
Abstract
Traditional research on preschool language development often fails to capture the complex nonlinear relationships and high-dimensional characteristics of language growth, leading to low prediction accuracy and poor cross-cultural applicability. This paper introduces a novel BERT (Bidirectional Encoder Representations from Transformers)-based model to predict preschool language development and evaluate its cross-cultural effectiveness. Text data from preschool children’s language datasets across multiple cultural backgrounds is collected, cleaned, and preprocessed to create suitable training samples. Special attention is given to the unique grammatical structures and cultural expressions in each language to ensure compatibility with the model. The BERT model is used to encode the processed text, leveraging its bidirectional self-attention mechanism to extract contextual information and generate deep feature representations essential for understanding preschool language development. The model combines both grammatical and semantic features for meaningful representations in subsequent predictions. Fine-tuning the pre-trained BERT model using the Adam optimizer enhances prediction accuracy, while cross-validation and hyperparameter tuning further improve its performance. Culturally specific annotations and vocabularies are incorporated to ensure the model’s effective prediction of language development across different regions. Experimental results show that the BERT model achieves an MAE (Mean Absolute Error) between 0.20 and 0.25, an MSE (Mean Squared Error) between 0.05 and 0.08, and an average R2 value of 0.84 across English, Chinese, Spanish, and Japanese. These results demonstrate the model’s high accuracy and strong cross-cultural stability in predicting preschool language development.
Keywords
Introduction
Preschool language development is the basis of children’s cognitive and social adaptability, and it can directly affect their future learning and living abilities.1,2 Preschool children’s language development in different cultural backgrounds has its own characteristics. How to accurately assess these differences is an important topic in the current education field.3,4 Language development is influenced by culture, social environment, and education methods. Effective cross-cultural assessment is very important for understanding and promoting the development of children’s language ability all over the world. In order to achieve this, it is necessary to combine advanced deep learning technology in building a cross-culturally applicable language development prediction model.
In the current research on preschool language development prediction, feature extraction relies on manual work, and the models rely on rule-based methods, which have many defects in fitting the complexity and nonlinear characteristics of preschool children’s language development. The traditional methods depend on a few language features, too simple to reflect the development of children’s language ability.5,6 A single traditional method cannot capture the diversity and changes in children’s complex and multi-dimensional language ability; the accuracy of prediction is low accordingly.7,8 Most of the existing methods adopt some statistical analysis model, such as regression analysis or simple classification model. The expressive power of such models is very weak, which can’t effectively mine deep semantic and contextual information from a large amount of language data.9,10 Existing methods ignore the contextual relationship of language when processing language data, and it is difficult to obtain subtle differences and potential patterns.11,12 Studies on preschool children’s language development tend to ignore the impact of cultural background on language learning.13,14 Each language has unique expressions, grammatical structures, and vocabulary usage, which are deeply rooted in its cultural background.15,16 Previous language development predictions focused on the construction of a single language or cultural background, lacking cross-cultural flexibility and adaptability,17,18 and could not provide accurate predictions when faced with diverse language and cultural groups. Traditional methods are difficult to identify and adapt to the characteristics of various cultures and languages in the context of multiple languages and cultures, which greatly limits the wide application of models and prediction accuracy.19,20 There are still some problems with traditional preschool language development prediction methods, which seriously hinder the effectiveness and practicality of these methods in the field of preschool language research.
This paper proposes a BERT-based model for predicting preschool children’s language development, aiming to assess its effectiveness across different cultural backgrounds. Existing methods for studying language development often fall short in addressing the multifaceted characteristics and complexities of preschool language growth. By leveraging BERT’s bidirectional self-attention mechanism, this study delves deeper into the intrinsic features of preschool children’s language data, effectively processing language information from diverse cultural contexts. This approach enables accurate extraction of grammatical structures, semantic characteristics, and expression patterns unique to different languages and cultures, overcoming the limitations of traditional methods and better handling the complexity of multilingual and cross-cultural language data.
The model undergoes fine-tuning with hyperparameter optimization, coupled with cross-validation, to ensure its stability and robustness across various cultural backgrounds. The ultimate aim of this research is to create a universal tool for language development prediction that is adaptable to different languages and cultural contexts. By providing more scientific and precise insights into language development, this model supports global preschool education, assisting educators in better understanding and fostering children’s language growth. Through this work, the study contributes to a more effective, cross-culturally relevant approach to language development research and offers valuable support for early childhood education worldwide.
Related work
Currently, there are more and more studies on the prediction of preschool language development. Many studies have explored the impact of different language features on language development by analyzing various data in the process of children’s language acquisition. Some studies have proposed methods based on neural networks21,22 to process different levels of children’s language expression and more accurately obtain the laws of language development. In order to overcome the problem of insufficient prediction effect of traditional methods, some scholars have adopted methods based on deep learning23,24 to automatically extract language features to improve the accuracy of prediction and have achieved certain results.25,26 Oh B D used deep learning and statistics to analyze Korean transcription data and combined it with a multi-core deep learning model to successfully determine the speaker’s age group and language development level with a high average accuracy rate. 27 These studies actually focused on a single language environment and achieved success within a certain range but ignored the differences between different languages and cultural backgrounds. The applicability of the model was limited in a cross-cultural environment. The culturally specific elements in a language, the differences in syntactic structure, vocabulary choice, and expression, to a large extent, make it impossible for traditional deep learning methods to effectively handle diverse language features; traditional research results cannot fully solve the problem of predicting language development in a cross-cultural context.
In order to solve the problem of insufficient prediction accuracy in traditional research, some new deep learning methods have been widely used in language development prediction. The introduction of the BERT28,29 model makes the processing of text data more accurate. The BERT model is based on a bidirectional self-attention mechanism and can obtain deep semantic information in the context, capturing the complexity and diversity of language. Compared with traditional methods, BERT can automatically extract and learn grammatical and semantic features, avoiding the limitations of manual feature selection and performing well in many language processing tasks. Some studies have shown that BERT and its derivative models not only achieve excellent performance in single language tasks but also have certain potential in multilingual and cross-cultural tasks.30,31 Acs J used multilingual datasets to detect morphological information in language models and found that the pre-trained BERT model performed strongly in these tasks. Using masked context and Shapley value methods, the previous text contains more prediction-related information than the following text. 32 These studies provide theoretical support for the cross-cultural language development prediction model proposed in this paper. However, these methods usually lack systematic evaluation of cross-cultural effectiveness and do not consider the diversity of language features in different cultural backgrounds. Therefore, the BERT-based preschool language development prediction model proposed in this paper aims to solve these problems and achieve cross-cultural effectiveness evaluation through targeted adjustments and optimizations.
Methods
Data collection and processing
Text data can be collected from preschool children’s language datasets of multiple cultural backgrounds, and text cleaning and denoising can be performed to generate training samples that can be used for deep learning. The special grammatical structures and cultural expressions of different languages are properly processed to adapt them to model input.
Data collection
Text data were collected from a variety of preschool children’s language datasets across multiple cultural contexts, encompassing sources such as oral records, children’s books, parent–child conversations, and audio transcriptions. To ensure cross-cultural adaptability, the datasets include language samples from different languages and cultural backgrounds, reflecting the unique linguistic characteristics of each culture. In addition to maintaining high data quality, the data collection process prioritizes diversity and representativeness, ensuring that the samples span a wide range of language development levels across children of various ages. This approach provides a comprehensive and culturally inclusive foundation for the model, enhancing its ability to predict language development across diverse populations.
Each text data is annotated in detail, including children’s vocabulary usage, syntactic structure, and specific cultural expressions. The annotation standards of the text refer to the commonly used grammatical annotation methods in multilingual research. Considering the language differences between different cultures, a consistent annotation standard is adopted to facilitate unified processing of the model.
Basic statistical information of datasets under different cultural backgrounds.

Data processing
The text data was cleaned and denoised during the data processing stage. Irrelevant punctuation, extra spaces, special characters, and non-semantic content can be removed. In order to further ensure the quality of the data, regular expression cleaning and text standardization technology are applied. Assuming that the original text is 
To handle special grammatical structures in multilingual texts, language-specific processing methods are used. There are obvious differences in syntax between English and Chinese. English texts specifically handle tenses, plural forms of nouns, etc. Chinese uses standardized processing of quantifiers and word order, and establishes a symbolic mapping function 
After the processed text data is standardized using this function, it can better adapt to the input requirements of the model. The text denoising algorithm is applied in data processing, based on TF-IDF (Term Frequency-Inverse Document Frequency)33,34 keyword extraction and denoising, to remove common stop words and reduce data dimensions while retaining core information. The goal of denoising is to minimize the ratio between signal and noise, making the data used more effective.
Adaptive processing of cultural differences, taking into account culturally specific language expressions and syntactic structures, uses syntax tree adjustment methods to unify the data formats of different cultural languages. Assuming 
This adjustment enables the model to handle grammatical differences and expression habits in different cultural backgrounds in the input data, improving the model’s adaptability and cross-cultural prediction capabilities.
Data enhancement techniques can be used to enrich data, and operations such as synonym replacement and sentence structure rearrangement can be used to expand the training set and prevent overfitting. The enhancement operation was 
The enhanced dataset expands the sample size and provides better coverage of diverse language development contexts, ensuring greater diversity in the training process and improving the model’s robustness. By incorporating techniques such as text cleaning, denoising, grammar structure adjustments, and data augmentation, the training samples are not only of high quality but also exhibit strong cross-cultural adaptability. These preprocessing steps lay a solid foundation for subsequent deep learning model training, enabling the model to more effectively capture the complex features of children’s language development.
Changes in feature dimensions before and after preprocessing of different language datasets.

Feature extraction and modeling
Feature extraction
In the feature extraction stage, the cleaned text data is encoded using the BERT model, and the bidirectional self-attention mechanism of BERT is used to obtain the contextual information in the text. The text data is divided into several tokens and further refined using the WordPiece word segmentation technology. For each input text, 
The BERT model processes the above embedding representation through the Transformer encoder and uses the self-attention mechanism to obtain the dependency between different tokens in the input sequence. In each attention layer, the BERT model calculates the attention weight through the query, key, and value:
Feature modeling
In the feature modeling stage, the token representations generated by BERT are further processed to extract deep features related to the language development of preschool children. The grammatical and semantic features of the text are effectively integrated into the prediction model, and the feature aggregation technology is used to integrate the token representation of each sentence. For the token representation of each sentence, a pooling operation is used to generate a sentence-level representation, either maximum pooling or average pooling:
This pooling operation compresses all token representations in a sentence into a vector of fixed dimension, so that the vector can contain the grammatical and semantic features of the entire sentence.
Combining cultural background and language characteristics, the grammatical features of the text are refined and modeled. For key information such as verb phrases and noun phrases in the sentence, a weighted summation method based on the attention mechanism is used to weightedly fuse the sentence features. The following formula is used to weighted sum the structural units to obtain the final sentence feature representation 
Features are input into the fully connected layer for further processing to obtain the deep feature representation required for the prediction of language development in preschool children:
The deep features extracted by the BERT model through the bidirectional self-attention mechanism effectively obtain the contextual information in the text and also combine the language features of different cultural backgrounds, so that the model can better understand the complex patterns of language development in preschool children. These feature representations provide strong support for subsequent prediction models, improving the accuracy and cross-cultural adaptability of language development predictions.
Figure 1 shows the structure of the BERT model. The input text is converted into multiple tokens through the word segmentation process, and each token represents a vocabulary unit. The input token is processed by the embedding layer and position encoding together with the special [CLS] tag and then sent to multiple Transformer encoder layers for processing. Each Transformer layer obtains the relationship between each word in the text through the self-attention mechanism. The output of each layer represents the context information of each token in the text. Using the pooling operation, the model extracts sentence-level feature representations to provide deep semantic features for subsequent tasks. Figure 1 shows the overall structure from the input layer to the final output, highlighting how BERT gradually learns the complex features of text through the nested Transformer mechanism when processing text. Structure of the BERT model.
Model training and optimization
The pre-trained BERT model is fine-tuned on the preschool language dataset, with model parameters adjusted using optimization algorithms such as the Adam optimizer to enhance the accuracy of language development predictions. The model’s stability and predictive performance are further improved through cross-validation and hyperparameter tuning, ensuring more reliable and precise results.
Model training
In the model training phase, the pre-trained BERT model is loaded onto the preschool language dataset for fine-tuning to adapt the pre-trained model to the characteristics of preschool children’s language data; all layers of the BERT model are initialized, trained on the dataset, the loss function is minimized, the model parameters are optimized, and the prediction accuracy is improved.
The study adopted a loss function for the prediction error calculation in the regression task. Given the predicted value and the true value, the mean square error is calculated as follows:
The study also used the Adam optimizer to adjust the model’s parameters to better optimize the model. The Adam optimizer combines the advantages of the momentum method and the RMSProp optimizer, adaptively adjusting the learning rate of each parameter. The update rule of the Adam optimizer is as follows:
The training also uses an early stopping strategy to avoid overfitting. The loss value of the validation set is monitored. If the validation set loss does not decrease within several consecutive epochs, the training is stopped. This strategy effectively prevents the model from overfitting the training data and improves its adaptability.
Hyperparameter tuning and cross-validation
Tuning the model’s hyperparameters further improves the model’s stability and predictive ability; the main hyperparameters to be tuned include learning rate, batch size, and number of training rounds. Grid search or random search is used to train under different hyperparameter combinations to select the parameter combination with the best performance.
The learning rate can be adjusted. The learning rate is a key factor affecting the convergence speed and stability of model training. If the learning rate is too large, the model can skip the optimal solution and the convergence can be unstable. If the learning rate is too small, the model may converge too slowly and fail to achieve the best results within the limited training time. To find a suitable learning rate, a learning rate decay strategy needs to be adopted. Assume that the initial learning rate is 
The batch size can be adjusted, and the batch size determines the number of training samples used for each parameter update. A smaller batch size may cause unstable gradient estimation, while a larger batch size may lead to a waste of computing resources. The experiment selects the optimal batch size to balance training efficiency and stability.
The number of training rounds is selected based on cross-validation. Using k-fold cross-validation, the dataset is divided into k subsets, each subset is used as a validation set, and the rest is used as a training set. The model is trained k times, and the average performance index of each training is calculated. Cross-validation can effectively evaluate the adaptability of the model and prevent performance fluctuations caused by different data partitions. Stability is evaluated by calculating the variance of each validation result. The smaller the variance, the more stable the model is under different data partitions.
After the above steps obtain the optimal hyperparameter combination, the model can undergo final training. Cross-validation helps select appropriate hyperparameters and further verifies the performance of the model on different datasets, allowing the model to adapt to diverse language data and have strong cross-cultural prediction capabilities.
Cross-cultural adaptability adjustment
Culture-specific input adjustment
The characteristics of preschool children’s language data from different cultural backgrounds can be adjusted for input. The text data of each cultural background is language-specific to meet the requirements of the model. For the vocabulary and grammar structure of different languages, the corresponding language-specific processing methods are adopted, and the cultural background related vocabulary and word segmentation rules are adopted, and the input data meets the specific needs of each language.
Certain languages feature unique grammatical structures or special punctuation marks, requiring the use of regular expressions and custom word segmentation tools for text processing. For languages like Chinese and Japanese, which lack clear word boundaries, the word segmentation process must be adjusted according to contextual information. In contrast, for languages with standard space separators, such as English, word segmentation follows conventional methods, with custom algorithms designed to accommodate the specific characteristics of each language, ensuring the model can accurately process input in all languages.
To address vocabulary differences across cultural contexts, culture-specific vocabularies are incorporated into the input data, enabling the model to recognize high-frequency words and idioms unique to each language and culture. For example, there are significant differences between Chinese and English in expressing concepts like time, numbers, and emotions. These differences are addressed through cultural adaptation in data processing. For instance, while “suishu” in Chinese and “age” in English convey the same meaning in context, they differ in word form and expression. Vocabulary mapping is employed to standardize these culturally distinct terms. This approach ensures that the model can effectively extract relevant features while accounting for cultural differences, mitigating the impact of cultural bias on model performance when processing multilingual data.
Adjustment of model input and feature encoding
The adjusted culturally specific input data is passed to the BERT model through the encoding layer. Using vocabularies and word embeddings for different languages and cultural backgrounds, the encoding capabilities of the BERT model are used to obtain semantic differences between cultures. The processing of culture-specific words also involves the expression of complex features such as emotional color and syntactic differences. The weighted word embedding technology is used to adjust the cross-cultural adaptation to fully express the culture-specific information. With large weight on the corresponding embedding vectors, these words have high influence in the learning process of the model. The weighted word embeddings are expressed as follows:
Figure 2 shows how to adjust the input and process the data of the preschool children’s language development prediction model in a cross-cultural context. Data can be collected from multiple cultural backgrounds and processed in a culturally specific manner. Language-specific word segmentation and culturally specific vocabulary mapping can be performed for the characteristics of different languages, so that the unique expressions of each language can be properly processed. The adjusted data is passed into the BERT model as input, encoded using BERT’s bidirectional self-attention mechanism, and contextual information and deep semantic features in the text are extracted. The model outputs predicted results of preschool children’s language development and achieves cross-cultural language prediction. The entire process fully considers different cultural backgrounds and language characteristics, ensuring that the model can make stable and accurate predictions in a multicultural environment. Data processing flow of the cross-cultural preschool children’s language development prediction model.
Method effect evaluation
Self-attention weight analysis
Figure 3 shows the attention weight distribution in the BERT model self-attention mechanism, reflecting the relationship between different word pairs in the text. Each cell represents the strength of attention between two words. The color depth corresponds to the weight. The light-colored area indicates a stronger attention relationship, which means that the two words are more closely related in the model; the dark-colored area indicates a weaker attention relationship, which means that the two words are loosely related. The model allocates stronger attention when processing common words such as “the” and “lazy” and has lower attention weights between some insignificant word pairs. This visualization clearly shows how the BERT model uses contextual information to dynamically adjust the focus of each word and effectively obtain grammatical and semantic information in the text. This mechanism is crucial for language understanding tasks. It enables the model to flexibly transfer information between different words and enhances the ability to process complex language structures. BERT model self-attention weight heat map.
Prediction accuracy and comparison
The prediction accuracy of the evaluation model is selected as the main regression evaluation indicators, and MSE and MAE can effectively measure the deviation between the model prediction results and the true value. MSE focuses more on the penalty of large errors, while MAE can provide an intuitive measurement of the error of each sample.
The study compared BERT with traditional BiLSTM (Bi-directional Long Short-Term Memory) and GRU (Gated Recurrent Unit) to verify BERT’s advantages in processing preschool language development prediction, calculated the MSE and MAE values of each model, and used the average value to evaluate its overall performance.
The 10 marks in Figure 4 range from 1 to 10, and there are three columns above each mark, representing the MAE values of the BERT, BiLSTM, and GRU models. The smaller the MAE value is, the more accurate the model prediction. Comparison of MAE of different models.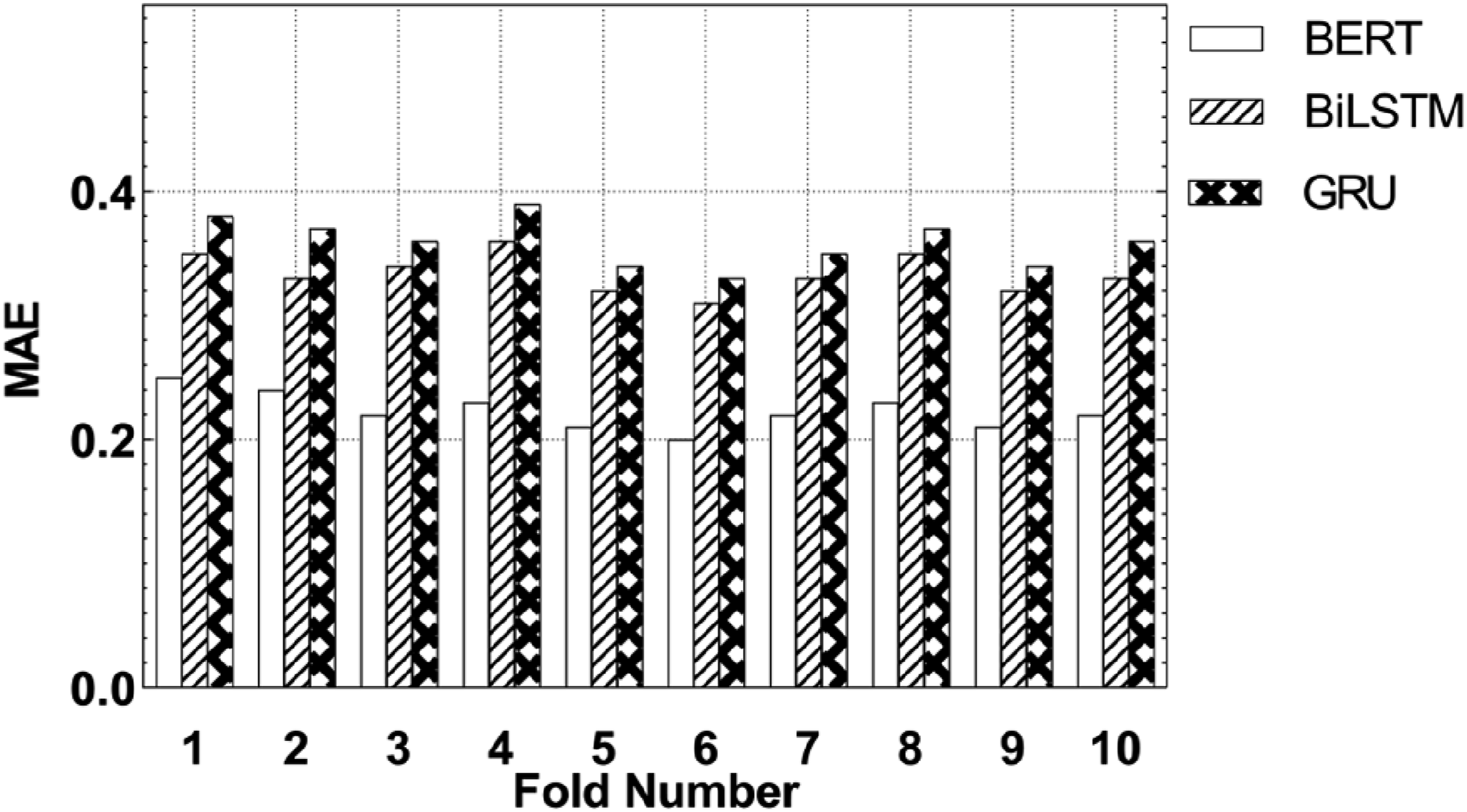
The data shows that the MAE value of the BERT model is between 0.20 and 0.25. Compared with BiLSTM and GRU, BERT always shows a lower error. In the first fold, BERT’s MAE is 0.25, while BiLSTM and GRU are 0.35 and 0.38, respectively. Comparing the MAE values of different folds, it can be seen that BERT is always better than the other two models in terms of prediction accuracy. These data changes show that the BERT model has a stronger ability to obtain language features and contextual information than the BiLSTM and GRU models, and is more accurate in predicting the language development of preschool children.
Figure 5 is similar to the MAE bar chart. Each fold sign corresponds to the MSE value of the BERT, BiLSTM, and GRU models. The MSE value range is between 0 and 0.15. MSE comparison of different models.
The MSE of BERT in the first fold is 0.08, while that of BiLSTM and GRU are 0.12 and 0.14, respectively, showing a relatively small prediction error. The MSE value of BERT is always at a low level in the 10 folds, with the lowest being 0.05, showing the superiority of BERT in preschool language prediction tasks. The MSE values of BiLSTM and GRU are always higher than that of the BERT model, which once again verifies the advantage of BERT in processing language data with greater accuracy and stability. The trend of MSE reflects the stability of BERT in each dataset, and it can still maintain high prediction accuracy in different cultural and language backgrounds. The MSE values of BiLSTM and GRU are larger, showing a certain instability.
Cross-cultural stability
The cross-cultural stability of the model is evaluated using R2 as an evaluation indicator to measure the degree of fit of the model on different cultural data. The R2 value reflects the proportion of variability in the observed data that the model can explain. The closer the value is to 1, the better the model fits the data. The model is trained and tested on the language data of preschool children in different cultural backgrounds to comprehensively evaluate the cross-cultural adaptability of the model and calculate the R2 value of each cultural sample.
The R2 values of different cultural samples can be compared to evaluate the stability of the model in different languages, grammars, and cultural expressions. If the model has a high R2 value on each cultural dataset, it means that the model can stably adapt to the language characteristics of multicultural backgrounds and has strong cross-cultural generalization capabilities. If the R2 value is large or small, it indicates that the model may have cultural bias and cannot effectively handle data features from different cultural backgrounds. This process can verify the stability of the model in a multicultural environment and provide guidance for further optimization and adjustment of the model.
As can be seen from Figure 6, the prediction accuracy of the BERT model is better than that of the BiLSTM and GRU models in all languages, with an average R2 value of 0.84. BERT can better obtain the deep features and contextual information of the language, and has a higher degree of fit on the data of these languages. The R2 values for Chinese and Japanese are 0.83 and 0.80, respectively, which are relatively low, but still demonstrate BERT’s strong cross-cultural adaptability and can effectively process preschool children’s language data from different cultural backgrounds. The performance of the BiLSTM and GRU models is relatively poor, with low fit in Chinese and Japanese. These two models have poor adaptability when processing different cultural languages and cannot fully capture the complex grammatical structures and cultural expressions of these languages. The stability and cross-cultural generalization ability of the BERT model are significantly better than those of the BiLSTM and GRU models, and it has wide applicability and high prediction ability on multicultural datasets. R2 comparison of different models.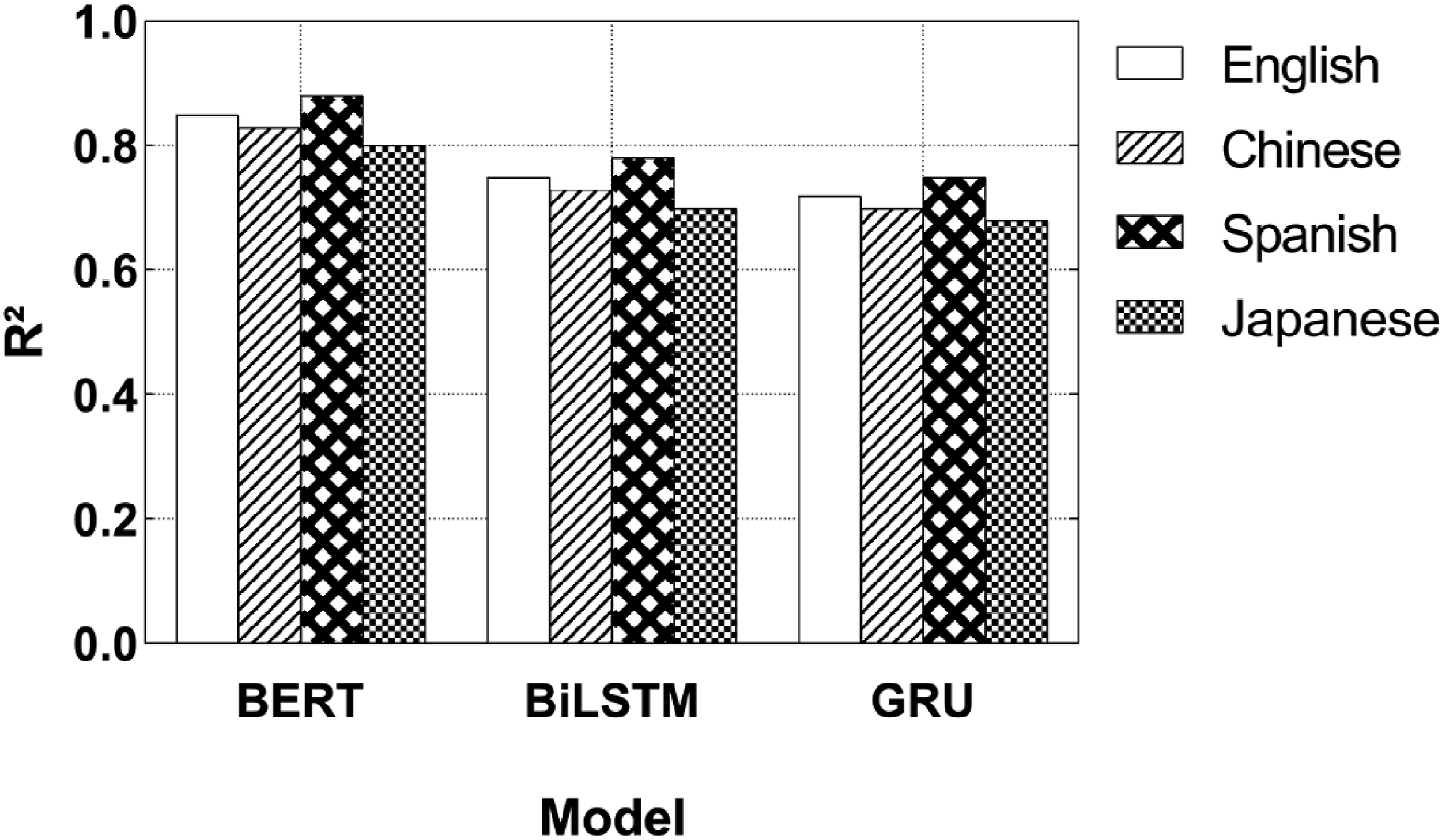
Conclusions
This paper proposes a preschool language development prediction method based on the BERT model and evaluates its cross-cultural effectiveness. By processing language datasets of preschool children in multiple cultural backgrounds, a deep learning model was constructed that can capture the complex nonlinear relationships in language development. In feature extraction and modeling, the BERT model extracted the deep features of the language through a bidirectional self-attention mechanism, and combined it with grammatical and semantic information to provide meaningful input for language development prediction. By fine-tuning the pre-trained BERT model, cross-validation and hyperparameter tuning were used to greatly improve the accuracy of language prediction.
In terms of cross-cultural adaptability, the model’s input has been carefully adjusted to account for the unique language characteristics of different cultural backgrounds. This enables it to effectively handle the special grammatical structures and cultural expressions inherent in various languages, ensuring the model’s robustness across multicultural datasets. The evaluation of the BERT model’s prediction accuracy demonstrated its superiority over traditional BiLSTM and GRU models, highlighting its strengths in predicting preschool language development. Furthermore, the model’s cross-cultural stability, as measured by the R2 value, shows strong adaptability and stability across diverse cultural contexts, indicating its significant potential for cross-cultural application.
The BERT-based preschool language development prediction model not only enhances prediction accuracy but also successfully addresses the complexity of cross-cultural data. This marks a substantial advancement in preschool language education research, offering novel approaches for better understanding and supporting language development in young children from various cultural backgrounds.
Looking ahead, future research could explore integrating additional deep learning techniques, such as reinforcement learning or transfer learning, to further enhance the model’s ability to adapt to evolving linguistic trends and real-time data. Expanding the dataset to include more languages and diverse cultural contexts could improve the model’s generalizability and make it a more universal tool for global preschool language education. Additionally, enhancing the model’s interpretability will be critical for providing educators with clear insights into the factors influencing language development, ultimately supporting more personalized and effective teaching strategies.