
Abstract
The IoT and Artificial intelligence, the amount of information generated on the Web site is increasing. The rise of the Hadoop distributed cloud computing platform (HDCCP) makes it possible to use multiple computing nodes for parallel computing to solve the performance problems of traditional serial algorithms. The purpose of this paper is to study data design based on cloud computing and improved k-means algorithm (KMA). This paper deeply researches Hadoop distributed cloud computing platform and clustering algorithm and other related technologies, and designs and implements a cluster analysis system (CAS) based on HP. And through an in-depth analysis of the problems existing in the KMA, an improved scheme based on the HDP is designed. The experimental environment was conFig.d with the cluster analysis system implemented. Finally, the improved KMPA was tested experimentally from four directions: convergence speed, acceleration ratio, initialization sampling rate, and accuracy rate. We can see the experimental results that the CAS based on the HDCCP designed in this paper can provide efficient and configurable cluster analysis services. In this paper, the correct rate is 90.7%.
Introduction
The popularization of the Internet, the world has entered an era of high informatization, and all kinds of huge amounts of information are flooded around people [1]. In the face of increasingly large amounts of data, traditional database-based storage solutions appear to be increasingly stretched. How to use the high computing power of modern computers to automatically extract potential and valuable information from people’s production and life without human supervision has become an urgent issue. Cluster analysis is a method to classify the input original data set according to different rules. To extract information from data, the first task is to classify it, so cluster analysis is the first step in the data mining process. The Internet of Things, and artificial intelligence, the amount of information generated on the Web site is getting larger and larger, and daily PB-level log information is generated, which makes the traditional clustering algorithms facing unprecedented challenges. Limited by the hardware limitations of a single computing node of a computer, the traditional cluster-based clustering algorithm is extremely limited in its ability to improve the processing of data of this size.
Distributed cloud computing is proposed under the Internet massive data environment. As one of the most popular open-source distributed frameworks at present, Hadoop has the characteristics of high efficiency, strong reliability, sustainable scalability, and low deployment and maintenance costs. Therefore, how to make full use of the computing power of the Hadoop distributed cloud platform, apply it to cluster analysis, and use parallelized improvements, this research has also become very practical. Because of the importance of the clustering algorithm in data mining technology, the research content of this paper has great research value and significance.
Boru D and his team see cloud computing as an emerging paradigm, providing computing resources as services over the network. Copying data (such as a database) closer to the data consumer (such as a cloud application) is considered a promising solution. It allows to minimize network latency and bandwidth usage. Evaluation results obtained during extensive simulations help reveal trade-offs between performance and energy efficiency and guide the design of future data replication solutions [2]. Jiahu Qin and his team developed a KMA and a distributed fuzzy CMA for a wireless sensor network (WSN) equipped with sensors at each node. The basic topology of WSN should be firmly connected. The consensus algorithm in multi-agent consensus theory is used to exchange the measurement information of sensors in WSN. To obtain faster convergence speed and higher possibility of global optimality, a DKM++A was first proposed to execute DKMA, distributed FCM find the initial centroid before the algorithm. The proposed DKMA can divide the data observed by the nodes into groups with small metric-dependent distances and out-of-group distances, the proposed distributed DCMA can partition the data observed by nodes correlative groups of different metrics with membership values ranging from 0 to 1. They found that their proposed distributed algorithm can achieve almost the same results as the centralized CA [3]. Zhou X Q and his team believe that with the rapid development and in-depth application of the Internet, the storage problem of massive image data is becoming increasingly prominent. Therefore, the traditional storage framework has low management efficiency, low storage capacity, and high costs. The emergence of Hadoop provides new ideas. However, Hadoop itself is not suitable for processing small files. They proposed a massive image file storage framework based on Hadoop. Through the classification algorithm of the preprocessing module, efficient import and first-level indexing mechanism, they solved the internal storage bottleneck of NameNode when there are too many small files. Tests show that the system is safe, easy to maintain, has good expansion quality. They found that it can achieve good results [4].
This paper designs and implements a CAS based on HP by researching related technologies such as Hadoop distributed cloud computing platform, clustering algorithm. Then it analyzes the problems existing in the KMA, designs an improvement scheme based on the HDP.
Cloud computing and improved K-means algorithm
Cloud computing
Cloud computing is a distributed computing technology. The general concept is to automatically divide large computing programs into multiple subprograms through the network, and then the system consists of multiple servers to query, calculate and analyze and then return the processed values to the user through the network [5]. It is also a network-based resource delivery and usage model. This model can provide resources such as networks, servers, storage, application software, and services. Users can obtain on-demand and convenient services from service providers with a small amount of time and interaction available resource services [6, 7]. The general principle of cloud computing is that users no longer run the required application software on terminal devices such as personal computers and mobile phones, but instead run them in large-scale network-based server clusters. The data generated by the software operation also does not require local storage, and is stored in a network-based data center. The provider of cloud computing is responsible for the management and maintenance of server clusters and data centers, which can guarantee the super-computing power and expandable storage space that users need. Users connected to the network can use the terminal equipment to obtain the required resources in real-time. Whether it is an individual or an enterprise, cloud services can be implemented on demand.
Hadoop platform
(1) HDFS distributed file system
The amount of information in massive data has also shown a blowout growth, limited by space constraints, which makes single-machine data storage particularly difficult [8, 9]. The emergence of distributed file systems is a product that arises as the data volume increases. The distributed file management system can manage and maintain the files distributed on different node machines, and manage and schedule the data storage of the distributed cluster in a highly available and scalable manner [10].
1) Features and architecture of HDFS
HDFS has the following characteristics:
Ability to efficiently handle errors that occur in the cluster. HDFS’s error handling mechanism is the basic guarantee of distributed computing. It enables a single data storage node to fail without affecting the entire data integrity. At the same time, the master’s scheduling can be used to perform normal data calculations [11, 12].
Distributed cluster permeability. During the process of setting up a Hadoop cluster, you need to conFig. SSH remote connections between hosts to avoid login verification. This allows any node in a distributed cluster environment to access files as quickly and easily as if it were a local disk.
Efficient cluster sharing capabilities. Sharing is reflected in the entire distributed file system, and data between nodes can be shared and synchronized.
Besides, HDFS data read operations have very efficient characteristics. Since HDFS does not support concurrent writes, it is more suitable for application scenarios with fewer writes and more reads [13, 14].
HDFS adopts a standard master-slave architecture. NameNode is the master node of the architecture, and it is also the only master node. DataNode is the slave node of the architecture. The system supports multiple slave nodes [15, 16].
The constitutive relationship between various modules in the HDFS architecture. As the file management center of the entire distributed system, NameNode is responsible for the maintenance of all file directories in the entire system, and responds accordingly when users send specific requests. The storage of file data in the distributed file system is handled by the DataNode. In the process of reading and writing large files, the DataNode first divides it into blocks, that is, it is divided into small file blocks (Blocks) and distributed across different DataNodes [17, 18] on the node. Besides, redundant operations are performed while slicing, and multiple file copies are generated and stored on other nodes. This way, not only can large files be efficiently backed up by slicing operations, but also the file corruption problem can be handled efficiently and quickly by file copy replacement. The damaged file block can be repaired by regenerating a new copy of the file. After the repair, it can be repaired by the NameNode and continue to be called as a copy of the file.
2) HDFS read and write process
Distributed system development and operation and maintenance personnel usually use the Java API provided by Hadoop to operate Hadoop [19]. Similarly, JavaAPI, as an interactive interface for distributed clusters, can implement data read and write operations on HDFS. To meet the special requirements of different downstream systems and enhance the scalability and portability between downstream, Hadoop also encapsulates the FileSystem abstract class developed based on Java for developers to call and rewrite operations, which is almost customized Implementation of file operations in distributed systems [20, 21]. When the K-Means clustering algorithm studied in this paper is used in a Hadoop distributed cluster, how the sample data is retrieved can be analyzed in depth by analyzing the HDFS file reading process.
The client sends a signal to read the file. The server first needs to authenticate the currently accessed client. Only after the authentication is passed can the data access continue. The data requested by the user is stored on the NameNode in the form of data blocks. The NameNode sorts the labels and the corresponding list of DataNode nodes. The work of the NameNode is to respond to the client’s data request and send the data block information to the client. The client can directly communicate with the corresponding DataNode for data transmission. After the required files are transmitted, the long link is actively closed, and the data request process of the client is completed once.
(2) MapReduce, a distributed computing framework
Hadoop can be used for offline parallel computing, and MapReduce is one of the programming model components. The input content of big data can be mapped after being read by the Map. The output result is stored in the form of a key-value. The Map also has a processing step of Shuffie sorting. The sorted key-value set is reduced by the Reduce model to obtain the final calculation results [22, 23].
After the original data of MapReduce is input, to be used as input parameters of the Map task, it will be divided into several splits of the same size. After that, the Map step can be executed. The data records in the input split are first read by MapRunnable and pushed to Mapper. The final result is output by Map.
All tasks in MapReduce are stored in the form of a circular queue. The threshold of the circular buffer is set to 80% of the buffer capacity by default. This configuration item can be controlled by modifying the threshold. When the buffer threshold is set, the disk will start a thread to start the Map task, and the overflow operation will be written to the overflow file and stored.
The Shuffle process is that the Reducer first divides the data into multiple partitions, and then writes it to disk. The rowkey will be used as the standard for sorting in the background thread of each partition. To make Map output more efficient, usually use the Comminer class to temporarily store key-value pairs in memory. The output file of the Map process is transmitted to the Reducer via HTTP for replication, and the Reduce task is replicated in a multi-threaded manner, and the final result is stored in HDFS for storage.
Cluster analysis
Cluster analysis is a classification process. The classification criterion is based on different characteristics of the data. A unified collection of data objects with similar characteristics is called a class cluster [24]. The similarity between data objects is expressed using a distance function.
The method of cluster analysis is done through unsupervised autonomous learning. It can analyze the similarity between data, classify the original data set, and perform clustering calculation on any data set without known classification rules [25, 26]. The common clustering methods are as follows:
(1) Clustering by partitioning. The purpose is to divide the original data object into several different sub-regions, each sub-interval represents a different class cluster, and the specific number is usually represented by k. The partitioning method requires the number k of the final clusters and the criteria used to determine the similarity of the data. This method has a good clustering effect for spherical data sets, but for large-scale or irregular-shaped data sets, the method needs to be improved and optimized. Many algorithms in practical applications are proposed based on the idea of this method, such as the K-Means algorithm studied in this paper. The common feature of these algorithms is that they can be applied well in a small number of data sets, but due to the limitations of the space and time complexity of the algorithm itself, it cannot adapt to the ultra-large-scale data sets generated by the modern Internet, ground makes sense.
(2) Clustering method by grid. According to the idea of this method, the data space will be cut into several grids. Due to the spatial subdivision, the magnitude of the original data set does not affect on the calculation time of the method, which is also the advantage of the algorithm. However, how to determine the size of the grid and how to balance the accuracy and computational efficiency are difficult. The practical applications of this method include the STRING algorithm and the CLIQUE algorithm which mixes multiple method ideas.
(3) The method of clustering by model. The model-based method is to use mathematical modeling, assuming that the original data set obeys a certain probability distribution, and perform clustering calculations on the data set in combination with the model. Statistics and neural networks are all practical applications of the model method.
Traditional K-Means algorithm
(1) Algorithm formula
To conveniently describe the improved K-Means algorithm, the symbol X = {x j ∈ R n , i = 1, 2, . . , n} is used to represent the original data set, M1, M2, . . . , M k represents K class cluster centers, and L1, L2, . . . , L k represents K different classes.
In the formula, the center point defining is:
(2) Problems with the algorithm
1) Due to the limitation of the stand-alone hardware, it cannot adapt to the increasing amount of data aggregation.
2) The accuracy of the existing KM cluster center switching operations. To ensure the global sequential use of the cluster switching center, the time complexity of this loses operation algorithm increases and the impact of execution efficiency.
(1) Algorithm improvement plan
K-Means algorithm improvement scheme To effectively improve the performance of the K-Means algorithm, this paper mainly studies the algorithm improvement scheme from three directions: initialization random sampling(RS) process, sample Euclidean distance calculation parallelization. Use the Hadoop-based cluster analysis system designed in this paper to provide parallel technical support.
1) Parallel random sampling
The research and analysis, there are currently two random sampling methods commonly used for text data sets: traversal sampling and byte offset sampling. The traversal method is also called progressive sampling. Its feature is that the original data format is not changed during the sampling process, but the time complexity is high. Although the byte offset method can handle large-scale sampling, it is limited by the efficiency of the algorithm and the sampling effect is also poor.
A PRS process based on Top K processing is designed in this paper. The PRS program is implemented based on the HDS. The algorithm implementation program is as follows: The algorithm input parameters include the range of random number values. Data capacity N, reducer number R
n
. At this time, each Reducer will output the sorted first N/R
n
data. Finally, the samples are preprocessed to obtain the center point of the initial cluster. The preprocessing formula is defined as follows:
(2) Algorithm improvement
The algorithm is performed from three directions: PRS, Mapper parallelization, Reducer parallelization optimization. Among them, the parallelization improvement of the sample distance calculation is realized in the Mapper stage.
1) The original data set adopts parallel random sampling processing based on TopK. After the sample is preprocessed by formula (5), the initialized cluster center point is obtained.
2) Using the data sequence number as the key, use the distance calculation formula (6) to calculate the Euclidean distance of each data point.
Data collection
Because the experiment needs to test the accuracy and the acceleration ratio in the cluster environment, two data are prepared, one is the Iris open-source data set commonly used for cluster analysis, and the other is the generated large-scale data set.
Experimental environment
Hardware configuration: The CPU selects AMD Athlon (TM) X4 with a main frequency of 3.10 GHz, a memory size of 4GB, and a disk space of 500 G.
This system uses Eclipse as a development tool and development language Java, and the system runs in a Linux environment. Among many free-to-use lDE (Integrated Development Environment), Eclipse is one of the most excellent cross-platform portability, and it is also the IDE of choice for many enterprise-level development. Not only does it support the development of the Java language, but it can also extend support for many other mainstream programming languages. Therefore this system uses it as a development environment. The Java language is a very popular programming language. It has the characteristics of object-oriented thinking, cross-platform portability, and support for generic programming. The portability of Java cross-platform mainly depends on its Java virtual machine, which compiles the source code into bytecode, and the compiled bytecode can be executed multiple times on any platform. Hadoop framework supports programming in multiple languages, but its adaptability to Java is optimal, so this system uses Java as the development language.
Overall architecture
The system architecture is divided into three layers, namely the bottom driver layer, the middle logic layer and the service layer.
The underlying driver layer is built with the Hadoop framework as the core and provides the underlying environment support for logic layer applications.
The middle logic layer theme includes four modules, which are the data management module, algorithm management module, resource monitoring module, and eye analysis module. The data management module implements functions such as adding, deleting, modifying, and checking data sets. The algorithm management module encapsulates the clustering algorithms such as KMA and KMPA mentioned in this paper, supports query and call of algorithms, and can dynamically expand the algorithm library. The resource monitoring module can support viewing the status information of clusters, nodes, and tasks. The log analysis module supports operations such as querying and downloading operations, tasks, and error logs.
The service layer exposes external interfaces. These interfaces are transparent to the internal implementation. Users can access the system for cluster analysis operations through the interface of the service layer, and they can also perform secondary development. Due to the existence of the service layer, users do not need to care about the implementation process of specific cluster analysis to complete the cluster calculation operation.
Analysis of test results
(1) Comparative Analysis of Convergence Speed and Accuracy
1) Comparative analysis of convergence speed
However, during the test, it was found that the traditional KMA was lower in terms of algorithm running time. This is because the improvement direction of Hadoop-based parallel clustering algorithm is suitable for clustering analysis on large-scale data sets. Instead, the intermediate steps of slicing, internal sorting, merging, and allocation in the Map and Reduce function operation process lead to longer algorithm preparation time, which affects the operating efficiency. The test results are shown in Fig. 1.
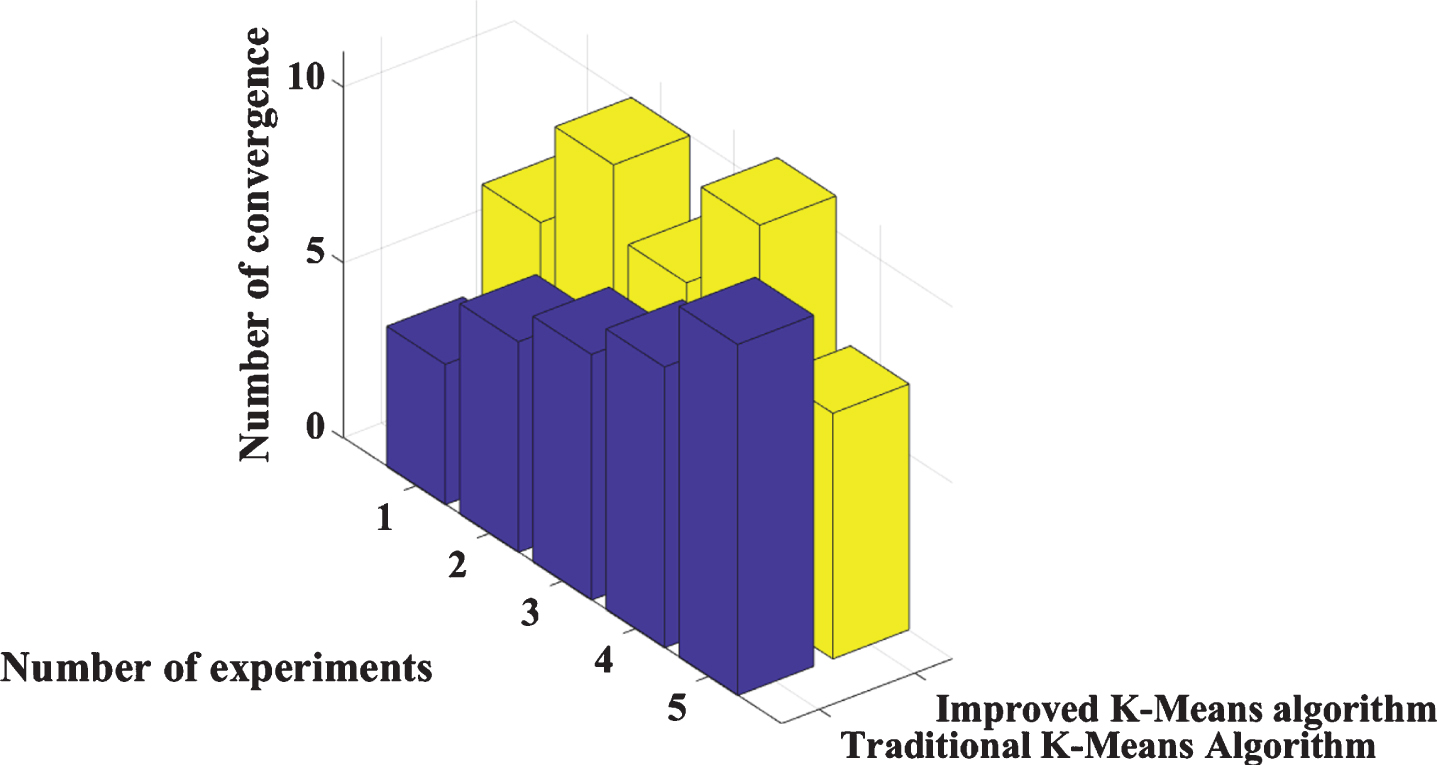
Test results.
It can be seen from Fig. 1 that the improved K-Means parallel algorithm in the single-machine pseudo-distribution mode has fewer average iterations, So he has a very good irretrievable.
2) Comparative analysis of accuracy
Mahout KMA and the improved KMPA on the clustering of standard Iris datasets. The mahout KMA is the K that has been implemented on the HP, K-Means parallel algorithm. The clustering effect of the three algorithms is shown in Fig. 2.

Clustering effect of three algorithms.
From Fig. 2, it can be concluded that the total number of Iris datasets is 150. The conventional KMA is correct 128, the correct rate is 85.3%; The revised KMPA calculates 136 correctly, and the correct rate is 90.7%, so the results prove that the revised KMPA has better accuracy. After analysis, the main reason for this result is that the improved algorithm effectively eliminates the interference of dirty data after data preprocessing, reduces the randomness of the initial center point, and improves the accuracy of the algorithm’s overall clustering.
(2) Sampling rate comparison and cluster environment acceleration ratio analysis
1) Sampling rate comparison
The sampling methods involved in the comparison are line-by-line traversal, byte offset, and PRS improved based on TopK. The time-consuming comparison of each method is shown in Fig. 3.
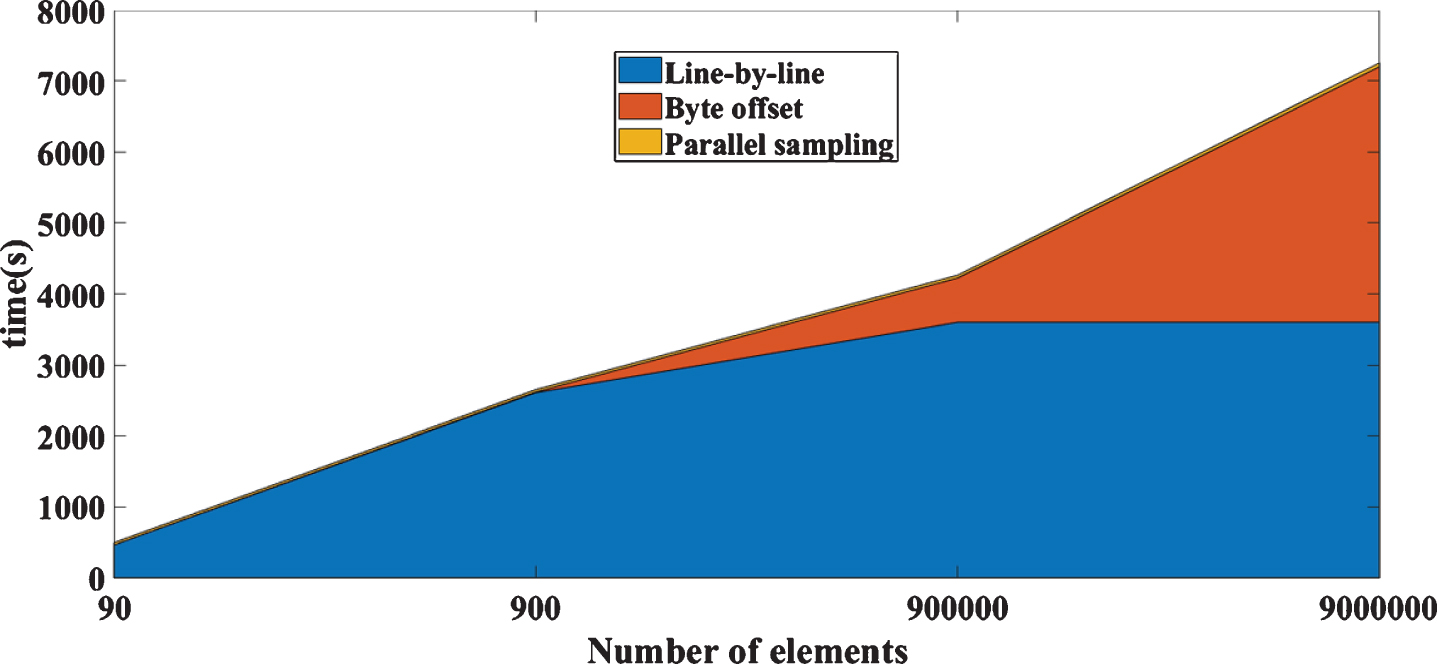
Comparison of sampling time for each method.
It can be seen from Fig. 3 that the line-by-line traversal method has the worst efficiency. The byte offset sampling method has the best efficiency when the amount of data is small, but it is limited by the time complexity. Its runtime consumption increases linearly with the increase of the amount of data, so it is not suitable for the initial sampling of large-scale data sets. The parallel random sampling method takes a lot of time when the amount of data is small, because the intermediate steps of MapReduce distributed computing affect the efficiency. Therefore, the parallel random sampling based on TopK designed in this paper can effectively improve the sampling rate of the K-Means algorithm.
2) Analysis of cluster environment acceleration ratio
Because the improved algorithm designed in this paper is parallel, and the speedup ratio is one of the most intuitive indicators of whether the performance of the parallel algorithm is good or not, the speedup ratio experiment of the improved KMA is performed at the end of this chapter. The formula for the acceleration ratio is as follows:
In the formula, T s represents the running time of the algorithm in a single processor environment, T p represents the time required for the algorithm to run in a multiprocessor environment, and S p represents the speedup ratio. The speedup of the algorithm is large, indicating that it can effectively improve the operating efficiency in a distributed cluster environment. In this experiment, a total of five artificial data sets of FileA, FileB, FileC, Filed, and FileE is used as the original input data, and 1, 2, 3, 4, and 5 computing nodes are used to calculate the speedup of the parallel algorithm. The results of the accelerated tests and their processes are shown in Table 1 and Fig 4.
Speedup experiment consequence
It can be seen from Fig. 4 that the acceleration ratio of all data sets increases, and the increase of the acceleration ratio increases. Under the environment, it can adapt to the cluster computing of large-scale data sets.
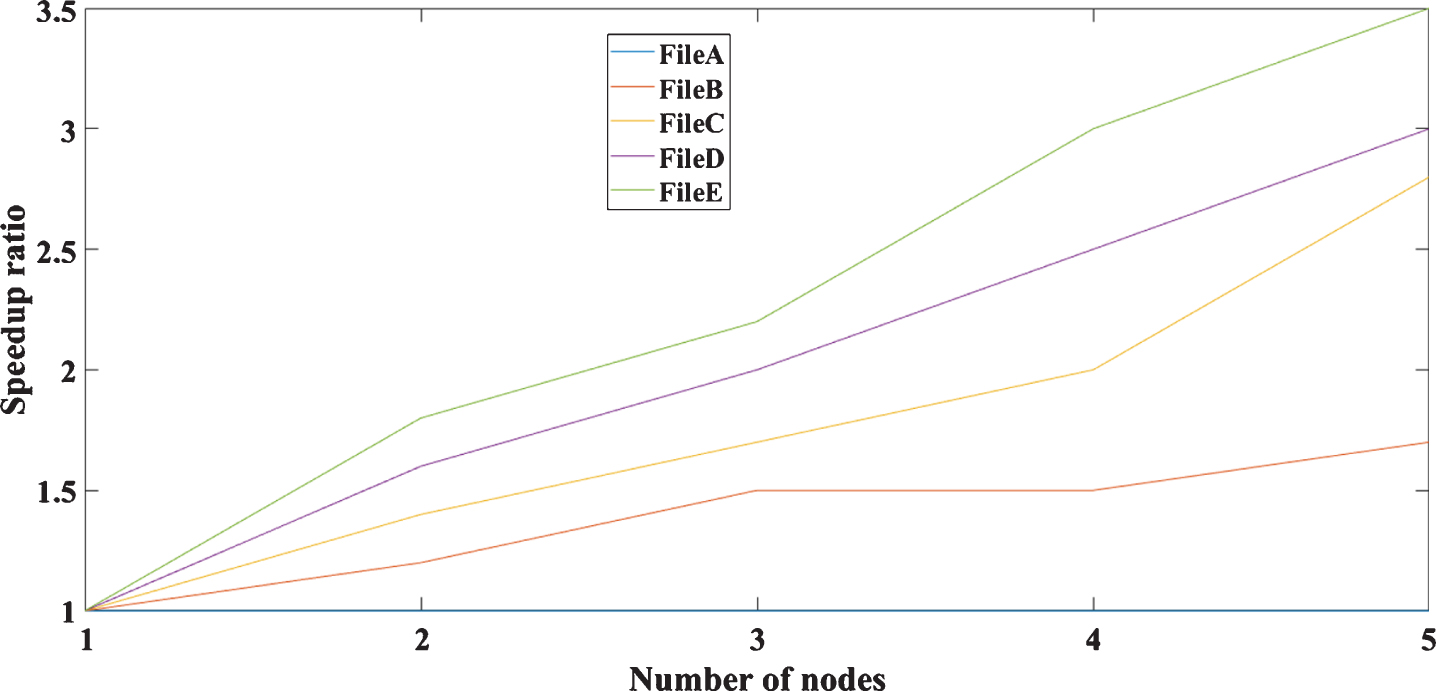
Speedup experiment results.
(1) The CAS based on the HDCCP designed in this paper can provide efficient and stable cluster analysis services. The improved KMPCA can quickly handle large-scale cluster analysis calculations. Achieved the expected design goals of this subject.
(2) In the cloud computing environment provided by the cluster analysis system designed, the improved PRS has a significant increase in speed compared to the traditional initialization sampling method. Through the improvement of parallel random sampling and preprocessing methods, the accuracy of the algorithm is improved. At the same time, KMPA has better convergence.
(3) Based on in-depth research and analysis of the development status of distributed cloud computing platforms and clustering algorithms at home and abroad, this paper designs and implements a CAS based on the HP, and uses this system to perform the K-Means algorithm Parallelization improvements. In the actual test process, users can quickly conFig. the experimental environment through the system, while the system can provide a stable parallel computing environment.
Footnotes
Acknowledgments
This work was supported by Engineering Research Center of Business Intellgent in Big Data for Fujian Province (Document No. 90 of Education and Scientific Research of the Education Department of Fujian Province in 2018).
This work was supported by Collaborative innovation center of big data in business field (Document No. 23 of Scientific Research of the Education Department of Fujian Province in 2019).