
Abstract
Web data classification has become a subject of great value due to the increase of premium data source in the web data and as the pointer to utilizing this source of data. Deep learning is a technique that requires a significant quantity of well-designated data that is difficult and high consumption time to gather explicitly. To bridge this gap, a hybrid approach named Archimedes conditional autoregressive optimization algorithm (ACOA) is established for web data classification. Firstly, the input web page is fed up with the Bidirectional Encoder Representations from Transformers (BERT) tokenization phase. Secondly, Aspect term extraction (ATE) is done by the tokens for the identification of phrases selected by opinion indicators in review sentences. Thirdly, feature extraction is performed by obtained suitable features. Lastly, web data classification is performed by Random Multimodel Deep Learning (RMDL) that is tuned using ACOA. ACOA is an incorporation of Archimedes optimization algorithm (AOA) with the Conditional Autoregressive Value at Risk (CAViaR) model. The presented approach ACOA is evaluated with metrics like, precision, recall and F1-Score, which acquires the maximum values as 91.6%, 94.7% and 93.1%.
Keywords
Introduction
Natural language processing (NLP) is the investigation of how computers can understand and alter natural language text or speech for advantageous reasons. So that the appropriate tools and techniques may be developed to help computers comprehend and manipulate natural languages to do the needed tasks, NLP specialists study to learn more about how people interpret and utilize language. NLP is based on a variety of disciplines, including computer and information studies, linguistics, mathematics, electrical and electronic engineering, artificial intelligence and robots, psychology, and others. Machine translation, user interfaces, multilingual and cross-language information retrieval (CLIR), speech recognition, and expert systems are just a few of the areas of study where NLP is applied. 1 NLP has drawn a lot of interest from experts in artificial intelligence (AI) due to the exponential rise in text data produced over time. 2 An interdisciplinary discipline called NLP researches and creates algorithms and systems that let computers comprehend and carry out tasks involving human language. Computational linguistics, computer speech and language processing, or human language technology are other names for NLP. 3 NLP is involved with analyzing spoken and written human language to derive instructions or practical knowledge. 4 A ranking number between a query and text in the corpus is assigned in information retrieval using a similarity measure. Applications involving questions and answers demand the ability to identify comparable questions and answers. Given the variety of natural language phrases, it is very challenging to evaluate the sentimental terms. 5
Many natural language tasks, including word sense disambiguation, language modeling, synonym extraction, and automatic thesaurus extraction, effectively use semantic similarity measures. 6 The ability to quantify the sentiment similarity or the distance between two concepts in terms of ontology is known as the semantic similarity between concepts. In other words, concepts with comparable “characteristics” are found using semantic similarity. Humans can evaluate whether two concepts are related even though they are not aware of the formal definition of that relationship. 7 Semantic similarity measures have recently gained importance due to the Web's rapid growth in many Web-related tasks. Semantic similarity metrics are crucial in the business spheres as well. According to the sponsored search model, interested companies pay search engines in showing advertisements for their websites with the search option. When a business bids on a keyword, its advertisement is shown when the term is entered into the search engine. “Keyword generation,” which is when a company, which is implicated in executing a campaign advocate keywords that are related to that campaign, is a significant issue in this process. Then, as potential bid suggestions, keywords with a high degree of semantic similarity to the company can be used. 8 Several key tasks, including retrieval of structured data based on partial specification, data and schema integration based on the similarity of definitions in different sources, and similarity-based query answering on the integrated model, are made easier by the ability to compute meaningful measures of similarity between data and data models. 9
It is important to keep in mind when central correspondence actions for semantic network statistics that this data is frequently characterized using ontological acquaintance that establishes inherent in sequence about the data. This implicit knowledge must also be taken into account when defining a meaningful similarity measure for such data. 9 With the rise in popularity of the Internet over the past ten years, the number of web sites has increased exponentially.3,10 Web data can be downloaded straight from the internet or gathered using different APIs and web crawlers that are made available by third parties. 11 The two main difficulties with using web info are as follows: Retrieving pictures and their tags from a compilation of web data is crucial like, truthfully and as many as possible. If not, the network source of data may not precisely represent the illustration theme or may only have a small amount. The two issues are brought on by the complexity of web image content and the potential difference between web image data spread and target dataset. 12 As a result, classifying data from various websites using the web is a crucial job. Many computer vision tasks, including general picture classification, object detection, and scene recognition, have significantly improved thanks to deep learning. A faster and easier method as an option is to use a network to gather a lot of images. Although some noise in online data is unavoidable, the abundance of network data can make up for this shortcoming. 13
The primary goal of this paper is described in this segment. A Novel framework is introduced for web data classification named ACOA_RMDL. The input web data based on text is considered and it is allowed to the BERT tokenization process. After the tokenization process, the ATE is performed and the feature extraction is done by utilizing punctuation marks, negation, question marks, exclamation marks, bag of units, sentence length, numerical words, hashtags, all caps, emoticons, and semantic-based similarity to acquire the suitable vectors. Furthermore, the web data classification is obtained by RMDL, which is trained by ACOA.
✓
The remainder portion of this research is spitted as, probe 2, 3 4 and 5. In 2, the reviews and the difficulties of the existing techniques are explained. The proposed methodology of ACOA and the structure of RMDL and the training algorithm are deliberated in part 3. Segment 4 expresses the resultant of comparative and algorithmic examination of the established technique. Lastly, the conclusion of this research, efficaciousness and future work is described in probe 5.
Literature review
Several online methods for gathering data offer a variety of information and optimized generation. However, some noisy groups may share the same traits. Thus, the previous schemes of web data classification are investigated to encourage and to devise the new approach.
Baharlou and Aghamaleki, 14 developed the Transfer Learning Approach. The noisy dataset was used to train two state-of-the-art networks, which resulted in excellent recognition accuracy. However, when applied to a bigger dataset with more classes, it was unable to accomplish the noise reduction. Gopianand and Jaganathan, 15 devised an optimal neural network (ONN) classifier. This strategy enhanced search efficiency and classification accuracy for different groups. However, a more effective algorithm was not used to produce improved results. Xiaoping Wu, et al. 16 ; designed bidirectional self-paced learning (BiSPL) framework. The experimental evaluation on more tasks and large-scale datasets was not done, despite the fact that this method reduced the impact of sound by learning from network data sources in a concise manner. Jia Li, et al. 17 ; established Ubiquitous Reweighting Network (URNet). By reweighing the impact of various classes, their labels, huge occurrence clusters, undersized occurrence bags, and their assurance, each instance has the potential to make a positive contribution by reducing noise and bias. This allows for a gradual reduction in the impact of sound and bias in web source, which enhances URNet's performance over time.
Yang, et al. 12 ; introduced the progressive filtering method. It was successful in retrieving useful data from online data. However, this model's selection ability was very constrained for the smallest size. Li, et al. 3 ; devised a deep web data source classification method. High performance and a workable approach were achieved using this strategy. However, there was an increase in labor consumption. Liu, et al. 18 ; developed the weighted frequency algorithm P-TF-IDF. Nevertheless, it gave a source base for the apparition of seismic crisis data. The earthquake alert network web papers were only partially cleaned by the data cleaning framework. Patel and Verma, et al. 19 ; created supervised learning classifiers. Higher precision was offered by the Support Vector Machine (SVM) and Support Vector Regression (SVR) classifiers. However, it was discovered that the K-Nearest Neighbor (K-NN) method was very memory and processing intensive.
With the aim of rectifying the drawbacks of the existing data classification techniques, this paper introduces an ACOA_RMDL for web data classification. Here, BERT tokenization is used for pre-processing. BERT saves a lot of time while building the NLP-based model. Also, it is available and pre-trained in more languages than other models. Moreover, RMDL is used for data classification. RMDL can be utilized in any kind of data set for classification. Also, the RMDL model can use any kind of optimizer. Hence, the proposed method offers better results than the previous data classification methods.
Proposed archimedes conditional autoregressive optimization algorithm _ random multimodel deep learning for web data classification
Even though web data is inherently sparse, optimizing the class number for each classification is an especially important issue when it comes to the analysis of web pages. The primary intention of this work is to establish ACOA_RMDL for web data classification. Initially, the input web page which is specified in the dataset 20 and 21 is given to the BERT 22 tokenization, in order to break the sentences into tokens. After that, ATE 23 is performed by the tokens to identify the phrases targeted by opinion indicators in the review sentence. Moreover, feature extraction is done in regards to achieve the suitable features. Finally, the web data classification is sophisticated employing RMDL, 24 which is trained by ACOA. ACOA is obtained by the incorporation of AOA 25 with the CAViaR model. 26 In Figure 1, the schematic view of ACOA_RMDL for web data classification.
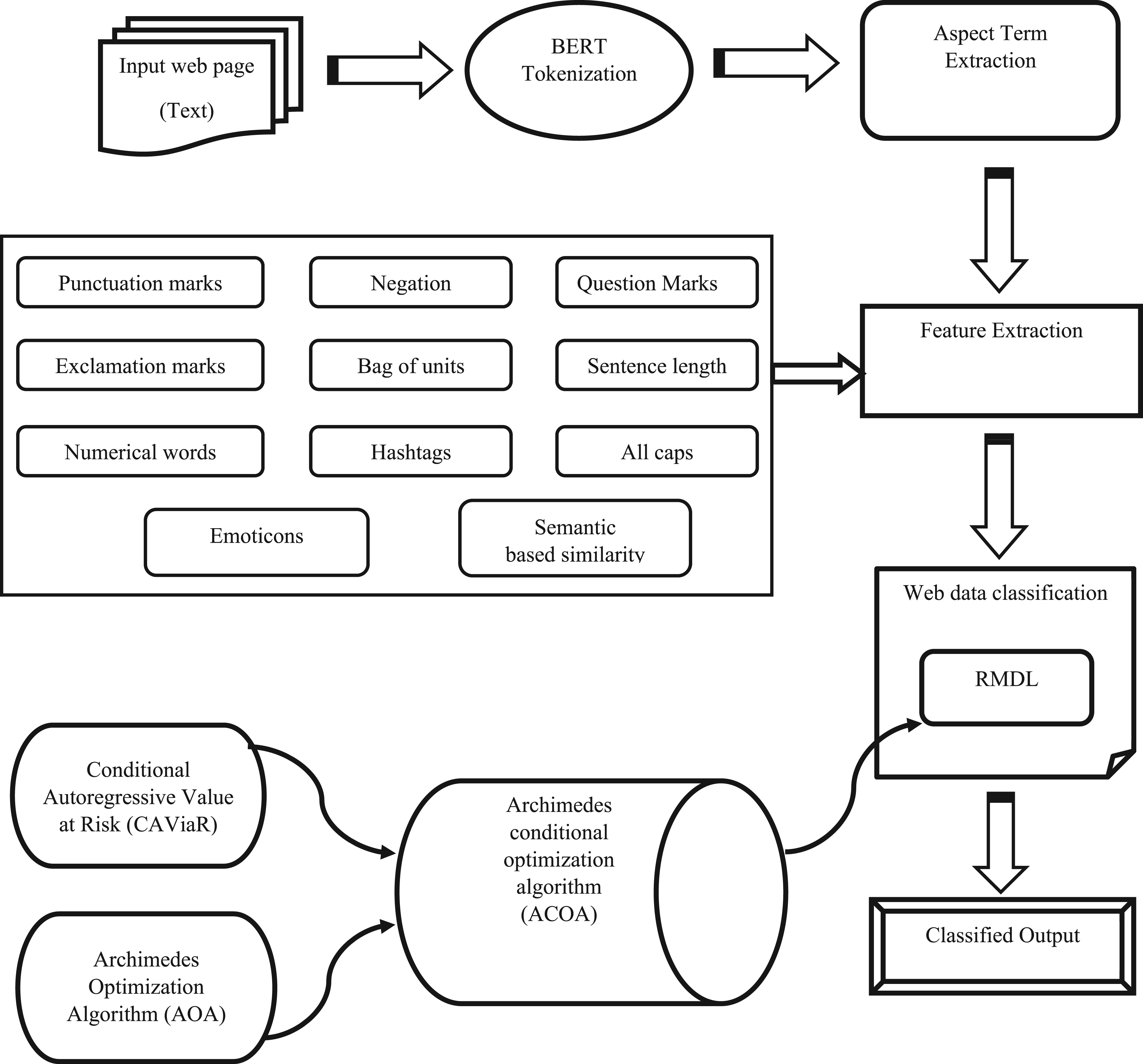
Modeled diagram of archimedes conditional autoregressive optimization algorithm _ random multimodel deep learning for web data classification.
Consider a database W for web data classification, which is formulated as,

The input web page data based on text
Aspect term extraction
The input
The BERT shared layers are enriched with Local Context Feature Generator (LCFG) and Global Context Feature Generator (GCFG) which is formulated as,

The aspect polarity classifier (APC) performs a head-pooling on the acquired concatenated context features. After extracting the hidden states on the matching location of the first token in the input sequence using head-pooling, the sentiment polarity is predicted using a Softmax operation. It is formulated as,




The aspect word extractor completes the token-level classification for each token, which is calculated as,

Therefore, the outcome of ATE is implied as
The ATE Punctuation Marks Negation Question Marks Exclamation Marks Bag of words Sentence Length Numerical Words Hash-tags All Caps Emoticons Semantic based similarity
It is referred to as the collection of symbols used to control texts and make their contents clear, primarily by separating or joining words, which is illustrated as
It is defined as the number of negation in the text which is constructed by interchanging the truth value of the statement and it is formulated as
It is an interrogation point used to punctuate interrogative sentences at the end of question tags, which is illustrated as
It is commonly referred to as the exclamation point, is used to denote intense feelings and emotions. It is used with interjections and in exclamatory sentences. It is calculated as
It is a method used in natural language processing to describe an image feature. NLP is described as
It has generated a great deal of interest in linguistic and literary studies because it is defined by the number of words in the phrase and it is signified as
The numeral of various text or arithmetic digits utilized to deliver the values is represented as
It is referred by symbol # and it is used to separate the contents and it have affirmative and pessimistic which counts and includes it as two aspects which is implied as
It describes the overall capitalized words and it is denoted as
It is the representation of facial expressions using specific numbers, punctuations and alphabets which are specified as
It is used to assess measures that are entirely text-based and make use of the proximity or context of words or terms, which is denoted as


Finally, the feature vector is formulated as,

Web data can be easily gathered from the internet, but it might be cluttered with noise because of the way most search engines work. Therefore, choosing reliable data from noisy web data is the secret to web data learning. Additionally, some deep learning studies demonstrate that clean, hard examples benefit model training. As a result, the RMDL structure is explained below.
Structure of Random Multimodel Deep Learning Deep Neural Networks Recurrent Neural Networks
The feature vectors
DNN are built with many connections between their layers, with each layer only receiving connections from the layer before it and only providing connections to the layer after it in the hidden portion. It is formulated as,
The Long Short-term Memory (LSTM) and Gated Recurrent Unit (GRU) are both used to resolve the tribulations with RNN. LSTM is good at remembering patterns over short periods of time, while GRU is good at dealing with difficult sequences. RNN assign additional importance to the preceding data points in succession, which makes it a great tool for text, string, and sequential data sorting. It can also be utilized for image cataloging.





Long Short-term Memory: LSTM helps you keep a strong connection between memories over time, which is helpful when trying to trounce the “vanishing gradient” issue. LSTM is more complex than RNNs, with multiple gates that help regulate how much information gets passed into each node. The input gates, memory cell values, forget gate activation, new memory cell value, and output gate values, which is illustrated below.
Convolutional Neural Network
CNNs are used to classify documents or images. They are similar to the way the brain processes information, and they are often used to classify text. In RMDL, this technique is utilized on all of our datasets, which is implied as






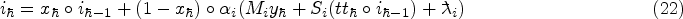
The classified outcome of web data classification is formulated as Archimedes conditional autoregressive optimization algorithm
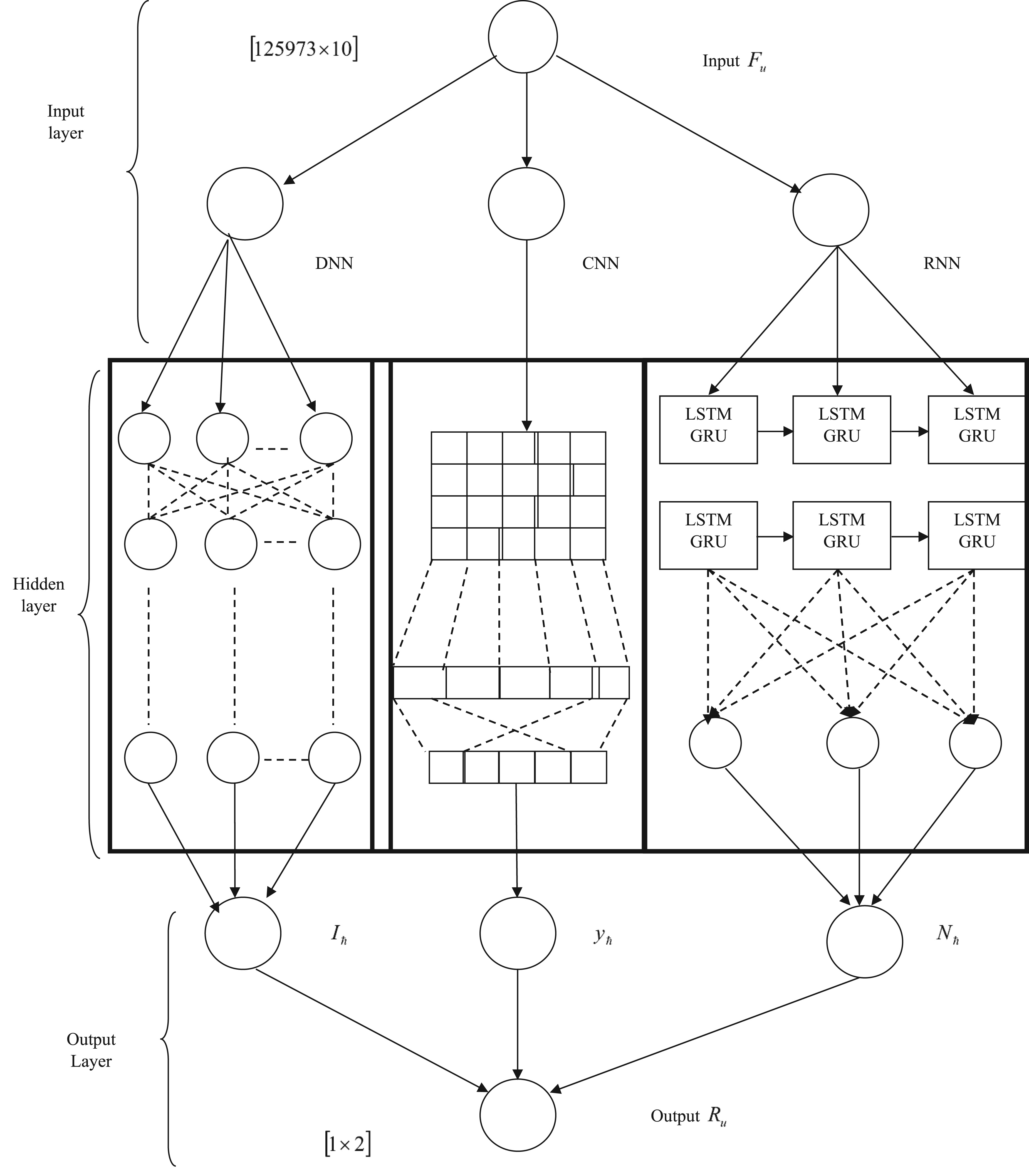
Structure of random multimodel deep learning.
Every person in the population serves as the pre-occupied objects in the developed method called AOA. AOA also introduces items with random volumes, densities, and accelerations at the beginning of the search process. At this moment, a random spot in the fluid serves as the initialization point for each item. After evaluating the fitness of the starting population, AOA repeats iterations until the termination condition is satisfied. AOA changes each iteration's density and volume for every object. Based on whether an object collides with any other nearby objects, its acceleration is changed. The new location is computed by the upgraded density, volume, and acceleration. The optimally tuned algorithm of ACOA is discussed in the following steps.
The uttermost outcome for the particular algorithm concern in a search space

This measure is employed to analyze the peak solution to obtain the greatest solution. It is formulated as,
Step 1: Initialization
Step 2: Evaluate Fitness Function
Step 3: Upgrade volume and density
Step 4: Evaluate transfer operator and density factor
Step 5: Exploration phase
Step 6: Exploitation Phase
Step 7: Compute acceleration
Step 8: Upgrade the position
Step 9: Termination
Pseudo code of Archimedes conditional autoregressive optimization algorithm _ Random Multimodel Deep Learning.
The position of all objects
In this process, the best outcome should be selected, so that the value of fitness can be examined on the solution by using equation (24). The value found to be exact is utilized for the further aspect.
The volume and density of objects is computed by,
Once the time has passed since the first collision, the objects attempt to attain an equilibrium condition. With the aid of the transfer operator, this is implemented in AOA, changing search from exploration to exploitation and is signified as,
If
If
It is utilized to calculate the percentage of change, which is illustrated as,
The standard expression from AOA is followed for the upgrade process, which is formulated as,
This process will repeat until this approach acquires the uttermost outcome with better efficaciousness. The pseudo code of ACOA is discussed in Algorithm 1.






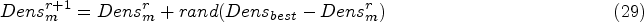
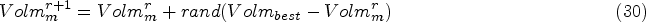


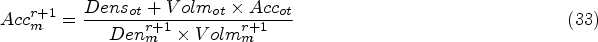
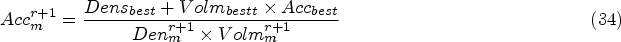

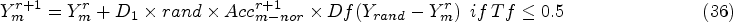
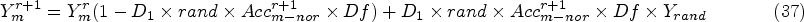
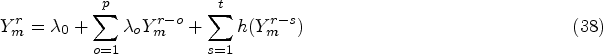
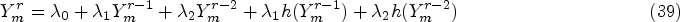
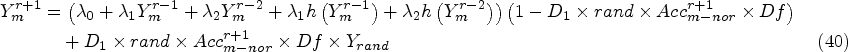
This segment portrays the outcomes of the presented technique ACOA_RMDL and deliberated the effectiveness of this method. The experimentation is performed in the Personal Computer with the PYTHON tool.
Evaluation metrics
The metrics employed for ACOA_RMDL is deliberated as follows,
Precision Recall F1- Score
It displays the likelihood that all of the positives are genuine positives, which is formulated as,

The ratio of accurately forecasted positives to all positives, which is calculated as,

Better evaluation is given, and the average precision and recall are calculated. It is calculated as,

Website classification dataset 1
Website classification dataset 1 20 is the database used for classifying online data. It was made by scraping various web pages and categorizing them according to the text that was extracted. This collection weighs in at 7.51 MB in size.
Website classification dataset 2
Website classification dataset 2 21 is used for URL based classification. The Open Directory Project (ODP) was another name for the website and the group of people that kept it updated. Although a community of volunteer editors built and maintained it, AOL (now a subsidiary of Verizon Media) controlled it. The size of the dataset is 82.72 MB.
Performance analysis
This section presents the performance analysis of the proposed method using the metrics, such as precision, recall, and F1-score.
Performance analysis using website classification dataset 1
Analysis by varying the number of hidden layers
Figure 3 presents the performance of the proposed ACOA_RMDL by varying the number of hidden layers. Figure 3(a) shows the precision of the proposed method. When the learning set is 60%, the precision of the proposed method with layers 2, 4, 6, and 8 is 0.809, 0.828, 0.838, and 0.865, respectively. The precision increases with the increase in the learning set. Figure 3(b) shows the recall of the proposed ACOA_RMDL. The proposed method has the recall of 0.889, 0.898, 0.918, and 0.936 with layers 2, 4, 6, and 8, respectively, for 90% of the training data. Similarly, the F1-score of the proposed method is shown in Figure 3(c). When the learning set is 90%, the proposed method has the F1-score of 0.874, 0.883, 0.902, and 0.921 with layers 2, 4, 6, and 8, respectively.
Analysis by varying the hidden neurons
Performance analysis by varying the number of hidden layers for website classification dataset 1.
Figure 4 shows the performance of the proposed ACOA_RMDL by varying the number of hidden neurons. Figure 4(a) depicts the precision of the proposed method. When the learning set is 60%, the precision of the proposed method with hidden neurons 5, 10, 15, and 20 is 0.828, 0.839, 0.858, and 0.865, respectively. The recall of the proposed ACOA_RMDL is shown in Figure 4(b). For 90% of the learning set, the proposed method has the recall of 0.849, 0.868, 0.877, and 0.897 with hidden neurons 5, 10, 15, and 20, respectively. The F1-score of the proposed method is depicted in Figure 4(c). The proposed method has the F1-score of 0.838, 0.853, 0.867, and 0.881 for 90% of the learning set with hidden neurons 5, 10, 15, and 20, respectively.
Performance analysis by varying the number of hidden neurons for website classification dataset 1.
From Figures 3 and 4, it is noted that the performance of the proposed method is high when the number of hidden layers and the hidden neurons is 8 and 20, respectively.
Analysis by varying the number of hidden layers
The performance of the proposed ACOA_RMDL is analyzed by varying the number of hidden layers and the results are plotted in Figure 5. Figure 5(a) shows the precision of the proposed method. When the learning set is 60%, the precision of the proposed method with layers 2, 4, 6, and 8 is 0.788, 0.810, 0.818, and 0.838, respectively. Figure 5(b) illustrates the recall of the proposed ACOA_RMDL. The proposed method has the recall of 0.818, 0.829, 0.849, and 0.876 with layers 2, 4, 6, and 8, respectively, for 70% of the training data. Likewise, the F1-score of the ACOA_RMDL is shown in Figure 5(c). When the learning set is 80%, the ACOA_RMDL has the F1-score of 0.823, 0.839, 0.857, and 0.887 with layers 2, 4, 6, and 8, respectively.
Analysis by varying the hidden neurons
Performance analysis by varying the number of hidden layers for website classification dataset 2.
Figure 6 demonstrates the performance of the proposed ACOA_RMDL by varying the number of hidden neurons. Figure 6(a) portrays the precision of the proposed method. When the learning set is 90%, the precision of the proposed method with hidden neurons 5, 10, 15, and 20 is 0.829, 0.859, 0.867, 0.889, respectively. The recall of the proposed ACOA_RMDL is shown in Figure 6(b). For 70% of the learning set, the proposed method has the recall of 0.818, 0.828, 0.847, and 0.876 with hidden neurons 5, 10, 15, and 20, respectively. The F1-score of the proposed method is depicted in Figure 6(c). The proposed method has the F1-score of 0.829, 0.843, 0.863, and 0.887 for 80% of the learning set with hidden neurons 5, 10, 15, and 20, respectively.

Performance analysis by varying the number of hidden neurons for website classification dataset 2.
On seeing Figures 5 and 6, it is identified that the proposed ACOA_RMDL offers the good performance with high values of precision, recall, and F1-score. Particularly, the best performance is attained when the number of hidden layers is 8 and the number of hidden neurons in 20. From the analysis, one can know that the proposed method is a powerful tool for handling and classifying complex web data.
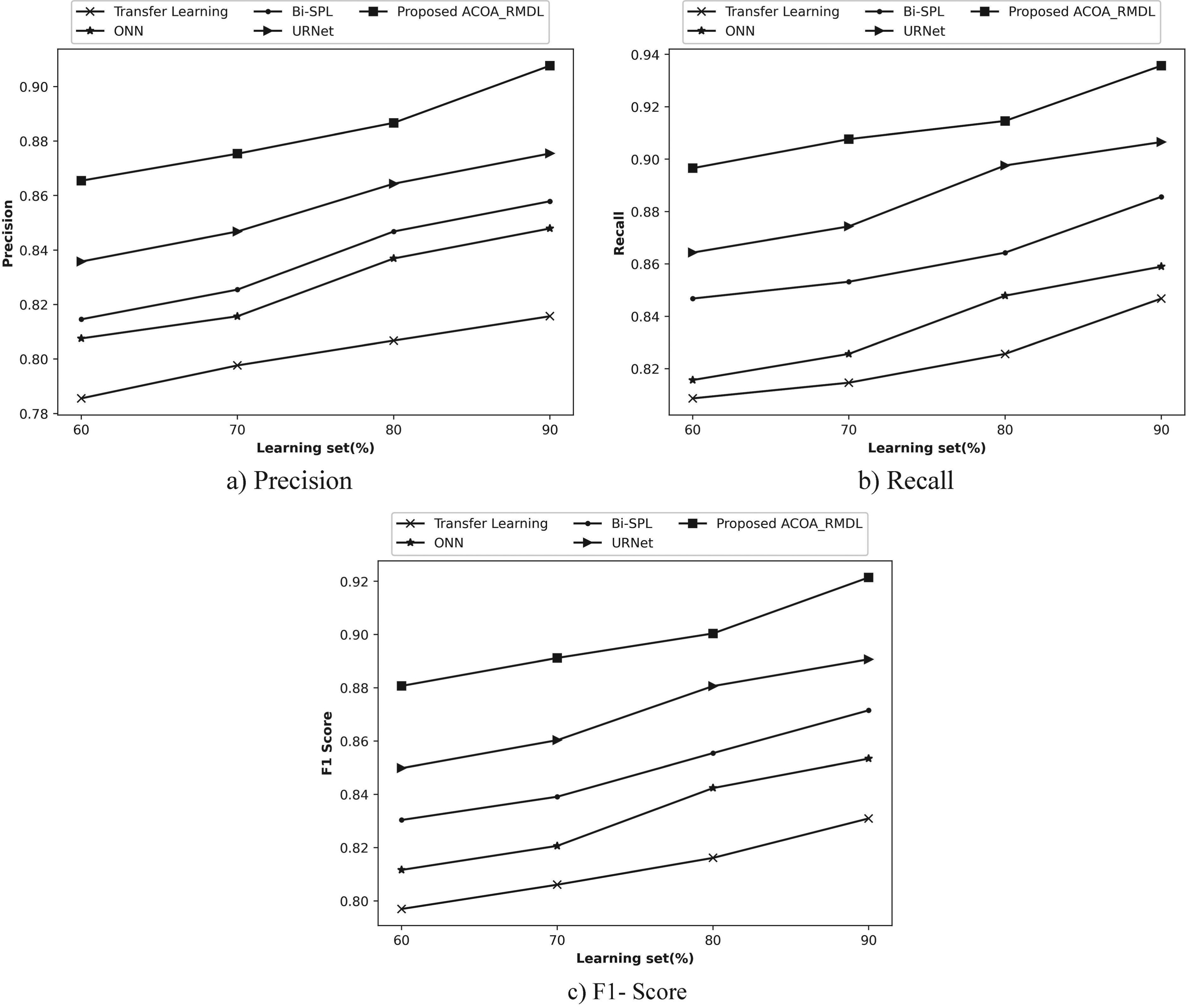
The evaluation based on the learning set and K-fold is examined and deliberated in the below segment. The strategies utilized for ACOA_RMDL are Transfer learning, 14 ONN, 15 BiSPL 16 and URNet 17 by varying learning set and K-fold.
Performance based on learning set for Website classification dataset1 Performance based on K-fold for Website classification dataset1
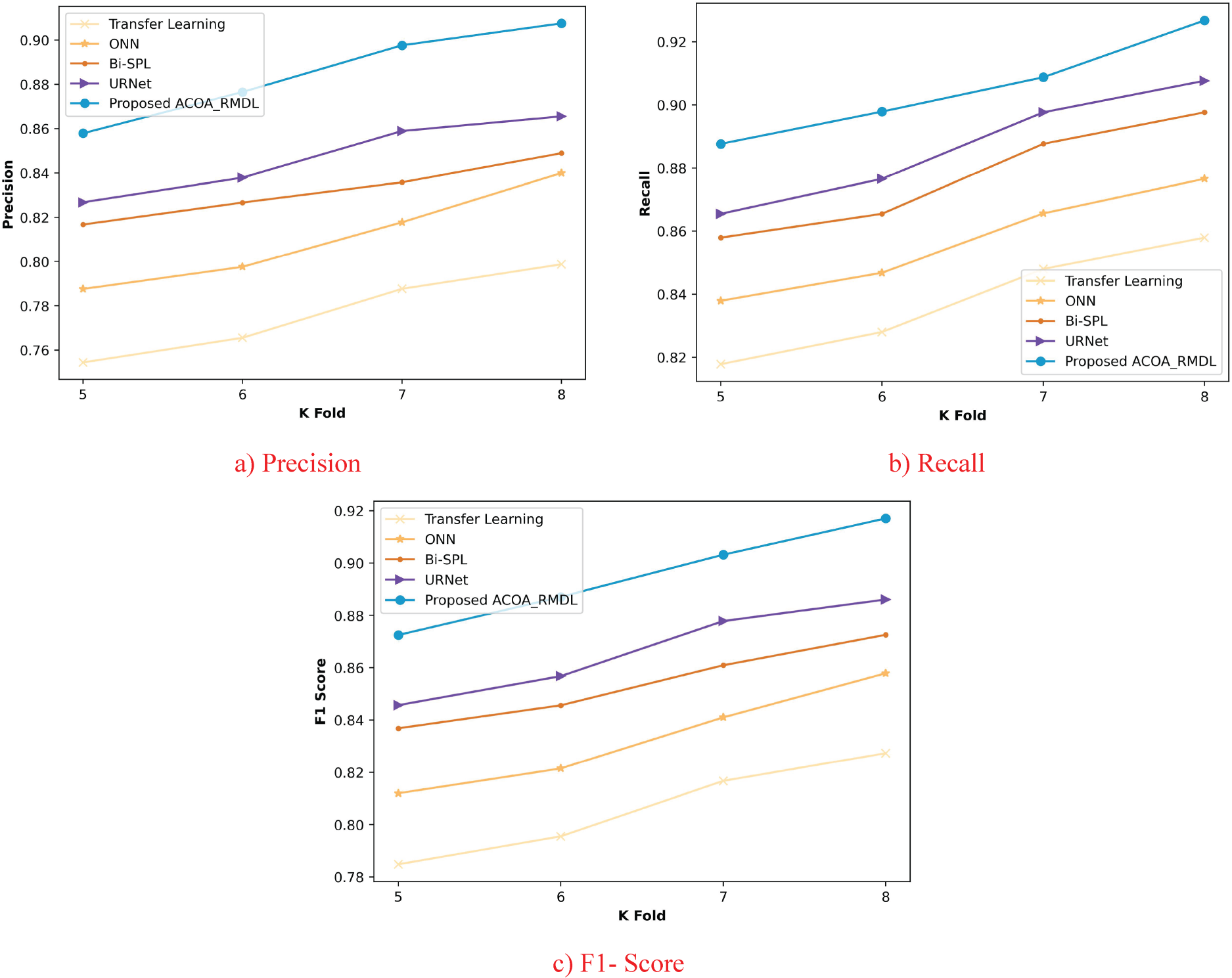
Figure 7, exploits the valuation of ACOA_RMDL based on a learning set. In Figure 7(a) the ACOA_RMDL by means of precision is illustrated. If the training set = 90%, the ACOA_RMDL achieved 0.908, while the performance of conventional techniques namely, Transfer learning, ONN, BiSPL and URNet obtained precision with 10.133%, 6.584%, 5.483% and 3.550%. Figure 7(b) implies the ACOA_RMDL by means of recall. The presented scheme achieved recall as 0.936, while the previous models attained performance enhancement with 9.500%, 8.196%, 5.347% and 3.114%, by the learning set as 90%. In Figure 7(c), the F1- score of ACOA_RMDL is deliberated. With 90% of the learning set, the ACOA_RMDL of F1- score had 0.921, Transfer learning had 9.822%, ONN had 7.385%, BiSPL had 5.417% and URNet had 3.336%.

Valuation of archimedes conditional autoregressive optimization algorithm _ random multimodel deep learning for website classification dataset 1.
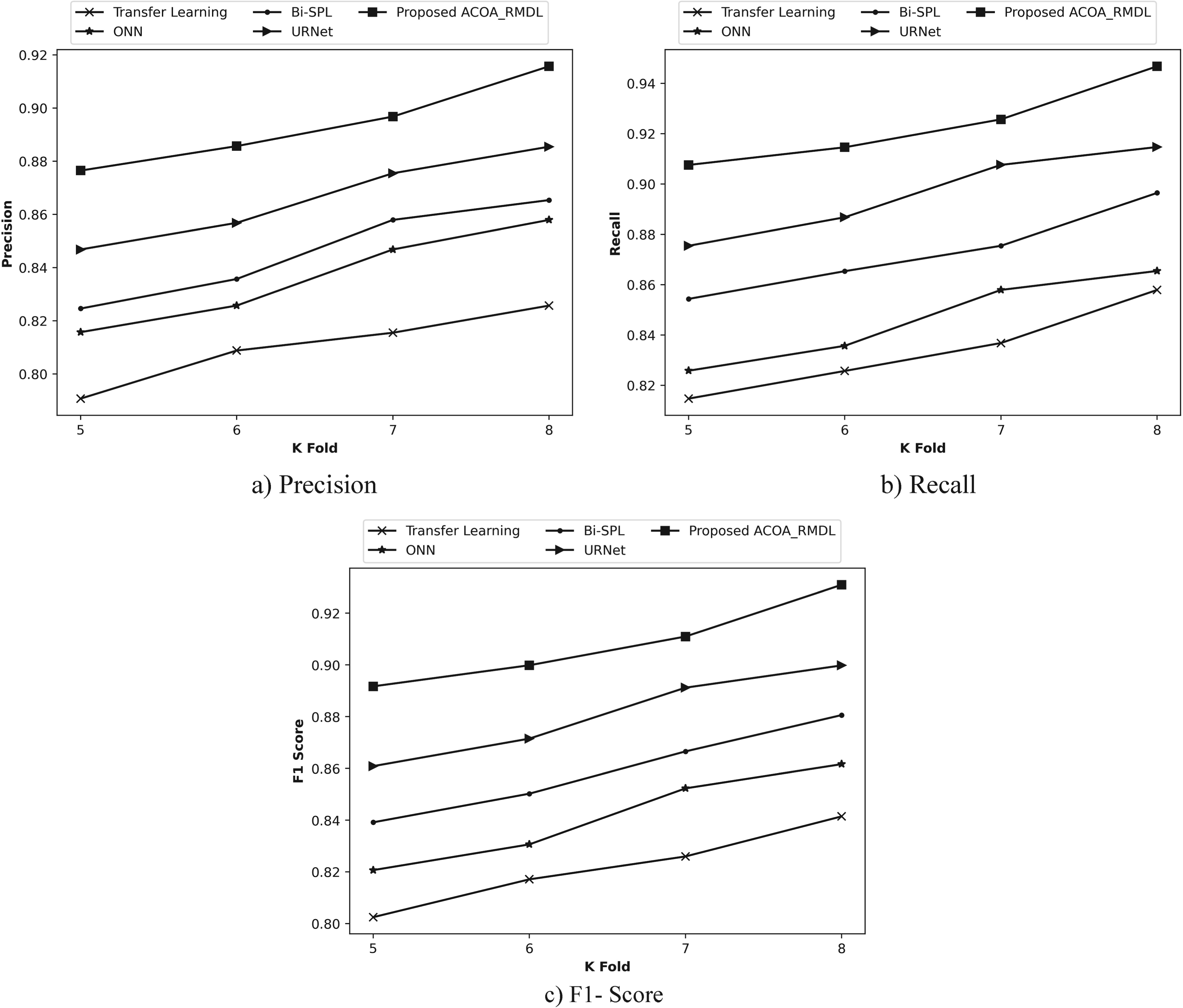
Figure 8, represents the evaluation of ACOA_RMDL based on K-fold. In Figure 8(a), the ACOA_RMDL utilizing precision is illustrated with the K-fold as 8. ACOA_RMDL attained precision as 0.916 and the performance improvement of existing methods such as, Transfer learning, ONN, BiSPL and URNet acquired 9.829%, 6.311%, 5.497% and 3.303%. Figure 8(b), the analysis of ACOA_RMDL in regard of recall is described. When the k-fold is 8, the ACOA_RMDL by means of recall observed 0.947 while comparing it to the conventional techniques like, Transfer learning obtained 9.388%, ONN achieved 8.591%, BiSPL attained 5.316% and URNet observed 3.390%., when the k-fold is considered as 8. In Figure 8(c), the F1-Score of ACOA_RMDL is deliberated. The previous approaches based on F1- score attained 9.612%, 7.446%, 5.408% and 3.346%, while the ACOA_RMDL acquired 0.931, when the k-fold =8.
Performance based on learning set for Website classification dataset 2
Valuation of archimedes conditional autoregressive optimization algorithm _ random multimodel deep learning for website classification dataset 1.
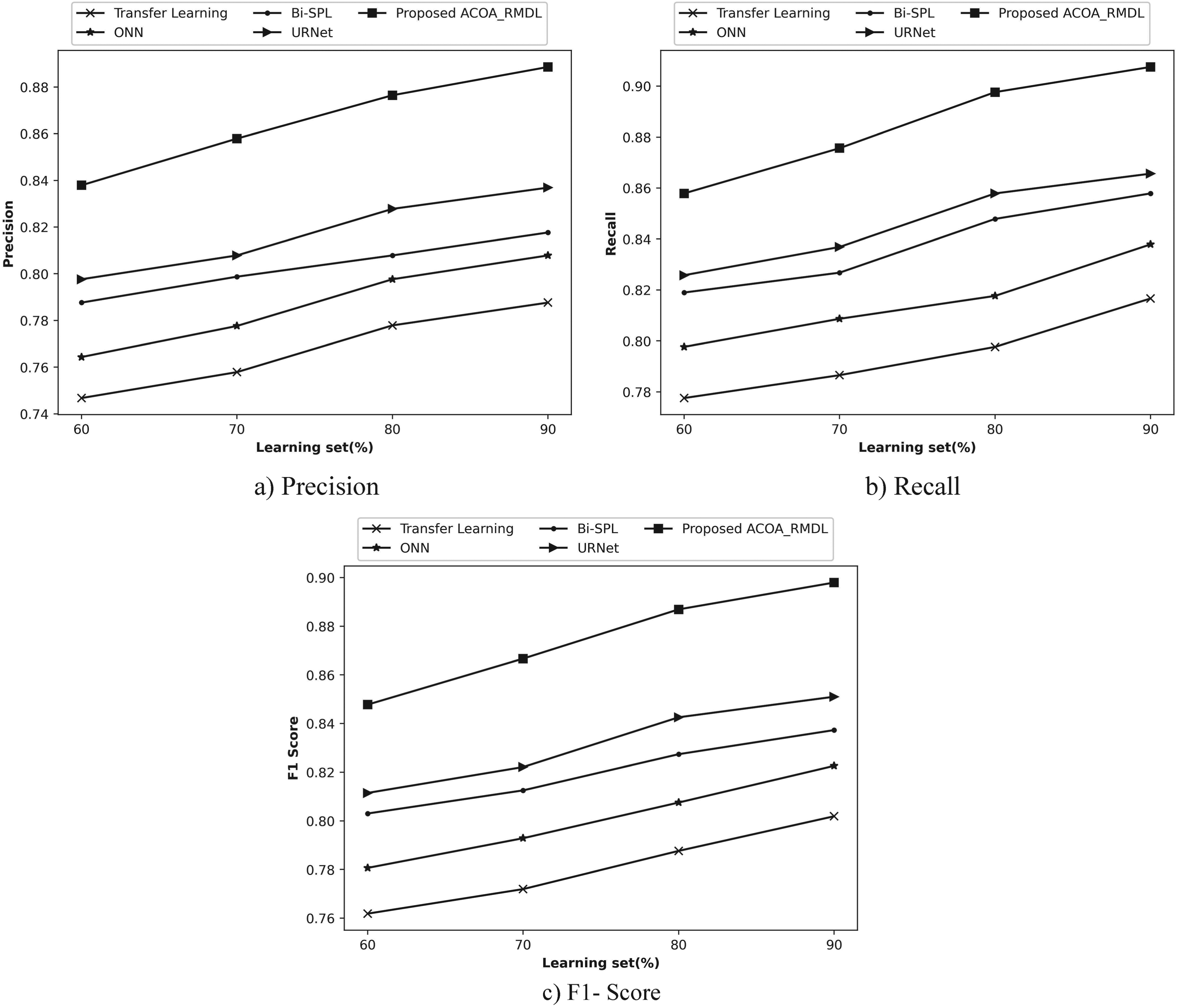
Figure 9, exploits the valuation of ACOA_RMDL based on a learning set. In Figure 9(a), the ACOA_RMDL by means of precision is illustrated. If the training set = 90%, the ACOA_RMDL achieved 0.889, while the conventional techniques namely, Transfer learning, ONN, BiSPL and URNet obtained precision with 0.788, 0.808, 0.818, and 0.837. Figure 9(b) implies the ACOA_RMDL by means of recall. The presented scheme achieved recall as 0.908, while the previous models attained 0.817, 0.838, 0.858, and 0.866, by the learning set as 90%. In Figure 9(c), the F1- score of ACOA_RMDL is deliberated. With 90% of the learning set, the ACOA_RMDL of F1- score had 0.898, Transfer learning had 0.802, ONN had 0.823, BiSPL had 0.837 and URNet had 0.851.
Performance based on K-fold for Website classification dataset 2

Valuation of archimedes conditional autoregressive optimization algorithm _ random multimodel deep learning for website classification dataset 2.
Figure 10, represents the evaluation of ACOA_RMDL based on K-fold. In Figure 10(a), the ACOA_RMDL utilizing precision is illustrated with the K-fold as 8. ACOA_RMDL attained precision as 0.908 and existing methods such as, Transfer learning, ONN, BiSPL and URNet acquired 0.799, 0.840, 0.849, and 0.866. Figure 10(b), the analysis of ACOA_RMDL in regard of recall is described. When the k-fold is 8, the ACOA_RMDL by means of recall observed 0.927 while comparing it to the conventional techniques like, Transfer learning obtained 0.858, ONN achieved 0.877, BiSPL attained 0.898 and URNet observed 0.908, when the k-fold is considered as 8. In Figure 10(c), the F1-Score of ACOA_RMDL is deliberated. The previous approaches based on F1- score attained 0.827, 0.858, 0.873, and 0.886, while the ACOA_RMDL acquired 0.917, when the k-fold =8.
Valuation of archimedes conditional autoregressive optimization algorithm _ random multimodel deep learning for website classification dataset 2.
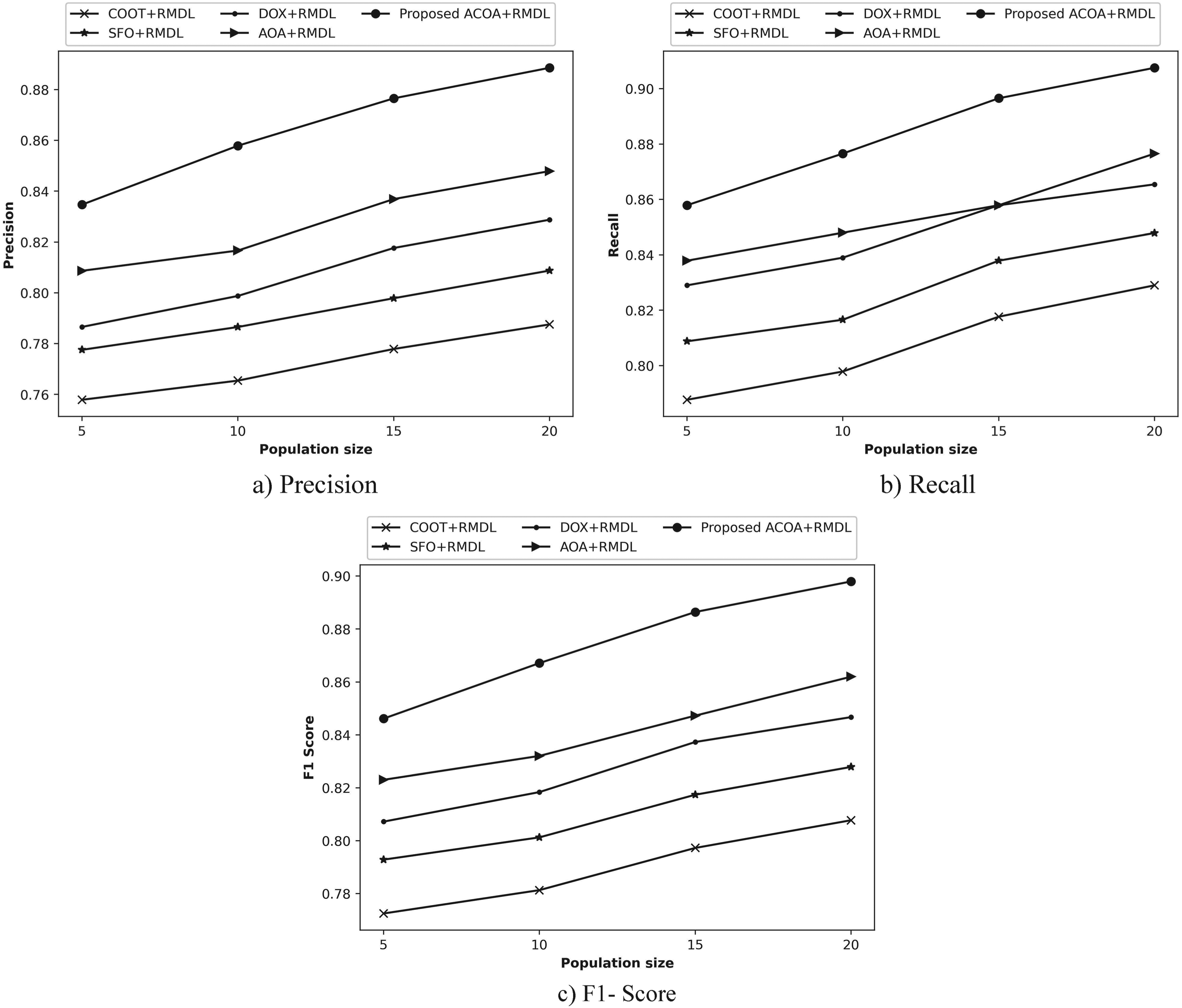
Various algorithmic approaches is provided for the evaluation namely, COOT,
28
SFO,
29
DOX,
30
AOA
25
and proposed ACOA_RMDL by changing population size.
Performance based on Website classification dataset 1 Performance based on Website classification dataset 2
Figure 11, dissipates the evaluation of ACOA_RMDL by varying population size. Figure 11(a) shows the precision of ACOA_RMDL. When the population size is 5, ACOA_RMDL with respect to precision obtained 0.858; the conventional techniques acquired 0.775, 0.787, 0.808 and 0.826. ACOA_RMDL obtained 0.908, while comparing, the performance gain achieved by former techniques namely COOT, SFO, DOX and AOA attained 10.244%, 9.152%, 6.706% and 4.773% by considering population size as 20. In Figure 11(b), the recall of ACOA_RMDL is represented. If the population size =5, then the ACOA_RMDL had the recall as 0.897 and the traditional strategies had 0.825, 0.847, 0.854 and 0.875. Figure 11(c) illustrates the F1- score of ACOA_RMDL. By considering the population size as 5, the ACOA_RMDL achieved the F1- score as 0.877 and the previous techniques like COOT obtained 0.799, SFO acquired 0.816, DOX achieved 0.830 and AOA attained 0.850.
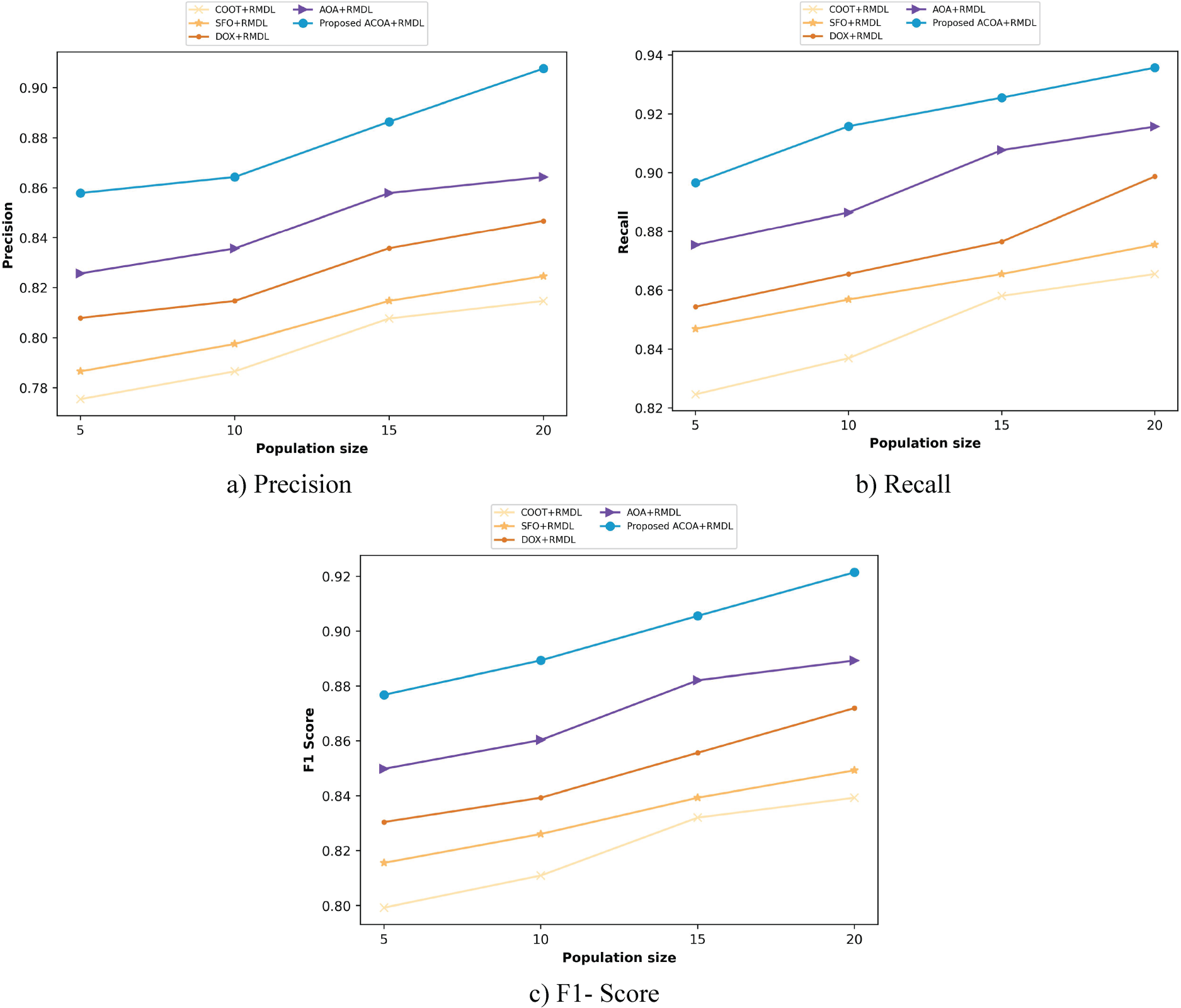
Algorithmic valuation of archimedes conditional autoregressive optimization algorithm _ random multimodel deep learning for website classification dataset 1.
The evaluation of ACOA_RMDL is dispersed by changing the population size in Figure 12. Figure 12(a) illustrates the accuracy of ACOA_RMDL. With regard to precision, ACOA_RMDL obtained 0.889 when the population size was 20, but conventional approaches, such as; COOT + RMDL, SFO + RMDL, DOX + RMDL, AOA + RMDL obtained 0.788, 0.809, 0.829, and 0.848. The recall of ACOA_RMDL is shown in Figure 12(b)). The recall for the ACOA_RMDL was 0.908 when the population size was 20, while the recall for the conventional techniques, such as, COOT + RMDL, SFO + RMDL, DOX + RMDL, AOA + RMDL was 0.829, 0.848, 0.865, and 0.877. Figure 12(c)) shows the ACOA_RMDL's F1-score. With a population size of 20, the ACOA_RMDL obtained an F1-score of 0.898, compared to prior methods such as COOT + RMDL obtained 0.808, SFO + RMDL obtained 0.828, DOX + RMDL obtained 0.847, and AOA + RMDL obtained 0.862.
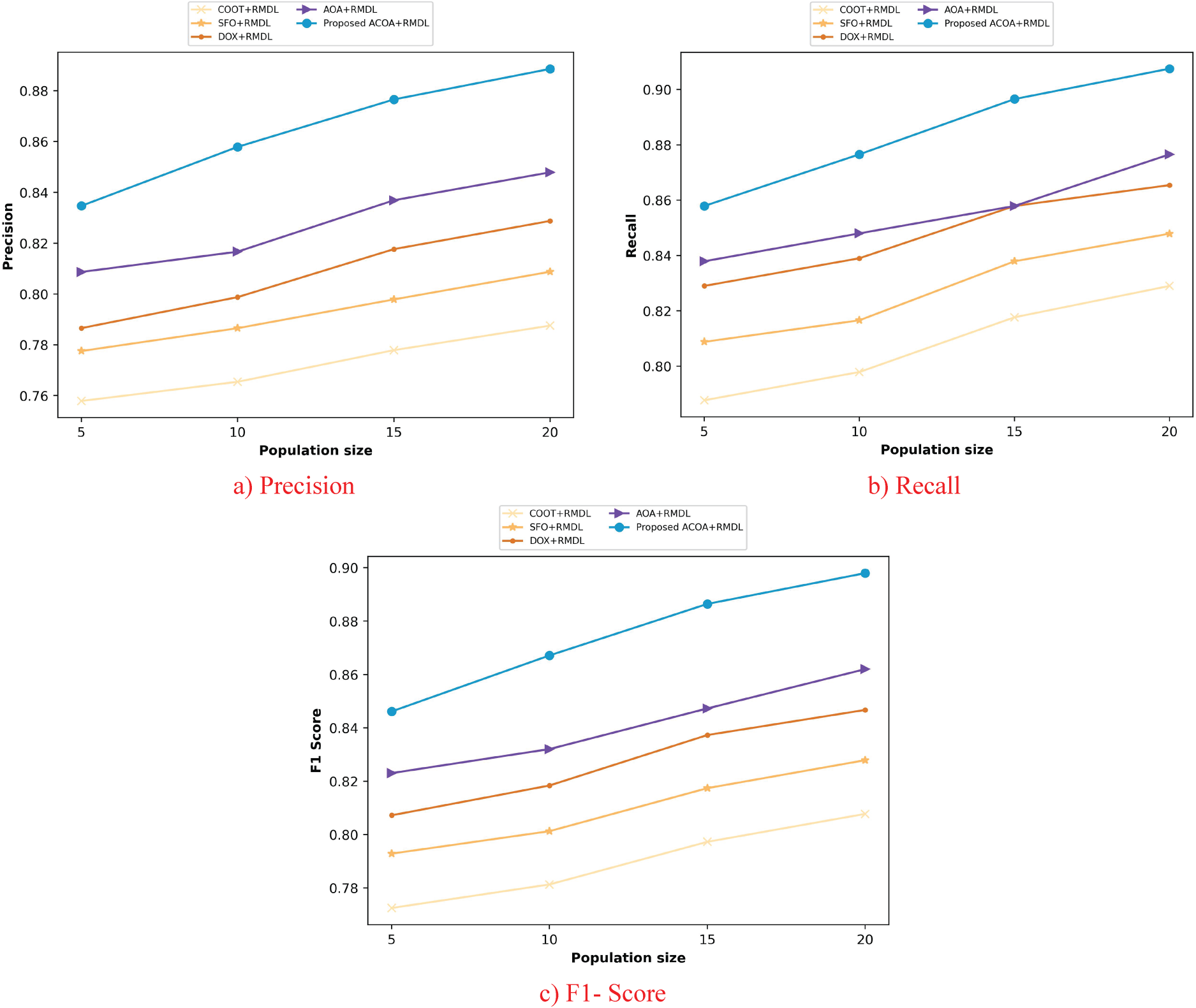
Algorithmic valuation of archimedes conditional autoregressive optimization algorithm _ random multimodel deep learning for website classification dataset 2.
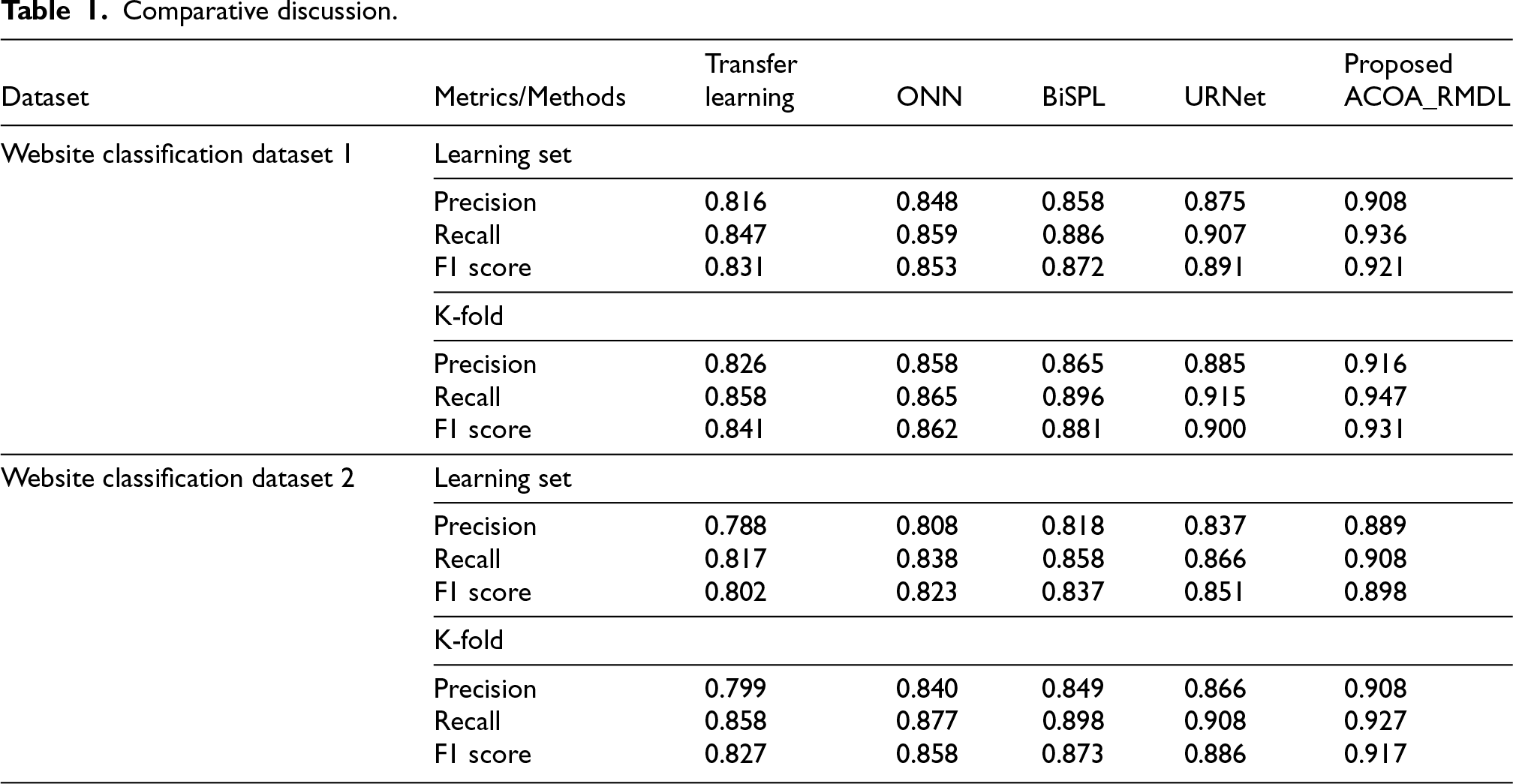
In Table 1, indicates the comparative discussion of ACOA_RMDL when compared to the former approaches. From this table, the evaluation metrics utilized for ACOA_RMDL namely, precision, recall and F1- score obtained with maximum values of 91.6%, 94.7% and 93.1% for Website classification dataset 1. Similarly, for website classification dataset 2, the ACOA_RMDL obtained maximum values of 90.8%, 92.7%, and 91.7% for precision, recall and F1- score.
Comparative discussion.
Comparative discussion.
Table 2 shows the training time of the proposed and existing methods. The training time of the proposed method is 9.456 s, whereas the training time of the existing methods, such as, Transfer learning, ONN, BiSPL and URNet, are
Training time.

Training time.
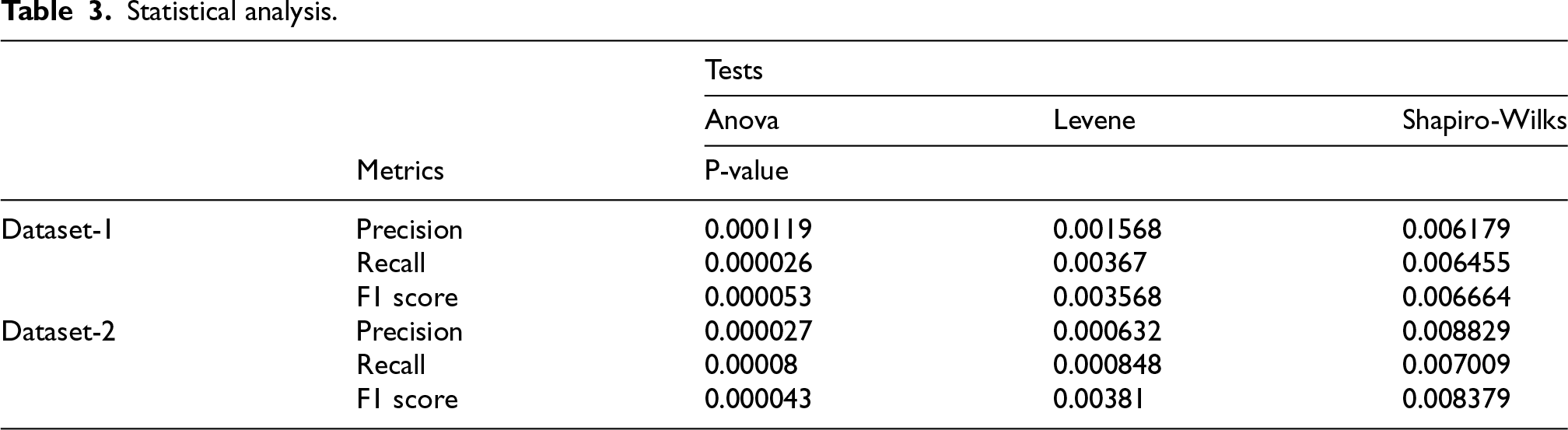
One of the most effective techniques for comparing experimental results is statistical hypothesis testing. 31 This method involves making inferences about a hypothesis based on the observation of processes modeled through random variables. The primary goal is to determine whether a sample of results supports a specific hypothesis and if the conclusions drawn can be generalized beyond the tested scenarios. In statistical hypothesis testing, the P-value, or probability value, quantifies the likelihood that the observed results could occur under the null hypothesis. P-values assist in deciding whether to reject the null hypothesis. A smaller P-value indicates that the observed results are less likely to have occurred under the null hypothesis, suggesting that the null hypothesis should be rejected. P-values are typically reported as decimals ranging from 0 to 1, with a critical value, usually 0.05, considered significant. If the p-value is less than the critical value, the null hypothesis is rejected; if it is equal to or greater than the critical value, the null hypothesis is not rejected. Here, three tests, namely Analysis of Variance (ANOVA), Levene, and Shapiro-Wilks are conducted and the resultant P-values are provided in Table 3.
Statistical analysis.
Statistical analysis.
ANOVA test is used to determine if there are significant differences between the means of three or more groups. The Levene test assesses whether multiple groups have equal variances within the population. It is used to test the null hypothesis that the variances of the samples being compared are equal. The Shapiro-Wilk test is a hypothesis test that examines whether a data set follows a normal distribution. It compares the sample data against the null hypothesis that the data set is normally distributed. A high p-value suggests that the data set is normally distributed, while a low P-value suggests it is not. On seeing Table 3, it is noted that the proposed method rejects the null hypothesis by obtaining the P-value less than 0.05.
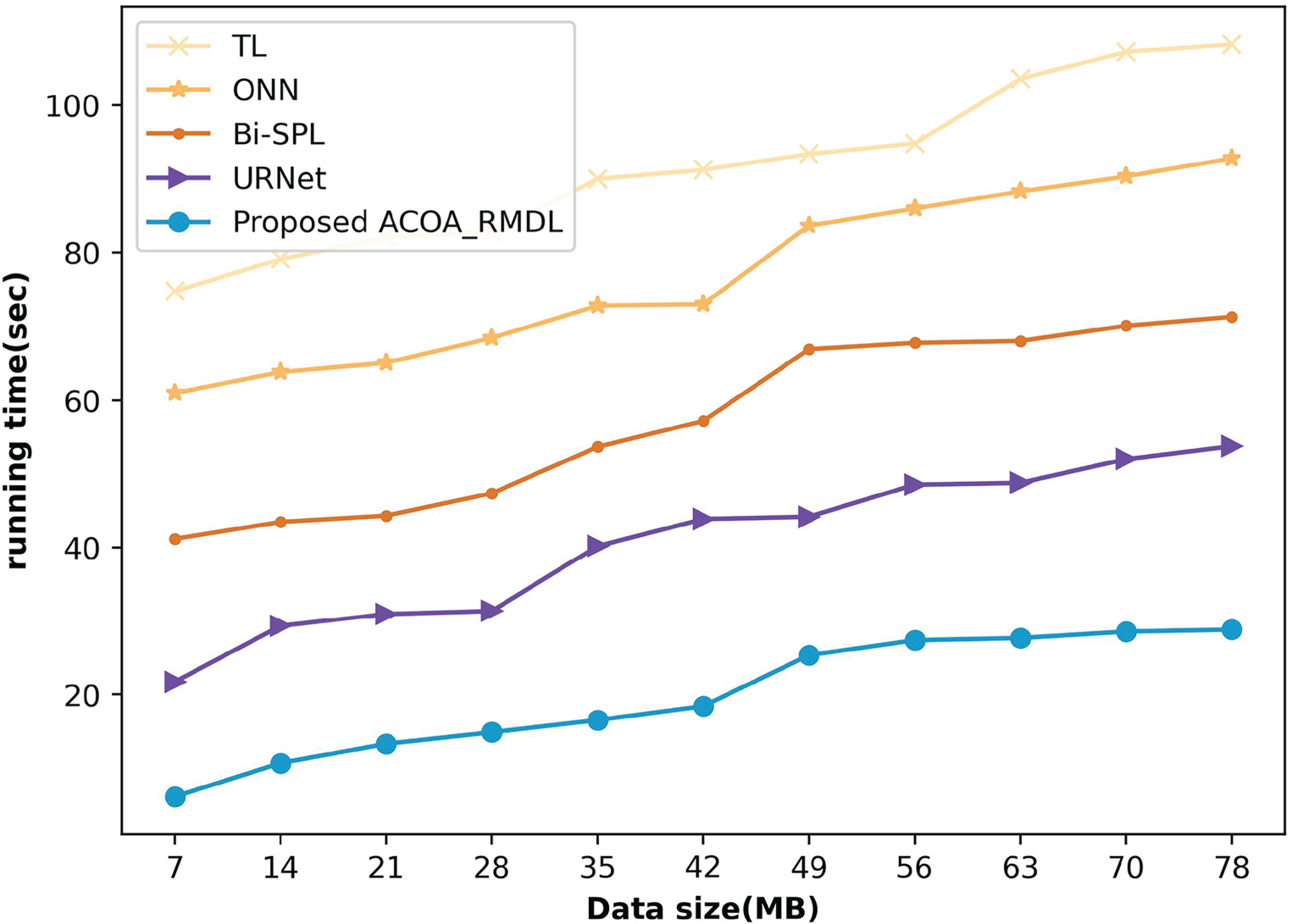
Scalability analysis is the evaluation of the classifier's performance as the dataset's size or complexity grows. This involves evaluating the classifier's ability to handle larger volumes of data, more features, and more complex patterns without a significant degradation in performance. Figure 13 shows the scalability of the proposed method and the existing methods for various data sizes. When the data size is 7 MB, the running time of the methods, such as Transfer learning, ONN, BiSPL and URNet is 74.745 s, 60.963 s, 41.173 s, 2 and 1.716 s On the other hand, the running time of the proposed method is 6.177 s The running time of all methods increases with the increase in the data size. When the data size is 78 MB, the running time of the comparative methods, such as Transfer learning, ONN, BiSPL, URNet, and ACOA_RMDL is 108.212sec., 92.736 s, 71.275sec., 53.761sec., ad 28.818 s, respectively. When compared to the other methods, the running time of the proposed method is low, which means that the proposed method is highly scalable in large size of the data.
Scalability analysis.
Due to the Internet's increasing popularity, the number of web sites has recently increased dramatically. A promising method for tackling the issue of insufficient data when training DL is to use web data. However, incorrect tags are frequently found in web pictures, which could undermine the DL strategy. Hence, in this research, a hybrid framework ACOA-enabled RMDL is designed for web data classification. First, the input web data based on text is considered and it is allowed to the BERT tokenization. After that process, the aspect term extraction is done. Moreover, the feature extraction is done by utilizing punctuation marks, negation, question marks, and exclamation marks, bag of units, sentence length, numerical words, hashtags, all caps, emoticons, and semantic based similarity to acquire the suitable vectors. Furthermore, the web data classification is obtained by RMDL, which is trained by ACOA. Here, ACOA is blended with the integration of AOA and CAViaR. The performance metrics employed for ACOA_RMDL are precision, recall and F1-score. The metrics attained with maximum values of 91.6%, 94.7% and 93.1% respectively. In future, classification tools may be used to enhance the processing and handling of sensitive data will be extended.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.