
Abstract
Researchers can expect to perform analytic actions repeatedly; that this iteration is required is a common observation. Yet, how researchers engage in iteration to progress their theorizing is not articulated. Our analysis provides new insight into what it means to iterate in the service of driving analysis. We examine iteration through the lens of the analytic process of coding in specific research projects. Using a relational definition of coding, we identify the reported coding actions of several studies with rich descriptions of their analytical processes. By doing this, we show that it is useful to understand these coding actions in the context of coding moments that relate to how researchers use the coding actions as their project develops. The moments we identify are making codes, organizing to code, and putting patterns together. To show iteration, we trace the reported coding practices in exemplar articles. These tracings indicate that the reported process is not a fixed or consistent sequence. Rather, iterativity is organized by what is the next needed analytic input required to progress a given situated study.
Keywords
Contrary to the assumption of many apprentice researchers, collecting data is not even half the battle. Data analysis is always the name of the game.
Expansion of postgraduate research in the social sciences has created demand for more explicit guidelines for conducting qualitative research (Dey, 2007). Yet relatively few aspiring qualitative researchers have access to a range of introductory and advanced qualitative research courses and a bench of faculty with whom they can apprentice to develop their methodological craft (Locke, 2011). The paucity of mentors available to guide researchers endeavoring to theorize with qualitative data means that many aspiring researchers are learning qualitative research without the benefit of guidance from seasoned researchers.
As noted by Silverman (2007) in the opening quote, analysis is critical to our success as qualitative researchers; it is “always the name of the game” (p. 61). Methodological texts and research accounts in published studies provide some guidance for organization and management researchers in developing their analytic practice (Cunliffe, 2011; Locke, 2011). They elaborate specific procedures such as writing cases (e.g., Eisenhardt, 1989; Pettigrew, 1990), producing visual artifacts (e.g., Langley & Ravasi, 2019; Miles et al., 2014; Yin, 2011), memoing (e.g., Corbin & Strauss, 2015; Emerson et al., 2011), and coding (e.g., Saldaña, 2015). They also lay out general analytic strategies (Langley, 1999).
These texts and accounts typically emphasize iterativity as a feature of the procedures deployed to make analytic progress. For example, explicating his five-phase model, Yin (2011) underscored that researchers should “expect to go back and forth” both within and across phases (p. 67). Similarly, Agar (2006) stated that once a research project is underway, its key question, “repeated over and over,” is “What am I going to do next” (p. 2010). Thus, an analytic action “at time n + 1 is a function of what was just learned at time n” (Agar, 2010, p. 289). And Miles et al. (2014) described qualitative data analysis as a “continuous iterative process” (p. 14), providing the injunction to “expect iteration” as one of seven pieces of “final advice” (p. 343). We define iteration as the repeated application of analytic actions oriented toward theoretical progression. In practice, iteration often takes place through the active work of pursuing the questions and noticings that arise in and from this analytic work with yet more analytic actions.
Iterativity is a feature of two predominant templates in the organizational methods landscape: the Eisenhardt method 1 and the Gioia method 2 (Langley & Abdallah, 2011; Reay et al., 2019). For example, these scholars noted that the research process includes “twists, turns, and roller-coaster rides” (Gioia et al., 2013, p. 19) and “cycling between emergent data, themes, concepts, and dimensions and the relevant literature” (Gioia et al., 2013, p. 21); it includes “constant iteration backward and forward between steps” (Eisenhardt, 1989, p. 546). Accounts, therefore, indicate that researchers can expect to perform the procedures they describe repeatedly in a dynamic process. They emphasize that analysis is “highly iterative” (Eisenhardt, 1989, p. 532; see also Gehman et al., 2018).
Despite this acknowledged need for iterativity, templates suffer from two significant shortcomings that severely constrain one’s ability to understand how procedures and iterativity relate in analytic practice. First, although helpful in highlighting the temporal unfolding of research projects, templates cannot help but represent analytic procedures like coding as involved in a stepwise process. Two sequences are commonly represented: one that is generally top down from specific research questions and working models to data (Eisenhardt, 1989; Eisenhardt & Graebner, 2007) and that entails producing case histories and then conducting within- and cross-case analyses and a second that is bottom up from lived experiences and actions to a theoretical narrative (Gioia et al., 2013), deploying first-, second-, and third-order coding. Relatedly, templates embed assumptions about what analytic procedures should be used and when these procedures take place in a research project. Second, because they invite—despite their best intentions—a view of research practice as linear, such represented sequences must be explicitly qualified as being “highly iterative” (Eisenhardt, 1989, p. 532) to reference analysis as a complex, live, and idiosyncratic endeavor (Locke et al., 2015; Mantere & Ketokivi, 2013).
Consequently, accounts of analysis underarticulate not only how researchers relate procedures and iterativity in analysis but also how they progress analyses of particular research projects. For instance, what analytic actions are necessary to transform first-order and second-order coding into a generated Gioia data structure? Is “revisiting” and repeating analytic procedures driven only by discussion among the research team when “agreements about some codings are low” (Gioia et al., 2013, p. 22)? What role do analytic procedures play in moving “from cross-case comparison back to redefinition of the research question, and out into the field to gather evidence on an additional case” (Eisenhardt, 1989, p. 546)? How do researchers choose from the “variety of techniques” they use “for cross-case analysis techniques as they iterate across cases and at later stages, with the extant literature” (Eisenhardt as cited in Gehman et al., 2018, p. 292)?
In this study, we focus on coding as an exemplary analytic procedure and on its relation to iterativity in progressing analysis. Scholars who read qualitative articles published in management and organization studies will recognize coding as ubiquitous in the methodological accounts of these studies. Coding is commonly used and often appropriate and useful. Accordingly, Strauss (1987), one of the authors of the grounded theory tradition that emphasizes coding, argued that “the excellence of research rests in large part on the excellence of coding” (p. 27). Coding is also central to the Gioia method, often used in the Eisenhardt method, and entailed in several of the analytic strategies proposed by Langley (1999). Because coding is so commonly used in qualitative research, focusing on the way coding is used in projects allows researchers to understand more about iterating as a part of the analytical process. Thus, we here examine what people do when they do coding. This examination allows us to show iterativity in practice and how iterativity participates in theorizing. Based on what our analysis allows us to see, we propose conceptualizing iterativity as dependent on a sequentiality determined by the internal logic of a given project. We begin by discussing the practice of coding.
The Practice of Coding
In the practice of coding, we “symbolically assign a summative, salient, essence-capturing and/or evocative attribute” to a portion of data (Saldaña, 2009, p. 3) that applies to other portions or segments as well (Fielding, 2002). In everyday parlance, this is often thought of as putting comparable data segments into “buckets.” More specifically, coding signifies a range of actions for interacting with data across the span of a research project, through which names create links between data segments and ideas (Richards & Morse, 2013; Saldaña, 2016).
Coding entails the work of scrutinizing, pondering, and organizing collected observations and relating them to theoretically relevant abstract features, possible relationships, and research questions. Coding is used in both deductive and inductive research. It can be highly dynamic and fluid or comparatively fixed and linear (Locke et al., 2015). Of course, coding is not the only way to analyze data; it is one analytic procedure, and it is not uncontroversial (Saldaña, 2016; St. Pierre & Jackson, 2014). For example, scholars have challenged coding, claiming it is a “quasi-statistical analytic practice” (St. Pierre & Jackson, 2014) that rests on the application of a “naïve model of the natural sciences to human phenomena” (Packer, 2011, p. 9).
Acknowledging that coding has its detractors and that it is not the only way to analyze data, we suggest that some of this critique stems from an assumption that coding is a sufficient one-size-fits-all approach to analysis. Coding, however, is not a self-contained homogeneous practice. It can be focused in a variety of ways, such as descriptive coding, values coding, dramaturgical coding (Saldaña, 2014, 2015), and from the perspective of different ontological and epistemological traditions (Gephart, 2004), including functionalist (e.g., Holton, 2007; Lee, 1999), constructivist (e.g., Charmaz, 2006, 2007), and critical feminist perspectives (e.g., Clarke, 2005, 2006). It can take different forms at different points in analyses, for example in-vivo coding, focused coding, and axial coding (Corbin & Strauss, 2008; Saldaña, 2016) and first- and second-order coding (Gioia et al., 2003; Van Maanen, 1979). And it can be enacted top down from specific research questions and operationalizations to data (e.g., Krippendorf, 2018) or bottom up from lived experiences and actions to a theoretical narrative (e.g., Glaser, 2001).
We introduce a relational conception of coding to both capture this range of coding practice and help us see how coding relates to iterativity and participates in theorizing. Richards and Morse’s (2013) and Saldaña’s (2009, 2016) description of coding as implicating names, ideas, and observations provides a promising foundation for understanding what codes are and what the work of coding entails. We build on it to assert that the codes we produce are provisional analytic objects constituted relationally. By understanding codes as provisional objects, we recognize that codes are things that researchers bring into being for the purpose of using them in research. This is true for both inductive and deductive research projects. By understanding codes as constituted relationally, we emphasize that the code is a joint property of multiple elements. A given code, from this perspective, is constituted neither by the observations indicating it nor its name or the ideas it references; rather, a code is constituted in between them. Its status as an object relies on their joint custody, so to speak (Sidorkin, 2002). Constituting this relation among these multiple elements requires researchers to do active work.
Conceptualizing codes in this way helps us see their potential for generating the repeated performance of analytic procedures and, through this participation in iterativity, for keeping our analyses active and dynamic. As researchers make connections among observations, names, and ideas, adjustments in the code become possible through shifts in the meaning of codes, shifts in the observations included, and shifts in what the researchers understand about the project (Locke et al., 2015). Drawing attention to codes’ relationality, then, underscores their dynamic participation in the process of moving between raw and theorized data and thus provides a perspective to better appreciate how the performance of coding participates in the iterativity central to theorizing.
In this article, we show how coding is engaged in research projects—both inductive and deductive (so characterized by researchers)—in ways that are varied and dynamic. Based on this, we argue that although templates and these reifications of research traditions are useful, using them productively requires us to understand the process of iterating and how analytical iteration allows the logic of a research project to progress to a theorized conclusion. To accomplish this, we examined accounts of what people describe themselves as doing when they do coding. We analyzed articles published in four top-rated management journals and focused on the actions researchers perform when they do coding, the moments in which these actions are enacted as practices, and how these practices relate to iterativity.
Following an overview of our own analytic approach, we describe and show the coding practices articulated in articles that had especially rich descriptions of their analyses. We understand that even an especially rich description portrays only part of what takes place as researchers engage with their data, produce ways of organizing the data, and theorize using these ways of organizing their data. As such, the practices we present provide a way of seeing something that we have only begun to articulate and a glimpse at the ways in which coding and iterativity relate in analysis. In doing so, we enrich researchers’ understanding of coding as a practice and the relation between coding and iterativity.
Analytic Approach
We used accounts of data analysis in methodology sections of empirical articles published in top management journals to develop our understanding of coding practices and explore how coding is used in relation to theorizing. Our sample consists of 29 articles published in 2013 and 2015 in the following journals: Academy of Management Journal, Administrative Science Quarterly, Organization Science, and Organization Studies (see to Appendix A). We created this sample by searching the methods sections of each article for explicit articulation of coding. We used the search term, cod, to capture all forms of the word code, for example, coding, codes, and coded, and chose articles that used the term coding methodologically. This yielded 262 articles. We chose 29 articles whose articulated methods accounts contained “thicker” descriptions of what the researchers did when they created and used codes in their studies. This strategy maximized the sample’s richness of our focal phenomenon: articulations of coding practice (Patton, 2002). These articles included a range of research approaches, including hypothetico-deductive studies whose analyses were organized through the testing of formal articulated hypotheses and inductive studies whose analyses were organized by the ordering and interpretation of relatively unstructured observations.
Coding Actions
As we reviewed the methods accounts for authors’ descriptions of coding, we asked: What do people do when they do coding, and how do they use the coding to progress the particular theorizing they are engaged in? As descriptions accumulated, we noticed first that coding is carried out through a range of actions and that similar coding actions are used for different purposes. For instance, two common and recognized things people do when they code are engaging their data and engaging the extant literature. We illustrate in the following some of the range of coding actions involved in engaging the data and literature. By attending to how authors described their use of these actions, we noticed that summarizing them as “engaging the data” or “engaging the literature” barely scratches the surface of how these ways of coding are enacted in the research process. We focus on the breadth of coding actions reported in our sample, first as they relate to engaging the data and second as they relate to engaging the literature, to explore how the authors used coding in their research process. In subsequent sections, we focus on the way these actions are implicated in the unfolding logic of a research project and how they relate to iterativity.
Coding by Engaging the Data
Engaging with data directly is a signature activity of qualitative research, and researchers do so through a number of different actions as they pursue coding. These include: (a) engaging with the data directly as a source of ideas and labels to make codes, (b) generating artifacts as a way of organizing to do coding, and (c) putting patterns together across the data.
Direct Source of Making Codes
A hallmark of analytic practice in qualitative research is the making of codes through close engagement with primary data to generate relationships between data, ideas, and a label. Documented data include transcripts of interviews, observation field notes, and collected archival material (e.g., reports, emails, etc.).
As an illustration, Di Stefano et al. (2015) studied sanctioning behavior in the face of collaborative norm violations within the gourmet cuisine industry. They described the process of initiating their analyses through direct engagement with “187 pages of single-spaced transcripts” (p. 910) of interviews with chefs: “We began with in-vivo codes generated directly from the interview material …. Examples included ‘anger,’ ‘damage’’ ‘stop helping’ ‘stop talking’ and ‘gossip’” (p. 910). As their analyses progressed and they worked with the configurations of data, ideas, and labels implicated in these in vivo codes, the researchers identified ways in which these codes related to each other. This resulted in more code-making activity that allowed broader and more refined codes to be made from direct engagement with the data assembled across multiple initial codes. “For instance, ‘participation in social exchange’ included quotes referring to exchanges of knowledge, while ‘gossiping’ included quotes referring to instances in which chefs violated social norms and were denigrated by their colleagues” (pp. 910-911).
With an interest in organizational identity processes, Petriglieri (2015) studied what happens when executives’ relationships to their organization are destabilized through the latter’s wrongdoing. Interviews at British Petroleum following the 2010 Gulf of Mexico oil spill focused on eliciting executives’ accounts of their career and experience with the organization and the impact of the spill. An initial round of coding relied on executives’ own language and her descriptive characterizations to “identify common statements and group them into first-order codes” (p. 526) that sketched executives’ experience of and relationship to the organization through the crisis. “Feeling torn between conflicting emotions” is an example. Language that indexed feelings such as “torn” and “conflicting emotions” contributed to code making by bringing together data excerpts that pointed to ideas around particular emotional dynamics. This was one area of experience related to the crisis captured by her coding. Then, after many rounds of coding, she reengaged with concrete data in making more refined codes by relating emotional dynamics and executive identification with the organization.
In their study of how financial analysts’ framing repertoires shaped investor evaluations of those analysts, Giorgi and Weber (2015) gathered a 23-year sample of over 36,000 investment analysis reports. This sample represented reports generated by 32 analysts who had achieved industry recognition as “All-America Research Team” members and a comparison group of 62 who had not achieved that acknowledgement. To measure analysts’ framings in their reports and test their hypotheses, Giorgi and Weber needed to identify the framing dimensions and develop a coding scheme for them. After generating their comparative data set, they identified “dimensions and their associated categories” (p. 345). Each author independently engaged with a subset of 50 reports, scrutinizing their visible elements (e.g., headings, executive summaries) to identify the framing activities used. In this round, the authors made codes (tentative recurring dimensions such as focus, motivation), which they “compared and adjusted through discussion” (p. 345). They then asked a group of experienced investors how they characterize analysts’ reports, which was another avenue of direct engagement for making codes. The final set of made codes resulted from adjusting the initial round of codes based on these inputs and using them to code a sample of reports.
As the aforementioned examples demonstrate, researchers engage with the data to make codes at various points and cycles in the analysis process. Although this practice often occurs at the initial stages of analysis, it may also occur subsequently when codes are made from reading and labeling selected data that have been reorganized through prior analytic cycles and procedures. For example, Petriglieri (2015) made codes by engaging directly with data and then recoding concrete data as an outcome of prior coding processes to follow up on something she later recognized in her analyses.
Generating Artifacts as a Way of Organizing to Code
Researchers also draw on data directly to generate various analytic artifacts that affect their coding, including helping them decide what to code and how to code it. Any type of artifact—for example, writing memos, generating chronologies, creating figures, making lists, composing narratives—can do the work of informing and delimiting how to engage the data in a coding effort. Taking analytic actions outside of coding thus can shape the latter in at least two ways. They provide a means for researchers to look across a lot of data and generate noticings that suggest a potential analytic focus. Consequently, they help researchers decide what they need to code and what codes to make. Second, they provide a means for researchers to drill down and refine an analytic focus previously specified through coding.
In an example of engaging directly with data to generate analytic artifacts as a way of organizing to code, Smith (2015) described developing case studies from her data as an initial analytic move. To examine how top management teams of six strategic business units in a Fortune 500 company engaged strategic paradox in their decision-making, Smith reported that she “developed a rich case study for each strategic business unit, which incorporated various types of data…to describe the organizational context, exploratory and exploitative strategies, and a chronology of senior leadership challenges and responses” (p. 63).
This process of developing case studies as artifacts focused her analytic attention on particular and persistent issues that top leaders experienced as ones with which they were “constantly grappling” (Smith, 2015, p. 63). In addition, it highlighted the opportunity to examine the pattern of leader response to the issues over time.
Later in her analytic process, Smith (2015) generated a different analytic artifact to organize her coding. Specifically, she made a list of all the “emerging issues…defined as conflicts facing senior leaders involving both the existing product and the innovation.” Then, she made codes concerning emerging issues through her direct engagement with the leader’s descriptions of the conflicts “using short descriptions of invivo codes” (Smith, 2015, p. 63). Thus, Smith relied on producing at least two different artifacts from direct engagement with her data—cases and lists—to help her organize coding activities at different points in her project and for different coding purposes.
In another example, Reinecke and Ansari (2015) similarly generated a range of analytic artifacts as they worked to understand how actors navigate ethical complexity. They began their analyses of how actors come to collective agreement in the situation of setting “fair” prices on certified Fairtrade products by creating weekly analytic memos, chronological case histories for three pricing projects, and tables of observed events and themes. The action of producing these analytic artifacts helped them to generate noticings and questions that enabled them to use coding to home in on the analytic importance of argument practices: “The development of chronologies revealed the ongoing struggles of participants…. We noted that stakeholder processes were organized around certain judgement criteria that deliberants followed to render their arguments fair and valid” (p. 873).
As was the case in directly engaging the data to make codes, engaging the data to generate other analytic artifacts can happen at any point in the analytic journey. For example, artifacts may be made to initiate analyses as Smith (2015) and Reineke and Ansari (2015) described, or they may be made later in the analytic process as Smith (2015) recounted.
Putting Patterns Together Across the Data
Researchers put together patterns of observations expressed across codes and other data engagements to make their codes meaningful. Putting patterns together is an important source of ideas that inform researchers’ theorizing.
One way this is achieved is by relating codes to one another through what is often termed axial coding. Another way is by engaging with the data to connect patterns that emerged from coding with other patterns discerned in the data whether through coding or a different analytic process. For example, in her study of how two professional groups were affected by a mandated change process, Huising (2015) used coding to bring forward similarities and differences that she had a sense of but “could not articulate clear[ly] prior to my coding” (p. 270). She described the process of arriving at clarity about a pattern of differences between the groups by examining similarities and differences across codes to generate broader categories that were then developed through axial coding (returning to the data to fill in properties and dimensions). “For example, issues of group membership, hierarchy, and division of labor were bundled into a broader category of group organization.” As these categories emerged, she used axial coding to “identify the properties and dimensions of each, clarifying the similarities and differences between [the two groups] by category” (p. 270). Her theorizing was supported by bringing this pattern of similarities and differences in relation to a second pattern related to clients’ responses to the groups’ enactment of the mandated change process. Engagement with her data showed that one group lost “control of significant aspects of their [work] jurisdiction whereas the [other group] did not, because managers received complaints about the work of [one] but not the [other]” (p. 271). Understanding how these two patterns related through complaints then become a larger question to pursue that was meaningful to her project.
Another example of engaging with data to connect patterns across the data is evident in Mazmanian’s (2013) 3-year study of how mobile email devices were enacted within and across two occupational groups (sales and legal) in a footwear and apparel company. She noted that her analyses began with direct interaction with her data including interview transcripts, email responses, and field notes. Through open coding, she generated “dominant categories and sub themes” (p. 1231), making an initial set of working codes. This process led her to identify a pattern; she “noted that the lawyers’ attitude about BlackBerrys was initially positive but became increasingly negative over time, while the sales representatives were more diverse in initial impressions but became increasingly positive” (p. 1231)
Mazmanian (2013) reported that this led her to reengage her data by examining more closely the extent to which attitudes and patterns of use “were aligned within groups” (p. 1231). Her first pattern then related to attitudes and use across groups. Doing so, she found that “attorneys described similar patterns of communication with the device and shared assumptions about how others were using it.” This was not the case for the sales representatives, who “throughout the life of the study…varied in how they described using the mobile email device and asserted that everyone used the device differently” (p. 1231). With this recognition, in the next step, she reengaged her data with an eye to theorizing the key dimensions of this difference. She recoded her data, looking for broader “categories that could account for the homogeneity in interpretations and use among the legal team and the heterogeneity among the sales force” (p. 1231). Reengaging her data to connect two patterns of use—one across groups and one within groups—moved her analysis along.
Coding by Engaging the Literature
Although concrete data themselves are important sources of ideas and labels to make codes, researchers also reach into the literature for ideas and labels to bring to their engagement with the data. Scholars engage the literature in many ways in relation to coding throughout the process of a research project. We note three broad uses: (a) the literature as a direct source of codes independent of engaging with the data, (b) the literature as a source of definitions and concepts that help delimit the field of/sensitize researchers to possibilities in their data, and (c) the literature as a source of ideas that researchers use to help make sense of and theorize about the categorization schemes in the project.
Direct Source of Made Codes
Sometimes the literature is a direct source of codes used to organize the data. For example, in their study examining the relationship between women serving on boards and firm performance, Post and Byron (2015) drew closely on the literature to identify constructs for making their codes for board-monitoring activities. We used a coding system based on Eisenhardt (1989) to categorize each measure of board activities…. Because boards’ monitoring mechanisms (i.e., the specific processes through which boards keep managers aligned with shareholders) remain elusive in the strategic leadership literature (Finkelstein et al, 2009), we conformed to the existing literature, which has often relied on proxies for monitoring (e.g., number of board meetings). (p. 1554)
In their examination of a failed and a successful attempt to introduce pay TV to the United States as instances of entrepreneurship in regulated environments, Gurses and Ozcan (2015) highlighted the use of literature as a direct source to code their “two main categories of analysis.” In what they referred to as Phase 2 of their analysis, they drew on the literature to code their generated case histories: Once the case histories were finished, we began to compare them, looking for variance in the descriptions of how the OTA pay TV and cable TV operators acted (both individually and collectively) as they attempted to legitimize their product. Here, we used theory and empirical evidence from prior studies (e.g., Gu´erard et al., 2013; Hargadon & Douglas, 2001; Rao, 1998) to identify two main categories of analysis that we were interested in: framing and collective action. (p. 1715)
In their study of learning from safety errors in the Italian air force, Catino and Pariotta (2013) started their coding process with descriptive codes that “comprised the five conceptual categories driving the research. These included learning, error, cognition, culture, and emotions.” After developing these codes “through dictionary work and inductive reading of the data transcripts,” they turned to the literature as a direct source of codes: Drawing on the existing literature, we further specified the codes within each broad category (analytical codes). For example, we considered different types of information processing (routine/mindful); we classified emotions in terms of timing, valence, and intensity; we looked at selected aspects of organizational culture such as attitudes towards error and blame, and attitudes towards safety. (p. 445)
Delimiting the Field as a Way of Organizing to Code
A second way the literature can be used in coding is to delimit the field in preparation for engagement with the data. Used this way, the literature is not a direct source of codes but rather helps researchers identify what observations to look into further and bound what observations to scrutinize in their coding. For example, to delimit the field for coding, Heaphy (2013) relied on the research of ethnomethodologists and the importance ethnomethodological analysis places on the process of breaching rules and repairing these breaches. Focusing first on rules, she developed four analytical questions that she used to create inductive codes that answered these questions. She followed that analysis with a second phase that drew more explicitly on the concept of breach in ethnomethodology to further delimit her focus on the data: In the second phase, I introduced an ethnomethodological approach to analyzing the data, specifically examining each of the 108 situations identified above as breaches…. I asked the following analytic questions of each situation, now conceptualized as a breach, which I developed based on the recommendations of Feldman (1995): Who is experiencing a breach? What is the breach? How is the patient advocate responding to the breach? Did the rule use maintain or change local contexts? Did the rule use attempt succeed or fail? This analysis revealed six different types of breaches. At this stage, I had identified that patient advocates were using rules as tools in the repair of breaches. (pp. 1297-1298)
Putting Data and Literature Patterns Together
The literature is a source of ideas that researchers use not only to make codes and delimit the field but also to help make sense of and theorize from categorization schemes used to code their data. Theorizing from categorization schemes often involves relating codings to conceptual categories of interest to the broader academic community. In one expression, the patterns of ideas expressed across literatures are used to derive hypotheses that will be operationalized and then tested through coding. Their meaningfulness to the academic community is established through this process. For example, in their study of leadership selection criteria, Jacquart and Antonakis (2015) developed their third hypothesis by juxtaposing the literature suggesting performance as the main criterion with the literature suggesting charisma as the main criterion: Hypotheses 1 and 2 depend on two types of information signals: performance (i.e., outcomes) and behavioral (i.e., charismatic). We believe that these two signals interact with each other. The clearer the performance signal, whether positive or negative, the less likely charisma will matter for leader evaluation and selection. Charisma will matter less because selectors have what they believe is concrete evidence of a leader’s competence (or incompetence). (p. 1054)
An example of using the literature to make sense of coded observations involves taking an idea from the literature and using it as a sensitizing concept to provisionally theorize codes. In their study of how members of the “Track Town” community reenergized a valued identity after years of decline, Howard-Grenville et al. (2013) reported on the use of “carriers” as a sensitizing concept that helped them provisionally conceptualize a pattern that had emerged through their coding process: Coding alerted us to the importance of specific identity referents and to the classes of actors that referenced, connected, or produced such referents. Following Glynn (2008), we initially used Scott’s (2003) term “carriers” as a sensitizing concept to refer to symbols, ideas, events, and people that appeared to help the identity “move from place to place and time to time” (Scott, 2003, p. 879). (p. 119) Scott distinguishes carriers of four types—symbolic systems, relational systems, routines, and artifacts (2003). Whereas the term “carriers” connotes largely inanimate receptacles for identity content and referents, our developing understanding of the resurrection process led us to regard identity as propelled by both tangible and intangible resources that agents draw into use, and by experiences that regenerate identity-relevant understandings and emotions. Intangible resources in our analysis include symbols and relational systems (defined as “connections between actors, including both individual and collective actors” [Scott, 2003: 886]) that are tapped and regenerated through experiences. Tangible resources (financial, human, and physical) also fuel the generation of experiences, which in turn attract further tangible resources. (Howard-Grenville et al., 2013, p. 119) I wanted to understand why the same clients responded differently to these two groups. I returned to my data and analysis to examine why researcher complaints surfaced for the BIOs when so few surfaced for the RADs. I considered the “objective,” or immutable, qualities (Abbott, 1988) of their jurisdictions, such as the materials, their legal mandate, or their clients, that might affect the professionals’ abilities to control their clients or their clients’ responses to their work. I also considered the “subjective,” or mutable, qualities (Abbott, 1988) of their jurisdictions that might affect the professionals’ abilities to control their clients or their clients’ responses to their work. I used an iterative, comparative approach to understand differences in the professionals’ relations to their clients. Through this process, I identified similarities between the groups and differences that affected each group’s ability to manage clients’ responses. (p. 271)
Coding Practices: Actions in Moments
Our exposition suggests that these commonly acknowledged coding actions can be enacted in a range of ways in a research project and for different purposes. Here we refer to these goal-differentiated points of a research project as moments. The moments we have identified are making codes, organizing to code, and putting patterns together. Moments are important because they affect the impact of a coding action on a research project. Although the specific actions taken in the process of coding may appear similar (e.g., categorizing the data or drawing on the literature for codes), if they occur in a different moment of the project, their effect on the project is different. In addition, our examination of coding actions pointed to other coding actions that participate in analyses such as training coders and assessing codes for fit. With this in mind, we describe the work that takes place in each of the three moments we have identified.
Making Codes
Engaging the literature and data directly are important avenues for making codes, that is, for naming a relation between a set of data and ideas, thereby creating working analytic objects. There are two central questions in identifying code making actions: Where do researchers find names that characterize their data? and What actions do they engage in to create and modify these names? Although code making often occurs at the initial stages of analysis, coding actions involved in making codes may occur at different points in a given project’s analytic journey. Furthermore, as noted, the sample of studies we examined brought forward other actions besides engaging the literature and observations involved in the moment of making codes. For example, authors often reported engaging in discussion. Through coding, authors often found discrepancies in the data, idea, label relation that either require agreements to settle understanding or lead to further exploration of ideas (e.g., Kish-Gephart & Campbell, 2015; Kreiner et al., 2015). They also specified and refined prior made codes. Inevitably, codes are made and remade over the course of progressive rounds of coding as the ideas they reference are clarified and labels are adjusted (e.g., Brown et al., 2015; Petriglieri, 2015). Another action is using decision rules. Deploying analytic questions or extant protocols to make codes in a specific coding effort can provide clarity on a subset of data (e.g., Heaphy, 2013). Authors also assessed the fit of made codes. Different procedures were sometimes used to evaluate the fit in relation between data, ideas, and labels (e.g., interrater reliability tests, Schilpzand et al., 2015; individual check-coding, Canato et al., 2013).
Organizing to Code
The moment of organizing to code is distinguished by the effort to prepare for a given coding exercise within a project. This moment involves coding actions that generally precede and structure a given coding exercise. Among the studies in our sample, in addition to engaging the literature and data to delimit the field and generate other analytic artifacts, researchers sometimes engaged in training coders as an action to ensure the relations established between labels, data, and ideas will be reliable and justifiable (e.g., Goncalo et al., 2015; Jacquart & Antonakis, 2015). And as was the case for making codes, organizing to code may occur at different points in the analytic journey at an initial coding exercise, or as researchers engage in subsequent rounds of coding precipitated by new noticings or new questions, or as they refine or stabilize codes.
Putting Patterns Together
Finally, putting patterns together, whether across the data, across the data and literature, or across literatures, is oriented to explaining how patterns of observations and ideas expressed in codes come to be grasped and understood as important and interesting to the broader organization studies community. It is, thus, central to theorizing.
In Table 1, we summarize these moments and list coding actions often used in each moment. We refer to coding actions in coding moments as coding practices. Table 1 is not intended to be a comprehensive list of coding practices. Rather, we offer it here to make the point that coding actions taken in different moments have different implications for research projects.
Coding Practices.
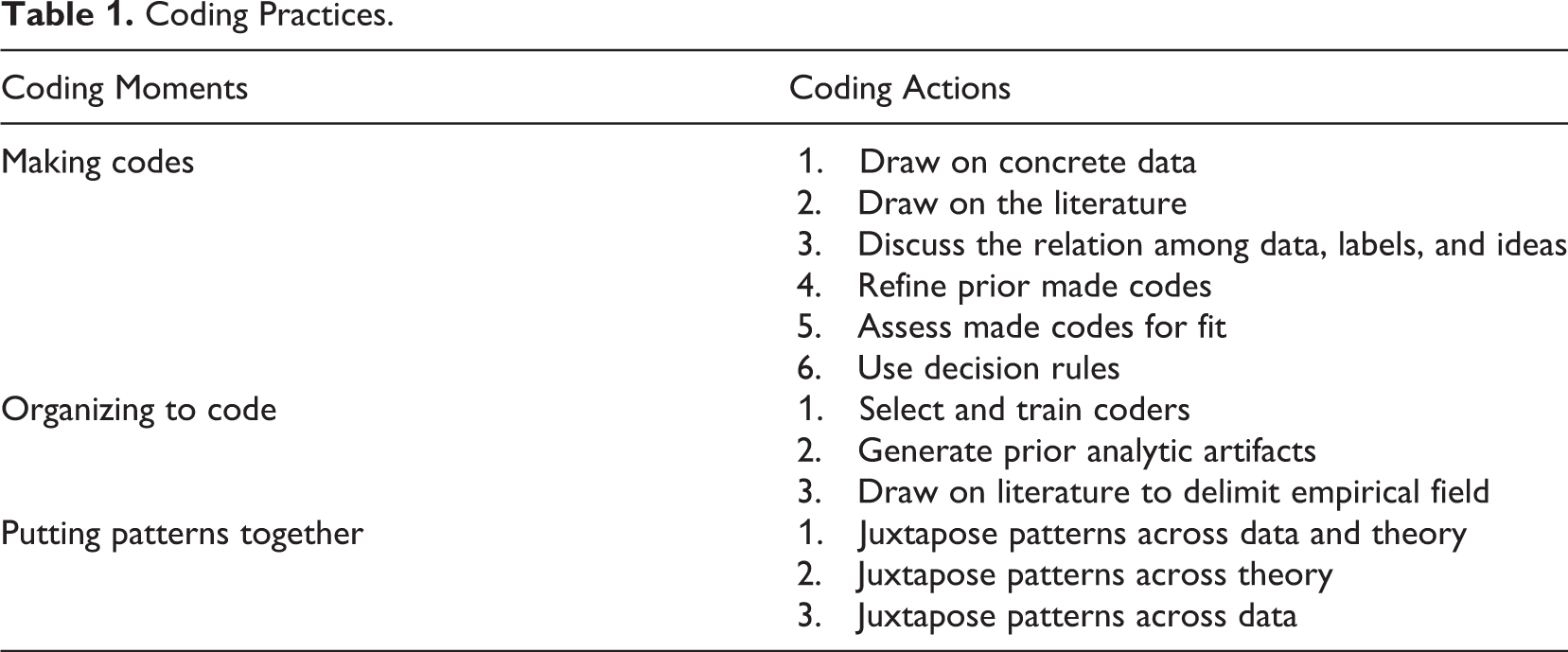
Because it is impossible to tell all that is entailed in any given analytic journey and create a coherent narrative for an inherently complex and messy process (Turner, 2014), we have no doubt that coding actions are even more varied than those outlined previously. Next, we reengage these practices (actions in moments) to demonstrate iterativity, exploring how coding relates to the unfolding logic of the project. To do this, we use three different research projects that provide different demonstrations of sequencing. We show iterativity as enacted through coding practices happening at any point and importantly, at multiple points in particular projects.
Coding in the Unfolding Logic of Projects
How do researchers engage coding as they move through a research project working to arrive at a stable set of concepts used in theorizing? And how does that work itself progress theorizing? We recognize that what actually happened in each project is almost certainly much more complex than what the researchers reported in the methods section. Nonetheless, we find that tracing the sequences of reported actions already indicates considerable complexity. One might, at first blush, assume that there are two main sequences of coding moments corresponding to deductive and inductive research. That is, inductive projects follow the sequence of organizing to code, making codes, and then putting patterns together and deductive projects follow the sequence of putting patterns together (for hypothesis creation), organizing to code, and making codes. However, this is not what we found. Rather, each of these moments may occur at any time in the research process. Furthermore, authors reported using coding actions associated with all three moments, repeating practices as they worked to develop their codes.
Table 2, for instance, presents a segment of the moments and practices in Giorgi and Weber’s (2015) hypothetico-deductive investigation of how financial analysts’ framing repertoires shaped investor evaluations. Their analysis to test five hypotheses regarding how framing impacts audiences begins with putting patterns together via the hypothesis generation process. It next moves into making codes and then into organizing to code before another cycle of making codes. Within this analysis, the practice—assess made codes for fit (A5)—recurs in different cycles (first during an initial set of efforts to make codes and later after organizing to code) as the researchers worked to stabilize them for use in testing their hypotheses.
As noted previously, this is not the linear sequence of putting patterns together, organizing to code, and then making codes that we would expect code development to follow in a hypothetico-deductive study. Instead, moments are enacted repeatedly. In addition, whereas we might expect codes to be made by drawing on the literature, that is, by establishing a priori the ideas and names for observations, codes are in fact made by drawing on concrete data through four different coding practices (A1, A3, A4, A5). Thus, this project does not follow the expected top-down sequence of a hypothetico-deductive study with respect to either the sequence of coding moments or the source of code development.

In another example, Table 3 excerpts part of Smith’s (2015) analytic work to discern how senior leaders engage with paradox in their decision-making by moving from raw data to theoretical interpretations. Such an inductive model suggests a bottom-up sequence of coding moments. At first glance, it appears that Smith did follow such a model beginning with organizing to code and moving then to making codes. But as the excerpt indicates, although practices associated with making codes followed from organizing to code, practices for making codes also informed and generated repeated rounds of organizing to code as she progressed her effort to understand how senior leaders approached and enacted their decision-making. Generating prior analytic artifacts (B2) as a way to focus her coding occured repeatedly as she first developed a case study and then in a repeated cycle of organizing to code assembled a list of the emerging issues her managers faced. The expected sequence of moments breaks down as moments reciprocally shape each other. Furthermore, examination of her coding practices indicates there is no pure bottom-up sequence that begins with drawing codes from raw observations and moves to generalization through a unidirectional sequence of steps. The practices of making codes by drawing on concrete data (A1) and the literature (A2) occured repeatedly, even within a particular moment of code making. Thus, in one cycle of making codes, as she sought to stabilize her understanding of how senior leaders responded to the listed issues they faced, she engaged with concrete data (A1) and the literature (A2) repeatedly, moving between them to arrive at a stable set of practices to theorize how leaders effectively deal with paradox.

Giorgi and Weber (2015) and Smith (2015) progressed their theorizing through iteration of coding practices that achieve stability. They did this by creating and naming conceptual elements necessary to build their explanations of how framings impacted investors’ evaluations of analysts and of how senior leaders engaged with paradox. In contrast, in their inductive study, Brown et al. (2015) progressed their theorizing when the stability they were iteratively working to establish was disrupted, causing a shift in their understanding of their phenomenon. Their account of the external and internal drivers of institutional change demonstrates how disruption helped to identify what became the key insight of their research—that human capital bargaining power is a key mechanism that integrates internal and external drivers of change.
As Table 4 indicates, through two rounds of coding and data gathering, Brown et al. (2015) worked to identify and refine their key drivers of change at the hospital they studied. That is, they worked to arrive at a comprehensive and stable set of change drivers. Following the second round of data gathering and making codes (A1, A6, A4, A1), they had generated a set of distinct internal and external drivers of change. Yet, by engaging in further rounds of data gathering and making codes, new observations with attendant codes brought a different perspective on institutional change. In highlighting the central role and bargaining behaviors of physicians, these new codes represented a different pattern relative to the change process. Thus, the interaction of prior stable and refined codes with different codes emerging in the third and fourth rounds of interviewing and coding challenged the established and refined pattern of change drivers; this provided an opportunity to adjust their research question (A1, C3, C1). Putting together the ideas implicated in the two patterns of change drivers (C3) and relating them to the literature on bargaining power (C1) altered their understanding of the change process. Specifically, it helped shift their focus to physicians as “a fulcrum in the patient placement process” and enabled them to conceptualize how internal and external drivers of change operated within, not as a separate process. Their systematic efforts to stabilize the initial coding analysis that developed the focus on drivers of change created a basis for new observations to challenge subsequent analysis. In turn, the process of repeatedly making codes from further rounds of observations shifted and progressed their theorizing. Again, we see that movement through prior moments shape the unfolding logic of the project, influencing what it is possible to do and to see in subsequent moments.

In these three examples, we see two expressions of how iterativity progresses theorizing. In one expression, instanced by Giorgi and Weber (2015) and Smith (2015), iterativity in the multiple practices and moments necessary to develop stable codes resulted in new conceptual elements to inform their theorizing. In a second expression of how iterativity progresses theorizing, instanced by Brown et al. (2015), we see how the effortful work to fix relations results in stabilities that through their disruption yield new perceptions of observations and new associations and distinctions. This analytic work progresses theorizing by developing new questions, that is: How do physicians operate as a fulcrum for the change process?
Iterativity as Theorizing
Our analysis of coding in the unfolding logic of projects reveals what researchers do when they iterate through coding. As defined in the introduction, iteration is enacted through the repeated application of analytic actions—for example, from the repeated action of coding actions or other analytic actions that are prompted by or that inform a round of coding—and through the active work of pursuing the questions and noticings that arise in and from this analytic work with yet more analytics actions. Iterativity is enacted when analytic activities (e.g., coding practices) provide emergent conceptual products or result in adjusted or new questions that aggregate over time to bring into focus some phenomenon of interest. Consequently, iterativity advances the mundane everyday work entailed in developing explanations, that is, in theorizing (cf. Isaac, 2010; Swedberg, 2014; Weick, 1995, 2014).
In this section, following from our analyses, we make three claims about coding practice that enrich extant understanding of iterativity as theorizing. First, there is no set sequence of coding practices that can be imposed externally to the project. Instead, the sequence of coding practices unfolds within the logic of the project. Second, we suggest the term progression as a way of describing the sequencing of analytic practices in a way that moves projects toward theoretically satisfying understandings. Third, we note that progression occurs through the active work involved in iterating.
Coding as Relational Process
Contrary to the idea of a template, we do not find a priori established sequences of coding practices. Instead, we found a relational process that entails moving from a current understanding of the relation of names, ideas, and observations in a project to a next understanding. The sequence of coding practices discerned in the articles analyzed cannot be determined externally, for instance, by following a template or path suggested by a particular research logic. Our analysis shows that although coding practices follow a sequence in any given study, the sequence is not fixed, for example, for a hypothetico-deductive study or an inductive study. Thus, our analyses of the progression in Giorgi and Weber (2015)—a “hypothetico deductive” study—demonstrated several rounds of code making and engaging concrete data. Our analyses of progression in Smith’s (2015) “inductive” study demonstrated repeated cycling between engaging with concrete data as well as theory in code making.
There were certainly differences between hypothetico-deductive and inductive studies. In the articles we looked at, for instance, deductive researchers were more likely to report engaging in putting patterns together prior to coding, whereas inductive researchers were more likely to report engaging in putting patterns together after coding the data gathered as part of the specific project. But there was not a fixed starting coding moment that began the process. Similarly, in deductive projects, provisionality appears as comparatively contained when coding is related to the development of particular variables for specific hypotheses, and therefore, iterativity is dampened. But in the projects we reviewed, iterativity both is present and did not necessarily follow expected sequences. Thus, our analysis highlights the unfolding logic of projects and the progression toward stability of analytical objects rather than the directionality implied by templates (e.g., top down or bottom up). Our discussion and illustration of coding as it relates to the unfolding logic of projects highlights that prescribing set analytical sequences does not reflect the active work that people do when they use coding to progress analyses.
Progression Toward Theoretical Understanding
We use the term progression to denote the active work of accreting understanding within a project. For instance, what are you learning from the analytic practices you are performing? How might what you are coming to understand be of value to the broader community? What analytic practice might you do next to get better purchase on this? Sequence denotes a particular order in which related events, movements, or things follow each other in an externally given order. By contrast, progression implies the dynamism through which developing understanding of the project becomes the perceptual ground out of which the next analytic practice arises (O’Kane et al., 2019). For example, our analysis of the multiple analytic rounds it took for Smith (2015) to arrive at the codes that explained the practices of senior leaders in the face of paradox suggests that within projects and the work of coding, there is progression rather than fixed sequence.
Iterating Through Active Work
The process of iteration supports progression as it entails not only moving forward but also a deep awareness of what has come before (prior codes, prior understandings, and prior analytic activities) and where we are now. What we see articulated in our examples as progression is movement from “I did this” to “now I understand that” to “as a result of understanding that, I took the following next step” to “as a result, of taking that next step I….” Doing something next matters. As Agar (2010, p. 289) noted, the next analytic step “at time n + 1” is a function of what was noticed, learned at “time n.” The choice of the next practice is based on where the project is and what the researcher understands about the project from what has been done before. Accordingly, it matters less where researchers start. What matters in progressing analytic work is what researchers do next (as a result of what happened from what they did before).
As we showed in the previous section, this movement is enabled by the active work central to our conceptualization of codes as provisional objects (Knorr Cetina, 1997; Rheinberger, 1992, 2011). For instance, in Brown et al. (2015) their active work produced new data and new codes that disrupted their understanding of the phenomenon (that change drivers were structured by an internal/external distinction) and required that they reconsider this prior understanding. And in Giorgi and Weber (2015) and Smith (2015), although their understanding of the phenomenon did not shift, their active coding developed new concepts that helped them answer their questions. Specifically, they stabilized codes only after enacting multiple rounds of coding practices.
Drawing attention to codes as provisional relational objects, then, underscores their inherent instability and the active work that researchers do to bring forward new meanings and eventually to stabilize meanings for the purpose of theorizing (Knorr Cetina, 1997; Rheinberger, 1992, 2011). With respect to coding, this active work provides the basis for making shifts in the meaning of codes, shifts in the observations included, and shifts in what the researchers understand about the project (Locke et al., 2015). In this way, our analysis shows how iterativity is central to how one’s actions in the process of coding engage provisionality to create stability in the constellation of names, ideas, and observations. When these actions provide emergent conceptual products or result in adjusted or new questions that aggregate over time to bring into focus some phenomenon of interest, iterativity in these coding practices advances the mundane everyday work entailed in developing explanations, that is, in theorizing (cf. Isaac, 2010; Swedberg, 2014; Weick, 1995; 2014).
Conclusion
In our project, we described the analytic work accomplished iteratively through the lens of a particular analytic procedure—coding. Iterating coding practices within the unfolding logic of projects means that there are many paths to the kinds of insights that are the hallmark of articles published in top management journals. There are also many ways in which the coding practices we identified can be put to use as part of the analytic process of any given study. Our work demonstrates that there is no one way to code and that there may be no way to prescribe the order for deploying coding practices within a particular study.
The question arises, then, what guidance do we offer researchers? First, we have emphasized in elaborating coding practices that those we describe are necessarily incomplete. Yet, the practices are a useful starting guide to coding possibilities for researchers. Second, the article focuses on coding, bringing it forward as an analytic practice. It would be a mistake, however, to take from this that coding is a particularly privileged analytic practice or that it is the only practice that drives iterativity. Certainly, coding is a useful and regularly used procedure. However, we might have selected other analytic practices such as making visual diagrams (Langley & Ravasi, 2019), generating matrix displays (Miles et al., 2014), or memoing (Emerson et al., 2011) as the procedural lens through which to analyze iterativity and the progression of our theorizing efforts. Indeed, one of the implications of the moment, organizing to code, is that using analytic practices different from coding enriches coding. Thus, as researchers, the richer our arsenal of analytic practices—that is, the more things we have available with which to take the next analytic step—the better able we are going to be to progress our theorizing. Third, although we recognize that the practices and sequences for using them suggested by templates offer a degree of comfort, they also may prevent researchers from engaging with the internal logic of the project. Our final guidance is to engage analytic action within a given project’s unfolding internal logic. The internal logic of the project does not speak itself. We have to ask repeatedly, what did this last analysis suggest about my research? What do I need to understand better about it? What analytic action(s) can I take that will help me accomplish that?
Our analysis provides insights into how this iterativity is accomplished in specific research projects. We have used the rich articulations of authors’ coding practices to demystify one of the most common analytical practices and make more transparent the process of iteration involved in analyzing and theorizing. We have developed the notion of coding moments as a way of categorizing coding actions and identified and illustrated several specific coding practices. Our analysis of coding practices and exposition of their heterogeneity draws attention to the active work of analysis that is integral to the injunction that qualitative analysis involves iteration. By showing how others progress their analysis by engaging in the unfolding logic of their projects, we expose the inner workings of the iterative process that is so central to qualitative research. We offer these insights in the hopes of providing authors some guidance about both what they can do when they are engaged in analytical practices such as coding and what these practices can do for them.
Footnotes
Appendix A
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.