
Abstract
Text summarization (TS) plays a crucial role in natural language processing (NLP) by automatically condensing and capturing key information from text documents. Its significance extends to diverse fields, including engineering, healthcare, and others, where it offers substantial time and resource savings. However, manual summarization is a laborious task, prompting the need for automated text summarization systems. In this paper, we propose a novel strategy for extractive summarization that leverages a generative adversarial network (GAN)-based method and Bidirectional Encoder Representations from Transformers (BERT) word embedding. BERT, a transformer-based architecture, processes sentence bidirectionally, considering both preceding and following words. This contextual understanding empowers BERT to generate word representations that carry a deeper meaning and accurately reflect their usage within specific contexts. Our method adopts a generator and discriminator within the GAN framework. The generator assesses the likelihood of each sentence in the summary while the discriminator evaluates the generated summary. To extract meaningful features in parallel, we introduce three dilated convolution layers in the generator and discriminator. Dilated convolution allows for capturing a larger context and incorporating long-range dependencies. By introducing gaps between filter weights, dilated convolution expands the receptive field, enabling the model to consider a broader context of words. To encourage the generator to explore diverse sentence combinations that lead to high-quality summaries, we introduce various noises to each document within our proposed GAN. This approach allows the generator to learn from a range of sentence permutations and select the most suitable ones. We evaluate the performance of our proposed model using the CNN/Daily Mail dataset. The results, measured using the ROUGE metric, demonstrate the superiority of our approach compared to other tested methods. This confirms the effectiveness of our GAN-based strategy, which integrates dilated convolution layers, BERT word embedding, and a generator-discriminator framework in achieving enhanced extractive summarization performance.
Keywords
Introduction
Nowadays, the amount of information in different areas of the World Wide Web in various formats, such as web pages, articles, emails, log files, and linked data, is increasing sharply [1, 2]. However, much of the information is less important. On the other hand, manually identifying important information in a large text is time-consuming and practically impossible [3]. Therefore, we need a system that extracts vital information from the text in the shortest time and with the highest accuracy [4]. This system is called automatic text summarization (ATS). Primary hypotheses are presented for summarization. A summary is a text produced from one or more texts, not more than half of the whole text. According to research in [5], summarization is extracting the most important information from a source or sources to produce a shorter version for a specific user or task. In other words, this process is one of the crucial steps in diverse cases, such as extracting knowledge from text with huge information about the similarity of diseases in the OMIM dataset. Text summarization methods can be categorized in a different view of points. Output-based summarization can be done as extractive or abstractive. Extractive summarization is done by selecting important sentences from different text parts [6, 7]. In abstractive summarization, the system tries to identify the text’s key concepts and then converts it to another form that is shorter than the original text [8]. Extractive summarization ensures a semantic and grammatical rule between sentences. Input-based summarization may be a single-document or multi-document [9]. In the process of multi-document summarization, multiple documents pertaining to a similar topic are processed as input, and the concluding summary is derived from the entire collection of documents [10]. Depending on the content, the resulting summary may either be general or query-based. For query-based summarization, the system generates a summary specifically tailored to the user’s query [11]. This type of summary focuses on the user query and does not consider the general index of concepts in the text. However, in a general summary, the text is produced regardless of the subject and domain.
So far, many approaches have been proposed to address extractive summarization challenges. Several methods have relied on machine learning principles, including clustering [12] and support vector machine [13]. In more recent times, optimization algorithms [14–17] and fuzzy techniques [18] have also been employed for summarization. Graph-based approaches have been chosen as alternative methods for this objective [19]. In these methodologies, the typical approach involves treating each sentence as a graph, where the words are represented by nodes and the connections between the words are represented by graph edges. With recent advances in deep learning, other previous machine learning methods are less commonly utilized in natural language processing tasks. With its relatively complex structure, deep learning can learn the features of words, sentences, or documents automatically [20]. Despite the deep learning-based methods provided for summarization, many of them could not solve the challenges of extractive summarization. The two main components of summarizing are scoring sentences and selecting them. Most previous works suffer from a greedy choice of sentences [21]. In other words, after choosing a high-ranking sentence, they put it aside and do not consider it in choosing the next sentence, which leads to a decrease in the quality of the summary.
BERT has emerged as a groundbreaking model that tackles various limitations associated with traditional word embeddings in NLP [22, 23]. One significant challenge is the static nature of word representations employed by conventional embeddings. These fixed representations fail to capture the dynamic nature of language and the context in which words appear. BERT overcomes this hurdle by providing contextual word representations, leveraging the bidirectional nature of the transformer architecture. This allows BERT to capture the meaning of words within the context of the entire sentence, leading to more accurate and nuanced representations. Another challenge in NLP is the difficulty of capturing contextual information, including the multiple senses, polysemy, and ambiguity of words. Traditional word embeddings often struggle to disambiguate word meanings, resulting in limited semantic understanding. BERT, with its deep bidirectional architecture, excels at capturing the contextual nuances of words. By considering both the left and right contexts of a word during pre-training, BERT can better model the various senses and disambiguate word meanings more effectively.
Traditional word embeddings face challenges in handling word order and syntax. Sequential models, such as recurrent neural networks, struggle with long-term dependencies and preserving word order information. BERT leverages the self-attention mechanism in transformers to capture dependencies across the entire input sequence. This allows BERT to effectively model word dependencies and understand the syntactic structure of sentences, resulting in improved performance on tasks that require an understanding of sentence structure and grammar. Last, traditional word embeddings often cannot handle out-of-vocabulary (OOV) words efficiently. OOV words, which do not appear in the vocabulary of the pre-trained embeddings, pose a challenge for many NLP models. BERT addresses this issue by incorporating OOV words in its pre-training process. By using subword tokenization and leveraging subword embeddings, BERT can handle OOV words by breaking them down into smaller subword units that do exist in its vocabulary [24].
Convolutional neural networks (CNNs) have been widely successful in various domains, including computer vision [25–29], but face unique challenges when applied to NLP tasks [30]. NLP involves processing and understanding human language, which often comes as variable-length sequences, such as sentences or documents. Traditional CNNs are designed for fixed-size inputs, which pose a challenge in handling such variable-length input in NLP tasks. Dilated convolution emerges as a solution to this problem [31]. It allows CNNs to effectively handle variable-length input by adjusting the receptive field. By introducing gaps between filter weights, dilated convolution enables CNNs to capture information from a wider context, addressing the challenge of capturing long-range dependencies in NLP tasks. Standard CNNs with small receptive fields may struggle to capture the intricate relationships between distant words in a sentence, but dilated convolution provides a mechanism to incorporate a broader context and capture these long-range dependencies more effectively. Another challenge in NLP is the large vocabulary sizes and high-dimensional input representations associated with language data. Traditional CNNs may require a significant number of parameters to handle the complexity of the data, which can hinder both model performance and computational efficiency. Dilated convolution offers a solution by improving parameter efficiency. By exploiting the gaps between filter weights, dilated convolution allows CNN to model the input data more effectively with fewer parameters, leading to more efficient and scalable models for NLP tasks [32].
Generative Adversarial Networks (GANs) are powerful machine learning models comprising a generator and a discriminator. The generator aims to produce realistic outputs, such as images or text, while the discriminator’s role is to distinguish between real and generated data [33]. GANs offer a promising approach to address greedy sentence selection in extractive text summarization. In extractive text summarization, GANs consider the overall context of the text during the summary generation process. Rather than treating each sentence in isolation, the generator component is endowed with a comprehensive understanding of the entire document. This broader perspective empowers the generator to make informed decisions when selecting subsequent sentences for the summary. Considering the previously chosen high-ranking sentences within the summary, GANs avoid the pitfall of neglecting their importance, resulting in enhanced summary quality. The crucial role of Adversarial Training further enhances the performance of GANs in tackling the greedy sentence choice problem. During training, the discriminator provides valuable feedback to the generator regarding the quality and coherence of the generated summary. This feedback loop facilitates the refinement of the generator’s sentence selection strategy. As a result, the generator learns to choose sentences that are individually significant while also maintaining cohesiveness with the previously selected high-ranking sentences. Harnessing the power of adversarial training, GANs effectively overcome the challenge of excluding relevant sentences, leading to the production of more coherent summaries.
The proposed GAN-based extractive text summarizer combines the power of BERT for word embedding with the competitive dynamics of a generator and discriminator. By leveraging these components, the summarizer aims to generate concise and accurate summaries of documents. The generator plays a crucial role in this framework by assigning a score to each sentence in the document. Its objective is to produce summary sentences that effectively capture the key information while maintaining coherence and readability. The generator’s scoring mechanism allows for a comprehensive evaluation of sentence importance, enabling the selection of the most relevant content for the summary. To enhance the performance of the generator, a discriminator is incorporated into the GAN architecture. The discriminator’s purpose is to distinguish between real and fake summaries. By analyzing the generated summaries, the discriminator provides valuable feedback to the generator, facilitating the refinement of its scoring mechanism and promoting the production of more authentic and informative summaries. The generator operates in a non-greedy manner, which means it evaluates the possibility of each summary sentence simultaneously. This approach allows for a more holistic consideration of the document’s content, enabling the summarizer to capture important information across multiple sentences and sections. Both the generator and discriminator are structured with three dilated convolution layers. This design choice facilitates the extraction of significant features from the document in parallel, leveraging the benefits of dilated convolutions to capture a wide range of contextual information. The extracted features from the generator and discriminator are then concatenated to make the final decision regarding the inclusion of a sentence in the summary.
To contextualize the innovations presented in this work, it is imperative to understand their interdependencies and collective contributions. The primary challenge we address is the greedy sentence selection in extractive text summarization. Leveraging BERT’s contextual word representations provides a foundation, offering enhanced granularity in understanding text. Including dilated convolutions within CNNs complements this by effectively handling variable-length textual sequences, capturing intricate relationships and long-range dependencies vital for effective summarization. To further improve summary generation, we integrated the GAN architecture, allowing the discriminator’s feedback to continually refine the generator’s outputs. This interplay ensures that sentence selections are not only relevant individually, but also coherent when combined into a summary. The generator’s scoring mechanism, equipped with insights from BERT embeddings and dilated convolutions, provides a holistic view of the document’s content. Together, these innovations form a harmonious ensemble, each addressing specific challenges in text summarization, but when combined, they produce a system greater than the sum of its parts.
The following are the article’s contributions:
The summarizer model is equipped with an ensemble of dilated convolutions, which aids the model in extracting useful characteristics from the text for improved classification decision-making. We utilize GAN for summarization, wherein the generator is trained using the discriminator’s feedback. Therefore, introducing fake summaries to the discriminator can prevent the generator from producing summaries of poor quality. We extract some fabricated and genuine summaries from each document and use them for discriminator training. During training and testing, we generate multiple summaries of each document. Each document enters the generator with a unique set of noises, and the model identifies different and combinations of sentences that result in high-quality summaries. During the test, we input each document into the generator with various noises and use the voting system to compile the final summary. The suggested model automatically learns and extracts complex and significant text representation from the input data using BERT word embedding.
The remaining portions of the paper are organized as follows: Section 2 covers some related works, while Section 3 introduces our proposed text summarization method. Section 4 presents experimental findings and the paper is concluded in Section 5.
Related work
Abstractive summarization techniques, a prominent approach in NLP, strive to generate summaries that go beyond a mere selection and rearrangement of existing sentences or phrases [8]. Instead, abstractive methods aim to comprehend the context of the text and generate new, concise and coherent phrases or sentences that encapsulate the key information and meaning of the original document [34]. The goal of abstractive summarization is to create summaries that are more human-like in their expression and can capture the essence of the source text that is not limited to verbatim extraction. By understanding the underlying semantics, relationships, and nuances of the input document, abstractive techniques have the potential to generate summaries that are more informative, concise, and linguistically fluent. To achieve this, abstractive methods often employ sophisticated approaches, such as neural networks and natural language generation models [35, 36]. These models leverage techniques, such as sequence-to-sequence architectures, attention mechanisms, and reinforcement learning, to generate summaries that are semantically meaningful and coherent. By understanding the context and meaning of the text, abstractive summarization models can paraphrase and rephrase the original content, incorporating new phrases, restructuring sentences, and even generating novel expressions to capture the most salient information. This ability to go beyond the surface-level extraction enables abstractive summarization to produce more concise summaries while maintaining the core meaning of the source text. However, abstractive summarization also presents unique challenges. The generated summaries must balance being concise and informative while ensuring coherence and maintaining the factual accuracy of the original content. Additionally, abstractive methods often require large amounts of training data and complex models to effectively capture the nuances and variations in natural language [37]. Dang et al. [38] proposed an abstractive text summarization method using GANs. The model comprises a generator, two discriminators, and utilizes policy gradient optimization. Vo et al. [39] introduced a semantic-enhanced GAN model for abstractive text summarization. Addressing limitations of RNN-based methods, this approach leverages BERT and graph convolutional networks for improved textual embedding, ensuring coherent summaries. Lin et al. [40] presented the EDA framework, integrating GANs into the Encoder-Decoder architecture for text summarization. By leveraging keyword information and semantic distance, EDA enhances encoding quality and summary precision.
So far, many methods for extractive summarization, including graph-based and deep learning, have been proposed [41, 42]. Moravvej et al. [43] introduced a medical text summarization technique using conditional GANs and convolutional neural networks. The method introduces a unique sentence selection approach, biomedical word embedding, and an improved discriminator loss function. Maleki et al. [44] proposed an innovative extractive summarization technique leveraging generative adversarial networks and attention. By integrating twelve traditional sentence features with Skip-Gram embeddings and employing a novel discriminator loss function, the method effectively discerns high-quality summary sentences. LeClair et al. [45] explored advancements in code summarization techniques through the application of Graph Neural Network (GNN), which contributes to the generation of insightful summaries from input documents, enhancing the overall effectiveness of code summarization. Zhong et al. [46] made the document word features and then calculated the scores of the sentences using the scores of its words. Yousefi et al. [47] used cosine similarity between sentences and subjects to score sentences. Cao et al. [48] used recurrent neural networks to rank sentences. They considered each sentence as a tree where the words are on the leaves, and the sentence is at the root. The score of each sentence is obtained from the leaves based on a non-linear process. Rosca et al. [49] used reinforcement learning to summarize. In this work, the coherence between sentences is considered a reward. The policy is implemented as a multilayer perceptron that assigns a score to each sentence. Abdi et al. [50] presented a deep learning approach aimed at generating opinion-oriented summaries for multiple documents. The method involves the utilization of various components, namely sentiment analysis embedding space (SAS), text summarization embedding spaces (TSS), and an opinion summarizer module (OSM). To capture sequential information and overcome limitations of previous techniques, SAS employs a recurrent neural network (RNN) based on long short-term memory (LSTM). TSS incorporates statistical and linguistic knowledge factors to enhance word-level embedding and extract representations. Fitrianah and Jauhari [51] explored a similar approach for ETS summarization, utilizing LSTM and GRU models. They employed feature engineering techniques to extract meaning from the input document and generate meaningful summaries. Hin et al. [52] introduced LineVD, a deep learning architecture that focuses on identifying vulnerabilities at the statement level using a Graph Neural Network (GNN). Notably, LineVD achieves improved prediction performance by excluding vulnerability status from its analysis. Nallapati et al. [53] introduced a model called Summarunner for extraction summarization based on RNN networks. They used two RNN layers to embed words and sentences. Then, they employed logistic regression to classify sentences. Kobayashi et al. [54] suggested a summarization technique based on embeddings and document level similarities. The embedding of a word serves as a representation of its meaning. A sentence is regarded as a bag of words; a document is a bag of sentences. The goal is defined as optimizing a sub-modular function supplied by the sum of the nearest neighbor distances on embedding distributions. Chen et al. [55] suggested a deep reinforcement learning method and encoder-extractor architecture for a single-document summarization. The summary sentences are then extracted once the key features are selected using a sentence-level selective encoding system. Mikael et al. [56] used continuous vector representations in RNN and got the best outcome on the Opinosis dataset. A unique sentence selection approach was used by Yin et al. [57] to balance sentence prestige and variety after developing an unsupervised CNN for learning phrase representations.
The processing of natural languages has recently undergone a revolution thanks to BERT. BERT, a transformer-based model, has significantly advanced the field of NLP by introducing a contextual understanding of words and sentences. Unlike previous models that processed sentences in a unidirectional manner, BERT considers both the preceding and the following words, capturing a deeper understanding of the contextual dependencies within the text. This bidirectional approach allows BERT to generate word representations that are more meaningful and representative of their usage in specific contexts. The utilization of BERT has led to remarkable improvements in various NLP tasks, including text classification, named entity recognition, sentiment analysis, and, importantly, text summarization. By incorporating BERT into text summarization frameworks, researchers have achieved more accurate and contextually informed summaries. The ability of BERT to grasp the nuances of language and generate comprehensive representations has revolutionized the way we process and understand natural languages, enabling the development of more sophisticated and effective NLP applications. As BERT continues to inspire advancements in language modeling and understanding, it holds immense potential for further transforming the field of natural language processing. Koto et al. [58] presented document-level discourse probing techniques, which were employed to identify relations between documents and evaluate the performance of pre-trained language models. They utilized BERT, BART, and RoBERT as models to assess the results obtained from their evaluation. Abdel-Salam and Rafea [59] conducted a study to evaluate the performance of different variants of BERT-based models for text summarization. They proposed an unsupervised approach for extractive multi-document summarization, leveraging transfer learning from the BERT sentence embedding model. The researchers fine-tuned the BERT model using supervised intermediate tasks from GLUE benchmark datasets, employing single-task and multi-task fine-tuning methods to enhance sentence representation learning. Srikanth et al. [60] employed the BERT model to generate extractive summaries by clustering sentence embeddings using K-means clustering. Additionally, they introduced a dynamic method to determine the appropriate number of sentences to select from the clusters.
Most previous deep learning approaches encounter a limitation in their sentence selection process, where they are overly focused on selecting the highest-scoring sentence without considering its relevance in subsequent sentence selection. This approach leads to a decrease in the overall quality of the generated summary.
Architecture of the proposed approach
The proposed model’s structure, illustrated in Figs. 1 and 2, provides a clear representation of its architecture and flow. When presented with a document D = [s1, s2, . . . , sN] as input, where each si represents the i-th sentence, and N represents the maximum number of sentences in the document; the model passes this input through the BERT model. The outcome is an embedding matrix E = [e1 ; e2 ; … ; e n ], with each ei corresponding to the embedding of a sentence si. To extract meaningful features from these sentence embeddings, the model employs three parallel dilated convolution layers. Each branch of the convolution layers independently processes its respective sentence and extracts a feature vector. Subsequently, through the utilization of max pooling, the model acquires rich features from the convolution process, simplifying the computational complexity of the network. Moving on to the generator network, the output of the pooling layer connects with the noise vector and enters a feed-forward neural network. Within this network, the final layer computes the probability vector [p1, p2, . . . , pN], representing the likelihood of each sentence’s inclusion in the summary. By introducing noise, the generator can generate diverse outputs. Through multiple iterations and varying noise inputs, each document is summarized in different ways while maintaining a comparable level of quality. This approach allows the generator to explore various combinations of sentences suitable for the summary. Consequently, sentences that may not individually contribute significantly to the summary can still enhance their overall quality when strategically placed alongside other sentences. In the discriminator network, the probability vector of sentences is contacted with the representation vector of the document (see Fig. 2). In this context, the probability vector of sentences is the vector of the number of sentences in a document, and each element is zero or one.
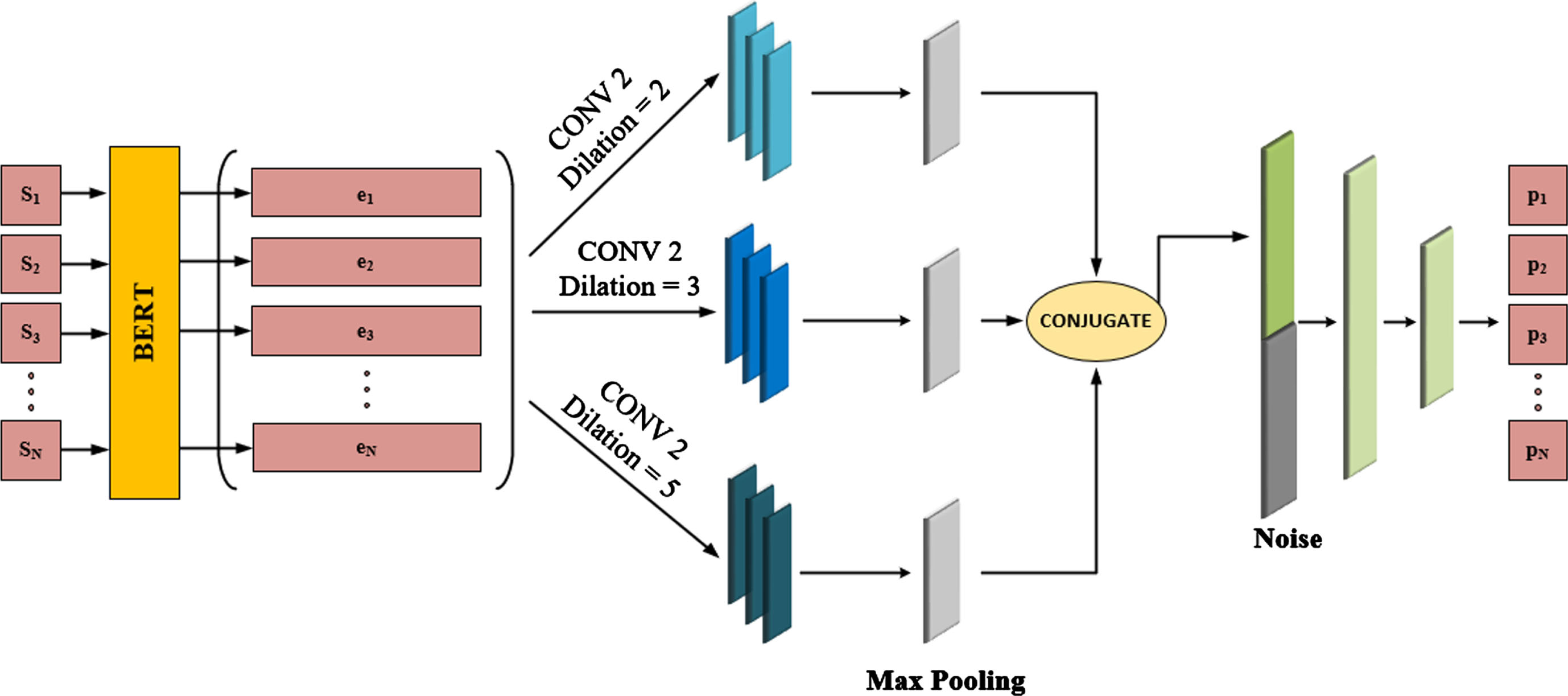
Overall architecture of the proposed generator.
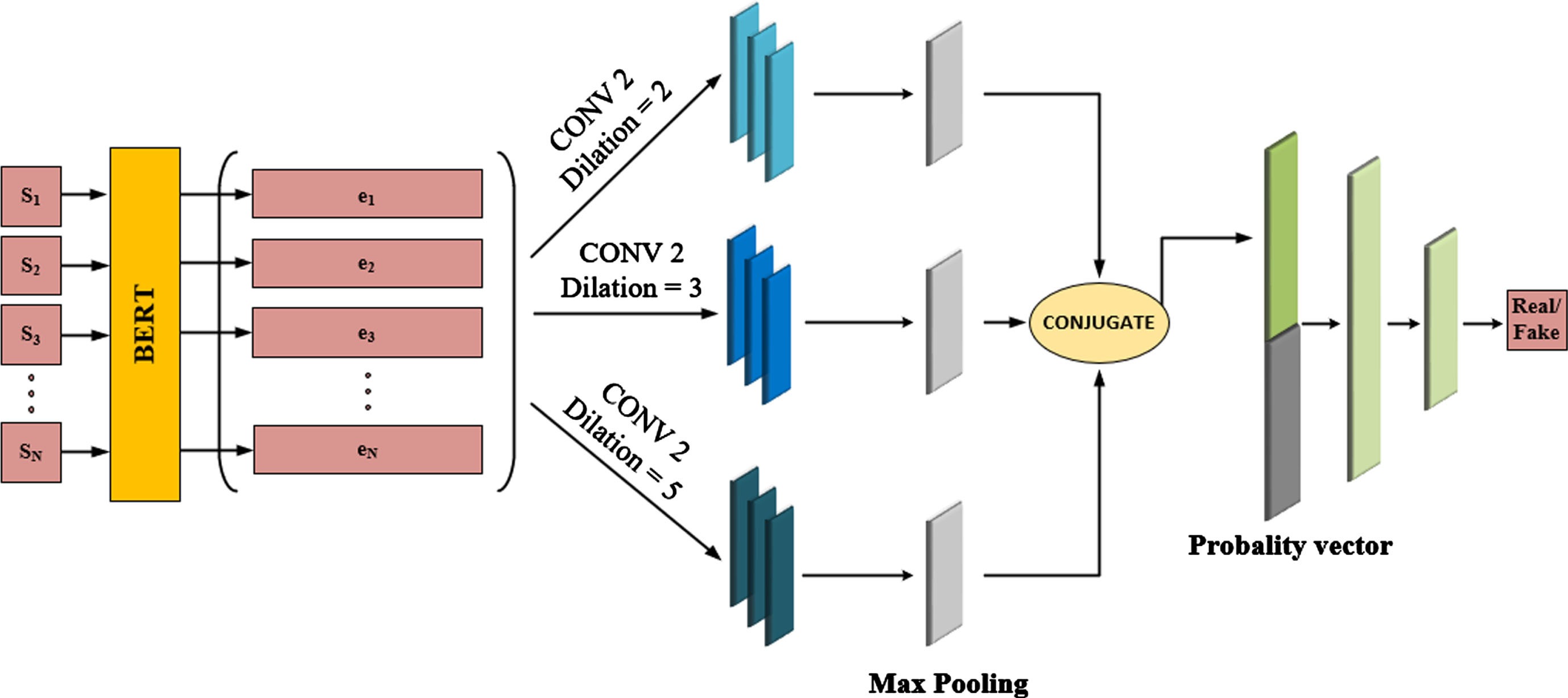
Overall architecture of the proposed discriminator.
The loss function for the generator in the proposed model is defined as follows:
In Equation 1, the term Data represents a collection of documents, y
i
represents the features of sentences in document i, and E denotes the mathematical expectation. The loss function for the discriminator considers the generator output, real summaries, and fake summaries:
Here, p Real i and p Fake i represent the distributions of real and fake summaries for document i. The objective of this equation is to train the discriminator to distinguish between high-quality and low-quality summaries effectively. By doing so, the discriminator becomes sensitive to the summaries generated by the generator and encourages the generator to produce high-quality summaries. Throughout the training process, Equation 2 is optimized to assign values of one and zero to actual and fake examples, respectively, allowing the discriminator to learn to discern between real and generated summaries accurately. The generator, on the other hand, receives feedback signals from the discriminator and strives to approximate the actual data distribution. It learns to adjust its parameters and generate summaries that closely match the quality and characteristics of real summaries. By iteratively updating the discriminator and generator, the GAN model progressively improves the quality of the generated summaries. The discriminator’s ability to discriminate between real and fake summaries helps guide the generator towards producing more convincing and high-quality summaries. As the training progresses, the generator becomes increasingly adept at capturing the underlying patterns and structure of the input data, resulting in more realistic and coherent summaries that closely resemble those generated by human au.
Within the framework of the general generative adversarial network, the generator’s output plays a crucial role as synthetic data for training the discriminator. In addition, a real target is extracted for each sample. In this study, multiple summaries of comparable quality are selected from each document to introduce high-quality summaries to the discriminator. However, subpar summaries are also generated for the document. Since the original summaries of the document are in text format and unsuitable as targets, a numerical representation is necessary to indicate the presence or absence of each sentence in a summary. To accomplish this, a vector with N elements is defined, where N represents the total number of sentences in each document. The vector’s elements are binary, taking the values of zero or one, where one signifies the inclusion of a sentence in the summary. Initially, a vector of length N with M ones is obtained, with M denoting the number of summary sentences. The ones in the vector are randomly distributed. The quality of the generated summary is evaluated using the ROUGE measure, which involves grouping the statements in the vector that have a value of one. The ROUGE score is updated by randomly swapping ones with zeros and vice versa. If the updated ROUGE score surpasses the previous one, the new vector replaces the previous one. This process is repeated Itr times, with the best vector from each iteration serving as the output. It’s important to note that the algorithm needs to start from the beginning in order to generate an actual target. The procedure for creating a false target follows a similar process, except that if the ROUGE score is lower, the vector replaces the previous one. To maintain consistency, all documents are constrained to a length of N sentences. Longer texts exceeding N sentences are trimmed, while shorter documents are zero-padded to match the desired length.
Results and model comparisons
In this section, we delve into the detailed results obtained from our experimental evaluations. We divide our results into three primary areas: overall performance, effects of noise on the performance of generator, and word embedding analysis.
Overall performance
We conducted a comprehensive comparison between the suggested approach and several existing methods, including both graph-based and deep-learning approaches. The graph-based methods we evaluated were BGSumm [61], TextRank [62], EdgeSumm [63], BiGram-PageRank [19], and MG-GNNES [21], while the deep learning methods included SummaRunner [53], RENS [64], SHA-NN [65], HSSAS [66], T5 [67], BART [68], and SS-HES [6]. The evaluation results of our proposed system on the CNN/Daily Mail dataset are depicted in Fig. 4. Notably, the BiGram-PageRank model showed significant superiority over other graph-based models, including MG-GNNES, across all evaluation criteria. Specifically, it achieved a remarkable reduction in errors of over 20%, 22%, and 31% for the R-1, R-2, and R-L metrics, respectively. Interestingly, while BGSumm showed promising results on a medical dataset, it failed to deliver satisfactory performance on the CNN/Daily Mail dataset. In contrast, our suggested model outperformed the BiGram-PageRank model, achieving a substantial error improvement rate of approximately 24.70%, 26.40%, and 28.41% for the R-1, R-2, and R-L metrics, respectively. As expected, the deep learning methods exhibited clear superiority over the graph-based algorithms, which highlights the power of deep learning in natural language processing tasks. However, even when considering sentence coherence, the RENS method fell short in terms of accuracy compared to our proposed model. Among the deep learning-based models, SS-HES demonstrated the highest performance. However, it still exhibited a weakness of 21%, 22%, and 27% when compared to our proposed model, further affirming the effectiveness and superiority of our approach in summarization tasks.

Flowchart of generating an actual summary for a document.
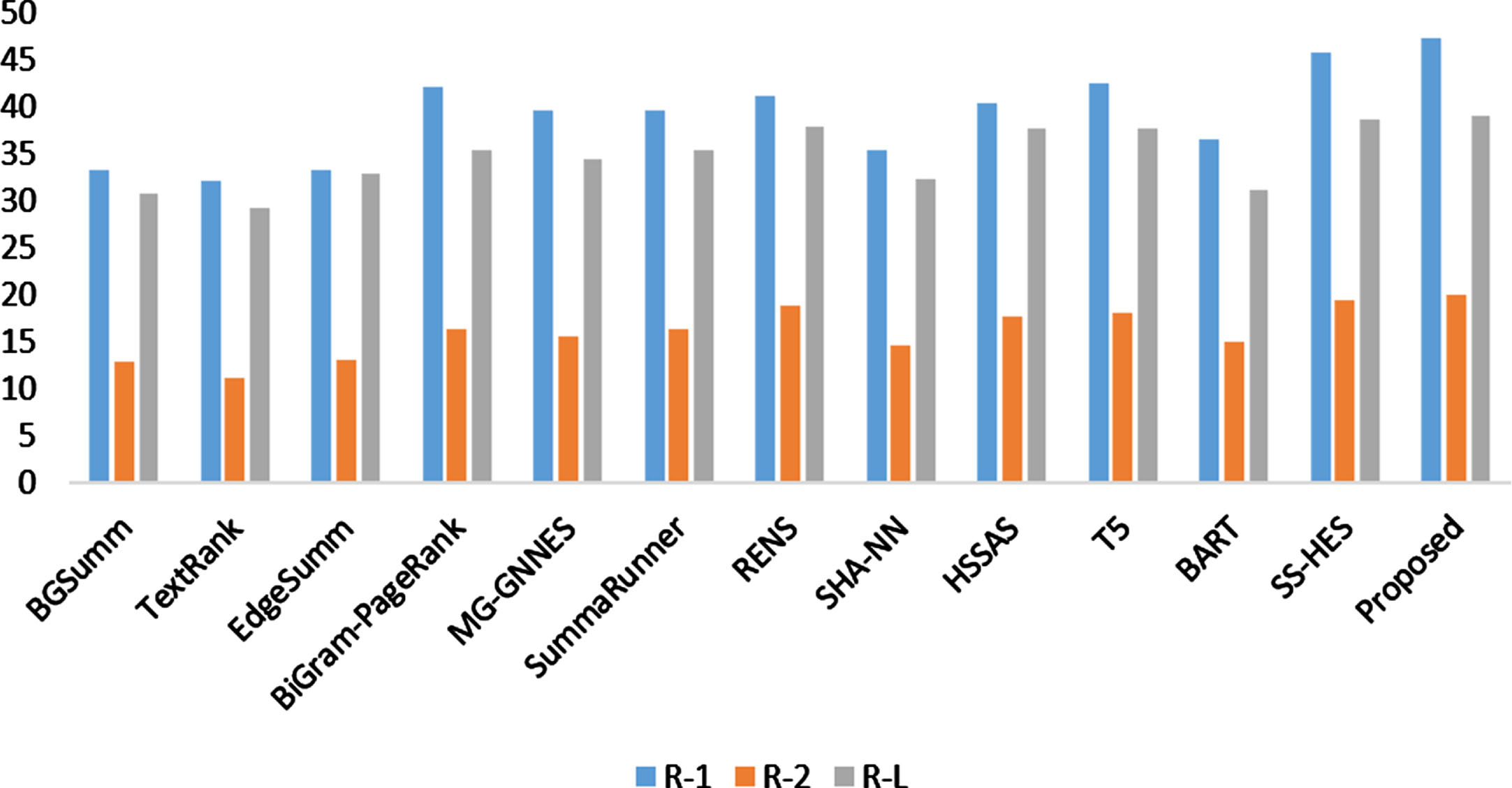
Quantitative evaluation of the suggested approach and state-of-art methods using the CNN/Daily Mail dataset.
In order to delve deeper into the behavior of the generator in the presence of noise, further investigations were conducted. This research aimed to assess how different levels of noise affect the generator’s performance. By introducing varying magnitudes of noise, we could observe the outcomes in terms of the R-1, R-2, and R-L evaluation criteria for both datasets. These results have been visually represented in Fig. 5, providing a clear comparison. Analyzing the CNN/Daily Mail corpus, we observed an interesting pattern. Initially, as the noise size increased to 70, there was a corresponding improvement in the R-1, R-2, and R-L scores. This suggests that a moderate level of noise introduced to the generator can enhance its performance to generate summaries. However, beyond the noise size of 70, we noticed a decreasing trend in the evaluation metrics. This implies that excessively high levels of noise could negatively impact the generator’s ability to generate accurate and coherent summaries. The findings highlight the significance of noise in the performance of the suggested model. The presence of noise, up to a certain magnitude, seems to stimulate the generator, resulting in improved summary generation. However, it is crucial to strike a balance, as excessive noise can hinder the model’s effectiveness. Thus, the suggested model showed its superior performance when noise is appropriately introduced, optimizing its summarization capabilities.
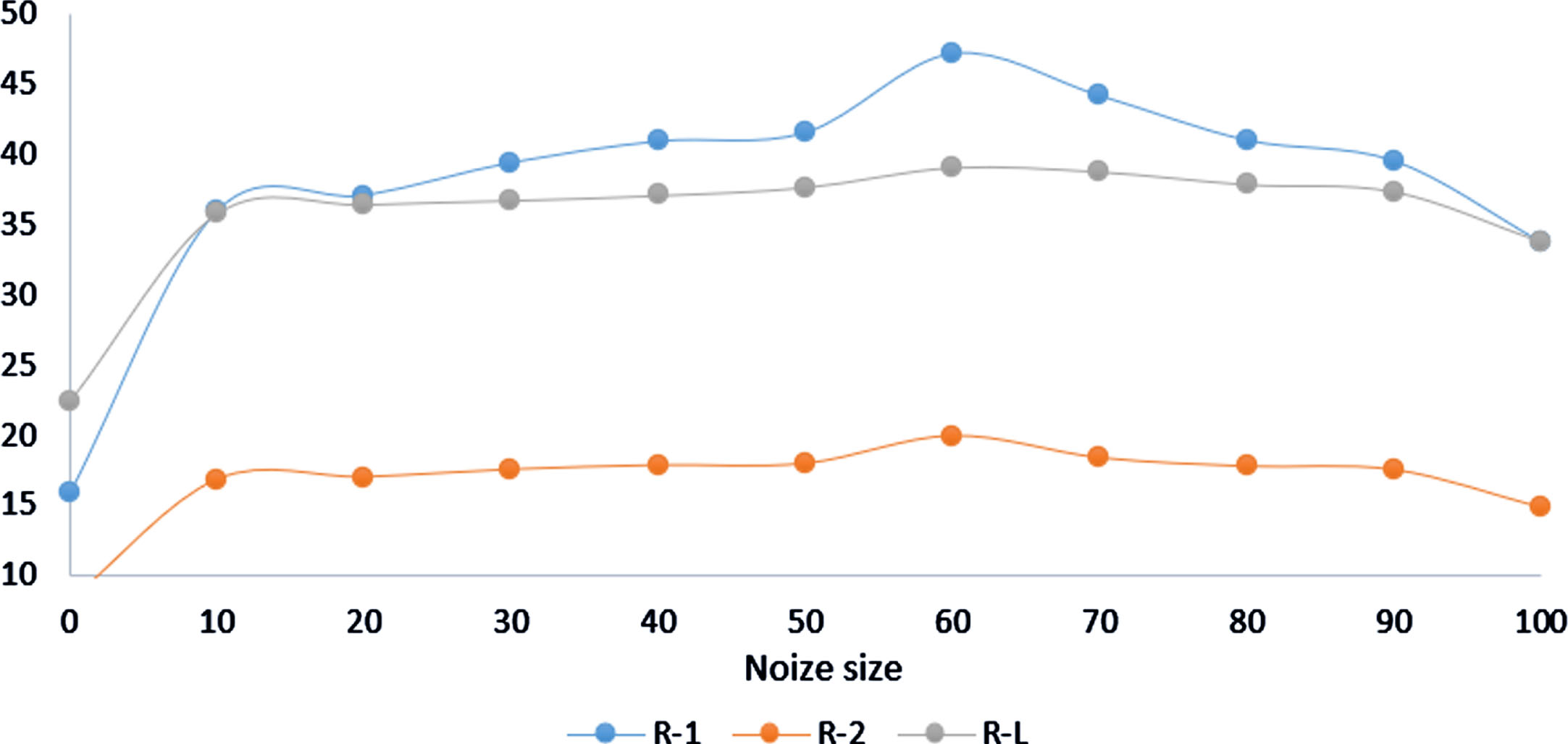
Outcome measurements of the proposed model under various noise conditions using the CNN/Daily Mail dataset.
Word embedding plays a critical role in deep models as it allows input to be represented as vectors, and incorrect embeddings can lead to misinterpretation by the model. To ensure accurate embedding, we employed the innovative BERT model in our research. Additionally, we conducted a comparative analysis of various word embeddings, including One-Hot encoding, CBOW, Skipgram, GloVe, and FastText [22], alongside our suggested model. The results of this investigation are visually presented in Fig. 6. Among the different word embedding techniques, One-Hot encoding demonstrated the poorest performance on the CNN/Daily Mail dataset. However, the proposed model showcased significant improvements, with success rates of approximately 32% and 35% over One-Hot encoding. Notably, CBOW and Skip-gram exhibited similar performance, both surpassing GloVe in terms of accuracy. Interestingly, the FastText model emerged as the top performer among the evaluated embeddings, showcasing excellent word embedding capabilities, even though its effectiveness when combined with BERT was slightly diminished. The utilization of BERT as the word embedding technique led to an impressive 9% reduction in error on the CNN/Daily Mail dataset. This outcome underscores the substantial impact of BERT on enhancing the performance of the proposed model in summarization tasks. By leveraging the power of BERT’s advanced word embeddings, our model achieved superior accuracy and showed its effectiveness in generating high-quality summaries.

Quantitative evaluation of various word embedding using the CNN/Daily Mail dataset.
This article presented a novel and effective strategy for extractive text summarization by combining several techniques. The proposed method integrated a GAN-based approach, BERT word embedding, and dilated convolution layers. To enable effective summarization, the method employed a generator and discriminator within the GAN framework. The generator evaluated the likelihood of each sentence in the summary, while the discriminator assessed the quality of the generated summary. This GAN framework enabled the generator to explore diverse sentence combinations, leading to the production of high-quality summaries. In order to capture a broader context and incorporate long-range dependencies, the method introduced three dilated convolution layers in both the generator and the discriminator. By introducing gaps between filter weights, the dilated convolution expanded the receptive field, enabling the model to consider a wider range of words in the context.
The article claims the superiority of the proposed model based on performance results measured using the ROUGE metric on the CNN/Daily Mail dataset. However, the evaluation is limited to a single dataset, and it is unclear how the proposed model would perform on other diverse datasets. Further evaluation of multiple datasets could provide a more comprehensive understanding of the model’s effectiveness. The evaluation of the proposed model is solely conducted on the CNN/Daily Mail dataset, which may introduce dataset bias. The dataset selection should be justified, and the generalizability of the proposed model across diverse datasets should be explored. Different datasets may have variations in language style, domain, and content, which can impact the summarization performance. Evaluating the model from multiple datasets would provide a more comprehensive understanding of its effectiveness.
Moreover, Transfer learning approaches could augment the performance of the model. Transfer learning is an effective method that allows models to use information gained from one domain to enhance performance in another. By giving the model a pre-training with a considerable amount of data from a related domain, the model can learn to extract useful features and patterns relevant to the target task. This can drastically lower the quantity of training data needed for the target task and improve the model’s accuracy and robustness.
Assessing the performance of additional BERT variants, such as RoBERTa, ELECTRA, and ALBERT, and comparing their efficiency and effectiveness with DistilBERT, offers an intriguing research direction. RoBERTa, ELECTRA, and ALBERT represent some of the most recent advancements based on the BERT model, having demonstrated considerable improvements over the initial BERT version. Future work could involve exploring these models’ performance in the proposed text summarization task, allowing for a comparison of their efficiency and effectiveness against DistilBERT, which may reveal the most suitable model for this task. Additionally, it could be fruitful to consider other pre-trained language models, like GPT-3 and T5, for text summarization and compare their performance with BERT-based models. Examining the proficiency of various pre-trained language models, such as GPT-3 and T5, in text summarization tasks could yield valuable insights regarding their appropriateness for this application. GPT-3, a transformer-based language model, has been trained on an extensive corpus of diverse texts, and it has demonstrated notable results across a range of natural language processing tasks. Conversely, T5 is a text-to-text transformer model that can be fine-tuned for a variety of tasks, including text classification and sequence labeling.
Conclusion
This paper presented a novel approach to extractive summarization by combining a GAN method with BERT word embedding. Our proposed method utilized a GAN framework consisting of a generator and discriminator. The generator assessed the likelihood of each sentence’s inclusion in the summary, while the discriminator evaluated the quality of the generated summary. To extract meaningful features simultaneously, we incorporated three dilated convolution layers in the generator and discriminator. By employing dilated convolution, we captured a broader context and incorporated long-range dependencies. To encourage the generator to explore diverse sentence combinations and generate high-quality summaries, we introduced various noises to each document within our GAN framework. This allowed the generator to learn from a range of sentence permutations and select the most suitable ones for the summary generation process. To evaluate the performance of our proposed model, we conducted experiments using the CNN/Daily Mail dataset. The results, measured using the ROUGE metric, demonstrated the superior performance of our approach compared to other methods tested in the evaluation.
In future work, we will recognize the importance of coherence in generating high-quality summaries that accurately reflect the original text. We will explore different strategies to incorporate coherence effectively. One promising avenue for enhancing coherence is to consider it during the construction of the target summaries. By taking coherence into account during the summary generation process, we can ensure that the selected sentences flow smoothly and coherently, creating a more cohesive and readable summary. Additionally, we will consider the option of integrating coherence as a loss function within the generator. By incorporating coherence as a measure of success or accuracy, we can guide the generator towards generating summaries that maintain a coherent structure and logical progression of ideas. This approach will encourage the model to prioritize coherence while generating summaries, resulting in more coherent and well-structured outputs. By addressing the challenge of coherence, we aim further to elevate the quality and coherence of the generated summaries.