
Abstract
Sports competition data analysis and strategy optimization are important ways to enhance athlete competitiveness and team collaboration. The current competition analysis and strategy formulation have strong subjectivity, making it difficult to deeply understand the performance characteristics and patterns of athletes and teams. Traditional analysis methods cannot accurately identify the performance differences of different athletes, and there are limitations in their feature recognition and classification. In order to enhance the scientificity of strategy formulation and improve the performance of athletes in competitions, this article combined the K-means clustering algorithm and focused on basketball sports to conduct an in-depth analysis of sports competition data analysis and strategy optimization. Firstly, the competition data was collected and preprocessed. Then, feature selection was carried out from three dimensions: competition results, player performance, and team characteristics. Finally, the K-means clustering algorithm was used to perform hierarchical clustering on the original data through a hierarchical method. To verify its effectiveness, this article conducted practical analysis on the data of nearly 5 basketball competitions in 10 university basketball leagues in a certain province and optimized strategies based on cluster analysis. The results showed that in terms of player performance, compared to before optimization, the average number of rebounds, assists, and steals of team players optimized based on algorithm strategy increased by about 38.9%, 25.0%, and 63.2%, respectively. The conclusion indicates that the application of K-means clustering algorithm in sports competition data analysis and strategy optimization can help improve the competitive level of athletes and enhance their performance.
Keywords
Introduction
The progress of social economy has driven the development and prosperity of the sports industry.1,2 With the continuous expansion of the scale and quantity of competitions, sports data analysis has become an important method to improve the competitive ability of athletes. Sports competition data contains rich information, and traditional statistical analysis methods have limitations when dealing with large-scale and heterogeneous data. How to effectively mine and analyze these data in order to design more reasonable competition strategies is an urgent problem that needs to be solved in the current competitive sports industry. With the advent of the big data era, K-means clustering algorithms are increasingly being used in practical scenarios. It is easy to understand and implement, with high computational efficiency, and has broad application prospects in professional fields such as marketing, signal processing, image segmentation, and financial risk analysis. As a common clustering analysis method, it can effectively classify multi-dimensional data, thereby better discovering the internal connections and patterns between data. 3 Applying it to competition data analysis can better understand the important influencing factors and patterns during the competition process, help coaches and athletes formulate strategies more accurately, and improve the overall strength and effectiveness of the team. This has important practical value and significance for promoting the development of the competitive sports industry and improving the level of competition.
In order to improve the scientificity of training strategy formulation and enhance the performance level of athletes, this article combines the K-means algorithm to study the analysis of sports competition data and strategy optimization. Taking basketball as an example, clustering analysis is conducted on competition data, and experimental analysis is conducted on this basis. To verify its effectiveness, this article takes participating teams from 10 university basketball leagues in a certain province as samples and takes data from nearly 5 competitions of each team as objects. Practical analysis is conducted from three levels: clustering results, player performance, and team performance. From the clustering results, it can be seen that the overall allocation of data at the three levels of competition results, player performance, and team characteristics is good, and the silhouette coefficient results of each clustering level are generally close to 1; from the perspective of player performance, compared to before optimization, the average number of rebounds, assists, and steals of team players optimized based on algorithm strategy increases by about 38.9%, 25.0%, and 63.2%, respectively; from the perspective of team performance, compared to before optimization, the average score of the team after optimization based on algorithm clustering analysis increases by 12.7%, and the difference in average scores between home and away competitions decreases by 50.0%. The innovation of this article lies in identifying different types of athletes or performance patterns through clustering analysis of athlete performance data, and then developing personalized training plans for each type. In practical applications, applying K-means clustering algorithm for sports competition data analysis and strategy optimization can help improve the overall performance of athletes and teams, and provide good support for enhancing their competitive level.
Related works
Sports data analysis is not only a tool but also a necessary means of optimizing athlete training.4,5 With the rapid development and application of digital sports, sports competition data analysis and strategy optimization have also achieved certain results. To balance team building decisions, Muniz Megan provided a sports analysis model based on mixed integer nonlinear programming, which rephrased the objective function and overcame the computational challenges of nonlinearity. By using team competition data from 2019 to 2020 as a case study, it was demonstrated that the proposed model maximized the total value of the team and balanced the synergy between players. 6 Cao Yuan established a multi-objective optimization method and a simulation model for sports activity exercise data in a multi-decision network design model based on existing decision network planning methods and situational analysis methods, and analyzed sports competition data and strategy optimization. Finally, the experimental results showed that the proposed model can simultaneously select multiple decision spaces. 7 In order to gain a competitive advantage and manage injury risk, Torres-Ronda Lorena discussed the application of a quantitative training and competition feature tracking system in sports competition data analysis and strategy optimization, and demonstrated through examples that the system can monitor and evaluate the training and competitions of each sport, and support the prescription of training loads and objective decision-making of operations. 8 Although existing analytical methods have certain guiding capabilities for improving athlete performance and competition strategies, they still struggle to effectively handle a large amount of multi-dimensional competition data and cannot uncover the potential patterns and correlations behind the data. They often focus on a few indicators or data dimensions, while ignoring the more complex and diverse factors in sports competitions, resulting in one-sided and incomplete analysis results.
The development of big data technology and algorithms has provided more possibilities for intelligent analysis of the potential patterns and correlations of competition data. 9 Fujii Keisuke proposed a data-driven analysis method to quantitatively understand behaviors in invasive team sports such as basketball and football. By extracting easily interpretable features or rules from competition data, behaviors were generated and controlled in a visually understandable manner, providing support for sports strategy optimization. 10 Wang Zejun proposed a football tactical analysis method based on position data in the context of big data, which automatically identified the characteristics of team tactics through machine learning algorithms. By using data visualization and reporting methods, objective information was provided for optimizing athlete performance results, and a new approach was provided for football tactical research. 11 Liu Aijun proposed an effective video-based visualization framework based on artificial intelligence and big data analysis, which extracted temporal and spatial features of sports videos to classify them. The experimental results showed that compared with other existing models, the proposed model achieved 98.7% precision in analyzing competition data. 12 Based on 100 sets of historical scoring data from 14 teams in the basketball league, Zhang Hanzhe qualitatively analyzed the level of each team using Analytic Hierarchy Process (AHP) and then compared these data through cluster analysis. This provided a more reasonable and scientific method for improving the probability of each team winning the championship, effectively promoting the development of basketball. 13 Clustering algorithms can fully consider the ability to simultaneously consider multiple data dimensions and analyze competition situations more intelligently and comprehensively. However, most studies still have certain limitations in personalized tactical optimization and training program development.
Sports competition data analysis and strategy optimization
Sports competition data analysis is the analysis of various data information displayed by athletes based on their performance on the field, such as the performance of technical movements. While conducting longitudinal analysis of individual athlete competition data, it is also necessary to conduct horizontal analysis with other athletes. Basketball is a type of team sports event with rich statistical data, and the individual performance of each player has a significant impact on the results of the event.14,15 This article takes basketball sports as an example and, through clustering analysis of competition data, explores the performance characteristics of athletes and teams to achieve strategy optimization.
Data collection and processing
Compared to real-time data, historical competition data can better reflect the sports development trends and changes of athletes over a long period of time. Therefore, in data collection, this article only analyzes historical competition data.
This article uses Python to obtain competition data from relevant websites. In the data collection process, the site is first opened from the searcher in yield, and the website is processed through the engine. Then, the crawler is used to obtain the URL (Uniform Resource Locator). When the engine obtains the first URL, it does not process it and sends it to the scheduler, as shown in Figure 1. Crawling process of competition data.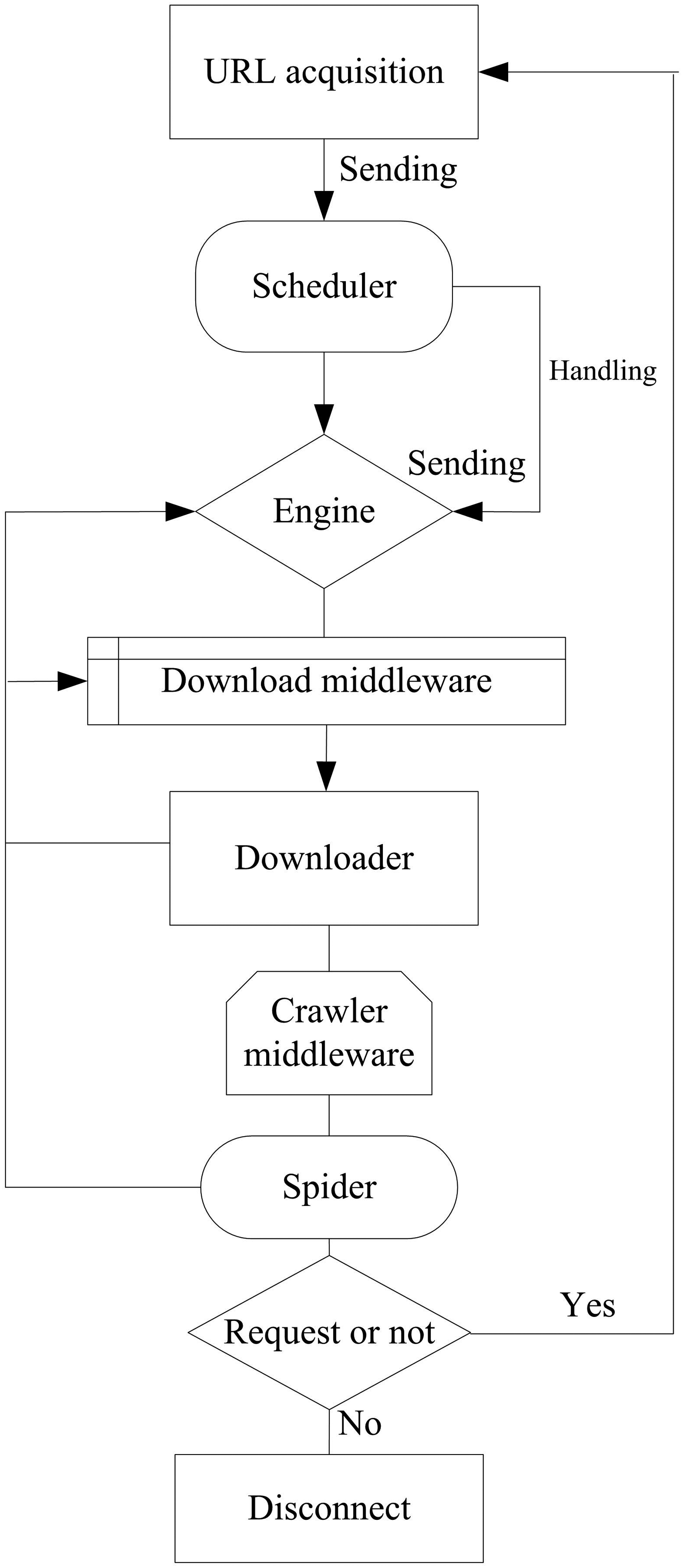
In Figure 1, when the scheduler processes it, it generates a request instruction and sends it to the engine for post-processing. When a request instruction is received, the scheduler feeds back each URL in the list to the engine, which sends feedback on the instruction to the downloader through a downloaded middleware. After the webpage download program is completed, the information is transmitted back to the engine through the download middleware. At this point, the engine receives a response to download the program and sends it to the crawler through the crawler middleware. The crawler processes these responses and returns the crawled items, and then sends the request instructions to the engine. The scheduler provides pending requests to the engine, ensuring that the same URL is not repeatedly crawled, while the engine is responsible for processing these requests and generating results. This process is repeated until there are no URL request instructions in the schedule, and the connection between the engine and the domain is then disconnected.
In response to the differences in data structure among different sites and the coexistence of peak concurrency in databases, stability must be maintained to ensure data integrity during corresponding crawler processing. This article uses Requests to send HTTP (Hypertext Transfer Protocol) requests to users and then uses BeautifulSoup to analyze the HTML (Hyper Text Markup Language) structure, extracting relevant data such as competition dates, opposing sides, scores, and player performance, and storing them in the Pandas data framework. In order to obtain more complete data, a third-party open source API (Application Programming Interface) is used to obtain JSON (JavaScript Object Notation) format data, which includes detailed statistical data of each competition, player personal data, team data, etc., and then analyzed and stored through Pandas. API has ideal response speed and stability, and in practical operation, HTTP protocol is used to call API. In JSON data conversion, the pandas. read_comson() function is used to directly read JSON strings or files, and Pandas’ data processing capabilities are used to clean and convert the data.
After collecting competition data, data cleaning and preprocessing are carried out to obtain a more concise and accurate dataset. For data with a small proportion of missing data, the mean of the column is used to fill in; if the missing ratio exceeds 40%, it is directly removed. Incomplete data filled in with blank values in the record; excess data is directly deleted; for inconsistent data types, standardized feature processing methods are used to express discrete data using numerical values


Feature selection
In order to more accurately depict the competition situation, a deep analysis of the performance of athletes and the characteristics of the team is conducted, laying a good foundation for subsequent data analysis and decision optimization. Based on the characteristics of basketball competitions, feature engineering is constructed in the collected competition data. From the three aspects of competition results, player performance, and team characteristics, feature data is extracted and then used as input for the algorithm, as shown in Figure 2. Feature selection.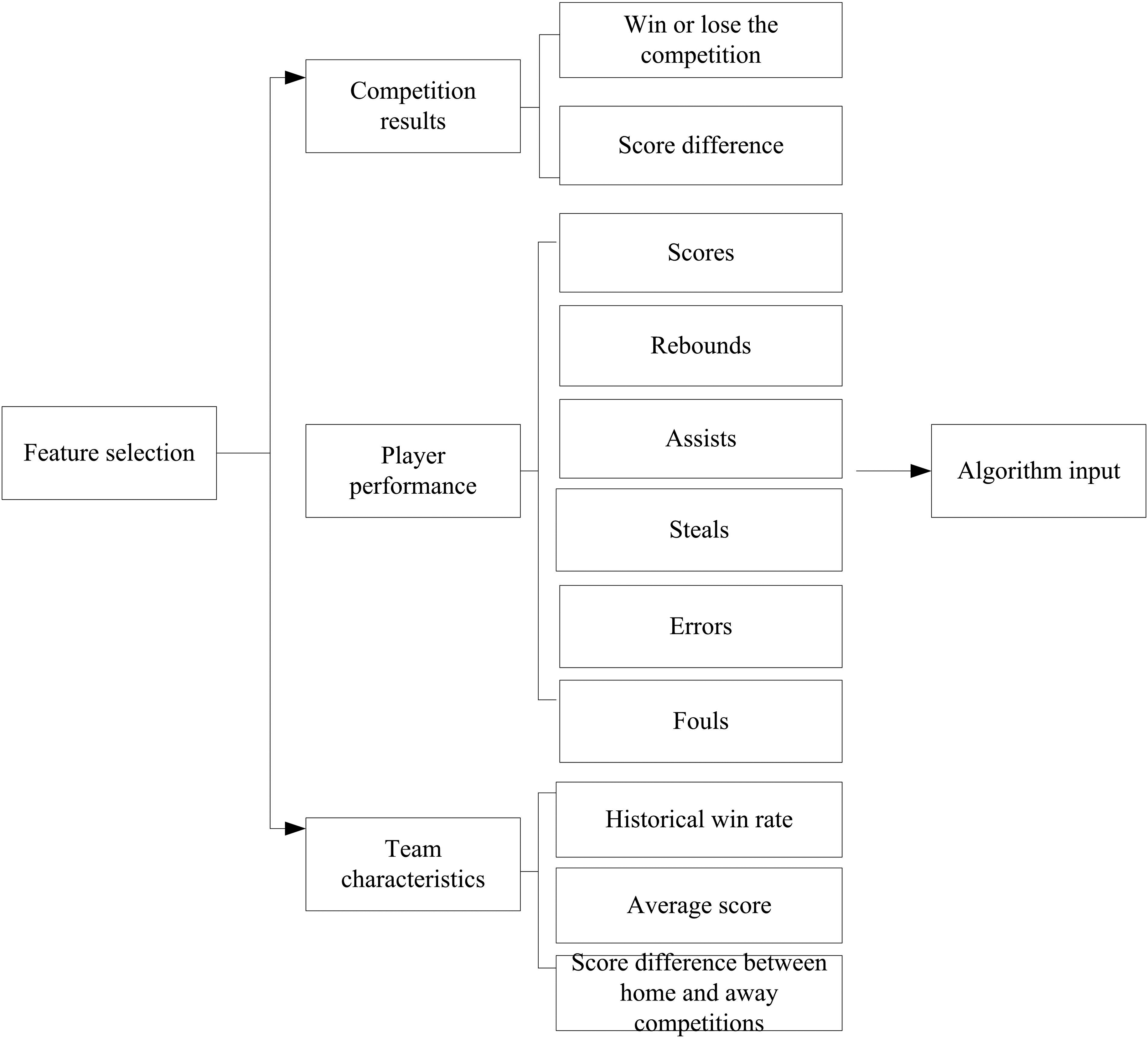
Competition results
Feature selection of competition results.

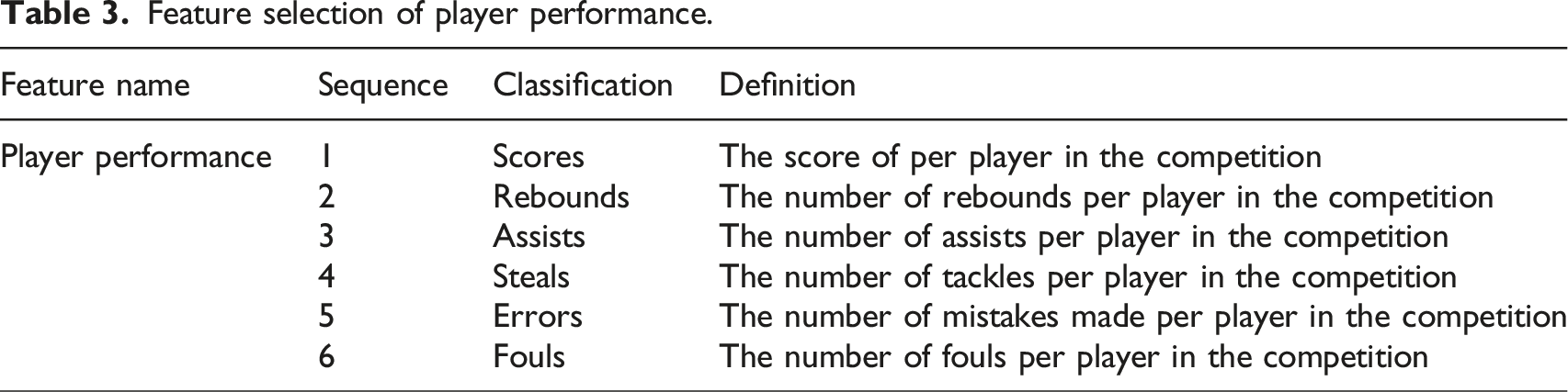
Player performance
Feature selection of player performance.
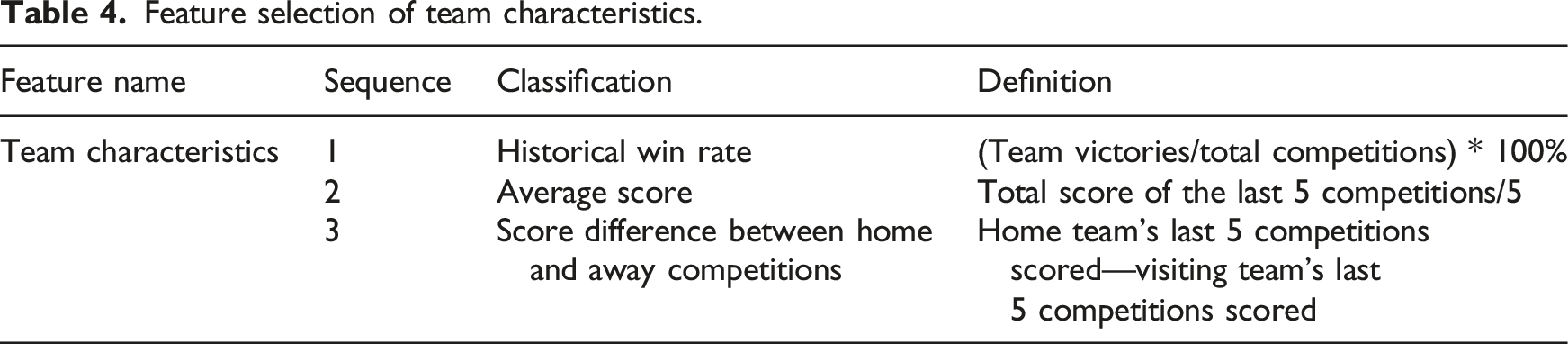
Team characteristics
Feature selection of team characteristics.
Cluster analysis
On the basis of feature selection, the cluster analysis is used to deeply mine and analyze the data. As an unsupervised learning method, clustering analysis measures the similarity between data and gathers data that meet similar conditions, while those that do not match are classified into different groups.19,20 In competition data analysis, clustering algorithms are used to divide competition data into several clusters, effectively identifying the characteristics of participating players and teams. By exploring the patterns and rules contained in competition data, the understanding of competition results, player performance, and team characteristics can be deepened.
The K-means algorithm is a simple and effective algorithm.21,22 It is suitable for partitioning competition data with large-scale characteristics. The basic idea is to divide the dataset into K clusters, so that the data points within each cluster are similar to each other, while the data points between different clusters have significant differences. K-means iteratively finds the structure of the dataset, with the core being to define the center points of clusters and partition the data based on these centroids. This article combines the K-means algorithm to analyze feature data, as shown in Figure 3. K-means algorithm clustering.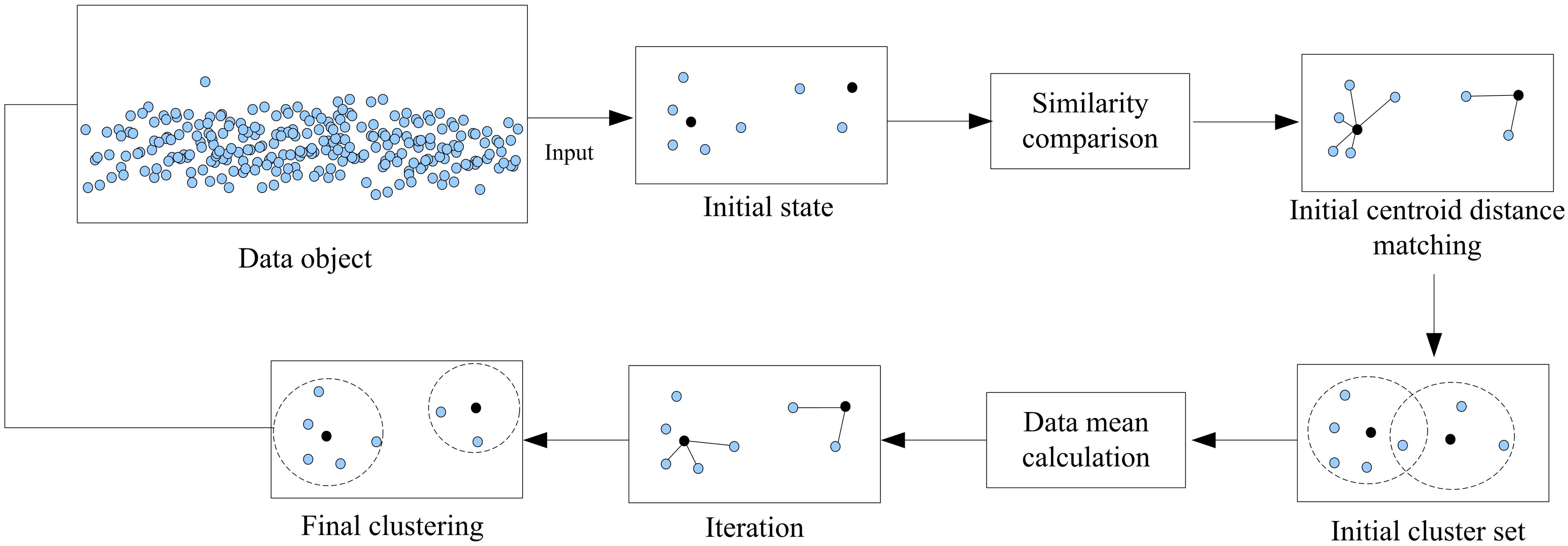
From Figure 3, it can be seen that in clustering analysis, k targets are randomly selected from the competition feature data to form the initial cluster. Then, based on the principle of high similarity between the same cluster objects and low similarity between different cluster objects, the remaining targets are assigned to the corresponding clusters, and a new cluster is formed based on this. The average of the data in the new cluster is taken and used as the center of the new cluster until the cluster center no longer changes, and finally the clustering result is output.
The similarity between data points within the same cluster is measured using Euclidean distance. Assuming that the competition dataset 
Among them, 
On this basis, using the established clustering objective function and iteratively correcting it, each iteration is carried out towards the direction of minimizing the objective function, thereby obtaining the optimal clustering result. The competition data sample set 
The objective function 
Among them, 
Basketball competition data has a large scale and many features, and using only the K-means method limits its discriminative ability. Moreover, excessive data dimensionality can also lead to poor clustering performance. To improve the time complexity of the algorithm and obtain better initial centers, a hierarchical clustering method is applied to the original data, as shown in Figure 4. Hierarchical clustering analysis.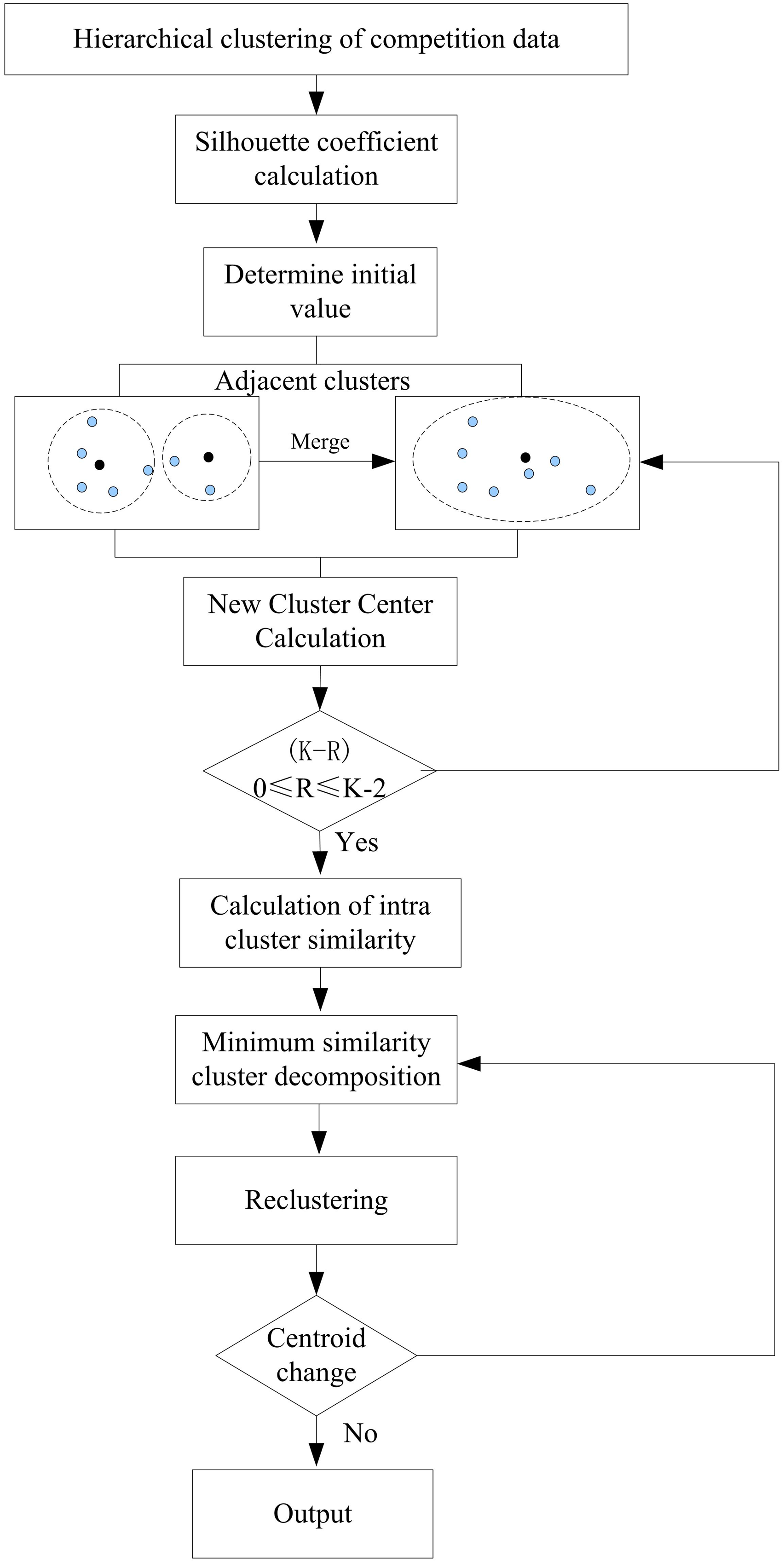
In Figure 4, for the problem of determining the value of k, the approximate number of classes is determined by the silhouette coefficient first. It is assumed that the competition data can be clustered to form a result, that is, these data have been divided into several clusters. For any data object 
It is assumed that 
Then, the profile coefficient 
The silhouette coefficient helps evaluate whether the clustering is reasonable, that is, whether the samples within each cluster are compact and whether good separation is maintained between different clusters. A high silhouette coefficient (close to 1) indicates that the sample matches well in the cluster and there is a clear distinction between clusters, and a low silhouette coefficient (close to −1) indicates that the sample may have been incorrectly assigned to adjacent clusters or that the sample within the cluster is not tightly packed. Among them,
Based on these characteristics, targeted training and competition strategies are developed for each cluster. By analyzing post-competition data, training plans and tactical arrangements are continuously optimized, ensuring the effectiveness and adaptability of strategies, and achieving better competition performance and higher win rates.
Basketball competition data analysis and strategy optimization practice
In order to analyze the data analysis and strategy optimization effects of sports competitions using K-means clustering algorithm, this article takes participating teams from 10 university basketball leagues in a certain province as samples and takes the data of nearly 5 competitions of each team (5 players per team) as the object for data analysis and strategy optimization practice. The practical effects are verified from three levels: clustering results, player performance, and team performance.
Experimental data
Using the official website of university basketball leagues publicly available in the province as the data source, the competition data from the experiment is obtained through web scraping. In data collection, by using the Scrap crawler, starting from the homepage of the website, and extracting competition links, each competition page is accessed one by one, and then the date, participating teams, and competition result information of each competition are extracted. The data mainly includes basic information of athletes, game data such as scores, rebounds, assists, game results, and game dates. Considering the timeliness of competition data, in the processing of differences between long-term and recent data, the weighting is gradually reduced in chronological order, with the latest game having the highest weight and gradually decreasing to the earliest game.
The collected data is cleaned up, and missing values and outliers are processed to ensure data quality. In order to eliminate dimensional effects and ensure comparability of data, different data multiples are standardized. Then, the competition results, player performance, and team characteristic values are extracted from the original competition data. 10-fold cross-validation can provide a more stable model performance estimate, with 90% of the data used to train the model in each cross validation cycle, which can reduce the risk of model overfitting. The data is divided into 10 groups according to sample distribution, with 9 groups being the training group and 1 group being the testing group. Using K-means clustering algorithm, cluster analysis is conducted on the selected teams to study the competition characteristics and performance of each team within the cluster.
Experimental results
Cluster results
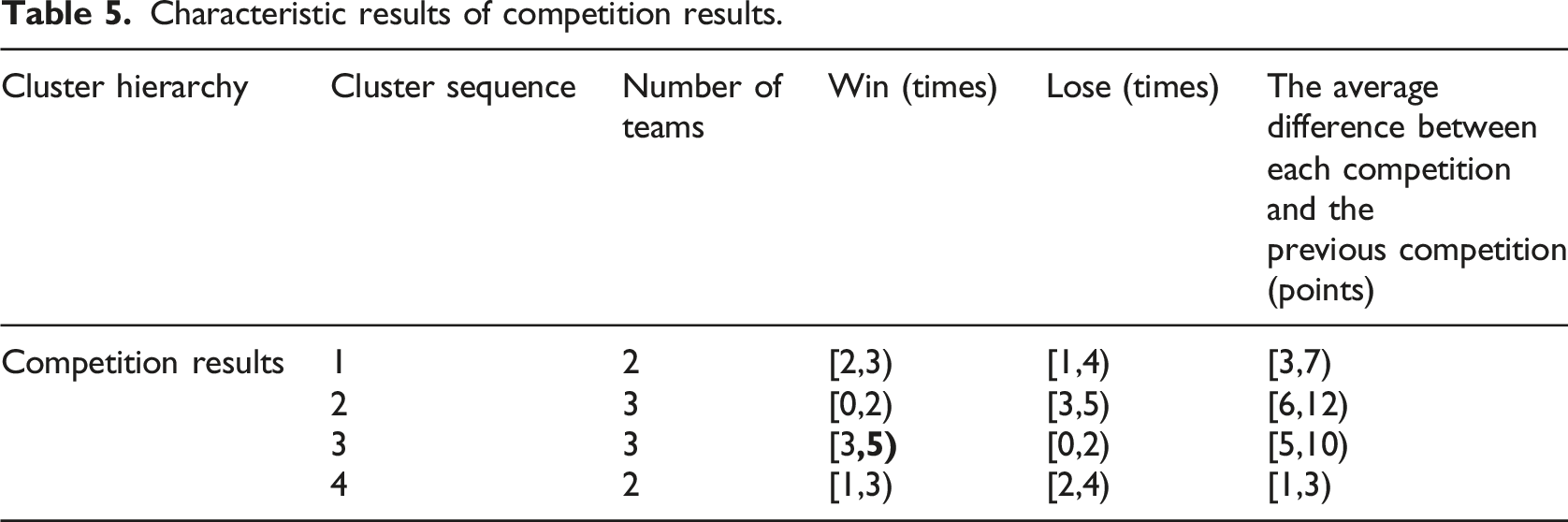
Characteristic results of competition results.
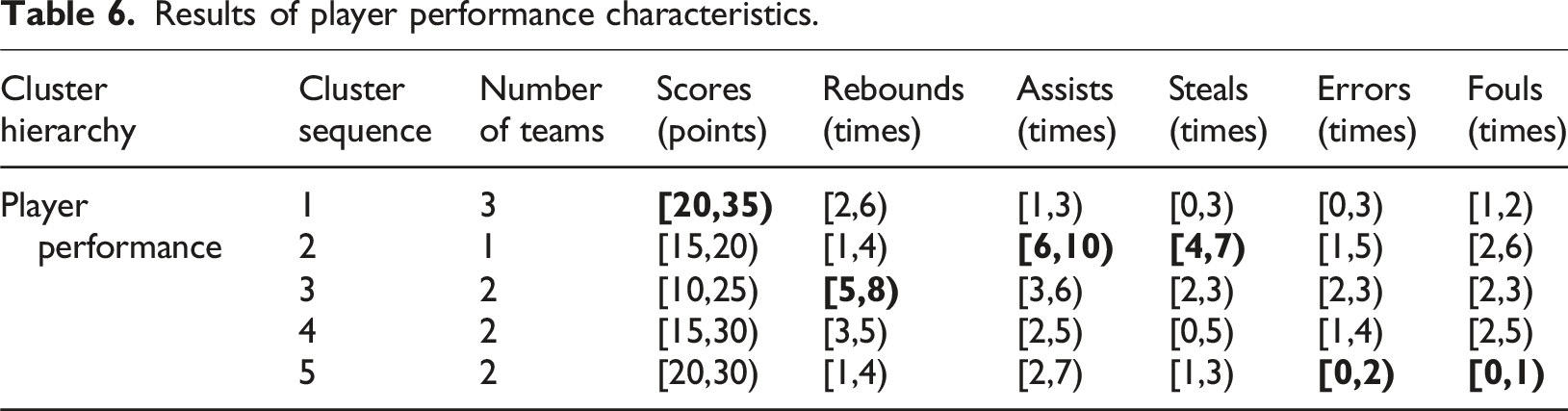
Results of player performance characteristics.
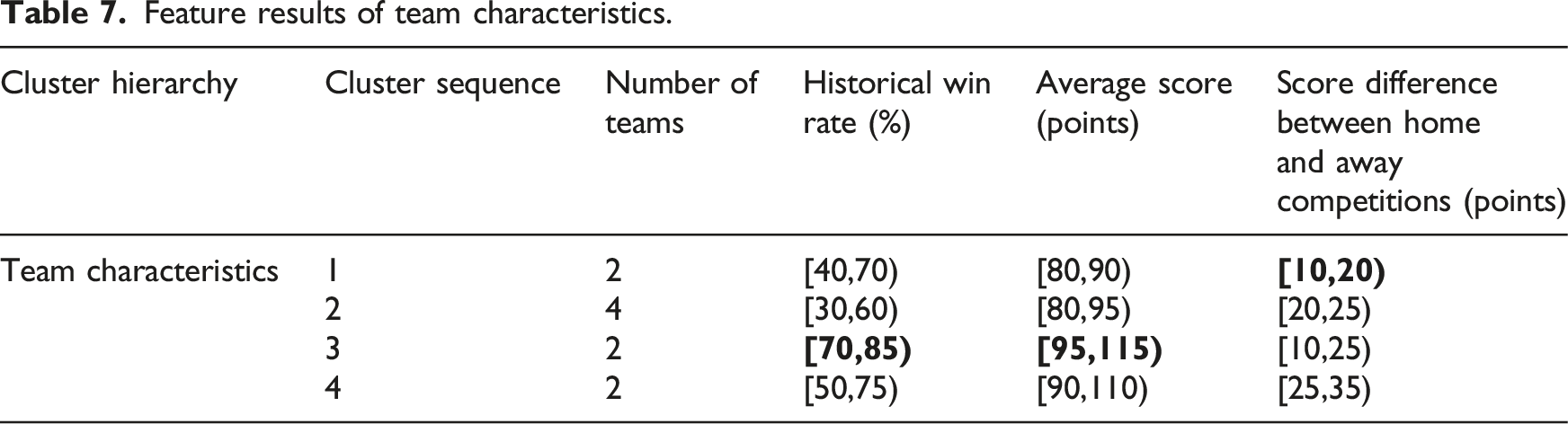
Feature results of team characteristics.
From Table 5, it can be seen that the team in Cluster 3 has the highest winning result range, indicating that the team in this cluster has a better level of state and performance in the competition; the team in Cluster 4 has the lowest average difference interval between each competition and the previous competition, indicating that the team in this cluster has relatively ideal stability in their performance in the competition.
From Table 6, it can be seen that the scoring range of each player in the team in Cluster 1 is the highest, reaching [20,35), indicating that the attacking ability of the team in Cluster 1 is relatively ideal; the scoring range of each player in Cluster 2 is the highest in the number of assists and steals in the competition, reaching [6,10) and [4,7), respectively, indicating that the team in Cluster 1 has excellent cooperation and personal defensive ability; the team in Cluster 3 has the highest number of rebounds in the competition, reaching [5,8), indicating that the team in Cluster 2 has a higher level of offensive and defensive rebounds; the team in Cluster 5 has the lowest number of errors and fouls scored in the competition, reaching [0,2) and [0,1), respectively, indicating that the team members in the cluster have ideal control abilities on the field.
From Table 7, it can be seen that the team in Cluster 3 has the highest historical win rate and average score interval results, reaching [70,85) and [95, 115), respectively, indicating that the team in this cluster achieves relatively ideal results in the last 5 competitions. The team in Cluster 1 has the smallest score difference interval results in home and away competitions, with specific interval results of [10, 20), indicating that the team in this cluster is less affected by the competition environment and the overall performance level of the team is relatively stable.
To verify the clustering results, the silhouette coefficients of the clustering analysis results are calculated. Among them, the coefficient results are within the range of [0,1). When the coefficient is close to −1, it indicates that the data object is significantly different from the cluster object, and the overall allocation of the dataset is poor; when the coefficient is close to 1, it indicates that the data object and the cluster object have less dissimilarity, and the overall allocation of the dataset is better. The final result is shown in Figure 5. Silhouette coefficient result. (a) Coefficient results of the competition result hierarchy. (b) Coefficient results of player performance levels. (c) Coefficient results of team characteristic levels.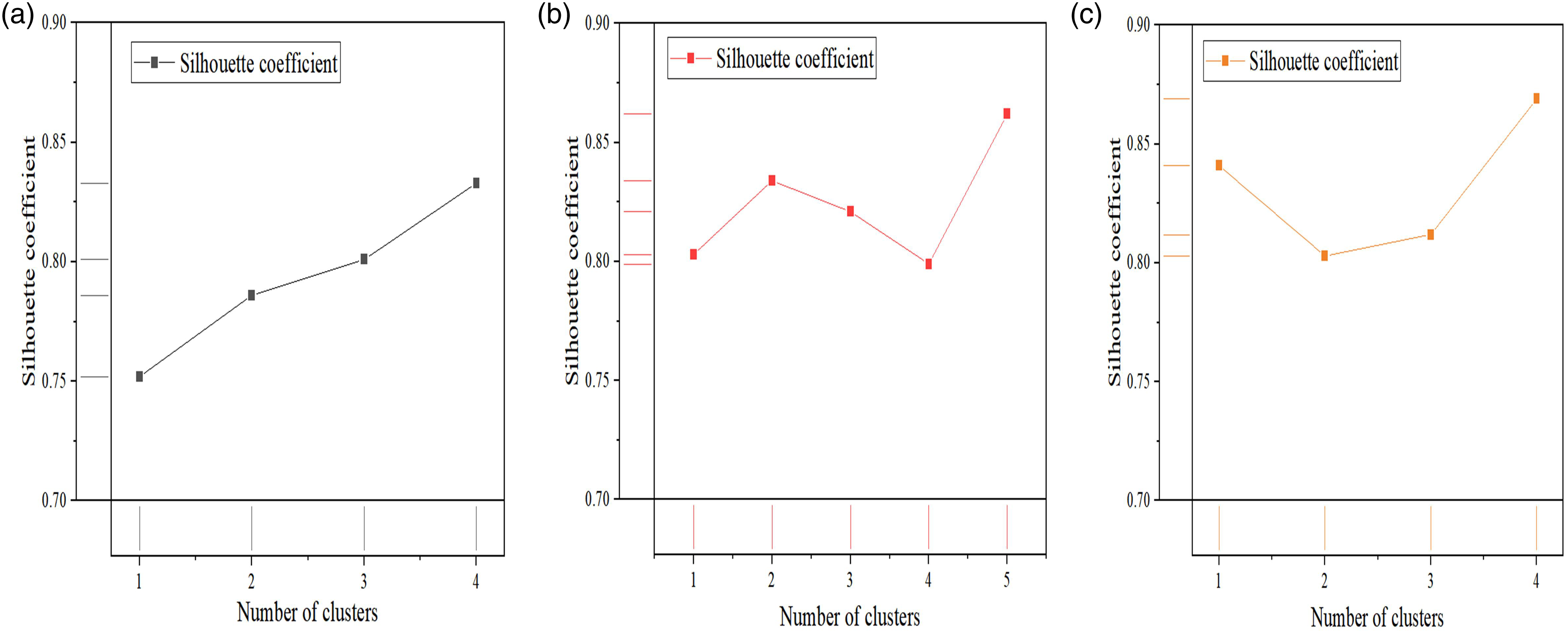
From Figure 5, it can be seen that the overall silhouette coefficient results of each clustering level are close to 1, indicating a better overall allocation of data for the three levels and a better clustering effect. From the specific experimental results, in Figure 5(a), when the number of clusters is 4, the coefficient result reaches 0.833; in Figure 5(b), when the number of clusters is 5, the coefficient result reaches 0.862; in Figure 5(c), when the number of clusters is 4, the coefficient result reaches 0.869. The clustering algorithm effectively captures the intrinsic structure of the data. All clustering levels show high silhouette coefficients, close to 1. At each level, data points are tightly clustered in their respective clusters and maintain good separation from other clusters. This result indicates that the distribution of sample points in the competition data is reasonable, with good inter class separation. The clustering analysis results for competition results, player performance, and team characteristics have high credibility and interpretability.
Based on the clustering results, targeted strategies are developed according to the characteristics of each cluster. In training and competition, the team in the test set is used as the sample object, and the lineup configuration is adjusted based on the team’s player performance and team characteristics. For players with strong offensive skills, emphasis should be placed on attacking efficiency, and training should be provided for quick counterattacks and perimeter shooting. For players with strong defense, defensive intensity is emphasized, and rebounding competition and defensive positioning training are strengthened. The effects of strategy optimization before and after from two aspects are compared: player performance and team performance.
Player performance
In the competition, the individual abilities, technical level, and competitive state of players are crucial for the success of the team.
30
Optimization strategies are applied to the daily training of the team, with a training period of 8 weeks. Before and after the end of the training cycle, the team is tested 5 times, and their average performance before and after optimization is compared in terms of rebounds, assists, steals, errors, and fouls. The final result is shown in Figure 6. Comparison of player performance. (a) Performance of players before optimization. (b) Performance of players after optimization.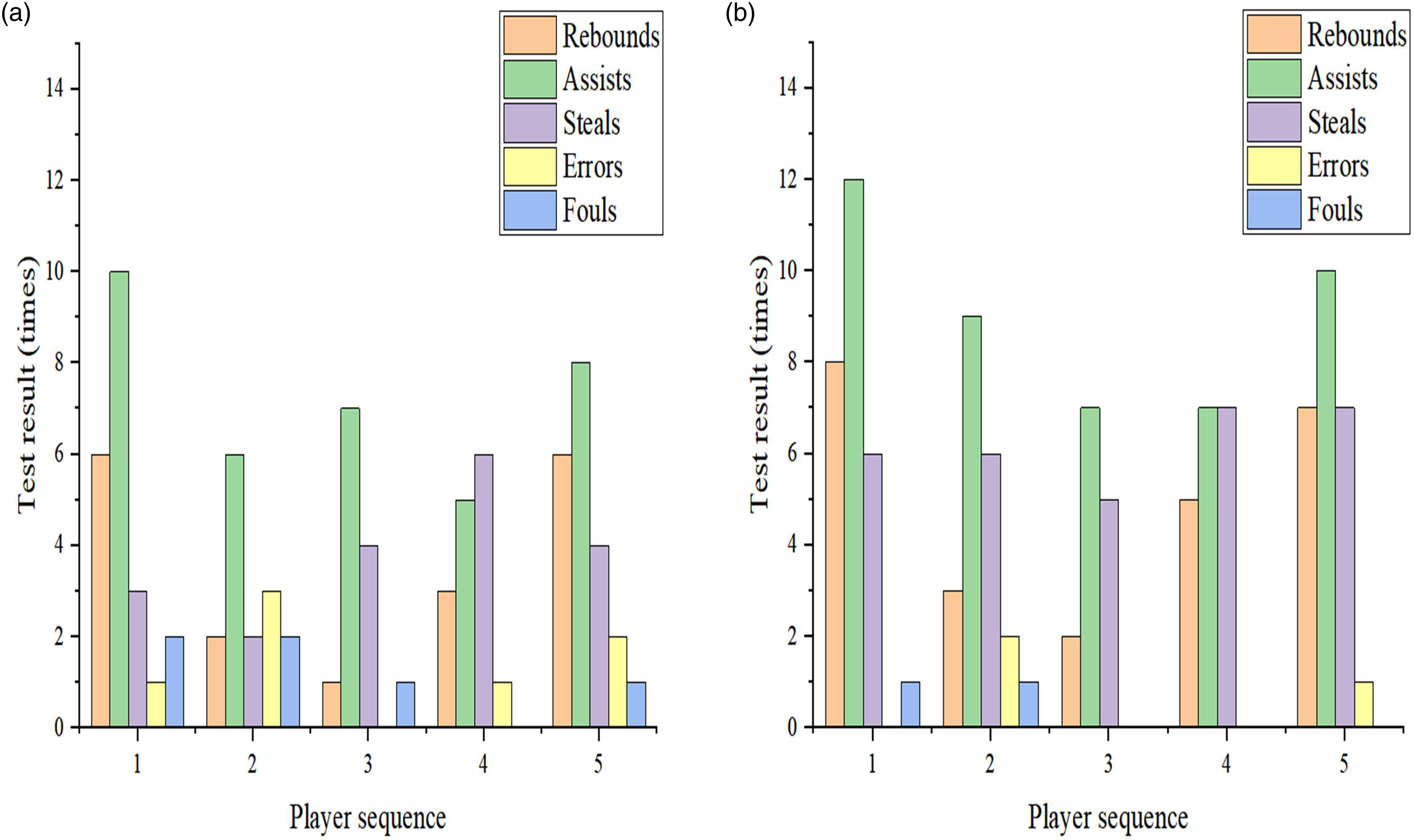
From Figure 6, it can be seen that under the strategy optimization based on cluster analysis, there is a significant improvement in the performance of players before and after training. In Figure 6(a), the average number of rebounds, assists, steals, turnovers, and fouls of the team members before optimization reaches approximately 3.6, 7.2, 3.8, 1.4, and 1.2, respectively; in Figure 6(b), the average number of rebounds, assists, steals, turnovers, and fouls of the team members after optimization is about 5, 9, 6.2, 0.6, and 0.4, respectively. From the specific comparison results, compared to before optimization, the average number of rebounds, assists, and steals of players in the team after optimization increases by about 38.9%, 25.0%, and 63.2%, respectively. This result not only reflects the improvement of the team in rebounding, assisting, and stealing events but also reflects the comprehensive improvement of the team’s overall strategy, individual player abilities, and teamwork. Through data analysis guided strategy optimization, the team can continuously improve its performance. Coaches can build tactical systems around versatile players, as they can contribute to both offense and defense. The rebounding king can serve as a tactical supplement, with the former focusing on scoring at critical moments and the latter playing a role in rebounding protection.
Team performance
As a sport that heavily relies on teamwork, team performance plays a decisive role in the outcome of basketball competitions. This article compares the team performance before and after strategy optimization from two aspects: scores and the difference in scores between home and away competitions. The final results are shown in Figure 7. Comparison of team performance. (a) Team performance before optimization. (b) Team performance after optimization.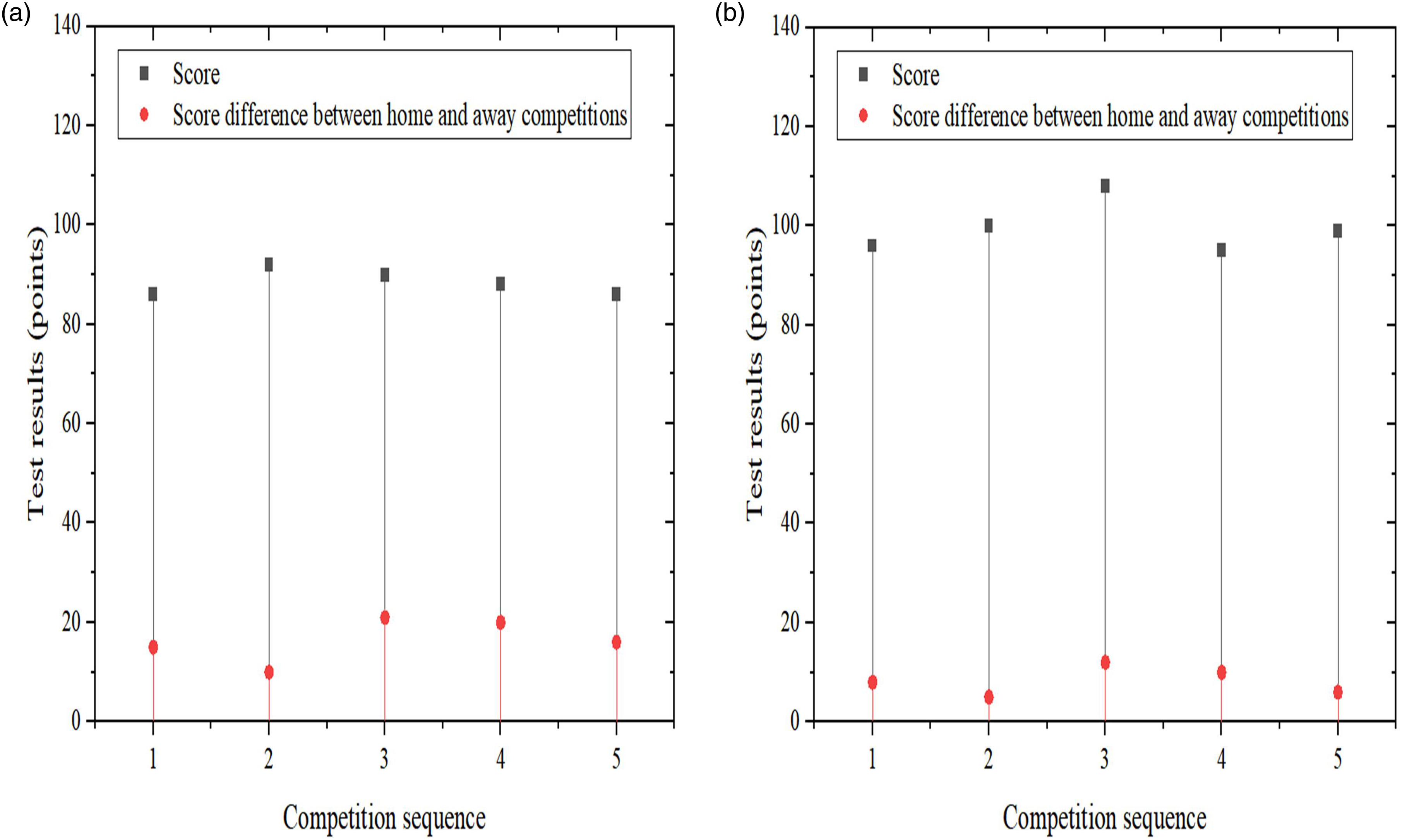
From Figure 7, it can be seen that there are certain differences in team performance before and after optimization. In Figure 7(a), the average score of the team in each competition and the difference in average scores between home and away competitions before optimization are 88.4 points and 16.4 points, respectively; in Figure 7(b), the average score of the optimized team in each competition and the difference in average scores between home and away competitions are 99.6 points and 8.2 points, respectively. From the specific comparison results, compared to before optimization, the average score of the team after clustering analysis optimization based on K-means algorithm increases by 12.7%, and the average score difference between home and away competitions decreases by 50.0%. This result indicates that under strategic optimization, the overall performance of the team and its adaptability in different environments have been improved.
Discussion
In the experimental analysis, to verify the effectiveness of applying K-means clustering algorithm in sports competition data analysis and strategy optimization, this article conducts experimental analysis from three levels: clustering results, player performance, and team performance. From the clustering results, the overall silhouette coefficient results of the clustering analysis of the competition results, player performance, and team characteristics are close to 1. This indicates that the algorithm in this article has performed a good classification of the competition data, which can well reflect the internal structure and classification characteristics of the data. From the perspective of player performance, after optimizing the training strategy, the number of rebounds, assists, and steals of each player in the team has increased, while the number of errors and fouls has decreased to a certain extent; from the perspective of team performance, compared to before optimization, the average score of the optimized team in each competition and the difference in average scores between home and away competitions have achieved significant improvement. Supported by the K-means clustering algorithm, the overall performance of players and teams has been effectively improved through analysis of competition data and optimization of training strategies.
Conclusions
The expansion and development of the sports industry and event scale have put forward higher requirements for the level of mobilization and competition. The current traditional competition analysis and strategy formulation often rely on the subjective experience of coaches, making it difficult to comprehensively analyze the performance characteristics of players and the entire team. In order to improve the scientificity of training and competition strategy formulation, and improve the technical level of athletes, this article combined the K-means clustering algorithm to analyze the competition data and strategy optimization of basketball as the object. With the support of K-means clustering algorithm, a good classification of competition data was achieved, and on this basis, the performance of players and the overall performance of the team were effectively improved, enhancing their competitive level. K-means clustering can help coaches and analysts identify different types and styles of athletes and customize personalized training plans and competition strategies based on clustering results, not only improving the scientific and competitive level of competitive sports but also promoting the modernization and data-driven transformation of the sports industry. In actual sports training, based on clustering results, the strengths and most suitable roles of each player can be identified, and personalized training plans and on-field responsibilities can be developed. Periodic data analysis can be implemented, and player performance and strategy effectiveness can be monitored to adjust training plans and game strategies in a timely manner. The application of cluster analysis and K-means algorithm in game data analysis helps optimize resource allocation, provide forward-looking guidance for long-term planning and short-term adjustments of teams, and promote the intelligent, efficient, and fair development of sports in the future. Although this study can provide some guidance for the daily training and competition strategy formulation of athletes to a certain extent, there are also certain limitations. The environment and conditions of sports competitions often change, and strategy optimization needs to be able to flexibly adapt to these changes, rather than just relying on static analysis of historical data. This article did not delve into the impact of the timeliness and regionality of competition data on the analysis results, and the universality of the algorithm in practical scenarios still needs further optimization and verification. Future research should consider expanding data sources and sample ranges, and delving into the impact of different factors on the analysis results, in order to promote the intelligent and healthy development of the sports industry.
Statements and declarations
Footnotes
Conflicting interest
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.