
Abstract
In response to the challenges of underwater garbage recognition due to insufficient lighting, poor visibility, and complex background interference in underwater environments, this paper proposes an improved YOLOv5s-based underwater garbage recognition algorithm. By integrating the CBAM(Convolutional Block Attention Module) attention mechanism into the C3 structure of YOLOv5s, the ability to capture subtle features of underwater debris has been significantly enhanced. Additionally, GhostConv lightweight convolution layers have been introduced into the model’s neck network, which not only accelerates the computational speed but also ensures the stability of feature extraction. Experiments show that the proposed algorithm achieves a recognition accuracy of 88.0% on a self-built underwater garbage dataset with an average detection time of just 6.8 ms. This improved model surpasses both YOLOv5s and similar algorithms in recognition accuracy and operational efficiency. This research not only greatly enhances the precision and real-time performance of underwater garbage monitoring but also provides an effective solution for the automated monitoring of underwater environments.
Introduction
With the increase in marine and lake activities and the proliferation of plastic products, underwater garbage pollution has become increasingly severe. Items such as discarded plastic bags, bottles, and shoes often sink to the bottom, posing a serious threat to the health and biodiversity of marine and lake ecosystems. 1 Traditional manual monitoring methods are inefficient and have limited coverage, making it difficult to meet the needs of large-scale identification and cleanup of underwater debris. Therefore, using underwater robots for garbage removal is gradually becoming an efficient solution. 2 To ensure that underwater robots can accurately identify and locate garbage in complex environments, developing efficient and precise underwater garbage recognition algorithms is crucial. 3 However, the unique characteristics of underwater environments, such as insufficient lighting, low visibility, and diverse types of garbage, present higher challenges to existing recognition technologies.
In recent years, vision algorithms based on deep learning have made remarkable progress and development in the field of target detection and recognition. 2 Currently, common object detection algorithms based on convolutional neural networks include the R-CNN series,4–6 as well as the YOLO series 7 and SSD detection algorithms, 8 which are based on classification and regression.
Wei Liu et al. 9 proposed the SSD algorithm model, which uses multi-scale detection methods and anchor mechanisms for object detection. Fulton et al. 10 applied advanced deep learning models like SSD, Faster R-CNN, and YOLOv2 to specific underwater environment model training and achieved high-precision detection in the “plastic” category. However, they used only three categories of datasets, limiting the model’s generalization capabilities to other types of garbage. Lin et al. 11 adopted the ROIMIX method, integrating Regions of Interest (ROI) from multiple images to improve underwater target detection performance, effectively addressing issues such as low contrast, blur, and color distortion in underwater environments, but without considering the model’s parameter size and computational consumption. Liu et al. 12 used WQT (Water Quality Transfer) and DG-YOLO (Domain Generalization YOLO) technology to enhance detection performance in unknown underwater environments, but due to potentially insufficiently broad or diverse datasets, their generalization capability in complex environments was limited. Ma D et al. 13 proposed the MLDet deep learning method, which can effectively address challenges in complex underwater environments, but relies heavily on high-end hardware. Although these studies have achieved significant results in underwater garbage recognition, they still face challenges such as low recognition accuracy due to unclear underwater images and low contrast; some models have improved detection accuracy through optimization but struggle to maintain real-time performance.
This paper addresses the above problems by conducting research on an improved YOLOv5s algorithm for underwater garbage recognition. Through the MSR (Multi-Scale Retinex) image enhancement strategy derived from Retinex theory, the clarity and contrast of the images were effectively improved. The integration of attention mechanisms and lightweight convolution modules optimized the YOLOv5s architecture, enhancing the model’s ability to extract key regional features. Through iterative processes of training and testing, the model was continuously refined to ensure high recognition accuracy while enhancing its real-time detection capabilities of underwater garbage, thus providing a more efficient and reliable solution for underwater environmental protection.
Image acquisition and data processing
The underwater debris recognition image dataset used in this study primarily comes from the public dataset on the CVMart platform (https://www.cvmart.net/dataSets/detail/344), supplemented with underwater garbage images captured in real-world aquatic environments, allowing for a more comprehensive testing and evaluation of the algorithm model. The dataset includes various angles, distances, and occlusion scenarios of common garbage, totaling 5500 images, which are divided into training, validation, and test sets at a ratio of 7:2:1. The dataset retains pure underwater environment images without garbage targets as negative samples to prevent overfitting or underfitting and to enhance the model’s robustness against interference. The LabelImg software is used to annotate the segmented dataset, which is categorized into four classes: trash bag , trash bottle, boot trash , and other trash.
Due to the complex underwater environment, some images suffer from severe fogging issues. Therefore, the MSR algorithm
14
was employed to preprocess the dataset by performing a weighted sum of multiple image components, as shown in equation (1), effectively improving the contrast and brightness of underwater images, thereby enhancing their clarity and detail visibility.
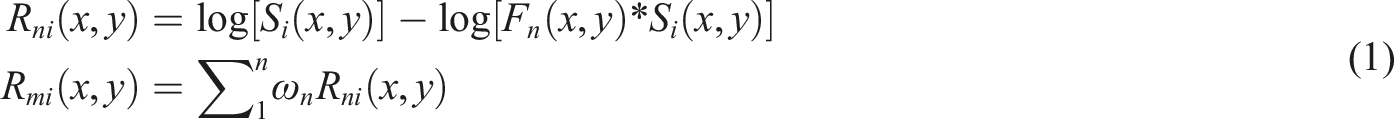
In equation (1), the values of i (1, 2, 3) represent the three RGB color channels, where a surrounding Gaussian function is used to filter the RGB channels;
The images enhanced using the MSR algorithm are clearer, with more prominent features and sharper outlines, which facilitates subsequent image processing and analysis tasks. The results of the image dataset processing are shown in Figure 1. Images prior to and post MSR processing. (a) Original image of underwater trash bag. (b) MSR-Processed underwater trash bag image.
Research methodology
Principle of the YOLOv5s algorithm
The YOLOv5 series is a set of one-stage object detection models built upon the YOLO concept, designed to achieve a balance between efficiency and accuracy. This series includes four core variants: YOLOv5s, YOLOv5m, YOLOv5l, and YOLOv5x. These variants share a similar basic architecture but are adapted to different performance requirements by adjusting two key parameters: depth_multiple and width_multiple. Among them, YOLOv5s is the most lightweight model, featuring a shallower network depth and narrower feature map width, enabling it to run at extremely fast speeds, making it highly suitable for applications with strict speed requirements. YOLOv5s primarily consists of four parts, and the network framework is illustrated in Figure 2. Network framework of YOLOv5S.
Input network
The Mosaic data augmentation technique is employed to enhance the model’s generalization capability. The input scaling ratio and anchor box sizes are automatically adjusted according to the size of the input images, allowing the model to adapt to inputs of varying dimensions.
Backbone Network: Consists of modules such as CBS (Convolutional Block with Batch Normalization and activation), C3, and SSPF (Spatial Pyramid Pooling-Fast) for feature extraction. The CBS layer encapsulates convolution, batch normalization, and activation functions to extract image features. The C3 layer groups input features and integrates features across different levels through cross-layer connections, aiming to enhance the model’s representation power. In the Backbone network, the C3 layer utilizes the CSP1_X structure, whereas in the Neck network, the C3 layer without shortcuts adopts the CSP2_X structure. The SSPF layer performs pooling operations on feature maps of different scales, reducing computational load while improving the model’s feature extraction capability, as illustrated in Figure 3. Structure of the SSPF layer.
Neck network
Processes and efficiently utilizes the feature maps extracted by the Backbone network. It is composed of convolutional layers, upsampling, and the C3 structure of CSP2_X. The network employs a top-down followed by a bottom-up feature fusion cyclic pyramid structure, which not only shortens the propagation path of feature information but also integrates features from different layers of the image, enriching the feature information for mask prediction in the Output network.
Output network
Contains at least three detection layers, which detect the position and class probabilities of objects by identifying features from the feature maps.
Optimization of the backbone network’s C3 layer
This study embeds the CBAM at the output end of the C3 structure used in the backbone network to extract features and positional information of regions of interest. This enables adaptive feature optimization of the information passing through the C3 structure, thereby constructing the CBAMC3 module to enhance the feature extraction performance of the C3 structure. The structure of the CBAMC3 module is illustrated in Figure 4. CBAMC3 structure diagram.
Among these, CBAM is a lightweight convolutional attention module that includes two sub-modules: CAM (Channel Attention Module) and SAM (Spartial Attention Module). The CAM module enhances the extraction of contours of features of interest, with the channel attention calculation formula as shown in equation (2). The SAM module enhances the extraction of positional information of features of interest, which not only saves parameters and computational resources but also makes it easy to plug into existing network frameworks. The spatial attention calculation formula is shown in equation (3).

In equation (2), C represents the number of channels,

Optimization of the neck network’s convolutional layers
This study optimizes the standard convolutional layers in the neck network using the GhostConv lightweight building block, accelerating the feature extraction process of the model to meet the specific requirements for real-time performance and efficiency in underwater garbage detection scenarios. The core of the Ghost module is to generate more “ghost” feature maps from existing feature maps through linear operations, thereby improving the computational efficiency of the network. The structure of the GhostConv module is illustrated in Figure 5, consisting of convolution, linear transformations, and feature map concatenation. Structure of GhostConv.
GhostConv convolution reduces the number of channels in the input feature maps

CCGS-YOLOv5sS network framework
The C3 layer in the Backbone network is integrated with the CBAM structure, which enhances the features of regions of interest and improves the extraction of positional information. The GSConv structure is used in the convolutional layers of the Neck network, reducing the model’s parameters and computational load while maintaining the original model’s detection accuracy. The CCGS-YOLOv5sS algorithm is obtained by replacing the corresponding C3 layers and Conv layers in the YOLOv5S algorithm with the CBAMC3 module and GhostConv blocks, respectively. The overall framework is illustrated in Figure 6. CCGS-YOLOv5s network architecture.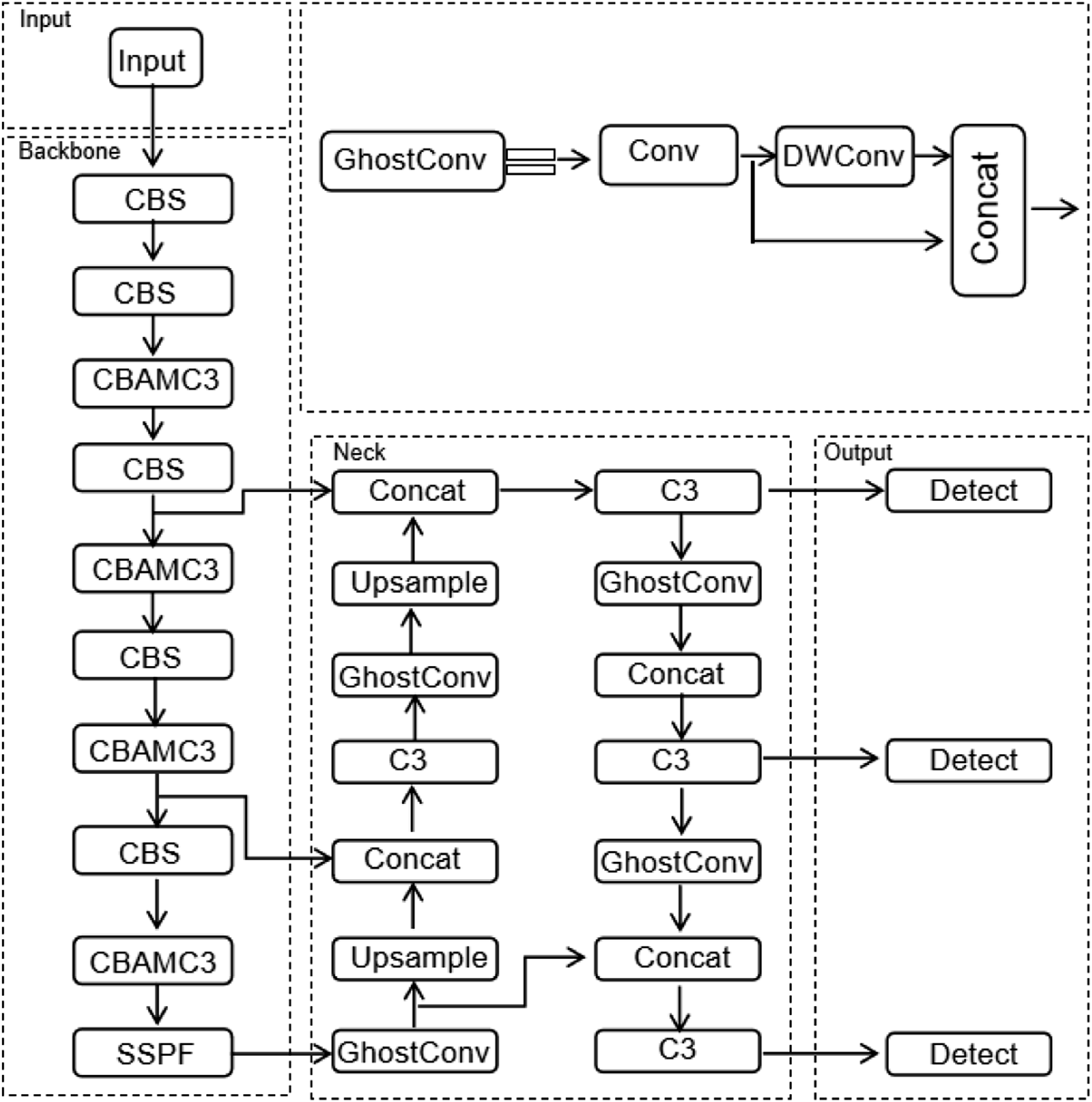
Input images pass through the convolutional layers of the Backbone to obtain different feature maps. These feature maps then undergo four rounds of processing through CBS and CBAMC3 layers to extract the target features of the regions of interest. The extracted features are then fed into the SSPF (Spatial Pyramid Pooling-Fast) layer, which converts them into fixed-dimension feature vectors and performs feature fusion. The Neck network performs upsampling, enlarging the feature maps and fusing them to produce three feature maps. Finally, the detection layers in the Output network generate the final output results.
Results and analysis
Experimental hardware configuration.

The experimental results were obtained with input image dimensions of 640×640 pixels, 200 iterations, and a training batch size of 8 samples.
MSR image enhancement algorithm experiment
To validate the effectiveness of the MSR image enhancement algorithm, we specifically selected underwater images with poor lighting and low contrast, as shown in Figure 7(a), where the object detection confidence levels were only 87% and 67%. After applying the MSR algorithm to optimize the images, the contrast and brightness improved significantly, and the detection confidence levels increased to 91% and 70%. This demonstrates that processing images with the MSR algorithm effectively improves the clarity of underwater debris images, enhances the visual contrast between debris and the surrounding environment, highlights the key features of target objects, and substantially increases the precision of the detection algorithm, thereby enhancing the model’s ability to recognize underwater debris, as shown in Figure 7(b). Comparison of MSR enhancement algorithm experiment. (a) No MSR enhancement algorithm. (b) MSR enhancement algorithm.
FPS experiment comparison
FPS comparison of two models.

Detection performance experiment comparison
The detection performance of CCGS-YOLOv5s and YOLOv5s was evaluated using randomly selected underwater garbage images, as shown in Figure 8. In Experiment Group 1, the YOLOv5s algorithm model exhibited missed detections. In Experiment Groups 3 and 4, the YOLOv5s algorithm model had false detections, incorrectly identifying irrelevant information in the images as plastic bottles. Across all four experiments, the CCGS-YOLOv5 algorithm showed higher detection confidence compared to the YOLOv5 algorithm model, indicating better recognition performance and robustness. However, Experiment Group 4 revealed that the model also had false detections for targets that were not significantly different from the background. Comparison of MSR enhancement algorithm experiment. (a) Images; (b) YOLOv5 algorithms; (c) CCGS-YOLOv5s algorithms.
Ablation study
Comparison of ablation study results.

From the data in the table, it can be observed that embedding the CBAM module in the C3 backbone network layer increases the model size by 8.2% and reduces the FPS by 11%, but significantly improves the mAP by 6.8%, indicating that CBAM effectively enhances the model’s ability to capture key features. Replacing the convolutional layers in the neck network with GhostConv sacrifices a minor 1.8% in mAP but significantly reduces the model size by 34.7% and effectively increases the FPS by 35.8%, demonstrating that GhostConv ensures efficient acceleration with minimal precision loss. The CCGS-YOLOv5s model, optimized with both CBAM and GhostConv, achieves an mAP improvement of 4.8%, reduces the model size by 19.6%, and accelerates the FPS by 32.9%, demonstrating stronger real-time detection capabilities and higher detection accuracy while ensuring detection precision.
Conclusion
This paper focuses on common underwater garbage such as trash bags, discarded shoes, abandoned bottles, and other types of underwater waste. Addressing the challenges posed by underwater environments, including poor lighting, low visibility, and complex background interferences, an improved YOLOv5 algorithm is proposed. The main conclusions are as follows: (1) To address issues such as insufficient lighting, poor visibility, and interference from complex backgrounds in underwater environments, a multi-scale Retinex image enhancement algorithm was applied to preprocess the underwater debris images, effectively improving the image quality. In terms of the quantity of images, additional garbage pictures captured in actual water environments were added to enhance the assessment of the improved model’s robustness and detection accuracy. (2) Based on the YOLOv5 architecture, an attention mechanism is embedded within the C3 backbone network to enhance its ability to extract features of image targets. Meanwhile, in the neck network, the ordinary convolutional blocks are replaced with the GhostConv lightweight convolutional module, which reduces the model’s parameters and computational costs, improving the recognition speed of the model to meet the demands of real-time recognition.
In summary, the CCGS-YOLOv5s model proposed in this paper demonstrates the vast potential of deep learning in specific applications, opening new avenues for subsequent underwater environment monitoring and protection. However, while lightweight convolutional structures reduce the model’s parameter count, they may also decrease recognition accuracy for small or multiple targets, leading to significant deviations in detection positioning. Further research is needed to optimize the model’s detection performance.
Statements and declarations
Footnotes
Conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Natural Science Foundation of Jiangxi Province (20224BAB202033) and Research Project on Teaching Reform in Higher Education Institutions of Jiangxi Province (JXJG-22-70-7).