces where “anything may happen” (Turner, 1974, p. 13) and where, as Preston-Whyte (2004) notes, we can find brief moments of freedom and escape from the socio-cultural expectations and norms found in the more defined spaces of social life. Indeed, Dale and Burrell (2008) neatly argue that liminal spaces are those in-between the dominant spaces of organizational life—spaces that are somehow both semipublic and semiprivate where we may seek “snatched moments of private business or intimacy” (p. 283). This is significant because hairdressers work in predominantly shared, fluid spaces that involve movement and a lack of autonomy or ownership over salon space, and it seems this is the case across the different types of salons and hairdressers that make up the sample. Consequently, the most important spaces for them—and interestingly, those that the hairdressers call their “own”—are the spaces at the edges of the salon, those between dominant spaces (Dale & Burrell, 2008).
It is the grounded visual pattern analysis and in particular the bringing together of dialogic and archaeological meanings that allows us opportunity to further theorize these everyday experiences where previous research has paid attention to more dominant work spaces and corporate environments (e.g., Elsbach, 2004; Elsbach & Pratt, 2007; Halford, 2004). Little attention has been paid to more communal and flexible work spaces and even less to the in-between, liminal spaces of organizational life (Dale & Burrell, 2008; Iedema et al., 2010; Taylor & Spicer, 2007). This is important in practical terms as organizations may reconsider the financial investments made in the physical work environment in light of these data: Many of the hair salons invested a great deal in an aesthetically appealing workplace, designed to “wow” and inspire both clients and employees, yet important spaces for reflection, private contemplation, and breaks from work were found in the liminal spaces at the periphery of salon itself—in the toilets and on doorsteps. This, in turn, echoes recent emerging research on how corridors are used by other professions who also lack “personal” space—for example medical workers, doctors, and consultants’ use of hospital corridors for teaching, learning and reflection (e.g., Iedema et al., 2010). Furthermore, there are also implications here for the management of open-plan, flexible, and new forms of coworking space that are emerging even in seemingly traditional occupational settings like banks and insurance companies.
Discussion: Reflections on the Broader Value of Methodological Bridging and GVPA
In this section, we further develop these theoretical discussions, reflecting on the value of methodological bridging and suggesting how other “cross fertilizations” between Meyer et al.’s (2013, p. 517) visual approaches could hold promise for future organizational research. In doing so, we also demonstrate the methodological contribution of GVPA beyond the empirical study presented in this article.
Considering Different Bridgings
As we progress into ever more image-saturated times, greater scholarly and applied understandings of the roles images and visual organization have in contemporary society is needed (Bell & Davison, 2013). To further this endeavor here, we consider how Meyer et al.’s (2013) visual classifications—archaeological, practice, strategic, dialogical—and documenting (discussed above) might be fruitfully blended to generate new research agendas that better address this visual turn in organizational life (Table 3). The following discussion is not intended to be a blueprint for all possibilities—for example, the order of the bridgings suggested below might usefully be reversed, and other studies in different organizational contexts would surely be possible. However, we hope this section will serve as further inspiration for research agendas that bridge the five approaches.
Considering Other Possible Methodological Bridgings from Meyer et al.’s (2013) Five Approaches to Visual Research.
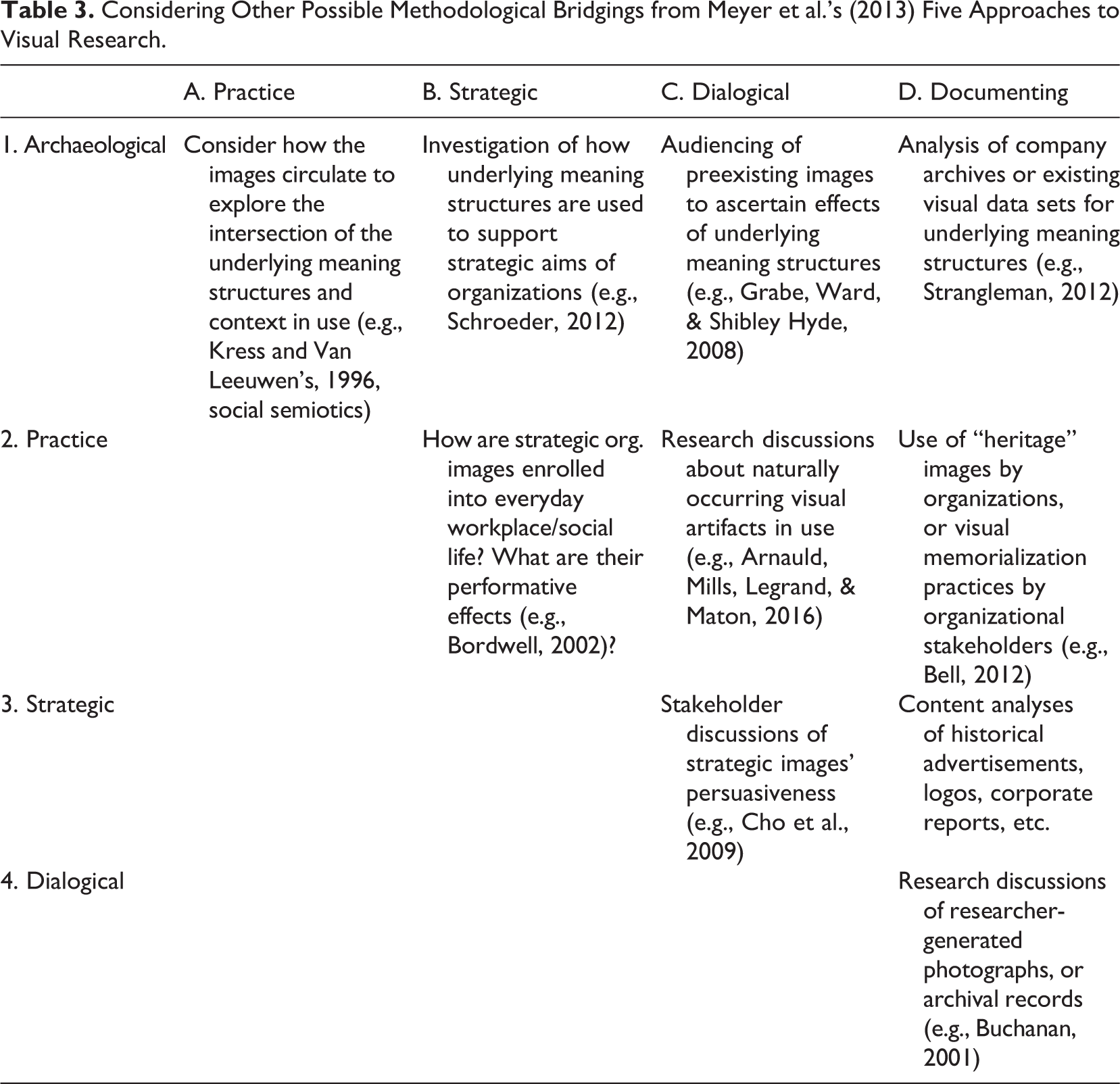
Archaeological bridgings A1, B1, C1, and D1—Table 3
As we discuss at the outset of the article, the archaeological approach is one that has already been used to good effect in uncovering the meaning structures in preexisting organizational images. If it were to be combined with a practice approach (A1, Table 3), we might foresee useful data being generated on how those meaning structures are recognized and taken up (if at all) by the organizational stakeholders who use them in the course of their everyday action. So, for example, how do the assumptions apparent in the visual features of the “corporate posters” displayed in banks impact on perceptions of employer branding among employees? Combining the data generated by an archaeological approach with an explicitly strategic agenda (B1, Table 3) would ask how those messages are “doing work” (Schroeder, 2012) for the organization and in what ways social meanings are put to use by organizations to express certain sentiments for competitive advantage. We have spoken at length about bridging the archaeological and dialogical approaches in this article (C1, Table 3), but an alternative application focusing on intentionally produced organizational images, promotional films, or websites, could be to undertake studies of how intended audiences regard the effects of the visuals—do they see them? Do they matter? The (detrimental) effect of magazine advertising on young women’s body image is a good example here (Grabe, Ward, & Shibley Hyde, 2008). Finally, bringing a documentary approach alongside archaeological analyses (D1, Table 3) might prove useful for studying company photographic archives (e.g., Strangleman, 2012) and/or preexisting image-sets, such as the Mass Observation study undertaken in the United Kingdom in the mid-20th century (Mass Observation, n.d.). How do the underlying meaning structures change over time, or across cultures?
Strategic bridgings B1, B2, C3, D3—Table 3
We have already ruminated on how the strategic approach could be combined with the archaeological to see how meaning structures are benefiting organizational agendas (B1, Table 3), but through a practice lens (B2, Table 3), it would be possible to see what organizational stakeholders actually do with these strategic images-as-artifacts. How do people enroll them into their lives—for example, brands, advertisements, and so on? How do interest groups subvert strategic images for their own ends as seen in “culture jamming” campaigns such as “Adbusters” (Bordwell, 2002) and viral filmmaking? (Bell & McArthur, 2014). Using a dialogical approach to the analysis of strategic images (C3, Table 3) would involve asking stakeholders for their views on visuals such as marketing communications, annual report images, or experiments could be done to ascertain their persuasive effect (e.g., Cho, Phillips, Hageman, & Patten, 2009). A more participatory variation of the dialogic-strategic bridging can be seen in the work of Delta 7—who produce visual maps and drawings from discussions with groups of employees (often on the topic of organizational engagement or culture change) and then use these pictures to generate further reflection and dialogue among those involved. Thus employees are better involved in strategic change initiatives, increasing the likelihood of their success (see Delta 7, n.d.). Last, the strategic approach to organizational visuals could be applied to a corpus of documentary photographs (3D, Table 3), either a researcher-generated set, or company archive as suggested above—but this time to excavate the economic, market, or brand value that visuals have for the organization across different temporal, spatial, and cultural contexts.
Dialogical bridgings. C1, C2, C3, 4D, Table 3
In addition to combining dialogic approaches with archaeological, and strategic agendas as suggested above, we also see value in generating data through investigations that bridge the practice approach (C3, Table 3) and would envisage these as being ethnographically inspired projects. The circulation of visual artifacts in and through social relations would be explored through conversations with organizational members, rather than by relying on researcher-only interpretation as would be the case in a strategic-practice hybrid (B2, Table 3). Examples of this include Arnauld, Mills, Legrand, and Maton’s (2016) article on strategy as material practice outlined below. In a similar vein, generating dialogue with various stakeholders around documentary images (4D, Table 3) would yield interesting insights, for example Buchanan’s (2001) study of the “patient-trail” in a hospital where he took photographs to record his observations, then held focus groups with hospital employees to view and discuss the photographs.
Documentary bridgings (D1, D2, D3, D4, Table 3)
The only combination with the documentary approach that we have yet to mention is the documentary-practice bridging (D2, Table 3), which we speculate could be useful in studies where the use of heritage images in the everyday lives of organizational stakeholders is explored. The enrolling of “retro” brands in consumer identities for example, such as Apple devotees who have the iconic apple/Mac logo tattooed on their skin (see Brownlee, 2011).
Application of GVPA and other Bridgings to Material Organization Studies
As will have become clear throughout this article, and the examples we have used to illustrate the potential of alternative methodological bridgings, visual analysis sits especially well with the emergence of research agendas that attend to the materiality of work and organizations. These encompass fields such as organizational space (Dale & Burrell, 2008), strategy as (material) practice (Dameron, Lê, & LeBaron, 2015), embodied cognition (Gylfe et al., 2016), servicescape aesthetics in marketing and consumption studies (Bitner, 1986, 1992; Lin, 2016; Wardono, Hibino, & Koyama, 2012). In particular, GVPA is useful in these “material fields” because it provides researchers and research participants with an alternative way to express themselves as we have alluded to throughout this article—enrolling visual artifacts in ways that augment (or in some cases transcend, e.g., Scarles, 2010) text-based accounts (O’Toole & Were, 2008). Second, analyzing the visual character of photographs using GVPA is a proxy for space and materiality (Bramming et al., 2012; Shortt, 2015; Warren, 2008) since photographs bring these dimensions “into the frame” for organizational analysis in a more immediate and striking way than by, say, descriptions in verbal interviews, or observations and written field notes by researchers. Attention to the objects in the photographs deliberately focuses attention on the material domain (whereas it is the social domain that is foregrounded if only the dialogic phase is employed). This affords opportunities for sedimented social meanings to be mined from image-sets as we have explained above.
Researching Contemporary Conceptualizations of Fluid Organizational Space
Aesthetic and material dimensions are rising in significance as organizations exploit their buildings, work spaces, and places as generative assets (Kornberger & Clegg, 2004) aimed at improving organizational outcomes such as increased creativity and employee morale and to project a desirable corporate image. In addition, the ubiquity of mobile technologies is changing where and when work is performed (Towers, Duxbury, Higgins, & Thomas, 2006). As Munro and Jordan (2013, p. 1516) explain, this necessitates new strategies to “repurpose” spaces from public environments into work spaces, such as airports, coffee shops, libraries, and so on. Employing strategic variants of visual analysis as outlined above could explore with different stakeholder groups (cafe employees, mobile workers, airport security personnel, etc.) how the aesthetics of previously recreational and/or consumption/transit spaces need to change in order to better cater for their new uses as quasi-work spaces.
Returning to our dialogical bridgings, in researching such shifting spatial boundaries (Malhotra, Majchrzak, & Rosen, 2007), we might ask commuters (Lyons & Chatterjee, 2008) and home-workers (Holliss, 2012; Whittle & Mueller, 2009) to take photographs of the various spaces and places in which they find themselves working. GVPA in particular would allow us to see patterns across image-sets that could highlight hitherto unrecognized and perhaps undervalued tensions experienced by groups of workers whose public/private, work/home boundaries are unclear and “messy” both physically and temporally. Assembled as an exhibition, these data would also bridge a documentary function, putting mobile workers lived practices on show to estates managers, architects, urban planners and so on in order to stimulate policy or other change. Indeed, as we discuss above, Hockney (1983) may agree that viewing image-sets (or photomontages, as he described them) in this context might help us to emphasize important narratives that engender a sense of movement and time, which is no doubt vital to our understanding of contemporary transitory workers.
Excavating the Material Dimension of Strategy–As-Practice
Dameron et al. (2015, S9) note that photographic and video methods are particularly suited to exploring how strategists are embedded in the material worlds they enact organizational realities through. From the artifacts and objects they use as “mundane tools” (Arnauld et al., 2016), to the spaces they mobilize in and through, strategy-as-practice pays particular attention to the role and emplacement of the body, which is, after all, “a material object that is necessarily located and oriented relative to other things” and therefore instructive in this regard (Dameron et al., 2015, S5). Taking photographs of things at work and generating discursive meaning among those who use them—as the first stages of GVPA enable—can uncover the sensemaking (and sensegiving) practices organizational members engage in, whether for the purposes of identity work as in the case of the hairdressers in our study, or to enact and mobilize strategic intent in and through their objects and spaces (Arnauld et al., 2016). However, as we have established in this article, GVPA has more to offer than illuminating discursive meanings. Symbolic and compositional viewing can show patterns in photographers’ unacknowledged cultural discourses at a field, or sample, level which could help understand how practices are always a blend of materiality and discourse, in an arrangement akin to Dameron et al.’s (2015, S6) description of “entanglement” between people and things, and which sees them as inherently inseparable. A strategic-practice analysis (B2, Table 3) of how stakeholders use charts, planning tools (such as visual management boards), PowerPoint presentations, and so on in the strategy process would also be illuminating, as would asking team members to produce documentary accounts of their visual process tools (3D, Table 3). To recap, these visual cross-fertilizations are useful here because it is not enough to pay attention only to “things”—“the missing masses” as Whittington (2015) puts it, but how they mesh with the social too.
Embodied Cognition
Related is the emerging field of embodied cognition, which specifically picks up on the bodily dimensions of materiality in the strategy-as-practice field as highlighted by Dameron et al. (2015) above. Scholars here emphasize the “body as a site for cognition” (Gylfe et al., 2016, p. 135, original emphasis) that enables thinking, as well as sometimes getting in the way of it, such as a headache affecting concentration (ibid.) So researchers of embodied cognition are inspired by ethnomethodological traditions that pay close attention to the routines and gestural practices of organizational actors in situ (Gylfe et al., 2016), suggesting that analytical bridgings involving practice perspectives would be useful (in particular C3 Table 3). Sensory anthropologists such as Hindmarsh and Pilnick (2007) have also paid attention to similar processes in studying how anesthetists coordinate their work at a micro-level with small gestures, gazes and actions, and in consumer research, Llewellyn (2014) has explored these below-conscious movements as they ease the process of sensitive transactions in service encounters. To our knowledge, these studies tend to use researcher interpretations of visual data to draw their conclusions, from meticulous analysis of video footage and still photographs. Thus, to a certain extent the archaeological element of GVPA is already undertaken because underlying meaning structures of people’s behaviors are inferred from viewing several episodes of similar transactions (e.g., Llewellyn, 2014). However, incorporating a dialogical dimension, say, by jointly viewing a previously videoed work episode with research participants, understandings of the motivations behind these movements could be enriched.
Servicescape Aesthetics
Another fruitful area in which to apply GVPA could be the study of servicescapes—the physical environment of a service business—which has been explored in marketing and consumption studies for some time (e.g., Bitner, 1986, 1992; Lin, 2016). Surprisingly little attention has been paid to the visual servicescape aesthetics of such environments. Lin (2016) aims to investigate how individuals perceive and experience the visual aesthetic cues of boutique hotel lobbies and uses simulated video clips and survey methods to capture potential customer evaluation and satisfaction. Interestingly, despite using visual methods, the study itself pays little attention to the visuals used and interpreted by participants. We might contend, then, that GVPA would be useful in such investigations. Not only would a dialogic approach glean a deeper and perhaps more varied understanding of how consumers respond actively to aesthetic cues, but a symbolic and compositional viewing of, perhaps, stills taken from the video clips used in this particular study, could show patterns in consumers’ unacknowledged cultural discourses, for example, how they perceive and construct notions of what is a beautiful or appealing in a service environment, for example. Such patterns could be particularly useful when considering and comparing the experiences of consumers in different countries and cultures, for example, as in Venkatraman and Nelson’s (2008) study of Starbucks in China and bridgings between practice and/or dialogical approaches and strategic visual artifacts (B2, C3, Table 3) could also be relevant in this context—as we have suggested in our discussion of the strategy-as-practice field.
Conclusion
In sum, we see promising opportunities for applying GVPA to a range of materially oriented research agendas in organization studies, and suggest that fuller insights into the visual dimensions of organizational life (beyond the material domain) are possible through creative bridging of visual research approaches that emanate from different research traditions. We have explicated one such bridging in this article—grounded visual pattern analysis—and shown the steps a researcher would take in applying GVPA to their photographic data: namely dialogic analysis, and archaeological visual pattern analysis comprising of the grouping and ordering of “image-sets” followed by an investigation of meaning structures underlying field-level photographic choices revealed by undertaking a structured viewing. In the spirit of the article’s aim to increase the analytical resources available to researchers undertaking photograph-based research practice, we have provided what we hope is an inspiring set of future possibilities for the application of GVPA and further bridgings of methodological approaches, in order to both push the boundaries of rigorous visual research practice and equip researchers with robust techniques in order to respond to institutional pressures that are increasingly apparent on the execution and presentation of qualitative, visual, research (Cassell & Symon, 2012).
Footnotes
Acknowledgments
We would like to thank Renate Meyer, Markus Höllerer, Denis Jancsary, Anne Smith, Liz Rivers, Mubarak Mohamed for their helpful advice on earlier drafts of this article. We would also like to thank Anne Smith as associate editor, and the two anonymous reviewers for their constructive and thorough comments in preparing this article for publication. Finally, we owe a debt of gratitude to the members of the inVisio network for their enthusiasm in supporting visual research in management studies.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.