
Abstract
Apple, as one of the largest fruit varieties in terms of planting yield and planting area in China, plays an important role in agricultural production. However, the development of apple industry is limited by apple leaf diseases, which pose a serious threat to apple yield and quality. In recent years, deep learning technology has made significant progress in image recognition. Based on the Masked Auto-Encoder (MAE) self-supervised pre-training method and weak supervision method, this study proposes a fine-grained apple leaf disease recognition method. The model uses the Masked Auto-Encoder (MAE) self-supervised pre-training method to extract features from apple leaf images to obtain accurate high-dimensional feature representation. And using the Weak Supervised label propagation process based on Bayesian method, a large amount of unlabeled data is collated as a supplement, thus achieving accurate recognition of apple leaf diseases. The experimental results show that the proposed method exhibits high accuracy and robustness in apple leaf disease recognition task. Compared with general deep learning, this method can improve the recognition accuracy of difficult samples and has strong generalization ability, which can adapt to apple leaf image recognition tasks under different environments.
Introduction
In China’s fruit industry, apples are the largest fruit variety in terms of both production and planting area. High-level planting methods can further improve apple production and quality. The application of Smart-Agriculture to timely prevent and control early diseases is of great significance at the level of fruit supply in China, and it can also reduce farmers’ production burden and improve the production efficiency of the apple industry. From the perspective of disease prevention and control, if the disease is detected and correctly classified in the early stage, it will have the least impact on fruit tree production. However, due to the fact that crop diseases often have unclear characteristics in the early stage, and the characteristics of various diseases are relatively subtle, it is difficult to distinguish the type of disease with high accuracy in the early stage without rich experience in disease analysis. This also poses a great challenge for disease prevention and control. In current research, most studies on fruit tree disease identification and diagnosis at home and abroad are based on traditional image processing methods, requiring manual extraction of disease characteristics such as color, shape, and texture. After feature dimensionality reduction, traditional artificial intelligence algorithms such as SVM and KNN are used for disease classification, identification, and diagnosis. Disease recognition research based on image processing covers wheat, 1 corn, 2 cotton, 3 tomato, 4 cucumber, 5 and apple 6 crop diseases, but the recognition rate is poor and the ability for on-site application is limited. With the development of deep learning technology, especially the achievements made by Convolutional Neural Networks (CNNs) in image classification, some scholars have begun to study the application of CNN in crop disease identification and lesion segmentation.7–10 Although the research on plant disease identification based on deep learning started late, it has achieved good results, indicating that deep learning networks have good potential and prospects for plant disease identification and disease severity diagnosis.
It can be found that there is a consensus in the current research on better diagnosis of crop and plants diseases using deep learning. However, there is still a lack of relevant research on difficult early disease sample recognition. This paper believes that further in-depth exploration and application of cutting-edge deep learning algorithms can achieve higher accuracy in early disease recognition, which will increase the probability of early disease detection in the front-line apple planting industry, further expanding the depth of application of deep learning in agricultural planting.
Relative works
The Vision Transformer (ViT) is a deep learning model based on attention mechanisms, designed for various computer vision tasks. Introduced by Google in 2020, it has achieved significant success by incorporating the successful Transformer architecture from the natural language processing domain into the field of computer vision. Historically, Convolutional Neural Networks (CNNs) have been the dominant models for computer vision tasks. However, with the continuous growth and complexity of image datasets, traditional CNN architectures face challenges in handling global information and long-range dependencies. The introduction of ViT represents a new paradigm for computer vision, leveraging a global self-attention mechanism to capture the global context information in images. This enables the model to adapt better to features of different scales and relationships. ViT’s development marks a trend in the deep learning field towards adopting the Transformer architecture for visual tasks.
This paper adopts the cutting-edge ViT model and conducts extensive research and improvements on early disease detection in apple leaves based on it. Firstly, since the advent of machine learning, many attempts have been made to improve the training quality of models using weak supervision methods, such as the early semi-supervised label propagation method, which can use an under-trained model to label propagation on a larger scale of unlabeled data. With the development of deep learning in the field of weak supervision, deep learning has proposed more efficient methods based on its own characteristics, such as the MOCO method and 11 MAE method. 12 The MOCO method uses contrastive learning for unsupervised training. Each sample is treated as an independent classification, without distinguishing between actual categories. After data augmentation of the samples, the ArcFace Loss and other contrastive loss functions are used to distinguish between different images, allowing the model to understand the feature differences between all different images. Then in the downstream task, strongly supervised learning is used for finetuning to optimize the accuracy of the downstream task. The MAE method is generally applied in the Transformer model. MAE masks different random regions of the image, up to 70% or more, and then reconstructs the image through the Transformer encoder-decoder structure, which is the meaning of Masked Auto-Encoder. This approach can analyze the relationship between image regions through the encoder, store the relationship in the encoder structure, and apply the model pre-trained by this method to the downstream task, which can effectively analyze the image region association to obtain better downstream task accuracy.
Weakly supervised learning is usually applied in downstream tasks of the model, such as disease recognition in this paper, using pre-trained models. The finetuning mode is used for weakly supervised training. Deep learning has brought more applications for weak supervision, making it possible to apply samples that are not well labeled. Ghahramani, Z proposed using DropOut as an approximate idea for Bayesian sampling, 13 which can also be applied to model soup, 14 TTA (Test Time Augmentation) method15,16 for model integration or sample enhancement methods to more effectively perform weak supervision label propagation, resulting in better performance of weakly supervised training models than strongly supervised training models.
Fine-grained apple leaf disease recognition based on MAE
Based on expert experience, the apple leaf diseases analyzed in this paper include the following 12 types of apple leaf diseases and normal categories: complex diseases have 1602 images, frog_eye_leaf_spot has 2181 images, frog_eye_leaf_spot complex has 165 images, healthy has 4624 images, powdery_mildew has 1184 images, powdery mildew complex has 87 images, rust has 1860 images, rust complex has 97 images, rust frog_eye_leaf_spot has 120 images, scab has 4826 images, scab frog_eye_leaf_spot has 686 images, and scab frog_eye_leaf_spot complex has 200 images.
This paper proposes a new workflow and model to improve the accuracy of fine-grained analysis methods for early disease classification in apple leaves. The main workflow proposed in this paper is shown in Figure 1. First, this paper collected the corresponding dataset. The data with disease category labels came from the Plant Pathology 2021-FGVC8 Challenge dataset. And the data without expert labels came from the Internet. Among them, there were 17,632 labeled data and 67,329 unlabeled data. Data collecting and model training.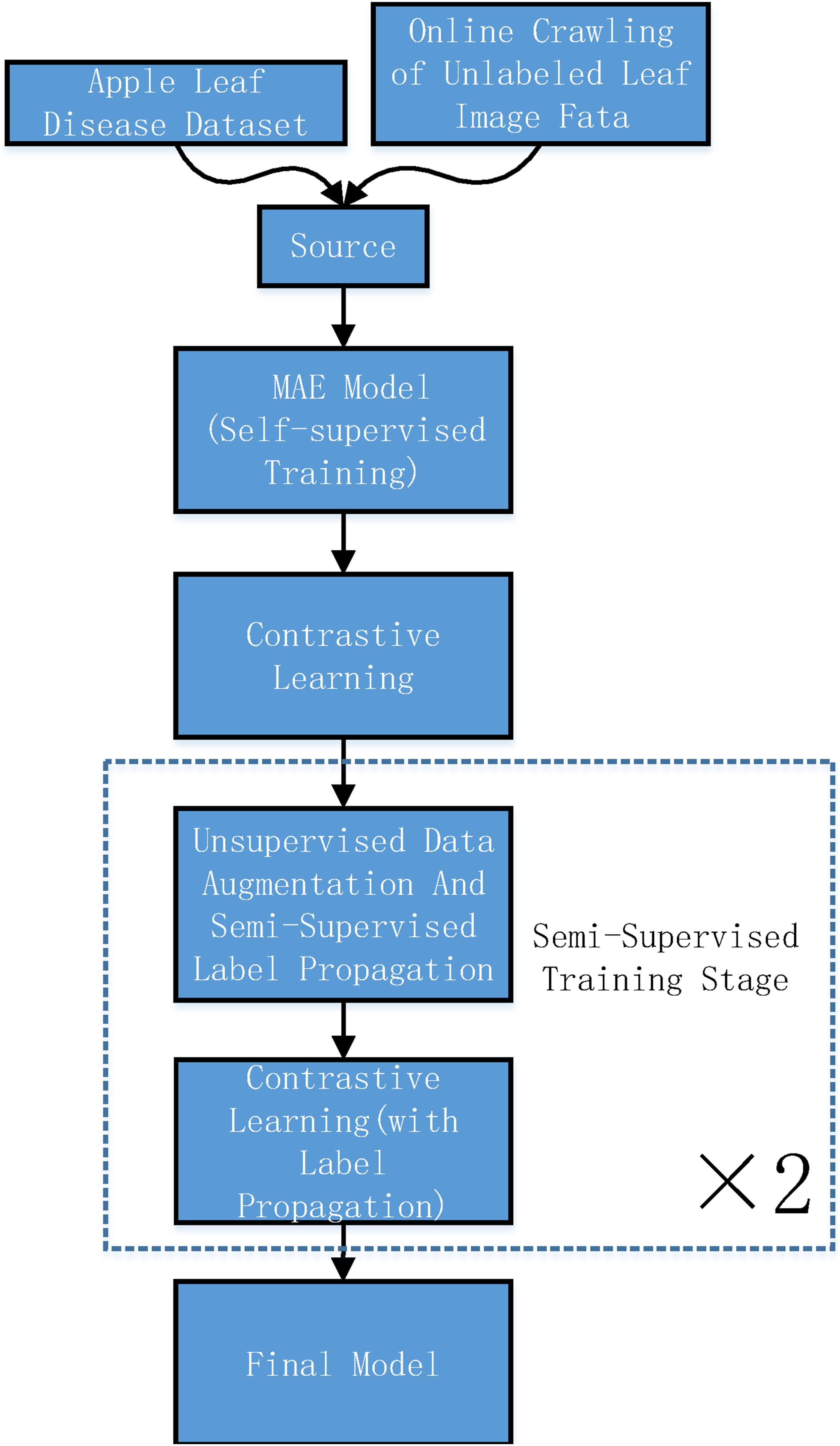
This paper constructs a new MAE Transformer model and uses all unlabeled data for self-supervised pre-training. After the pre-training of the model, expert-labeled data and contrastive learning training method are used for fine-grained classification and strongly supervised training. The primary model is obtained. Based on the primary model, Dropout and model soup methods are used for weakly supervised label propagation, which converts unlabeled data into usable label data. After fully integrating the weakly supervised label propagation data with expert-labeled data, the model is further trained using contrastive learning training method to produce the final fine-grained classification model, achieving the goal of high accuracy for early disease classification. The MAE Transformer model proposed in this paper is shown in Figure 2. MAE Transformer model.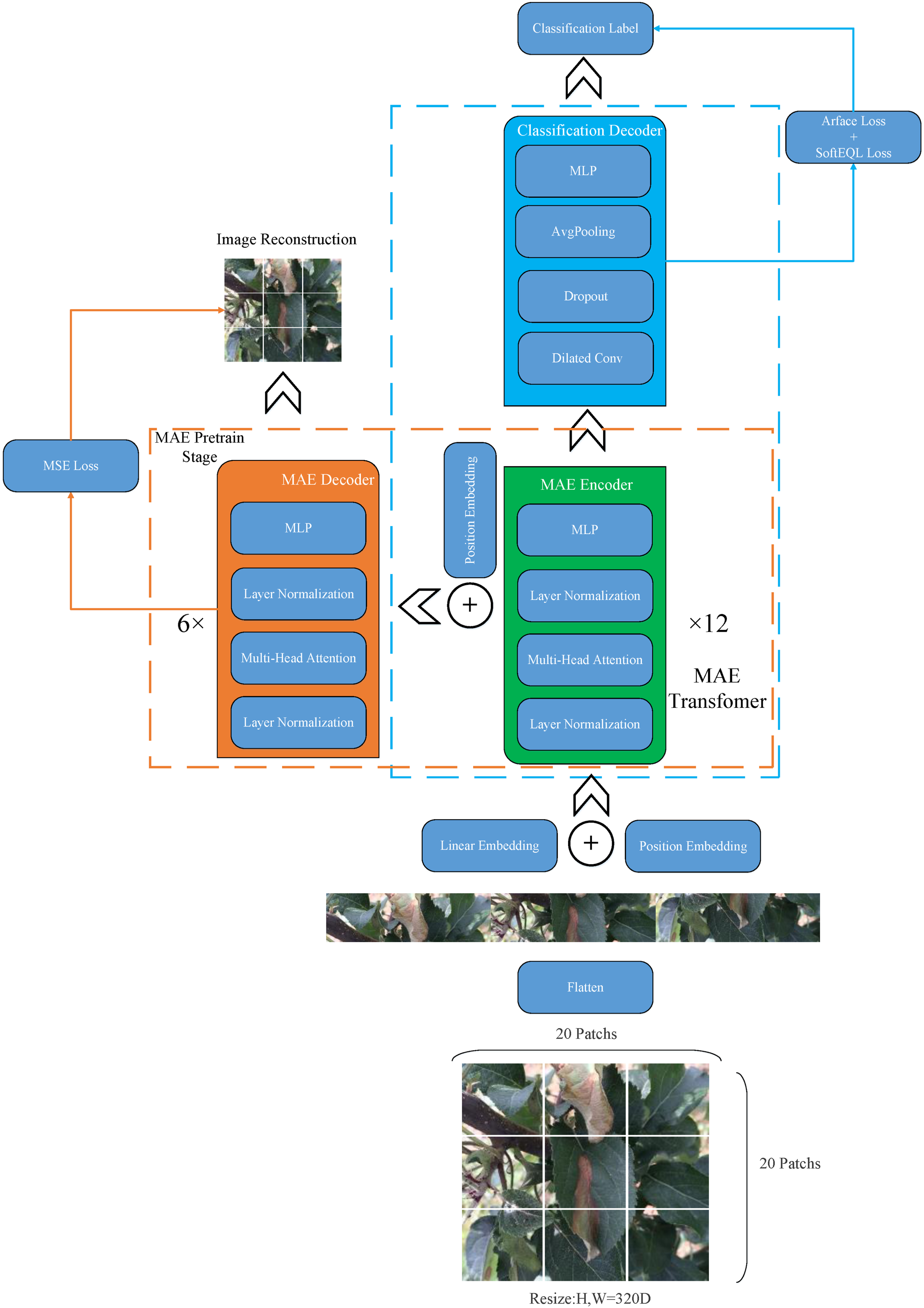
Based on the MAE idea, this paper constructs a new Transformer model. In Figure 2, the MAE Transformer has different network structures during pre-training and downstream tasks, which are represented by orange and blue dashed boxes, respectively. The orange dashed box represents the network structure of the MAE Transformer during the pre-training stage. The network first scales the original image to a 320 × 320 image. Then, the image is cut into 20 patches by rows and columns, totaling 400 patches. Each patch (16 × 16 × 3 pixels in size) is encoded into a 768-dimensional vector through linear embedding and input all patches to the network. The input is also added with a learnable position encoding layer. During the pre-training stage, the model is trained by randomly masking 400 input patches and the MAE decoder will recover the masked patches. During the pre-training process, no classification labels for the images are required; only image reconstruction training is performed. A simple MSE Loss is used as the self-supervision loss function, as shown in equation (1):

In equation (1), x and y represent the output and label values of the network, respectively. i and j represent the pixel location.
In Figure 2, the blue dashed box represents the model structure of the downstream fine-grained classification task. Based on the MAE Transformer encoder, the MAE Transformer decoder structure used for image reconstruction is discarded, and the output features are filtered through dilated convolution and pooling operations using random Dropout to improve the stability during model training. Finally, the model output is converted to one-hot category through an MLP layer to achieve fine-grained classification of apple leaf categories. During the training process of the downstream task, the optimized Subcenter Arcface Loss and SoftEQL Loss functions are used for training. The Subcenter Arcface Loss is shown in equation (2):
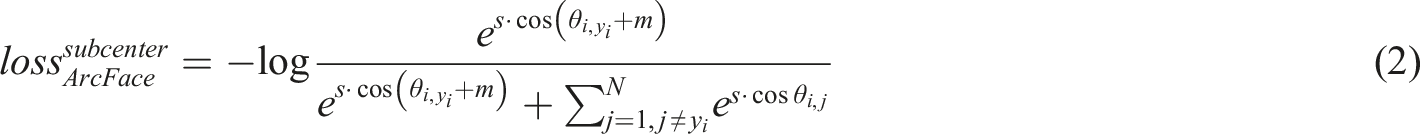
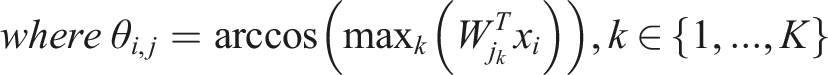
In equation (2),
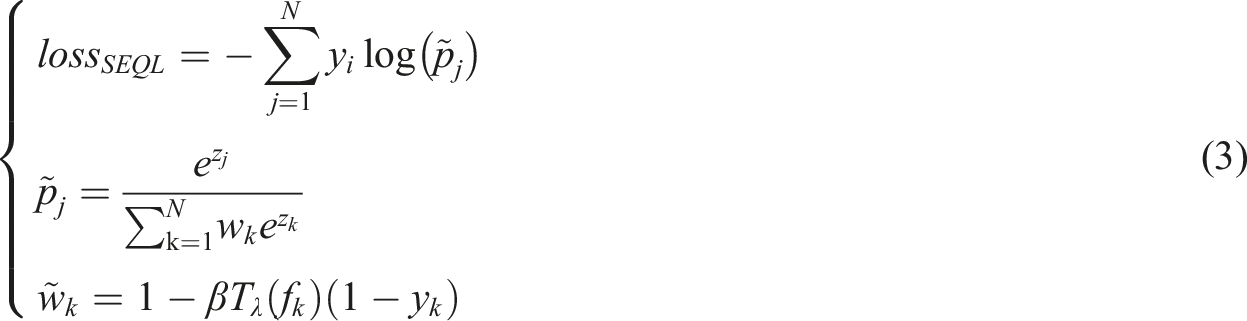
In equation (3), N represents the classification category,
The final loss function is defined as equation (4):

Equation (4) combines equations (2) and (3), using
Model parameter table.
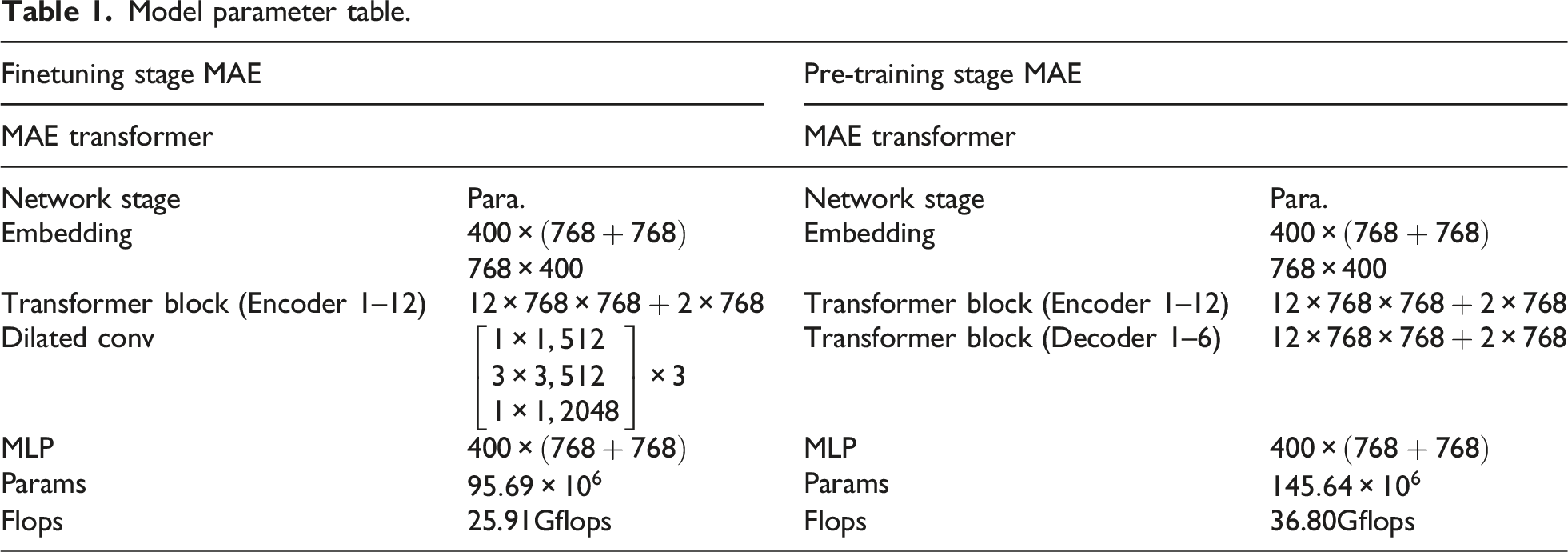
In Table 1, we mainly show the model structure parameters in the pre-training and finetuning stages. In the finetuning stage, the MAE Decoder used for image reconstruction is removed, which reduces the model’s parameter count and computational requirements. As the model is constructed with reference to the standard ViT, it consists of 12 attention heads forming a single Transformer Block, and the parameter count calculation for the Transformer Block is shown in Table 1.
After the first training of image labels, a primary model will be formed. The primary model has some early disease recognition capabilities, and in order to further use unlabeled data, this paper proposes a unique weakly supervised label propagation process.
After completing the primary model training, multiple copies of the classification head are copied and share weights. When recognizing the same image, multiple different classification softmax results are obtained. This is due to different classification heads having different output truncations during random Dropout, allowing the model to simultaneously output multiple different results. Finally, the classification results are averaged to obtain the classification result.
In the process of weak-label propagation, if the difference between the highest-scoring category and the second-highest-scoring category is small, we will remove such images. The threshold is set to
Under the guidance of this method, in order to fully utilize the weak supervision effect, we used two propagation processes. After using 33,664 unlabeled images for label propagation for the first time, we mixed the weak supervision label data with expert label data for one training. Then, we used the trained model for the second label work, using 33,665 unlabeled images. Detailed training experiments in each stage will be described in detail in Chapter 4.
Training hyperparameters and ablation experiments
MAE Transformer training stage and accuracy.
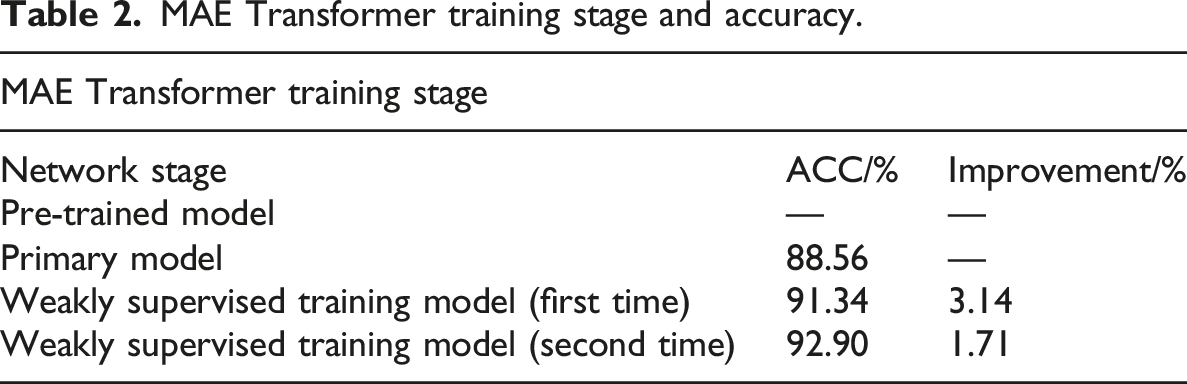
Table 2 uses the standard accuracy calculation formula to calculate the accuracy, as shown in equation (1):
In equation (1), TP and TN represent the correct positive and negative classes predicted, while FP and FN represent the incorrect positive and negative classes predicted, respectively. The first row in Table 2 represents the pre-training stage of the model, when the model is not yet matched to the downstream task and therefore cannot calculate the relevant accuracy rate. However, based on the primary model, it can be observed that the initial accuracy level is already at a high level, and further model accuracy improvement can be achieved through two weakly supervised label propagation processes.
Network hyperparameter table.
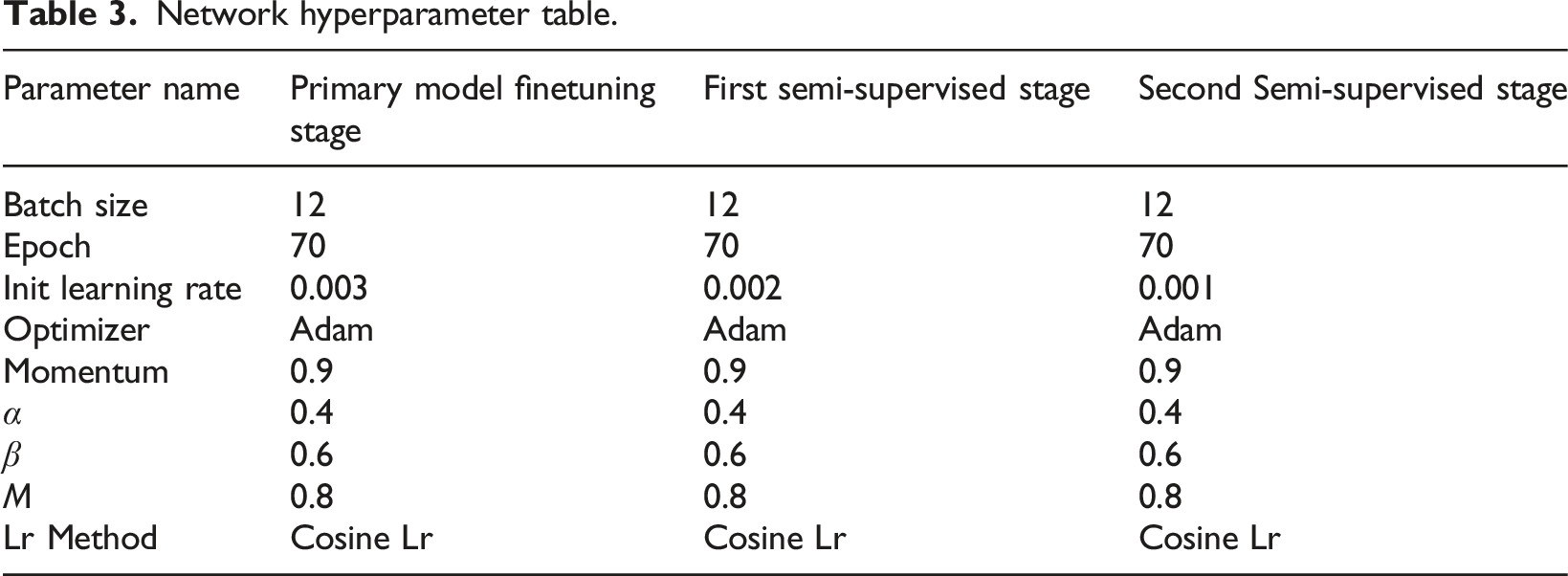
The parameters in Table 3 for the three training stages are basically the same, and the same cosine learning rate decay method is used.
This paper shows Figure 3, a training loss chart for the model during the three training stages. Due to the use of MSE Loss in the pre-training stage and the inability to effectively compare it with supervised loss, this paper shows the loss iteration for the latter three training stages. To visually demonstrate the actual performance of the model based on the Loss iteration curve of test set.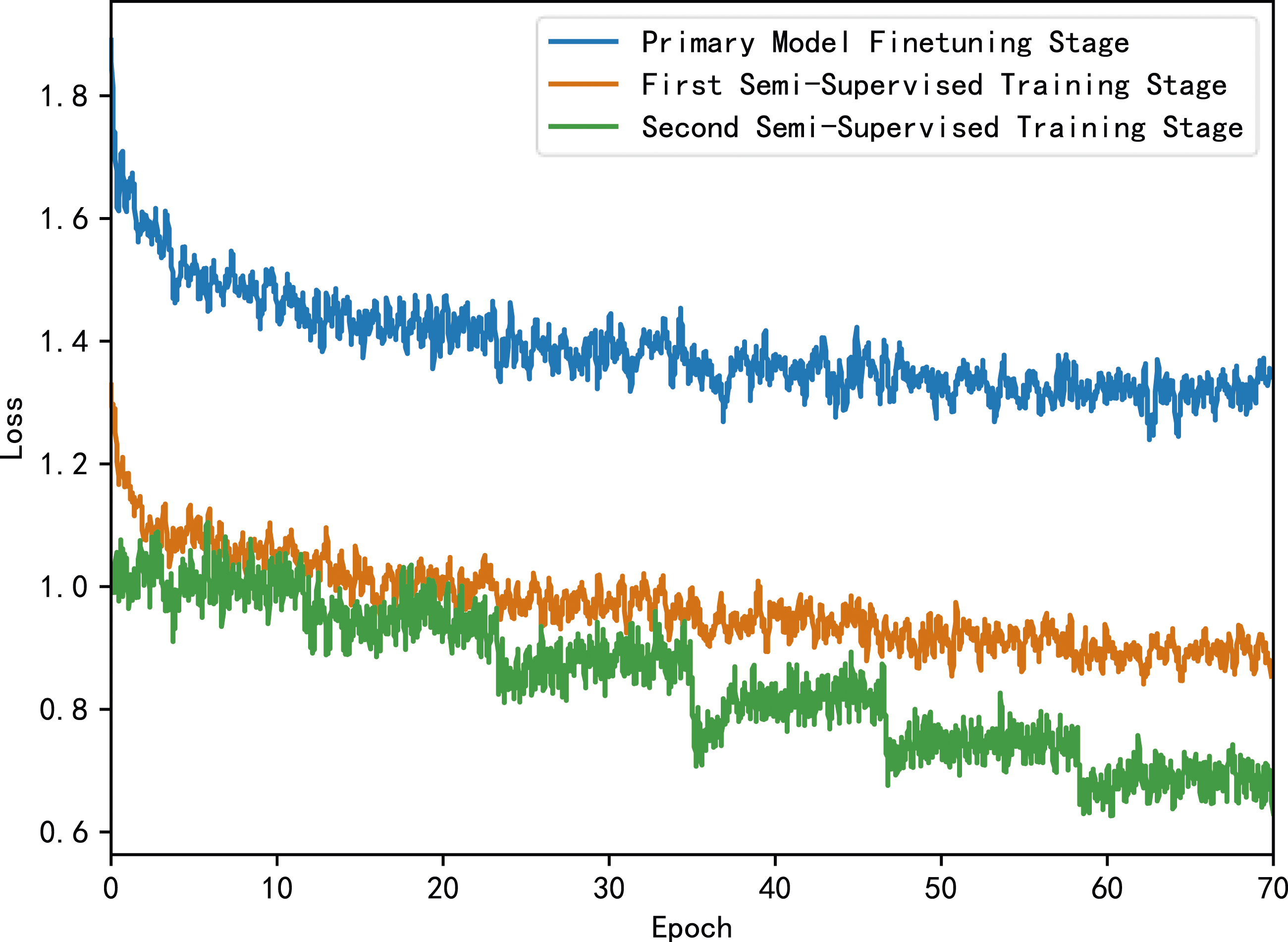
In the training iteration process shown in Figure 3, it can be observed that the loss gradually decreases with multiple iterations. It can be found that the model trained through this process has a significant optimization progress on the test set.
Also it can be observed that, under the training parameter settings in this paper, although all three curves exhibit a basic downward trend, their performance differs. During the pre-training phase, the model’s loss shows a modest decline, with a tendency to overfit in the later stages of training. In contrast, during the first weakly supervised training phase, the loss exhibits a more favorable downward trend, and there is less apparent overfitting. This is attributed to the different loss functions employed; training with reconstruction loss is inherently more challenging compared to classification loss. In the second weakly supervised training phase, the adoption of a cosine learning rate strategy introduces periodic fluctuations in the learning rate. Additionally, the learning rate is further reduced during the second weakly supervised training, leading to a conspicuous staircase-like loss curve pattern. In contrast, during the first weakly supervised training, the higher learning rate results in a less pronounced staircase pattern.
Discussion
This paper explores the application of weak-supervision and self-supervision in deep learning. In the context of the current development of visual pre-training models, it organically combines two cutting-edge methods of pre-training large models and weakly supervised learning to achieve better results for fine-grained classification in specific domains.
As shown in Figure 4, this paper presents the fine-grained classification effect of the proposed method and demonstrates the classification results on some early disease samples. Images of fine-grained classification quality.
The green icon in Figure 4 indicates correct recognition, and the red icon indicates incorrect classification. It is evident from the comparison that the weakly supervised training improves the accuracy of difficult-to-recognize and confusing samples. Even the accuracy of the primary model, as shown in the top 1 ACC of the 2021 challenge champion scheme, only reached 88.36%, 17 which can be seen as a significant improvement compared to the results of this paper. This also indicates that the model proposed in this paper has strong performance.
The workflow proposed in this paper uses multiple propagation methods in the weakly supervised label propagation step to prevent the bias generated by single training from being strengthened and accumulated. By using different data multiple times, we can enhance the performance of the model as much as possible, achieving the actual training effect of weak supervision data training better than using only strong supervision data, and also achieving the goal of high-precision early disease recognition proposed in this article.
We believe that the proposed workflow in this paper utilizes multiple iterations of label propagation in the weakly supervised label propagation step. This approach aims to prevent biases from being reinforced and accumulated through a single training iteration. By incorporating different forms of data through multiple iterations, the model’s performance is enhanced, resulting in better training outcomes compared to using only strongly supervised data. The ultimate goal of this approach is to achieve high-accuracy early disease detection, as stated in the paper.
Conclusion
In this study, we have presented a high-accuracy early disease classification model for apple leaf diseases. The model is built upon the MAE Transformer and optimized accordingly. We have also designed a self-supervised and weakly supervised training workflow to address the limited availability of expert-labeled data and unlabeled data. This workflow improves the performance of the strongly supervised learning process with limited labeled data, thereby enhancing the accuracy of early disease classification. By focusing on apple leaf diseases as a specific domain, we have explored cutting-edge techniques and their application sequence in high-accuracy fine-grained classification training. The proposed model has successfully achieved the goal of accurately identifying early-stage diseases in apple leaves. We believe that this study holds strong implications for other domains and can serve as a valuable reference.
Statements and declarations
Footnotes
Conflicting interest
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.