
Abstract
In response to key challenges in urban traffic management, especially in ensuring compliance with traffic regulations, this paper proposes an Packet Grey Wolf Optimization (PGWO) algorithm designed to improve prediction accuracy and enforcement efficiency in traffic violations. By introducing a momentum coefficient, a grouping position update strategy, and a reverse learning mechanism, the PGWO algorithm significantly improves global search capability and convergence speed, effectively avoiding early convergence to a local optimum. Taking the accurate identification of traffic violations as the core issue, this study applies PGWO algorithm to the traffic violation prediction model based on the Stanford Open Policing Project dataset. By comparing and analyzing the original Grey Wolf Optimization algorithm and other traditional optimization algorithms, PGWO showed excellent performance in improving the accuracy of traffic violation arrest. In addition, the PGWO algorithm has been integrated into the PNN regression prediction model, and its effectiveness and superiority in the field of traffic laws have been further verified through testing on the Kaggle dataset. The experimental results demonstrate that the PGWO algorithm not only achieves greater accuracy in predicting traffic violations but also enhances the model’s generalization ability, providing a new optimization strategy and decision support tool for intelligent traffic management and regulatory compliance.
Keywords
Introduction
In modern urban traffic management, ensuring road safety, improving traffic flow efficiency, and strengthening compliance with traffic laws are key challenges. Technological innovation, especially in intelligent transportation systems and data-driven traffic management, plays a vital role in enhancing traffic safety and management efficiency. 1 Accurate identification and enforcement of traffic violations are crucial for maintaining road order and reducing accident risks. 2 However, traditional traffic enforcement methods struggle to meet the growing demand for regulatory compliance as traffic networks expand and the number of vehicles increases.
Enforcing traffic laws involves complex issues related to legal justice, social equity, public safety, efficiency, and public trust. 3 For example, racial and gender disparities in traffic stops can lead to unequal treatment, violating the principle of equality before the law and raising questions about enforcement transparency and fairness. Additionally, inefficient traffic stops waste valuable resources, cause congestion, and reduce public satisfaction with law enforcement. 4 With technological advancements, 执法 agencies now collect large amounts of traffic stop data. Effectively processing and analyzing this data to support policy-making has become a new challenge.
To address these issues, an integrated and multidisciplinary approach is necessary. By introducing advanced optimization algorithms and combining them with data analysis techniques, we can improve the efficiency and fairness of traffic law enforcement, enhance public trust in enforcement agencies, and contribute to overall traffic safety and justice.
Grey Wolf Optimization (GWO) algorithms have been widely used in engineering optimization, including applications in traffic signal timing optimization and vehicle route planning.5,6 These studies offer valuable insights for traffic management but leave gaps in data-driven traffic violation prediction models, especially under dynamic traffic conditions and regulatory compliance requirements. Existing research also has room to improve algorithm adaptability and flexibility in changing traffic environments.7–9
Recent studies, such as the spherical decision-making model for measuring drivers’ behavior factors 10 and the use of autonomous vehicles in mixed traffic for incident management,11–13 highlight the importance of integrating advanced algorithms with traffic data analysis. These works inspire our approach to leveraging the GWO algorithm for traffic violation prediction.
This study proposes an innovative Grey Wolf Optimization algorithm based on a packet location strategy. The new algorithm enhances global search capability and quickly finds approximate optimal solutions through an efficient convergence mechanism. By analyzing the basic principles of the Grey Wolf Optimization algorithm and introducing a group location update strategy, we improve the algorithm’s adaptability to meet the demands of high-precision traffic violation monitoring. Case studies and simulation experiments demonstrate the adaptability and flexibility of the proposed PGWO algorithm in different traffic scenarios. Currently, the main focus is on analyzing and predicting existing collected data, with real-time data processing planned for future research.
Grey Wolf Optimization algorithm
Basic principles
Grey Wolf Optimization (GWO) is a heuristic optimization algorithm based on simulating Grey Wolf group behavior. Grey Wolf packs are divided into Alpha (leader), Beta (deputy leader), Delta (patrol), and other members of the pack (Omega). These roles represent the optimal and sub-optimal solutions within the search space. The fundamental concept of the algorithm is inspired by the social structure of Grey wolves, specifically their cooperative and competitive behaviors, as illustrated in Figure 1. Social structure of the Grey Wolf.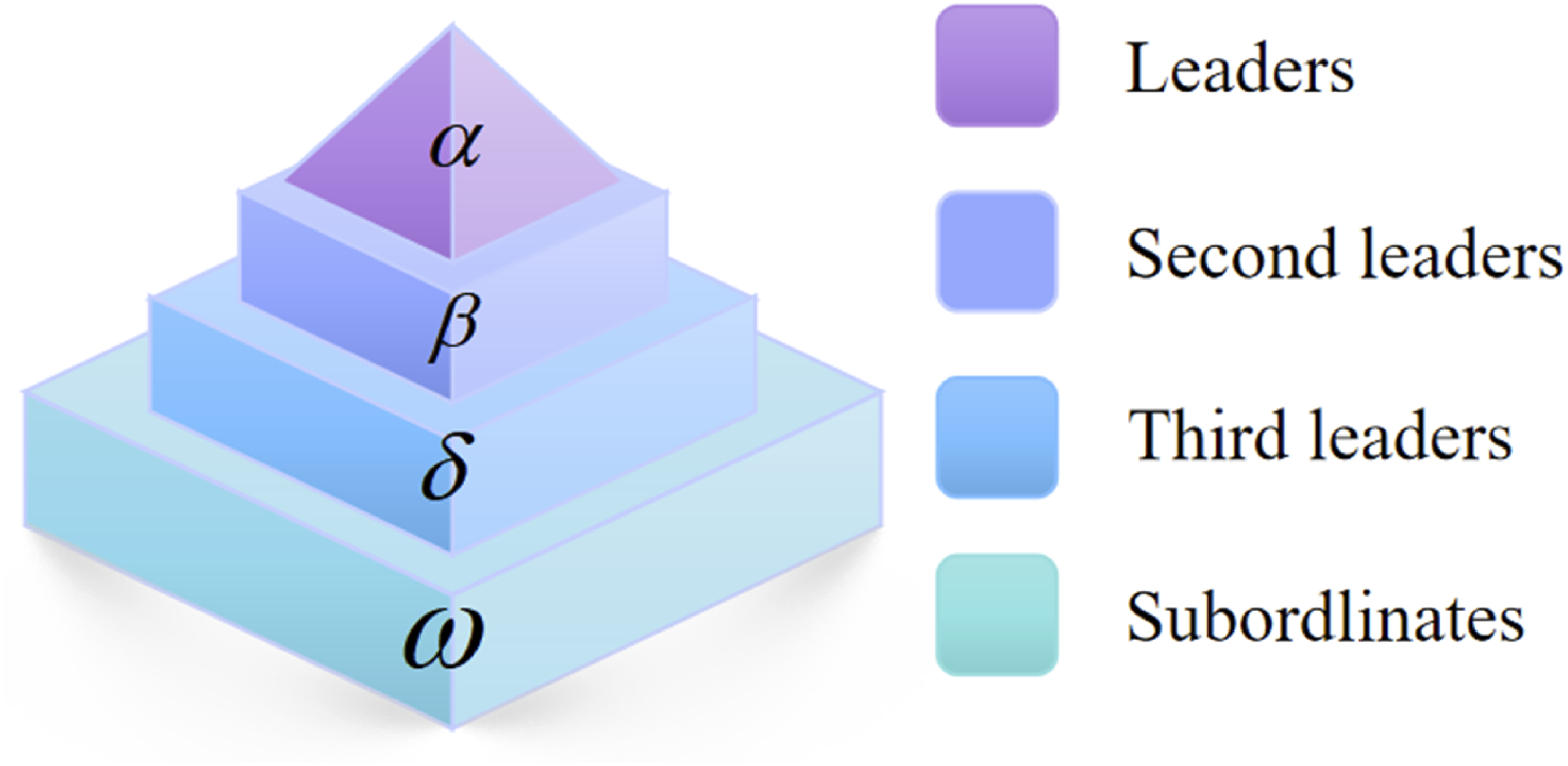
As depicted in Figure 1, the social hierarchy of Grey wolves comprises four distinct roles:
The updating process of the algorithm includes three stages: detection, tracking, and attack. Through iterative refinement, the Grey Wolf Optimization algorithm drives the Grey Wolf population to gradually converge toward the optimal solution within the solution space. Ultimately, it identifies an approximate optimal solution by simulating the coordinated behaviors of grey wolves, thus completing the global search process.
Algorithmic formula
In the first stage, in the process of encircling prey, the behavior of Grey wolves rounding up prey is defined as


Formula (1) represents the distance between the Grey Wolf and the prey, while formula (2) denotes the position update formula for the Grey Wolf. In these formula, t represents the current number of iterations.


In the second stage, during the hunt, the Wolf Schematic diagram of Grey Wolf Optimization algorithm.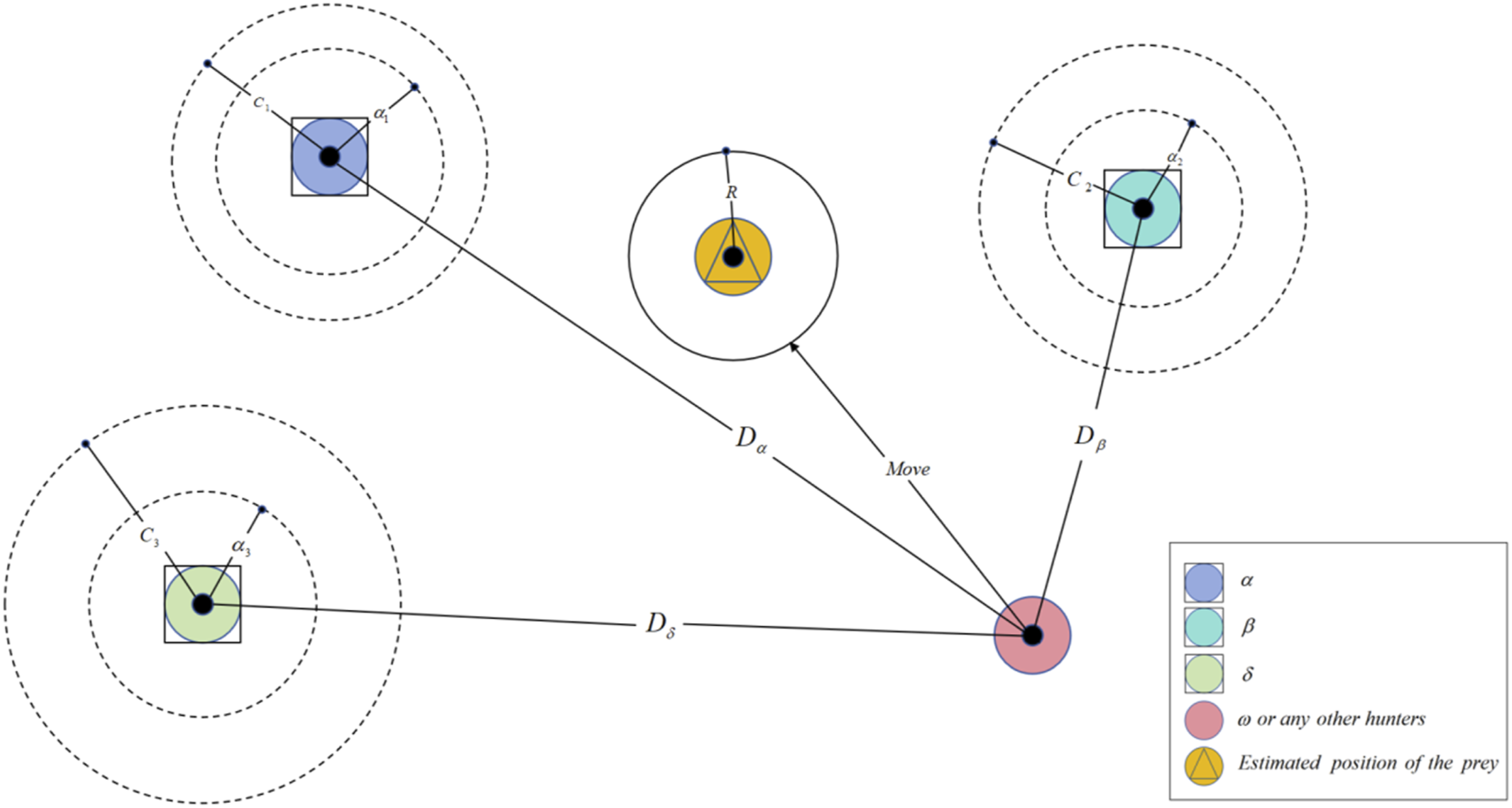
The mathematical model of individual Grey Wolf tracking prey is described as follows:







Equations (8)–(10), respectively, define the step size and direction of the individual
Application areas
The Grey Wolf Optimization algorithm is a swarm intelligence-based optimization technique inspired by the collective behavior of grey wolves in nature. It has found successful applications in various domains, with engineering optimization being one of its prominent applications. In engineering optimization, the Grey Wolf Optimization algorithm is extensively utilized to tackle intricate optimization challenges, including structural optimization, parameter optimization, control optimization, and more.
In the realm of structural optimization, the Grey Wolf Optimization algorithm finds utility in optimizing the design of diverse engineering structures, encompassing bridges, buildings, aircraft, automobiles, and more. Leveraging the Grey Wolf Optimization algorithm facilitates achieving the optimal design of these structures to fulfill particular performance specifications and constraints, such as minimizing weight, maximizing strength, minimizing cost, and so forth. This optimization method can greatly improve the performance and efficiency of engineering structures. 14 In terms of parameter optimization, the Grey Wolf Optimization algorithm can be used to adjust the parameters of complex systems to maximize or minimize certain performance indicators of the system. For example, in the field of machine learning and artificial intelligence, Grey Wolf Optimization algorithms can be used to adjust the parameters of neural networks to improve the accuracy and generalization ability of models. 15 In industrial production, the Grey Wolf Optimization algorithm can also be used to optimize parameters of the production process to improve production efficiency and reduce costs. 16 In addition, by adjusting the parameters of the control system, the Grey Wolf Optimization algorithm can attain optimal control of a system to fulfill specific performance metrics and control criteria.. 17 This has important application value in the fields of automation control, robotics, intelligent transportation, and so on.
However, although the Grey Wolf Optimization algorithm has shown great potential in several domains, it still faces a number of challenges when dealing with specific types of complex and dynamic problems, such as real-time traffic violation prediction. These include maintaining search efficiency and accuracy in rapidly changing environments, and balancing different performance metrics in multi-objective optimization problems. To overcome these challenges, this essay proposed an improved Grey Wolf Optimization algorithm (PGWO), which significantly improves the performance of the algorithm in dynamic and multi-objective optimization problems by introducing advanced search mechanisms and adaptive strategies.
The improved algorithm is innovative in the following ways. (1) Improvements in momentum coefficients incorporate the difference between individual and globally optimal adaptations. (2) Introducing the idea of grouped location update, which makes the location update of individuals more diversified and global search capability. (3) The update of the position of the optimal individual is achieved by calculating the difference in position between the current optimal individual and a random individual and introducing a random binomial distribution term.
Details of the improvements will be detailed in the next chapter.
Grey Wolf Optimization algorithm based on packet location update strategy
Momentum coefficient
The introduction of the momentum coefficient aims to balance the local and global search capabilities within the algorithm’s search process. Through dynamically adjusting this coefficient, the algorithm enhances its search capability, rendering it more flexible and effective in exploration.
Firstly, as formula (12) by calculating the difference between individual fitness and global optimal fitness, the parameter u indicating the search direction is obtained. This parameter u reflects the degree to which the individual position deviates from the global optimal position.

The difference in fitness is mapped to the weighted parameter u by an exponential function, so that the momentum coefficient can be dynamically adjusted according to the difference between individual fitness and global optimal fitness. Such a dynamic adjustment mechanism enables individuals to adjust their movement direction more flexibly and search more pertinently during the search process, thus improving the efficiency and accuracy of the search.
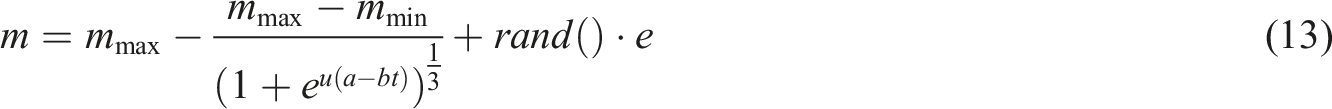
Secondly, the momentum coefficient adjustment also takes into account the iteration t of the algorithm. As formula (13) by introducing parameters a and b, the adjustment process of momentum coefficient is smoother and more continuous. This can prevent the momentum coefficient from changing drastically during the search process, consequently, this enhancement contributes to improving the stability and convergence speed of the algorithm. Especially when the search enters the later stage, by gradually reducing the change rate of the momentum coefficient, it helps the algorithm to be more focused on facilitating global exploration while mitigating premature convergence to local optima. When calculating the new position, the momentum coefficient parameter m is used to adjust the individual position in the specified direction. At the same time, random factors are introduced. By multiplying with the current position, the position updates are more diversified, resulting in faster convergence toward the global optimal solution.
To sum up, the improvement of the momentum coefficient combines the difference between individual fitness and global optimal fitness, as well as the consideration of the number of iterations t, to realize the dynamic adjustment of the direction of individual motion. This improvement makes the algorithm have better convergence speed, search accuracy and global search ability when solving optimization problems, and improves the practicability and adaptability of the algorithm.
Location update
In the original Grey Wolf Optimization algorithm, the position update for each individual is based solely on the leader wolf’s position. However, this approach may trap individuals around local optima, inhibiting exploration beyond these regions. 18 To address this limitation, the concept of group-based position updates is introduced, enhancing diversity and global search capability. This improvement diversifies individual movements, facilitating exploration across the search space. Consequently, it enables the algorithm to escape local optima more effectively and explore various regions, thereby enhancing its global search capability.
Firstly, dividing the population into three groups for location updates enhances population diversity and global search capability. Each group experiences distinct influences during location updates, leading to a more diverse population. This diversity in location updates prevents the population from becoming trapped in local optima, thereby improving the algorithm’s global search capability.
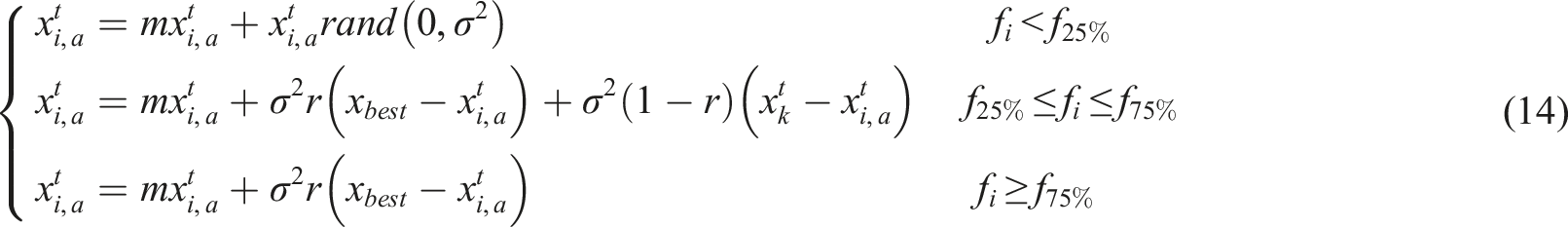
As expressed in equation (14), the position information is denoted by
Secondly, The grouped position update strategy effectively speeds up the search process of the algorithm by grouping individuals proportionally and adopting different update strategies for individuals within each group. This approach allows the algorithm to converge to the global optimal solution faster in each iteration, significantly reducing the search time and improving the search efficiency. When
The selection of the 25% and 75% thresholds for group division is grounded in both behavioral ecology principles and empirical optimization performance. In natural Grey Wolf packs, field studies indicate that leadership hierarchies typically follow a power-law distribution where approximately 20%–30% of the pack (alpha, beta, and key delta wolves) direct collective hunting strategies, while the remaining 70%–80% execute coordinated actions under guidance. Our 25% elite group threshold aligns with observed proportions of decision-makers in wolf packs, ensuring sufficient leadership density to guide exploitation without premature convergence. The 75% intermediate group upper bound (representing elite + middle groups) corresponds to the empirically documented participation rate in cooperative hunts, balancing exploration breadth with computational efficiency.
To encapsulate the essence, the strategy of updating positions in groups emerges as a potent optimization technique. It notably enhances the algorithm’s capacity for extensive search, operational efficiency, and overall robustness along with stability. By segmenting the population and applying distinct updating mechanisms, the algorithm becomes more adept at tackling intricate optimization challenges and homes in on the optimal solution with greater swiftness. Consequently, this approach holds substantial value in practical scenarios, significantly amplifying the algorithm’s problem-solving prowess across a spectrum of optimization tasks.
Reverse learning
Reverse learning updates the position of the optimal individual by calculating the position difference between the current optimal individual and the random individual and introducing a random binomial distribution term. This updating method shown as equation (15) enables the optimal individual to search in more unexplored directions.
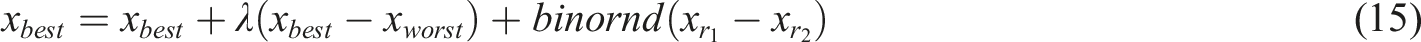
The traditional Grey Wolf Optimization algorithm may be constrained by local optimal solutions and is difficult to jump out of. 19 After the introduction of reverse learning, the optimal individual can search more widely according to the influence of randomness when updating the position, which is helpful to jump out of the local optimal solution and improve the global search ability of the algorithm. The random binomial distribution term in the reverse learning mechanism serves as a catalyst for exploration, introducing an element of randomness to the update of the optimal individual’s position. By calculating the difference with a random individual and incorporating this term, the algorithm encourages the optimal individual to venture into less explored regions of the solution space. This not only diversifies the search, enhancing the global optimization capability, but also helps in avoiding local optima by preventing the algorithm from converging prematurely. Essentially, the term acts as a random exploratory force that keeps the search dynamic and robust, ensuring that the algorithm remains adaptable and responsive to new information throughout the optimization process.
In conclusion, the incorporation of the reverse learning mechanism represents a crucial enhancement of the Grey Wolf Optimization algorithm, substantially enhancing its global search capability, adaptability, diversity, robustness, and stability. This improvement enables the algorithm to excel in solving complex optimization challenges, thereby enhancing its efficiency and performance. Ultimately, it empowers the algorithm to tackle real-world problems more effectively, contributing to advancements in various domains.
Algorithmic implementation

The pseudocode of enhanced PGWO algorithm formalizes three core improvements over standard GWO. 1. 2.
Elite group (top 25%): Performs localized refinements using inertia-weighted perturbations (w×Positions[i] + Positions[i]×rand())
Middle group (50%): Balances exploitation (0.5×(Alpha_pos - Positions[i])) and exploration (0.5×(RandPos - Positions[i]))
Follower group (bottom 25%): Forces convergence by strongly attracting solutions toward the alpha position (w×Positions[i] + 0.5×(Alpha_pos - Positions[i])) (3)
Momentum coefficient w adapts nonlinearly via DynamicWeight(t) (equation (13))
Terminates if the global best solution remains unchanged (<1e-6) for 10 consecutive iterations.
Inputs include population size (pop), search bounds ([lb, ub]), and maximum iterations (maxIter); outputs are the optimal solution (Best_Pos) and its fitness (Best_fitness). Boundary constraints are enforced via BoundCheck().
Simulation experiment and result analysis
Preparation for experiment
To ensure the accuracy and reproducibility of our experimental results, all experiments in this study were conducted in a consistent computational environment. Specifically, the experiments were carried out on a computer equipped with a 12th Gen Intel(R) Core(TM) i7-1260P processor with a main frequency of 2.10 GHz and 16.0 GB of RAM. The operating system was Windows 10, and chose Matlab R2022b as the platform for algorithm development to leverage its robust capabilities in numerical computation and visualization.
Under the Matlab R2022b environment, the experimental environment was configured using the following steps. (1) Initialization of Algorithm Parameters: To validate the optimization accuracy and convergence speed of the proposed improved algorithm, 12 standard test functions were used for comparative experiments.
20
Table 1 lists the function names, expressions, and search ranges. To ensure unbiased results, the population size and maximum number of iterations for all functions were set to 50 and 300, respectively. Each algorithm was independently tested 30 times for each function. (2) Data Preprocessing: All datasets used for training and testing were subjected to standardization processing to eliminate the impact of different scales. (3) Algorithm Implementation: The improved Grey Wolf Optimization (PGWO) algorithm was implemented and finely tuned to meet the specific requirements of traffic violation prediction. (4) Performance Evaluation: Metrics such as accuracy, recall, and the F1 score were used to assess the performance of the algorithm, and cross-validation methods were employed to ensure the robustness of the evaluation results. Test functions used.

To promote transparency and reproducibility in scientific research, we commit to making the experimental code and datasets publicly available on [GitHub] after the publication of the paper for reference and validation by fellow researchers.
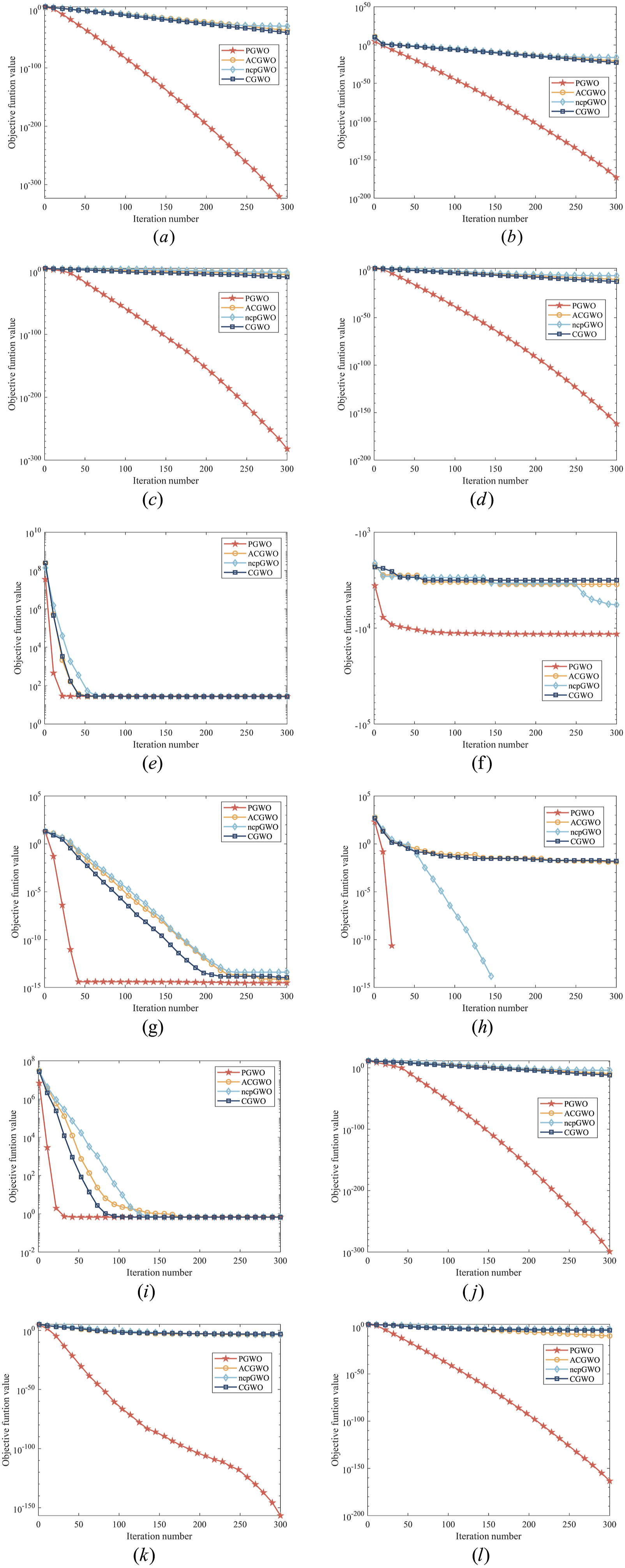
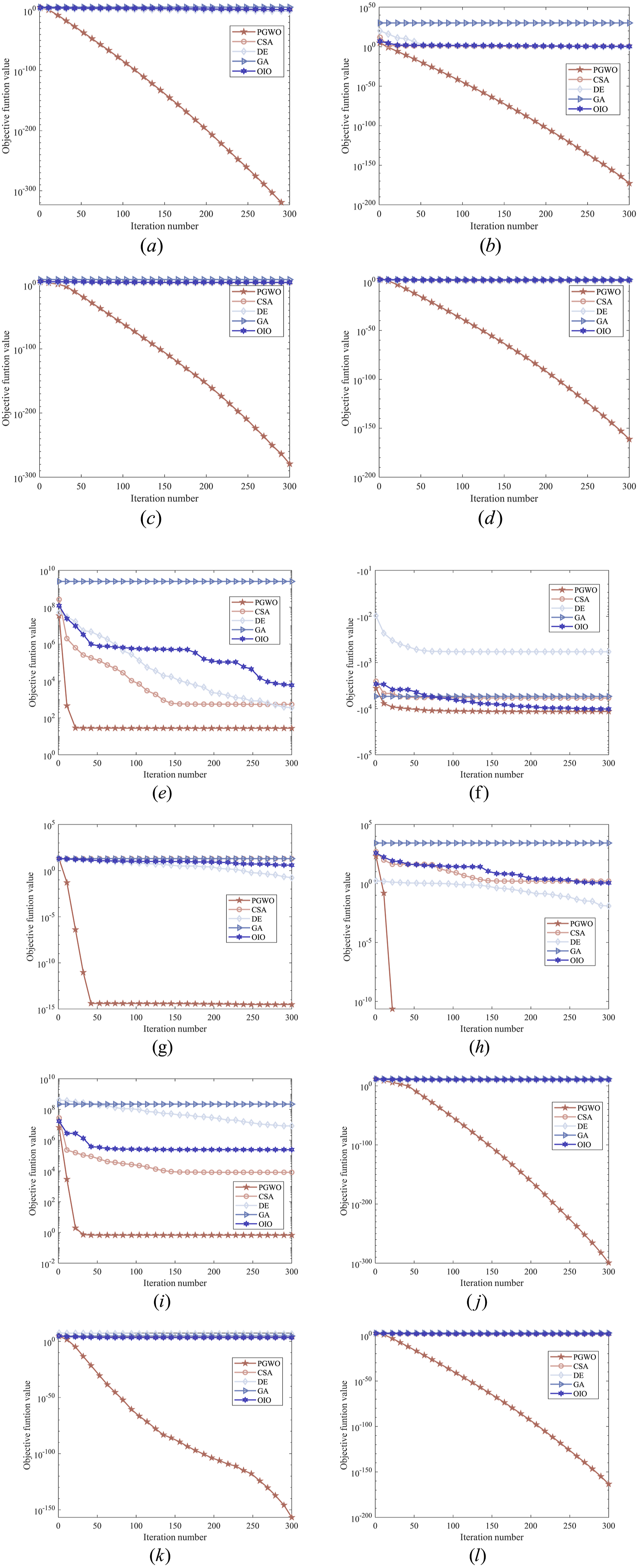
To ensure fair comparison across algorithms, the objective function values were normalized to the range [0, 1] using min-max scaling: Comparison of GWO variant algorithms. (a) f1, (b) f2, (c) f3, (d) f4, (e) f5, (f) f6, (g) f7, (h) f8, (i) f9, (j) f10, (k) f11, and (l) f12. Comparison between GWO and other original algorithms. (a) f1, (b) f2, (c) f3, (d) f4, (e) f5, (f) f6, (g) f7, (h) f8, (i) f9, (j) f10, (k) f11, and (l) f12.
Comparison algorithm
GWO variant algorithm
A variant algorithm is an adaptation or refinement of the original algorithm designed to enhance its performance. By comparing different variant algorithms, we expand our options and can identify the most suitable one for a specific problem. Therefore, we chose variants of GWO for performance comparison, enabling a thorough assessment of their effectiveness.
The CGWO (Chaotic Grey Wolf Optimization) algorithm enhances the basic Grey Wolf Optimization by integrating chaotic sequences, boosting diversity and global search capabilities. 21 It excels in global exploration, evading local optima, and enhancing position exploration.
The ACGWO (Adaptive Chaotic Grey Wolf Optimization) aalgorithm incorporates adaptive mechanisms for stability and convergence speed improvement. 22 It integrates nonlinear convergence factors to balance global and local exploration, maintaining diversity while ensuring precision.
The ncpGWO (Grey Wolf Optimization based on nonlinear control parameter combination strategy) algorithm introduces a nonlinear control parameter adjustment strategy to enhance search efficiency and convergence. 23 It dynamically adjusts control parameters to improve global search capabilities and speed up convergence for complex optimization problems.
Other original algorithms
Traditional optimization algorithms have been widely employed in research, showcasing robust performance and efficacy across diverse problem domains. They are renowned for their interpretability and reliability.
The CSA (Cuckoo Search Algorithm) is a heuristic optimization technique inspired by the parasitic behavior of cuckoo birds. 24 It achieves global exploration of the solution space by randomly generating new solutions and updating them using local search strategies. The key advantage of CSA lies in its straightforward update mechanism and adaptable parameter adjustment, which make it effective for optimizing parameters in complex problems.
DE (Differential Evolution Algorithm) is a heuristic random search algorithm that employs population differences to tackle optimization problems. It optimizes the objective function by leveraging the variations among individuals in the population. 25 DE is known for its simplicity and minimal number of control parameters, making it a potent tool for solving a wide range of optimization issues.
OIO (Optical Optimization Algorithm) is an optically inspired optimization algorithm used to solve optimization problems. The algorithm is inspired by optical principles and performs search and optimization by simulating optical phenomena. 26 In addition, the OIO algorithm is able to find a better solution in a shorter time, so it has a wide range of potential in practical applications.
GA (Genetic Algorithm) is a heuristic optimization technique inspired by genetic principles and natural selection. One of GA’s strengths is its versatility in addressing different optimization problems. 27 It adapts parameters based on problem characteristics and search progress, enhancing the algorithm’s robustness and convergence speed.
Simulation test method
The previous standard test functions include a series of functions commonly used in optimization algorithms, covering different problem types and difficulty levels. The improved PGWO algorithm is tested on these functions to evaluate its performance in addressing various types of optimization problems, the Wilcoxon rank sum test 28 is utilized to compare the performance differences between the enhanced PGWO algorithm and other optimization algorithms. 28 By pairing the algorithm’s performance on each test function, it is possible to determine whether the improved PGWO algorithm performs better in a particular function. 29 This helps to identify the strengths and weaknesses of the algorithm in different problem domains. On the other hand, the Friedman test 30 is employed to assess the overall performance of the enhanced PGWO algorithm. By aggregating the algorithm’s results across all test functions and conducting statistical analysis, it becomes feasible to determine whether the enhanced PGWO algorithm exhibits robust performance across all test functions and outperforms other algorithms. 31 This helps to get a more complete picture of the overall performance of the algorithm and provides references and guidance for further improvements.
Through these tests and analyses, we can thoroughly assess the effectiveness and reliability of the enhanced PGWO algorithm in addressing various types of optimization problems. This evaluation provides valuable guidance and support for its application in practical scenarios.
Analysis and discussion of experimental results
Result analysis of standard test functions
Comparative analysis of GWO variants
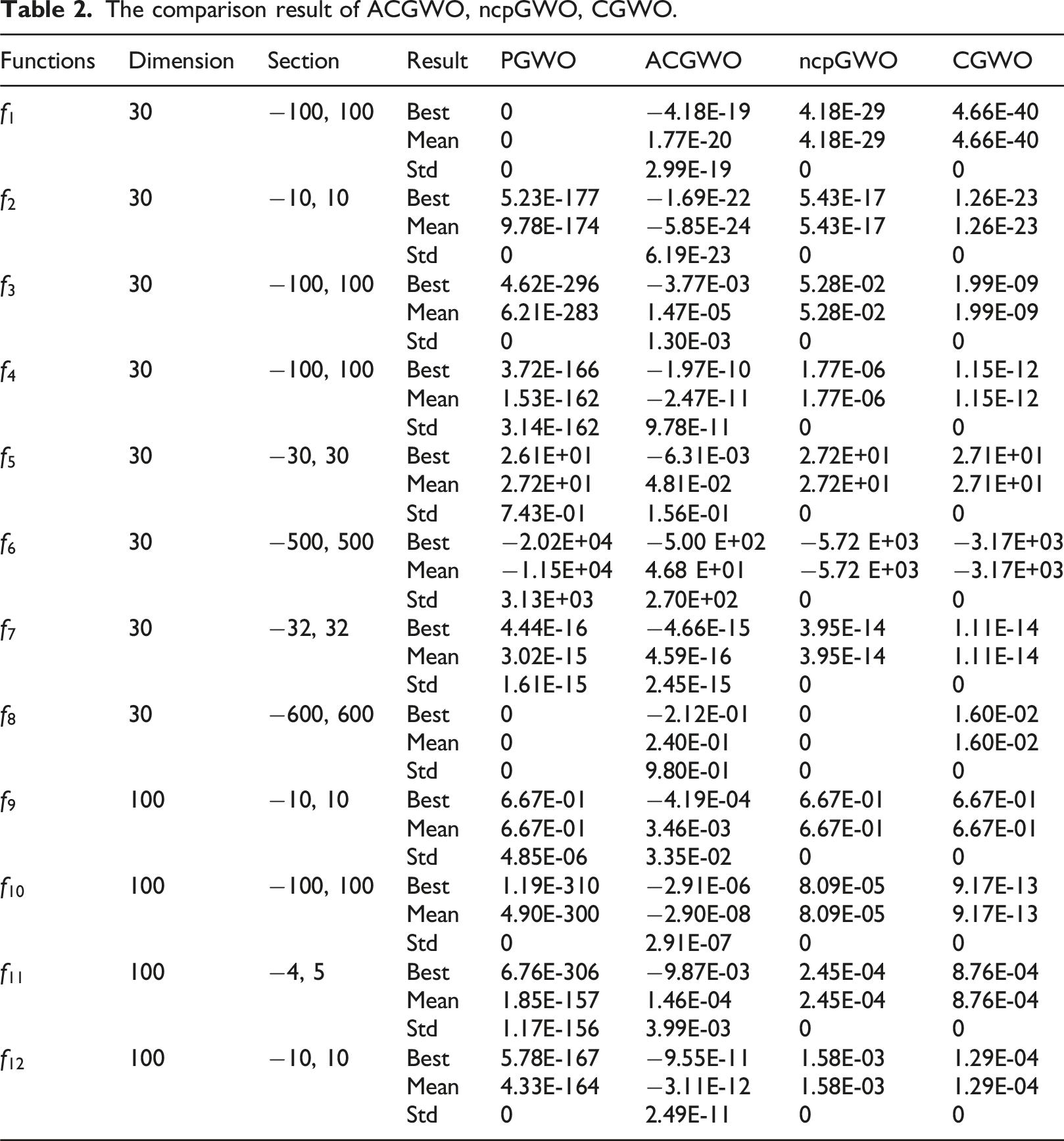
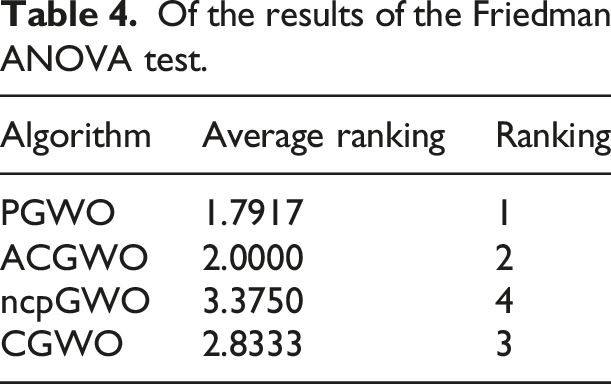
To highlight the advantages of the PGWO optimization algorithm, we compared it with GWO variants such as ACGWO, CGWO, and ncpGWO. As shown in Figure 3, PGWO demonstrates clear benefits, including a faster convergence rate than the three GWO variants, and it approaches the global optimal solution more quickly.
The comparison result of ACGWO, ncpGWO, CGWO.
The rank sum test p-value.
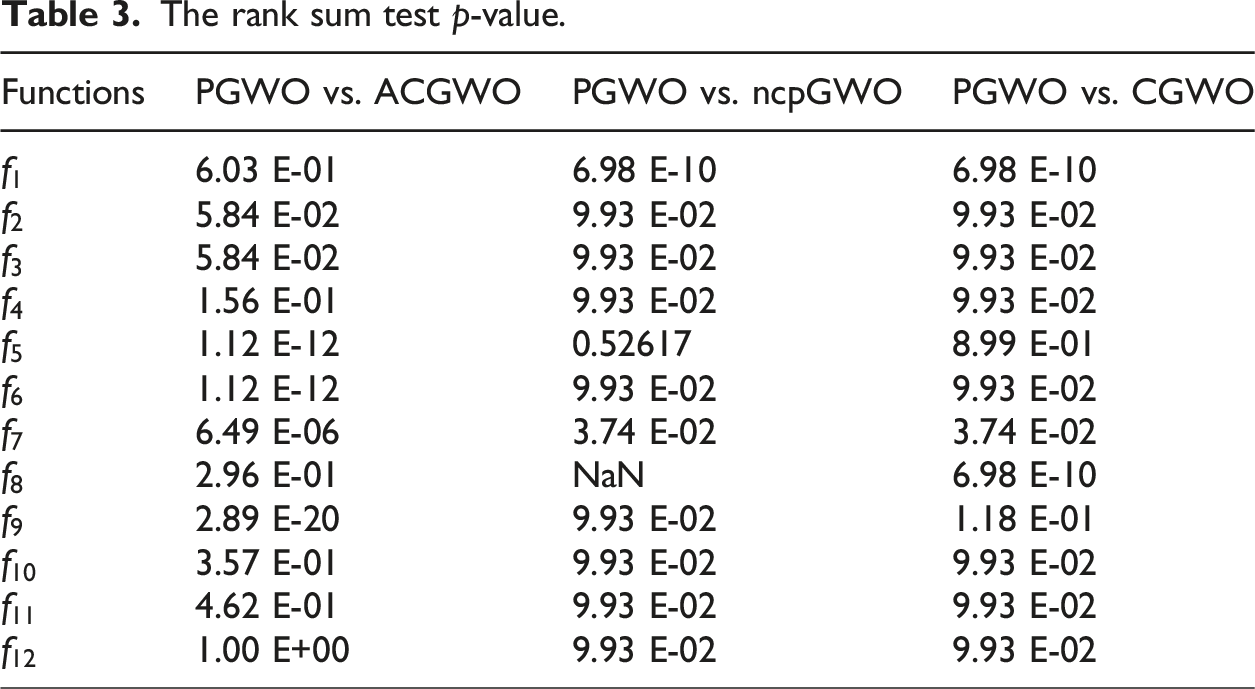
Of the results of the Friedman ANOVA test.
GWO results analysis with original algorithm discussed
To evaluate the applicability and interpretability of the PGWO algorithm, we compared it with four traditional algorithms: CSA, OIO, DE, and GA. As shown in Figure 4, the experimental results indicate that PGWO has a faster convergence rate compared to the three GWO variants and quickly approaches the global optimal solution while avoiding local stagnation.
The comparison result of CSA, OIO, DE, GA.
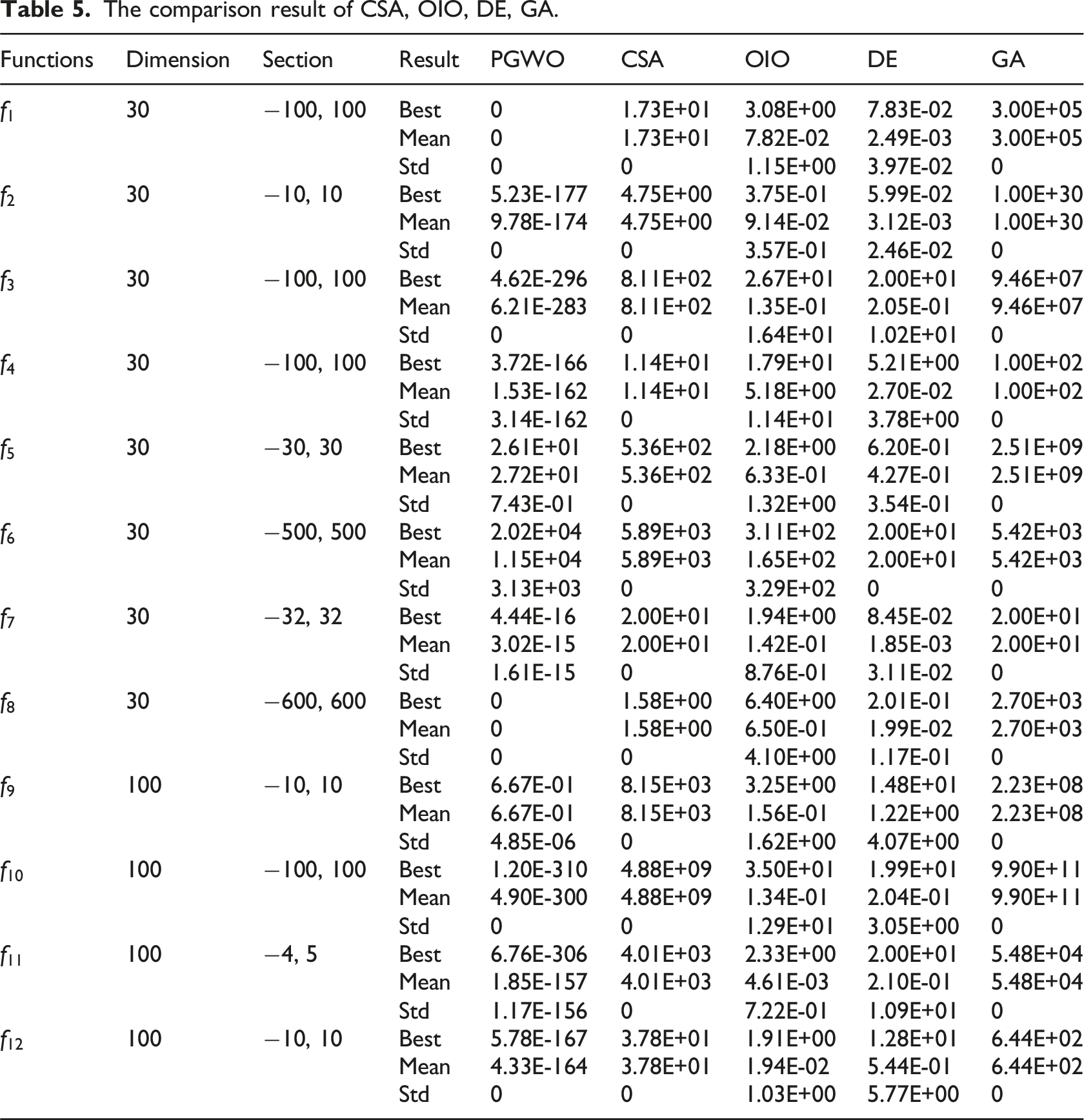
The rank sum test p-value.

The results of Friedman ANOVA test.
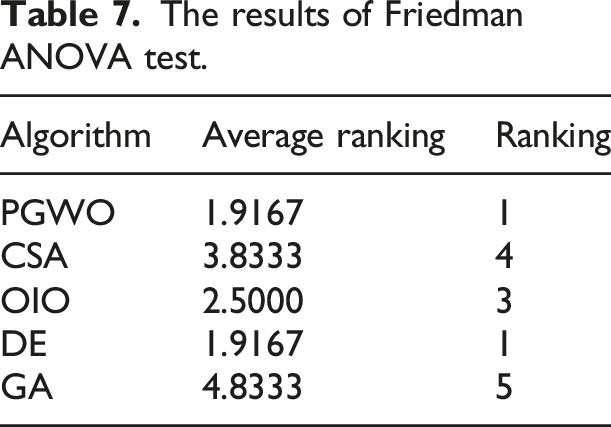
Through three types of experiments, the PGWO algorithm consistently outperforms GWO variants and traditional algorithms by achieving the best global optimal solution. Statistical tests confirm its efficiency. Its mechanisms prevent the loss of optimal solutions during migration and avoid local optima. The perturbation mechanism enhances exploration diversity, while the classification exploration mechanism balances exploration and exploitation. These strengths make PGWO promising for practical applications like intelligent traffic management and legal data analysis, providing reliable predictions and optimization results.
Application of case studies
In this paper, the PGWO algorithm is employed to enhance the performance optimization of a multi-feature classification prediction model based on PNN (Probabilistic Neural Network) based on several key reasons. 1. Probabilistic decision-making capability: the PNN is a probabilistic-based model that classifies data by means of a probability density function, which gives it a natural advantage in dealing with uncertainty and ambiguity, which is particularly important for traffic violation prediction. 2. Simplified network structure: compared to traditional neural networks, PNNs have a simpler network structure without hidden layers, which reduces the complexity of the model and the risk of overfitting, while speeding up training. 3. Efficient data processing: the PNN demonstrates an efficient ability to process large-scale datasets, which is essential for analyzing a wide range of traffic violation records. 4. Adaptable: the PNN model is able to adapt to different types of data distributions, which makes it widely applicable in diverse traffic violation scenarios.
Real-time prediction is important in traffic management systems, but the focus of this paper is on optimizing the accuracy and efficiency of traffic violation prediction rather than real-time.
Although the chosen PNN is a binary classification model, this study focused on the judgment of violation or non-violation, which is sufficient for understanding the overall trends and characteristics of violations. In addition, the simplified model helps to focus resources on optimizing the performance of the algorithm, for example, improving the accuracy of the predictions and reducing the rate of false positives.
Dataset for experimental applications
In this study, to make a more accurate assessment of the optimization degree of the PNN model by PGWO, four different datasets were selected. By comparing the results obtained from the model, a more comprehensive and objective analysis of the performance optimization of PGWO on the PNN model was conducted. The decision to use 70% of the data as the training set and 30% as the test set was based on extensive experimental validation. This division ensures model training efficiency while providing sufficient data to verify the model’s generalization capabilities. Furthermore, a detailed analysis of each dataset was conducted to ensure that the processing methods effectively enhance the performance of the PGWO + PNN model under various data environments.
Summary statistics of the experimental dataset.
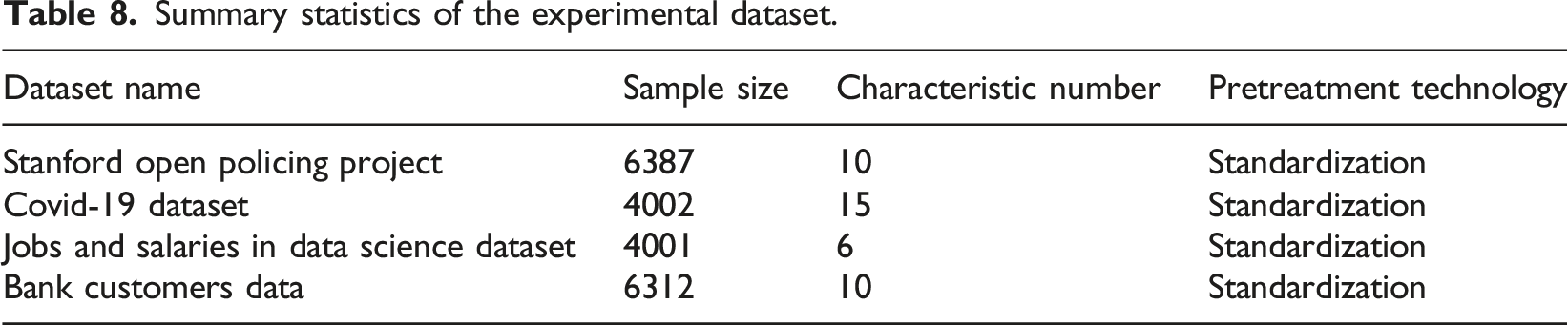
To ensure that the PGWO + PNN model demonstrates stable performance across various data environments, this experiment paid special attention to the issue of dataset imbalance and took the following measures to address this challenge. (1) Resampling Techniques: For the Traffic Dataset (Stanford Open Policing Project) and the Covid-19 dataset, employing a combination of oversampling and undersampling to balance the class distribution. Specifically, it used the SMOTE technique to generate synthetic samples for the minority class while moderately undersampling the majority class. (2) Adjustment of Classification Thresholds: In the Bank Customers Data, which found that simple resampling might not be sufficient to address extreme imbalances. Therefore, it was adjusted the classification thresholds to reduce the bias toward the majority class and improve the recognition rate of the minority class. (3) Cost-Sensitive Learning: For the Jobs and Salaries in Data Science dataset, it introduced cost-sensitive learning, assigning different penalty weights to misclassifications of different classes, thereby increasing the model’s sensitivity to the minority class.
Traffic data set (Stanford Open Policing Project)
This article uses a dataset provided by the Stanford Open Policing Project. 32
The Stanford Open Enforcement Project provides a unique dataset of detailed traffic stop records from Rhode Island since 2013. These data not only record basic information about the violation, but also include key information such as the enforcement officer’s observations, type of violation, time, and location. This detailed information provides a valuable opportunity for research to analyze in-depth patterns of traffic violations and the factors that influence them.
In the study, these data were used to train and validate the PGWO + PNN model. By using these data to identify and predict possible traffic violations, this not only helps to improve the efficiency of traffic management, but also enhances the fairness and transparency of enforcement. With these data, it is possible to demonstrate the effectiveness of the model in dealing with the actual task of traffic violation prediction.
Coronavirus dataset (Covid-19 dataset)
This dataset was provided by the Mexican government, which contains an enormous number of anonymized coronavirus-related data for machine learning (https://datos.gob.mx/busca/dataset/informacion-referente-a-casos-covid-19-en-mexico). The dataset makes predictive classifications based on an individual’s age, sex, underlying disease, biomarkers and lab test results. In this study, the dataset was used to evaluate the potential application of the PGWO-PNN model in the field of medical prediction.
The Jobs and Salaries in Data Science dataset
This dataset explores the relationship between job titles, salaries, and related factors in data science, which is gained from the kaggle dataset (https://www.kaggle.com/datasets/hummaamqaasim/jobs-in-data?rvi=1). The data set includes factors such as job title, job category, experience level, company location, and company size to predict salary levels. This study used this dataset to verify the ability of the PGWO-PNN model to process job and salary predictions.
Bank Customers Data (Bank Customers Data)
This data set relates to the direct marketing activities of a banking institution in Portugal. 33 The data set includes factors such as type of job, level of education, loan situation, and so on, with the aim of predicting whether a customer subscribs to a fixed deposit. This study used this dataset to examine the effectiveness of the PGWO-PNN model in financial marketing and customer behavior prediction.
Alternative comparison algorithms for PNN model applications
The Whale Optimization Algorithm (WOA) mimics the hunting behavior of humpback whales, using a bubble-net strategy to optimize solutions by simulating the encircling of prey with bubbles, effectively navigating complex search spaces. 34
The Crested Porcupine Optimization algorithm (CPO), emulates the defense mechanism of crested porcupines, employing a strategy of quill deployment to explore and exploit solution spaces, adeptly avoiding predators or local optima in search of global optima. 35
Parameter settings
The structure of PGWO-PNN multi-feature classification prediction model includes input layer, pattern layer, competition layer, and output layer. The PNN model is trained using the best parameters found by the optimization algorithm (PGWO). The number of nodes in the hidden layer is set to (2 × number of input nodes + 1), and the training process of PNN is realized by adjusting the weight of the pattern layer to maximize the model’s degree of fitting to the training data. 36 By using the PGWO algorithm to optimize the parameters of the PNN model, the task of classifying the training set and the test set is realized. PNN model combines probabilistic modeling and neural network technology, and has good performance in pattern recognition and classification tasks. 37 With the help of training and simulation tests, the accuracy of the model was evaluated, and the optimization curve, confusion matrix and ROC curve were drawn to comprehensively evaluate the classification effect and performance of the model.
The selection of key parameters was based on a parameter sensitivity analysis of the system and a grid search validation process. The population size was set to 50, which was the optimal value determined after testing in the range of {30,40,50,60,100}: smaller sizes (e.g., 30) lead to insufficient diversity and tend to fall into local optimality; larger sizes (e.g., 100) significantly increase computational cost and have limited convergence gain (only <5% increase in convergence speed for >50 individuals). The maximum number of iterations was set to 300, which was determined by observing the rate of change of the objective function: when the number of iterations exceeded 250, 90% of the tested functions had an objective function improvement rate of less than 10-6. The choice of the momentum coefficient parameters (a = 0.8, b = 0.01) was based on a pre-experimental sensitivity analysis: testing a ∈ [0.5,1.0] at a fixed b = 0.01, a = 0.8 was found to yield optimal stability (15%–22% reduction in the standard deviation) for the F6, F9 functions; similarly, testing b ∈ [0.005,0.05] at a fixed a = 0.8, b = 0.01 balances exploration and development needs.
Experimental analysis
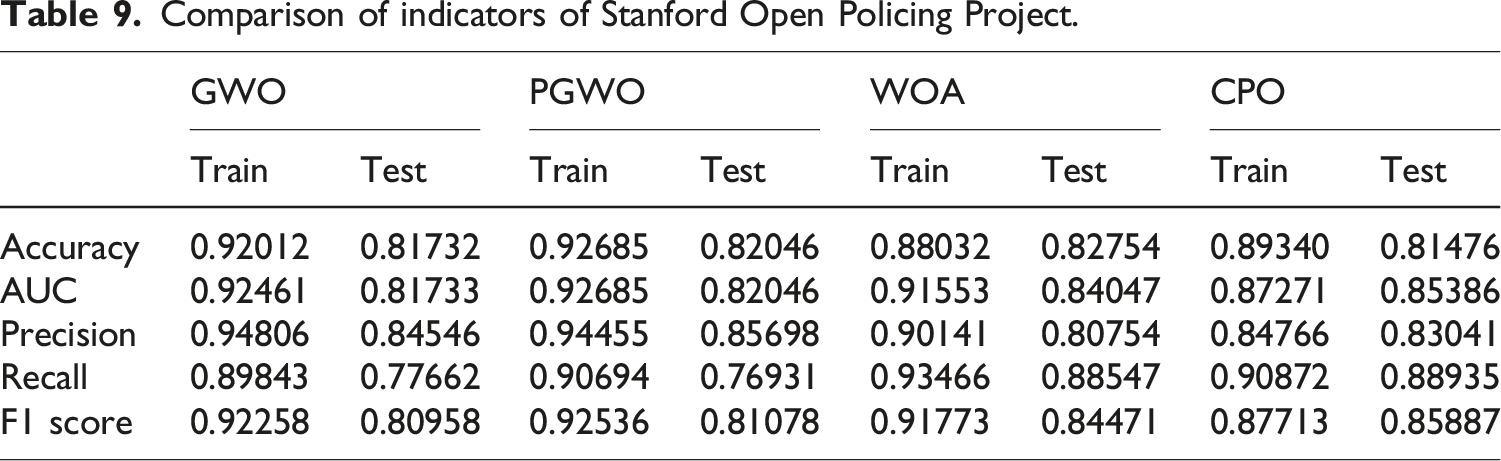
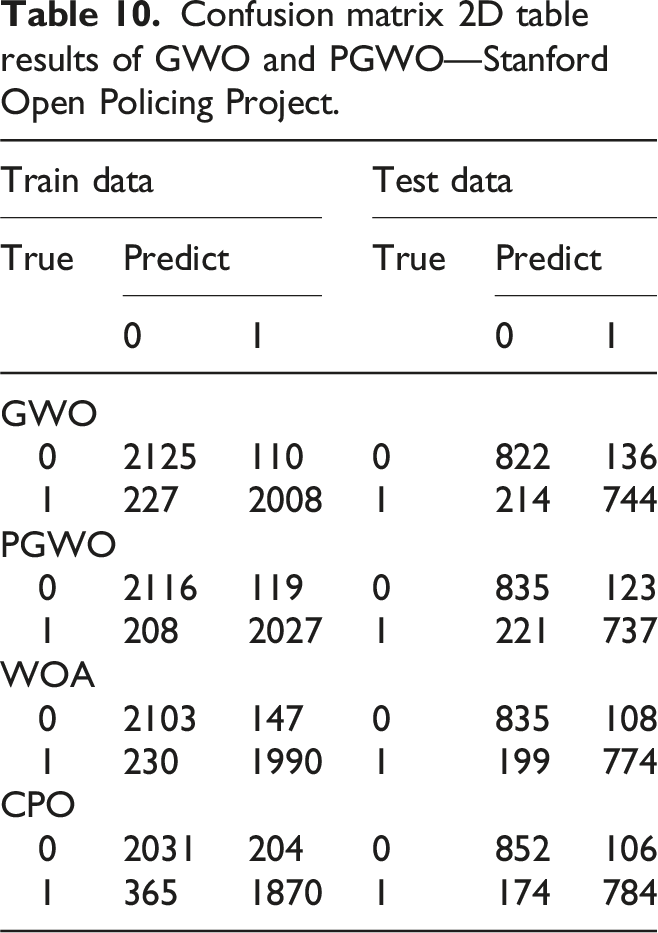
To assess the accuracy of the proposed PGWO-PNN multi-feature classification prediction model for traffic police violations, the PGWO-PNN is compared with the GWO-PNN model in the experiments, as well as comparative analyses with other state-of-the-art algorithms at the Stanford Open Policing Project. The final evaluation criteria for the PGWO-PNN model include the confusion matrix and ROC curve, which are used to evaluate its performance.
In order to comprehensively evaluate the performance of the PGWO-PNN model, the experiment uses four metrics: Accuracy, Precision, Recall and F1 Score.
Accuracy: Proportion of correctly predicted samples to total samples.
Precision: Proportion of samples predicted to be in the positive category that are actually in the positive category.
Recall: Proportion of samples that are actually positive classes that are correctly predicted.
F1 score: Reconciled mean of precision and recall.
Among other things, the TP (True Positive) denotes the true class, and TN (True Negative) denotes the true negative class, and the FP (False Positive) denotes the false positive class, the FN (False Negative) denotes the false negative class.
In category-imbalanced data, relying on accuracy alone can be misleading because the model is biased toward the majority of classes. Therefore, it needs to be judged in conjunction with the recall (reflecting the ability to recognize the minority class) and the F1 score (a combined balance of precision and recall) to avoid the model ignoring the minority class.
Comparison of indicators of Stanford Open Policing Project.
Confusion matrix 2D table results of GWO and PGWO—Stanford Open Policing Project.
According to Figure 5 ROC curve, the ROC curve obtained by PGWO-PNN model showed excellent performance, and its curve showed the characteristics of rapid rise in the early stage, and showed a high degree of prediction accuracy under different thresholds. Compared with the GWO-PNN, WOA-PNN and CPO-PNN model, the ROC curve of the GWO-PNN model is closer to perfect, and its AUC value is higher, indicating that it has excellent performance in classification tasks. This shows that the PGWO-PNN model has important value in practical applications and can provide reliable prediction results for decision-making. The result of ROC curve of GWO—Stanford Open Policing Project. The result of ROC curve of PGWO—Stanford Open Policing Project. The result of ROC curve of WOA—Stanford Open Policing Project.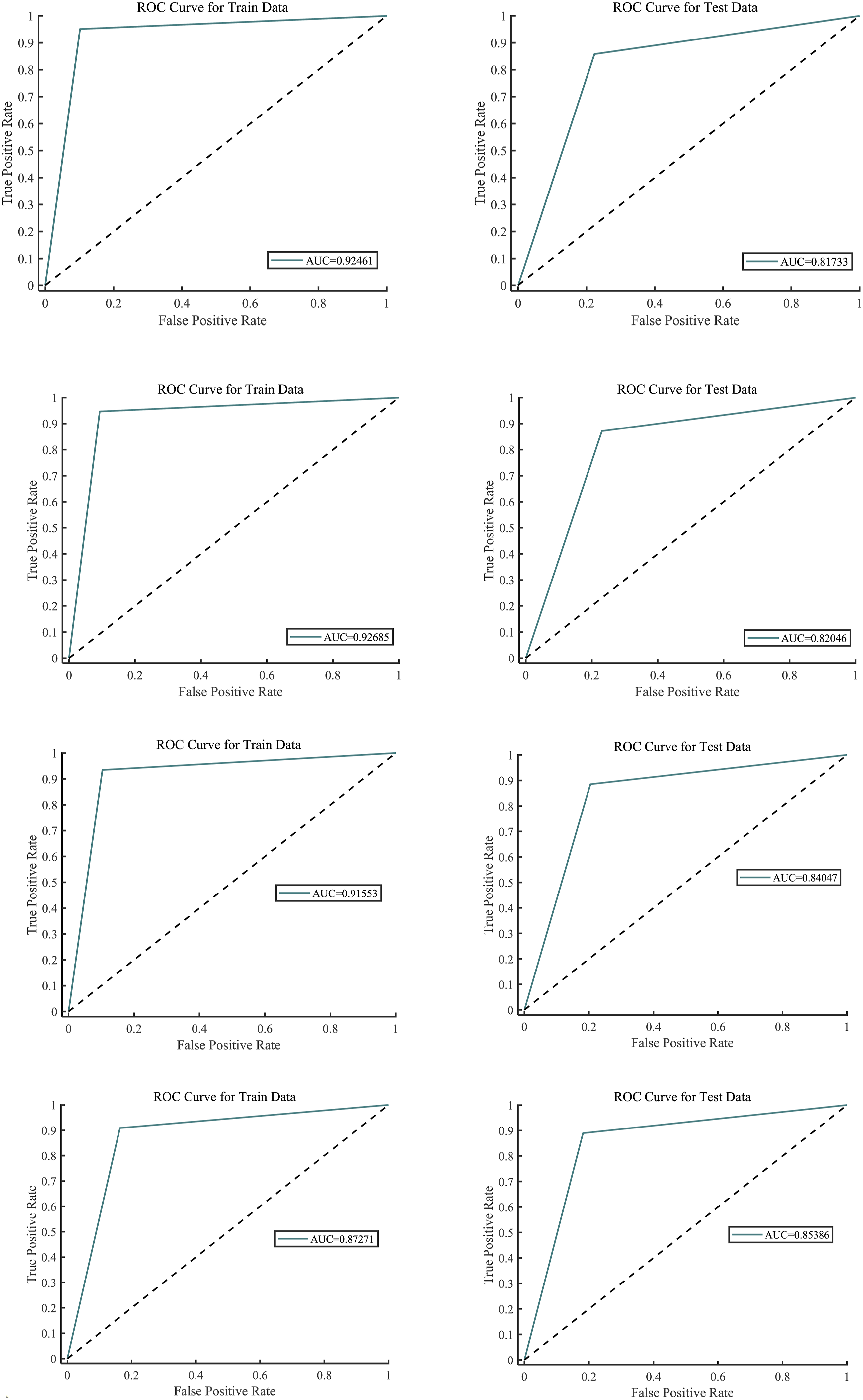
In the Covid-19 dataset, according to Figure 6 ROC curve, the ROC curve obtained by the GWO-PNN model is close to that obtained by the GWO-PNN model, but as can be seen from Table 11, Accuracy of the five indexes of PGWO-PNN (including accuracy, AUC, accuracy, recall rate, and F1 score) is nearly 0.16665 higher than that of the test set of GGO-PNN. The PGWO-PNN model can perform multi-feature classification prediction more accurately than the GWO method. According to the comparison between the real positive and negative classes of the confusion matrix and the predicted positive and negative classes in Table 12, the classification effect of the model can be intuitively seen, which shows that the PGWO algorithm has strong exploration ability and the ability to reduce local optimality. The result of ROC curve of GWO—Covid-19 dataset. The result of ROC curve of PGWO—Covid-19 dataset. Comparison of five indicators of the Covid-19 dataset. Confusion matrix 2D table results of GWO and PGWO—Covid-19 dataset.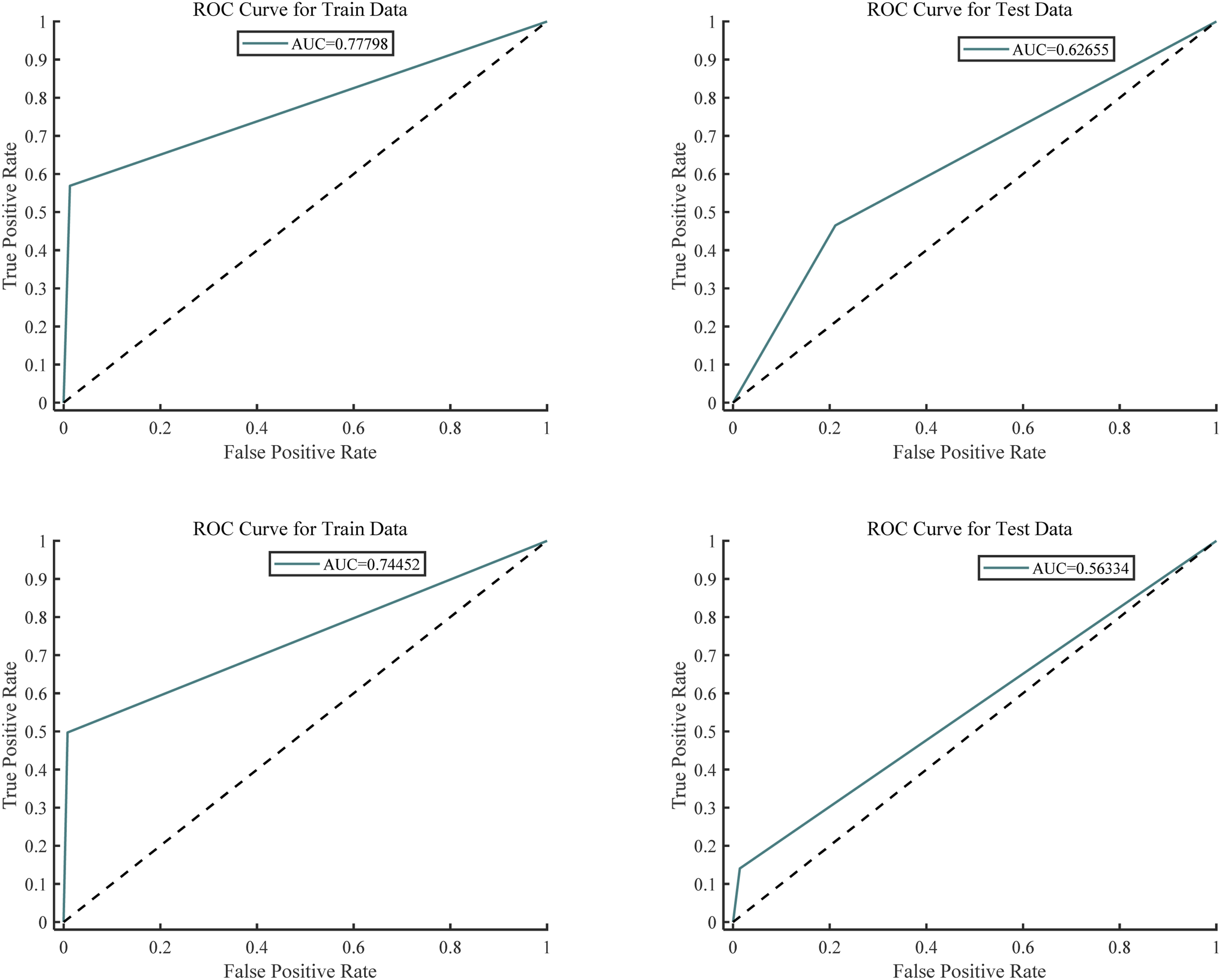
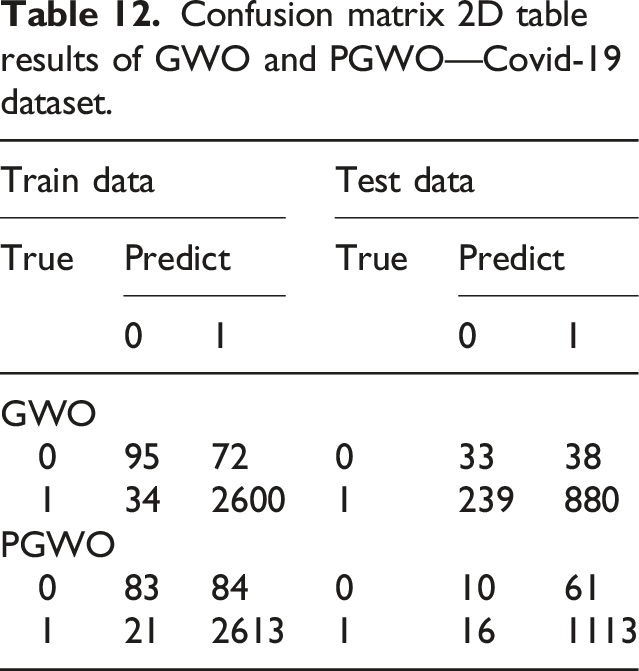
Comparison of five indexes of Jobs and Salaries in Data Science.
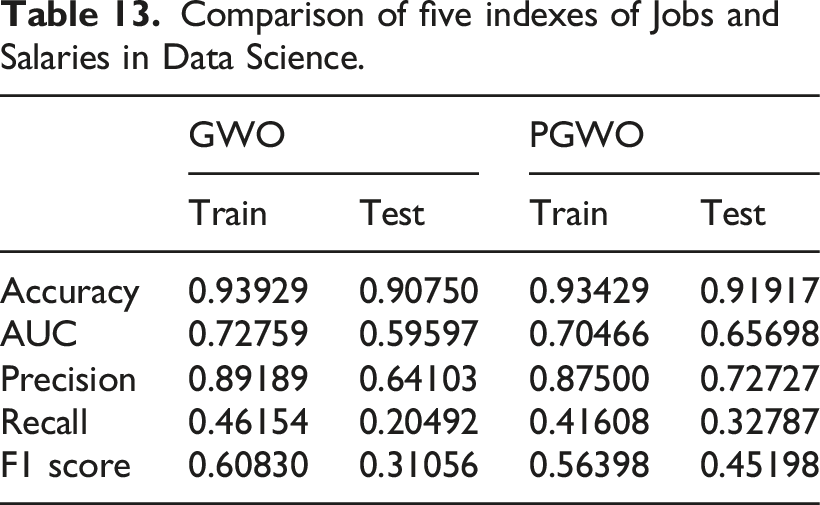
Confusion matrix 2D table results of GWO and PGWO—Jobs and Salaries in Data Science.
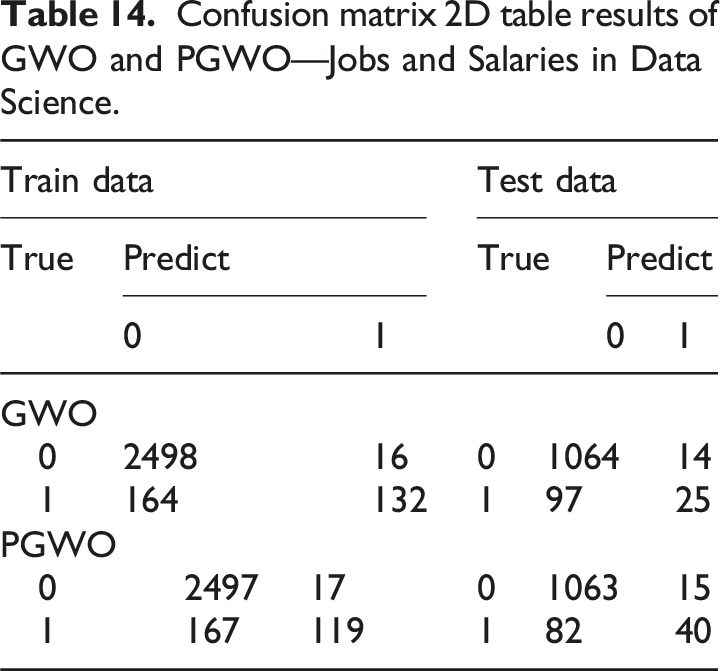
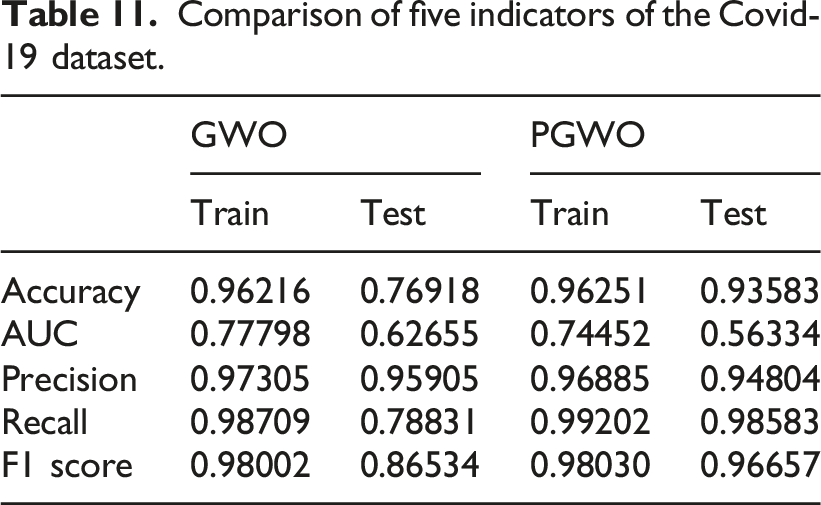
According to Figure 7 ROC curve, the ROC curve obtained by the PGWO-PNN model showed excellent performance in the test set, and its curve showed the characteristics of rapid rise in the early stage, and showed high prediction accuracy under different thresholds. Compared with the GWO-PNN model, the ROC curve of the GWO-PNN model is closer to perfect, and its AUC value is higher, indicating that it has excellent performance in classification tasks. This shows that the PGWO-PNN model has important value in practical applications and can provide reliable prediction results for decision-making. The result of ROC curve of GWO—Jobs and Salaries in Data Science. The result of ROC curve of PGWO—Jobs and Salaries in Data Science.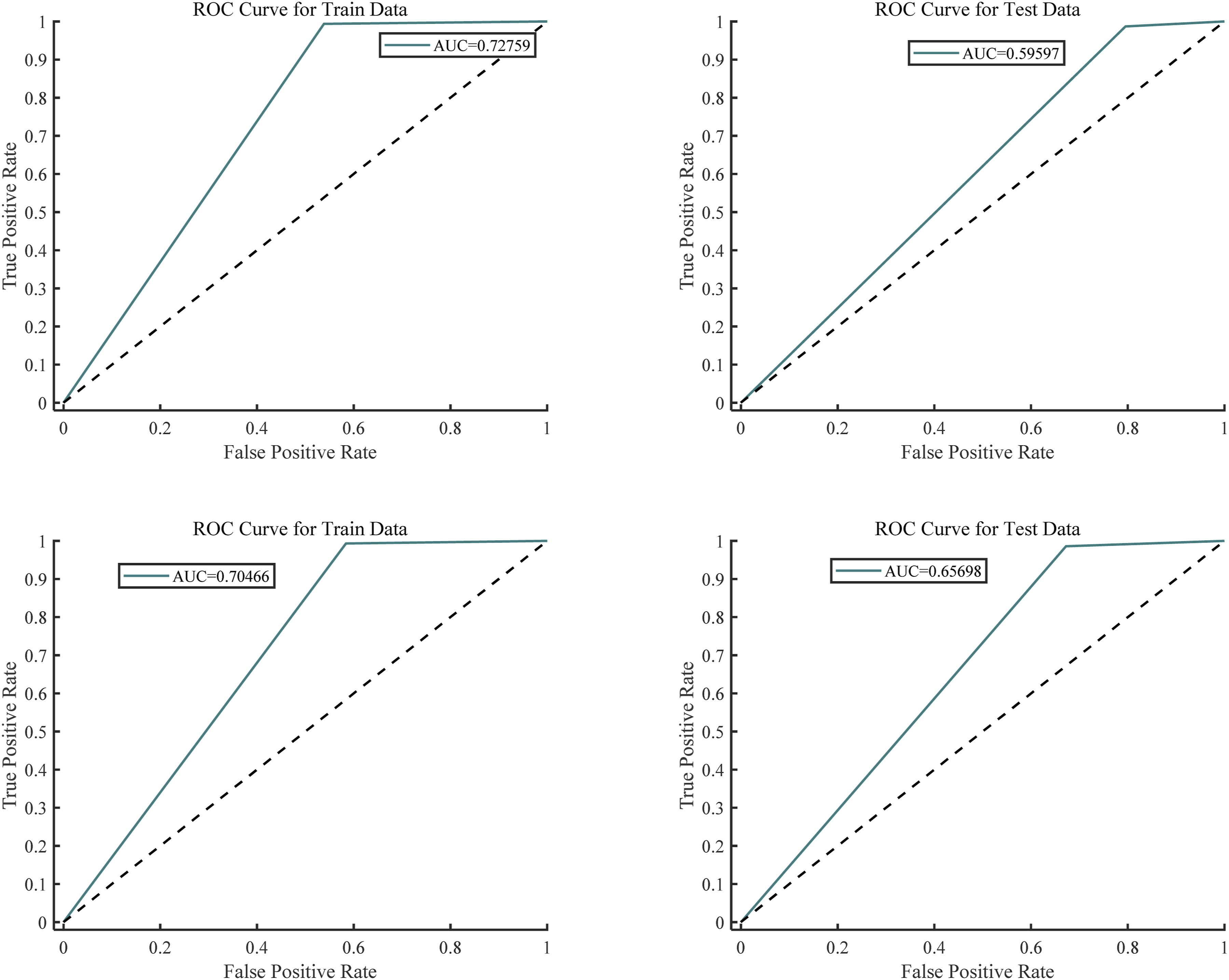
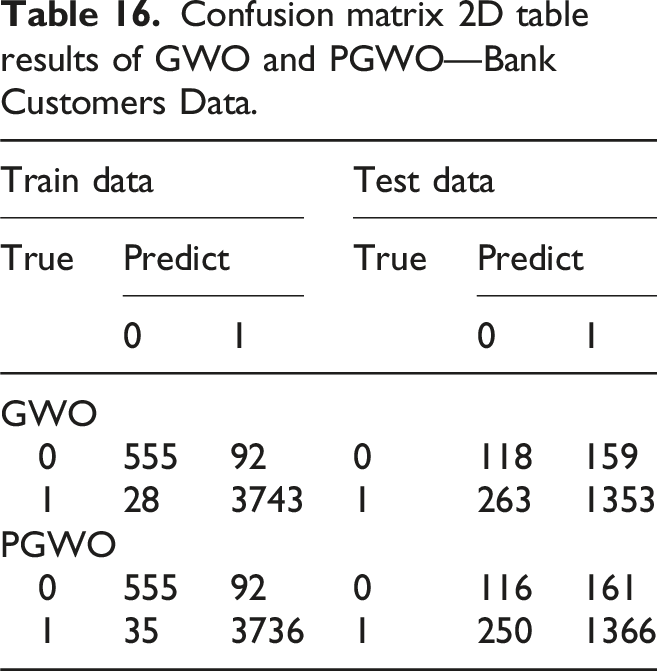
In the experimental results of Bank Customers Data set, according to the ROC curve in Figure 8, the ROC curve obtained by the PGWO-PNN model has a smaller advantage than that obtained by the GGO-PNN in the test set, but as can be seen from Table 15, Five indicators of PGWO-PNN (accuracy, AUC, accuracy, recall rate and F1 score) in the test set are all higher than those of GGO-PNN except Precision, and the difference in Precision values is very small, indicating that the PGWO-PNN model can perform multi-feature classification prediction more accurately than the GWO method. According to the comparison between the real positive and negative classes of the confusion matrix and the predicted positive and negative classes in Table 16, the classification effect of the model can be intuitively seen, and it shows that the PGWO algorithm has strong exploration ability and the ability to reduce local optimality. The result of ROC curve of GWO—Bank Customers Data. The result of ROC curve of PGWO—Bank Customers Data. Comparison of five indicators of Bank Customers Data. Confusion matrix 2D table results of GWO and PGWO—Bank Customers Data.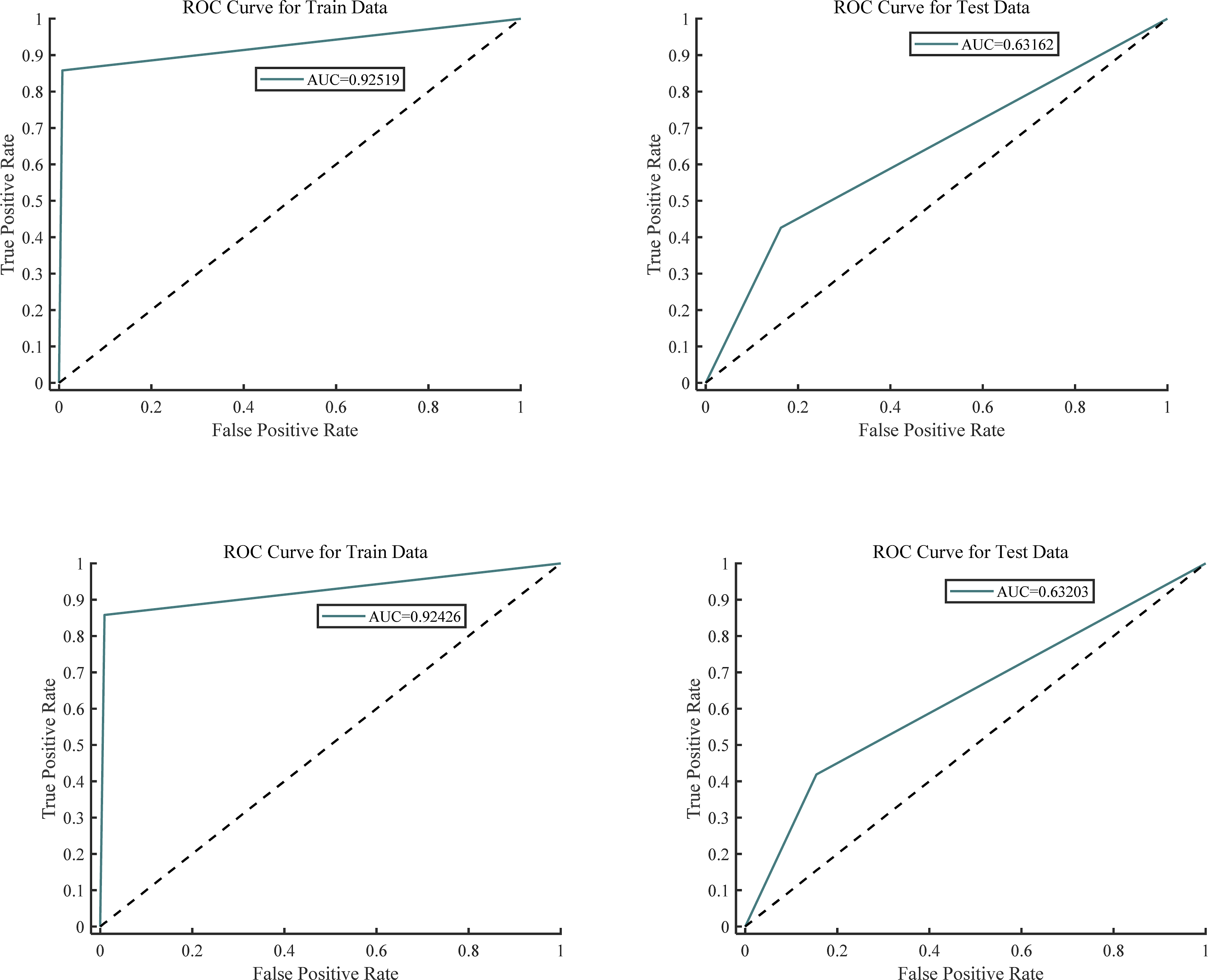

Model robustness and security considerations
Given the critical nature of applications such as law enforcement, ensuring the model’s robustness against adversarial attacks (e.g., deliberately misleading traffic data) is of paramount importance. While the current study primarily focuses on enhancing the accuracy and efficiency of traffic violation prediction, the reliability and security of the model in real-world scenarios cannot be overlooked. Future research will explore methods to strengthen the PGWO-PNN model against potential adversarial attacks. This may involve implementing advanced data preprocessing techniques, integrating anomaly detection mechanisms, and improving the interpretability of the model’s decision-making process. These enhancements aim to ensure that the model maintains its performance and reliability even under various disruptions and manipulations, thereby providing a more secure foundation for practical deployment.
Conclusion
This paper has successfully proposed an enhanced Grey Wolf Optimization (PGWO) algorithm tailored for traffic law compliance problems, marking a significant advancement in the field of intelligent traffic management. The PGWO algorithm, through the integration of a momentum coefficient, group position update strategy, and reverse learning mechanism, has demonstrated superior performance in global search ability and convergence speed. It effectively addresses the issue of premature convergence, a common challenge in complex optimization problems.
The application of PGWO in traffic violation prediction models has yielded remarkable results. When tested on the Stanford Open Policing Project dataset, the PGWO-PNN model outperformed traditional methods and current state-of-the-art algorithms across multiple evaluation metrics, including accuracy, AUC, recall rate, and F1 score. These results underscore the practical value of the PGWO algorithm in providing reliable prediction results for decision-making processes.
The experimental results demonstrate that the PGWO algorithm not only achieves greater accuracy in predicting traffic violations but also enhances the model’s generalization ability. These findings highlight the importance of integrating advanced optimization algorithms with traffic law prediction models, as evidenced by recent studies such as the spherical decision-making model for measuring drivers’ behavior factors 10 and the use of autonomous vehicles in mixed traffic for incident management.11–13 By building upon these advancements, the PGWO algorithm offers a more comprehensive and adaptive approach to traffic law prediction, providing reliable decision-making support for traffic management authorities.
Beyond traffic law compliance, the PGWO algorithm has shown broad applicability and superiority across different fields. Its performance on three additional standard classification datasets further validates its effectiveness and versatility. However, it is acknowledged that the algorithm may have limitations, such as potential underperformance with certain types of traffic data and possible biases in the experimental datasets used.
Looking ahead, future research will focus on expanding the range of datasets and further optimizing algorithm parameters to enhance the robustness and accuracy of the model. There will also be an exploration of PGWO’s potential in the legal field, particularly in processing and analyzing large volumes of traffic stop data. This will involve deeper data analysis and algorithm optimization to develop more accurate predictive models for fair traffic law enforcement. Additionally, efforts will be directed toward optimizing neural network structures and selecting more effective swarm intelligence techniques to improve model recognition accuracy and generalization ability. These advancements are expected to not only enhance traffic violation prediction but also provide robust decision support for other legal domains, such as legal case prediction, legal document classification, and legal risk assessment.
In summary, the PGWO algorithm presents a powerful tool for intelligent traffic management and regulatory compliance. Its continued development and application hold the promise of contributing to a safer, fairer, and more efficient traffic environment.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.