
Abstract
Purpose:
The present study investigates the suprasegmental reflexes of code-switching, considering both language context (i.e., language mode) and language dominance.
Design:
To this end, an experimental oral production paradigm was administered to 14 Spanish-English bilinguals, comparing code-switched to non-switched productions and varying both context (monolingual or bilingual) and response language (dominant or non-dominant).
Data and Analysis:
Productions were analyzed for two suprasegmental features: pitch height and stressed vowel duration.
Conclusions:
Results indicate a significant effect of code-switching on suprasegmental production, with code-switched tokens produced with overall greater pitch movement and duration relative to non-switched tokens. These effects, however, were modulated by both language context and language dominance.
Originality:
Given the relation of prosody to cognitive factors, this novel approach to the suprasegmental features of code-switching, specifically considering language dominance and context, provides a unique opportunity to further the understanding of the underlying language switching process.
Significance:
These findings are addressed within a theoretical framework of predictability and hyper-articulation, and it is suggested that the suprasegmental realizations of code-switched tokens correspond to a degree of contextually driven predictability.
Introduction
While bilinguals are able to communicate effectively in either of their two languages, one of the more salient features of bilingual speech is the ability to switch between languages within a given conversation or even within the same utterance. Code-switching (CS) can be broadly defined as the usage by bilinguals (or multilinguals) of at least two languages during the same interaction. These language switches offer an opportunity to investigate both of a bilingual’s two languages, as well as the interaction between those two languages, and serves to provide additional insight into language processing mechanisms that may be unavailable in monolingual populations.
Although CS has been well studied from the social (e.g. Zentella, 1997) and syntactic perspectives (e.g. Pfaff, 1979), the phonetic reflexes of these switches have remained relatively underexplored, most noticeably at the suprasegmental level (Bullock & Toribio, 2009). While investigations at the segmental level have focused predominantly on notions of transfer, given that the suprasegmental level reflects cognitive constraints, namely through an inverse relationship between prosodic prominence and predictability (Aylett & Turk, 2004), an examination of prosodic features provides unique insight into the language switching mechanisms not otherwise available at the segmental level. Furthermore, the position of a bilingual along a language mode continuum (Grosjean, 1998), from monolingual to bilingual production in a given interaction, may serve to modulate these prosodic reflexes.
The current study, employing a controlled production paradigm, examines the effect of CS on phonetic production at the suprasegmental level, while considering the effects of language context (i.e. language mode) and language dominance. The results are discussed within a framework of both hyper-articulation (Lindblom, 1990) and predictability (Aylett & Turk, 2004).
Literature review
The terminology used to describe the languages in intrasentential CS has varied among authors. Macnamara (1967), for example, distinguishes the base language, or utterance initial language, from the guest language. Rather than drawing on the utterance initial language, the matrix language frame (MLF) model distinguishes the languages of CS based on the number of morphemes in a given utterance or discourse from each language (Myers-Scotton, 1993). According to the MLF, the approach adopted for this study, a code-switched utterance may be divided into the matrix language and the embedded language. The matrix language is defined as the language in an interaction from which the greatest number of morphemes is drawn. The embedded language refers to the other language or languages that are used in the interaction, but with a lower frequency. Cross-linguistically, and relevant for the current study, the most common realizations of insertional CS involve the embedding of a single noun or noun phrase in a matrix utterance (for a review see Chan, 2003; for Spanish see Poplack, 1980). Furthermore, research has demonstrated that CS is an intentional practice (e.g. Zentella, 1997), is used for a number of pragmatic functions (e.g. Gumperz, 1982), and is representative of highly proficient bilingual abilities (Poplack, 1980).
Code-switching and phonetic production
As has been noted previously, CS offers an opportunity to investigate phonetic interaction between a bilingual’s two languages given the “interlanguage interaction” that occurs in CS (Antoniou, Best, Tyler, & Kroos, 2011, p. 561). To that end, the vast majority of studies have focused on the effects of code-switching at the segmental level. The initial focus in this line of investigation has been to determine if switching languages results in a “complete” switch in phonetic systems, or if there is a degree of phonetic transfer, with one language influencing the production of the switched token. Beginning with Grosjean and Miller (1994), this line of research has frequently exploited inter-language differences in voice onset time (VOT). VOT corresponds to the lag between the release of a stop consonant and the onset of vocal fold vibrations (Lisker & Abramson, 1964), and significantly differs cross-linguistically (e.g. French short-lag voiceless stops: range 0–30ms; English long-lag voiceless stops: range 30–120ms). This limited body of research has produced a variety of differing findings. Specifically, findings have included: no phonetic interaction resulting from CS (Grosjean & Miller, 1994); unidirectional transfer, perhaps constrained by inherent phonetic principles (i.e. long to short-lag transfer: Bullock, Toribio, González, & Dalola, 2006); and bidirectional convergence (Bullock & Toribio, 2009). Furthermore, alluding to the potential impact of language dominance, Antoniou et al. (2001) characterize their findings as indicative of first (L1) to second (L2) language transfer. 1
However, noticeably absent from this line of research has been the suprasegmental level, with a limited number of studies addressing the topic. While a number of authors have worked to detail the intonation patterns of bilinguals in non-switched contexts (e.g. Spanish–English: Penfield & Ornstein-Galicia, 1985; Canadian French–English: Cichocki & Lepetit, 1986; Catalan–Spanish: Simonet, 2008; Dutch–Greek: Mennen, 2004), contexts of CS have received less attention. From a production standpoint, initial work on the study of suprasegmental features of CS paralleled that of the segmental level, seeking to determine if a switch in language at the lexical level implied a switch at the suprasegmental level. These studies, descriptive in nature, examined limited contexts and found distinct results. For example, in an examination of German–Turkish bilinguals, Queen (2001) found that German question words inserted into Turkish matrix utterances were produced with German intonation patterns. Additionally, when Turkish question particles were inserted into German utterances, they were produced with Turkish intonation patterns. In contrast, in the description of a limited number of switches in a listing environment produced by Portuguese–German bilinguals (Birkner, 2004), opposite patterns were found. Specifically, switched tokens were produced with the intonation contours of the immediately preceding language. Although these studies examined the presence of language-specific contours, potentially in isolated intonational phrases, they do not report on other prosodic features.
While previous research, both segmental and suprasegmental, has focused exclusively on examining inter-language interference (i.e. complete switch vs. transfer), we may not necessarily expect similar outcomes at the suprasegmental level. Prosody, including intonation and duration, is clearly language specific; however, it is also a sensitive indicator of a variety of constraints and speaker intentions. 2 Crucial for the current study, prosody is also subject to cognitive factors (e.g. predictability: Aylett & Turk, 2004; Turk, 2010), with speakers modulating prosody, such as producing louder, longer syllables with greater intonation modulation, in response to such difficulties. As such, it is relevant to consider not only the language-specific prosodic features, but also the other suprasegmental patterns that may emerge during the production of CS, to gain insight into these cognitive factors.
To that end, Olson (2012) examined the suprasegmental phonetic production of English CS tokens embedded in Spanish matrix utterances produced by early Spanish–English bilinguals. Comparisons between the only English and only Spanish control stimuli and the insertional CS stimuli revealed significant differences in the phonetic production of the CS constituent at the suprasegmental level. Specifically, results demonstrated that CS tokens were produced with a significantly greater fundamental frequency (F0) and stressed vowel duration than their non-CS counterparts. These results were tentatively taken as evidence of a hyper-articulation of the CS token at the suprasegmental level, driven by decreased predictability (Olson, 2012). While Olson (2012) was one of the first to investigate suprasegmental reflexes of CS, these results failed to take into account both language dominance, having examined only early balanced bilinguals, and language mode. As such, the current study seeks to expand these previous findings in a late bilingual population, while simultaneously considering the role of language dominance and language mode.
Language mode
While the analysis of CS, and particularly that of suprasegmental features of CS, may provide unique insight into bilingual speech behavior, any study of bilingualism must account for the variable linguistic expectations of a bilingual speaker (e.g. Grosjean, 2008). Specifically, bilinguals can effectively speak one of their two languages (i.e. operate monolingually) or choose to alternate between them (i.e. operate bilingually), as seen in cases of CS. However, this distinction is not categorical, but rather gradient. Bilinguals have the ability to move along a continuum from monolingual to bilingual speech production, also termed language modes (e.g. Grosjean, 1998). At any given point in an interaction, driven by both psychological and linguistic factors, a bilingual must decide “which language to use, and how much of the other is needed—from not at all to a lot” (Grosjean, 2001, p. 2). The concept of language mode has been expanded to refer to both written and spoken speech (Grosjean, 1997), as well as production and perception (Grosjean, 1998).
Important for the study of bilingual speech behaviors, a number of authors note that language mode may impact speech patterns (e.g. Soares & Grosjean, 1984) and that controlling for this variable is crucial (Grosjean, 2008). To that end, a number of studies have demonstrated an effect of language mode on the frequency (Treffers-Daller, 1998) and types of CS (Lanza, 1992). Furthermore, and crucial for the current study, it has been shown that language mode may impact phonetic production. Khattab (2003, 2009), for example, presented a case study in which English–Arabic children were able to modulate their non-switched phonetic productions based on the communicative role. That is, they were able to produce English tokens with English-like phonetic patterns or Arabic-like phonetic patterns, depending on the communicative context and interlocutors.
While language mode is established in naturalistic conversation through a variety of social and psychological factors, language mode can be manipulated in an experimental setting by adjusting the language context, which is the linguistic content or the amount of discourse drawn from each language (Olson, 2013). The language context is adjusted, while other factors impacting language mode (e.g. interlocutors, topics, environment) are held constant in the experimental setting. In short, shifts in language context should result in corresponding shifts in language mode, but language context itself does not encompass all of the factors that also impact language mode. Importantly, language context has also been shown to impact phonetic production (Olson, 2013; Simonet, 2014). As such, any discussion of the impact of CS on phonetic production should necessarily account for the potential impact of language context.
Research questions
Given both the lack of previous research and the potentially unique contribution of suprasegmental features to the understanding of code-switching, the current study examines the effect of CS on two main suprasegmental features: pitch range and duration. In addition, drawing on previous work particularly at the segmental level, this paper examines the roles of language context and language dominance in the suprasegmental production of CS, and responds to the following research questions:
RQ1: What is the effect of code-switching on suprasegmental features, namely pitch range and duration? RQ2: What is the effect of language context on the suprasegmental features of code-switched tokens? RQ3: What is the effect of language dominance on the suprasegmental features of code-switched tokens?
Methods
To investigate the research questions, an oral production task was administered to Spanish–English bilinguals, both Spanish-dominant and English-dominant. Broadly, participants produced tokens in three conditions: (a) as non-switched tokens in a monolingual context; (b) as code-switches in an otherwise monolingual context; and (c) as insertional code-switches in a balanced bilingual context. To analyze the impact of language dominance, response language was balanced, and tokens were produced in both the L1 and L2 in each of the above conditions. Tokens were analyzed with respect to intonation (i.e. pitch range) and duration (i.e. stressed vowel duration).
Participants
A total of 14 Spanish–English bilinguals were recruited on the campus of a large southwestern public university. One subject was subsequently eliminated for failing to complete all parts of the task. English-dominant participants (N = 7) are defined as those having learned English as an L1, beginning acquisition of Spanish after the age of 12, and self-rating as more dominant in English than Spanish. 3 Correspondingly, Spanish-dominant participants (N = 6) are defined as those having learned Spanish as an L1, starting acquisition of English after the age of 12, and self-rating as more dominant in Spanish. With respect to dominance, English-dominant participants self-rated their English as significantly stronger than Spanish in both speaking (t(6) = 7.07, p = .000) and comprehension (t(6) = 7.78, p = .000). Correspondingly, Spanish-dominant participants self-rated their Spanish as stronger than English in both speaking (t(5) = 5.94, p = .002) and comprehension (t(5) = 6.71, p = .001). Similar trends were also found in reports of current daily exposure, self-perceived accent, and other-perceived accent. Lastly, given that not all bilinguals engage in CS, participants were asked to evaluate their code-switching habits. Both groups of speakers reported switching languages with similar frequency (t(12) = −1.41, p = .188) and were equally comfortable when others switch languages (t(13) = 1.56, p = .15). All subjects reported normal hearing, speech, and normal or corrected to normal vision. Table 1 summarizes the language backgrounds of both groups.
Language experience and proficiency questionnaire results.
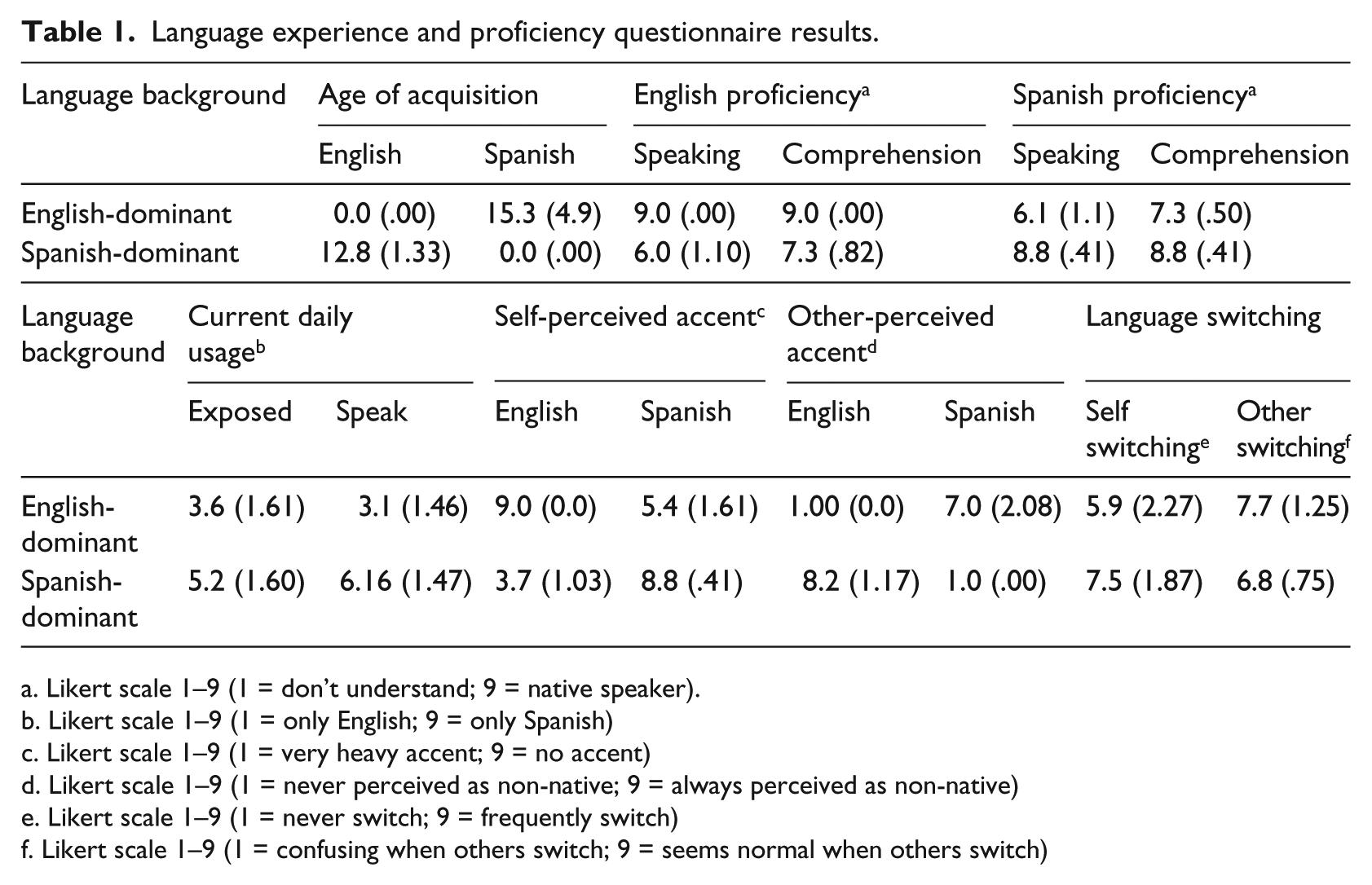
Likert scale 1–9 (1 = don’t understand; 9 = native speaker).
Likert scale 1–9 (1 = only English; 9 = only Spanish)
Likert scale 1–9 (1 = very heavy accent; 9 = no accent)
Likert scale 1–9 (1 = never perceived as non-native; 9 = always perceived as non-native)
Likert scale 1–9 (1 = never switch; 9 = frequently switch)
Likert scale 1–9 (1 = confusing when others switch; 9 = seems normal when others switch)
Stimuli
Stimuli consisted of a contextualizing paragraph, followed by a contrastive focus utterance, containing the target token in post-focal context. The stimuli contained target tokens in both English and Spanish, produced in three distinct conditions: (a) monolingual context – non-switched (non-switched target token in a monolingual context); (b) monolingual context – switched (code-switched target token in a monolingual context); and (c) bilingual context – switched (code-switched target token in a bilingual context). Example 1 (a–c) illustrates the resulting three stimuli types, with the target English token indicated in italics (for translations see Appendix A). Corresponding stimuli were created with the opposite language pairings (i.e. Spanish target tokens). The target tokens (see following section), the contextualizing paragraphs (see section “Contextualizing paragraphs”), and contrastive focus utterances (see section “Contrastive focus utterances”), are described in further detail below.
(1) a. Monolingual context – non-switched, English target I went to my daughter’s school, because I had a meeting about her behavior, but I went to the wrong classroom. The nice lady smiled, and said “No, not me. MS. HARRISON AND MRS. SMITH are the teachers in charge of your daughter’s class.” b. Monolingual context – switched, English target Salió un reportaje sobre la gente que trabaja en las escuelas públicas. Mi madre me preguntó, “¿Tu escuela tiene buena gente?” “¿Mi escuela? No, pero la escuela de mi HERMANA tiene teachers muy buenos que enseñan a los niños.” c. Bilingual context – switched, English target My parents wanted the escuela with the best people to educate me. “La escuela pública tiene los mejores?” my mom asked. “No, la PRIVADA tiene teachers muy buenos en cada clase,” my dad told her.
Target tokens
Target tokens in both English and Spanish were two syllable words with word-initial lexical stress. Target words consisted of an initial consonant-vowel structure, balanced for the three voiceless stops (/p, t, k/), and followed by the three point vowels (/i, a, u/). All tokens are considered to be non-cognate (de Groot, 1992) and non-loanwords. In total, there were 27 English and 26 Spanish 4 tokens.
Target tokens – loanword norming task
To confirm that target tokens were code-switches, not loanwords fully adopted into the opposite language (Poplack & Sankoff, 1984), a norming study was conducted. Seven early Spanish–English bilinguals (age of acquisition: English: M = 2.5; Spanish: M = 0.0), different from those in the oral production task, participated in the loanword norming task. Participants were provided with a list of 85 tokens (27 English targets, 26 Spanish targets, 32 fillers) and asked to rate, via a Likert scale, how “English-like” or “Spanish-like” they considered each token (1 = “Only English;” 10 = “Only Spanish”). Filler tokens, chosen to be potentially acceptable as part of both languages, included cognates (e.g. doctor) and generally accepted loanwords adopted from English into Spanish (e.g. lonche “lunch”) and Spanish into English (e.g. tortilla).
English target tokens, used in the oral production task, were rated as strongly English-like (M = 1.37, SD = 1.10). Spanish target tokens were rated as strongly Spanish-like (M = 9.34, SD = 1.55). The filler tokens, not used in the oral production experiment, were generally rated as being acceptable in both languages (M = 6.31, SD = 2.68). Subsequent statistical analysis (ANOVA) demonstrated a significant effect of token type (English, Spanish, filler) (F(2,80) = 238.3, p <.001) on ratings. Crucially, post-hoc analysis (TukeyHSD) revealed a significant difference between the English target tokens and the Spanish target tokens (diff. 7.97, p < .001, d = 5.93), and both were shown to be significantly different from the fillers (English: diff. = 4.95, p < .001, d = 2.41; Spanish: diff. = 3.02, p < .001, d = 1.38), confirming that the target tokens were non-loanwords.
Target tokens – semantic predictability norming task
As semantic predictability has been shown to impact phonetic production (e.g. Bell, Brenier, Gregory, Girand, & Jurafsky, 2002), with lower semantic predictability resulting in greater articulatory effort, target tokens were normed for semantic predictability via a cloze task (Taylor, 1953). A total of 28 participants, different from those who participated in the oral production task, performed the semantic predictability norming task. Participants were presented with the stimuli used in the oral production task, including the contextualizing paragraph (detailed in the following section) but missing the target token, and were asked to fill in the missing token. Monolingual English stimuli, not containing code-switches, were evaluated by English-dominant speakers (N = 12), monolingual Spanish stimuli were evaluated by Spanish-dominant speakers (N = 8), and all code-switched stimuli were evaluated by early, balanced bilingual speakers (N = 8).
Participant responses were evaluated with respect to the synonymic score (s-score) (McKenna, 1976), defined as the percentage of responses employing the target token or a synonym (for English: Princeton University, 2010; for Spanish: Proyecto Europeo Diccionario Conceptual Zirano, 2012). Minor spelling errors as well as singular/plural variations were accepted. All tokens reached the pre-determined threshold of 70% for s-scores and are considered to be highly semantically predictable.
Contextualizing paragraph
Each target token for the oral production paradigm was presented within a stimuli consisting of a contextualizing paragraph followed by a contrastive focus utterance, with the target token in post-focal position. The contextualizing paragraph, consisting of the discourse provided before each target utterance, allowed for the manipulation of language context and semantic predictability. The contextualizing paragraphs in the monolingual contexts (Examples 1a and 1b) consisted entirely of constituents from a single language. In contrast, the bilingual contextualizing paragraphs (Example 1c) consisted of half English constituents and half Spanish constituents (mean number of syllables: English = 21.96; Spanish = 22.26, t(52) = −.479, p =.634). Color was used as the only cue to the language of a given token. In the bilingual contexts, one language was indicated by blue, the other by red. The color language pairing was counter-balanced across all subjects. Paralleling the color conditions in the bilingual context, the monolingual contextualizing paragraphs were presented with a color pairing of either red/purple or blue/green. Again, an equal percentage of syllables were presented in each color (t(52) = .327, p = .745).
Contrastive focus utterance
The target token was embedded in a contrastive focus utterance, following the contextualizing paragraph. Contrastive focus utterances are defined as utterances in which information contrasts or corrects a previous statement (e.g. Hualde, 2005). Focus has been shown to impact articulation, correlated with an increase in F0 movement and duration (for Spanish: Beckman et al., 2002). Furthermore, many authors propose functions of code-switching, including communication factors (e.g. intensification and attention grabbing) and clarification (e.g. repairing) (Auer, 1998; Chan, 2003; Gumperz 1982; Zentella, 1997), which partially overlap with this definition of contrastive focus. To dissociate the phonetic effects of focus from those of CS, target tokens in the current study were all produced in a post-focal position. To ensure that prosodic features of the focus constituent were separated from the target token, target tokens occurred a minimum of two syllables from the contrastive focus constituent (range = 2–6 syllables; M = 2.97). In addition, to avoid end of utterance effects, all target tokens were a minimum of four syllables from the end of the utterance (range = 4–19 syllables; M = 8.00).
Procedure
Participants, in a quiet laboratory environment, were instructed to read the visually presented stimuli aloud as though they were speaking to “a good friend who is also bilingual.” In the case of reading errors, participants were told that they could restart at the beginning of the utterance containing the error. Stimuli were presented using SuperLab Pro v4.1.2 (Cedrus Corporation, 2010) and the rate of presentation was self-paced. To limit read-ahead effects, presentation of the utterance containing the target token occurred after the participant had read the contextualizing paragraph.
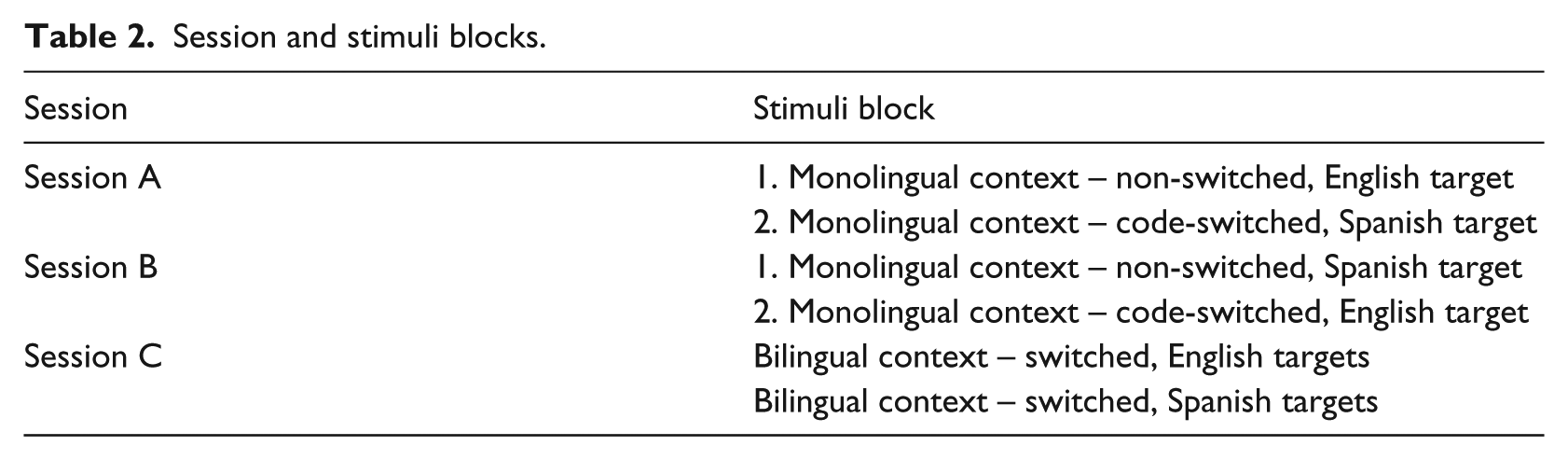
The oral production task was completed in three distinct sessions on different days in order to control for language context. As several authors note, inducing a purely monolingual mode in an experimental setting my not be possible (Blumenfeld & Marian, 2007). Acknowledging this constraint, the monolingual contexts in the current study are understood to represent a language context that approaches the monolingual end of the continuum. Sessions were blocked as shown in Table 2. Blocking the monolingual context – non-switched targets before the monolingual context – code-switched targets (i.e. sessions A and B) allowed for clear participant expectations, and consequently a more monolingual language context. Stimuli in session C were not blocked, and all bilingual stimuli were randomized together, thus speakers could potentially switch in either direction following the balanced contexts. Each subject received a different randomized order. The session order was counter-balanced across subjects.
Session and stimuli blocks.
Participants were recorded using a Shure Beta54 head-mounted microphone and Audacity v1.2.5 recording software with a 44.1kHz sampling rate. Each stimulus was repeated in three randomized sets, for a total of 477 productions per participant (53 stimuli × 3 repetitions × 3 sessions = 477 tokens).
Data analysis
A total of 6201 tokens were initially examined and a total of 202 tokens (3.26%) were eliminated for various errors, including laughter, yawning, and pauses in excess of 500ms at the point of switch. The remaining tokens were coded for two suprasegmental features: pitch range and stressed vowel duration. Pitch range was measured, via Praat (Boersma & Weenink, 2009), as the difference between the F0 maximum in the target token and the immediately preceding F0 minimum. To ensure consistency, the maximum F0 value in the target token, as well as the immediately preceding F0 minimum, was calculated by an automatic script. Figure 1 illustrates a sample F0 contour for a partial utterance come pavo para el (eats turkey for the), with pitch range indicated for the target token by the vertical arrow. Given individual differences in F0 and the potentially different pitch range employed in each of a bilingual’s languages (Altenberg & Ferrand, 2006), analysis was conducted on a normalized pitch range measure, calculated by dividing the pitch range of a given token by the non-switched average produced by the same speaker in the same language (Olson, 2012). A normalized pitch range greater than 1 indicates a pitch range that is greater than the average for a non-switched token of the same language. An additional 325 tokens (5.24%) were eliminated from the pitch range analysis due to creaky voice, making pitch tracking impossible.

Pitch range measurement. Waveform and F0 intonation contour for the partial utterance come pavo para el (eats turkey for the), produced by a native speaker of Spanish. The pitch range for the target token pavo is indicated by the solid vertical arrow.
Stressed vowel duration was coded with initial and terminal points defined by the onset of voicing after the release of the initial stop consonant and the onset of the following consonant, respectively. 5 Boundaries were marked by hand with particular attention to the waveform, and duration was extracted via automated script. Figure 2 provides a sample waveform and spectrogram for the word piso (floor), with the stressed vowel indicated by the horizontal arrow. Given the intrinsic differences in vowel duration between English and Spanish, analysis was conducted on a normalized stressed vowel duration measure, calculated by dividing the duration of a given token by the average of the non-switched tokens for the same speaker in the same language.
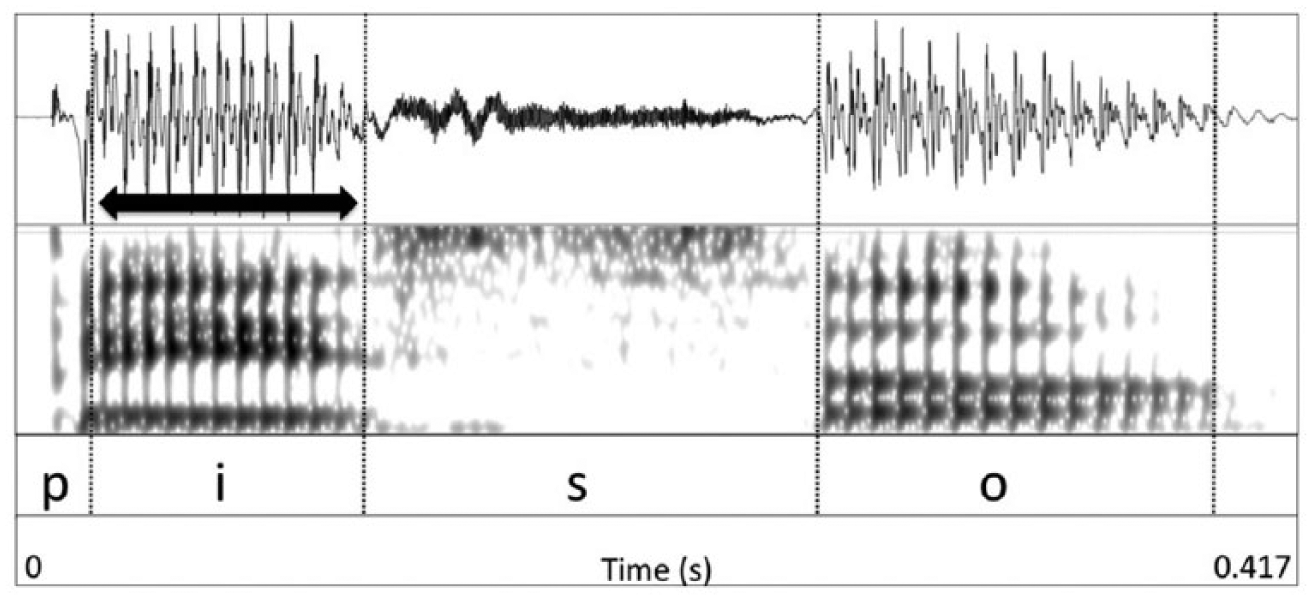
Stressed vowel duration measurement. Waveform and spectrogram for the target word piso (floor), produced by a native speaker of Spanish. The stressed vowel duration is indicated by the solid horizontal arrow.
Results
Statistical analysis was conducted using a linear mixed model analysis in R v3.0.2 (R Foundation for Statistical Computing, 2008) with the LME4 package. The significance criterion was set at |t| > 2.0. As there is no consensus on calculating F values, they are not presented here. Results are presented first for pitch range and then for stressed vowel duration.
Pitch range
Initial statistical analysis considered normalized pitch range, employing a linear mixed model approach with condition (monolingual context – non-switched targets; monolingual context – switched targets; bilingual context – switched targets) and response language (L1 or L2) as fixed effects, and subject as a random effect, with both random slopes and intercepts (Barr et al., 2013). 6 Results of the model revealed a significant difference between the intercept (L1, monolingual – non-switched) and the L1 monolingual – code-switched tokens (β = .340, t = 2.30), but no significant differences between any further comparisons (Table 3). To better understand these results, separate LME models were conducted for both the L1 and L2 response data. Parameters of the model were identical to the main model, with the exception of the exclusion of response language.
Pitch range, fixed effects of LME model.

Fixed effects are condition (monolingual context – non-switched; monolingual context – code-switched; bilingual context – code-switched) and response language (L1, L2). Subject is declared as random effect with random intercepts and slopes.
CI: confidence interval.
Results for the L1 response data mixed model (Table 4) demonstrated a significant difference between the intercept (monolingual – non-switched), and the monolingual – code-switched tokens (β = .340, t = .213), but no difference between the intercept and the bilingual – code-switched tokens (β = .233, t = 1.45). As such, while both switched conditions produced increased pitch ranges (monolingual – code-switched: M =1.34, SD = 1.10; bilingual – code-switched M =1.23, SD = 1.04), this increase was significant only in the monolingual – code-switched condition.
Pitch range, L1 and L2 response data, LME models.

The fixed effect is condition (monolingual context – non-switched; monolingual context – code-switched; bilingual context – code-switched). Subject is declared as random effect with random intercepts and slopes.
CI: confidence interval.
Results for the L2 response data (Table 4) stand in contrast, with the model revealing no significant differences between the intercept (monolingual – non-switched), and either of the code-switched conditions (|t| < 2.00). It should be noted, however, that the pattern that emerged was similar to the L1 data, with the code-switched tokens produced with slightly greater pitch ranges (monolingual – code-switch: M = 1.25, SD = .98; bilingual – code-switched: M = 1.06, SD = .73), relative to the non-switched tokens (monolingual – non-switched: M = 1.00, SD = .69). The main difference between the L1 and L2 responses lies in the magnitude of the effect, with L1 code-switched responses being produced with greater pitch ranges than the L2 counterparts. This difference is visible in Figure 3.
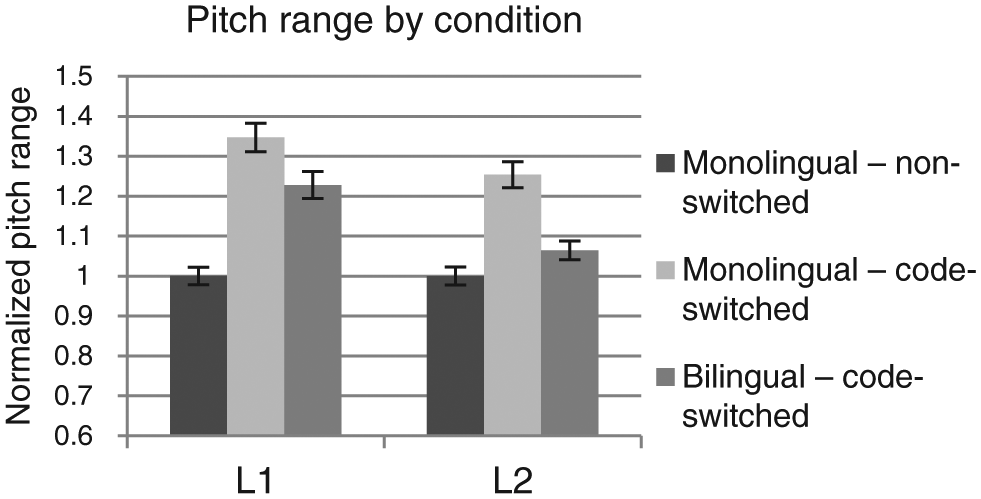
Normalized pitch range by condition and response language. Error bars represent +/− 1 SE.
Stressed vowel duration
To analyze the stressed vowel duration, a LME model was conducted for the normalized stressed vowel duration, with both condition and response language as fixed effects and subject as a random effect, with both random slopes and intercepts (Table 5). Results of the initial model revealed a significant difference between the intercept (L1, monolingual – non-switched) and both the L1 monolingual – code-switched (β = .158, t = 3.16) and L1 bilingual – code-switched tokens (β = .094, t = 2.61), as well as a significant interaction between condition and response language (L2 monolingual – code-switched: β = −.179, t = −3.10; L2 bilingual – code-switched: β = −.143, t = −3.08). As with the pitch range results, to better understand these results separate models were conducted, under identical conditions, for the L1 and L2 data separately.
Stressed vowel duration, fixed effects of LME model.
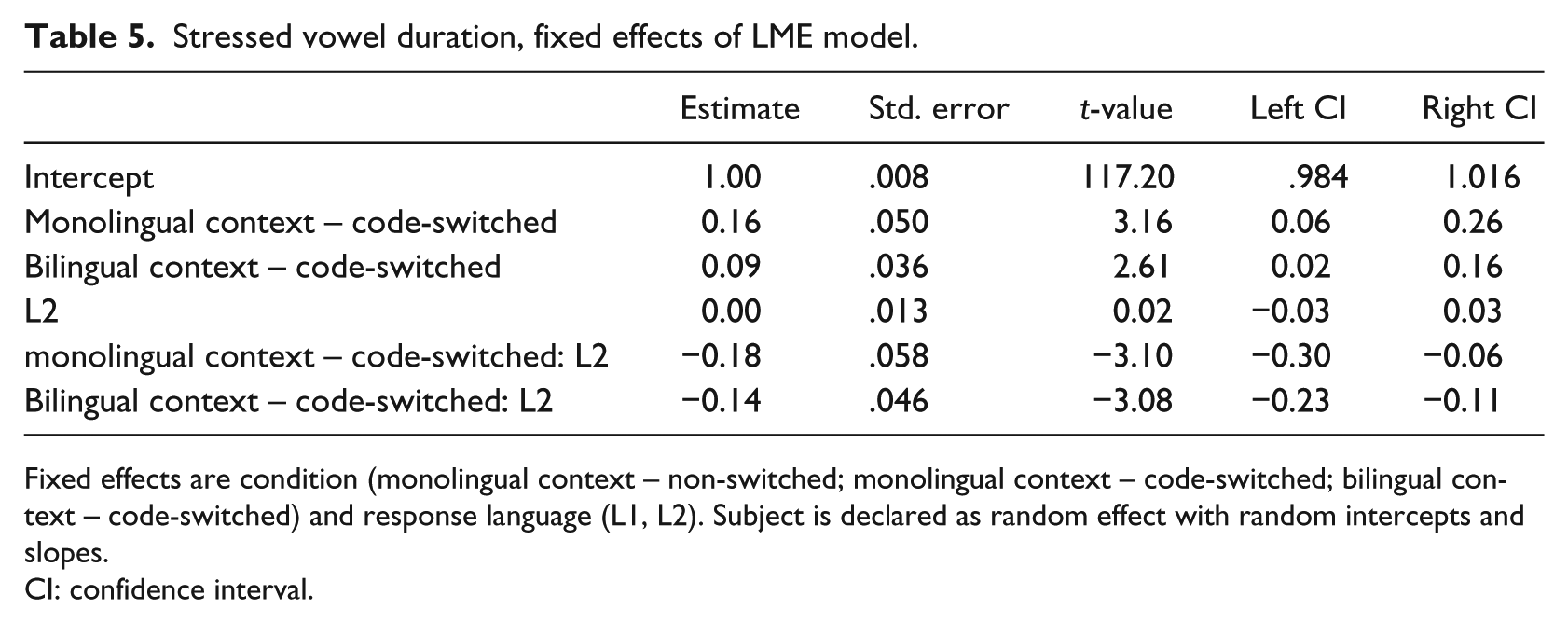
Fixed effects are condition (monolingual context – non-switched; monolingual context – code-switched; bilingual context – code-switched) and response language (L1, L2). Subject is declared as random effect with random intercepts and slopes.
CI: confidence interval.
Results for the mixed model conducted on the L1 response data (Table 6) demonstrated a significant difference between the intercept (monolingual – non-switched) and each of the code-switched conditions (monolingual – code-switched: β = .158, t = 3.04; bilingual – code-switched: β = .094, t = 2.15). In addition, post-hoc comparison (TukeyHSD) revealed a significant difference between the monolingual – code-switched and bilingual – code-switched tokens (diff. = −.064, p = .024, d = .186). As such, while both sets of switched tokens (monolingual – code-switched: M = 1.54, SD = .34; bilingual – code-switched: M = 1.09, SD .32) were produced with greater stressed vowel durations than the non-switched tokens (monolingual – non-switched: M = 1.00, SD = .26), the magnitude of this difference was greater for the monolingual – code-switched tokens relative to the bilingual – code-switched tokens.
Pitch range, L1 and L2 response data, LME models.
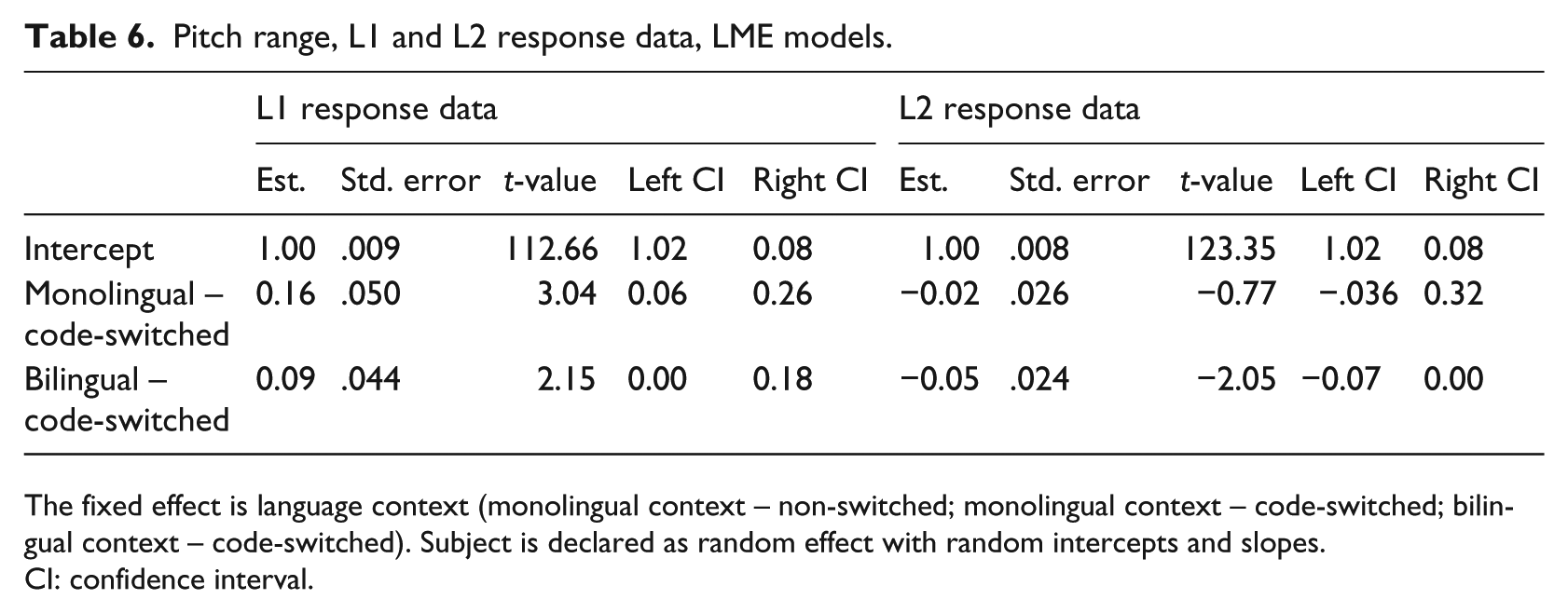
The fixed effect is language context (monolingual context – non-switched; monolingual context – code-switched; bilingual context – code-switched). Subject is declared as random effect with random intercepts and slopes.
CI: confidence interval.
Results for the mixed model conducted on the L2 response data (Table 6) stand out in contrast. Specifically, while there was no significant difference between the intercept (monolingual – non-switched) and the monolingual – code-switched tokens (β = −.020, t = −.77), there was a significant difference between the intercept and the bilingual – code-switched tokens (β = −.049, t = −2.05). An observation of the means revealed that the bilingual – code-switched (M = .95, SD = .25) tokens were actually produced with slightly shorter normalized vowel durations than the non-switched tokens (M = 1.00, SD = .29). 7 The difference between L1 and L2 data can be clearly seen in Figure 4.
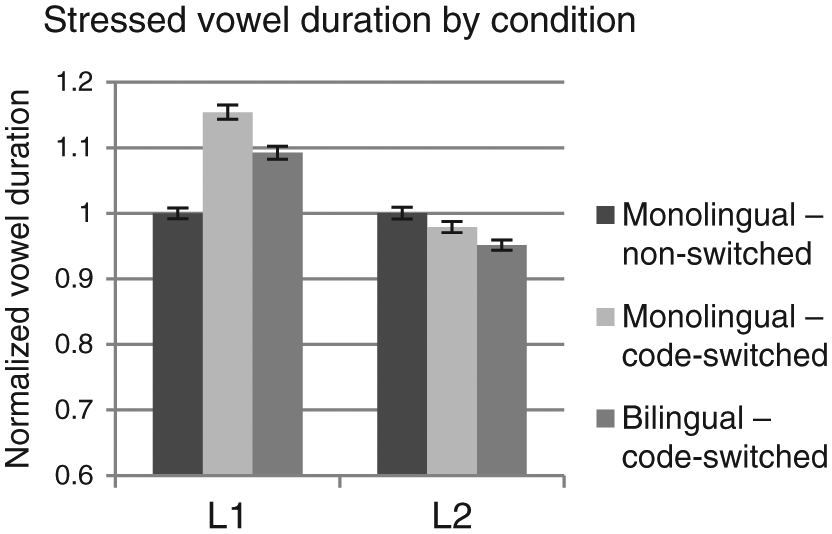
Normalized stressed vowel duration by condition and response language. Error bars represent +/– 1 SE.
Summary of results
Taken as a whole, the results revealed that code-switched tokens are produced with greater overall pitch range and longer stressed vowel durations than their non-switched counterparts. However, this difference was modulated by both language mode and language dominance. Considering language mode, most notably in the L1, the results demonstrated that both pitch range and stressed vowel duration pattern similarly, with greater pitch range and stressed vowel duration for code-switches in the monolingual mode relative to the bilingual mode. With respect to language dominance, both pitch range and stressed vowel duration pattern similarly, with significant increases in both pitch range and vowel duration in the L1, and no significant increases in pitch range and vowel duration in the L2.
Discussion
The results of the current study seem to demonstrate an effect of code-switching, language context, and language dominance on the prosodic production of code-switched tokens. Paralleling the original research questions, these three factors are discussed below, drawing heavily on notions of hyper-articulation and predictability.
Suprasegmental reflexes of code-switching and hyper-articulation
Considering the first research question, specifically the impact of code-switching on suprasegmental production, a general trend emerges from the results. With respect to pitch range, the current study demonstrates that the code-switched tokens were produced with a greater pitch range than the non-switched tokens. While this trend was consistent for all code-switched tokens (Figure 3), it reached statistical significance only for switches into the L1 following a monolingual context. A similar pattern emerged for stressed vowel duration, with L1 code-switched tokens produced with greater stressed vowel duration than the non-switched tokens (Figure 4). Although Olson (2012) found an increase in pitch height and vowel duration in code-switched tokens, the results were limited to the performance early, of balanced bilinguals switching into English. As such, the current results expand on these findings by showing similar patterns for late, L1 dominant bilinguals, as well as controlling for language mode and language dominance. Ignoring, for the moment, the impact of response language, it is clear that code-switched tokens are produced with a degree of prosodic markedness, including greater F0 movement and duration.
The current results provide additional evidence for the hyper-articulation of code-switches at the suprasegmental level. Olson’s (2012) account of the effects of code-switching on suprasegmental production relied on notions from hyper- and hypo-articulation (HH) theory (Lindblom, 1990) and local predictability (e.g. Bell et al., 2002). HH theory proposes that speakers modulate the effort of their articulatory gestures to compensate for cognitive factors (i.e. diminished predictability). When speakers encounter difficulties, they hyper-articulate, producing tokens with greater articulatory effort, including greater duration and pitch movement. Crucial to the current study, research has shown that speakers often hyper-articulate less predictable elements in a discourse relative to more predictable elements. Bell et al. (2002), for example, found that function words in English are produced with both fuller vowels and greater word duration in less predictable contexts (see also Pluymaekers, Ernestus, & Baayen, 2005; Raymond, Dautricourt, & Hume, 2006). Such findings have also been addressed in the smooth signal redundancy hypothesis (SSRH) (Aylett & Turk, 2004), which proposes an inverse relationship between predictability, resulting from pragmatic, semantic, and lexical factors, and prosodic prominence, including duration, “care of articulation,” and F0 excursions (p. 53). Moreover, while the original SSRH considered specifically the acoustic salience of syllables, the acoustic salience of words, specifically marked through prosodic constituent structure, also seems to vary inversely with predictability (Turk, 2010).
While code-switches are often high frequency nouns, their high frequency does not necessarily imply high predictability. Specifically, when single noun code-switches are inserted into an otherwise monolingual discourse, their local predictability is drastically diminished. Thus, for example, in a gating paradigm study in which bilinguals were given a carrier utterance followed by a segment of the target token, Grosjean (1988) demonstrated that listeners were most likely to expect tokens from the matrix language. It can be concluded that code-switched tokens, by their nature, are less predictable in a discourse than non-code-switched tokens. Within the SSRH framework (Aylett & Turk, 2004; Turk, 2010), code-switching may create a cognitive difficulty, namely diminished local predictability, which then results in an increase in prosodic prominence, or hyper-articulation, of the code-switched syllable or token.
Language mode and hyper-articulation
Responding to the second research question, investigating the effect of language context on the suprasegmental production of code-switched tokens, the results reveal significant differences between code-switched tokens produced following a monolingual context and following a bilingual context. Specifically, code-switches following a monolingual context were produced with greater pitch range and stressed vowel duration than those following a bilingual context, a finding most clearly illustrated in the L1.
These results also find explanation within the framework of language mode and HH theory. While several authors have noted the potential effect of language mode on phonetic production (e.g. Soares & Grosjean, 1984), this line of work has predominantly considered the potential influence of the relative accessibility of the two languages on segmental production. In sum, a more bilingual mode may allow a greater degree of phonetic transfer, while monolingual mode may beget less transfer, and more monolingual-like phonetic norms. However, it is clear that language mode may also impact phonetic production indirectly, by manipulating the degree of local predictability. As a code-switched token may be considered a less predictable element in a discourse, its predictability must be subject to contextual factors, such as language mode. That is, a single code-switched element produced in an otherwise monolingual discourse (i.e. monolingual mode) may represent a highly unpredictable element. A code-switched token in a bilingual discourse (i.e. bilingual mode), while less predictable than a non-switched token, may not entail the same degree of diminished local predictability. In short, when speakers are engaged in a discourse with a significant number of code-switches, each code-switched element may not represent such an unexpected occurrence. As such, while code-switches in a monolingual context are highly unpredictable, and therefore produced with significant hyper-articulation of suprasegmental features, code-switches in a bilingual context may be somewhat more predictable, and produced with a slight hyper-articulation relative to non-switched tokens. This pattern is reflected in the above results, with monolingual – code-switched tokens produced with greater pitch range and vowel duration than bilingual – code-switched tokens. Thus, language context (i.e. language mode) may effectively modulate predictability, which in turn impacts the degree of hyper- or hypo-articulation of a given token.
Language dominance and asymmetries
Relevant for the third research question, a similar pattern was found for both pitch range and vowel duration, with respect to the impact of language dominance as investigated through response language. Specifically, code-switched tokens in the L1 were produced with significantly greater pitch range and vowel duration than code-switched tokens in the L2.
These seemingly counter-intuitive results may find a parallel in the asymmetries found for temporal language switching costs (e.g. Meuter & Allport, 1999). In their seminal work, Meuter and Allport (1999) demonstrated that bilinguals are slower when switching into their L1 relative to their L2 (cf. for non-forced switching: Gollan & Ferreira, 2009). These findings, widely replicated for a number of different languages and dominance profiles (e.g. Costa, Santesteban, & Ivanova, 2006; Linck, Schwieter, & Sunderman, 2011) and paralleled in task switching studies (for a review see Monsell, 2003), have provided support for an inhibitory control (IC) model of bilingual language selection (Green, 1986, 1998). It has been proposed that to access the L1, the L2 must be inhibited, to minimize interference and transfer (although for the direct access hypothesis see Costa & Santesteban, 2004). Correspondingly, to access elements of the L2, the L1 must be inhibited. With this IC framework, it is hypothesized that greater inhibition is required on the L1 relative to the L2, given the relative strength of the L1 network. Greater inhibition on a given lexical item makes it inherently less accessible (and as a result less predictable), which accounts for the greater switching costs in the L1 relative to the L2.
Applying the same principles to the current study, and drawing on HH theory, less accessible constituents, and likely less predictable, should evidence greater degrees of prosodic prominence, a hypothesis borne out in the current results. That is, while code-switches are inherently unpredictable, switches into the L1 represent switches into a more strongly inhibited system, and thus result in greater degrees of suprasegmental prominence. As such, language dominance effectively serves to modulate the predictability of code-switched tokens, as evidenced through suprasegmental production.
Conclusions
As a whole, the current study demonstrates an effect of code-switching on suprasegmental production. Code-switched tokens were shown to be produced with greater pitch movement and duration than non-switched tokens. However, these findings appear to be modulated by both language context and language dominance. Specifically, a more monolingual context resulted in greater prosodic movement associated with the code-switched token than a more bilingual context. Similarly, switches into the L1 were associated with greater prosodic movement than switches into the L2. These results, couched within a framework of HH theory (Lindblom, 1990), allude to the potential impact of code-switching, language context, and language dominance on predictability. That is, less predictable code-switches, or those in a monolingual mode or into the L1, evidence greater F0 movement and longer durations.
While a predictability-based interpretation of code-switching seems to adequately account for the current results, future work should seek to challenge, confirm, and provide alternatives to this account. For example, acoustic cues in addition to prosodic prominence, such as prosodic constituency, may serve to modulate the acoustic salience of a given target (Turk, 2010). In addition, while pitch range and vowel duration largely patterned similarly in the current study, they differed slightly in the case of code-switches into the L2 in bilingual mode. Future research may address both which acoustic cues are associated with predictability, and the interplay between various cues. Lastly, while the oral production paradigm used here allows for the careful control of language context, phonetic content, and pragmatic intent (i.e. focus), this laboratory-based approach should serve as a starting point for future investigations based in naturalistic speech.
Footnotes
Appendix A
Translation of stimuli example 1.
Acknowledgements
I would like to thank A. J. Toribio and M. Ortega-Llebaria for their invaluable feedback on various portions of this project, as well as the anonymous reviewers.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by the National Science Foundation [grant number 1024320]. Any opinions, findings, conclusions or recommendations expressed in this material are those of the author and do not necessarily reflect the views of the National Science Foundation.